
Оптимизация кода и развитие микросервисной архитектуры занимает значительную часть жизни команды разработчиков МВидео-Эльдорадо. Тем любопытней изучить опыт коллег за рубежом. Предлагаем вашему вниманию очередной пост на тему: «А как там у них».
Разработчики ПО любят абстракции. Абстракции великолепны и являются ключевым инструментом эффективной разработки. В конце концов, писать ПО только единицами и нулями было бы слишком трудоёмко. Проблема возникает тогда, когда абстракции внедряются преждевременно, то есть до того, как они начнут решать реальную, а не теоретическую проблему. За добавление абстракций мы всегда расплачиваемся увеличением сложности, а при чрезмерном их количестве они замедляют разработку и усложняют понимание кодовой базы.
Все проблемы в computer science можно решить ещё одним уровнем абстракции… Кроме проблемы слишком большого количества уровней абстракций. — Батлер Лэмпсон
Этот пост иллюстрирует мысль о том, что избегание стандартных абстракций может привести к созданию гораздо более чистой кодовой базы с сильно сниженной сложностью, а также повышенной читаемостью и удобством поддержки.
В посте рассказывается, как мы с командой пишем микросервисы сейчас по сравнению с прошлым. В нашем случае это уменьшило размер стандартной фичи, например, новой конечной точки микросервиса для обновления или считывания данных, с примерно 25 файлов всего до пяти, то есть уменьшение составило 80%. При этом основная часть кода просто была удалена, и при этом также повысилась читаемость кода.
Описанные в посте идеи основываются на принципах Keep it Simple, Stupid (KISS) и You Aren’t Gonna Need It (YAGNI), означающих, что мы стремимся минимизировать абстракции и добавлять сложность только тогда, когда она обеспечивает существенную и реальную выгоду. Эти идеи применимы к большинству типов разработки ПО.
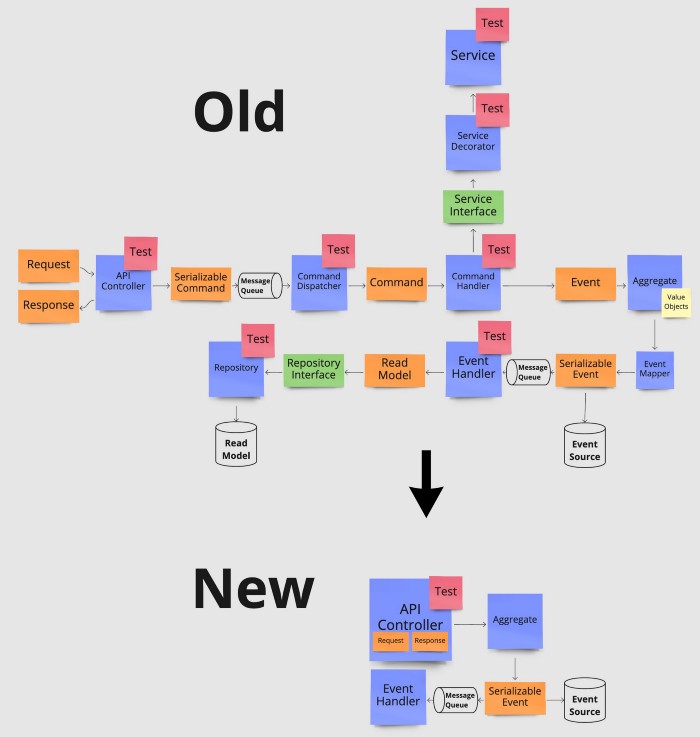
Файлы, требовавшиеся до и после устранения преждевременных абстракций. Схема создана на основе реального примера конечной точки, обновляющей элемент данных. Каждый прямоугольник обозначает файл.
Распространённые преждевременные абстракции
Давайте рассмотрим некоторые конкретные случаи преждевременных абстракций, которые часто возникают на практике. Все они взяты из реальных примеров в наших собственных кодовых базах.
- Слишком мелкая детализация ответственностей
- Применение шаблонов проектирования без реального выигрыша
- Преждевременная оптимизация производительности
- Повсеместное внедрение слабого связывания
Давайте внимательнее взглянем на каждую по отдельности.
1. Слишком мелкая детализация ответственностей
Одной из первопричин сложности кодовой базы является разделение ответственностей на слишком мелком уровне. Это может быть абстрагирование запроса к базе данных в специальный класс репозитория, HTTP-вызов, абстрагированный в класс службы или какой-нибудь полностью внутренний элемент логики, перемещённый в отдельный компонент.
Обычно так делают в соответствии с очень популярным в SOLID принципом единственной обязанности — каждый класс должен иметь только одну причину изменения или иметь только одну задачу. Если мы разобьём каждый крошечный элемент логики на отдельные классы, то всё будет иметь очень чётко очерченные ответственности, выполнять только одну задачу, а значит, иметь только одну причину для изменений. Звучит здорово, правда? Проблема заключается в том, что все эти мелкие элементы обычно всё равно тесно связаны и сильно зависят друг от друга. Если меняется любая коммуникация между элементами, то это часто имеет каскадный эффект и требует изменений во многих элементах. Поэтому пусть они и имеют только одну причину для изменений, это не приносит пользы, если единственное изменение часто требует внесения изменений во множество элементов, превращая модификацию кода в мучения.
