Было бы здорово иногда иметь под рукой программку, которая в наше отсутствие умеет записывать звук со встроенного микрофона нашего ноутбука и передавать его по сети на другой наш комьютер. А тот, в свою очередь, этот звук умел бы воспроизводить в режиме реального времени. Давай попробуем самостоятельно написать такую программу, тем более что это, как оказывается, не так уж и сложно.
Содержание:
Описание
Алгоритм записи и воспроизведения звука
Устанавливаем необходимые библиотеки
Пишем сервер: запись звука
Шаг 1. Получаем удобный интерфейс для работы с аудио-подсистемой
Шаг 2. Создаём буфер и привязываем его к аудио устройству
Шаг 3. Читаем аудио поток из звукового буфера
Представление звуковых данных
Шаг 4. Закрываем аудио буфер и звуковую подсистему
Билдим сервер
Пишем клиент
Сетевое взаимодействие
Сервер
Клиент
Проверяем, что получилось
Доработать напильником
Итоги
Описание
Что мы в итоге хотим получить и какой алгоритм работы реализовать:
Сервер, который запускается на той машине, пространство вокруг которой мы хотим прослушивать. Он тихо ждёт, пока к нему не подключится клиент. Затем он открывает устройство записи звука, настроенное по умолчанию в системе, и начинает передавать аудио поток на машину клиента. При отключении клиента от сервера, звуковое устройство закрывается, чтобы не тратить ресурсы зря.
Клиент, который подключается к серверу и начинает принимать аудио поток и воспроизводить его в режиме реального времени. Для того, чтобы клиент мог правильно (в нужном формате) открыть устройство воспроизведения звука, он получает нужную мета информацию от сервера в Hello сообщении.
Единственное, что нужно иметь в виду - это то, что не все устройства поддерживают одинаковые конфигурации звука. В теории, может оказаться так, что сервер открыл устройство в каком-то формате, а звуковое устройство на машине клиента просто напросто не поддерживает такой формат. В таком случае нужно использовать алгоритмы конвертации звукового потока, но эта информация не входит в данную статью.
Какие аудио-подсистемы будет поддерживать наша программа:
ALSA (Linux)
CoreAudio (macOS)
DirectSound (Windows)
OSS (FreeBSD)
PulseAudio (Linux)
WASAPI (Windows)
Сервер и клиент будут кросс-платформенными и поддерживать Windows, Linux, FreeBSD и macOS. И само собой разумеется, что например сервер может работать на Windows, а клиентом к нему будет программа под Linux, или как угодно иначе.
Какие пакеты для Линукса понадобятся (на примере Fedora):
libalsa-devel (для ALSA)
libpulse-devel (для PulseAudio)
Для остальных ОС дополнительно ничего устанавливать не надо.
Алгоритм записи и воспроизведения звука
Прежде чем мы приступим к кодингу, я кратко расскажу в чём принцип работы со звуковой подсистемой.
Первым шагом нужно выбрать звуковое устройство. В системе может быть зарегистрировано несколько устройств. Они делятся на 2 типа: устройства записи и воспроизведения. В самом простом варианте на любом ноутбуке будет одно устройство для записи - встроенный микрофон, и одно для воспроизведения - встроенные колонки, они же будут являться устройствами по умолчанию. Любая программа может определить через звуковое API количество таких устройств, их свойства, в т.ч. иногда и список всех поддерживаемых этим устройством форматы звука. Однако в случае, когда нам нужно всего лишь использовать устройство по умолчанию, то мы можем пропустить этот шаг.
Далее, нужно открыть выбранное устройство для записи или воспроизведения, задав нужную конфигурацию. При этом происходит создание и привязка аудио буфера к этому устройству. Важнейшими характеристиками здесь является формат звука, а именно: ширина одного аудио сэмпла (как правило, 16 или 24 bit), частота сэмплов (например, 44100 или 48000 Hz) и количество каналов. Всегда нужно быть готовым к тому, что аудио-подсистема вернёт код ошибки, если устройство, которое мы пытаемся открыть, не поддерживает заданный формат. В таком случае нам нужно скорректировать нашу конфигурацию и попробовать снова. Бывает и так, что устройство в данный момент занято другим системным процессом. Так запросто может случиться, например, на Линуксе, если мы попытаемся открыть устройство напрямую через ALSA, в то время как оно же используется системным PulseAudio процессом.
