
Эта статья посвящена основным современным моделям для генерирующего реферирования и генерации текста в целом: BertSumAbs, GPT, BART, T5 и PEGASUS, и их использованию для русского языка.
В отличие от извлекающих моделей, которые рассмотрены в предыдущих двух статьях, эти модели создают новые тексты, а не только выделяют предложения из оригинального документа. Из-за этого они могут нетривиально изменять исходный текст: удалять слова или заменять их на синонимы, сливать и упрощать предложения, а значит делать ровно то, что делают люди при составлении рефератов.
Ещё десять лет назад методы из этой категории казались фантастикой. Развитие систем нейросетевого машинного перевода сделало генерирующее автоматическое реферирование намного более лёгкой задачей.
Серьёзные методы оценки качества реферирования будут в следующих частях цикла. Сейчас же для наглядности мы испытаем алгоритмы на одной конкретной новости про секвенирование РНК клеток коры головного мозга. Это свежая новость, то есть модели заведомо не могли её видеть. К тому же она довольно сложная: 5.7 баллов по шкале N+1.
Кстати говоря, заголовок к этой статье написан одной из описываемых моделей.
- Что нужно знать о современных моделях реферирования и генерации текста
- Что нужно знать об генерирующем реферировании текстов для русского языка
- Основные современные модели для генерирующего реферирования и генерации текста
- Основные модели генерации текста для русского языка: BertSumAbs, GPT, BART, T5 и PEGASUS
- Реферирование и генерация текста: основные современные модели
- Генерирующие модели для автоматического реферирования текстов
- Как автоматическое реферирование текстов может быть проще
- Как автоматически реферировать тексты для русского языка
- Как автоматизировать генерацию текста на русском языке
- Обзор основных современных моделей для автоматического реферирования текстов
- Автоматическое реферирование текстов: какие модели эффективны для русского языка
- Разработаны самые точные и надежные модели реферирования для русского языка
1) Постановка задачи автоматического реферирования и методы без учителя
2) Извлекающие методы автоматического реферирования
3) Секреты генерирующего реферирования текстов ⬅️
Seq2seq
Sequence-to-sequence — семейство подходов для перевода одной последовательности в другую. В случае задачи реферирования в качестве входа служит набор токенов исходного документа, а в качестве выхода — набор токенов реферата. Входную последовательность обрабатывает кодировщик, а выходную генерирует декодировщик.
На каждом своём шаге декодировщик предсказывает распределение вероятностей для следующего генерируемого слова,  . При обучении мы считаем функцию потерь как кросс-энтропию между предсказанным распределением вероятностей и унитарным кодом настоящего токена.
. При обучении мы считаем функцию потерь как кросс-энтропию между предсказанным распределением вероятностей и унитарным кодом настоящего токена.
Первые версии sequence-to-sequence моделей использовали кодировщики и декодировщики из рекуррентных сетей. При этом начальным скрытым состоянием декодировщика было последнее скрытое состояние кодировщика. Подобная модель для задачи машинного перевода схематично изображена ниже.

Механизм внимания
Проблема такой архитектуры — "узкое горлышко" в виде контекста из кодировщика  , который фиксирован для всех шагов декодировщика. На разных шагах декодировщика мы хотели бы менять учитываемый контекст. Именно с этой целью и был создан механизм внимания. Его идея в том, чтобы на разных шагах декодировщика по-разному взвешивать выходы кодировщика. При этом веса для этих выходов считаются на основе предыдущего выхода декодировщика и всех выходов кодировщика.
, который фиксирован для всех шагов декодировщика. На разных шагах декодировщика мы хотели бы менять учитываемый контекст. Именно с этой целью и был создан механизм внимания. Его идея в том, чтобы на разных шагах декодировщика по-разному взвешивать выходы кодировщика. При этом веса для этих выходов считаются на основе предыдущего выхода декодировщика и всех выходов кодировщика.
Вариант механизма внимания представлен на рисунке ниже. Есть и вариант, в котором мы считаем веса внимания на основе текущего, а не предыдущего выхода декодировщика, и подаём итоговый вектор контекста сразу в предсказатель распределения токенов.