Кроме того, наличие классов, меняющихся только по одной причине, часто не даёт реальных практичных преимуществ. На самом деле, внесение изменений в классы, выполняющие несколько действий, часто даёт разработчику гораздо больше контекста, упрощающего понимание изменения и его влияние на окружающий код.
Так когда же нужно разделять ответственности? Распространённый и крайне подходящий случай: когда логику нужно использовать в нескольких местах. Если один и тот же HTTP-вызов или запрос к базе данных необходим в нескольких местах кода, то дублирование логики часто снижает удобство поддержки. В таком случае перенос кода в общий многократно используемый компонент, скорее всего, будет хорошей идеей. Главное не делать этого прежде, чем станет необходимо. Ещё один подходящий случай: когда логика очень сложна и отрицательно влияет на читаемость окружающего кода. Если элемент логики занимает триста строк кода, это приемлемо, но в случае всего нескольких строк это только ухудшит читаемость и усложнит ориентирование в коде. Помните, что разделение ответственностей всегда добавляет в код больше структурной сложности.
Ниже показано, как смена нашей точки зрения на ответственности классов повлияла на исходную архитектуру, показанную в начале поста. Слева мы размещаем логику из класса службы непосредственно в обработчике команд, которому нужна логика службы. Справа мы помещаем запрос к базе данных в классе репозитория непосредственно в обработчик событий, которому он нужен.
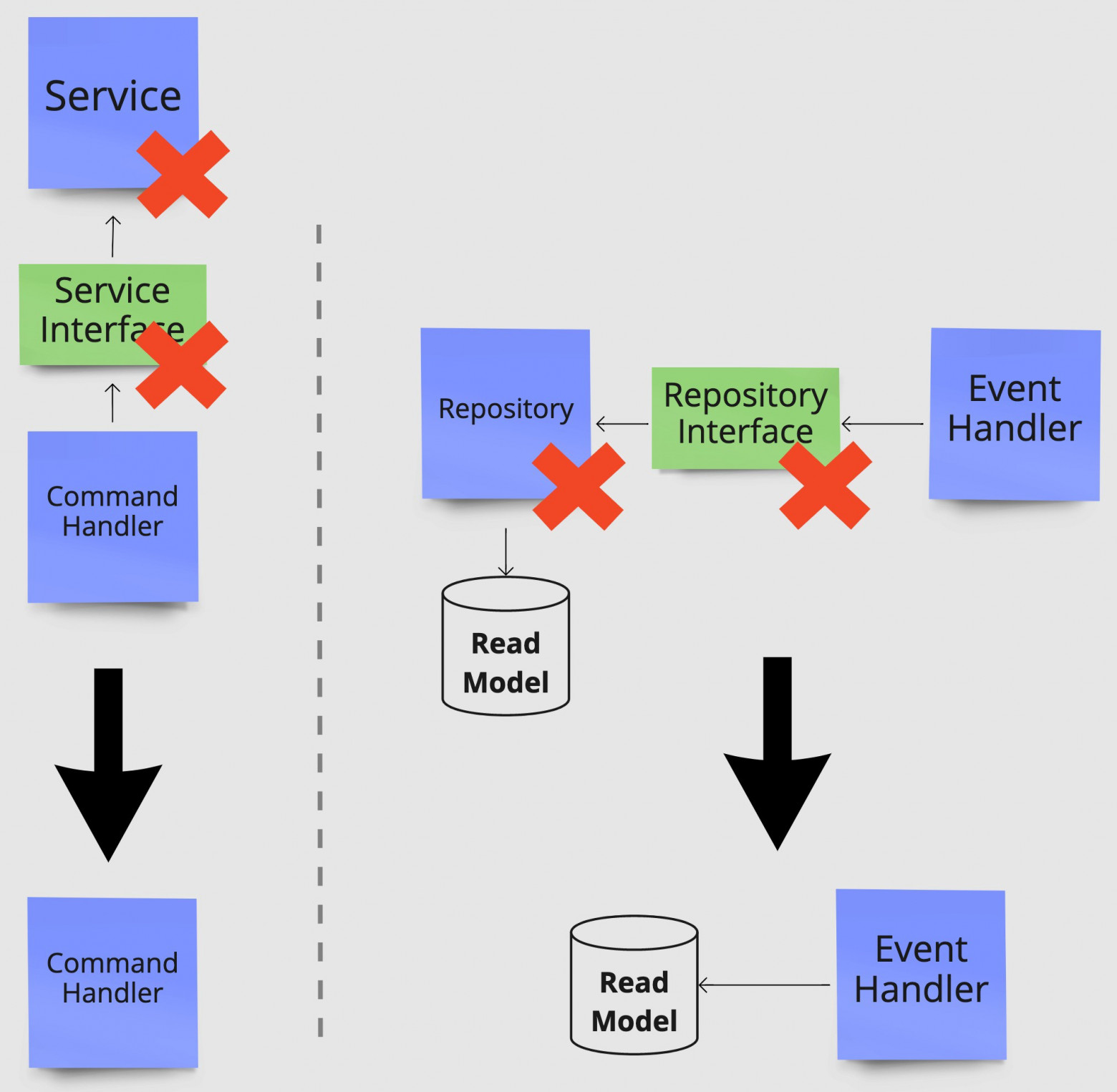
Слева мы поместили логику класса Service непосредственно в Command Handler, которому она необходима. Справа мы перенесли запрос к базе данных в Repository непосредственно в Event Handler, которому он нужен.