Ещё одним важным параметром при открытии устройства является размер внутреннего аудио буфера. Чем меньше этот буфер, тем меньше задержка (latency), которая очень важна для некоторых приложений. Следует только помнить, что малый размер буфера увеличивает нагрузку на CPU, да и к тому же у каждого устройства есть свои внутренние ограничения на этот параметр. Как правило, размер буфера в 250мс или 500мс является достаточным для большинства приложений.
После того, как мы открыли устройство, мы можем начать работать с аудио потоком. Само собой, если это устройство звукозаписи, то мы читаем данные из него; если это устройство воспроизведения - мы пишем данные в него. Звуковой буфер - это как правило обычный кольцевой буфер, где запись и чтение бегут непрерывно по кругу.

Но здесь есть одна проблема: центральный процессор вечно хочет бежать вперёд, а звуковое устройство с данными работает равномерно. И здесь важно вовремя остановиться и ждать некоторое время, чтобы данные в кольцевом буфере не испортить. В режиме звукозаписи, если мы вычитали все имеющиеся данные, то мы должны ожидать, пока не будет доступен следующий кусок. А в режиме воспроизведения если буфер устройства заполнен на 100%, то мы должны ожидать, пока в нём не появится пустота.
В режиме воспроизведения есть ещё одна особенность - после того, как все имеющиеся данные успешно добавлены в звуковой буфер устройства, не правильно сразу закрывать используемое устройство, а нужно дождаться, пока оно не доиграет все имеющиеся данные. Для этого в буфер добавляется тишина нужной длины, и только теперь после одного оборота кольцевого буфера можно будет устройство закрывать.
Ну что же, слишком много теории - это скучно, поэтому давай приступим к практике.
Устанавливаем необходимые библиотеки
Скачиваем или клонируем с Гитхаба репозитории с библиотеками, которые нам понадобятся:
git clone https://github.com/stsaz/ffbase git clone https://github.com/stsaz/ffaudio git clone https://github.com/stsaz/ffos
Зачем они нужны:
ffbase - здесь хранится набор вспомогательных функций и базовых алгоритмов для C, без этого программировать на C очень уж не удобно
ffaudio - библиотека для работы со звуком
ffos - это чтобы нам удобно было писать кросс-платформенный код
Пишем сервер: запись звука
Шаг 1. Получаем удобный интерфейс для работы с аудио-подсистемой.
Т.к. мы используем кросс-платформенную библиотеку ffaudio, то нам здесь вообще не нужно думать ни о каких различиях между разными API. Мы пишем код один раз, и он работает одинаково в любой конфигурации. Для начала подключаем хэдер со всеми необходимыми интерфейсами и enum-ами:
#include <ffaudio/audio.h>
Затем берём интерфейс звуковой подсистемы. Как именно он настраивается я объясню ниже в разделе "Билдим сервер".
const ffaudio_interface *audio = ffaudio_default_interface();
Далее мы везде работаем с этим интерфейсом, он позволяет делать всё, о чём мы говорили выше. Но самое первое - инициализируем аудио подсистему с конфигурацией по умолчанию:
ffaudio_init_conf aiconf = {}; audio->init(&aiconf);
Для WASAPI эта функция инициализирует систему COM-объектов через CoInitializeEx(). Для PulseAudio она подключается к PA серверу и создаёт отдельный поток для обработки событий. А для ALSA, DirectSound, OSS и CoreAudio на самом деле нет необходимости в этой функции.
Шаг 2. Создаём буфер и привязываем его к аудио устройству.
ffaudio_buf *abuf = audio->alloc(); ffaudio_conf aconf = {}; aconf.format = FFAUDIO_F_INT16; aconf.sample_rate = 48000; aconf.channels = 2; int r = audio->open(abuf, &aconf, FFAUDIO_CAPTURE); if (r == FFAUDIO_EFORMAT) r = audio->open(abuf, &aconf, FFAUDIO_CAPTURE);
Вначале создаём объект аудио буфера через ffaudio_interface::alloc(). Можно иметь множество таких объектов одновременно, по-разному их настроить, привязать к разным звуковым устройствам. Единственное, что нужно помнить - не всегда можно привязать несколько буферов к одному и тому же устройству. Например, в ALSA и в WASAPI (в эксклюзивном режиме) сделать это точно не удастся.
Затем устанавливаем конфигурацию (структура ffaudio_conf) звукового буфера, где задаём формат 16bit, 48000Hz, стерео. В этой же структуре мы могли бы задать и идентификатор желаемого устройства, и желаемый размер буфера в миллисекундах, но можно и не задавать эти параметры - оставить всё по умолчанию.
