
22 июня автор курса «Разработчик C++» в Яндекс.Практикуме Георгий Осипов провёл вебинар «Вычисляем на видеокартах. Технология OpenCL».

После перерыва продолжаем публикацию текстовой версии вебинара.
В этой части мы наконец напишем на OpenCL полноценную программу, которая нарисует красивое изображение.
У программы для OpenCL есть две части: kernel-код и host-код — то, что выполняется на видеокарте, и то, что выполняется на компьютере. Кроме того, программу нужно скомпилировать и запустить. Всё это будет рассмотрено в сегодняшней статье. Начнём с самого интересного — напишем часть kernel.
Прежде чем начать, напомним основные термины из предыдущей части.
Kernel-код для OpenCL пишется на C с ограничениями. В нём нельзя использовать:
Тип
Хорошая новость: у OpenCL есть не только ограничения, но и дополнения. Например, очень крутые векторные типы. И честно вам скажу: когда я начал программировать на OpenCL, их стало очень не хватать в обычном программировании на CPU. С векторными типами можно сделать переменную, в которой будет храниться сразу 16 значений
Но не будем отвлекаться и вернёмся к написанию kernel. Мы будем писать функцию, рисующую множество Мандельброта.
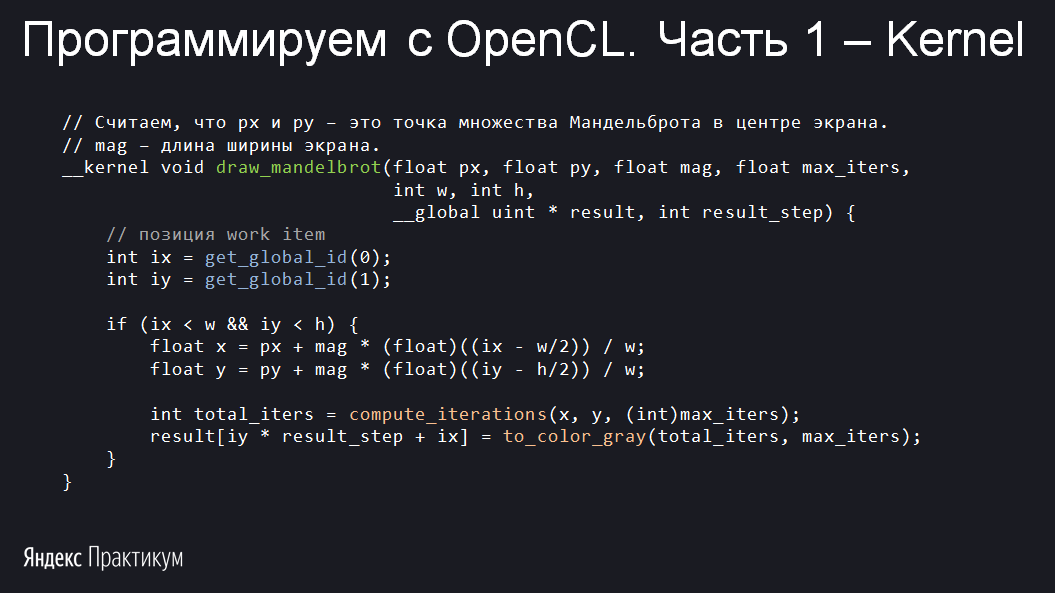
Пишем точку входа — kernel-функцию. Она всегда
Зелёным выделено название kernel, синим — встроенные функции OpenCL, красным — функции, которые мы скоро напишем.
