Я работаю над открытой реализацией предложенного стандарта идентификаторов UUIDv7. На данный момент спецификация существует в виде IETF черновика. Черновик уже пережил два переиздания, и мы постоянно обновляем спецификации. Но сам документ — это дело простое. Для того чтобы кто-то мог воспользоваться новыми UUIDv7, нам надо написать как можно больше открытых имплементаций на различных языках.
Мне выпала стезя писать клиент на Golang. И всё бы было достаточно просто, если бы не сам стандарт. Для создания UUIDv7 вам нужно будет постоянно двигать различные биты в разных направлениях.
В этой статье я расскажу, с чем столкнулся, помогая с разработкой на golang.
Работа над подобным проектом — эта та ещё веселуха. Черновик стандарта находится в разработке, и после того как мы пробуем сделать что-то одно, идём, пробуем и разбираемся, что же получилось в итоге.
Во-первых, если вы посмотрите на обсуждение в github, то читать придётся очень много. Каждый из участников пытается спокойно обосновать свою точку зрения, это спокойствие обычно заключается в том, что любой комментарий занимает от двух до пяти страниц текста. Все эти комментарии сопровождаются вдумчивым вступлением и очень осторожным объяснением того, почему автор предыдущего комментария — дурак.
Во-вторых, надо быть готовым воевать. Над стандартом сейчас активно работают три человека. Я подключился к процессу имплементации. И всё бы хорошо… Открываешь документ, начинаешь писать код, аккуратно выравниваешь все значения в памяти, коммитишь код, идёшь, проверяешь комментарии… И впадаешь в ступор. Там уже дерутся по поводу того, сколько бит должна занимать та-самая-фича, которую ты только что писал. Тяжело вздыхаешь и идёшь переписывать уже существующий код.
Иногда, после того как я писал код, ко мне приходили и спрашивали моего мнения. «Удобно ли тебе писалось?». Я наивно отвечал: «Да не очень, но ничего, написалось». В таком случае мне радостно отвечали: «Отлично! Мы пересмотрим стандарт в таком случае, чтобы сделать его проще!». Фейспалм.
Посему основными требованиями для проекта были:
- Данные в памяти всегда хранятся в виде [16]byte, чтобы их можно было запихнуть в уже существующие проекты и как следует протестировать.
- Код должен быть легко изменяемым. Когда ты работаешь с 128 битами, то думаешь, что можно просто взять и захардкодить все данные в нужные места. Но каждое новое утро приносит новые коммиты и новые витки в разработке. Нужно садиться и переделывать всё то, что ты написал. Поэтому мы будем писать код, который позволяет нам эти биты двигать с большей лёгкостью.
Для начала быстрое введение в тему UUIDv7
Вместо генерирования случайных значений в идентификаторах — мы будем зашивать дату и время в сам идентификатор. Разница между UUIDv4 и v7 заключается в том, что последний является бинарно-сортируемым.
Огромное количество движков баз данных позволяет хранить UUID как первичный ключ в таблице. При создании новых записей в распределённых системах создание уникальных идентификаторов — это больная тема. Наш новый стандарт создаёт записи, которые можно отсортировать бинарно. При этом мы можем существенно ускорить и упростить сортировку значений в базах данных. Более того, это положительно отразится на индексах.
Итак, давайте посмотрим на то, с чем мы работаем:
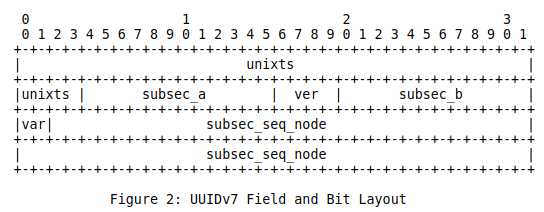
Вот наш герой. Первые 36 бит занимает unix-timestamp. Само по себе это уже гарантирует бинарную совместимость. Мы решили сократить 64 бита ts до 36 бит. При этом мы сможем сохранять даты до 4147 года. Оставшиеся биты нам понадобятся для хранения субсекундной точности. В UUID нам важно сохранить как можно больше энтропии. Первые 28 бит полного unix-ts хранят в себе нули на следующие два тысячелетия, посему мы их отсеиваем.
Далее у нас есть два замечательных прикола, называющиеся «обратной совместимостью». Нам надо хранить значения полей ver и var для совместимости с UUIDv4.