Далее мы вызываем ffaudio_interface::open(), передавая ей на вход наш буфер, конфигурацию и флажки. Обрати внимание, что мы используем флаг FFAUDIO_CAPTURE - мы хотим открыть устройство звукозаписи. Внутри этой функции исполняется наиболее сложная логика по подготовке и настройке звукового устройства: каждое звуковое API требует знания некоторых нюансов, из-за чего, например для WASAPI, необходимо по меньшей мере 300 строк кода, чтобы все эти нюансы учесть (ты можешь разобраться в деталях, открыв код библиотеки ffaudio).
Функция open() возвращает код ошибки FFAUDIO_EFORMAT, в случае если не удалось открыть устройство в заданном нами формате. При этом она же сама находит наиболее близкий формат звука, которое звуковое устройство поддерживает, и обновляет объект конфигурации для нас. Теперь мы можем либо ещё раз скорректировать аудио формат, либо просто ещё раз вызвать эту функцию (что мы в нашем коде и делаем). Всегда необходимо проверять результаты всех вызовов на ошибки, и в случае чего прервать исполнение нашей программы и записать сообщение пользователю о том, что пошло не так. Для этого можно получить от аудио подсистемы более подробное описание ошибки через вызов ffaudio_interface::error(), передав ей наш объект аудио буфера:
const char *error = audio->error(abuf);
Шаг 3. Читаем аудио поток из звукового буфера
const void *buffer; int r = audio->read(abuf, &buffer);
Функция ffaudio_interface::read() возвращает нам указатель на внутренний буфер, где находятся аудио сэмплы в interleaved формате, а также количество байт в этом буфере, которое мы можем безопасно прочитать.
Представление звуковых данных
Interleaved формат - это когда в одной непрерывной области памяти друг за другом идут значения сэмплов для каждого канала. Для стерео потока 16bit схематически это выглядит вот так:
short[0][L] short[0][R] short[1][L] short[1][R] ...
где индексы 0 и 1 - порядковый номер сэмпла, а L и R - левый и правый каналы.
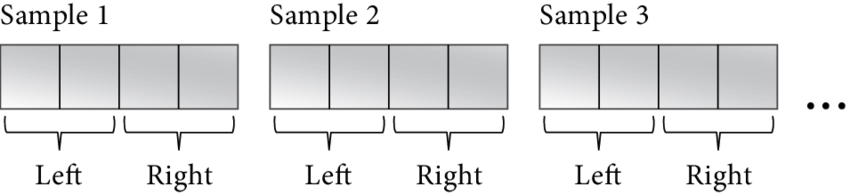
Иными словами, для разбора на сэмплы аудио потока 16bit/stereo нам нужно привести void *buffer к типу short * и умножать индекс нужного сэмпла на количество каналов (т.е. 2). Например возьмём значения сэмпла №9 для обоих каналов:
short *samples = (short*)buffer; short sample_9_left = samples[9*2]; short sample_9_right = samples[9*2 + 1];
16-битные знаковые значения, которые мы здесь получили - это уровень звукового сигнала, где 0 - тишина. Но громкость звука обычно измеряют в значениях dB. Вот как мы можем к ним привести наши данные:
short sample = ...; double gain = (double)sample * (1 / 32768.0); double db = log10(gain) * 20;
Т.е. мы вначале конвертируем integer значение во float - получаем gain, в котором 0.0 - тишина, а +/-1.0 - максимально громкий сигнал. Затем, используя формулу gain = 10 ^ (db / 20), переводим gain в dB. Если нужно перевести обратно, то можно использовать такой код:
#include <emmintrin.h> // SSE2 функции. Есть на любом AMD64 процессоре. double db = ...; double gain = pow(10, db / 20); double d = gain * 32768.0; short sample; if (d < -32768.0) sample = -0x8000; else if (d > 32768.0 - 1) sample = 0x7fff; else sample = _mm_cvtsd_si32(_mm_load_sd(&d));
Несмотря на то что в нашей программе не нужно разбирать поток на сэмплы, знание этого всё равно очень важно. Иначе получится, что мы работаем с какими-то данными, и даже не знаем что именно это за данные и как они устроены - это не путь настоящего хакера.