Это двумерная задача. И я хочу, чтобы один work-item рисовал какую-то точку множества Мандельброта. Каждый work-item выполняет код функции независимо от других, и ему прежде всего нужно понять, какую точку множества Мандельброта отрисовать. Чтобы это как-то кастомизировать, в аргументах задаём точку плоскости, которая находится в центре нашей картинки, и масштаб. Разберём аргументы подробнее:
Эти параметры мы зададим в host-коде при вызове kernel. Из них наиболее неочевидны два последних:
Параметр
Последний параметр
При ознакомлении со списком параметров у вас мог возникнуть вопрос: зачем передавать
При помощи функции
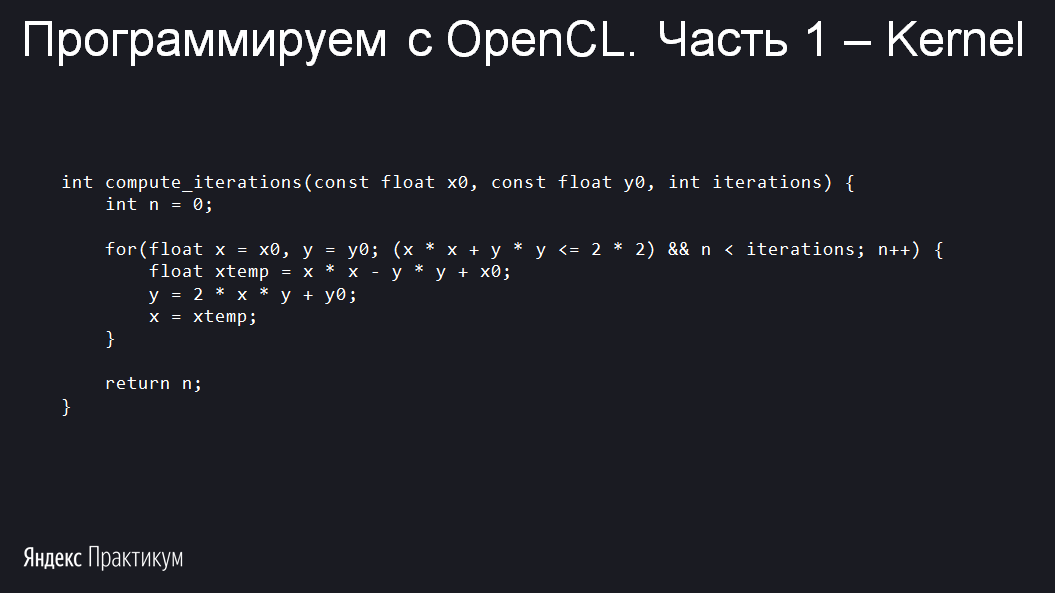
Вычисляем количество итераций для каждой точки экрана
Как видите, ничего страшного и сложного тут нет — обычная функция на C. Для полноты картины не хватает лишь одной маленькой детали —

Вычисляем цвет по количеству итераций
Вот такой нехитрый kernel у нас получился. Переходим к части host.
Теперь kernel-код надо запустить на GPU. План такой:
В конце обязательно прибираем за собой, освобождаем ресурсы.
Программа, использующая OpenCL, выглядит так:

Ошибки в этом примере обрабатывать не будем
Программа начинается с include-директивы. Внутри
Чтобы
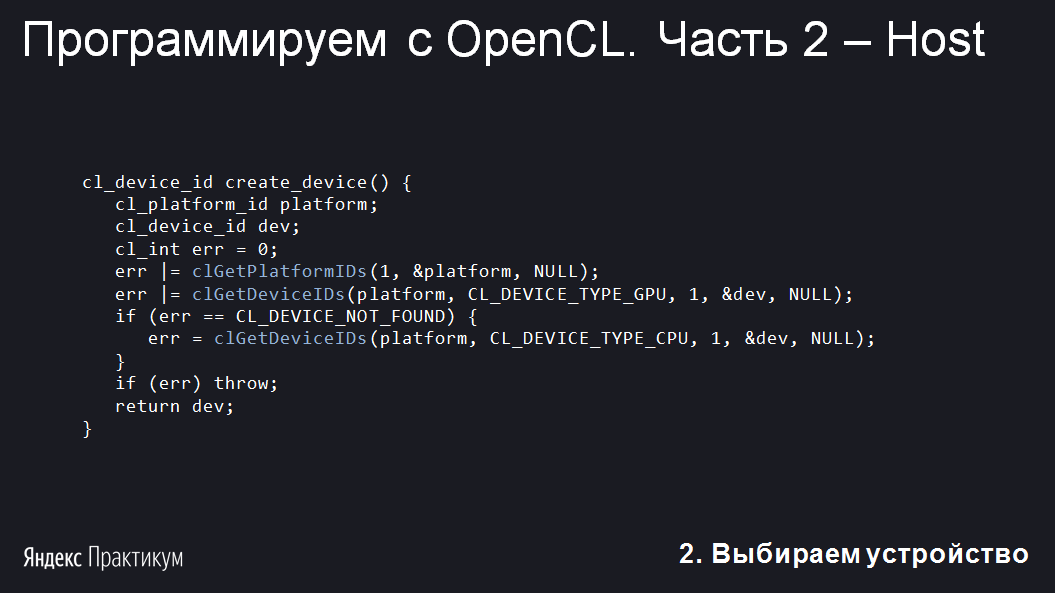
В этом примере не будем умничать и возьмём первое же устройство. Вначале попробуем найти GPU. Если не получилось — ищем CPU. Да, OpenCL может выполняться и на обычном процессоре, если установлен соответствующий драйвер. В реальной программе можно получить список всех устройств и предоставить возможность выбора пользователю. Проверять железо на поддержку не нужно, потому что библиотека OpenCL выдаёт только те девайсы, на которых она будет работать.
В этом примере синим цветом выделены функции из API OpenCL. Здесь также использованы три типа данных OpenCL:
Когда девайс выбран, нужно создать контекст — объект, отвечающий за конкретную сессию взаимодействия с устройством. Ваша программа может создавать несколько контекстов, но они будут работать независимо. Память, выделенная в рамках одного контекста, не может использоваться в другом. Создадим контекст в функции
