Когда-то давно люди много путешествовали, посещали новые города и страны, им удавалось насладиться культурой других народов, пообщаться с ними на языке жестов. Исследовать новый для себя город можно по-разному. Например, бесцельно гулять по его улицам, впитывая атмосферу, состоящую из множества разных мелочей. И это отличный способ, если времени на осмотр много и точно знаешь, что рано или поздно еще вернешься. В противном случае полезно оптимизировать визит, используя путеводители, карты достопримечательностей и статьи других путешественников.
Число исследований в области машинного обучения с каждым годом растет. Конечно, приятно было бы прогуляться по каждой статье или ветке исследований отдельно, но времени на это просто может не хватить, а «посетить» 2021 год еще раз, увы, не удастся. Следовательно, необходимо также искать «путеводители» - статьи, подсвечивающие некоторые тренды, понимание которых важно для будущих направлений исследований. В начале года одна из таких статей «гуляла» по различным каналам и чатам. Мне захотелось перевести ее на русский и поделиться с вами. Далее приведу перевод этой статьи с моими комментариями.
 (https://arxiv.org/abs/2107.13586)")
В предлагаемой работе обобщаются достижения в нескольких значимых областях машинного обучения, в частности, в обработке естественного языка за 2021 год.
2021 год отмечен впечатляющими достижениями в сферах машинного обучения (machine learning, ML) и обработки естественного языка (natural language processing, NLP). Эта работа охватывает наиболее примечательные, на взгляд ее автора, публикации и направления исследований. Я рассмотрел только те, о которых сам имел представление, поэтому я вполне мог упустить из виду многие относящиеся к делу статьи. Прошу указывать в своих комментариях не упомянутые мной публикации, которые произвели на вас впечатление. В этом обзоре я рассмотрел следующие темы.
1) Универсальные модели (Universal/ Foundation models)

Обучение без учителя межъязыковому представлению речи с помощью модели XLS-R. Эта модель была предобучена на разнообразных многоязычных речевых данных с использованием функции потерь (loss) в парадигме обучения без учителя wav2vec 2.0. Затем эту обученную модель можно было файн-тюнить для решения различных речевых задач (Babu et al., 2021).
Основные результаты
В 2021 году продолжалась разработка все более крупных предобученных моделей. Предобученные модели нашли свое применение в различных областях и стали считаться критически важными для исследований машинного обучения [1]. В области компьютерного зрения предобученные модели с учителем, такие, как Vision Transformer [2], подверглись масштабированию [3]. Предварительно обученные модели с самообучением учителя догнали их по производительности [4]. Последние были масштабированы за пределы контролируемой среды ImageNet до случайных коллекций изображений [5]. В области обработки речи были созданы новые модели на основе wav2vec 2.0 [6], такие, как W2v-BERT [7], а также более мощные многоязычные модели, например XLS-R [8]. В то же время мы увидели новые унифицированные предобученные модели для малоизученных пар модальностей: видео и язык [9], а также речь и язык. [10]. В сочетании пар модальностей «зрение и язык» контролируемые исследования выявили важные аспекты подобных мультимодальных моделей [11][12]. Благодаря формулированию различных задач в парадигме языкового моделирования удалось создать модели, которые могут быть применимы и в других областях, таких, как обучение с подкреплением [13] и предсказание структуры белков [14]. Исходя из наблюдаемого поведения этих универсальных моделей при масштабировании, исследователи обычно отмечают производительность таких моделей при различных размерах параметров. Однако повышение производительности при использовании предобучения не обязательно приводит к улучшению качества на последующих этапах [15][16].
Почему это важно
Исследования показали, что предобученные модели хорошо обобщаются при решении новых задач для определенного домена или модальности. Эти модели демонстрируют устойчивое поведение при обучении с использованием малого количества примеров (в парадигме few-shot) и устойчивость при обучении. В качестве таковых они являются ценным «строительным блоком» для получения новых научных результатов и создания областей практического применения.
Перспективы
В будущем, несомненно, будет разработано еще больше предобученных моделей, причем, еще более масштабных. В то же время следует ожидать, что отдельные модели будут одновременно выполнять больше задач. Это явление уже имеет место в обработке естественного языка, в которых модели способны выполнять множество задач путем представления их в обычном формате text-to-text. Нечто подобное мы, вероятно, увидим у моделей изображений и речевых моделей, каждая из которых сможет одновременно выполнять большое количество типовых задач. И, наконец, мы увидим и другие работы по обучению моделей для нескольких модальностей.
2) Массовое многозадачное обучение

Массовое многозадачное обучение с использованием модели ExT5. В процессе предобучения модель обучается на входной информации (слева) из разнообразного набора различных задач в формате text-to-text с целью получения соответствующей выходной информации (справа). В состав указанных задач входят: заполнение маскированных слов, автоматическое реферирование, семантический парсинг, ответы на вопросы в режиме closed-book, передача стиля, моделирование диалогов, определение логической связи между текстами, разрешение кореферентности в стиле схемы Винограда (сверху вниз) и проч. (Aribandi et al., 2021).
Основные результаты
Большинство предобученных моделей из предыдущего раздела относится к категории моделей с самообучением (self-supervised). В общем случае эти модели обучаются на больших объемах неразмеченных данных в рамках некоторых типов задач, где не требуется наличие явного учителя. Однако для многих доменов уже доступны большие объемы размеченных данных, которые можно использовать для получения более качественных текстовых представлений. Сейчас есть целый пласт многозадачных моделей: T0 [17], FLAN [18] и ExT5 [19] ― предобученых для решения примерно 100 задач, преимущественно языковых. Такое массовое многозадачное обучение тесно связано с понятием мета-обучения (meta-learning). Имея доступ к набору разнообразных задач [20], модели способны научиться обучаться более вдумчивой обработке входящей информации, что позволяет осуществлять обучение в контексте (in-context learning) [21].