2. Применение шаблонов проектирования без реального выигрыша
Ещё одной распространённой ошибкой является реализация различных шаблонов проектирования программ до того, как выигрыш от них действительно необходим. Шаблоны проектирования отлично подходят для решения определённых проблем в кодовой базе, и при определённых обстоятельствах могут уменьшать общую сложность. Тем не менее, почти все шаблоны имеют недостаток: они повышают структурную сложность и снижают согласованность кода.
Хорошим примером этого является шаблон «Декоратор». Этот шаблон часто используется для добавления дополнительной функциональности поверх имеющегося компонента. Это может быть компонент, выполняющий HTTP-запрос, к которому нам нужно добавить механизм повторного запроса. Без изменения исходного компонента мы можем добавить новый компонент, оборачивающий исходный в добавленную поверх него логику повторного запроса. Реализовав тот же интерфейс, его можно заменить для исходного компонента напрямую или через внедрение зависимости.
Поначалу это кажется отличной идеей. Нам не нужно менять имеющийся код, мы можем протестировать каждый из них по отдельности и каждый элемент легко понятен. Огромный недостаток возникает вследствие того, что мы снова теряем согласованность. Когда в будущем разработчик посмотрит на исходный компонент или использующий его код, то ему не сразу станет понятно, что происходит при выполнении кода, так как поверх него «за кулисами» добавлена другая логика. В моей практике бывали реальные случаи того, что повторные запросы добавлялись непосредственно в класс, а потом выяснялось, что он уже декорирован логикой повторного запроса, и при развёртывании это оборачивалось множественными повторами запросов. Подобные случаи происходят, когда не сразу понятно, как ведёт себя код.
Ещё один часто применяемый шаблон — это «Команда» и «Издатель-подписчик». В нём класс вместо непосредственной обработки запроса абстрагирует его в команду, которая должна обрабатываться в другом месте. Примером этого может быть API-контроллер, отображающий HTTP-запросы в команды и публикующий их, чтобы они обрабатывались соответствующим обработчиком, подписанным на эту конкретную команду. Это обеспечивает слабое связывание и чёткое разделение между частью кода, получающей и интерпретирующей запросы, и частью, знающей, как обрабатывать запросы. Разумеется, существуют подходящие случаи применения такого шаблона, но правильно будет задаться вопросом, не является ли он на практике просто бесполезным слоем отображения. Слоем отображения, ещё сильнее запутывающим отслеживание пути исполнения программы, так как издатель, по определению шаблона, не знает, где выполняется обработка команды.
