Это первая статья - историческая ретроспектива технологий и интерфейсов автоматизации сети. Если хочется более практического разбора, я отсылаю читателя к статье-спутнику, в которой мы собираем лабу, дёргаем апишки, настраиваем коробки.
В этой же разбираемся, как мы оказались в том месте, где мы находимся, и куда ведёт нас этот путь. Практическую пользу вам принесут только обе прочитанные статьи. Вторая без первой будет непонятна. Первая без второй - беллетристика.

Когда началась история сетевой автоматизации?
С Ansible в 2018? С ним она явно получила ускорение благодаря безагентной природе.
Не. До него были голые языки на букву "P": Python, Perl, PHP.
С NETCONF? Точно нет, CLI ещё мой дед парсил. А уж сколько expect'ов там поработало…
SNMP - вот что приходит на ум в качестве первого подхода - он родом из 90-х.
Однако как насчёт перехода от коммутации каналов к коммутации пакетов? Нельзя ли назвать динамическую сеть, не требующую мгновенного ручного вмешательства при обрывах, разновидностью автоматизации?
А первый декадно-шаговый искатель, разработанный Строуджером в 19-м веке и раз и навсегда избавивший мир от ручного труда телефонисток?
Да и в целом даже сам факт появления телефонных станций взамен почты, курьеров и гонцов?
Весь наш мир последние лет 300 безостановочно гонится за ускорением. Людей становится всё больше (Индия вон обогнала уже Китай), но их труд всё дороже (не в Индии). И в этом помогает автоматизация.
300 лет! Тем временем в сфере сетевых технологий сложилось мнение, что тут всё замерло, мы топчемся на месте, изобретая велосипеды. Но это лишь из-за того, что мы берём довольно короткий период времени и гораздо больший акцент делаем на текущем моменте, нежели на тенденции.
Как говорится, мы склонны переоценивать краткосрочные последствия и недооценивать долгосрочные.
Все статьи АДСМ