Почему это важно
Массовое многозадачное обучение возможно благодаря тому, что многие недавно появившиеся модели, как T5 и GPT-3, применяются в формате text-to-text. Таким образом, для эффективного обучения нескольким задачам моделям больше не требуются разработанные вручную функции потерь или слои для конкретных задач. Подобные недавно появившиеся подходы подчёркивают преимущества сочетания предварительного обучения без учителя с многозадачным обучением с учителем и демонстрируют, что это сочетание приводит нас к моделям более общего характера.
Перспективы
Учитывая доступность и открытый характер кода датасетов в унифицированном формате, мы можем представить себе эффективный цикл, в котором вновь созданные высококачественные датасеты используются для обучения более мощных моделей на все более разнообразных коллекциях задач, которые в перспективе можно использовать в цикле для создания еще более многообещающих датасетов.
3) За пределами трансформера
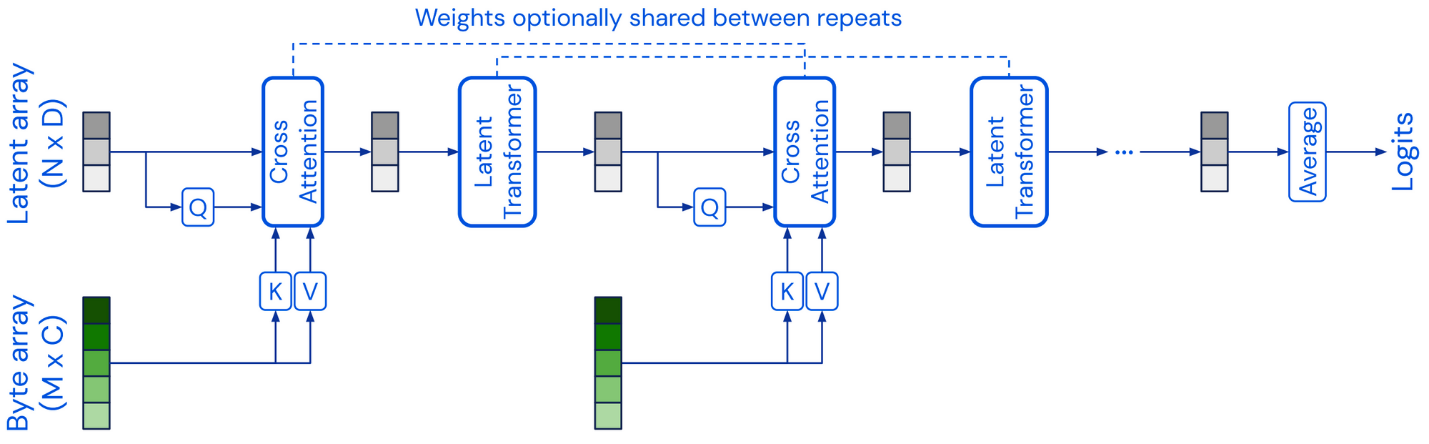
Perceiver проецирует входной байтовый массив высокой размерности посредством перекрестного внимания (cross-attention) на скрытый массив фиксированной размерности, который он обрабатывает с помощью блока внутреннего внимания (self-attention) трансформера. Затем попеременно применяются блоки перекрестного внимания и внутреннего внимания (Jaegle et al., 2021).
Основные результаты
Большинство предварительно обученных моделей, рассмотренных в предыдущих разделах, основано на архитектуре трансформера (Transformer) [22]. К 2021 году на основе такой архитектуры были разработаны жизнеспособные альтернативные архитектуры. Perceiver [23] – это подобная трансформеру архитектура, которая масштабируется до входных данных очень высокой размерности путем использования скрытого массива фиксированной размерности в качестве своего базового представления и адаптации его на входе посредством перекрестного внимания. Perceiver IO [24] – это дальнейшее расширение архитектуры Perceiver, позволяющее также иметь дело со структурированными выходными пространствами. В других исследованиях пытались уйти от вездесущего слоя внутреннего внимания, прежде всего с использованием многослойных перцептронов (MLP), таких, как MLP-Mixer [25] и gMLP [26]. Также и FNet [27] в качестве альтернативы внутреннему вниманию использует одномерные преобразования Фурье для смешивания информации на уровне токенов. Хочется отметить, как важно в общем случае абстрагироваться от связи архитектуры трансформера с парадигмой предобучения. Если CNN-сети предварительно обучены как и модели-трансформеры, то они достигают конкурентоспособной производительности во многих задачах обработки естественного языка [28]. Использование альтернативных задач для предобучения (см. предобучение в стиле ELECTRA [29]) может привести к увеличению качества результатов [30].
Почему это важно
Исследования развиваются путем одновременного задействования множества дополнительных или ортогональных направлений. Если большинство исследований будет сосредоточено на единственной архитектуре, результатом этого неизбежно станут смещение, слепые пятна и упущенные возможности. Новые модели могут устранить некоторые ограничения трансформеров, например, высокая вычислительная сложность, сходство с «черным ящиком» и независимость от порядка последовательности. Например, нейронные расширения обобщенных аддитивных моделей предлагают гораздо лучшую интерпретируемость по сравнению с нынешними моделями [31].
Перспективы
Весьма вероятно, что для многих задач в качестве базового стандарта по-прежнему будут использоваться предобученные трансформеры. Однако следует ожидать появления и альтернативных архитектур, особенно в ситуациях, когда нынешние модели терпят неудачу, например, при моделировании долгосрочных зависимостей и многомерных входящих данных, или в ситуациях, когда требуется интерпретируемость.