Теперь всё готово к тому, чтобы переходить к запуску kernel-кода. Но для начала нужно его скомпилировать. Сделаем это такой функцией:

Скомпилированный код программы можно сохранить и переиспользовать
Функция сперва загружает исходный код, а затем выполняет компиляцию. Это простой пример, и в нём не затронуты следующие возможности, необходимые в реальной программе:
Не хватает одной детали — загрузки OpenCL-кода. Для полноты картины приведём эту функцию, хотя в ней нет ничего специфичного:

Код можно прочитать из файла или встроить в программу как ресурс
Далее нужно создать объекты и ресурсы, необходимые для запуска. Мы взяли kernel-код, но не сказали, какая функция из него нам нужна. В нём может быть несколько точек входа, kernel-функций. А нам нужна та, которую мы назвали

Ещё одно важное понятие — очередь. Она нужна для взаимодействия программы и устройства. Вы даёте задачи для GPU, они поступают в очередь. Так как всё происходит асинхронно, видеокарта может быть уже занята задачей, которую ранее поставило ваше приложение либо другая программа, работающая на том же компьютере. Новая команда встанет в очередь и выполнится, когда устройство будет готово. В рамках одной очереди команды выполняются последовательно, но и это можно настроить параметрами функции
Также понадобится буфер для записи результата. Мы получили его, выделив нужное количество видеопамяти функцией
Теперь всё готово. Осталось только запустить kernel. Размер рабочей группы выберем стандартный: 256 в ширину и 1 в высоту. Глобальный размер задаётся параметрами
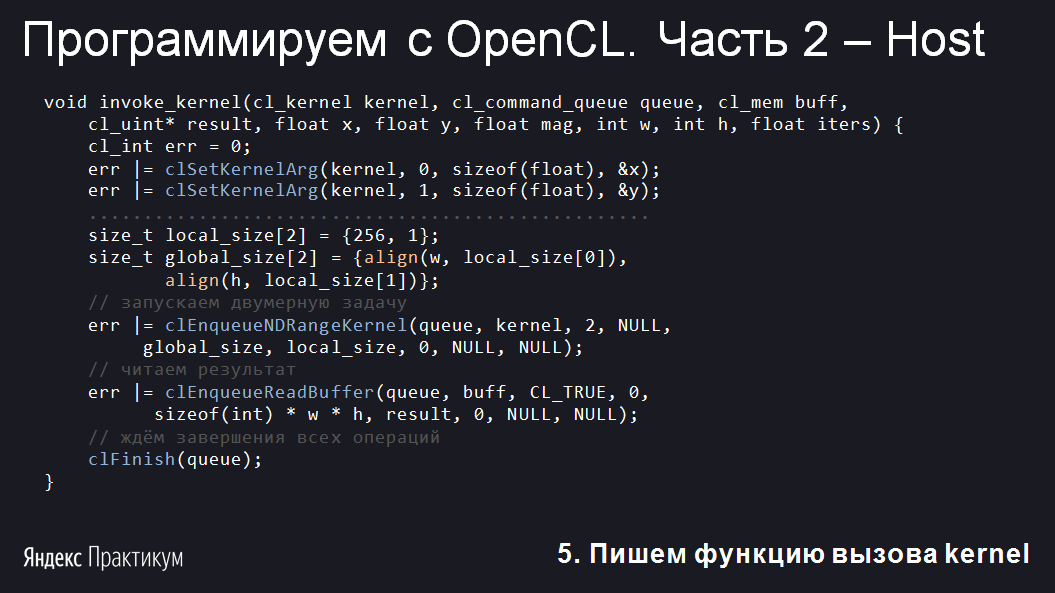
Вызовом clSetKernelArg задаются все аргументы, которые есть у kernel-функции draw_mandelbrot. Они сохраняются внутри объекта cl_kernel. Особо можно отметить, что clSetKernelArg — это единственная непотокобезопасная функция OpenCL. Все остальные вызовы можно делать из разных тредов вашей программы без каких-либо синхронизаций. Разумеется, если вы уверены в целостности своих данных.
Полный код задания аргументов:
Не хватает только функции

Чтобы глобальный размер был кратен размеру рабочей группы, воспользовались такой функцией