И это только пара примеров шаблонов проектирования, которые часто используют преждевременно. То же самое можно сказать почти о любом из шаблонов. У всех них есть недостатки, поэтому применяйте шаблон только тогда, когда его преимущества необходимы и перевешивают минусы. Ниже показано, как повлияло на нашу исходную архитектуру устранение необязательных шаблонов проектирования. Слева мы удалили шаблон «Декоратор», а справа весь поток выполнения команд, в том числе и механизм издателя/подписчика.
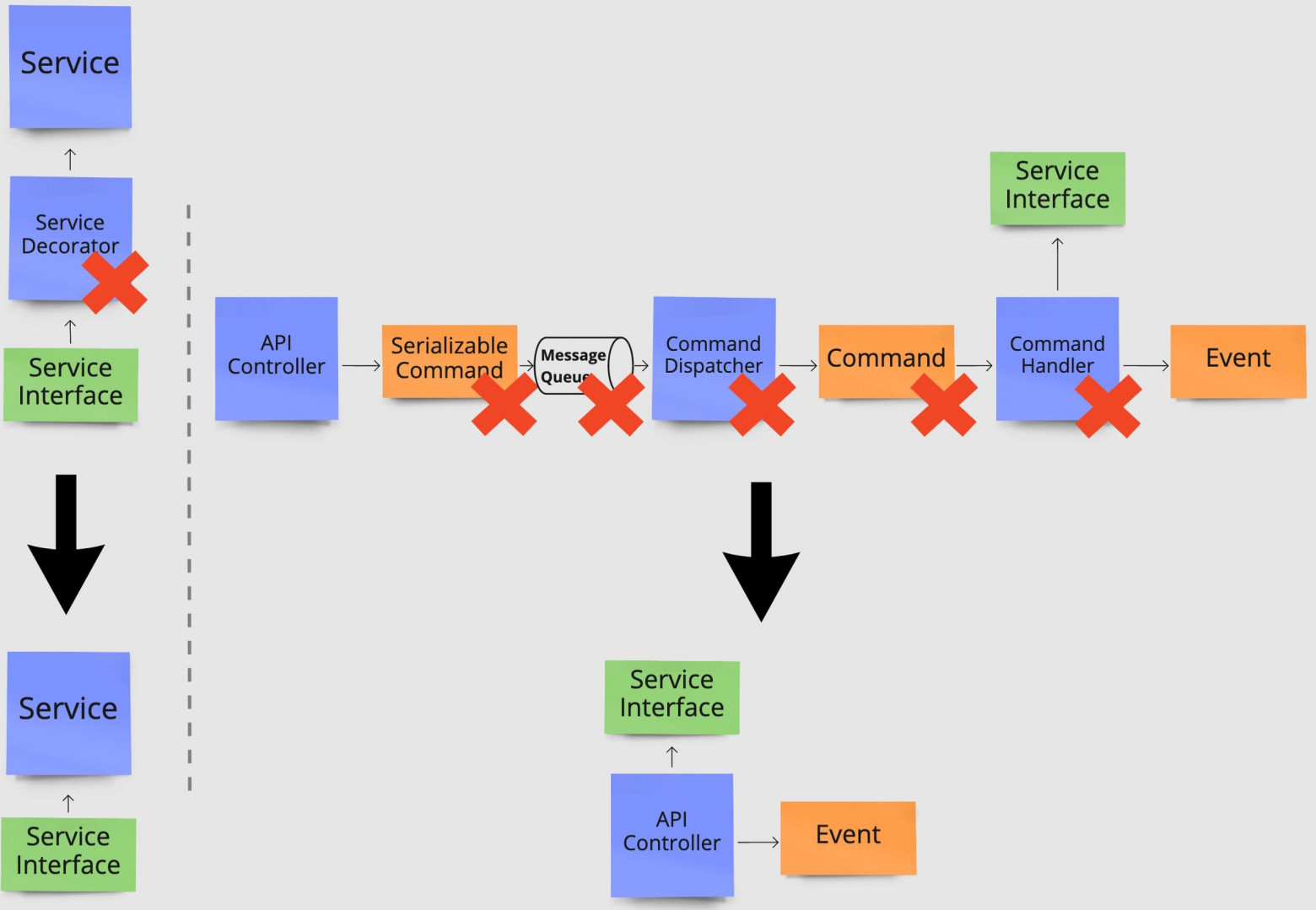
Удаление преждевременно добавленных шаблонов проектирования. Слева удалён шаблон «Декоратор». Справа удалён шаблон «Команда» и «Издатель-подписчик».
3. Преждевременная оптимизация производительности
Создание ПО с хорошей производительностью — критически важная задача, и часто самое эффективное решение задачи является самым чистым и простым. Однако иногда это не совсем справедливо. В таком случае стоимость оптимизации необходимо сравнить с реальным выигрышем, который мы ожидаем получить на практике. При сравнении нужно учесть такие затраты, как время, потраченное на анализ, реализацию и поддержку оптимизации, а также потенциальное снижение читаемости кода из-за использования более сложного подхода для достижения эффективности. Не жертвуйте читаемостью кода в пользу необязательной эффективности, и помните, что затраты времени разработчика часто сильно превосходят потенциальный выигрыш от экономии вычислительных ресурсов микрооптимизацией кода.
Преждевременная оптимизация — корень всех зол — Дональд Кнут
Оптимизации могут вноситься и на архитектурном уровне. Одним из примеров этого является шаблон Command Query Responsibility Segregation (CQRS). По сути, CQRS означает, что у нас имеются две отдельные модели данных, одна из которых используется для обновления данных, а другая для чтения данных, что разделяет приложение на части чтения и записи. Это позволяет оптимизировать одну часть для эффективного чтения, а другую — для эффективной записи, а также масштабировать одну из частей в случае, если приложение особенно активно использует чтение или запись.
Огромный недостаток этого шаблона заключается в том, что необходимо создать и поддерживать целую отдельную модель данных, что приводит к большой трате излишних ресурсов на разработку. Если требуется производительность, то такой компромисс может вас устроить, но даже в случае приложений, используемых миллионами людей, я редко вижу, чтобы повышение эффективности чтения или записи обеспечивало какой-то заметный выигрыш. Более логичным решением было бы использовать единую модель и для чтения, и для записи, а оптимизированные модели чтения создавать только для нескольких отдельных случаев, когда точно известно, что простое решение не будет работать адекватно.
Ниже показана иллюстрация удаления части чтения из нашего примера выполнения программы. Повторные запросы выполняют считывание не из специальной таблицы Read Model, а непосредственно из Event Source, который в нашем примере является тем, куда данные записываются изначально.
