Введение
Этот лонг-рид является сильно переработанным и расширенным переводом статьи How to avoid machine learning pitfalls: a guide for academic researchers (Lones, 2021). Статья является кратким описанием ряда распространенных ошибок, возникающих при использовании методов машинного обучения, и руководством к тому, как их избежать. Материал предназначен в первую очередь для студентов-исследователей и касается вопросов, регулярно возникающих в академических исследованиях, например, необходимости проводить строгие сравнения и делать обоснованные выводы. Однако материал применим к использованию ML и в других областях.
Прежде чем приступить к созданию моделей
Подумайте. Это нормально, что вам хочется сразу же начать обучение и оценку моделей. Но начинать надо не с этого - оцените цели проекта; полностью поймите данные, которые будут использоваться; рассмотрите любые ограничения данных, которые необходимо устранить; и поймите, что в вашей области уже было сделано. Если действовать иначе, есть риск получить результаты, которые сложно будет опубликовать, и/или модели, которые не подходят для решения поставленной задачи.
Разберитесь с тем, какую задачу вы хотите решить
При оценке того, является ли задача решаемой, стоит спросить себя: а нужно ли ее решать? Если да, нужно ли ее решать с помощью машинного обучения?
Изучите литературу
Важно понимать, что было сделано и что не было сделано ранее. Другие люди работали над той же задачей - и это хорошо; академический прогресс обычно представляет собой итерационный процесс, в котором каждое последующее исследование опирается на предыдущее. Можно обнаружить, что кто-то уже исследовал вашу замечательную идею, но, скорее всего, они уж задали ряд направлений для дальнейших исследований.
Игнорировать предыдущие исследования - потенциально упустить ценную информацию. Возможно, кто-то уже пробовал предложенный вами подход и нашел фундаментальные причины, по которым он не сработает (и тем самым избавил вас от нескольких лет разочарования), или же частично решил проблему таким образом, что вы сможете от этого решения оттолкнуться.
Важно провести обзор литературы ДО начала работы. Если вы сделаете это слишком поздно - возможно, придется объяснять, почему вы повторяете те же самые исследований и не опираетесь на существующие знания.
Как искать статьи
Выделите ключевые слова (на английском) по которым вы будете искать похожие исследования
Вбейте их в Google Scholar
Изучите релевантные статьи
Внимательно почитайте вводную часть, возможно там есть ссылки на похожие исследования
Выпишите ключевые идеи и достижения, добавьте ссылки на статьи в свои личные архивы. Они вам еще понадобятся для своего собственного введения.
Так же существует множество агрегаторов, которые мониторят свежевыходящие статьи и каждый день публикуют обзоры на самое интересное (Twitter @ak92501, YouTube Yannic Kilcher и многие другие).

Как искать готовые модели
Для поиска готовых моделей с опубликованным кодом существует отличный ресурс - Papers With Code. Отличительной особенностью ресурса является то, что все модели сравниваются между собой на бэнчмарках (сразу видно какая модель работает лучше всего на каком-то конкретном датасете).
На Papers With Code можно искать по типам задач (например Object Detection или Visual Reasoning). Реализован поиск по методам (например Attention или Graph Embeddings) и по датасетам (например CelebA или PubMed).

Потратьте время на понимание своих данных
В конечном итоге вы захотите опубликовать свою работу. Значительно проще публиковать работы, основанные на данных из надежного источника (собранных с использованием надежной методологии).
Если вы используете данные, скачанные с интернет-ресурса, убедитесь, что вы знаете, откуда они взяты. Описаны ли они в статье? Если да, посмотрите на документ; убедитесь, что он был опубликован в авторитетном месте, и проверьте, упоминают ли авторы какие-либо ограничения используемых датасетов.
Не предполагайте, что если набор данных использовался в ряде работ, то он хорошего качества - иногда данные используются только потому, что их легко достать, а некоторые широко используемые наборы данных имеют свои особенности и существенные ограничения (Paullada et al., 2020). Например, при исследовании категории faces в ImageNet (Deng et al., 2009, Crawford & Paglen, 2019) обнаружили миллионы изображений людей, которые были помечены оскорбительными категориями, включая расистские и унизительные фразы. В ответ на эту работу, большая часть набора данных ImageNet была удалена (Yang et al., 2020).
Если вы обучаете свою модель на плохих данных, то, скорее всего, у вас получится плохая модель. Существует соответствующий термин garbage in garbage out (чушь на входе - чушь на выходе). Всегда начинайте с проверки, что ваши данные осмысленны.
Проведите эксплораторный анализ данных (Cox, 2017). Ищите недостающие или непоследовательные записи. Гораздо проще сделать это сейчас, до обучения модели, чем потом, когда вы будете пытаться объяснить рецензентам, почему вы использовали плохие данные.
Анализ важно провести независимо от того, используете ли вы существующие наборы данных или генерируете новые данные в рамках своего исследования (в этом случае учитывайте, что исследовательский анализ может быть ценен сам по себе, а результаты этого анализа могут стать важной частью вашей статьи).
Отдельным пунктом необходимо отметить, что помимо "содержания", важна и "форма" данных. Формат хранения ваших данных повлияет на скорость, с которой вы сможете завершить свое исследование. Например, у вас есть массив, который называется ID и в нем хранятся следующие данные [1,30,111,221,234] в формате float64. Проверьте, а точно ли тут нужен float64, возможно, ваши данные представлены целыми положительными числами, и для их хранения будет достаточно формата uint32 или даже uint16 (подробный обзор форматов данных в Understanding Data Types).
Разберем на конкретном примере
Скачаем датасет: "Когда и где кого-то покусала собака в NYC" и загрузим его в pandas
# Download dataset !wget https://data.cityofnewyork.us/api/views/rsgh-akpg/rows.csv?accessType=DOWNLOAD -O dogs.csv # Load into pandas and display a sample import pandas as pd dataset = pd.read_csv('dogs.csv')
Проверим, есть ли дубликаты:
if len(dataset) == len(dataset.drop_duplicates()): print('Очевидных дупликатов нет') else: print('%.2f процентов данных являются дубликатами' % len(dataset.drop_duplicates())/len(dataset) * 100) >>>> Очевидных дупликатов нет
У нас есть колонки: UniqueID, DateOfBite, Species, Breed, Age, Gender, SpayNeuter, Borough, ZipCode. Давайте проверим все ли с ними в порядке. Начнем с определения того, в каком виде хранятся наши данные в памяти.
Object - это далеко не самая эффективная форма хранения информации в Pandas-DataFrame и, как правило, отличный индикатор того, что с данными, что-то не так. Давайте разберемся с каждой колонкой по отдельности.
UniqueID
Мы ожидаем, что в этой колонке каждому объявлению был присвоен уникальный ID. Судя по сэмплу, это просто порядковый номер начинающийся с 1. Можем визуализировать эту колонку, что бы убедиться что там никаких сюрпризов.
import matplotlib.pyplot as plt import numpy as np x = np.arange(len(dataset)) plt.xlabel('Index') plt.ylabel('UniqueID') plt.scatter(x, dataset['UniqueID'], s=0.1)