4) Затравочное программирование

Шаблоны затравок из коллекции затравок P3. Для каждой задачи возможно использование нескольких шаблонов. Каждый шаблон состоит из входного паттерна и целевого вербализатора. Для задачи перефразирования (paraphrasing), Choices состоит из {Not duplicates, Duplicates} (Не дубликаты, дубликаты) и {Yes, No} (Да, нет} в первом и втором шаблоне соответственно (Sanh et al., 2021).
Основные результаты
Ставшие популярными благодаря модели GPT-3 [32], затравки стали жизнеспособным альтернативным входным форматом для моделей при обработке естественного языка. Затравка обычно включает в себя паттерн (pattern), который просит модель сделать определенный прогноз, и вербализатор (verbalizer), который преобразует этот прогноз в метку класса. В некоторых подходах, таких, как PET [33], iPET [34] и AdaPET [35], затравки используются для обучения в парадигме few-shot. Однако затравки не являются универсальным решением. Качество работы моделей сильно различается в зависимости от выбора затравки, а для поиска лучшей затравки по-прежнему требуются размеченные примеры [36]. Для надежного сравнения моделей в ситуациях с few-shot были разработаны новые процедуры валидации [37]. Большое количество затравок доступно на ресурсе public pool of prompts (P3) (публичный пул затравок), упрощающем развитие исследований в области использования затравок. В этом исследовании [38] приведен прекрасный обзор методов затравочного программирования для обработки естественного языка.
Почему это важно
Затравку можно использовать для кодирования специфической информации конкретной задачи; в зависимости от задачи затравка может дать результат лучше, чем 3500 размеченных примеров [39]. Другими словами, затравки делают возможным новый способ включения экспертной информации в процесс обучения модели, помимо размеченных вручную примеров или определения функций разметки [40].
Перспективы
Я лишь поверхностно коснулся вопроса использования затравок для улучшения обучения модели. Со временем затравки станут более совершенными, например, они могут включать более длинные инструкции [18:1], положительные и отрицательные примеры [41], а также общие эвристики. Затравки также могут оказаться более понятным способом включения объяснений на естественном языке [42] в процесс обучения модели.
5) Эффективные методы
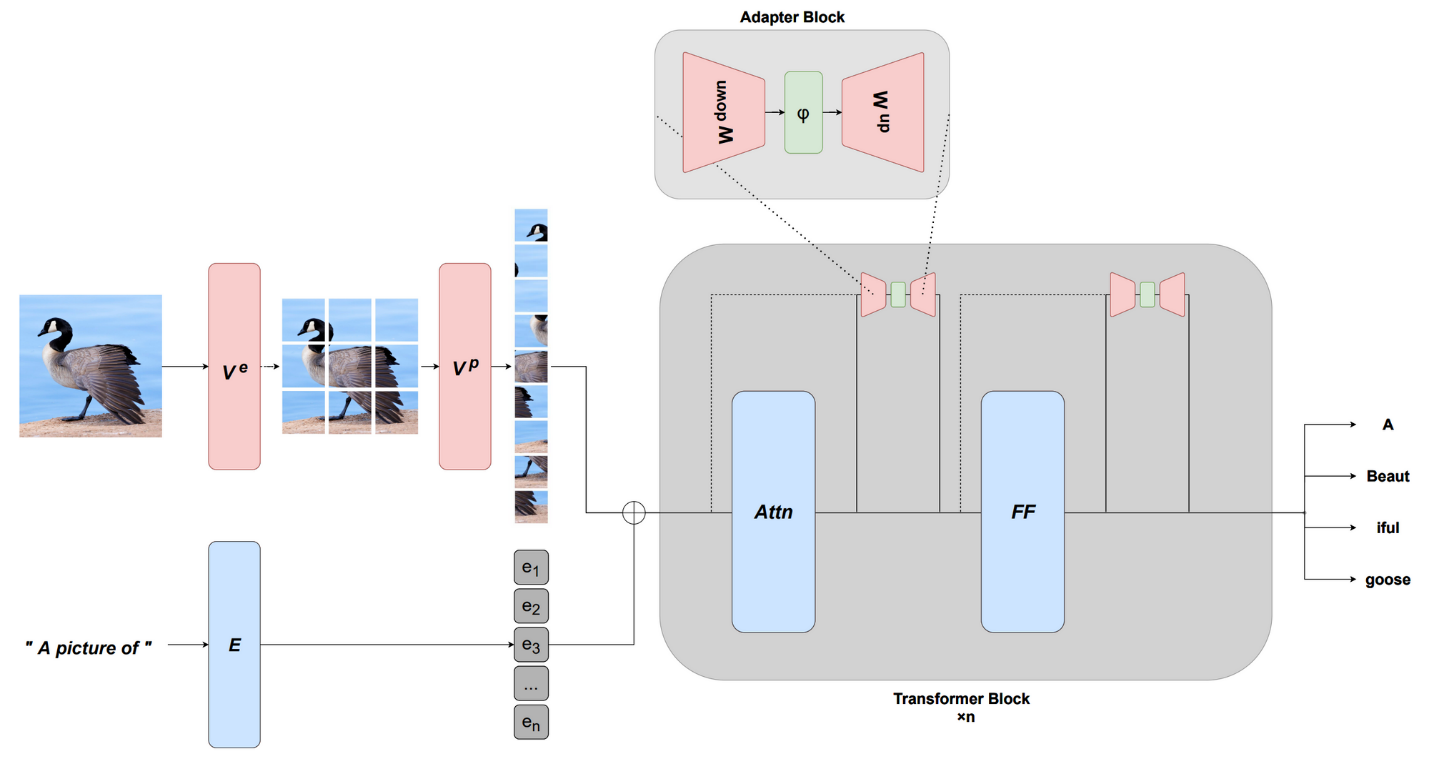
Мультимодальная адаптация по методике MAGMA. Предобученная языковая модель с замороженными весами адаптируется к мультимодальным задачам с помощью визуального префикса, изученного с помощью кодировщика изображений, а также слоев адаптера, специфичных для компьютерного зрения (Eichenberg et al., 2021).