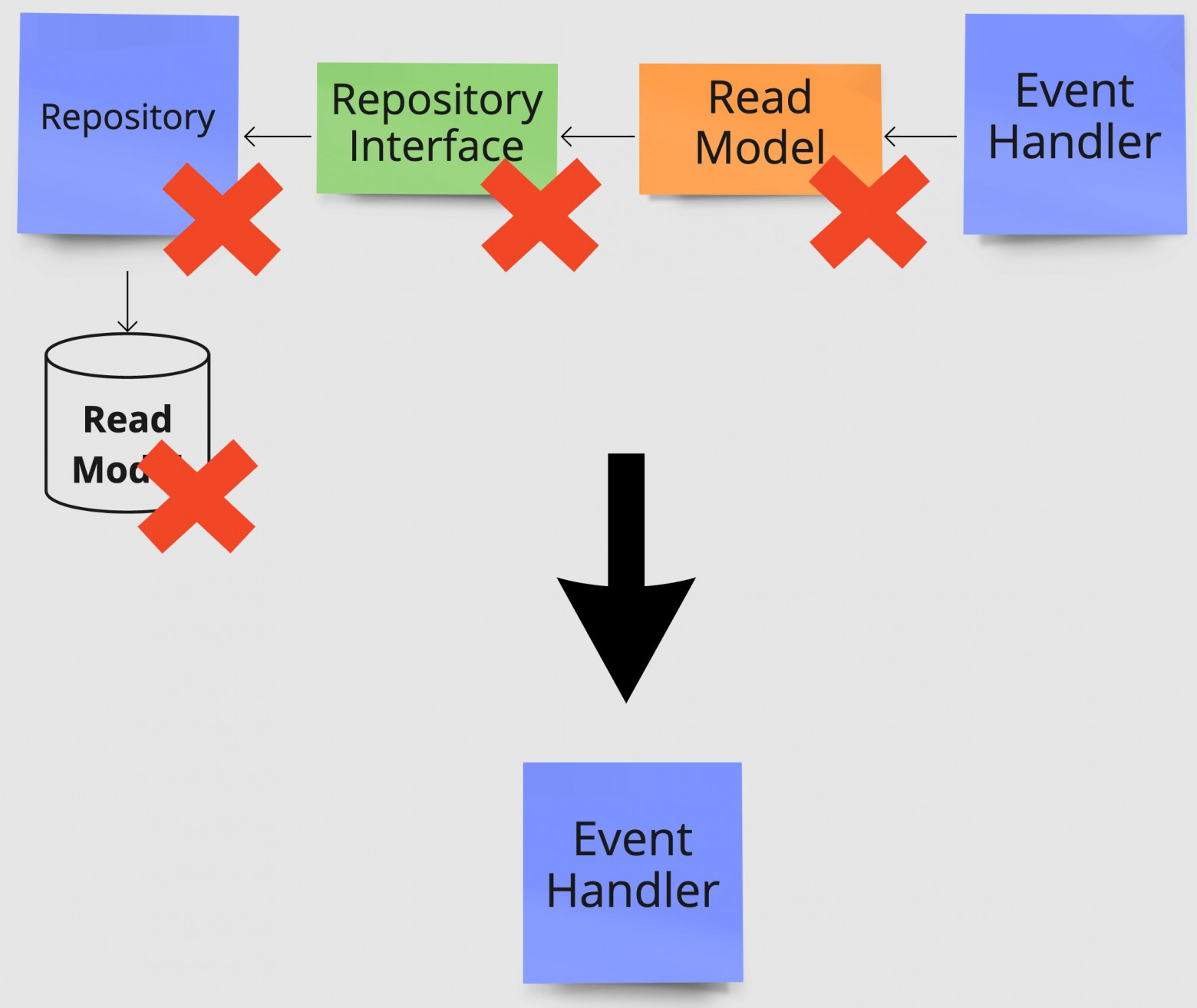
Удаление всей отдельной части чтения приложения, чтобы использовать одну модель и для чтения, и для записи.
4. Повсеместное внедрение слабого связывания
В кодовой базе со слабым связыванием каждая часть максимально независима от остальных частей. Благодаря слабому связыванию изменения в одной части минимально влияют на другие части и упрощается замена части кода, ведь они зависят друг от друга совершенно минимально. Хорошим примером этого являются внешние библиотеки или модули, используемые множеством различных кодовых баз. Нам не нужно, чтобы изменения в функциональности библиотеки влияли на использующие её кодовые базы больше, чем это совершенно необходимо, и нам удобно, если можно заменить эту библиотеку другой в случае возникновения такой необходимости.
Типичным способом достижения слабого связывания является реализация принципов инверсии зависимостей и открытости/закрытости из SOLID, гласящих, что сущности должны зависеть от абстракций, а не от конкретных реализаций, и в то же время быть открытыми для расширения и закрытыми для модификаций. На практике это часто реализуется абстрагированием классов в интерфейсы; другие классы при этом зависят от интерфейсов, а не от конкретных классов.
Проблема возникает, когда интерпретация этих принципов приводит к тому, что слабое связывание внедряется повсюду, даже среди отдельных классов внутри отдельной фичи, например, конечной точки API микросервиса или экрана во фронтенде. Часто это проявляется как обширное внедрение интерфейсов для каждого отдельного класса, открывающих всю логику, используемую другими классами внутри соответствующей фичи.
Отдельной фиче не требуются слабое связывание и интерфейсы для элементов, которые находятся внутри неё, потому что такое слабое связывание имеет свою цену. Слабое связывание, и в особенности интерфейсы, снижают согласованность кода и усложняют ориентирование в нём, потому что ты не знаешь непосредственно, какой конкретно код будет исполняться. Тебе сначала нужно проверить, какие реализации существуют в интерфейсе, а затем разобраться, какая конкретно применяется во время исполнения. Кроме того, интерфейс — это ещё один файл, добавляемый в проект, актуальность которого нужно поддерживать при изменении сигнатуры конкретной реализации.
Интерфейсы решают множество проблем, поэтому внедряйте их тогда, когда они необходимы для решения реальной практической проблемы, но не стоит добавлять их раньше только для достижения необязательного слабого связывания. Обычно оно необходимо, когда вам нужна возможность замены реализации или когда вы создаёте внешние библиотеки, используемые другими людьми, не имеющими доступа на изменение кодовой базы библиотеки. Кроме того, если вы используете интерфейсы только для того, чтобы можно было применять заглушки в тестах, то серьёзно рассмотрите возможность перехода на библиотеку-заглушку, позволяющую имитировать конкретные классы, чтобы избежать лишней траты ресурсов.
Ниже показан пример устранения двух интерфейсов; обработчик событий и обработчик команд получают прямые ссылки на конкретные реализации репозитория и класса службы.