Можно заметить, что уникальных идентификаторов меньше чем строк в датафрейме. Давайте убедимся:
dataset['UniqueID'].max(), len(dataset['UniqueID']) >>>> (12383, 22663)
То есть ID повторяются? Судя по всему, в какой-то момент времени нумерация была запущена заново. А значит ID совсем даже не unique => использовать эту колонку как уникальный идентификатор мы не можем.
В каком формате хранятся данные в этой колонке?
dataset['UniqueID'].dtype >>>> dtype('int64')
В int64 можно записывать целые числа в диапазоне от -9223372036854775808 до 9223372036854775807. Мы уже по графику видим, что знак нам не нужен, и что наше максимальное значение явно меньше. Определим какой у нас максимум.
dataset['UniqueID'].min(), dataset['UniqueID'].max() >>>> (1, 12383)
Значит, нам подойдет uint16 целое число без знака в диапазоне от 0 до 65535.
dataset_filtered = dataset.copy() dataset_filtered['UniqueID'] = dataset['UniqueID'].astype('uint16')
Сколько памяти мы выиграли?
def resources_gain(column = 'UniqueID', orig_dataset=dataset, filtered_dataset=dataset_filtered): original_memory = orig_dataset[column].memory_usage(deep=True) memory_after_conversion = filtered_dataset[column].memory_usage(deep=True) gain = original_memory/memory_after_conversion print(f'Gain: {round(gain, 2)}') resources_gain(column='UniqueID', orig_dataset=dataset, filtered_dataset=dataset_filtered) >>>> Gain: 3.99
Теперь колонка UniqueID занимает в 4 раза меньше места (а значит, и обрабатывается быстрее).
DateOfBite
В DateOfBite, судя по всему, записано время укуса, но в формате str. Нам было бы удобнее работать с timestamps.
dataset_filtered['DateOfBite'] = pd.to_datetime(dataset['DateOfBite'])
Оценим выигрыш в ресурсах
resources_gain(column='DateOfBite', orig_dataset=dataset, filtered_dataset=dataset_filtered) >>>> Gain: 8.87
Теперь проверим нет ли каких-то странных дат.
dataset_filtered['DateOfBite'].hist()
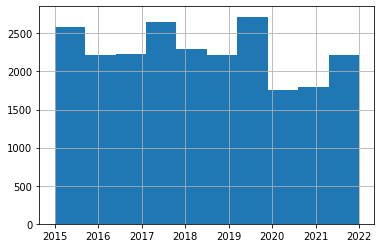
С датами все в порядке, кстати можно заметить, что во время Ковида собакам было меньше кого кусать =)
Species
Мы ожидаем, что в этом отчете сообщается только об укусах собак.
dataset['Species'].unique()
Если у нас целая колонка в которой исключительно значение DOG, то зачем нам эта колонка? Правильно. Удаляем ее.
del dataset_filtered['Species']
Breed
Посмотрим на то, какие значения есть в этой колонке.
dataset['Breed'].unique() >>>> array(['UNKNOWN', 'Pit Bull', 'Mixed/Other', ..., 'SHIH TZU', 'CHIWEENIE MIX', 'DUNKER'], dtype=object)
Можно заметить, что тип нашего массива - object. Обычно так бывает, когда в массиве есть несколько разных типов данных (например float и str). Давайте найдем все значения, которые не являются строками.
dataset['Breed'][dataset['Breed'].apply(lambda x: type(x) != str)].unique() >>>> array([nan], dtype=object)
Ага - NaN. А выше мы уже видели что есть категория UNKOWN. Давайте поправим
dataset_filtered['Breed'][dataset['Breed'].apply(lambda x: type(x) != str)] = 'UNKNOWN'
Теперь посмотрим на поправленный список.
np.sort(dataset_filtered['Breed'].unique()).tolist()[:15] >>>> ['/SHIH TZU MIX', '2 BULL TERRIER DOGS', '2 DOGS: TERR X & DOBERMAN', '2 PITBULLS', 'AFRICAN BOERBOEL', 'AIREDALE TERRIER', 'AKITA / SHEPHERD MIX', 'AKITA/CHOW CHOW', 'ALAPAHA BULLDOG', 'ALASKA HUSKY', 'ALASKAN HUSKY', 'ALASKAN HUSKY MIX', 'ALASKAN HUSKY/LABRADOR RETR', 'ALASKAN KLEE KAI', 'ALASKAN MALAMUTE']
Часто бывает, что категории повторяются с опечатками. Править это придется в ручную (чем мы заниматься сейчас, конечно, не будем). Но, для примера, поправим опечатку в ALASKAN MALMUTE (заменим на ALASKAN MALAMUTE).
dataset_filtered['Breed'][dataset['Breed'] == 'ALASKAN MALMUTE'] = 'ALASKAN MALAMUTE'
У нас есть ограниченное (хоть и большое) количество пород. В памяти их выгоднее хранить в качестве категориального признака.
dataset_filtered['Breed'] = dataset_filtered['Breed'].astype('category')
Оценим выигрыш в производительности.
resources_gain(column='Breed', orig_dataset=dataset, filtered_dataset=dataset_filtered) >>>> Gain: 6.35
В рамках примера будем считать, что почистили колонку Breed.
Age
Ожидаем, что колонка будет в числовом формате, на деле видим object. Давайте разбираться.
dataset['Age'].unique()[:15] >>>> array([nan, '4', '4Y', '5Y', '3Y', '7', '6', '5', '8', '11', '3', '13Y', '2', '10M', '1'], dtype=object)
Увы, тут тоже придётся править руками. Необходимо выбрать единую единицу измерения (например месяцы) и все привести к ней. Там, где непонятно - будем писать NaN (хотя, конечно, лучше было бы заполнить более осознанными значениями).
dataset_filtered['Age'][ (dataset['Age'] == '4') | (dataset['Age'] == '7') | (dataset['Age'] == '6') | (dataset['Age'] == '5') | (dataset['Age'] == '8') | (dataset['Age'] == '11') | (dataset['Age'] == '3')] = np.nan #так как нет уверенности, какие именно тут единицы dataset_filtered['Age'][dataset['Age'] == '4Y'] = 4*12 dataset_filtered['Age'][dataset['Age'] == '5Y'] = 5*12 dataset_filtered['Age'][dataset['Age'] == '3Y'] = 3*12 #и так далее
Gender
Посмотрим, какие есть варианты пола собаки.
dataset['Gender'].unique() >>>> array(['U', 'M', 'F'], dtype=object)
Тут без сюрпризов, но для увеличения производительности тоже сконвертируем данные в категориальные признаки.
dataset_filtered['Gender'] = dataset['Gender'].astype('category') resources_gain(column='Gender', orig_dataset=dataset, filtered_dataset=dataset_filtered) >>>> Gain: 56.97
SpayNeuter
Spay/Neutter - была ли собака стерилизована. Мы ожидаем только True и False (хотя удивительно, что нет колонки unknown).
dataset['SpayNeuter'].unique() array([False, True])
Уже используется формат bool, который занимает мало места. Значит, с этой колонкой закончили.
Borough
Boroughs - что-то вроде наших округов (например, ЮЗАО).
dataset['Borough'].unique() >>>> array(['Brooklyn', 'Manhattan', 'Bronx', 'Other', 'Queens', 'Staten Island'], dtype=object)
Также переведем в категориальные признаки.
dataset_filtered['Borough'] = dataset['Borough'].astype('category') resources_gain(column='Borough', orig_dataset=dataset, filtered_dataset=dataset_filtered) >>>> Gain: 94.79
ZipCode
dataset['ZipCode'].unique()[:15] >>>> array(['11220', nan, '11224', '11231', '11233', '11235', '11208', '11215', '11238', '11207', '11205', '11209', '11237', '11217', '11236'], dtype=object)
Видим категории ? и NaN. Их можно объединить.
dataset_filtered['ZipCode'][dataset['ZipCode'] == np.nan] = '?'
Остальные значения тоже сделаем категориальными.
dataset_filtered['ZipCode'] = dataset['ZipCode'].astype('category')
Напоминим себе какие типы получились в каждой колонке
dataset_filtered.dtypes >>>> UniqueID uint16 >>>> DateOfBite datetime64[ns] >>>> Breed category >>>> Age object >>>> Gender category >>>> SpayNeuter bool >>>> Borough category >>>> ZipCode category >>>> dtype: object
Оценим, насколько меньше места теперь занимает весь датасет.
gain = dataset.memory_usage(deep=True).sum()/dataset_filtered.memory_usage(deep=True).sum() print(f'Gain: {round(gain, 2)}') >>>> Gain: 7.13
На этом можем считать нашу чистку завершенной.
Правильно делайте разбиения
Что бы обучить модель, нам понадобиться разбить свои данные на несколько подвыборок (train-val-test).
Рассмотрим пример
Сгенерируем датасет
import numpy as np dataset_size = 1000 n_features = 2 # Создадим рандомный датасет X = np.random.normal(size=(dataset_size,n_features)) y = np.random.normal(size=(dataset_size,)) print('Размерность X', X.shape) print('Размерность y', y.shape) >>>> Размерность X (1000, 2) >>>> Размерность y (1000,)
Разделим его на train, val и test. Если вы применяете случайное разбиение (как в следующем блоке кода), не забудьте зафиксировать random state, что бы в следующий раз вы получили ровно такую же тестовую выборку.
from sklearn.model_selection import train_test_split X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.15, random_state=42) X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.15, random_state=42) print('Размерность X_train', X_train.shape) print('Размерность X_val', X_val.shape) print('Размерность X_test', X_test.shape) >>>> Размерность X_train (722, 2) >>>> Размерность X_val (128, 2) >>>> Размерность X_test (150, 2)
plt.scatter(X_train[:,0], X_train[:,1], color='red', alpha=0.5, label='Train') plt.scatter(X_val[:,0], X_val[:,1], color='green', alpha=0.5, label='Val') plt.scatter(X_test[:,0], X_test[:,1], color='blue', alpha=0.5, label='Test') plt.legend()
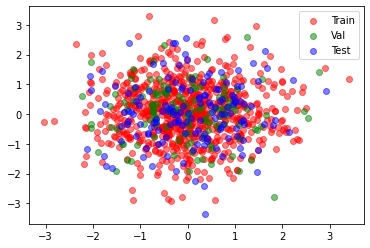
В следующий раз вам предстоит воспользоваться тестом только при проверке обученной модели. А вот валидационный (validation set) нам понадобиться при обучении модели.
Validation set
В процессе обучения модели мы вообще-то хотели бы знать, насколько хорошо она справляется с поставленной задачей. Если для оценки модели на каждой итерации обучения модели мы будем использовать тестовый сет, то просто оптимизируем модель к этому конкретному (тестовому) разбиению и потерям возможность объективно оценивать обобщающую способность модели (тестовое множество станет неявной частью процесса обучения Cawley, 2010). Вместо этого для измерения качества модели (и контроля процесса обучения) следует использовать отдельный (третий) набор для проверки - validation/val set.
Еще одним преимуществом наличия валидационного набора является возможность сделать раннюю остановку (early stopping). Во время обучения модели её качество оценивается по валидационному набору на каждой итерации процесса обучения. Обучение прекращается, когда результат валидации начинает снижаться, так как это указывает на то, что модель начинает переобучаться на train set.
Не смотрите на все ваши данные
Когда вы начнете погружаться в ваши данные, вы, скоре всего, заметите в них какие-то закономерности. Так или иначе, эти закономерности будут направлять вашу дальнейшую работу. Тем не менее, не делайте непроверяемых предположений, которые впоследствии будут использованы в вашей модели. Например, проанализировав датасет с собаками, можно решить что в 2020 и 2021 году собаки стали воспитаннее и перестали так часто кусать прохожих. Но это же не так! На самом деле людей на улицах было меньше, плюс меньше людей хотели и могли обращаться в полицию (из-за ковидных ограничений).
Вообще делать предположения - это нормально, но они должны использоваться только для обучения модели, а не для ее тестирования.
Следует избегать пристального изучения любых тестовых данных на начальном этапе исследовательского анализа. В противном случае вы можете сознательно или неосознанно сделать выводы, которые ограничат обобщающую способность вашей модели не поддающимся тестированию способом. К этой теме мы будем возвращаться еще не раз, поскольку утечка информации из тестового набора в процесс обучения является распространенной причиной плохой обобщаемости ML моделей.
Не допускайте утечки тестовых данных в процесс обучения
Критически важно иметь данные, которые можно использовать для измерения обобщающей способности вашей модели. Распространенная проблема заключается в том, что информация об этих данных просачивается в конфигурацию, обучение или выбор моделей. Когда это происходит, данные перестают быть надежной мерой обобщения, что, в свою очередь, ведет к тому, что опубликованные модели ML регулярно демонстрируют плохие результаты на реальных данных.
Существует несколько вариантов утечки информации из тестового набора. Некоторые из них кажутся вполне безобидными. Например, при подготовке данных используется информация о средних диапазонах переменных во всем наборе данных для масштабирования переменных - чтобы предотвратить утечку информации, такие вещи следует делать только с обучающими данными.
Пример нормализации данных
Создадим искусственный датасет и посмотрим на него
from sklearn.datasets import make_moons import matplotlib.pyplot as plt dataset = make_moons(n_samples=1000, shuffle=True, noise=0.1, random_state=42) plt.title('Full dataset') plt.scatter(dataset[0][:,0], dataset[0][:,1], c=dataset[1])