Итак, как вы видите, ничего не равняется ни по каким границам байтов. Более того, значение в поле subsec разбито на две части полем ver. Жизнь была бы намного проще, если бы мы могли просто выровнять всё по байтам и сложить их вместе. Но увы. Придётся выкручиваться.
Давайте посмотрим, что же такое UUID?
Весь код доступен по этому адресуtype uuidBase [16]byte
Какую бы версию UUID мы ни реализовывали, в конечном счёте нам надо выдать 16 байт. А так как нам нужно что-то, что очень легко портируется, переносится и адаптируется, то было бы глупо хранить UUIDv7 в любом другом формате, кроме как массив байт.
В файле uuid_base.go мы описываем этот массив и создаём простые форматтеры, позволяющие выводить сам идентификатор в нескольких широко используемых форматах.
Разврат начинается, когда мы добираемся до самой процедуры генерации идентификатора. В файле uuid_v7.go вы можете найти функцию Next, которая, собственно говоря, и генерирует идентификатор. В текущей реализации пользователь может установить определённые параметры генерации, поэтому сами поля заполняются по-разному.
Если вы посмотрите на эту логику, то увидите, что нам постоянно нужно выставлять определённые биты в определённых позициях в этом массиве данных.
Мы могли создать массив из 128 бит в памяти, но это было бы ужасно расточительно и требовало дополнительной конвертации данных из массива в 128 бит в 16-ти байтовый массив. Вместо этого мы будем писать в память напрямую.
Для этого мы создадим побитовый индексатор, который позволяет получать определённый бит из массива напрямую:
// getBit returns the value of a bit at a specified positon in UUID func (b uuidBase) getBit(index int) bool { pos := index / 8 j := uint(index % 8) j = 7 - j return (b[pos] & (uint8(1) << j)) != 0 } // getBit returns the value of a bit at a specified positon in UUIDv7 func (b UUIDv7) getBit(index int) bool { return uuidBase(b).getBit(index) }
Так как в будущем этот код будет использоваться для генерации UUID версий 6, 7 и 8, то мы пытаемся повторно использовать базовый код. Посему, так как мы не можем напрямую приводить тип UUIDv7 к массиву бит, нам придётся создать функцию, которая будет обращаться к аналогичной функции базового класса.
А после добро пожаловать в мир очень простой магии.
Преобразуем позицию текущего бита в позицию байта путём деления на 8 без остатка, после чего берём остаток, который по факту является позицией бита в байте.
Создаём байт, равный единице. В бинарном представлении у нас получается 0000 0001. Сдвигаем выставленный бит в позицию, которую нам надо получить, и делаем OR. Сравниваем результат с нулём, и у нас в руках нужный бит.
Описанные выше операции тривиальны и не занимают много времени на процессоре, экономя память.
Для выставления бита возьмём за базу тот же код:
// setBit sets the value of a bit at a specified positon in UUID func (b uuidBase) setBit(index int, value bool) uuidBase { pos := index / 8 j := uint(index % 8) j = 7 - j if value { b[pos] |= (uint8(1) << j) } else { b[pos] &= ^(uint8(1) << j) } return b } // setBit sets the value of a bit at a specified positon in UUIDv7 func (b UUIDv7) setBit(index int, value bool) UUIDv7 { return UUIDv7(uuidBase(b).setBit(index, value)) }
Для того чтобы выставить бит, мы опять создаём байт с одним битом и сдвигаем выставленный бит налево, после чего делаем побитовое OR, что гарантирует результат с поднятым битом.
Для того чтобы этот бит опустить, мы делаем побитовое AND с NOT нашего числа.
Итого: мы можем без особых проблем манипулировать битами в памяти напрямую.
Осталось только создать пару вспомогательных функций, которые сделают жизнь легче.