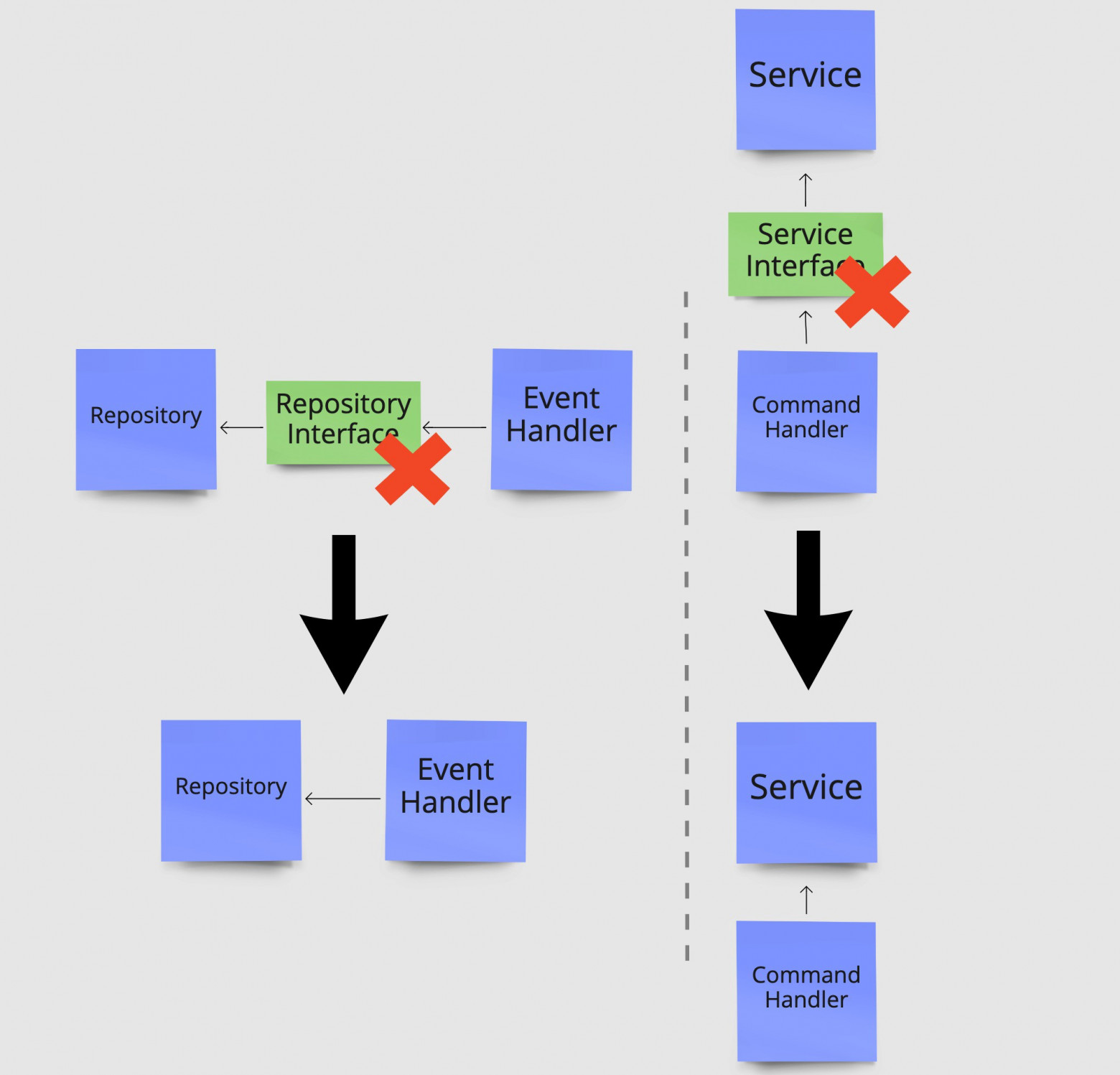
Избавление от интерфейсов, без которых можно обойтись. Интерфейс для репозитория слева и интерфейс службы справа.
Дополнительный совет для любящих рисковать
Если вы особенно любите рисковать, то можете пойти ещё дальше и переместить отдельные классы в один файл. Если классы сильно связаны, созависимы и часто изменяются вместе, это может повысить и удобство поддержки, и понимание контекста при внесении изменений. Тем не менее, будьте готовы переместить класс в отдельный файл, если он значительно вырастет в размерах — ведь в конечном итоге мы не хотим снизить читаемость.
Важно здесь то, чтобы совместно изменяемые элементы кода были расположены друг к другу как можно ближе, чтобы такие изменения проходили беспроблемно. Обычно чаще бывает так, что изменение влияет на несколько классов потому, что они находятся в одной фиче, чем потому, что они относятся к определённому типу. По сути, в таком случае предпочтительнее архитектура вертикального среза, чем классическая архитектура Onion, так как обычно изменения чаще вертикальны, чем горизонтальны. В такой ситуации очень полезно бывает группировать классы по папкам на основании фичи, к которой они относятся, а не на основании их типа.
В нашей архитектуре это проявляется следующим образом: классы для запроса и ответов располагаются в том же файле, что и контроллер, получающий запрос на входе и возвращающий ответ на выходе. Это хороший пример очень тесно связанных классов, которые часто меняются вместе. Поместив их в один файл, ты сразу же видишь фичу целиком без необходимости прыгать между файлами. Здесь также важно заметить, что для каждого контроллера есть только одна конечная точка. То есть каждый файл интересует только эта отдельная фича и ничего другого.