В конце мы ждём, пока в очереди выполнятся все команды, в том числе и чтение. За это отвечает
Подберём параметры и запустим функцию, читая результат в вектор:

Осталось совсем немного — сохранить результат. Для этого выберем самый простой формат изображений — PPM. Вот функция для сохранения в него:

И не забываем убирать за собой! В программировании нужно освобождать те ресурсы, которые вы уже использовали. А это ни много ни мало kernel-функция, буфер, очередь, вся программа и контекст.

Чтобы не забывать освобождать ресурсы, можно написать обёртку на C++. Или воспользоваться готовой
Итак, программа написана. Но сохраним интригу и прежде чем показать результат её работы, разберём сборку и запуск. Многие программисты на C++ сталкивались с проблемами сборки: то что-то не компилируется, то возникают конфликты, то странные ошибки. С OpenCL в этом плане не всё так плохо. Главная причина: библиотека OpenCL — динамическая. Так задумано её использование. Для обращения к ней нужен лишь несложный интерфейс, который умещается в нескольких файлах библиотеки clew. Clew — это маленькая библиотечка, позволяющая делать замечательные вещи. Она легко собирается, сама ищет динамическую библиотеку OpenCL и содержит все необходимые include-файлы.

Библиотека clew — не единственный поставщик cl.h. Альтернатива — тяжеловесный инструмент CUDA Toolkit или готовый пакет на системах с пакетным менеджером. При компоновке нужно добавить соответствующую библиотеку. Clew состоит всего лишь из одного компилируемого файла, и можно просто добавить его в проект.
Для запуска программы нужно, чтобы она увидела динамическую библиотеку OpenCL, а библиотека OpenCL должна увидеть видеокарту. На Windows для работы с видеокартой достаточно драйвера. Для других систем или для использования CPU, вероятно, придётся устанавливать специальные драйверы. Вот ссылка на драйвер для интеловских процессоров.
Как правило, самый универсальный способ установить всё и сразу — установить CUDA Toolkit. В него входит cl.h, динамическая библиотека OpenCL и драйвер карты Nvidia.
Ну что ж, программа готова, можно запускать!

