Технический долг — головная боль многих разработчиков. Это та ситуация, когда ты видишь, что можно сделать лучше, но не делаешь этого из-за высокой нагрузки, малого количества времени и ещё по тысяче причин. В итоге долг накапливается, накапливается, накапливается... А потом что-то происходит. Как сделать так, чтобы иметь возможность разгребать технический долг, поговорим в этой статье.

Технический долг — популярный термин у айтишников. Если максимально обще выражаться, под этим словосочетанием понимают использование неоптимальных решений для ускорения процесса разработки. Почему он называется именно «техническим долгом», а не просто «хламом»? Потому что он отчасти похож на финансовый долг: если мы не возвращаем его, это сказывается на новых функциях и даже обслуживании, точно так же, как проценты накапливаются по вашей задолженности.
Одной из причин возникновения технического долга являются сознательные и бессознательные компромиссы при проектировании и создании систем, отсутствие чистого кода, документации и "best practices". Есть и другая причина: технологии развиваются, и то, что было идеальным решением два года назад, уже не так удачно смотрится сегодня.
Мифы двух бэклогов
Некоторые команды зачем-то ведут два бэклога: один ориентирован на продукт, второй – на технологии. Это неразумно, и вот почему:
Трудно установить перекрёстный приоритет в отдельных невыполненных задачах из этих бэклогов;
Такой подход подпитывает мышление «мы против них», что убивает сплоченность команды и мешает общим целям;
Расстановка приоритетов определяется всей командой. Исключение представителей продукта — нерационально;
Усложняется планирование спринта, если нет строгих правил распределения ресурсов (например, 20% времени постоянно выделено на технический долг);
Рекомендую иметь один бэклог и добавлять туда все ваши задачи. Помечайте технический долг, если вам нужна статистика, но добейтесь того, чтобы приоритеты были расставлены по всем невыполненным задачам.
Не превращайте технический долг в игру «обвини другого»
Очень часто встречающаяся ошибка: обвинение всех вокруг в возникновении технического долга. Наверняка вы видели, как некоторые сотрудники (инженеры, продакт-менеджеры) говорили коллегам что-то вроде «Если бы вы сразу придумали лучшее решение, то эта ситуация не возникла бы». Это глупые, нечестные и бессмысленные обвинения.
Идеал недостижим. Мы — люди, контекст постоянно меняется, технологии развиваются. Это надо просто принять. Лучшее, что могут сделать разработчики и иже с ними — это учиться на своих ошибках, внедрять передовой опыт и максимально полно осознавать компромиссы, на которые идут при разработке продукта.
Игры в обвинения отвлекают всех от решения проблемы. Люди вынуждены защищаться, что снова приводит к «перебрасыванию мяча» друг к дружке, ни на шаг не приближая нас к действительно важному результату.
Как обсуждать технический долг
Мы обсудили основные ошибки, а теперь давайте поговорим о том, как правильно аргументировать важность погашения технического долга. Обычно это сводится к перечислению рисков, вызванных существующим техническим долгом, сложностью обслуживания и поддержки, а также, упором на то, что он препятствует разработке новых функций.
Большинство разработчиков не нуждаются в просьбах разобраться с техническим долгом. Часто они сами в этом заинтересованы. Но зачастую людям (другим разработчикам, продакт-менеджерам, руководителям т. д.) требуется больше контекста для того, чтобы оценить действительную важность погашения техдолга.
Лучшая стратегия здесь: говорить на языке, понятном собеседнику. Просто говорить о важности бессмысленно, ведь в бэклоге может находиться ещё 100500 задач, которые тоже кажутся важными. Не говорите, что хотите заняться техдолгом просто так, «по фану». Если ваши аргументы выглядят как желание поиграться с любимым проектом, вашу инициативу вряд ли одобрят.
Важно связать определённые задачи технического долга с потребностями ваших внутренних или внешних клиентов, а также производительностью продукта. Это — сработает.
Риски

К некоторой части технического долга прилагаются и риски. Например, если ваше решение использует стороннюю библиотеку, срок службы которой подходит к концу — это риск. Если вы не обновите решение или не перейдёте на другое, более совершенное, то ваша система, зависящая от третьей стороны, может превратиться в тыкву, став нефункциональным. Или станет уязвимым из-за отсутствия новых исправлений безопасности. Разумеется, ситуации могут быть разными. Надо различать уровни угрозы: отключение систем на следующей неделе или вероятность эксплуатации какой-либо уязвимости через пару лет.
Другой риск связан с удержанием клиентов. Плохой опыт, вызванный не самыми лучшими решениями (недовольство частыми отключениями, медленном обслуживании и прочими «мелочами») приводит к оттоку клиентов.