Данные нужно нормализовать. И очень хочется это сделать сразу со всеми данными, но это приведет к data leakage (утечке данных из тестовой выборки). Давайте все равно это сделаем и временно отложим наш неправильно нормализованный датасет.
import numpy as np from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(dataset[0]) dataset_wrong_data = scaler.transform(dataset[0]) dataset_wrong = (dataset_wrong_data, dataset[1]) plt.title('Неправильно нормализованный датасет') plt.scatter(dataset_wrong[0][:,0], dataset_wrong[0][:,1], c=dataset_wrong[1])

Теперь разобьем наш исходный датасет на train и test
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(dataset[0], dataset[1], test_size=0.2, random_state=42) plt.scatter(X_train[:,0], X_train[:,1], c=y_train, label='Train', alpha=0.2) plt.scatter(X_test[:,0], X_test[:,1], c=y_test, marker='x', label='Test') plt.legend()
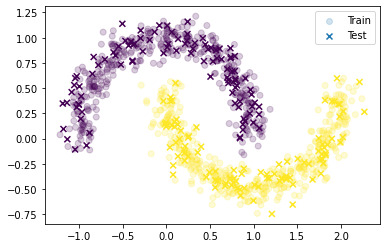
Теперь мы хотим нормализовать данные. Напрашивается идея применить нормализацию к train, и применить нормализацию к test. Так тоже неправильно.
scaler_train = MinMaxScaler() scaler_test = MinMaxScaler() scaler_train.fit(X_train) scaler_test.fit(X_test) X_train_wrong = scaler_train.transform(X_train) X_test_wrong = scaler_test.transform(X_test) plt.scatter(X_train_wrong[:,0], X_train_wrong[:,1], c=y_train, label='Train', alpha=0.2) plt.scatter(X_test_wrong[:,0], X_test_wrong[:,1], c=y_test, marker='x', label='Test') plt.title('Еще один не правильно нормализованный датасет') plt.legend()

Правильно будет использовать тот же скейлер для test, что и для train.
scaler_train = MinMaxScaler() scaler_train.fit(X_train) scaler_train.fit(X_test) X_train_norm = scaler_train.transform(X_train) X_test_norm = scaler_train.transform(X_test) plt.scatter(X_train_norm[:,0], X_train_norm[:,1], c=y_train, label='Train', alpha=0.2) plt.scatter(X_test_norm[:,0], X_test_norm[:,1], c=y_test, marker='x', label='Test') plt.title('Правильно нормализованный датасет') plt.legend()
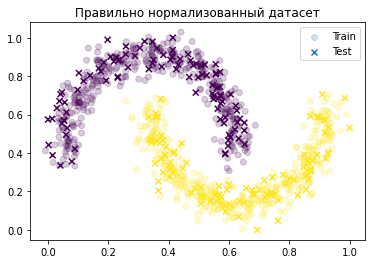
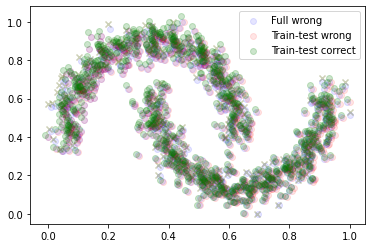
Сравним все вместе.
plt.scatter(dataset_wrong[0][:,0], dataset_wrong[0][:,1], color='blue', alpha=0.1, label='Full wrong') plt.scatter(X_train_wrong[:,0], X_train_wrong[:,1], color='red', alpha=0.1, label='Train-test wrong') plt.scatter(X_test_wrong[:,0], X_test_wrong[:,1], color='red', alpha=0.1, marker='x') plt.scatter(X_train_norm[:,0], X_train_norm[:,1], color='green', alpha=0.2, label='Train-test correct') plt.scatter(X_test_norm[:,0], X_test_norm[:,1], color='green', alpha=0.2, marker='x') plt.legend()
Другий распространенным примером утечки информации является выбор признаков (feature selection, см. Cai et al., 2018) до разбиения данных на подвыборки. Обычно при наличии большого количества признаков проводится их фильтрация тем или иным образом (корреляция с целевой переменной, жадное добавление признаков и пр.).
Например, в геномике это означает отфильтровывание генов, которые являются в каком-то смысле "низкокачественными". Так, мы можем захотеть отфильтровать гены с высокой разреженностью, т.е. имеющие значение 0 для большого числа пациентов. Поскольку критерии для отсеивания таких генов определяются на основе данных, важно, чтобы рассматривался только train set, а не весь набор данных, чтобы определить, нужно ли отсеивать функцию или нет. Поэтому следует вычислять разреженность каждого гена среди обучающих выборок, а не среди всех выборок. В противном случае для отбора признаков будет использована информация, полученная из тестового набора.
Лучшее, что вы можете сделать для предотвращения таких проблем, это разделить подмножество ваших данных в самом начале проекта, и использовать независимый тестовый набор только один раз для измерения генерализации модели в конце проекта (Cawley, 2010 и Kaufman et al., 2012 для более обширного обсуждения этого вопроса. А так же можно обратится к блог-посту Brownlee, в котором детально разбираются часто встречающиеся ошибки).
Убедитесь, что у вас достаточно данных
Если у вас недостаточно данных, то обучение хорошей обобщающей модели может оказаться невозможным. Понять, ваш ли это случай не получится до тех пор, пока вы не начнете строить модели: все зависит от количества шума и ошибок в наборе данных. Если данные "чистые", то можно обойтись меньшим количеством примеров; если много шума - потребуется больше.
Перекрестная валидация (cross-validation)
Если вы не можете получить больше данных - то вы можете более эффективно использовать уже имеющиеся, используя перекрестную валидацию (cross validation. CV).
Вообще говоря, кросс-валидация используется для более точной оценки качества модели. Однократное вычисление качества может быть ненадежно и привести либо к недооценке, либо к переоценке модели. По этой причине обычно проводится серия вычислений метрик. Существует несколько способов провести множественную оценку модели, и большинство из них предполагает многократное обучение модели с использованием различных подмножеств обучающих данных. Перекрестная валидация широко изучена и имеет множество разновидностей построения (Arlot et al., 2010).
Перекерстная валидация в машинном обучении подразумевает, что вместо разбиения набора данных на обучение (train) и тестирование (test), данные разбиваются на множество частей и процесс "обучение-тестирование" производится многократно. Обучение происходит на одних подмножествах, тестирование - на оставшихся, затем выбираются новые подмножества для обучения и тестирования и модель обучается заново. Процедура гарантирует, что модель обучается и тестируется на новых данных на каждом новом шаге.
Часто используют десятикратную прекрестную валидацию.
Разберем на примере
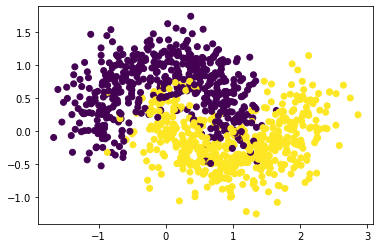
Создадим датасет
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_moons X, y = make_moons(n_samples=1000, noise=0.3, random_state=42) plt.scatter(X[:,0], X[:,1], c=y)
И разделим его на 10 (K) складок (folds). Для каждой складки посчитаем точность классификации
from sklearn.model_selection import KFold from sklearn.preprocessing import StandardScaler, MinMaxScaler from sklearn.ensemble import RandomForestClassifier #Split data intto 10 folds kf = KFold(n_splits=10) kf.get_n_splits(X) #Define scaler and classifier scaler = MinMaxScaler() clf = RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1) #Define figure space fig,ax = plt.subplots(nrows=2, ncols=5, figsize=(10,4)) row = 0 scores = [] #Itterate over folds for col, (train_index, test_index) in enumerate(kf.split(X)): #Split X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] #Normalize scaler.fit(X_train) scaler.fit(X_test) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) #Classify clf.fit(X_train, y_train) #Gauge performance score = clf.score(X_test, y_test) scores.append(score) #Plot figure if col > 4: col-=5 row=1 ax[row, col].scatter(X_train[:,0], X_train[:,1], c=y_train, alpha=0.05) ax[row, col].scatter(X_test[:,0], X_test[:,1], c=y_test, marker='x') ax[row, col].set_title(score) ax[row, col].axis('off')

