
Хабр Курсы для всех
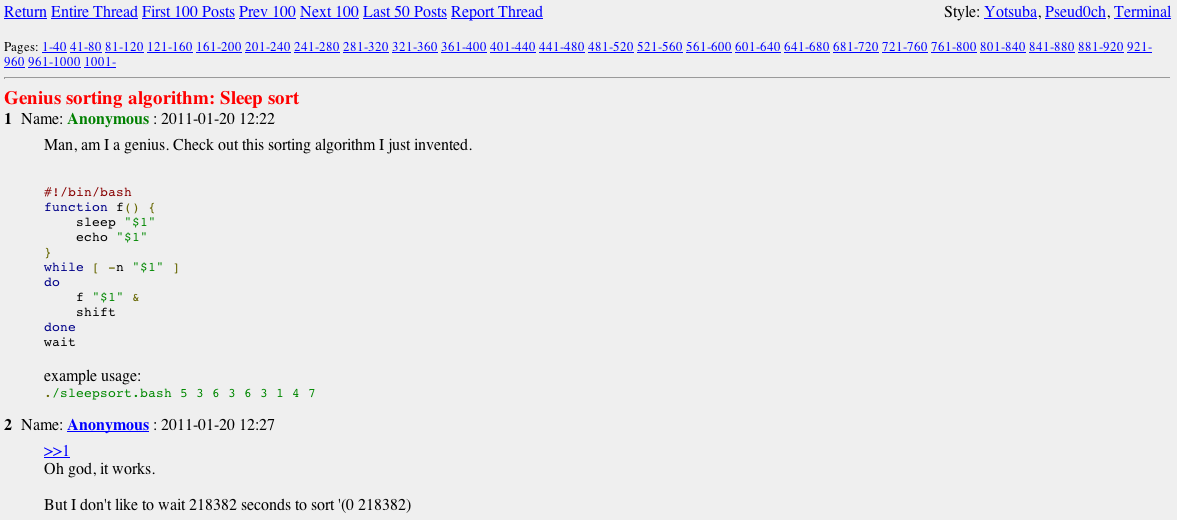
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Спасибо за перевод, но насчёт "крутости" алгоритма - представленные данные не слишком убедительны...
БОльшая часть графиков - про сортировку рандомных данных, но ведь это и так общеизвестный факт, что существуют алгоритмы, которые отлично справляются именно с рандомными входными наборами. Например (первый же результат в гугле) - статья 2013 г. "Unisort: an Algorithm to Sort Uniformly Distributed Numbers in O(n) Time". Сравнения с этим и подобными специализированными алгоритмами нет.
В остатке - честный график, что на нерандомных входах предложенный "ska sort" проигрывает std::sort; в некоторых диапазонах - проигрывает с треском. А также нестадартный интерфейс ("ska sort" нельзя подключить как drop-in replacement, потому что она не умеет работать с компараторами) и отсутствие поддержки некоторых видов элементов.
Неубедительно...
Вывод из статьи: "Ska Sort - с-ка сложный алгоритм" :)
Линк на оригинал говорит что это за 2016 год статья. Надо бы указать в примечании.
В boost в 2015-м году появилась boost.sort с аналогичной техникой (а написана первая версия библиотеки была в 2014). Алгоритм spreadsort сводит к поразрядной inplace сортировке в зависимости от типов данных. А после 2015-го туда добавлено множество новых алгоритмов сортировки.
Так что очень странно, что автор в 2016-м не проводил сравнение с boost::spreadsort хотя бы. Без такого сравнения статья не может считаться полной.
Ну и заявления, что проблема сортировки "решена", конечно, от незнания того, как развиваются хотя бы SIMD-возможности вычислительных устройств. Если смотреть за boost (а для большей ответственностью ещё и за библиотеками, которые там подаются на ревью), то видно, что это не так. А впереди ещё квантовые вычислители.
Автор решил задачу по-своему, и достойно, имхо.
Не думаю, что он не знаком с SIMD и GPU.
Разумеется, можно и GPU большой набор отсортировать, ни один CPU не справится быстрее.
И, думаю свой алгоритм он, скорее всего стал писать ещё до 2015)
Такие вещи за месяц не пишутся (спорьте, сколько хотите).
Ну я сравнил radix_sort (правда не автора а какой-то рандомный с гитхаба) со spreadsort-ом, radix_sort тащит на большом числе элементов:
Верно, 2016 год, я её прочёл примерно год назад, нашёл новое для себя. Достаточно современная, на мой взгляд. Добавил во введении от переводчика.