Ещё несколько аргументов, которые можно использовать при обсуждении рисков технического долга:
Мы можем исправить две ошибки, но пропустим третью из-за «дублирования кода».
Текущая архитектура системы может замедлить работу пользователей при высоких нагрузках.
Отсутствие современных решений по безопасности может привести к возникновению инцидентов и юридической ответственности;
Существует вероятность появления новых ошибок из-за отсутствия юнит-тестов;
Сложность и негибкость кодовой базы заставляют отказываться от новых функций из-за чрезмерных трудозатрат на их разработку.
Чтобы сделать вашу речь о необходимости заняться техническим долгом более убедительной, соберите данные о вашей инфраструктуре и назовите имеющиеся проблемы. Да, это не всегда возможно. Но с конкретными аргументами вы имеете больше шансов на принятие желаемого решения. Помните, что аргументом в вашу пользу может стать даже слишком долгое время выполнения тестов, ведь это время вы вынужденно простаиваете.
Трудности обслуживания

Многие задачи требуют больше времени и сил, если кодовая база сложная и негибкая, если используются неэффективные или устаревшие инструменты. В сочетании с наплывом клиентов или возникновении каких-то технических проблем это может привести к остановке работы всей команды, поскольку даже банальные исправления будут занимать целый день.
Ну правда, сначала часа четыре уйдёт на то, чтобы понять, что происходит в системе. Ещё часа два — на то, чтобы сделать тесты зелёными. А потом час разворачивать исправления, так как система при обновлении зависает 3 раза из 5.
Ситуаций, о которых я говорю, можно и нужно избегать ещё на ранних стадиях разработки. Но обычно вы осознаёте, насколько всё печально, лишь когда сталкиваетесь с подобными проблемами.
Мои примеры можно назвать забавными, но они помогают лучше понять, как много времени можно сэкономить, если всё будет работать должным образом. Поговорите со своей командой о том, что работу можно упростить. В идеале — если приведёте конкретные цифры.
Эффективность разработки новых функций
Снижение количества и качества разрабатываемых новых функций во многом определяется сложностью кодовой базы, о которой говорилось выше. Трудности обслуживания системы приводят к уменьшению возможностей для реализации новых функций. Но есть и другие проблемы.
Работа с трудной для понимания кодовой базой снижает скорость разработки (и может увеличить количество и серьёзность новых ошибок).
Адаптация новых сотрудников от команды больше времени и усилий со стороны команды. Когда ещё новичок разберётся с вашей кодовой базой?
Чрезвычайно трудно внедрить новое решение в плохо спроектированную или устаревшую с точки зрения архитектуры систему. Так рождаются ужасные проекты рефакторинга.
Патчи и всевозможные костыли, которые вы добавляете в систему, существуют лишь вокруг неё. Это ещё больше усложняет систему и увеличивает технический долг. Самый настоящий порочный круг!
Способы расстановки приоритетов
Стоимость задержки
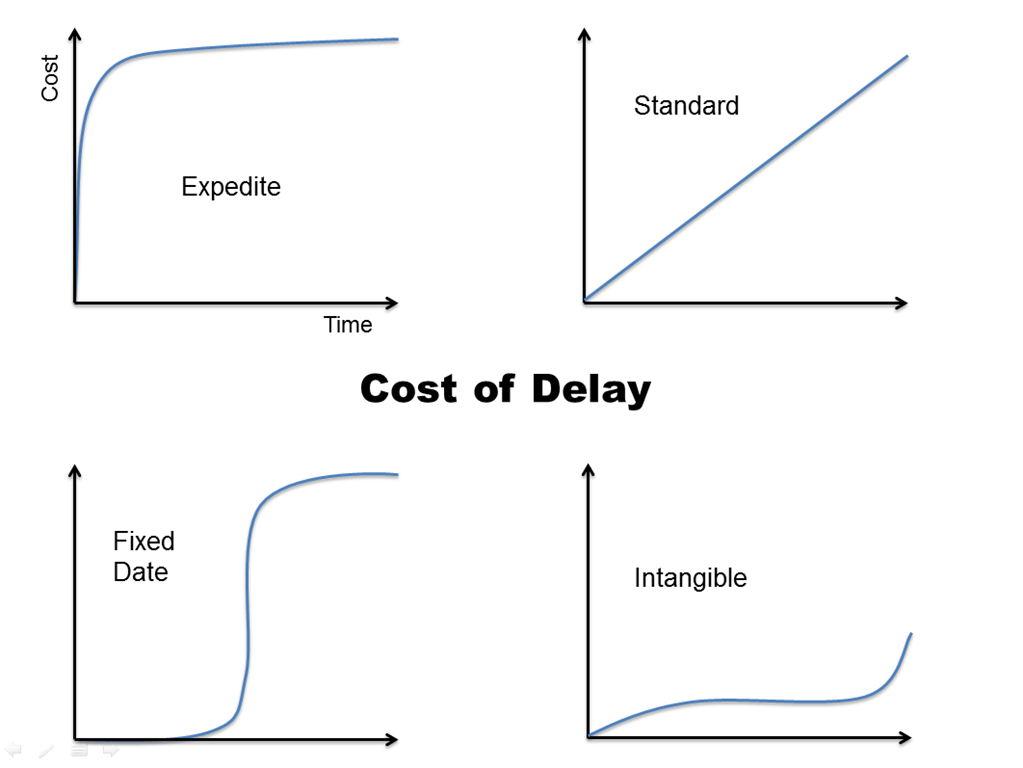
«Стоимость задержки» не является оптимальным методом приоритизации, но это очень хорошая метрика, когда речь идёт о рисках. Она сочетает в себе срочность и ценность, предлагая определить размазанные по определённому отрезку времени затраты, которые компания понесет, предоставляя эту конкретную функцию/проект/продукт позже, чем ожидает рынок или клиент.