Результирующую точность модели мы определим как среднее от всех оценок.
print('Финальная точность = %.2f ± %.2f' % (np.mean(scores), np.std(scores))) >>>> Финальная точность = 0.91 ± 0.03
Для большей надежности можно использовать метод вложенной перекрестной валидации (также известный как двойная кросс-валидация, (см. Cawley, 2010 и Wainer et al., 2021).
Аугментация данных
Вы можете использовать методы аугментации данных (например, Wong et al., 2016, Shorten et al., 2019). Они могут быть весьма эффективны для "расширения" небольших датасетов.
Разберем на примере
#Download image !wget https://wallpaperaccess.com/full/3842851.jpg #Read image image = cv2.imread("3842851.jpg") #Display plt.imshow(image) plt.axis('off')

Теперь определим аугментации
import albumentations as A import cv2 import matplotlib.pyplot as plt #Define augmentations transform = A.Compose([ A.Resize(width=512, height=512), A.HorizontalFlip(p=1), A.CLAHE(clip_limit=4.0, tile_grid_size=(8, 8), always_apply=False, p=0.5) ])
И применим их к картинке
#Apply transformation transformed = transform(image=image) transformed_image = transformed["image"] #Display original and transformed fig,ax = plt.subplots(ncols=2, figsize=(10,5)) ax[0].imshow(image) ax[1].imshow(transformed_image) ax[0].set_title('Original') ax[1].set_title('Augmented') for a in ax: a.axis('off')

Несколько аугментаций лучше чем одна
До 2021 года была принято проводить аугментации следующим образом: берем сэмпл, применяем к нему набор аугментаций с некоторой вероятностью (например p=0.5) и отправляем этот сэмпл в модель на обучение. В статье Fort et al., 2021 предлагается способ, который работает лучше: берем сэмпл, дублируем его N раз и к каждому из дублей применяем свою аугментацию.
Казалось бы, в каждом мини-батче становится меньше уникальных примеров, что должно бы негативно сказаться на способности к обобщению. Но нет. Точность на тесте только увеличивается.
")
Дисбаланс классов
Увеличение количества данных также полезно в случае дисбаланса классов. Такая ситуация характерна, скажем, для задач классификации, когда в семплов некоторых класса много меньше, чем других. Работа Haixiang et al., 2017 посвящена обзору методов решения данной проблемы.
Transfer-learning
Частично проблема недостаточного количества данных решается при помощи transfer-learning - использования моделей, заранее обученных на данных, близких к вашим.

Следует учитывать, что в случае значительной ограниченности количества данных, скорее всего, вам также придется ограничить сложность используемых моделей ML. Модели с большим количеством параметров, например, глубокие нейронные сети, могут легко переобучаться на небольших датасетах. В любом случае, важно выявить эту проблему на ранней стадии и разработать подходящую (и обоснованную) стратегию для ее решения.
Обращайтесь к экспертам в своей области
Эксперты в области вашего исследования могут быть ценным источником данных, знаний и навыков. Они помогут вам понять, какие проблемы решать полезно и актуально (а какие - нет), как выбрать наиболее подходящий набор данных и модель ML, а также как определить, в каком журнале публиковать статью (аудитория какого журнала будет наиболее подходящей). Если не учитывать мнение экспертов, вы рискуете тем, что ваш проект не будет решать полезные задачи или будет решать неоптимальным или даже вредным способом. К примеру, не лучшей идеей будет использовать неинтерпретирумую ML-модель в областях, где интерпретируемость критически важна. В частности, это относится к принятию медицинских и финансовых решений (Rudin, 2019).
Подумайте о том, как (и где) будет развернута ваша модель
Для чего вам модель ML? Как вы будете ее использовать? Это важные вопросы, и ответ на них должен повлиять на процесс разработки модели. Многие академические исследования по своей сути не подходят для создания моделей, которые будут использоваться в реальном мире (и это не беда, поскольку процесс построения и анализа моделей сам по себе может дать полезное понимание проблемы). Однако у статей, в которых описываются модели, которые можно применять в реальных ситуациях, обычно цитирование значительно выше. Так что стоит заранее подумать о том, как и где ваша модель будет применяться.
Например, если модель будет развернута в среде с ограниченными ресурсами, на датчике или роботе, это следует учесть сразу. На устройстве с маленьким объемом памяти запустить огромный трансформер просто не получится. А в случае, когда классификация сигнала должна быть выполнена в течение миллисекунд, следует обратить особое внимание на потенциальную скорость инференса модели.

Еще одним нюансом может являться контекст того, как ваша модель будет связана с окружением - с программной системой, в которой она будет развернута. Эта процедура зачастую далеко не так проста (Sculley et al., 2015). Однако современнные подходы, такие как ML Ops, направлены на решение подобных трудностей (Tamburri et al., 2020).
Как надежно строить модели
Построение моделей - одна из самых приятных частей ML. С современными ML-фреймворками легко использовать всевозможные подходы к данным и смотреть, какая модель лучше всего решает поставленную задачу. Однако, это может закончиться неорганизованным беспорядком экспериментов, которые потом сложно обосновать и о которых сложно написать статью. Удостоверьтесь, что данные используются правильно, что происходит понятное логирование результатов и что модель подходит для решения задачи.
Попробуйте различные модели
Вообще говоря, не существует такой вещи, как единственная лучшая модель ML. Существует даже доказательство в виде теоремы No Free Lunch, которая показывает, что ни один подход ML не лучше другого, если рассматривать все возможные проблемы (Wolpert, 2002).
Таким образом, ваша задача - найти модель ML, которая хорошо работает для вашей конкретной задачи. Возможно, у вас есть некоторые априорные знания о том, какая модель подойдет лучше всего, например, в виде качественных исследований по схожим темам. Но большую часть времени вам придется работать в темноте. К счастью, современные библиотеки ML позволяют опробовать несколько моделей с небольшими изменениями в коде, поэтому достаточно удобно перебрать несколько моделей и выяснить, какая из них подходит лучше.
Не используйте неподходящие модели
Снижая барьер для имплементации, современные библиотеки ML также облегчают применение неподходящих моделей к вашим данным. В качестве примера можно привести применение моделей, предполагающих категориальные признаки, к набору данных, состоящему из числовых признаков, или попытку применить модель, предполагающую отсутствие зависимостей между переменными к данным временного ряда.
Это особенно важно учитывать в свете публикации, поскольку представление результатов, полученных с помощью несоответствующих моделей, вызовет у рецензентов массу вопросов к вашей работе. Другой крайностью является использование неоправданно сложной модели. Глубокая нейронная сеть - не лучший выбор, если у вас мало данных, а общие знания об области предполагают, что лежащая в основе модель довольно проста.
И, наконец, не используйте "современность" модели в качестве оправдания для ее выбора: старые, проверенные модели часто работают лучше, чем новые.
Какие есть доступные ресурсы для обучения на GPU
GPU - крайне эффективный и ооооочень дорогой способ обучать модели. К счастью для вас вы относитесь к привилегированному классу разработчиков машинного обучения - к классу исследователей, которым за GPU обычно платить не нужно. Если вы можете обосновать зачем вам GPU - многие корпорации с удовольствием предоставят их бесплатно.
Google Colab - в базовой версии - бесплатный способ обучать модели на GPU, но про него вы уже все знаете.
Kaggle - похожим на Colab образом работают и Kaggle Kernels. Бесплатно и без особенных бумажек (GPU goes brrrrrrr)
Помимо бесплатных Colab и Kaggle, есть возможность получить доступ к серьезным ресурсам (несколько тысяч долларов на вычисления). У каждой программы немного свои правила, но в целом схема такая: пишете заявку, где рассказываете о своих исследованиях и объясняете зачем вам GPU. Затем отправляете заявку с официального университетского/институтского аккаунта и в течение месяца получаете свои кредиты.
Основные программы:
Советы по использованию GPU
DataLoaderпо умолчанию имеет плохие настройки. Поменяйтеnum_workers > 0(например в Colab используйте 2 workers, в ColabPro - 4)Используйте
torch.backends.cudnn.benchmark = Trueдля тюнинга cuda kernelsЕсли возможно - максимизируйте размер батча для максимальной нагрузки на GPU
Перед слоями нормализации не забывайте отключать bias (
bias=False) - в этом случае, это лишний параметр, который только раздувает размер моделиЕсли вы работаете на нескольких GPU, используйте
DistributedDataParallelдаже если на самом деле ваши GPU не distributedОбучайте с типом данных
float16
Оптимизируйте гиперпараметры вашей модели
Многие модели имеют гиперпараметры - то есть числа или параметры, которые влияют на конфигурацию модели. Примерами могут служить: функция ядра, используемая в SVM; количество деревьев в случайном лесу и архитектура нейронной сети. Многие из этих гиперпараметров существенно влияют на производительность модели, и, как правило, универсальных гиперпараметров (таких, которые были бы оптимальны для всех возможных задач) не существует.
То есть, чтобы получить максимальную отдачу от модели, гииперпараметры нужно подбирать под конкретный набор данных. Хотя может возникнуть соблазн возиться с гиперпараметрами до тех пор, пока вы не найдете что-то подходящее, такой подход, скорее всего, не будет оптимальным. Гораздо лучше использовать какую-то стратегию оптимизации гиперпараметров (в качестве бонуса, обоснованная стратегия, в публикации смотрится значительно лучше, чем что-то в стиле hyperparameters were chosen by chance). Базовые стратегии включают случайный поиск и поиск по сетке, но они не очень хорошо масштабируются для большого количества гиперпараметров или для моделей, которые дорого обучать, поэтому стоит использовать инструменты, которые ищут оптимальные конфигурации более интеллектуальным способом (исследовано в Yang et al., 2020).
Библиотеки для оптимизации гиперпараметров
Существует довольно много библиотек для оптимизации гиперпараметров. Ключевыми являются Ray-tune, Optuna и Hyperopt. В целом, друг от друга они принципиально не отличаются, скорее это вопрос вкуса.
Запомните, когда вы оптимизируете гиперпараметры или признаки, используемые моделью, для их отбора нужно использовать отдельный, валидационный датасет, или же кросс-валидацию. Вы НЕ должны подбирать модель или ее гиперпараметры на тесте.
Также можно использовать методы AutoML для оптимизации выбора модели и ее гиперпараметров (см. обзор в He et al., 2021).
Используйте систему для контроля за своими экспериментами
Учитывая все сказанное выше, легко представить какой хаос будет твориться в процессе ваших экспериментов. Что бы этого избежать имеет смысл каким-то образом систематизировать экспериментальную фазу.
В простейшем виде можно завести git репозиторий. Каждый раз, когда вы меняете что-то в модели, делайте commit. Таким образом если что-то пойдет не так - у вас будет возможность откатиться назад.
Отличной идеей будет использовать инструменты контроля типа Tensorboard или Weights&Biases, которые, помимо прочего, позволяют сравнивать результаты работы моделей и визуализировать их отдельные элементы.