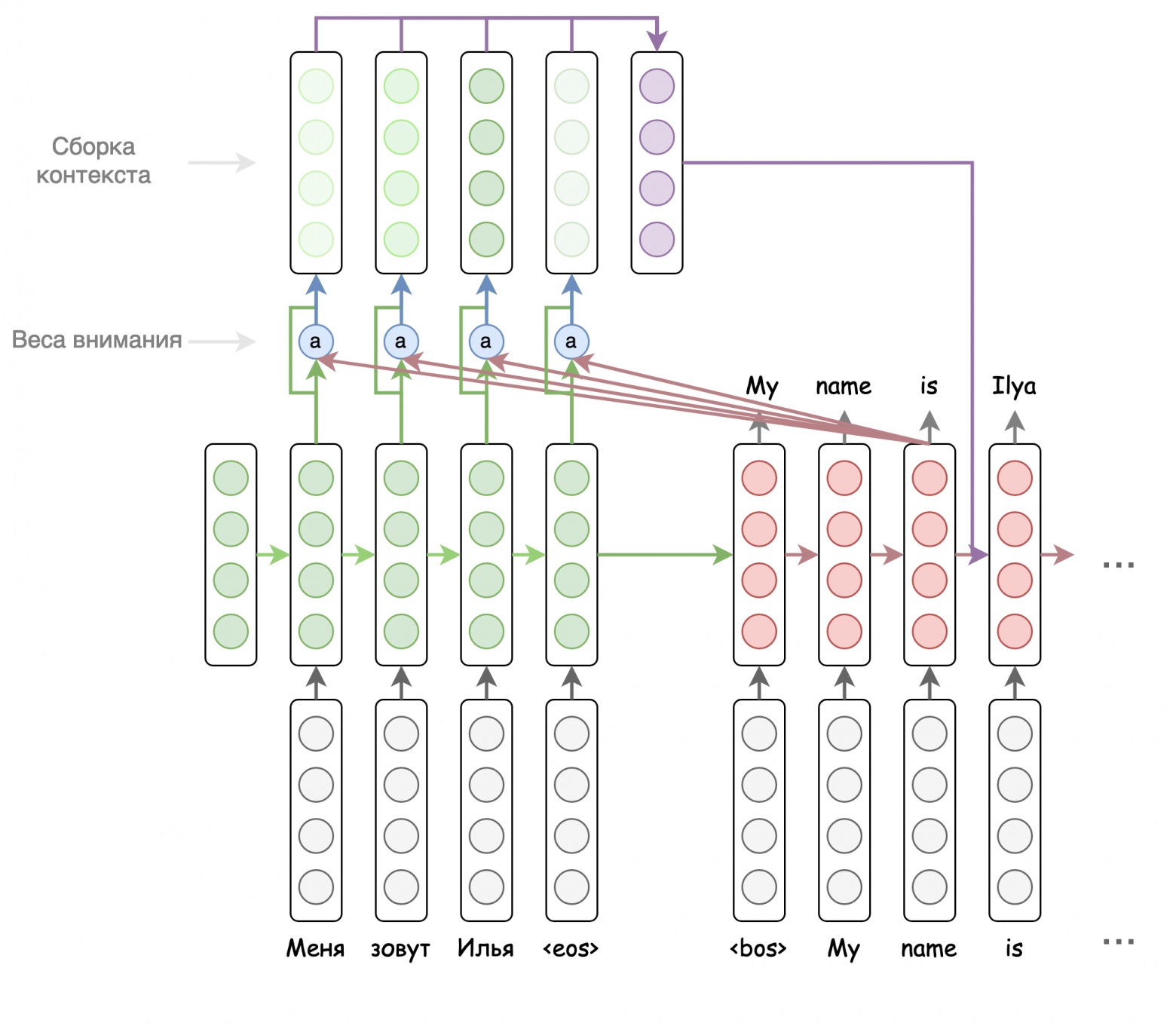
Pointer-Generator Network
В дотрансформерную эпоху было несколько модификаций рекуррентных seq2seq моделей для автоматического реферирования. Самая интересная из них — Pointer-Generator Network, указательно-генеративная сеть.
Основная её идея заключается в том, чтобы наравне с генерацией новых токенов позволить модели копировать токены из исходной последовательности. Выбор между генерацией и копированием делается через шлюз  , который вычисляется по формуле ниже.
, который вычисляется по формуле ниже.

