Писать, собирать, агрегировать и сохранять логи для последующего анализа важно: это наиболее подробное представление того, как работает система.
Логи можно собирать и отправлять в централизованную систему по-разному, например используя библиотеки в самом приложении или сторонние агенты вроде Filebeat, Fluent Bit, Vector. Есть множество систем хранения вроде Elasticsearch, Loki, Splunk, файлы на диске или объекты в S3.
Мы в М2 тоже занимаемся этим вопросом и постоянно ищем схемы и инструменты, помогающие улучшать централизованную систему логирования. Я, как инженер развития инфраструктуры, непосредственно принимаю в этом участие. В статье хотел бы поговорить об этапе агрегации и поделиться нашими наработками.
Агрегация
Агрегация, или агрегирование (лат. aggregatio — присоединение), — процесс объединения элементов в одну систему.
Как только у нас появляется множество разнотипных источников логов, нужно производить различные преобразования данных: фильтрацию, объединение по определенным признакам, парсинг и т. д. Все это принято выносить в слой агрегации. И если в самом простом случае можно обойтись такой схемой:
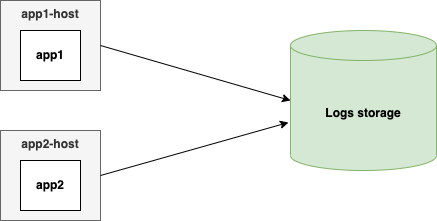
то в более сложных вариантах действовать нужно так:
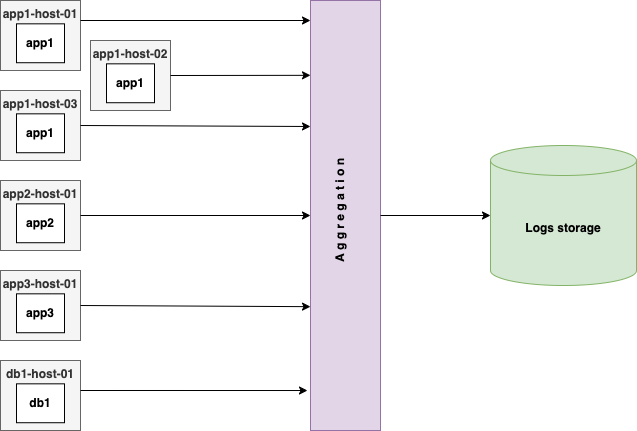
А при более большом объеме сообщений и так:
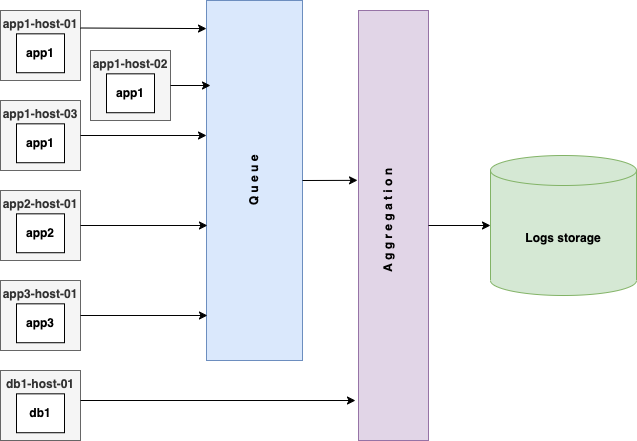
В какой-то момент мы пришли в нашей системе к схеме, подобной третьей, но позже встал вопрос, как гибко управлять уровнем агрегации и масштабировать его.
Управление слоем агрегации
Сейчас существует множество агрегаторов логов. Наиболее популярные, на мой взгляд, — Logstash, Fluentd, Vector. Так как изначально мы использовали Elastic Stack, логично было сосредоточиться именно на Logstash. Инстансы Logstash разворачивались в Kubernetes там, где и генерировалась основная масса логов. Для развертывания мы использовали официальный Helm chart.

С подов собирались логи и отправлялись в Kafka, затем инстансы Logstash, запущенные как StatefulSet, перекладывали логи в кластер Elasticsearch. Каждому namespace соответствовал свой топик в Kafka и индекс в Elasticsearch.
С ростом числа приложений стало понятно, что одним пулом Logstash не обойтись — нужно создавать отдельный пул под каждый топик и масштабировать их в зависимости от потока сообщений. Все это выливается в большое число helm-релизов с во многом дублирующейся конфигурацией и увеличением времени обновления.
Хотелось сделать все так, чтобы при создании нового namespace было достаточно указать несколько лейблов, и пул Logstash запускался автоматически. Так мы решили создать свой logstash-operator, т. к. ничего готового найти не удалось. Мы думали о варианте с logging-operator от Banzai Cloud, но он не вполне нам подходил.
Путь эволюции оказался довольно длинным и не завершился созданием оператора. О нем я расскажу подробнее в отдельной статье.
Logstash operator
Оператор управляется посредством пары CRD и ряда лейблов и аннотаций для namespace.

Чтобы начать работу с оператором, его нужно установить с помощью Kustomize или Helm Chart. Для корректной работы admission webhook требуется cert-manager.
Далее вам потребуется создать ресурс M2Logstash. Он определяет основные параметры запуска инстансов Logstash: образ, ресурсы, опции запуска JVM.
Затем — указать конфигурацию цепочек input, filter, output через ресурс M2LogstashPipeline. Помимо Kafka и Elasticsearch есть еще несколько вариантов.
После того, как CRD установлены, можно создать пул Logstash. Для этого достаточно на нужных namespace установить label “m2/logger=true”. Пулы появятся в том namespace, где создан M2Logstash. Число реплик можно регулировать с помощью аннотации "logger.m2.ru/logstash-replicas".
Если для подключения требуются креды, нужно заранее создать Secret с их значениями, а название указать в M2LogstashPipeline. Подробней можно прочитать в документации.
Ряд настроек input/output вычисляются исходя из названия namespace, к которому привязывается пул Logstash. Это может быть Kafka topic, Elasticsearch index, S3 bucket.
Таким образом, для конфигурирования необходимо только два манифеста с M2Logstash, M2LogstashPipeline, а также лейблы. Вся остальная работа возлагается на оператор.
Подробности по спецификации CRD и лейблам можно найти в документации.
Сфера применения
Изначально мы задумали оператор как средство агрегации логов, генерируемых подами в кластере kubernetes. Но ничего не мешает использовать его для логов с других сервисов и виртуальных машин.
После внедрения, оператор хорошо себя показал, поэтому мы решили опубликовать его на Github. Так он сможет приносить пользу и в других компаниях. Важно отметить, что задача сбора логов должна решаться отдельно, например при помощи Filebeat, Fluent-bit, Vector.
Ограничения и планы по развитию
Сейчас нет привязки M2LogstashPipeline к M2Logstash, поэтому они могут использоваться в единственном экземпляре.
Есть ряд идей по улучшению и расширению функционала, чтобы оператор можно было использовать в большем количестве кейсов. Например:
Сделать привязку M2LogstashPipeline к M2Logstash, чтобы можно было использовать несколько pipeline в одном Logstash. А также использовать несколько групп пулов с разным pipeline.
Добавить возможность автоскейлинга реплик внутри StatefulSet.
Добавить больше вариантов input/output.
Возможность создать Servicemonitor для добавления в Prometheus.
Буду рад другим идеям и предложениям по улучшению. Ссылка на репозиторий.