Изображение множества Мандельброта, полученное написанной программой
Пример сделал красивую картинку, но показал не всё. В частности, мы не рассмотрели:
Я ещё немного модифицировал программу: добавил палитру, возможность поворота и сгенерировал видео, которое можно увидеть в заставке вебинара. При этом изменился только kernel-код. Он приведён на слайде.

Напоследок я приготовил схему, которая напомнит, как по шагам написать host-код для OpenCL. Думаю, начинающим она будет полезна.

В этой статье мы подробно разобрали написание простейшей программы для OpenCL. В следующей части рассмотрим алгоритмы на GPU и напишем более сложный kernel-код.
Полный код примера опубликован в репозитории на GitHub.
После перерыва продолжаем публикацию текстовой версии вебинара.
- 0. Зачем мы здесь собрались. Краткая история GPGPU
- 1a. Как работает OpenCL
- 1b. Пишем для OpenCL
- 2. Алгоритмы в условиях массового параллелизма
- 3. Сравнение технологий
В этой части мы наконец напишем на OpenCL полноценную программу, которая нарисует красивое изображение.
У программы для OpenCL есть две части: kernel-код и host-код — то, что выполняется на видеокарте, и то, что выполняется на компьютере. Кроме того, программу нужно скомпилировать и запустить. Всё это будет рассмотрено в сегодняшней статье. Начнём с самого интересного — напишем часть kernel.
В предыдущих сериях
Прежде чем начать, напомним основные термины из предыдущей части.
- Kernel-код — код, который выполняется на устройстве, поддерживающем OpenCL: видеокарте, процессоре или другом устройстве.
- Host-код — код, который выполняется на центральном процессоре и отдаёт команду на запуск kernel-кода.
- Work-item — один поток выполнения, отвечающий за одну элементарную подзадачу большой задачи. Все work-item'ы одной задачи исполняют один и тот же kernel-код.
- Warp, или wavefront — группа work-item'ов, выполняющая команды синхронно.
- Work group, или рабочая группа, — группа work-item'ов, имеющая общую локальную память и средства синхронизации между потоками.
- Локальный размер — размер рабочей группы, измеряемый в work-item'ах. А именно длина, высота (для двумерных и трёхмерных задач) и глубина (для трёхмерных задач).
- Глобальный размер — размер всей задачи, измеряемый в work-item'ах.
Kernel
Kernel-код для OpenCL пишется на C с ограничениями. В нём нельзя использовать:
- рекурсию,
- указатели на функции,
- массивы с переменным размером,
- стандартные заголовки (stdlib.h, …),
extern,static,auto,register.
Тип
double допустим, но не на всех устройствах: он считается расширением. Самое неприятное, но в то же время логичное — отсутствие указателей на функции. Иногда их удаётся заменить макросами.Хорошая новость: у OpenCL есть не только ограничения, но и дополнения. Например, очень крутые векторные типы. И честно вам скажу: когда я начал программировать на OpenCL, их стало очень не хватать в обычном программировании на CPU. С векторными типами можно сделать переменную, в которой будет храниться сразу 16 значений
float. 16 — это довольно много, чаще используют два или три значения — так представляют координаты точки. Конечно, вы скажете, что в C++ можно сделать себе какой угодно векторный тип и определить для него все операции. Но я отвечу: не все. Тернарную операцию перегрузить не получится. А в OpenCL она прекрасно работает:int a = ..., b = ..., c = ...; // Инициализируем векторную переменную: int3 coordinates = (int3)(a, b, c); if (all(coordinates > 0)) { // Все координаты положительны. } else if (any(coordinates > 0)) { // Хотя бы одна координата положительна. } // Вычитаем из каждой координаты 100 и сравниваем с нулём. // sign — это вектор, имеющий элементы 1 и -1. // Тут применяется векторная тернарная операция. int3 sign = (coordinates - 100) >= 0 ? 1 : -1; // Можно выбрать из трёх координат любой набор // и сохранить в отдельную переменную: int2 drop_y = coordinates.xz;
Но не будем отвлекаться и вернёмся к написанию kernel. Мы будем писать функцию, рисующую множество Мандельброта.