При формировании итогового предсказания словарь искусственно расширяется на количество неизвестных слов во входной последовательности. Вероятности копируемых токенов берутся из весов внимания по этим токенам. Вероятности токенов из словаря домножаются на , а токенов из исходной последовательности — на  . Схематично это представлено на рисунке ниже.
. Схематично это представлено на рисунке ниже.

Кроме того, в этой модели использовался механизм покрывающего внимания, но я не буду на нём останавливаться.
Мне когда-то довелось написать собственную PGN в рамках фреймворка AllenNLP. Её реферат нашей новости представлен ниже. Модель пыталась скопировать первые два предложения исходного текста, но не совсем удачно.
Биологи из Великобритании получили полный транскриптом клеток коры головного мозга. С помощью секвенирования третьего поколениями специалистам удалось обнаружить нейродегенеративных и психиатрических заболеваний.
BertSumAbs
Помните BertSumExt из предыдущей статьи? Так вот BertSumAbs — это то же самое, но модель не выделяет предложения исходного текста, а генерирует новые в sequence-to-sequence варианте. Такой вариант Трансформера представлен на рисунке ниже.
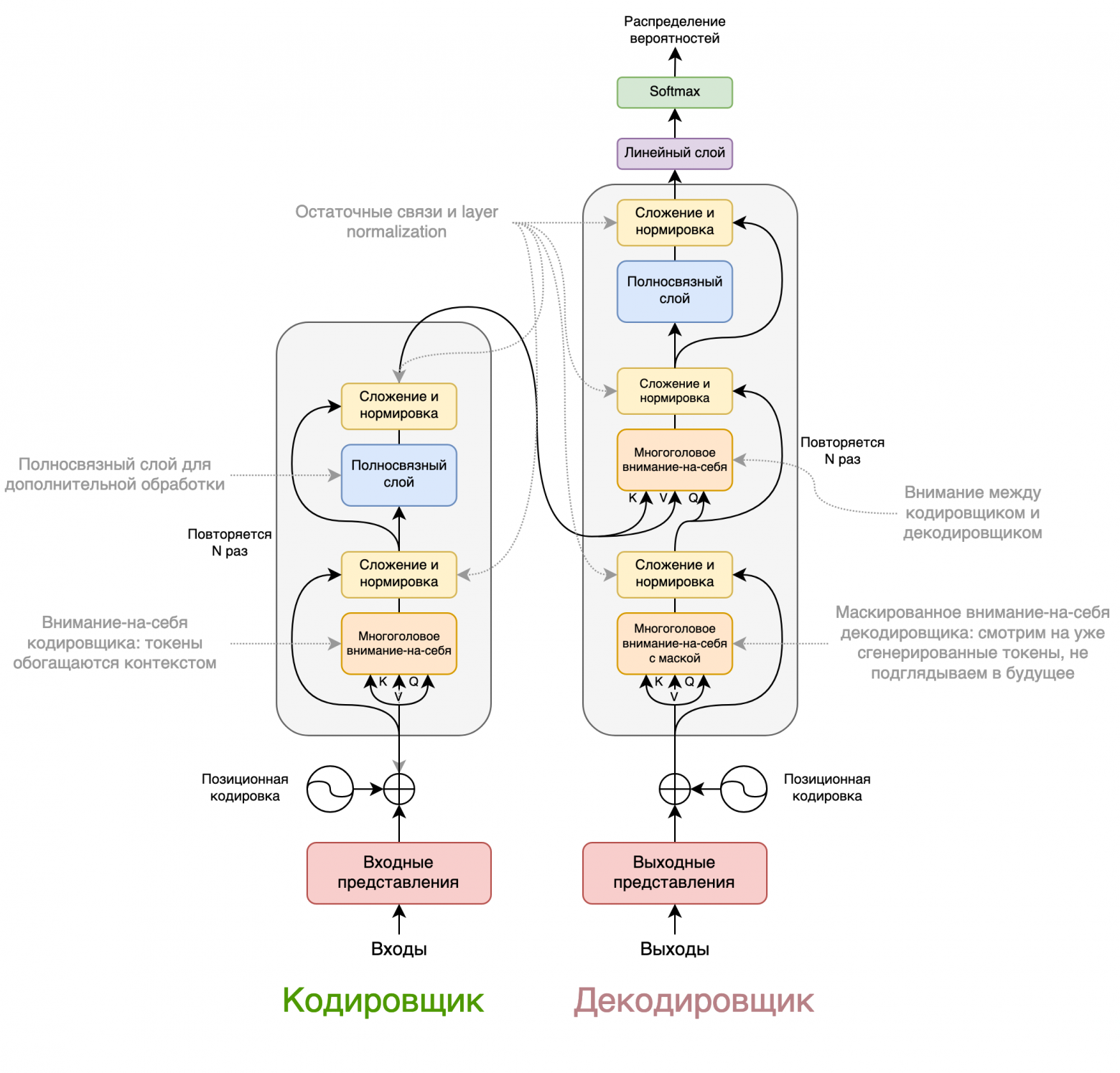
Кодировщик у этой модели тот же, что и у BertSumExt, а в качестве декодировщика используется случайно инициализированный Трансформер из 6 слоёв. При этом приходится учить кодировщик и декодировщик с разными оптимизаторами из-за того, что у них разное количество слоёв и разная инициализация.