Как надежно оценить модели
Достоверные результаты работы способствуют научному прогрессу в вашей области. К сожалению, переоценить возможности своей ML модели очень легко. Поэтому тщательно продумайте, как именно вы собираетесь использовать данные в своих экспериментах, как вы собираетесь измерять истинную производительность ваших моделей и как вы собираетесь сообщать об этой производительности в содержательной и информативной форме.
Используйте соответствующий тестовый датасет
Прежде всего, всегда используйте тестовый набор для измерения обобщающей способности модели ML. То, насколько хорошо модель работает на обучающем множестве (train set), на практике не имеет никакого значения, и достаточно сложная модель может на нем полностью переобучится, но так и не начать обобщать тестовые данные.

Также важно убедиться, что данные в тестовом наборе на самом деле подходят для тестов. То есть они не должны пересекаться с обучающим набором и в то же время в достаточной степени отражать реальные данные. Например, рассмотрим датасет из фотографий, где изображения в обучающем и тестовом наборах были получены на открытом воздухе в солнечный день. Наличие одинаковых погодных условий означает, что тестовое множество не будет независимым, а поскольку оно не охватывает широкий спектр погодных условий, то и репрезентативным не будет.

Аналогичные ситуации могут возникать, когда для сбора обучающих и тестовых данных используется разное оборудование. Например, для обучения вы используете томограф из одного госпиталя, а оценку качества модели проводите на томографе из другого госпиталя. Если модель не учитывает характеристики оборудования, она, скорее всего, не будет обобщаться на томограф из второй больницы (но на датасете из первого госпиталя эту ошибку вы отловить не сможете).
Фиксируйте случайные состояния
Многие модели ML нестабильны. Если вы обучаете их несколько раз или вносите небольшие изменения в обучающие данные, их производительность может значительно измениться. С этим можно и нужно бороться путем фиксации всех random states и переводом модели на детерминистические операции. Такая внимательность к деталям так же позволит другим исследователям на самом деле воспроизвести ваши результаты.
Что бы зафиксировать random states, можно использовать следующий код, исполняемый в начале файла/блокнота. Дополнительные фиксации, например, Dataloader'а, описаны в официальной документации.
import torch import random import numpy as np torch.manual_seed(42) random.seed(42) np.random.seed(42)
Используйте подходящие метрики
Будьте внимательны к тому, какие метрики вы используете для оценки моделей ML. Так, в случае моделей классификации часто используется точность (accuracy), которая представляет собой долю образцов в наборе данных, которые были правильно классифицированы моделью. Точность хорошо работает, если ваши классы сбалансированы, т.е. если каждый класс представлен примерно одинаковым количеством образцов. Но многие наборы данных не сбалансированы, и в этом случае точность может быть очень обманчивой метрикой.
Пример
Рассмотрим набор данных в котором 90% образцов представляют один класс и 10% - другой.
Сгенерируем датасет
from sklearn.datasets import make_blobs import matplotlib.pyplot as plt X, y = make_blobs(n_samples=1000, centers=2, n_features=2, random_state=42, cluster_std=7) plt.scatter(X[:,0], X[:,1],c=y)

И искусственно создадим в нем дисбаланс классов (мы хотим получить распределение 90% и 10%).
import numpy as np X_0, y_0 = X[y==0], y[y==0] X_1, y_1 = X[y==1], y[y==1] rnd_indx = np.random.choice(range(len(X_1)), int(len(X_1)*0.1), replace=False) X_new, y_new = np.vstack([X_0, X_1[rnd_indx]]), np.hstack([y_0, y_1[rnd_indx]]) plt.scatter(X_new[:,0], X_new[:,1],c=y_new)