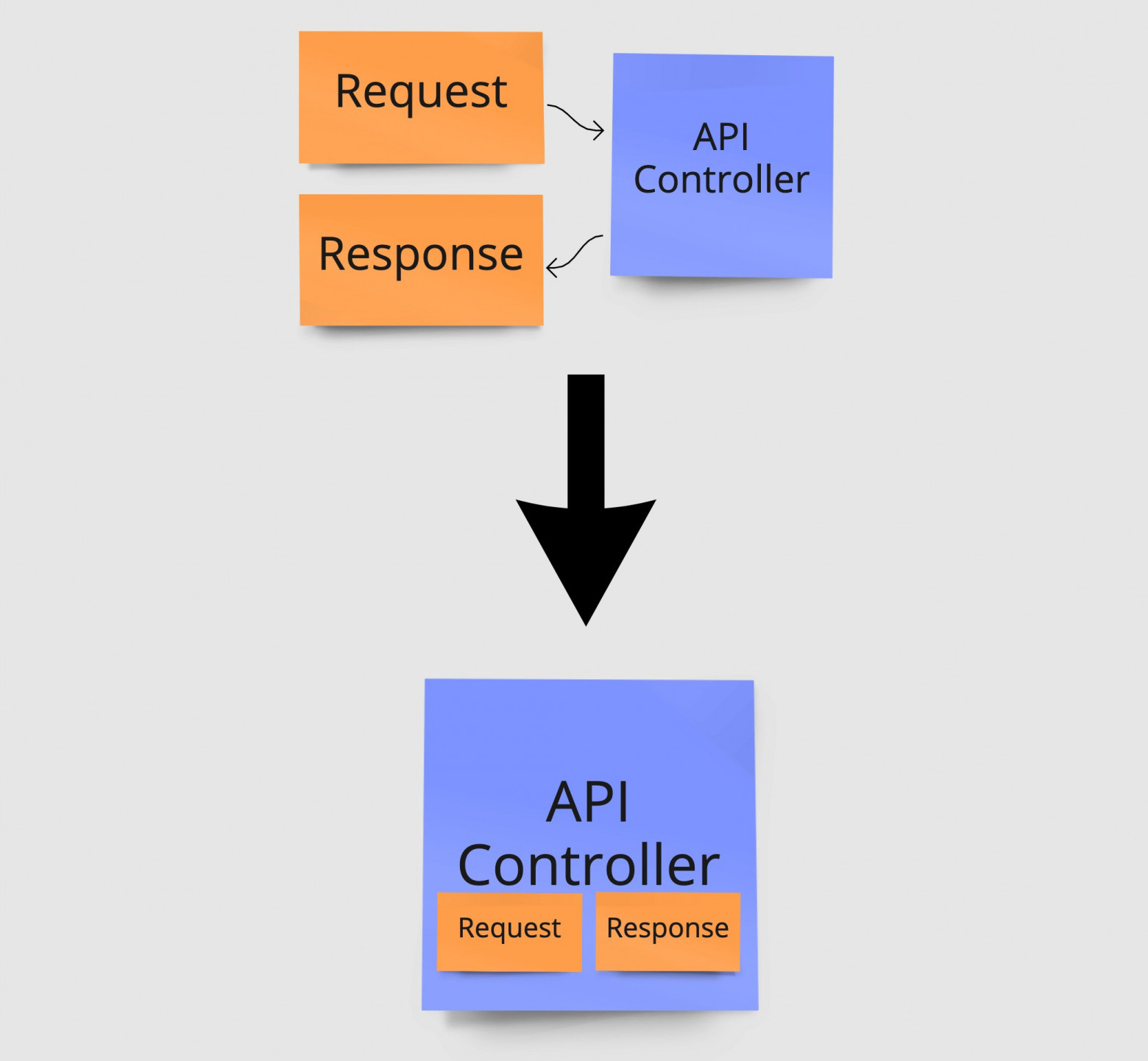
Слияние близко связанных классов, таких, как запрос, ответ и контроллер. Этот файл занимается обработкой всего для одной конечной точки. Иными словами, для каждого класса контроллера есть только одна конечная точка.
Выполняйте рефакторинг, когда возникнет потребность
Теперь, когда мы больше не создаём преждевременных абстракций, важно сделать рефакторинг неотъемлемой частью внесения изменений. Если элемент логики внезапно оказывается необходимым в нескольких местах, то настало время абстрагировать его в отдельный многократно используемый компонент. Если внезапно возникнет необходимость замены реализаций, то это подходящее время для добавления интерфейса. Избегание преждевременных абстракций не означает, что абстракции не будут добавляться никогда; мы просто добавляем их, только когда возникает реальная потребность. Это ни в коем случае не является оправданием для написания неуклюжего спагетти-кода.
Однако при наличии всех этих улучшений выполнение рефакторингов и перемещение элементов должны стать лёгкой задачей. Однако при рефакторинге часто остаётся одна болевая точка — наличие отдельных юнит-тестов для каждого отдельного класса, все зависимости которого имитируются. Подобный тип автоматизированного тестирования заставляет каждый класс вести себя и общаться с другими классами очень конкретным образом, потому что мы, по сути, тестируем реализацию кодовой базы, а не поведение. Это означает, что когда класс изменяет свои юнит-тесты, то часто приходится обновлять все остальные тесты, имитирующие этот класс. Это не очень удобно, если изменение является исключительно структурным рефакторингом, например, переносом какой-то части логики в многократно используемый компонент, при котором внешнее поведение кодовой базы не меняется.