Основные результаты
Оборотная сторона применения предобученных моделей заключается в том, что в общем случае эти модели очень велики и зачастую недостаточно эффективны для использования на практике. 2021 год принес достижения в двух областях: появились более эффективные архитектуры и методы файн-тюнинга. Что касается моделирования, то в 2021 году мы увидели несколько более эффективных версий внутреннего внимания [43][44]. В этой работе [45] представлен обзор моделей, созданных до 2021 года. Современные предобученные модели настолько мощны, что их можно эффективно настроить путем обновления лишь нескольких параметров. Это привело к разработке более эффективных подходов к файн-тюнингу на основе непрерывных затравок [46][47], адаптеров [48][49][50] и т.д. Кроме того, данная возможность позволяет адаптироваться к новым модальностям путем изучения соответствующего префикса [51] или подходящих преобразований [52][53]. Также были использованы методы квантования (для создания более эффективных оптимизаторов [54]) и разреженность.
Почему это важно
Модели бесполезны, если они непрактичны или их слишком дорого запускать на стандартных аппаратных средствах. Повышение эффективности гарантирует, что по мере увеличения размеров моделей они останутся полезными и доступными для практического использования.
Перспективы
Эффективные модели и методы обучения должны стать проще в использовании и доступнее. Одновременно с этим «сообщество» будет разрабатывать более эффективные способы взаимодействия с большими моделями и их успешной адаптации, комбинирования или изменения без необходимости предварительного обучения новой модели с нуля.
6) Бенчмаркинг

Увеличение концентрации использования датасетов по учреждениям и по датасетам с течением времени. Карта использования датасетов по учреждениям (слева). Более 50% использования датасетов приходится на датасеты, исходящие из 12 учреждений. Концентрация использования датасетов по учреждениям и по конкретным датасетам, измеряемая коэффициентом Gini, увеличилась в последние годы (справа) (Koch et al., 2021).
Основные результаты
Быстро совершенствующиеся возможности недавно созданных моделей в сфере машинного обучения и обработки естественного языка превзошли возможности многих бенчмарков для измерения их показателей. В то же время сообщества при оценивании моделей используют все меньше и меньше бенчмарков, источником которых является небольшое количество элитных учреждений [55]. Соответственно, в 2021 году состоялось множество дискуссий о типовых методиках и способах, посредством которых мы смогли бы надежно оценивать развитие таких моделей. Подробно эта тема рассмотрена в блоге автора. В 2021 году появились весьма перспективные концепции в сфере обработки естественного языка: динамическая состязательная оценка [56], оценка управляемая сообществом (члены сообщества совместно создают оценочные датасеты, такие, как BIG-bench), интерактивная детальная оценка различных типов ошибок [57] и многомерная оценка, которая выходит за рамки оценки моделей по одной метрике производительности [58]. Помимо прочего, были предложены новые бенчмарки для таких значимых областей, как оценка для few-shot задач [59][60] и междоменная генерализация [61]. Мы также увидели новые бенчмарки, ориентированные на оценку предобученных моделей общего назначения для определенных модальностей. Например, речь [62], конкретные языки (индонезийский и румынский [63][64]), а также для нескольких модальностей [65] и многоязычных сред [66]. Нам стоит уделять больше внимания оценочным метрикам. Метаоценка машинного перевода [67] показала, что среди 769 статей по машинному переводу за последнее десятилетие 74,3% из них использовали только метрику BLEU, несмотря на то, что было предложено 108 альтернативных метрик — зачастую лучше коррелирующих с оценками людей. Соответственно, в новых разработках, таких, как GEM [68] и двумерные лидерборды [69], предлагается оценивать модели совместно с методами.
Почему это важно
Бенчмаркинг и оценивание — основа научного прогресса в машинном обучении и в обработке естественного языка. Без точных и надежных бенчмарков невозможно понять, добиваемся ли мы реального прогресса или имеет место переобучение с использованием укоренившихся датасетов и метрик.
Перспективы
Повышение осведомленности о проблемах с бенчмаркингом должно привести к более продуманному дизайну новых датасетов. Кроме того, оценивание новых моделей должно меньше фокусироваться на одной метрике производительности, а учитывать сразу несколько характеристик модели: объективность, эффективность и устойчивость.
7) Генерация изображений по условию

Как CLIP генерирует произведение искусства. Генеративная модель создает изображение на основе вектора в латентном пространстве. После этого вектора в латентном пространстве обновляется на основе подобия встраиваний CLIP в сгенерированном изображении и текстового описания. Этот процесс повторяется вплоть до достижения сходимости (Благодарность: Charlie Snell).