Шаг 4. Закрываем аудио буфер и звуковую подсистему
Каждый буфер, который мы создали через ffaudio_interface::alloc() мы должны закрыть с помощью ffaudio_interface::free().
audio->free(abuf);
То же самое и со всей звуковой подсистемой: каждый вызов ffaudio_interface::init() должен в конце сопровождаться вызовом ffaudio_interface::uninit(), когда подсистема нам больше не нужна.
audio->uninit();
Билдим сервер
Помнишь как в самом начале мы чудесным образом получили указатель на интерфейс аудио подсистемы?
const ffaudio_interface *audio = ffaudio_default_interface();
Однако чудес на самом деле не бывает, поэтому придётся чуточку разобраться в том, как правильно конфигурить сборку бинарника, использующего ffaudio. На самом деле эта функция лишь возвращает указатель на один из поддерживаемых интерфейсов звуковой подсистемы: ffalsa, ffpulse, ffwasapi, ffdsound, ffcoreaudio, ffoss. Кстати, мы можем использовать любой из этих интерфейсов напрямую и вообще не вызывать ffaudio_default_interface().
Но в любом случае мы должны собрать как минимум по одному бинарю для каждой ОС и использовать поддерживаемую аудио подсистему. Для этого можно просто передать имя необходимой нам звуковой подсистемы на этапе сборки. И тогда ffaudio_default_interface() нам вернёт тот интерфейс, с которым мы этот бинарник и собирали. Я предлагаю сделать это следующим образом:
Придумать некий параметр и передавать его на этапе сборки (например
make FFAUDIO_API=wasapiдля компиляции Windows бинарника с WASAPI)Далее, внутри Makefile'а устанавливаем параметр
FFAUDIO_INTERFACE_DEFAULT_PTRСи препроцессору, например так:CFLAGS += -DFFAUDIO_INTERFACE_DEFAULT_PTR="&ff$(FFAUDIO_API)"Далее, нам необходимо указать необходимые зависимости для Си линкера, например:
ifeq "$(FFAUDIO_API)" "alsa" LINKFLAGS += -lasound else ifeq "$(FFAUDIO_API)" "pulse" LINKFLAGS += -lpulse else ifeq "$(FFAUDIO_API)" "wasapi" LINKFLAGS += -lole32 else ifeq "$(FFAUDIO_API)" "dsound" LINKFLAGS += -ldsound -ldxguid else ifeq "$(FFAUDIO_API)" "coreaudio" LINKFLAGS += -framework CoreFoundation -framework CoreAudio else ifeq "$(FFAUDIO_API)" "oss" LINKFLAGS += -lm endif
Минус предложенного мною решения лишь в том, что не получится вкомпилить функциональность ALSA+PulseAudio или WASAPI+DirectSound внутрь одного бинаря. Но это несложно исправить при необходимости: программно решить, какую подсистему мы хотим загружать, и взять нужный ffaudio интерфейс.
Пишем клиент
Подготовка к воспроизведению звука в основном выглядит так же, как и для звукозаписи. Точно так же получаем интерфейс ffaudio, затем инициализируем звуковую подсистему, затем создаём звуковой буфер и привязываем его к устройству. Разница лишь в том, что в вызове ffaudio_interface::open() теперь нам надо передать флажок FFAUDIO_PLAYBACK. Всё, у нас уже готов поток для воспроизведения.
ffaudio_buf *abuf = audio->alloc(); ffaudio_conf aconf = {}; aconf.format = FFAUDIO_F_INT16; aconf.sample_rate = 48000; aconf.channels = 2; int r = audio->open(abuf, &aconf, FFAUDIO_PLAYBACK);
Чтобы записать кусок звуковых данных в устройство воспроизведения вызываем ffaudio_interface::write(), передаём указатель на interleaved буфер и его размер в байтах. На выходе принимаем количество байт, которые ей удалось записать. Важно помнить, что это значение может быть меньше, чем мы передавали, поэтому тут нужен цикл. Но и не забываем про то, что функция может и ошибку вернуть.
char *samples = ...; int length = ...; while (length != 0) { int r = audio->write(abuf, samples, length); samples += r; length -= r; }
Сетевое взаимодействие
Записывать звук мы научились, воспроизводить - тоже. Но нужно теперь записанный звук передать по сети клиенту, а клиент должен эти данные получить и отправить в звуковое устройство. Для этого мы будем использовать кросс-платформенную библиотеку ffos. Заморачиваться с асинхронными сокет операциями мы не будем, а напишем самый простой код.
Сервер
Итак, наш сервер будет ждать подключения клиента, посылать ему мета информацию в Hello сообщении, а затем посылать ему аудио поток, прочитанный из аудио устройства.