Вы не могли бы изобрести этот алгоритм на старых компьютерах, потому что на старых компьютерах он был бы медленнее.И тут оказывается, что никакого математического чуда нет, и автор просто пользуется очень умным компилятором и/или очень умным процессором. И что если использовать этот алгоритм, то на одном компьютере может быть всё замечательно, а на соседнем — всё очень и очень плохо. А потом и вовсе понадобится собрать пот ARM или RISCV или ещё что-то более интересное — и всё, придётся обратно переписывать на использование более «медленного» std::sort…
Раз статья переведена два раза, то и я свой комментарий, сделанный под вторым переводом, скопирую (https://habr.com/ru/company/wunderfund/blog/597113/#comment_23855461):
Поразрядная сортировка - очень хорошая вещь, и я, когда познакомился с этим алгоритмом будучи студентом, тоже был им восхищён. Однако сложность алгоритма не чистая O(n), а O(nw), где n - число сортируемых ключей, а w - длина сортируемых ключей.
Длина же сортируемых ключей зависит от количества ключей - чем больше уникальных ключей, тем больше битов нужно для хранения ключа. И зависимость эта логарифмическая. Т.е. w ~ log n, и в принципе вылезает примерно то же самое O(n log n).
На практике особенности ключей сортировки во многих случаях позволяют, впрочем, этому алгоритму быть лучше других распространённых алгоритмов сортировки. Просто надо помнить, что сложность его вовсе не чистая O(n).
Спасибо, рад, что тема показалась кому-то ещё интересной настолько, что тоже стали повторно переводить именно ту часть публикаций Скарупке, которая уже переведена тут, ведь есть ещё как минимум непереведенная часть про взгляд автора на классическую radix сортировку, которая упоминается в статье.
Кстати, видимая линейность роста времени от размера сортируемого впечатлила и самого автора ska_sort, о чём он и отмечает отдельно.
Только логарифм по какому основанию? В qsort там всегда на две части делят, а вот в радиксе можно брать больше корзин и получается зависимость ближе к линейной.
Основание не имеет значение для сложности, так как любое основание можно привести к другому, домножив на константу. log_c(x) = log_n(x)/log_n(c)
Вот только на практике разница в основании или константе может давать например x10 буст к скорости.
вы явно не понимаете что такое O-нотация.
оценивается не насколько алгоритм быстр, а как затрачиваемое время изменяется при изменении n
вы явно не понимате что такое "практика"
оценивается не как затрачиваемое время изменяется при изменении n, а насколько алгоритм быстр
При чем тут практика? - тред про сложность! Вы переключаете тему и предьявляете, что никто ничего не понимает. Все прекрасно понимают, чем отличается сложность и быстрость, вы кого за дураков держите?
Тред про то, что один человек написал O(log(n)), а второй не понял, по какому основанию, я пояснил, что оно не имеет значение в данной записи
Вы напрасно разделяете О-нотацию и практику. Сложность алгоритмов - это очень практическая штука. Ведь практика - это не только "тяп, ляп - и в продакшн". Это и масштабируемость продуктов. Так что О-нотация имеет прямое отношение к практическому быстродействию.
На мой взгляд, вот этот блог https://accidentallyquadratic.tumblr.com/ позволяет хорошо ощутить, насколько это практический вопрос.
А вот в этом посте https://habr.com/ru/post/590663/ приводится очень практический пример:
На немецком сайте Ikea (надеюсь они это уже исправили) была проблема: при попытке купить больше 10-12 товаров корзина заказа начинала настолько люто тормозить, что почти любая операция с ней сводилась к 40 секундным задержкам. Т.е. до глупого забавная ситуация: человек хочет купить больше, т.е. отдать компании больше денег, но т.к. где-то внутри сокрыты алгоритмы маляра Шлемиля, он не может этого сделать. Полагаю разработчики ничего об этом не знали. И QA отдел тоже (если он у них есть). Не переоценивайте ваших посетителей, далеко не каждый будет готов ждать по 40 секунд на действие.
А так, да, разумеется, стоимость шага алгоритма тоже имеет значение. Но с ней гораздо проще, потому что она отлично анализируется профайлерами. И для случаев с небольшими n, которые зачастую бывают и наиболее часто используемыми, часто откатываются на алгоритмы с большей сложностью, но допускающие эффективные реализации для маленьких n. Во многих современных стандартных библиотеках сортировка как раз и реализована различными алгоритмами в зависимости от n. Вот здесь https://habr.com/ru/post/344288/ разбирается реализация в Джаве.