Основные результаты
Генерация изображений по условию, т. е. генерация изображений на основе текстового описания, дала впечатляющие результаты в 2021 году. Целая сцена искусств возникла с помощью генеративных моделей новейшего поколения (для получения более подробной информации прочтите этот пост в блоге). Вместо создания изображения непосредственно на основе ввода текста, как в модели DALL-E [70], последние подходы управляют выводом мощной генеративной модели, такой, как VQ-GAN [71], с использованием модели совместных эмбеддингов модальностей изображения и текста, такой, как CLIP [72]. Диффузные модели на основе правдоподобия, которые последовательно удаляют шум из сигнала, превратились в новые мощные генеративные модели, способные превзойти GANs [73]. Посредством управления выходными данными на основе введенного текста новейшие модели приближаются к фотореалистичному качеству изображения [74]. Кроме того, такие модели также особенно хороши при отрисовке и могут изменять области изображения на основе описания.
Почему это важно
Автоматическое создание высококачественных изображений, которыми могут управлять пользователи, открывает широкий спектр художественных и коммерческих приложений, от автоматического проектирования визуальных ресурсов до прототипирования и дизайна с помощью моделей, персонализации и т. д.
Перспективы
Сэмплирование из недавно созданных диффузных моделей выполняется намного медленнее, чем из их аналогов на основе GAN. Эти модели нуждаются в повышении эффективности, чтобы стать полезными для практического применения. Кроме того, эта область требует дополнительных исследований взаимодействия человека с потенциальным интерфейсом таких моделей с целью выявления наилучших способов такого взаимодействия и областей применения, в которых такие модели могли бы помогать людям.
8) Машинное обучение в науке

Архитектура модели AlphaFold 2.0. Модель учитывает эволюционно связанные последовательности белков, а также пары аминокислотных остатков, и итеративно передает информацию между обоими представлениями. (Благодарность: DeepMind).
Основные результаты
В 2021 году произошло несколько прорывов в области машинного обучения для развития естественных наук. В метеорологии достижения в краткосрочном и долгосрочном прогнозировании [75][76] существенно повысили свою точность. В обоих случаях эти модели превзошли самые современные модели прогнозов на основе физических законов. В биологии с помощью модели AlphaFold 2.0 удалось с беспрецедентной точностью предсказывать структуру белков, причем, даже в тех случаях, когда не было известно о каких-либо подобных структурах [14:1]. В математике машинное обучение продемонстрировало способность руководить интуицией математиков с целью выявления новых связей и алгоритмов [77]. Кроме того, модели-трансформеры при обучении на достаточном количестве данных доказали свои способности к изучению математических свойств дифференциальных систем, таких, как локальная устойчивость [78].
Почему это важно
Использование машинного обучения для улучшения нашего понимания и для применения в естественных науках является одной из наиболее эффективных областей его применения. Использование мощных методов машинного обучения позволяет создавать новые приложения и значительно ускорить существующие, например, разработку лекарств.
Перспективы
Особенно привлекательным направлением является использование моделей в цикле для содействия исследователям в совершении открытий и в создании инноваций. Для этого требуется как создание мощных моделей, так и работа в области интерактивного машинного обучения и взаимодействия человека с компьютером.
9) Синтез программ
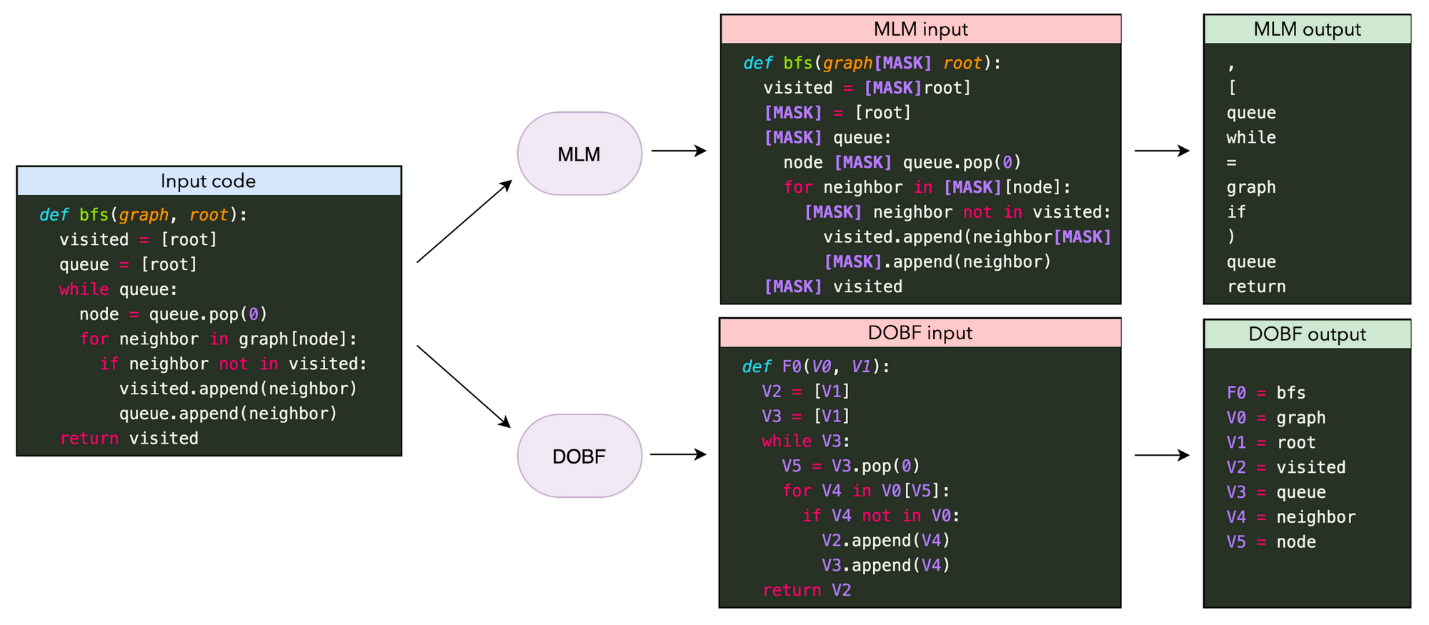
Сравнение моделей MLM (masked language modeling ) и DOBF (deobfuscation) при генерации программного кода. MLM предсказывает замаскированные случайным образом токены, которые относятся преимущественно к синтаксису языка программирования. Модель DOBF требует деобфускации имен функций и переменных, что является гораздо более сложной задачей (Roziere et al., 2021).