В этой статье посмотрим, сколько всего в эти 30 лет уместилось.
А уместилось немало.
Содержание
One CLI to rule them all
С начала времён и до сего дня.
Сегодня бумажные деньги - это артефакты уходящей эпохи. Мы не можем в одночасье от них отказаться - даже в самых прогрессивных странах, потому что есть ещё огромный хвост людей, не готовых перейти на безналичный расчёт.
Но купюры были естественным и незаменимым средством ещё лет 10 назад. Они пришли взамен монетам из золота и серебра, которые были естественны лет 300 назад. А те заменили собой натуральный обмен, который был естественным несколько тысяч лет назад.
Так и командная строка в своё время являлась совершенно естественным методом взаимодействия с сетевым железом. Вбивали же люди в nix'ах команды в терминал? Ну так и маршрутизатор - тот же nix.
Это самый понятный человеку-инженеру способ общаться с устройством.
Начал набирать команду, сделал табуляцию, посмотрел список доступных аргументов, продолжили. Возникла ошибка при выполнении - сразу же текст в терминале отображается - принимаешь меры. Понятно, удобно, интерактивно. Нет ничего лучше для интерфейса человек-устройство. Интерфейса, который сегодня стремительно теряет свои позиции в настройке сервисов.
И если в сфере серверов уже многие годы сумасшедшими темпами развивается RPC и IaC, то в области сетевых технологий всё как-то ни шатко ни валко. На самом деле на сегодняшний день ситуация немногим менее печальная, чем лет 15 назад.
Командный интерфейс (CLI) реализует императивный интерфейс. А мы во всех сферах стремимся к декларативности.
CLI может быть структурированным и логичным, как на Juniper. Может быть как на Cisco/Huawei/Arista. Он может поддерживать транзакции посредством коммитов, а может применять команды по мере их ввода.
Коммиты могут быть реализованы через подмену running конфигурации candidate, через применение только разницы между текущей и целевой или через последовательное применение введённых прежде команд.
Команды затем транслируются в вызовы какого-то внутреннего API, который может быть понятен и даже в каком-то смысле документирован (привет, Juniper) или представлять из себя чёрный ящик (йо, хуавэй, как жизнь?).
Но главная суть не меняется - если ты хочешь что-то настроить, ты подключаешься по ssh, вводишь команды - читаешь ответ, предпринимаешь дальнейшие действия. То есть максимально понятно для человека и абсолютно неудобно для взаимодействия машина-машина. Все эти приглашения, промпты, текстовые выводы, ошибки и предупреждения породили expect'ы, textfsm'ы, napalm'ы и триста способов заставить скрипт вести себя как человек.
Но самая главная проблема CLI - это фундаментальные различия в синтаксисе и семантике у различных вендоров. А порой даже в различных версиях.
Не существует такого способа, который позволил бы декларативно объявить - хочу вот именно такую конфигурацию BGP с такими пирами и таким набором политик, и не хочу вычислять, что мне нужно для этого добавить, а что удалить.
И кроме всего прочего долгое время не существовало надёжного инструмента доставки и применения конфигурации - каждый изгалялся в меру своей фантазии.
Спасибо Майклу Дехану, вендорам и сообществу, попытка создать такой инструмент была предпринята - Ansible. Да, к нему много (у кого-то очень много) вопросов. Да, он не решает большей части проблем, озвученных выше. Но по факту это лучший опенсорсный инструмент для применения конфигурации на сетевое железо (ну, кроме Nornir), и Ansible - спасение для многих сетевых инженеров. Сложить весь прод одним нажатием Enter никогда прежде не было так просто.
Ещё одна особенность CLI - отсутствие контроля состояния. CLI делает то, что ему сказали. Если ты не побеспокоился о том, чтобы удалить лишнего пира специальной командой - он и не почешется. Контроль состояния - ответственность инженера.
С другой стороны CLI - это на сегодняшний день (и долго ещё так будет) единственный вариант, который на 100% современных железок позволит настроить 100% предоставляемой ими функциональности.
Учитывая, что компаний, которые сейчас строят сеть с нуля и могут выбрать только то оборудование, которое поддерживает полноценный NETCONF/gNMI, очень и очень немного, всем остальным нужно уметь поддерживать зоопарк оборудования разного возраста и уровня.
Собственно в Яндексе именно тем, что CLI работает в буквальном смысле на всём, и воспользовались. Аннушка настраивает сетёвку именно через CLI.
Что можно утверждать однозначно - CLI как таковой никуда не денется никогда. Даже в эпоху полностью автоматизированных сетей, командная строка никуда не уйдёт из сферы диагностики.
Он, возможно, будет глубоко запрятан, или он трансформируется в полноценную линуксовую консоль, но как средство управления он останется.
Однако факт того, что все способы автоматизации чего-либо через CLI - это попытка написать скрипт, который будет прикидываться человеком и предугадать все возможные исключительные ситуации и варианты ответа операционной системы, заставляет писать очень изощрённые программы и постоянно их адаптировать под изменяющееся от версии к версии поведение и синтаксис новых вендоров.
А сколько радости представляет как крафтинг, так и парсинг текста, вы можете представить.
Желание унифицировать подходы и сделать стандартизированным интерфейс взаимодействия появилось не вчера. О нём думали уже в 80-е, что и породило очень удачное решение - SNMP.
SNMP - и не simple, и не management, и не short term
Бунтарские 80-е - лихие 90-е.
Это была достаточно смелая и, в некотором смысле, успешная попытка создать единый стандарт взаимодействия с сетевым устройством.
В 80-е годы было уже вполне понятно, что сети - бурнорастущая отрасль, в которой уже сейчас хаотически складываются подходы к управлению.
И вот умники в IAB (Internet Activities Board) крепко призадумались и 21-го марта 1988 года, собравшись в тогдашнем зуме (без шуток, не офлайн), постановили много важного стратегического про будущее систем управления интернетом. Ох они тогда напридумывали!
Результаты встречи они сели, записали и превратили в RFC1052.
Они уже тогда действительно проектировали штуки, которые должны были не дать превратиться системам управления в то, во что они всё же превратились.
Как иронично теперь читать это послание из 80-х:
(i) Future Internet development is a joint interest of the R&D community, the vendor community and the user community. (ii) We still don't have a common understanding of what [Inter]Network Management really is. (iii) We will learn what [Inter]Network Management is by doing it. (v) Define the Management Information Base for TCP/IP suite NOW! (vi) Seek a seat for IETF on ANSI, ISO and/or CCITT Удачи вам там, пацаны, в будущем…
Но работа закипела. RFC выходил за RFC. А количество рабочих групп не оставляло шансов для провала.
Что любопытно, так это то, что SNMP по их задумке был временным протоколом, решающим насущные нужды вендоров и операторов в перспективе нескольких лет. А в дальнейшем все должны были перейти на ISO CMIP/CMIS (RFC1095 и RFC1189). Общими для них оставались MIB (RFC1066) - спецификации, описывающие формат данных.
Уверен, что уже тогда не всем эта идея пришлась по душе.
В те дни человечество ещё верило в ISO.
CMIP/CMIS - Common Management Information Services/Common Management Information Protocol - это такая же несостоявшаяся вещь, как OSI. Здорово всё напланировали, но временный SNMP заполонил всю планету.
Есть и другие слова, выдуманные в те дни, которые мы сейчас нигде в обиходе не используем: HEMS, SGMP, NETVIEW, TNM, LANMANAGER, Network Computing Forum "Fat Document"...
SNMP именно потому и был Simple, что на горизонте маячил Common. И его планировали держать "Simple", пока не откажутся. А вовсе не потому что он сам по себе был прост. Кажется, нам, как цивилизации, ещё повезло, что на смену SNMP не пришло что-то не столь Simple.
Итак, SNMP победил, если это можно считать победой. А другие рабочие группы распустили.
MIB - являл собой спецификацию, говорящую как системе управления, так и сетевому устройству, как собирать и интерпретировать SNMP-сообщения.
То есть на одной стороне есть инструкции того, как собрать пакет, на другой - как его прочитать. Остаётся только подставлять переменные и посылать через SNMP.
Ну какова красота?! Никакого чтения документации, никакой человеческой интерпретации - только строгое следование спецификации. И это начало 90-х!
Скажу вам больше - те же парни из IAB, ещё до того, как Cisco начала паровозить тему с SNMP, придумали SMI - Structure of Management Information - по сути язык моделирования данных - то, как именно данные будут структурированы в MIB.
Для нас не очень важно что и в течение какого времени нужно употреблять, чтобы написать и прочитать написанные на языке ASN.1 модели SMI. Для нас важно, что SMI дал жизнь YANG'у. Всё же не вся работа тогдашних групп была в стол. Но об этом позже.
Уже тогда, в 90-е, все хотели сделать что-то универсальное и отвязаться от вендорской специфики, но настойчивых попыток не предпринимали, а вендоры в погоне за time to market были ещё меньше заинтересованы вкладываться в стандартизацию того места, где им не придётся стыковаться друг с другом. Поэтому единой модели тогда не появилось.
Однако теперь следите за руками: к концу 90-х у нас уже были:
Протокол - SNMP;
Спецификации - MIB;
Язык их моделирования - SMI;
Возможность стримить данные с железки на NMS - Trap'ы (ну серединка на половинку, конечно, но всё же);
Целая пачка инструментов, утилит и NMS, работающих с MIB и SNMP - snmpwalk, MIB browser;
Желание вендоров поддерживать это и выпускать MIB'ы для каждой новой версии вовремя.
По всей видимости мы были просто в шаге от дивного мира с единым фреймворком для сетевой автоматизации.