Кроме того, авторы предлагают гибридную схему BertSumExtAbs: сначала учим кодировщик на BertSumExt, а потом используем его в BertSumAbs. Это возможно благодаря тому, что кодировщики в этих двух моделях имеют полностью идентичную структуру.
GPT
GPT — семейство моделей (GPT, GPT-2, GPT-3), которые основаны на предобучении Трансформера-декодировщика на задачу языкового моделирования. Эта задача заключается в предсказании следующего токена по предыдущим, то есть в предсказании текста слева направо.
Для задачи автоматического реферирования мы конкатенируем текст и эталонный реферат для каждого обучающего примера через специальный разделитель. Модель учится при встрече с этим разделителем писать реферат всего текста до него.
В статье про GPT-2 таким разделителем являлся текст "TL;DR:", а модель специально не доучивалась ни на каких примерах. В таком варианте модель показывает очень плохие результаты на уровне базового решения с выбором 3 случайных предложений.
Для русского языка существует адаптация GPT-3 от Сбера. На основе этой адаптации я обучил модель для реферирования: rugpt3medium_sum_gazeta. Это не первая такая модель. Работает она сносно, но гораздо хуже полноценных sequence-to-sequence моделей, которые рассмотрим далее.
Реферат нашего примера представлен ниже. Это отличный реферат, в котором выделено всё самое главное. Не совсем корректная терминология, но зато понятно простому человеку. К сожалению, с этой моделью не всегда получается так хорошо.
Британские биологи получили полный генетический транскриптом мозга, в котором содержатся РНК, ассоциированные с шизофренией и другими психическими заболеваниями.
BART
BART — sequence-to-sequence Трансформер, который предобучается реконструкции испорченного зашумлённого текста. Разработка Facebook AI Research. На входе у модели каким-то образом испорченный текст, а на выходе ей надо сгенерировать его оригинальную версию.
BERT использует только кодировщик, GPT использует только декодировщик, а вот BART — полноценная sequence-to-sequence модель. Схематично это изображено на рисунке ниже.