Основные результаты
В этом году одним из наиболее примечательных областей применения больших языковых моделей оказалась модель для генерации программного кода Codex [79], которая впервые была интегрирована в значимый продукт как часть GitHub Copilot. Другие достижения в категории предобученных моделей охватили диапазон от улучшения целей предобучения [80][81] до экспериментов в области масштабирования [82][83]. Тем не менее, генерация сложных и длинных программ по-прежнему является трудной задачей для современных моделей. Интересным родственным направлением является обучение исполнению или моделированию программ, которое можно улучшить путем выполнения многошаговых вычислений, когда промежуточные этапы вычислений записываются в т.н. «электронный блокнот» (scratchpad) [84].
Почему это важно
Возможность автоматического синтеза сложных программ полезна в самых разных областях применения, например, для поддержки инженеров-программистов.
Перспективы
По-прежнему остается открытым вопрос: до какой степени модели для генерации программного кода улучшают реальный трудовой процесс инженеров-программистов [85]. Чтобы быть действительно полезными, такие модели? как и диалоговые модели – должны быть способны обновлять свои прогнозы на основе новой информации, а также учитывать локальный и глобальный контекст.
10) Смещения

Непреднамеренные побочные эффекты автоматического смягчения токсичности. Чрезмерная фильтрация текста о маргинализированных группах ослабляет способность языковых моделей создавать тексты об этих группах (даже позитивные) (Welbl et al., 2021).
Основные результаты
С учетом потенциального влияния предобученных моделей большого размера, крайне важно, чтобы они не содержали опасных смещений (bias) и не использовались некорректно для создания вредоносного контента, а, наоборот, использовались лишь надлежащим образом. Потенциальные риски таких моделей рассматриваются в нескольких обзорах [1:1][86][87]. Смещения моделей исследовалась в отношении таких чувствительных атрибутов, как пол, принадлежность к определенным этническим группам и политические взгляды [88][89]. Однако устранение смещений из моделей, например, «токсичности», сопряжено с компромиссами и может привести к сужению охвата текстов о маргинализированных группах и авторов таких текстов [90].
Почему это важно
Чтобы модели можно было бы использовать в реальных приложениях, они не должны демонстрировать каких-либо вредных предубеждений и дискриминировать какие-либо группы. Таким образом, улучшение понимания смещений современных моделей и способов их устранения имеет решающее значение для обеспечения безопасного и ответственного развертывания моделей машинного обучения.
Перспективы
До настоящего времени смещения изучались преимущественно на английском языке и в предобученных моделях, а также применительно к конкретным приложениям для генерации/классификации текста. Кроме того, исходя из предполагаемого использования и жизненного цикла таких моделей, нам следует выявлять и смягчать смещения в многоязычной среде, применительно к сочетанию различных модальностей и на разных этапах использования предобученной модели — после предварительного обучения, после файн-тюнинга и во время тестирования.
11) Дополнение модели возможностью извлечения данных

Обзор архитектуры RETRO. Входная последовательность разбивается на несколько фрагментов (слева). Для каждого входного фрагмента ближайшие соседние фрагменты извлекаются с помощью приблизительного поиска ближайшего соседа на основе близости эмбеддингов BERT. Модель работает с ближайшими соседями, используя перекрестное внимание для фрагментов (справа), чередующееся со стандартными слоями трансформера (Borgeaud et al., 2021).
Основные результаты
Языковые модели, дополненные возможностью извлечения данных (retrieval), которые интегрируют эту возможность в предобучение и последующее использование, уже фигурировали в Обзоре результатов за 2020 год. В 2021 году корпус данных для извлечения был масштабирован до триллиона токенов [91], а модели получили возможность запрашивать в интернете ответы на вопросы [92][93]. Мы также увидели новые способы интеграции извлечения в предобученные языковые модели [94][95].
Почему это важно
Дополнение моделей возможностью извлечения информации делает эти их гораздо более эффективными с точки зрения параметров – такие модели могут хранить меньше знаний в своих параметрах, поскольку вместо этого они способны извлечь эти знания. Кроме того, это обеспечивает эффективную адаптацию домена посредством простого обновления данных, используемых для извлечения [96].
Перспективы
Мы можем увидеть различные формы извлечения для задействования различных видов информации (знания, основанные на здравом смысле, фактические отношения, лингвистическая информация и т. д.). Кроме того, дополнение модели возможностью извлечения данных можно сочетать с более структурированными формами извлечения знаний, такими, как методы из наполнения баз знаний и с добычей открытой информации.
12) Модели без токенов

Подслова формируются на основе смежных последовательностей n-gram (a), которые оцениваются с помощью отдельной оценочной сети. Затем оценки блоков реплицируются на их первоначальных позициях (b). И, наконец, в каждой позиции подслова суммируются и взвешиваются на основе оценок их блоков с целью формирования скрытых подслов (Tay et al., 2021).
Основные результаты
В 2021 году появились новые модели без токенов, которые напрямую используют последовательность символов [97][98][99]. Было продемонстрировано, что эти модели превосходят по производительности многоязычные модели и особенно хорошо работают с нестандартным языком. Другими словами, эти модели являются многообещающей альтернативой укоренившимся моделям преобразования на основе подслов (данная тема подробно рассмотрена в этом информационном бюллетене под кодовым названием Char Wars).