И теперь попробуем классифицировать
from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_moons from sklearn.ensemble import RandomForestClassifier classifier = RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1) X_train, X_test, y_train, y_test = train_test_split( X_new, y_new, test_size=0.4, random_state=42 ) # normalize data scaler = StandardScaler().fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) # predict using each classifier classifier.fit(X_train, y_train) score = classifier.score(X_test, y_test) print("Точность классификации = %.2f процентов" % (score*100)) >>>> Точность классификации = 88.18 процентов
Какая замечательная точность! Но, классификатор, который всегда выдает первый класс независимо от входа, будет иметь точность около 90%, несмотря на то, что он совершенно бесполезен.
В такой ситуации предпочтительнее использовать такие метрики, как коэффициент каппа Коэна (?) или коэффициент корреляции Мэтьюса (MCC), которые относительно нечувствительны к дисбалансу размеров классов. Более широкий обзор методов работы с несбалансированными данными см. в Haixiang et al., 2017 и в блоге Дьяконова.
Перепроверим результаты с помощью MCC. Коэффициент корреляции Мэтьюса учитывает истинные и ложные положительные и отрицательные результаты и обычно считается сбалансированной мерой, которую можно использовать, даже если классы сильно несбалансированы. По сути, MCC - это значение коэффициента корреляции между -1 и +1. Коэффициент +1 представляет собой идеальное предсказание, 0 - среднее случайное предсказание, а -1 - обратное предсказание.
from sklearn.metrics import matthews_corrcoef y_pred = classifier.predict(X_test) mcc = matthews_corrcoef(y_test, y_pred) print('MCC=%.2f' % mcc) >>>> MCC=0.12
Так себе результаты, неправда ли?
Если данных какого-то конкретного класса мало, можно, например, провести стратификацию, которая гарантирует, что каждый класс будет адекватно представлен в каждой выборке (например с помощью метода StratifiedKFold в библиотеке sklearn). А так же учесть баланс классов в самом классификаторе (или в DataLoader'е в случае нейросети).
from sklearn.model_selection import StratifiedKFold #Split data into 5 folds kf = StratifiedKFold(n_splits=5) kf.get_n_splits(X_new, y_new) mcc_scores = [] classifier = RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1, class_weight = "balanced", random_state=42) scaler = StandardScaler() #Itterate over folds for train_index, test_index in kf.split(X_new, y_new): #Split X_train, X_test = X_new[train_index], X_new[test_index] y_train, y_test = y_new[train_index], y_new[test_index] #Normalize scaler.fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) #Classify classifier.fit(X_train, y_train) #Gauge performance y_pred = classifier.predict(X_test) mcc_score = matthews_corrcoef(y_test, y_pred) mcc_scores.append(mcc_score) print('Average MCC on stratified 5-fold = %.2f ± %.2f' % (np.mean(mcc_scores), np.std(mcc_scores))) >>>> Average MCC on stratified 5-fold = 0.33 ± 0.10
Как справедливо сравнивать модели
Сравнение моделей является основой академических исследований, но сделать его правильно сложно. Некорректно проведенное сравнение может ввести в заблуждение других исследователей. Чтобы этого избежать, убедитесь, что вы оцениваете различные модели в одном и том же контексте, учитываете несколько точек зрения и правильно используйте статистические тесты.
Не думайте, что большее число означает лучшую модель
Не редкость, когда в статье говорится что-то вроде "В предыдущих исследованиях сообщалось о точности до 94%. Наша модель достигла 95%, и поэтому она лучше." Существуют различные причины, по которым более высокий показатель не всегда означает лучшую модель. Например, если модели обучались или оценивались на разных разделах одного и того же набора данных, то небольшие различия в производительности могут быть вызваны этим. Или, вы использовали совершенно разные наборы данных при сравнении. Возможно, большие различия в производительности объясняются именно данными.
Другой причиной некорректного сравнения является неспособность провести одинаковый объем оптимизации гиперпараметров при сравнении моделей; например, если одна модель тестируется с настройками по умолчанию, а другая была дополнительно оптимизирована, то сравнение не будет справедливым. Так, в статье Csordás et al., 2021 авторы демонстрируют, что, просто пересмотрев такие базовые конфигурации модели, как масштабирование эмбедингов, early stopping, relative positional embeddings и другие гиперпараметры, можно значительно улучшить обобщающую способность трансформеров.
Поэтому к сравнениям, основанным на опубликованных цифрах метрик, всегда следует относиться с осторожностью. Чтобы действительно быть уверенным в справедливости сравнения двух подходов, вам следует заново реализовать все сравниваемые модели, оптимизировать каждую из них в одинаковой степени, провести множественные оценки, а затем использовать статистические тесты, чтобы определить, являются ли различия в производительности значительными.
В целом, ничего страшного, если точность вашей модели сравнима или чуть хуже, чем существующие методы. Возможно у вашей модели выше скорость инференса? Или может быть, она интерпретируема? Подумайте об этом и изложите свои заключения в четкой и ясной форме в статье.
Используйте статистические тесты при сравнении моделей
Если вы хотите убедить людей в том, что ваша модель лучше, чем другие, то статистический тест станет очень полезным инструментом. В широком смысле существует две категории статистических тестов для сравнения отдельных моделей ML.
Тестирование Макнемара
Первая категория тестов используется для сравнения отдельных моделей (например, двух обученных деревьев решений). Рассмотрим McNemar's test, который является довольно распространенным выбором для сравнения двух классификаторов, и работает путем сравнения выходных меток классификаторов для каждой выборки в тестовом наборе.
import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.datasets import make_moons from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier names = [ "Linear SVM", "Random Forest", ] classifiers = [ SVC(kernel="linear", C=0.025), RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1), ] X, y = make_moons(noise=0.3, random_state=42, n_samples=1000) # preprocess dataset, split into training and test part X = StandardScaler().fit_transform(X) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.4, random_state=42 ) # normalize data scaler = StandardScaler().fit(X_train) X_train = scaler.transform(X_train) X_test = scaler.transform(X_test) # predict using each classifier predictions, scores = [], [] for name, clf in zip(names, classifiers): clf.fit(X_train, y_train) correct_prediction = clf.predict(X_test) == y_test predictions.append(correct_prediction) scores.append([name, clf.score(X_test, y_test)])
Построим contingency table, которая будет иметь следующую структуру
Classifier 2 correct | Classifier 2 incorrect | |
Classifier 1 correct | ?? | ?? |
Classifier 1 incorrect | ?? | ?? |
В случае с первой ячейкой таблицы мы должны просуммировать общее количество тестовых случаев, которые Classifier 1 предсказал правильно, и Classifier 2 тоже предсказал правильно.
Найдем сколько сэмплов оба классификатора посчитали правильно (длинна Union между ними). Это и будет наша первая ячейка.
first_row_first_column = len(np.union1d(cls1_correct_index, cls2_correct_index)) first_row_first_column >>>> 369
Повторим операцию для остальных ячеек
cls1_incorrect_index = np.where(predictions[0] == False)[0] cls2_incorrect_index = np.where(predictions[1] == False)[0] second_row_first_column = len(np.union1d(cls1_incorrect_index, cls2_correct_index)) first_row_second_column = len(np.union1d(cls1_correct_index, cls2_incorrect_index)) second_row_second_column = len(np.union1d(cls1_incorrect_index, cls2_incorrect_index))
Получим нашу contingency table
data = np.array([[first_row_first_column, second_row_first_column], [first_row_second_column, second_row_second_column]]) data >>>> array([[369, 387], [369, 75]])
Проведем тестирование Макнемара.
from statsmodels.stats.contingency_tables import mcnemar import pandas.util.testing as tm result = mcnemar(data, exact=True) # summarize the finding print('statistic=%.3f, p-value=%.3f' % (result.statistic, result.pvalue)) # interpret the p-value alpha = 0.05 if result.pvalue > alpha: print('Same proportions of errors (fail to reject H0)') else: print('Different proportions of errors (reject H0)') >>>> statistic=369.000, p-value=0.536 >>>> Same proportions of errors (fail to reject H0)
Как интерпретировать результат? С помощью ячеек "Нет/Да" и "Да/Нет" в таблице случайностей. Тест проверяет, существует ли значительная разница между подсчетами в этих двух ячейках. Ничего более.
Если ячейки имеют одинаковые значения, это говорит о том, что обе модели допускают ошибки в одинаковой пропорции, просто на разных экземплярах тестового набора. В этом случае результат теста не будет значимым, и нулевая гипотеза не будет отвергнута (согласно нулевой гипотезе, оба алгоритма должны иметь одинаковый коэффициент ошибок).
Если в этих ячейках подсчеты не совпадают, это показывает, что обе модели не только совершают разные ошибки, но и фактически имеют разную относительную долю ошибок на тестовом множестве. В этом случае результат теста будет значимым, и мы отвергнем нулевую гипотезу.
Таким образом, мы можем отвергнуть нулевую гипотезу в пользу гипотезы о том, что два алгоритма имеют разную производительность при обучении на конкретном обучающем множестве.
В нашем случае мы получили, что обе модели делают похожее количество ошибок.
При этом если мы посмотрим на точность обоих классификаторов мы обнаружим, что один из них работает лучше
scores [['Linear SVM', 0.845], ['Random Forest', 0.89]]
Теперь мы можем сделать обоснованный вывод, что Random Forest справляется с задачей лучше.
Т-тест Стьюдента
Вторая категория тестов используется для более общего сравнения двух моделей, например, для определения того, какое дерево решений или нейронная сеть лучше подходит для данных. Они требуют множественных оценок каждой модели, которые можно получить с помощью кросс-валидации или повторной выборки (или, если алгоритм обучения стохастический, многократных повторений на одних и тех же данных). Затем тест сравнивает два результирующих распределения. T-тест Стьюдента является распространенным выбором для такого сравнения, но он надежен только в случае нормального распределения, что часто бывает не так.
Сделайте поправку на множественное сравнение
Все становится немного сложнее, когда вы хотите использовать статистические тесты для сравнения более чем двух моделей, поскольку проведение нескольких парных тестов сродни многократному использованию тестового набора - оно может привести к слишком оптимистичным интерпретациям значимости. В принципе, каждый раз, когда вы проводите сравнение двух моделей с помощью статистического теста, существует вероятность того, что он обнаружит значимые различия там, где их нет. Это отраженно в доверительных интервалах теста, который обычно устанавливается на уровне 95%: это означает, что в 1 случае из 20 тест даст ложный результат. Для единичного сравнения такой доверительный интервал может быть уровнем неопределенности, с которым можно смириться. Однако неопределенность накапливается. То есть, если вы проведете 20 парных тестов с уровнем достоверности 95%, один из них, скорее всего, даст вам неверный ответ. Такой эффект называется эффектом множественности, и является примером более широкой проблемы в науке о данных, известной как выкапывание данных (data dredging) или p-хакинг (Head et a., 2015).