В качестве бонуса, просто так - красивая табличка про алгоритмы и О-нотацию: https://www.bigocheatsheet.com/
Спасибо, был удивлён, что статью начали переводить ещё раз, даже 30% общего её обьема вдруг уже опубликовали сегодня.
Оставил на другом внезано начатом переводе комментарий, повторю здесь:
Я вот тоже удивляюсь, полный перевод уже есть вот тут
https://habr.com/ru/post/597059/
Зачем спешно переводить-публиковать 30% того, что уже переведено - опубликовано?
Неужели вдруг соревнование - кто первый и лучше перевёл? :)))
Длина же сортируемых ключей зависит от количества ключей
Спорное утверждение. Почему речь про уникальные ключи? Почему для уникальных ключей их длина вдруг начинает расти по мере добавления ключей?
Мне давали на собесе такую задачу, на 64-битных числах вела себя вполне линейно, уделывала сорт (и чем больше было чисел - тем сильнее).
Простите не понимаю как это может работать без дополнительных условий на значения в массиве.
В общем случае (если мн-во ключей просто 64 битные числа) - то не будет быстрее.
Ну и конечно можено подобрать (в зависимости от коллекции для хранения ключей) вообще worst-case, где будет кратно медленнее простого qsort.
- для хранения через bucket-HashMultySet: в массиве только два значения A и B и при этом hashcode A == hashcode B
- для tree-MultySet и list-HashMultySet: пусть у вас все элементы от 1..A.length, в случайном порядке.
https://www.onlinegdb.com/aBe_zFgte
100K 32-битных рандомных чисел, radix sort в 30 раз быстрее.
Результат по ссылке:
radix sort time: 13
arr[126689] = 272445306
std::sort time: 231
arr[898063] = 1927622001Результат по ссылке после добавления ключа -O2:
radix sort time: 11
arr[126689] = 272445306
std::sort time: 68
arr[898063] = 1927622001Так что не в 30.
Но в строке же 102 - как раз вычисляется логарифм от "актуального значения" максимального элемента.
Сохраняется в bytes_to_sort.
А потом bytes_to_sort раз пробегаемся по массиву, разделяя его на 256 бакетов.
Т.е. сложность сортировки - таки O(n * sizeof(elem)).
Он и без вычисления MAX будет работать (у меня числа до 2**31 если заметили). Тут вычисления max даже лишние, можно его заменить на max = 2147483648. Здесь это скорее оптимизация чтобы на мелких числах оно работало ещё лучше.
В общем случае (если мн-во ключей просто 64 битные числа) - то не будет быстрее.
Я вам пример скинул как ответ на ваше высказывание "оно не будет быстрее".
Для сортировки int32_t - да достаточно 2^31
Но если начнёте сортировать uint64_t - то нужно уже 2^64. Что сделает bytes_to_sort = 8. То есть кол-во операций в сортировке вдвое больше (это в дополнение, что в каждой итерации у вас будет копирование уже 64-битного числа).
Если начнёте сортировать __int128_t - то bytes_to_sort =16.
А если структурки, размером 32 байта - то bytes_to_sort = 32.
Это ровно оно и есть: временная сложность растёт как логарифм максимального значения ключа.
Почему для уникальных ключей их длина вдруг начинает расти по мере добавления ключей?
Отвечу сначала на этот вопрос, потому что он ключевой (no pun intended). Ячейка длиной в 1 бит может содержать два различных значения - 0 и 1. Ячейка длиной в два бита может содержать 4 различных значения - 00, 01, 10 и 11. С увеличением размера ячейки на 1 бит количество различных значений, которые она может содержать, увеличивается в 2 раза. Таким образом, ячейка в w битов может содержать не более  различных значений. Например, 8-битный байт может принимать
различных значений. Например, 8-битный байт может принимать  различных значений, а 16-битное слово -
различных значений, а 16-битное слово -  .
.
Т.е. если нужно отсортировать 257 различных ключей сортировки, то они не влезут в один байт. Если нужно отсортировать 18446744073709551617 различных ключей сортировки, то они не влезут в 64-битное слово.
Вы можете спросить, да кому может потребоваться сортировка ключей, не влезающих в 64-битное слово. На самом деле, очень многим: это и 128-битные GUID'ы или IPv6-адреса, и различные хэши, а самый часто встречающийся случай - это сортировка длинных символьных строк.