Пишем точку входа — kernel-функцию. Она всегда
void и будет вызвана для каждого work-item'аЗелёным выделено название kernel, синим — встроенные функции OpenCL, красным — функции, которые мы скоро напишем.
Это двумерная задача. И я хочу, чтобы один work-item рисовал какую-то точку множества Мандельброта. Каждый work-item выполняет код функции независимо от других, и ему прежде всего нужно понять, какую точку множества Мандельброта отрисовать. Чтобы это как-то кастомизировать, в аргументах задаём точку плоскости, которая находится в центре нашей картинки, и масштаб. Разберём аргументы подробнее:
float px,float py— координаты центра отрисовываемой области;float mag— коэффициент увеличения;float max_iters— точность прорисовки множества, которая показывает, сколько шагов нужно сделать для каждой точки;int w,int h— размеры рисуемого изображения;__global uint* result— память, куда нужно записать ответ;int result_step— смещение между строками ответа.
Эти параметры мы зададим в host-коде при вызове kernel. Из них наиболее неочевидны два последних:
result и result_step.Параметр
result имеет тип __global uint*, то есть это указатель на глобальную память. При написании host-кода её нужно заранее выделить. После работы kernel, который заполнит эту память, мы скопируем данные в RAM и обработаем их уже на стороне хоста. Тип uint, имеющий размер 4 байта, выбран для записи цвета одного пикселя. В нём 3 байта задают компоненты R, G и B, а один байт не используется.Последний параметр
result_step нужен для корректного заполнения памяти result. Если вы когда-либо программировали обработку изображений, то наверняка знаете, что это практически обязательный атрибут при передаче картинок. result_step ещё называют отступом. Он обычно примерно равен ширине и показывает, на сколько элементов нужно сдвинуться в памяти, чтобы перейти на следующую строчку изображения. Мы мыслим об изображении как о матрице, но в памяти это линия. Отступ нужен, чтобы сделать из линии прямоугольник.При ознакомлении со списком параметров у вас мог возникнуть вопрос: зачем передавать
w и h, если kernel знает глобальный размер? Ответ прост: глобальный размер иногда больше реального. Так делают, чтобы он был кратен размеру рабочей группы. Передача настоящего размера параметром позволяет избежать неправомерного доступа к памяти.w и h используются в условии основного if: если work-item оказался в добавочных пикселях справа или снизу, то он будет отдыхать. Конечно, из-за дивергенции он, скорее всего, будет имитировать те же действия, что и работающие work-item'ы, но на производительности это не скажется.При помощи функции
get_global_id work-item узнал, за какой пиксель он отвечает. Задача, которую мы решаем, настолько простая, что нас даже не интересует положение work-item внутри рабочей группы. Далее идёт получение координаты точки множества Мандельброта. Вот функция compute_iterations, которая вычисляет степень принадлежности к множеству Мандельброта, для выбора нужного цвета:Вычисляем количество итераций для каждой точки экрана
Как видите, ничего страшного и сложного тут нет — обычная функция на C. Для полноты картины не хватает лишь одной маленькой детали —
to_color_gray. Она преобразует количество итераций в число от 0 до 255 и помещает его во все три компоненты: R, G и B.Вычисляем цвет по количеству итераций
Вот такой нехитрый kernel у нас получился. Переходим к части host.
Host
Теперь kernel-код надо запустить на GPU. План такой:
- выбираем устройство, на котором будем запускать код;
- компилируем kernel под это устройство;
- создаём всё, что нужно для запуска, и вызываем kernel-код;
- сохраняем изображение, которое он построил, и смотрим, что получилось.
В конце обязательно прибираем за собой, освобождаем ресурсы.