Один из самых известных случаев связанных с эффектом множественности был даже награжден Шнобеелевской премией в 2012 году. Группа ученых обнаружила значительную мозговую активность у мертвого лосося. В этом исследовании авторы изучали активность мозга на 130 000 вокселей в типичном объеме фМРТ. Из-за большого количества тестов, вероятность получения как минимум одного ложноположительного результата была почти стопроцентной (так и произошло).
Чтобы решить эту проблему, можно применить поправку на множественные тесты. Наиболее распространенным подходом является поправка Бонферрони, очень простой метод, который снижает порог значимости в зависимости от количества проводимых тестов (см. Salzberg, 1997 и конкретный пример на Python).
Вообще, для решения проблемы эффекта множественности существует множество разных подходов, а споры о том, когда и где следует применять эти поправки ведутся до сих пор (обзор см. в Streiner et al., 2015).
Не доверяйте результатам community benchmarks
В некоторых проблемных областях стало обычным делом использовать эталонные наборы данных (benchmarks) для оценки новых моделей ML. На первый взгляд, раз все используют одни и те же данные для обучения и тестирования своих моделей, сравнения будут более прозрачными. К сожалению, этот подход имеет ряд существенных недостатков. Во-первых, если доступ к тестовому набору неограничен, то стоит исходить из предположения, что люди использовали его в процессе обучения, что приводит к data leakage.
Менее очевидная проблема заключается в том, что даже если каждый, кто использует данные, использует тестовый набор только один раз, в совокупности, тестовый набор используется сообществом много раз. В результате, сравнивая множество моделей на одном и том же тестовом наборе, становится все более вероятным, что лучшая модель просто слишком хорошо подходит к тестовому набору и необязательно обладает более высокой обобщающей способностью, чем другие модели.
По этой и другим причинам следует внимательно относиться к результатам, полученным с помощью эталонного набора данных и не считать, что небольшое увеличение производительности является значительным. См. Paullada et al., 2020 для более обширного обсуждения вопросов, связанных с использованием общих наборов данных.
Рассмотрите комбинации моделей
Хотя этот раздел и посвящен сравнению моделей, полезно держать в голове, что процесс машинного обучения не всегда заключается в выборе между различными моделями. Регулярно имеет смысл использовать комбинации моделей. Различные модели исследуют различные аспеты задачи; комбинируя их, вы можете иногда компенсировать слабые стороны одной модели за счет использования сильных сторон другой модели, и наоборот. Такие комбинированные модели известны как ансамбли, а процесс их создания известен как обучение ансамблей (см. обзор подходов к обучению ансамблей в Dong et al., 2019).
Основные вопросы в создании ансамблей касаются вопроса о том, как объединить различные базовые модели; подходы к этому варьируются от очень простых методов, таких как голосование или взвешенное голосование, до более сложных подходов, которые используют другую модель ML для объединения выходов базовых моделей. Этот последний подход называется стекинг.
Как сообщать о результатах
Для того, чтобы внести вклад в научное знание, вам необходимо предоставить полную картину вашей работы, охватывающую как то, что получилось, так и то, что не получилось. ML часто связан с компромиссами - редко бывает, что одна модель лучше другой во всех отношениях, и вы должны постараться отразить это, используя взвешенный подход к изложению результатов и выводов.
Будьте прозрачны
Прежде всего, всегда старайтесь быть прозрачным в отношении того, что вы сделали и что обнаружили - это облегчит другим людям использование ваших наработок. В частности, хорошая практика - делиться своими моделями в доступной форме. Например, если вы использовали скрипт для проведения всех экспериментов, опубликуйте его после публикации результатов.
Хорошим примером воспроизводимых исследований может служить AlphaFold - блокнот в Colab сопровождающий статью Highly accurate protein structure prediction with AlphaFold (Jumper et al., 2021). Во-первых, для того что бы им пользоваться не нужно ничего устанавливать; во-вторых, он снабжен более менее приличным графическим интерфейсом, что сильно упрощает использование для не-програмистов; и в третьих, при желании, код можно посмотреть "не отходя от кассы".
Важно, что бы другие люди могли легко повторить ваши эксперименты. Воспроизводимость придает убедительности вашей работе. Она также значительно облегчает людям сравнение моделей, поскольку им больше не придется все реализовывать с нуля (чтобы обеспечить справедливое сравнение). Само по себе знание того, что вам придется поделиться своей работой, также может побудить вас быть более осторожными, хорошо документировать свои эксперименты и писать чистый код.
Стоит отметить, что в ближайшем будущем вы, возможно, не сможете опубликовать работу, если ваш рабочий процесс не был надлежащим образом задокументирован и распространен - например, см. Pineau et al., 2020.
Сообщайте о результатах работы различными способами
Одним из способов достижения большей строгости при оценке и сравнении моделей является использование нескольких наборов данных. Это помогает преодолеть любые недостатки, связанные с отдельными наборами данных, и позволяет представить более полную картину работы вашей модели. Также хорошей практикой является представление нескольких метрик для каждого набора данных, поскольку разные метрики могут представить различные точки зрения на результаты и повысить прозрачность вашей работы. Например, если вы используете точность, то нелишним будет включить метрики, которые менее чувствительны к дисбалансу классов.
Если вы используете частичную метрику, такую как precision, recall, sensitivity или specificity, также включите метрику, которая дает более полное представление об уровне ошибок вашей модели. Убедитесь, что понятно, какие метрики вы используете. Например, если вы сообщаете F-score, уточните, идет ли речь о F1 или о каком-то другом балансе между precision и recall. Если вы сообщаете AUC, укажите, является ли это площадью под кривой ROC или кривой PR. Для более широкого обсуждения смотрите Blagec et al., 2020.
Не делайте обобщений, выходящих за рамки данных
Важно представлять действительные выводы, иначе вы собъете с пути других исследователей. Распространенная ошибка делать общие заявления, которые не подтверждаются данными, использованными для обучения и оценки моделей. Например, если ваша модель действительно хорошо работает на одном наборе данных, это не означает, что она будет хорошо работать и на других наборах данных.
Хотя вы можете получить более надежные выводы, используя несколько наборов данных, всегда существуют ограничения на выводы из любого экспериментального исследования. Этому есть множество причин (см. Paullada et al., 2020), многие из которых связаны с тем, как составлены наборы данных. Одной из распространенных проблем является предвзятость, или ошибка выборки: данные недостаточно репрезентативны для реального мира. Другая проблема - дублирование: несколько наборов данных могут не быть независимыми и иметь схожие предубеждения (т.н. biases).
Кроме того, существует проблема проверки качества, которая особенно актуальна для наборов данных глубокого обучения, где необходимость в большом количестве данных для обучения ограничивает объем проверки, которую можно провести. Суммируя сказанное, не преувеличивайте свои результаты и помните об их ограничениях.
Будьте осторожны, сообщая о статистической значимости
Мы уже обсуждали статистические тесты, и как их можно использовать для определения различий между ML-моделями. Однако статистические тесты не совершенны. Некоторые из них консервативны и склонны занижать значимость, другие либеральны и склонны значимость наоборот завышать. Таким образом, положительный тест не всегда означает, что что-то является значимым, а отрицательный тест не обязательно означает, что что-то значимым не является.
Кроме того, существует проблема использования порога для определения значимости; например, 95% доверительный порог (т.е. p-значение < 0.05) означает, что 1 из 20 случаев разница, отмеченная как значимая, не будет значимой. На самом деле, статистики все чаще утверждают, что лучше не использовать пороговые значения, а вместо этого просто сообщать p-значения и предоставить читателю самому их интерпретировать.
Помимо статистической значимости, необходимо также учитывать, действительно ли разница между двумя моделями важна. Если у вас достаточно данных, вы всегда можете найти значительные различия, даже если фактическая разница в производительности ничтожна. Чтобы лучше понять, является ли что-то важным, можно измерить размер эффекта (effect size). Для этого используется целый ряд подходов, ? статистика Коэна, вероятно, самая распространенная, но предпочтительнее более надежные подходы, такие как Колмогорова-Смирнова. Подробнее об этом см. в Betensky, 2019.
Посмотрите на свои модели
Обученные модели содержат много полезной информации. К сожалению, многие авторы просто сообщают показатели эффективности обученной модели, не давая никакого объяснения тому, чему она на самом деле научилась. Помните, что цель исследования не в том, чтобы добиться чуть более высокой точности, чем все остальные. Скорее, она заключается в том, чтобы генерировать знания и делиться ими с исследовательским сообществом. Если вы сможете это сделать, то вероятность того, что ваша работа получит достойную реакцию, значительно возрастет.
Хорошим примером может служить недавняя статья Causal ImageNet: How to discover spurious features in Deep Learning? (Singla et al., 2021), в которой очень подробно разбираются причинные и ложные признаки, на основании которых модель делает предсказания относительно содержания картинок.
")
Попробуйте "заглянуть внутрь" своей итоговой модели. Для относительно простых моделей, таких как деревья решений, также может быть полезно предоставить визуализацию ваших моделей (в большинстве библиотек есть функции, которые сделают это за вас). Для сложных моделей, таких как глубокие нейронные сети, рассмотрите возможность использования методов объяснимого ИИ (Explainable AI - XAI, рассмотрено в Belle et al., 2021); они вряд ли расскажут, что именно делает модель, но могут дать вам некоторые полезные идеи. Имейте в виду, что с XAI - тоже не все так радужно, и в нем есть подводные камни (см. разбор в Eshan et al., 2021).
")
На данный момент известно множество подходов для интерпретации предсказаний моделей, в том числе сложных моделей типа нейронных сетей. К таким относятся SHAP, LIME, Grad-Cam и многие другие. Существуют и методы, дающие более точную интерпретацию, но для конкретных моделей.
Если вы сможете изучить на что обращает внимание ваши модели - вы сможете: понять, какая модель обращает внимание на более разумные признаки; насколько устойчиво то, на какие признаки обращают внимание модели; найти уже упомянутые артефакты в данных.