Итак,  . Соответственно, если у нас ячейка дожна принимать не менее n различных значений, то её размер w должен быть не меньше
. Соответственно, если у нас ячейка дожна принимать не менее n различных значений, то её размер w должен быть не меньше  битов. Таким образом при стремлении n к бесконечности получаем w ~
битов. Таким образом при стремлении n к бесконечности получаем w ~  . Это то, о чём я написал выше, только более кратко.
. Это то, о чём я написал выше, только более кратко.
Почему речь про уникальные ключи?
Теперь отвечу на этот вопрос. Потому что прежде чем говорить о ситуациях, когда ключи бывают не уникальными, нужно понять ситуации, когда ключи уникальны. Переход к ситуациям, когда ключи бывают не уникальными, можно провести при наличии знания о структуре распреления уникальных и неуникальных ключей. Предположим, что каждый ключ встречается k раз. Тогда, если у нас всего ключей n, то количество различных ключей будет  штук. Тогда потребный размер ячейки для хранения составит
штук. Тогда потребный размер ячейки для хранения составит  битов. При стремлении n к бесконечности константное слагаемое
битов. При стремлении n к бесконечности константное слагаемое  значения не имеет, и получается w ~
значения не имеет, и получается w ~ .
.
Кроме того, хочу зачетить, что как выше уже написали, для O-нотации не имеет значения и основание логарифма, т.к.  , где x - любое основание, и
, где x - любое основание, и  - это константный множитель, и поэтому в O-нотации основание опускается.
- это константный множитель, и поэтому в O-нотации основание опускается.
Таким образом, w ~ log n.
Когда у сортируемых данных есть какие-нибудь особенности - большая разреженность, большое количество одинаковых ключей, специфическое неравномерное распределение, частичная упорядоченность обычно есть подходы, позволяющие эксплуатировать эти особенности данных.
Мне давали на собесе такую задачу, на 64-битных числах вела себя вполне линейно, уделывала сорт (и чем больше было чисел - тем сильнее).
Как должно быть понятно из написанного выше, так и должно быть.
Когда мы ограничиваем длину ключа сверху (например, говорим, что ключи у нас 64-битные), то при этом условии поразрядная сортировка ведёт себе предсказуемым линейным образом, и это одно из важнейших преимуществ этого метода сортировки.
Вы написали длинный коммент с объяснением очевидных вещей против которых я не возражал.
Я спорю с веденной вами log(n), которой там нет и которую вы пытаетесь аргументировать рядом утверждений, которые применимы лишь к частным случаям.
128-битные GUID'ы или IPv6-адреса
128 битные GUID-ы и IPv6 имеют фиксированную длину. Не важно хотите вы хранить 2 адреса, 10 адресов или 10 миллионов адресов - длина ключа у вас будет одинаковая (и как следствие - сортировка будет линейная).
Со строками тоже вопрос. Взять к примеру БД сотрудников с ФИО. Очевидно что независимо от числа сотрудников (2 человека, 200 или 20000) - средняя длина строк будет одинакова. То есть в общем случае для строк алгоритм тоже линеен по отношению к n (это кстати не означает что для строк radix sort быстрее, речь только про n vs log(n)).
Ваш анализ применим только для тех задач в которых:
1) Ключи уникальные
2) Для хранения этих ключей используется сжатие и кодирование приближенное к оптимальному
Простите, судя по Вашему ответу, Вы немного недопонимаете, что O-нотация имеет дело с  или что из этого вытекает.
или что из этого вытекает.
Это ключевой момент, который надо осознавать, когда работаешь с O-нотацией. Это важно, потому что поведение в пределах бывает неинтуитивным.
Надо, впрочем, отметить, что увеличение размера ключей косвенно влияет и на эффективность применения других алгоритмов тоже - т.к. это увеличение приводит к соответствующему замедлению процедуры сравнения ключей (скорость каковой при анализе сложности алгоритмов сортировки обычно принимается константной). И об этом тоже имеет смысл помнить, когда работаешь с реально огромными данными или пишешь библиотеку, которая должна быть способна работать с реально огромными данными. Ну или когда сравниваешь реализации алгоритмов и получаешь немного не тот результат, который ожидал получить теоретически.
простите отвечу и здесь: строка 102 приведённого вами алгоритма.
Лол, да что угодно быстрее чем std::sort
Я придумал замечательный алгоритм сортировки, который рветн ska-sort как Тузик - грелку, является cache-frendly и использует векторные операции современных процессоров.
К сожалению, он хорошо работает только на vector<bool>.
Я написал более быстрый алгоритм сортировки