По этой причине мы полностью отказались от подобного юнит-тестирования и выбрали совершенно иной подход к автоматизированному тестированию. Он позволяет нам быстро выполнять всевозможные внутренние рефакторинги, не обновляя ни одного теста. Но это уже абсолютно другая тема для отдельного поста, который можно найти здесь.
Применение описанных выше принципов к нашей исходной архитектуре привело к созданию показанной ниже улучшенной архитектуры. И для этого оказалось достаточно избавиться от преждевременных абстракций.
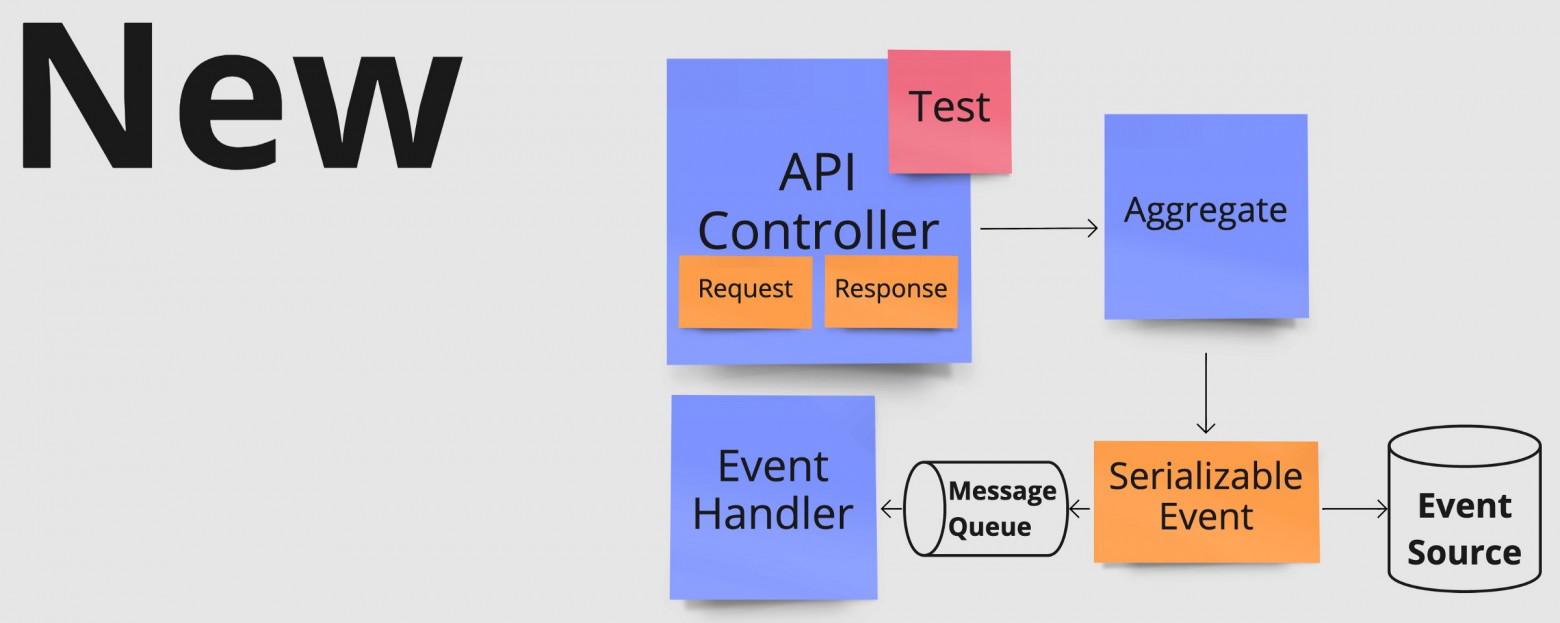
Улучшение архитектуры в результате избавления от преждевременных абстракций.
Заключение
Мы рассмотрели четыре распространённых типа преждевременных абстракций; они часто встречаются в кодовых базах, что приводит к необязательной сложности. Все эти абстракции имеют вполне обоснованные причины для использования, но проблема возникает, когда они внедряются преждевременно и на практике не дают реального выигрыша. Существует множество других примеров, похожих на перечисленные в этом посте. Самый важный вывод, который можно сделать из статьи — вам следует изменить образ мышления и всегда внимательно анализировать каждую часть кода.
Каждый раз, когда вы задумывайтесь о внедрении ещё одной абстракции, задайте себе и коллегам вопрос, действительно ли она обеспечивает ценность, к которой вы стремитесь, или от неё без проблем можно отказаться. Увеличение сложности исходя из теоретических причин типа «для разделения задач» или «чтобы не зависеть от конкретных реализаций» недостаточно обосновано. Каждый раз, когда вы увеличиваете сложность, у этого должны быть конкретные, практические, реальные преимущества.
Теперь взгляните на свои кодовые базы. Есть ли в них преждевременные абстракции, от которых можно избавиться? Хорошая кодовая база упрощает и ускоряет внесение простых изменений и выполнение рефакторингов. Проверьте свои недавние пул-реквесты и сравните размер изменений с тем, чего вы ими достигли.