Почему это важно
Начиная с предобученных языковых моделей, таких, как BERT, стандартным входным форматом при обработке естественного языка стал токенизированный текст, состоящий из подслов. Однако было показано, что токенизация на подслова плохо работает при зашумленном вводе (опечатки, орфографические вариации, распространенные в социальных сетях, определенные типы морфологии и т.д.). Кроме того, это порождает зависимость от токенизации, которая способна привести к несоответствиям при адаптации модели к новым данным.
Перспективы
Благодаря своей повышенной гибкости модели без токенов хорошо подходят для моделирования морфологии и могут лучше обобщать новые слова и языковые изменения. Однако до сих пор неясно, насколько результативно – в сравнении с методами на основе подслов – эти модели работают с различными типами морфологических процессов/процессов словообразования и на какие компромиссы они идут.
13) Адаптация временных рамок

Различные стратегии обучения для адаптации временных рамок при использовании модели T5. Стандартная модель (слева) обучается с использованием всех данных без явной информации о времени. Годовая модель (в центре) – для каждого года обучается отдельная модель. Временная модель (справа) – к каждому примеру добавляется префикс времени (Dhingra et al., 2021).
Основные результаты
Модели могут содержать множество смещений (bias), порожденных данными, которые использовались для обучения этих моделей. Одно из таких смещений, которое в 2021 году привлекло к себе большое внимание, относится к временным рамкам данных, с использованием которых обучались модели. С учетом того, что язык постоянно развивается, а дискурс включает в себя все новые термины, было показано, что модели, обученные на устаревших данных, сравнительно плохо генерализуются [100]. Однако полезность адаптации временных рамок может зависеть от последующей задачи. Например, эта адаптация может оказаться менее полезной для задачи, в которой вызванные событиями изменения в использовании языка не влияют на выполнение этой задачи [101].
Почему это важно
Адаптация временных рамок особенно важна для получения ответов на вопросы в тех случаях, когда ответы могут меняться в зависимости от того, в какой момент времени этот вопрос был задан [102][103].
Перспективы
Разработка методов, способных адаптироваться к новым временным рамкам, требует отказа от статической организации предварительного обучения и точной настройки, а также применения эффективных способов обновления знаний в предварительно обученных моделях. В этой связи полезны такие опции, как Эффективные методы и Дополнение модели возможностью извлечения данных. Кроме того, необходимо разработать модели, у которых входные данные не «существуют в вакууме», а основаны на внеязыковом контексте и на реальном мире. Для ознакомления с другими работами по этой тематике автор также советует обратиться к семинарам EvoNLP на конференции EMNLP 2022.
14) Важность данных

Пример из MaRVL, связанный с концепцией leso («носовой платок» на суахили). Требуется, чтобы модели определили, является ли описание в надписи на картинке истинным или ложным. Надпись (на суахили): Picha moja ina watu kadhaa waliovaa leso na picha nyingine ina leso bila watu. («На одном изображении имеется несколько человек, носящих носовые платки, а на другом изображении присутствует носовой платок без человека»). Оба описания в этом утверждении являются ложными (Liu et al., 2021).
Основные результаты
Данные, без сомнения, являются критически важным компонентом машинного обучения, однако обычно они находятся в тени достижений в области моделирования. Тем не менее, с учетом важности данных для масштабирования моделей, внимание постепенно перемещается с подходов, ориентированных на модели, на подходы, ориентированные на данные. Важные темы в этой области: как эффективно создавать и обслуживать новые датасеты и как гарантировать качество данных (см. Семинар по искусственному интеллекту, ориентированному на данные на конференции NeurIPS 2021.). В частности, в этом году тщательному анализу были подвергнуты крупномасштабные датасеты, которые используются предобученными моделями, в том числе мультимодальные датасеты [104], а также корпуса английских и многоязычных текстов [105][106]. Такой анализ помогает проектировать более репрезентативные ресурсы, такие, как MaRVL [107], для мультимодального вынесения суждений (multi-modal reasoning).
Почему это важно
Данные критически важны для обучения крупномасштабных моделей машинного обучения и являются для них ключевым источником новой информации. По мере масштабирования моделей все более сложной задачей становится гарантирование качества данных.
Перспективы
В настоящее время нам не хватает проверенных инструкций и принципиальных методов для эффективного создания датасетов в интересах различных задач, для надежного гарантирования качества данных и т. д. Кроме того, по-прежнему мало понятно, как данные взаимодействуют с процессом обучения модели и как данные влияют на смещение модели. Например, фильтрация обучающих данных может негативно сказаться на охвате языковой моделью маргинализированных групп [90:1].
15) Мета-обучение

Обучение и тестирование универсальной шаблонной модели. Модель, состоящая из совместно используемых сверточных весов и специфичных для конкретного датасета слоев FiLM, обучается в многозадачной среде (слева). Значения параметров FiLM для эпизода тестирования инициализируются на основе выпуклой комбинации обученных наборов параметров FiLM, полученных с помощью тренировочных данных (справа). После этого они обновляются с использованием градиентного спуска на опорном наборе данных с классификатором ближайшего центроида в качестве выходного слоя (Triantafillou et al., 2021).