Программа, использующая OpenCL, выглядит так:
Ошибки в этом примере обрабатывать не будем
Программа начинается с include-директивы. Внутри
main инициализируем OpenCL вызовом ocl_init. Жёстко зададим размер изображения, которое у нас получится: 1200 x 640 пикселей.Чтобы
main не разрастался, напишем отдельную функцию для выбора устройства.В этом примере не будем умничать и возьмём первое же устройство. Вначале попробуем найти GPU. Если не получилось — ищем CPU. Да, OpenCL может выполняться и на обычном процессоре, если установлен соответствующий драйвер. В реальной программе можно получить список всех устройств и предоставить возможность выбора пользователю. Проверять железо на поддержку не нужно, потому что библиотека OpenCL выдаёт только те девайсы, на которых она будет работать.
В этом примере синим цветом выделены функции из API OpenCL. Здесь также использованы три типа данных OpenCL:
cl_platform_id— задаёт платформу, то есть группу устройств;cl_device_id— задаёт устройство;cl_int— 32-битное знаковое число.
Когда девайс выбран, нужно создать контекст — объект, отвечающий за конкретную сессию взаимодействия с устройством. Ваша программа может создавать несколько контекстов, но они будут работать независимо. Память, выделенная в рамках одного контекста, не может использоваться в другом. Создадим контекст в функции
main:// main cl_device_id device = create_device(); // Функции clCreateContext из API OpenCL передаём список устройств. // В большинстве случаев — одно устройство. cl_context context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
Теперь всё готово к тому, чтобы переходить к запуску kernel-кода. Но для начала нужно его скомпилировать. Сделаем это такой функцией:
Скомпилированный код программы можно сохранить и переиспользовать
Функция сперва загружает исходный код, а затем выполняет компиляцию. Это простой пример, и в нём не затронуты следующие возможности, необходимые в реальной программе:
- передача параметров компилятору, например значений макросов;
- получение лога компиляции — ошибок и предупреждений;
- сохранение бинарного кода для последующего использования на том же компьютере;
- обработка ошибок.
Не хватает одной детали — загрузки OpenCL-кода. Для полноты картины приведём эту функцию, хотя в ней нет ничего специфичного:
Код можно прочитать из файла или встроить в программу как ресурс
Далее нужно создать объекты и ресурсы, необходимые для запуска. Мы взяли kernel-код, но не сказали, какая функция из него нам нужна. В нём может быть несколько точек входа, kernel-функций. А нам нужна та, которую мы назвали
draw_mandelbrot. Пишем её название как строковый литерал. Функция clCreateKernel получает нужную точку входа по имени функции. Проведём эту и другие манипуляции в main:Ещё одно важное понятие — очередь. Она нужна для взаимодействия программы и устройства. Вы даёте задачи для GPU, они поступают в очередь. Так как всё происходит асинхронно, видеокарта может быть уже занята задачей, которую ранее поставило ваше приложение либо другая программа, работающая на том же компьютере. Новая команда встанет в очередь и выполнится, когда устройство будет готово. В рамках одной очереди команды выполняются последовательно, но и это можно настроить параметрами функции
clCreateCommandQueue.Также понадобится буфер для записи результата. Мы получили его, выделив нужное количество видеопамяти функцией
clCreateBuffer. Параметр CL_MEM_WRITE_ONLY говорит о том, что kernel-код не будет читать из этой памяти. Это позволит применить дополнительные оптимизации.Теперь всё готово. Осталось только запустить kernel. Размер рабочей группы выберем стандартный: 256 в ширину и 1 в высоту. Глобальный размер задаётся параметрами
w и h. Но нужно позаботиться о том, чтобы он делился на локальный. Для этого воспользуемся функцией align, которую я приведу позже:Вызовом clSetKernelArg задаются все аргументы, которые есть у kernel-функции draw_mandelbrot. Они сохраняются внутри объекта cl_kernel. Особо можно отметить, что clSetKernelArg — это единственная непотокобезопасная функция OpenCL. Все остальные вызовы можно делать из разных тредов вашей программы без каких-либо синхронизаций. Разумеется, если вы уверены в целостности своих данных.