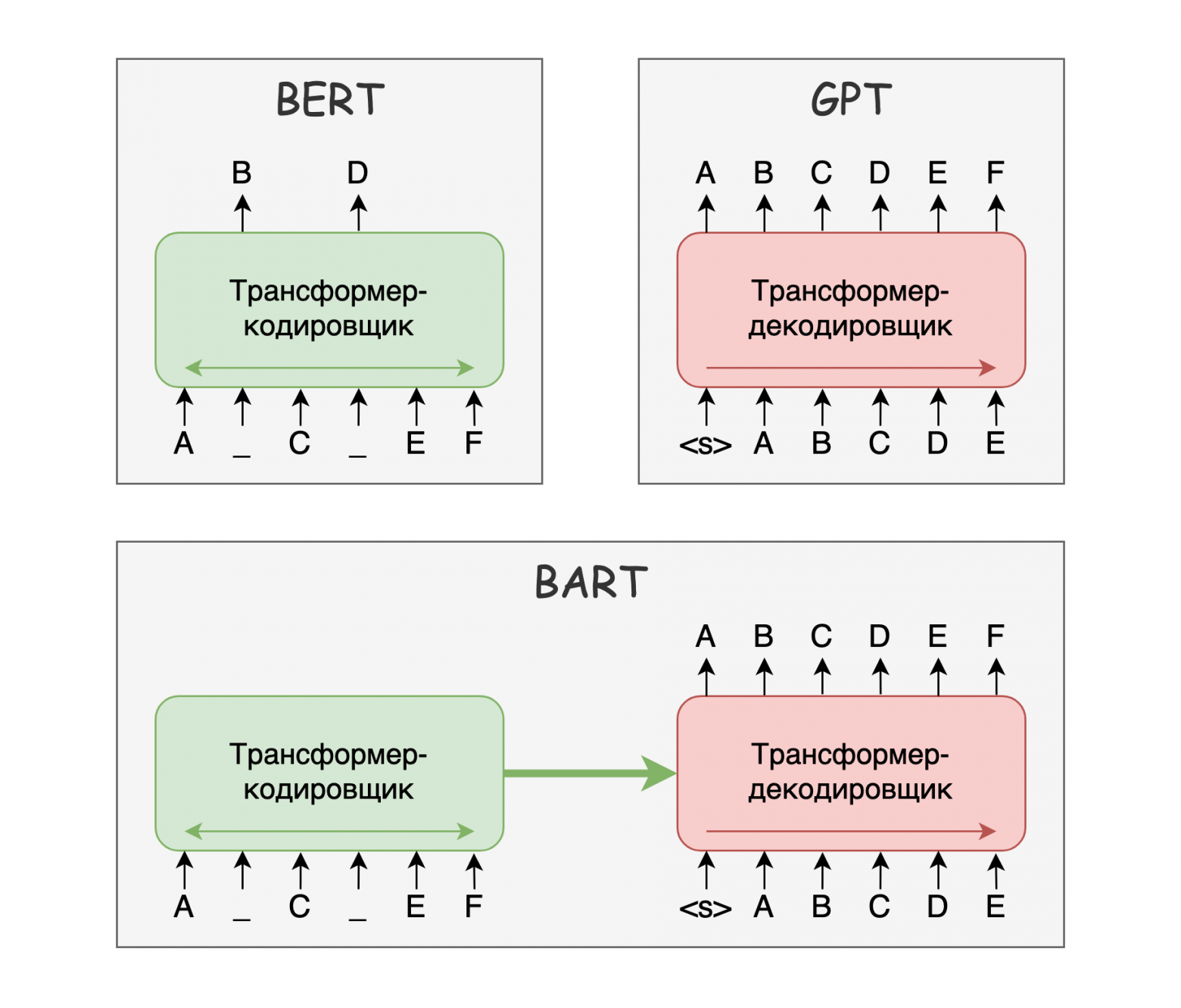
Как зашумляется текст:
- Маскировка токенов (аналогично BERT)
- Удаление токенов
- Маскировка нескольких подряд идущих токенов одной маской
- Перемешивание предложений
- "Вращение" документа относительно случайного токена. То есть мы делаем этот токен началом документа, а всё, что было до него — переносим в конец.
BART предобучался на том же корпусе, что и RoBERTa, то есть на составном корпусе из 4 частей: книг, новостей, документов по ссылкам из постов Reddit, кусочка Common Crawl.
Важно, что в отличие от BERT, эта модель сразу предобучается на генерации текста, и поэтому лучше подходит для автоматического реферирования. Наличие в задачах предобучения перемешиваний предложений и "вращений" документов также помогает при дальнейшем дообучении.
Кроме английской версии BART, была обучена ещё и многоязычная версия этой модели, mBART. Она обучалась на многоязычном корпусе CC25, подмножестве Common Crawl из 25 языков. При предобучении использовались одноязычные части корпуса, то есть никаких переводов модель не видела.
Русский язык там второй по степени представленности после английского. Это позволяет использовать эту модель и для русского языка тоже. Вот моя модель на основе mBART для автоматического реферирования на русском языке: mbart_ru_sum_gazeta. Модель довольно хороша, и с реферированием новостей может справляться не хуже некоторых людей, что подтверждается в этой статье.
Её реферат нашего примера представлен ниже. Модель отлично отработала и выделила самое главное. Единственная проблема — "уже упомянутые" болезни, которые в реферате до этого упомянуты не были.