// инициализируем сокеты на Windows // и блокируем SIGPIPE сигнал на Linux ffsock_init(FFSOCK_INIT_SIGPIPE | FFSOCK_INIT_WSA); // создаём слушающий сокет IPv4+TCP ffsock lsk = ffsock_create_tcp(AF_INET, 0); // привязываемся к 0.0.0.0:64000 ffsockaddr a = {}; ffsockaddr_set_ipv4(&a, NULL, 64000); ffsock_bind(lsk, &a); // начинаем слушать ffsock_listen(lsk, SOMAXCONN); // ждём, пока не присоединится клиент ffsockaddr peer = {}; ffsock csk = ffsock_accept(lsk, &peer, 0);
При этом никогда не забываем проверять вызовы на ошибки. После того как клиент соединился, посылаем ему Hello сообщение, в котором передаём мета информацию об аудио потоке. Hello сообщение может быть следующего вида:
struct hello { char version; char opcode; char format; char sample_rate[4]; char channels; };
Здесь первые 2 филда - версия протокола и код операции. А затем идёт описание формата аудио. Мы используем везде тип char для того, чтобы Си компилятор не упаковывал нашу структуру по своим правилам. Итак, формируем сообщение и посылаем клиенту следующим образом:
struct hello msg = { ... }; int r = ffsock_send(csk, &msg, sizeof(msg), 0);
Функция возвращает количество байт, которое было передано (а точнее, скопировано в системный буфер) по факту.
Затем просто в цикле считываем данные из звукового устройства и пересылаем их, как есть, клиенту.
for (;;) { const void *data; int length = audio->read(abuf, &data); const char *d = data; while (length != 0) { int r = ffsock_send(csk, d, length, 0); d += r; length -= r; } }
Наконец, закрываем сокеты при завершении программы:
ffsock_close(csk); ffsock_close(lsk);
Само собой, нужно учесть, что в случае ошибки взимодействия с клиентом, не нужно завершать весь сервер - нужно просто закрыть клиентский сокет и ждать следующего соединения. Иначе, наш сервер какой-то одноразовый получится.
Клиент
Наш клиент соединяется с сервером, получает от него мета информацию, открывает звуковое устройство с нужными параметрами и начинает передавать в него всё, что он получает от сервера.
// инициализируем сокеты на Windows // и блокируем SIGPIPE сигнал на Linux ffsock_init(FFSOCK_INIT_SIGPIPE | FFSOCK_INIT_WSA); // создаём сокет IPv4+TCP ffsock sk = ffsock_create_tcp(AF_INET, 0); // соединяемся c 127.0.0.1:64000 ffsockaddr a = {}; char ip[] = {127,0,0,1}; ffsockaddr_set_ipv4(&a, ip, 64000); ffsock_connect(sk, &a);
Читаем из сокета и воспроизводим:
for (;;) { char buf[64*1024]; int length = ffsock_recv(sk, buf, 64*1024, 0); char *d = buf; while (data.len != 0) { int r = audio->write(abuf, d, length); d += r; length -= r; } }
В целом у нас тут больше ничего особо интересного нет.
Проверяем, что получилось
Полные исходники программы доступны здесь: https://github.com/stsaz/audiospy. Скомпилим бинари для Линукса с PulseAudio и проверим на localhost'е.
Запускаем сервер на TCP порту 64000:
./audiospy_sv 64000
Затем запускаем клиент:
./audiospy_cl 127.0.0.1 64000
Теперь мы можем сказать что-нибудь в микрофон, сервер запишет это и перешлёт клиенту (т.е. нам же самим). А клиент это воспроизведёт через колонки. Ура, работает!
Доработать напильником
Есть несколько очевидных вещей, которые делают нашу программу неполноценной:
Сервер умеет работать только с одним клиентом. Вообще нормальные сетевые приложения должны быть асинхронные с использованием kernel queue, например epoll или I/O Completion Ports.
Нет сжатия аудио данных, из-за чего возникают большие требования к скорости соединения. Можно заиспользовать какую-нибудь библиотеку сжатия аудио, например Vorbis или Opus.
Нет возможности конвертации звука, из-за чего клиент может не смочь открыть аудио поток в том формате, который используется сервером. Для этого нужны алгоритмы конвертации, в т.ч. sample rate convertor типа libsoxr.
Итоги
Мы научились работать со звуковыми подсистемами, записывать и воспроизводить аудио потоки. Ещё мы поняли как устроены аудио сэмплы, и как их переводить в значения dB при необходимости. Ну и в итоге у нас есть полноценное приложение, которое можно использовать на своей аппаратуре в случае необходимости. Надеюсь, что это было тебе чем-то полезно.
По причине того, что я красиво рисовать не умею, использовал картинки отсюда (спасибо художникам!):