Полный код задания аргументов:
err |= clSetKernelArg(kernel, 0, sizeof(float), &x); err |= clSetKernelArg(kernel, 1, sizeof(float), &y); err |= clSetKernelArg(kernel, 2, sizeof(float), &mag); err |= clSetKernelArg(kernel, 3, sizeof(float), &iterations); err |= clSetKernelArg(kernel, 4, sizeof(cl_int), &w); err |= clSetKernelArg(kernel, 5, sizeof(cl_int), &h); err |= clSetKernelArg(kernel, 6, sizeof(cl_mem), &buff); err |= clSetKernelArg(kernel, 7, sizeof(cl_int), &w);
clEnqueueNDRangeKernel — функция, отдающая команду видеокарте на запуск kernel. Она поместит задачу в очередь. Kernel запишет результат в видеопамять, заданную буфером buff. В этот буфер будет записано изображение множества Мандельброта. Затем мы запросим чтение результата в обычную оперативную память. За трансфер из GRAM в RAM отвечает функция clEnqueueReadBuffer.Не хватает только функции
align:Чтобы глобальный размер был кратен размеру рабочей группы, воспользовались такой функцией
В конце мы ждём, пока в очереди выполнятся все команды, в том числе и чтение. За это отвечает
clFinish. Вопреки названию, она не завершает очередь, а ждёт завершения всех задач, которые в неё поставлены.Подберём параметры и запустим функцию, читая результат в вектор:
Осталось совсем немного — сохранить результат. Для этого выберем самый простой формат изображений — PPM. Вот функция для сохранения в него:
И не забываем убирать за собой! В программировании нужно освобождать те ресурсы, которые вы уже использовали. А это ни много ни мало kernel-функция, буфер, очередь, вся программа и контекст.
Чтобы не забывать освобождать ресурсы, можно написать обёртку на C++. Или воспользоваться готовой
Сборка и запуск
Итак, программа написана. Но сохраним интригу и прежде чем показать результат её работы, разберём сборку и запуск. Многие программисты на C++ сталкивались с проблемами сборки: то что-то не компилируется, то возникают конфликты, то странные ошибки. С OpenCL в этом плане не всё так плохо. Главная причина: библиотека OpenCL — динамическая. Так задумано её использование. Для обращения к ней нужен лишь несложный интерфейс, который умещается в нескольких файлах библиотеки clew. Clew — это маленькая библиотечка, позволяющая делать замечательные вещи. Она легко собирается, сама ищет динамическую библиотеку OpenCL и содержит все необходимые include-файлы.
Библиотека clew — не единственный поставщик cl.h. Альтернатива — тяжеловесный инструмент CUDA Toolkit или готовый пакет на системах с пакетным менеджером. При компоновке нужно добавить соответствующую библиотеку. Clew состоит всего лишь из одного компилируемого файла, и можно просто добавить его в проект.
Для запуска программы нужно, чтобы она увидела динамическую библиотеку OpenCL, а библиотека OpenCL должна увидеть видеокарту. На Windows для работы с видеокартой достаточно драйвера. Для других систем или для использования CPU, вероятно, придётся устанавливать специальные драйверы. Вот ссылка на драйвер для интеловских процессоров.
Как правило, самый универсальный способ установить всё и сразу — установить CUDA Toolkit. В него входит cl.h, динамическая библиотека OpenCL и драйвер карты Nvidia.
Ну что ж, программа готова, можно запускать!
Изображение множества Мандельброта, полученное написанной программой
Итоги
Пример сделал красивую картинку, но показал не всё. В частности, мы не рассмотрели:
- как передавать массивы в kernel;
- как и для чего использовать локальную память;
- как синхронизировать work-item'ы между собой;
- как пользоваться векторными типами, например
int4,float8; - для чего нужны события;
- как пользоваться текстурами.
Я ещё немного модифицировал программу: добавил палитру, возможность поворота и сгенерировал видео, которое можно увидеть в заставке вебинара. При этом изменился только kernel-код. Он приведён на слайде.
Напоследок я приготовил схему, которая напомнит, как по шагам написать host-код для OpenCL. Думаю, начинающим она будет полезна.
В этой статье мы подробно разобрали написание простейшей программы для OpenCL. В следующей части рассмотрим алгоритмы на GPU и напишем более сложный kernel-код.
Полный код примера опубликован в репозитории на GitHub.