В клетках коры головного мозга обнаружены изоформы генов, связанных с развитием нейродегенеративных и психиатрических заболеваний, выяснили британские биологи. Они надеются, что это поможет установить причины таких заболеваний как уже упомянутые болезнь Альцгеймера и шизофрения.
T5
T5 — ещё один sequence-to-sequence Трансформер, глобально аналогичный BART, разработка Google Research.
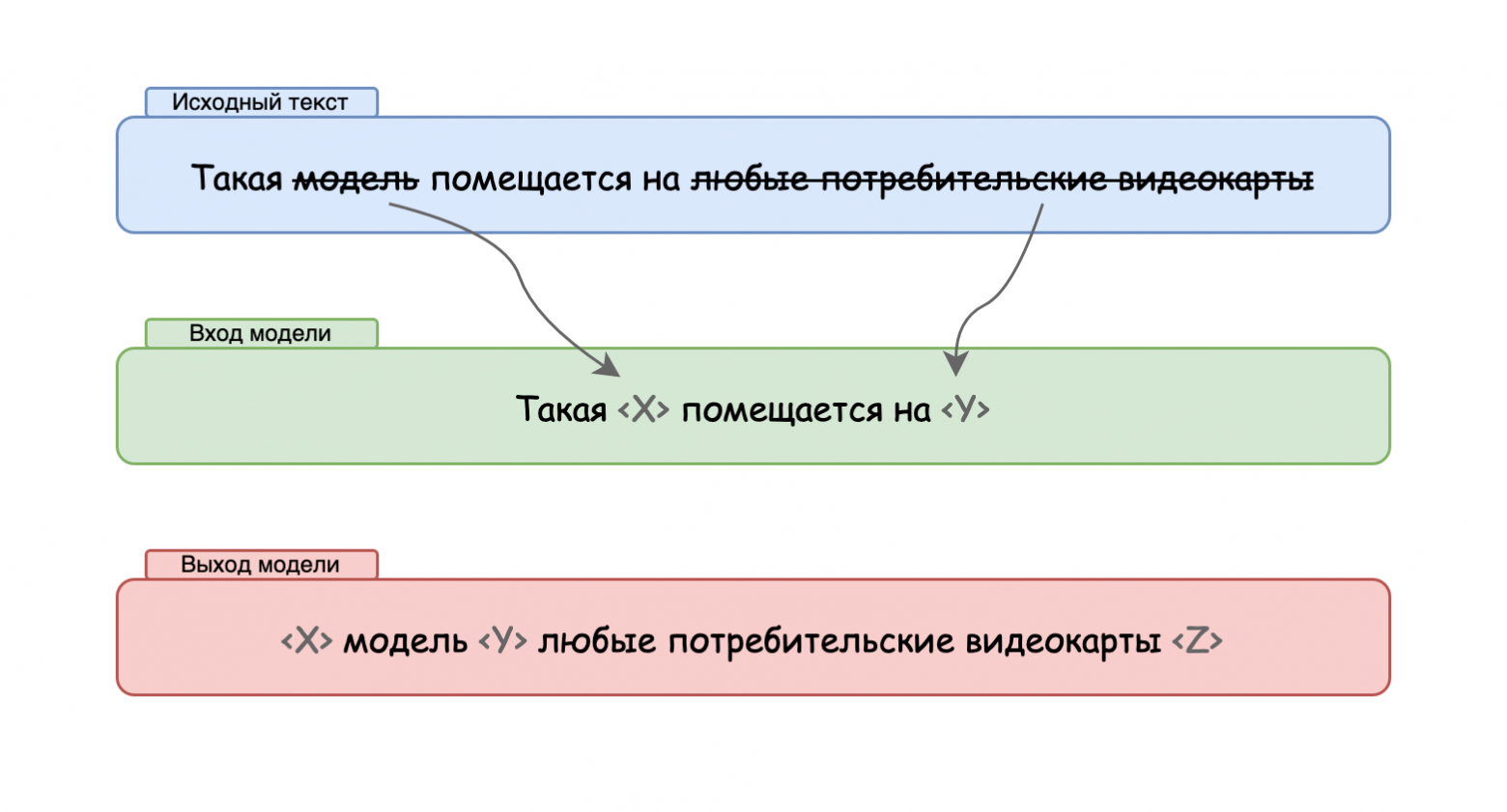
T5 предобучается на задаче восстановления промежутков, то есть наборов подряд идущих токенов. При обучении промежутки исходного текста скрываются, и задача модели их сгенерировать. В отличие от BART, где текст генерируется целиком, T5 нужно сгенерировать только сами скрытые промежутки. Схематично это изображено на рисунке ниже.