Проведите абляционные исследования
Эксперименты, выявляющие артефакты данных и моделей, или абляционные исследования, как их называет Heinzerling, 2019 можно рассматривать, как часть процесса интерпретации модели.
Например, в статье Ishaq, 2016 авторы классифицировали рыб по изображению. Для того, что бы провести абляционное исследование, они маскировали разные части рыб в обучающей выборке (точнее сам сэт-ап эксперимента позволял находить такие кадры, где видна только голова или только хвост рыбы). В процессе экспериментов заметили, что классификатор в большей степени основывает свои предсказания на форме рыбьих голов, чем на форме их хвостов.
Еще в качестве абляции можно попробовать обучить модель на бессмысленных признаках, полученных перемешиванием исходных признаков. Это и многое другое подробно описано в Meyes, 2019.
Стоит учитывать, что в современном мире машинного обучения опубликовать статью без абляций становиться все более и более затруднительно.
Общие советы по написанию статей
Зачастую, выбирать журнал следует еще до того как закончена экспериментальная часть. Не откладывайте этот выбор слишком надолго, так как от него зависит что именно будет написано в статье. Например, какие-то журналы очень технические, и сосредоточены на деталях метода и методологии. Какие-то, наоборот просят выносить технические детали в Supplimentary Materials и требуют основного фокуса на применениях и/или выводах.
Как выбрать журнал?
Подумайте о людях, с которыми вы хотите поделиться своими результатами. Кто они? Чем они занимаются? Где работают? На каком языке разговаривают? Найдите несколько конкретных людей, соответствующих вашему описанию и спросите у них, какие журналы они читают. Скорее всего, наиболее подходящим для вас, будет тот журнал, который появлялся в ответах чаще всего.
Полезные инструменты для написания статей
Английский язык для многих из нас не является родным (и даже не тем языком, на котором мы свободно разговариваем). При этом английский - де-факто язык международной науки.
Вам повезло, если в ваших соавторах есть носитель языка, или коллега, который много лет работал в Европе или США, но чаще всего - доступа к таким коллегам у нас нет.
⚠️ DISCLAIMER: Всем, о чем пойдет речь дальше, следует пользоваться с большой осторожностью и не пренебрегать дополнительными проверками.
Хороший способ перевести текст с русского на английский (хотя луче бы вы сразу писали статью на английском) - воспользоваться переводчиком DeepL, он довольно неплохо справляется со сложными научными и техническими текстами, плюс в него встроено редактирование "на ходу" (то есть, на каждое слово можно посмотреть несколько вариантов перевода).
Уже написанные на английском тексты, часто требуется перефразировать, например, когда вы описываете результаты исследований других людей или просто считаете, что написанное не доносит тот смысл, который вы хотели донести. Тут на помощь приходит инструмент Wordtuna, который позволяет перефразировать любое предложение другими словами. Опять-таки, часто в предложенных вариантах встречается белиберда, так что пользуйтесь внимательно и аккуратно.
Часто, когда мы пишем на английском, у нас страдает грамматика и орфография (да что уж на английском, на русском тоже). С помощью Grammarly можно, как минимум, часть ошибок обнаружить и поправить.
Еще один инструмент, GPT-J, вообще не стоит рассматривать всерьез как инструмент для научной коммуникации. Тем не менее. им можно пользоваться для вдохновения. Например, часто мы начинаем писать предложение и еще не уверены (далее курсив - дополнено GPT-J), что сказать. Поэтому мы записываем слова одно за другим, в произвольном порядке. Затем мы смотрим на записанные слова. Затем мы начинаем думать о том, как связать эти слова друг с другом. Затем мы снова записываем предложение. Иногда мы вносим изменения. Иногда мы начинаем сначала. Иногда мы думаем, что это никуда не годится, и выбрасываем предложения.
В общем вы поняли идею.
Советы по структуре и стилю статьи
Статьи часто имеют жестко определенную структуру, но, все таки, наличие структуры не противоречит возможности рассказать захватывающую историю (т.е. такую, которая ясно передает научные знания и которую приятно читать). Давайте обсудим, как этого можно добиться.
Излагайте свою мысль четко
Подумайте, какое послание вы хотите донести до читателей.
Самая важная информация должна быть в основном тексте. Чтобы не отвлекать внимание, авторам следует помещать дополнительные материалы в соответствующие разделы статьи (supplimentary material или appendix).
Бесчисленное количество рукописей отклоняется из-за того, что разделы введение и обсуждение (introudction and discussion) настолько слабы, что очевидно, что автор не имеет четкого представления о существующей литературе и состоянии предметной области. Авторы должны продемонстрировать свои результаты в глобальном контексте, чтобы доказать значимость и оригинальность результатов.
Существует тонкая грань между спекуляциями и выводами, основанными на доказательствах. Автор может спекулировать в дискуссии - но не слишком много. Если обсуждение состоит из одних домыслов, оно не годится, поскольку не основано на опыте автора.
В заключении в одном-двух предложениях расскажите о том, какие исследования вы планируете провести в будущем и что еще необходимо изучить (outline).
Создайте логичную структуру
Структура имеет первостепенное значение. Попробуйте сделать так: в каждом абзаце первое предложение определяет контекст, основная часть содержит какую-то идею, а последнее предложение дает какое-то заключение. Для всей статьи введение задает контекст, результаты представляют содержание, а обсуждение подводит к выводу (совет из Mensh et al., 2017).
Очень важно сфокусировать вашу работу на одной ключевой идее, которую вы сообщаете в заголовке. Все в статье должно логически и структурно поддерживать эту идею.
Вы должны подвести наивного читателя к тому моменту, когда он будет готов усвоить то, что вы сделали. Как писатель, вы должны подробно описать проблему. Читатель не будет понимать, почему его должен волновать ваш эксперимент, пока вы не объясните ему, почему он должен сопереживать вашей работе.
Уверенно излагайте свои доводы
Ответ на один главный вопрос - "Что вы сделали? - является ключом к определению структуры статьи. Каждый раздел рукописи должен поддерживать эту одну фундаментальную идею.
Не бойтесь делать уверенные заявления, иначе получится вялое или запутанное письмо, которое звучит оборонительно, со слишком большим количеством оговорок и длинных списков - как будто вы пишите, чтобы отбиться от критики, которая еще не была высказана.
Задача читателя - обратить внимание и запомнить прочитанное. Задача писателя - сделать эти две вещи легкими для понимания.
Остерегайтесь "существительных-зомби"
Вспомните себя, когда вы читаете статьи других людей. Скорее всего вы заняты и устали. Вполне вероятно, что читатели ваших статей будут себя чувствовать так же.
Нет ни одной предпосылки к тому, что бы научные статьи были скучными, сухими и абстрактными. Люди любят и умеют рассказывать истории. Конечно, научная литература должна быть фактологической, краткой и доказательной, но это не значит, что она не может быть увлекательной. Если науку не читают, ее не существует.
Автор Хелен Суорд придумала выражение "существительные-зомби" для обозначения таких терминов, как "внедрение" или "применение", которые высасывают кровь из активных глаголов. Постарайтесь задействовать эмоции читателей и избегать формального, безличного языка. Тем не менее соблюдайте баланс. Не сенсационизируйте науку.
Авторы научных статей должны с осторожностью относиться к "творчеству". Креатив - это конечно хорошо, но цель научной статьи - передать информацию. Вот и все. Изюминки могут отвлекать. Сделайте текст настолько простым и понятным, насколько это возможно.
Ориентируйтесь на широкую аудиторию
Недавнее исследование (Girolamo et al., 2017) показывает, что статьи с четкими, лаконичными, декларативными заголовками имеют больше шансов получить отклик в социальных сетях или популярной прессе.
Излагайте свою точку зрения четко и кратко - по возможности неспециализированным языком, чтобы читатели из других областей могли быстро понять ее смысл (или если термины использовать все-таки приходится - поясняйте их для читателей, которые могут быть менее знакомы с темой).
Если вы пишете доступным для неспециалистов языком, вы открываете себе возможность для цитирования экспертами из других областей.
Cover letter
И вот, наконец то, статья дописана и пришла пора ее отправить в журнал. Во время подачи, вас попросят прислать сопроводительное письмо (Cover Letter) для редактора. Сопроводительные письма, подчеркивающие выводы исследования и сообщающие детали, имеющие отношение к процессу рецензирования, являются важной частью подачи рукописей, даже если их читают только авторы и редакторы. Однако написание этих писем может показаться дополнительным бременем. Почему писать хорошие письма все таки важно?
Сопроводительные письма могут предоставить редакторам ценный контекст (соответствует ли исследование тематике журнала, место выводов по отношению к открытым, важным научным вопросам).
Не ломайте голову над тем, как адресовать письмо - достаточно простого "Уважаемый редактор" (можно адресовать конкретным редакторам, особенно если вы уже общались с ними ранее). Постарайтесь перед отправкой убедиться, что письмо адресовано правильному журналу.
Будьте лаконичны. Это ваш шанс непринужденно побеседовать о своей работе с редактором, и одной страницы обычно бывает достаточно. Воодушевление - это нормально (вы же рассказываете о конечном результате тяжелой работы), но гиперболизацию следует свести к минимуму. Гораздо полезнее объяснить, почему исследование представляет собой важный научный результат, вместо того, чтобы постоянно заявлять об этом. Если работа имеет более широкое общественное или политическое значение за пределами вашей области науки, это также стоит упомянуть. Сосредоточьтесь на самом исследовании, а не на резюме авторов.
Ссылки на другие исследования не обязательны, но могут быть полезны в некоторых обстоятельствах. Сопроводительные письма - подходящее место, чтобы объяснить, как текущее исследование связано с другими опубликованными или (особенно) еще не опубликованными работами вас или ваших соавторов. Предупредите, если публикация вашего исследования будет зависеть от публикации другого.
При выборе работ для рецензирования редакторы учитывают новизну, поэтому краткое обсуждение других исследований с похожими выводами может быть уместным, если совпадения существенны.
В письме порекомендуйте несколько релевантных рецензентов, которые охватывают диапазон тем и методов исследования. Это может помочь ускорить процесс рецензирования. Предлагаемые рецензенты в идеале не должны публиковаться ранее вместе с авторами вашего исследования или, по крайней мере, не публиковаться в течение некоторого времени, а также не должны быть связаны с теми же учреждениями, что и авторы рукописи.
Не стесняйтесь исключать рецензентов с которыми у вас может быть личный или профессиональный конфликт интересов, но делайте это в разумных пределах. Журналы не обязаны объяснять причины исключения, особенно если в список включено всего несколько имен. Исключать целые лабораторные группы и их выпускников не рекомендуется.