Варианты того, как стоимость задержки будет вести себя с течением времени, можно увидеть на изображении ниже:
Оценка ICE и RICE
Этот подход может помочь навести порядок в хаосе ожиданий, создавая понятную картину приоритетов, на основе которой можно сортировать задачи.
ICE расшифровывается как Impact, Confidence и Ease/Effort. R в RICE означает Reach.
Для каждого из этих факторов команда согласовывает набор баллов. Например, Критический = 3 Высокий = 2, Средний = 1, Низкий = 0,5, Минимальный = 0,25
Влияние (Impact). Какое влияние окажет решение этой проблемы на клиентов (помните, что клиенты могут быть и внутренними!) — или, говоря о риске, какое влияние окажет нерешённая проблема?
Уверенность (Confidence). Насколько вы уверены в своей оценке важности?
Легкость/усилие (Ease/Effort). Сколько усилий потребуется, чтобы решить проблему? Помните, что это относительная метрика, которую можно сравнить только с другими задачами из списка.
Охват (Reach) — на скольких людей это повлияет? 100% вашей клиентской базы? Только отдельных лиц?
Важно понимать, что эти оценки имеют значение только в каком-то конкретном случае. Когда у вас есть числа, расчёт прост:
RICE score = (Impact x Confidence) / Effort or Impact x Confidence x Ease
Ещё несколько советов
Предусматривайте ресурсы для работы с техдолгом
Я знаю, что многие команды выделяют какую-то часть рабочего времени на задачи из бэклога. Самая распространённая модель — это 70% для обычной работы, 20% для технического долга и 10% для обучения/экспериментов.
Проблема здесь кроется том, что крупные проблемы с техническим долгом никогда не решаются всего за 20% времени. Их переносят от спринта к спринту, в ходе переноса теряется контекст, и добиться нужного результата становится труднее. Ещё одна сложность заключается в невозможности соблюдения точных временных рамок при решении разных задач.
Договоритесь брать X задач в каждом спринте
Этот подход предполагает не обращать внимание на временные рамки, а просто брать и делать энное количество задач из бэклога в каждом спринте.
Некоторая проблематичность подхода заключается в том, что отдельные задачи могут занимать значительную часть спринта.
Относитесь к важным частям техдолга как к задачам
Иногда технический долг принимает форму длительных проектов, которые необходимо планировать и выполнять соответствующим образом. Так и относитесь к нему так же! Формулируйте четкое представление о цели, масштабе и поставленных целях (и измеряйте их!)
Делайте лучше
Есть хорошее правило: вы должны оставлять кодовые базы и системы в лучшем состоянии, чем вы их нашли. К средним задачам технического долга можно подходить именно таким образом. Вы можете резервировать ресурсы на частичное закрытие техдолга в ваших проектах.
Разумеется, для погашения технического долга необходимо работать не в одиночку, а командой.
Заключение
Это может показаться нелогичным, но уделяя время тылам, вы упрощаете своё движение вперёд. Работайте с техническим долгом, и у вас будет меньше проблем в будущем.
Источники
Что ещё интересного есть в блоге Cloud4Y
→ История Game Genie — чит-устройства, которое всколыхнуло мир
→ Как я случайно заблокировал 10 000 телефонов в Южной Америке
→ WD-40: средство, которое может почти всё
→ 30 лучших Python-проектов на GitHub на начало 2022 года
Подписывайтесь на наш Telegram-канал, чтобы не пропустить очередную статью. Пишем не чаще двух раз в неделю и только по делу.