Есть и некоторые небольшие архитектурные различия, а именно:
- LayerNorm перед сложением. В классическом Трансформере используется LayerNorm, который применяется после сложения с остаточными связями с предыдущего слоя. В T5 LayerNorm применяется до сложения.
- Упрощённый LayerNorm. В самом блоке LayerNorm используется масштабирование (scale), но не используется смещение (bias).
- Относительные позиционнные эмбеддинги. В классическом Трансформере позиционные эмбеддинги фиксированы и складываются со входами модели. В T5 позиционные эмбеддинги встроены непосредственно в механизм внимания и зависят только от относительного расстояния между входами, аналогично этой работе.
Модель предобучается на наборе данных, который представляет из себя очищенный Common Crawl с документами только на английском языке. Называется он C4 — Colossal Clean Crawled Corpus.
mBART vs mT5 — это Facebook vs Google. Какая из моделей лучше? С точки зрения общих соображений, mBART должен быть лучше, потому что его задачи предобучения больше подходят под реферирование. С другой стороны, у mT5 получше архитектура. Как всегда, для своих задач стоит попробовать оба варианта.
Аналогично mBART, кроме английской версии T5, была обучена ещё и многоязычная версия этой модели, mT5. Она обучена на подмножестве Common Crawl для 101 языка, mC4.
После этого модель была обрезана под русский язык Давидом Дале(cointegrated) и выложена в открытый доступ в таком виде как ruT5. Такая модель помещается на многие потребительские видеокарты, в том числе стало возможно её дообучение без особых сложностей под задачу автоматического реферирования текстов на русском языке.
Ровно это я и сделал: rut5_base_sum_gazeta. Это же сделал и сам Давид, но на составном корпусе из 4 источников: rut5-base-absum.
Реферат моей модели ниже. Первое предложение — незначительная перефраза одного из предложений текста. Может показаться, что второе предложение противоречит тексту, но это не так.
С помощью секвенирования третьего поколения ученые обнаружили изоформы РНК генов, связанных с развитием нейродегенеративных и психиатрических заболеваний. Это позволит установить различия в профилях РНК у больных и здоровых людей, таких как болезнь Альцгеймера и шизофрения.
PEGASUS
PEGASUS — модель со специально подобранной под автоматическое реферирование задачей предобучения. С точки зрения архитектуры это обычный sequence-to-sequence Трансформер, как и предыдущие две модели. Но вместо восстановления случайных кусков текста предлагается использовать задачу генерации пропущенных предложений. Она заключается в том, что мы выбираем самые важные предложения из документа, заменяем их на токен-маску, формируем из них квазиреферат, и пытаемся этот квазиреферат сгенерировать. Эту задачу можно решать одновременно в паре с маскированным языковым моделированием.
Авторы предлагают 3 основных стратегии выбирать важные предложения: случайно; брать первые несколько предложений; брать несколько предложения по некой мере важности. В качестве меры важности можно брать похожесть предложений на оставшийся текст по ROUGE или даже жадно набирать квазиреферат аналогично методу "оракула" из предыдущей статьи.
PEGASUS выигрывает у BART и T5 на всех основных наборах данных, особенно при использовании другого корпуса для предобучения, HugeNews, который составляли сами авторы, и который состоит из 1.5 миллиардов новостных документов.
К сожалению, никаких адаптаций этой модели для русского языка нет и пока не предвидится.
Стратегии декодирования
С генерацией слева направо связана одна фундаментальная проблема, а именно проблема поиска оптимального пути в пространстве состояний. Эта проблема касается всех вышеописанных моделей. Она описывается формулой ниже, где  — все возможные генерируемые последовательности,
— все возможные генерируемые последовательности,  — исходная последовательность,
— исходная последовательность,  — последовательность с максимальной вероятностью.
— последовательность с максимальной вероятностью.