Основные результаты
Несмотря на то, что мета-обучение (meta-learning) и трансферное обучение (transfer learning) имеют общую цель – обучение в парадигме few-shot – развитие этих дисциплин осуществлялось преимущественно разными сообществами. Согласно результатам применения нового бенчмарка [108], крупномасштабные методы трансферного обучения превосходят методы на основе мета-обучения. Перспективным направлением является масштабирование методов мета-обучения, что в сочетании с методами обучения с эффективным использованием памяти (memory-efficient training) позволит повысить производительность моделей мета-обучения в реалистичных бенчмарках [109]. Кроме того, методы мета-обучения можно сочетать с методами эффективной адаптации (efficient adaptation method), такими, как слои FiLM [110], чтобы эффективно адаптировать модель общего назначения к новым датасетам [111].
Почему это важно
Мета-обучение – это важная концепция, правда пока она не продемонстрировала высоких результатов в стандартных бенчмарках (которые были разработаны без учета систем мета-обучения). Сближение сообществ мета-обучения и трансферного обучения может породить более практичные методы мета-обучения, которые будут полезны в реальных областях применения.
Перспективы
Мета-обучение может оказаться особенно полезным в сочетании с большим количеством естественных задач, доступных для применения в рамках такой опции, как Массовое многозадачное обучение. Мета-обучение также может улучшить процесс затравочного программирования, научив его проектировать новые затравки или задействовать затравки из большого количества доступных затравок.
Несколько слов от себя
Несмотря на то, что данный обзор и так задает кучу направлений для дальнейшего изучения читателем, хочется добавить некоторые значимые, на мой взгляд, вещи последнего времени.
В первую очередь, те, о которых удалось послушать на конференции OpenTalks.ai, которую нам с коллегами из Центра компетенции больших данных и искусственного интеллекта ЛАНИТ удалось посетить в феврале 2022 года в Москве. Основные моменты будут сконцентрированы как и переводимом обзоре в сторону NLP, но укажу на некоторые также интересные мне моменты.
В первую очередь, хочется отметить отличный обзорный доклад Григория Сапунова по основным NLP-трендам и выделить те, которые в переведенной статье отсутствуют: OpenAI эмбеддинги или Embeddings as a Service. Действительно, сложно не согласиться с тем, что парадигма трансферного обучения на основе предобученных моделей глубоко засела в нашу жизнь и является сейчас основным инструментом во многих задачах. Но совершенно новый уровень этому явлению задала OpenAI, организовав платный сервис для получения эмбеддингов текста.
Textless NLP - продуцирование речи в ответ на речь без перевода всего этого безобразия в текст. Например, в области машинного перевода: ссылка.
Я считаю, что будет нелишним также рассказать и о канале, в котором он (Григорий Сапунов) и другие неглупые люди, разбирают статьи, избавляя нас от этой тяжкой, хотя иногда и приятной работы: ссылка на ТГ-канал.
Благодаря выступлениям Татьяны Шавриной и Давида Дале мы узнали, что в 2021 году появились новые русскоязычные адаптации зарубежных моделей (например, ruDALL-E, ruCLIP, rubert-tiny и rubert-tiny2), так и что-то свое (например, ruDOLPH). Наши российские коллеги также сильно озабочены проблемой бенчмаркинга и вовсю работают над ней для русского языка.
Проблема бенчмаркинга презентовалась и коллегами из Департамента здравоохранения Москвы. Предлагался целый пайплайн формирования датасета, начиная от постановки задачи, за которым уже следует формирование датасетов и апробация на нем алгоритмов машинного обучения. Применение машинного обучения в здравоохранении действительно требует большого контроля, правильно собранных наборов данных для обучения, хорошо продуманной оценки качества для каждой конкретной постановки.
Наконец, хочется отметить отдельный трек докладов, касавшихся железа. Во-первых, обзорный доклад Олега Сиротюка относительно импортозамещения всей инфраструктуры, лежащей в основе построения умных систем: чипов (аналоги GPU/CPU), операционных систем, ПО их поддерживающих (аналоги CUDA), фреймворков глубокого обучения (аналогов pytorch и tensorflow).
Во-вторых, обзорный доклад Дмитрия Ватолина об аппаратных ускорителях: выясняется, что модно сейчас разрабатывать чипы (помимо китайских компаний такие направления появляются в Amazon, Apple, Microsoft и Tesla). И здесь также появляются бенчмарки, чтобы иметь возможность эффективно сравнивать чипы разных компаний по производительности. Напрашивается термин benchmark-driven AI development (по аналогии с test-driven development).
Помимо услышанного на конференции, хочется добавить некоторые моменты и от себя.
Еще раз отметить всепоглощающее проникновение трансформеров во все области машинного обучения:
в рекомендательные системы, что в том числе вылилось в библиотеку Transformers4Rec (спасибо Андрею Кузнецову из Одноклассников, которые на Citymobil Data митапе про нее рассказал);
в обычные табличные задачки, что нашло отражение в недавнем посте Uber.
Отметить некоторые попытки обучения с подкреплением уйти от игровой зависимости и наконец-то начать приносить пользу:
MuZero вдруг перестал играть в Го, а стал сжимать видео YouTube;
тот же DeepMind еще и смог применить RL для управления плазмой в токамаке, что еще и в некоторой степени продвигает исследования в области термоядерного синтеза.
Также на конференции выступил наш коллега Дмитрий Степанов, технический директор компании «Системы компьютерного зрения» (входит в группу ЛАНИТ). В рамках демо-дня акселератора TEX Online была представлена система Smart Timber, использующая глубокие нейросети на мобильных устройствах для автоматизации измерения объёма брёвен в лесовозах и штабелях. В техническом плане интерес представляет проведенный анализ различных архитектур и выбор достаточно новых YOLOX и YOLOR как обеспечивающих наилучшие показатели с учетом ограничений по вычислительным ресурсам и времени работы (до 10 секунд). В рамках акселератора проект получил второе место, обойдя все другие решения, основанные на анализе данных, нейронных сетях и AI в целом.