Для начала в данном проекте нам потребуется пара индексаторов:
// indexer returns updated index of a bit in the array of bits. It skips bits 48-51 and 64,65 // for those containt information about Version and Variant and can't be populated by the // precision bits. It also omits first 36 bits of timestamp at the beginning of the GUID func indexer(input int) int { out := 35 + input //Skip the TS block and start counting right after ts block if input > 11 { //If we are bumbing into a ver block, skip it out += 4 } if input > 23 { //If we are bumping into a var block out += 2 } return out } // absoluteIndexer returns updated index of a bit in the array of bits. It skips bits 48-51 and 64,65 // for those containt information about Version and Variant and can't be populated by the // precision bits. It DOES NOT omit first 36 bits of timestamp at the beginning of the GUID func absoluteIndexer(input int) int { out := input //Skip the TS block and start counting right after ts block if input > 35+11 { //If we are bumbing into a ver block, skip it out += 4 } if input > 35+23 { //If we are bumping into a var block out += 2 } return out }
По факту длина нашего UUID равна 123 битам, а не 128. Пять бит уходят на поля var и ver. Поэтому, когда мы складываем биты вместе, нам нужно знать их «относительную позицию» от начала нашего идентификатора.
В дополнение, так как нам нужно складывать последовательности битов, давайте напишем функцию, которая позволяет добавить последовательность битов к идентификатору и возвращает положение курсора для последующей записи данных в массив.
// stack adds a chunk of bits, encoded as []byte at the selected started position, with respect to the timestamp, version and variant values. func (b uuidBase) stack(startingPosition int, value []byte, length int) (uuidBase, int) { cnt := 0 for i := startingPosition; i < startingPosition+length; i++ { bit := getBit(value, (len(value)*8-1)-cnt) b = b.setBit(absoluteIndexer(i), bit) cnt++ } return b, startingPosition + length }
Так как мы пользуемся нашими функциями для индексирования, то поля var и ver останутся незаполненными. Их надо будет забить статическими значениями после того, как генерация была завершена.
//Adding version data [0111 = 7] retval = retval.setBit(48, false) retval = retval.setBit(49, true) retval = retval.setBit(50, true) retval = retval.setBit(51, true) //Adding variant data [10] retval = retval.setBit(64, true) retval = retval.setBit(65, false)
Со всем вышеописанным работа с битами в байтах напрямую становится проще.
//Adding sub-second precision length retval, u.currentPosition = retval.stack(u.currentPosition, precisitonBytes, u.SubsecondPrecisionLength) //If we are using the counter, it goes right after precision bytes if u.CounterPrecisionLength != 0 { //counter bits retval, u.currentPosition = retval.stack(u.currentPosition, toBytes(u.counter), u.CounterPrecisionLength) } //Adding node data after bytes if u.NodePrecisionLength != 0 { retval, u.currentPosition = retval.stack(u.currentPosition, toBytes(u.Node), u.NodePrecisionLength) } //Create some random crypto data for the tail end rnd := make([]byte, 16) rand.Read(rnd) //Copy crypto data from the array to the end of the GUID cnt := 0 limit := absoluteIndexer(u.currentPosition) for i := 127; i > limit; i-- { //Ommiting bits 48-51 and 64, 65. Those contain version and variant information if i == 48 || i == 49 || i == 50 || i == 51 || i == 64 || i == 65 { continue } bit := getBit(rnd, cnt) cnt++ retval = retval.setBit(i, bit) }
Мы просто генерируем куски нашего идентификатора и собираем их в памяти с помощью одной функции.
retval, u.currentPosition = retval.stack(u.currentPosition, precisitonBytes, u.SubsecondPrecisionLength)
Эта функция получает и возвращает значение u.currentPosition, которое позволяет следить за тем, куда мы пишем в данный момент.
Страшная работа по написанию битов в байты выглядит не так уж страшно.
Берём всё, упаковываем, тестируем, создаём релиз, отдаём ребятам «на попробовать». И после сидим и ждём, что будет дальше, и что мы будем менять. Так как переписывать придётся всё, то надо перестать париться о том, что какой-то код можно будет спасти, или о том, что какой-то код можно будет использовать ещё раз.
При этом мы используем 16 байт памяти и не двигаем наш конечный массив туда-сюда по памяти. Экономим память один к шестидесяти четырём, так как массив из 128 бит хранит каждый бит в одном байте из-за выравнивания, и конечный объём памяти на хранение одного идентификатора (128*8) будет равняться одному килобайту, что расточительно для того, что занимает 16 байт.
Весь код доступен по лицензии MIT, посему, если вам приходится работать с битами в golang, вы запросто можете копировать функции из bitsetter.go. Этот код может работать с массивами произвольной длины.
Единственным ограничением будет потенциальное переполнение счётчика битов. Но я очень надеюсь, что вам не придётся писать код для ворочанья битов в гигабайтах информации.
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
— 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
Доступно до 31 декабря 2021 г.