На каждом шаге декодировщика выдаётся распределение вероятностей для следующего токена. Самая простая стратегия — наивная жадная, то есть такая, в которой мы на каждом шаге мы выбираем максимально вероятный токен. Такая стратегия выбирает локально-оптимальный путь, а значит общая вероятность выбранной последовательности не обязательно минимальна.
Для этой задачи без дополнительных ограничений глобально-оптимальный путь можно найти перебором. Однако, на практике его невозможно использовать: его сложность  , где
, где  — количество токенов на выходе, а
— количество токенов на выходе, а  — размер словаря.
— размер словаря.
Поэтому приходится использовать эвристики, которые выдают результат хуже перебора, но лучше наивного жадного алгоритма. Главная эвристика называется лучевым поиском. Её суть в том, что мы берём топ-N вероятных состояний на каждом шаге и высчитываем продолжения только для них. При  это в точности наивный жадный алгоритм, а при
это в точности наивный жадный алгоритм, а при  — перебор. На рисунке ниже изображён лучевой поиск с
— перебор. На рисунке ниже изображён лучевой поиск с  . На каждом шаге, кроме первого, генерируется
. На каждом шаге, кроме первого, генерируется  вариантов, из которых отбирается
вариантов, из которых отбирается  лучших. Отбор можно делать за линейное время без сортировки. Сложность всего алгоритма:
лучших. Отбор можно делать за линейное время без сортировки. Сложность всего алгоритма:  .
.
Пример использования лучевого поиска с  в transformers:
в transformers:
output_ids = model.generate( input_ids=input_ids, num_beams=5 )
Кроме детерминированных алгоритмов поиска, также возможны различные методы семплирования, в которых мы выбираем случайное продолжение либо из лучших K токенов по вероятности, либо из набора токенов, покрывающего P% вероятности.
Пример использования семплирования с  в transformers:
в transformers:
output_ids = model.generate( input_ids=input_ids, do_sample=True, top_k=50 )
Возможно ещё и изменение температуры генерации в softmax-функции. Температура — это  в формуле ниже. Чем выше температура, тем сглаженнее распределение. При
в формуле ниже. Чем выше температура, тем сглаженнее распределение. При  , распределение превращается в равномерное. При
, распределение превращается в равномерное. При  распределение превращается в вырожденное: топ-1 токен имеет вероятность 1, а остальные — 0. С точки зрения людей, чем выше температура, тем "новее" выглядит текст.
распределение превращается в вырожденное: топ-1 токен имеет вероятность 1, а остальные — 0. С точки зрения людей, чем выше температура, тем "новее" выглядит текст.

Пример использования температуры  в transformers:
в transformers:
output_ids = model.generate( input_ids=input_ids, temperature=0.5 )
Заключение
После выхода BERT в 2018 году, все последующие значимые модели для обработки естественного языка используют Трансформеры в том или ином виде. BERT, BART, T5, GPT, PEGASUS — все основаны на Трансформерах. Ещё две недели назад я бы написал "они точно с нами надолго", но после прорыва на LRA я уже не так в этом уверен.
PEGASUS является прекрасным примером успешного подбора и использования специализированной задачи предобучения под автоматическое реферирование. Кажется, что если улучшить механизм отбора маскируемых предложений, можно получить результаты ещё лучше. Жалко только, что для русского таких моделей пока нет.
Вы можете сравнить некоторые из моделей для русского языка на своих задачах:
- mBART, реферирование, Gazeta: mbart_ru_sum_gazeta
- ruT5-base, реферирование, Gazeta: rut5_base_sum_gazeta
- ruT5-base, генерация заголовков, Telegram contest: rut5_base_headline_gen_telegram
- ruT5-base, реферирование, составной корпус: rut5-base-absum
- ruGPT3-medium, реферирование, Gazeta: rugpt3medium_sum_gazeta
- mT5-base, реферирование, XLSum: mT5_multilingual_XLSum
Что осталось за кадром? Другой древний механизм копирования, CopyNet. Модель на основе N-граммных предсказаний, ProphetNet. Трансформеры для длинных текстов, такие как LED или BigBird. Основанная на них модель для сводного реферирования, PRIMER.
В следующих статьях будет обзор на метрики и обзор на доступные наборы данных. Надеюсь, какие-то из моделей выше пригодятся. Удачи!