Но добавляя ещё один пункт:
Никто из вендоров при этом так и не поддержал полноценное конфигурирование через SNMP.
мы получаем ситуацию, в которой мы находимся прямо сейчас. Та-дам!
Но даже без этого в силу сложности (S for Slozhnost), вопросов к архитектуре, безопасности, транзакционности, нечитаемости спецификаций, непрогнозируемости результатов, невозможности проиграть изменения повторно, UDP в качестве транспорта и многим другим, SNMP нашёл применение лишь в задачах сбора данных с сетевых устройств и в крайне вырожденных случаях для настройки точечно тех или иных вещей.

Впрочем сегодня даже в вопросах мониторинга SNMP скромно уступает место NETCONF и gNMI.
Смахнули скупую слезу и забыли! И про SNMP и про CMIP/CMIS. Не забываем только про SMI.
Переходим к современности.
API
Давайте на парсек поднимемся над нашей ежедневной рутиной и взглянем на сеть с расстояния. И тогда можно увидеть, что программную работу с сетевым оборудованием следует рассматривать как взаимодействие с удалённой системой (чем она и является). А уже много лет назад для этого придумали термин - API.
То есть, если мы хотим чего-то от этой системы, мы используем известный интерфейс, для которого описано, как и что мы должны сделать, чтобы добиться желаемого результата. API - это широкий и абстрактный термин, сам по себе не говорящий ничего о схеме данных, о формате и протоколах взаимодействия - просто программный интерфейс приложения - не человеческий, а программный.
И под одним этим зонтичным термином скрываются совершенно разные виды:
REST API
GraphQL
XML RPC
Linux Kernel API
SOAP
CORBA
PCI шины
JSON RPC
Android API
И сотни других

Одни из них, такие как REST оперируют ресурсами и представляют набор операций над ними, в случае REST: CRUD - Create Read Update Delete. То есть вы можете создать (Create) ресурс "билет на linkmeetup" и скачать (Read) его далее в любой момент. С REST мы уже разбирались как-то.
Другие виды API оперируют функциями, и позволяют на сервере запускать те или иные оговоренные программы. К последним относится класс API, который можно назвать RPC.
RPC - Remote Procedure Call
Этот термин родом из языков программирования. Ещё на рубеже 50-60-х годов языки вроде Fortran II и ALGOL ввели в обиход разработчиков процедуры (они же функции). С тех пор они везде - большинство языков - процедурные. Любое действие - это вызов процедуры - Procedure Call. И когда-то эта процедура должна была находиться где-то в том же модуле или в соседних, но точно рядом и в том же окружении. Но почему бы не слать вызов с параметрами на удалённую машину, где мы хотим что-то выполнить?
Например, мы могли бы по HTTP/FTP скачать несколько гигов данных sFlow с сервера и проанализировать их локально, а можем отправить сигнал на сервер, чтобы сложную статистику вычислил он сам и вернул результаты в ответе. Так вот второе - это удалённое исполнение кода.
Анналы истории говорят, что в в 1981 году Брюс Джей Нельсон, работая в Ксероксе, изобрёл концепцию и термин RPC - Remote Procedure Call.
RPC - удивительный клиент-серверный механизм, который позволяет запустить исполнение кода процедуры на другой машине так, словно бы он исполнялся локально. То есть разработчик просто привычным образом обращается к процедуре, не задумываясь о том, где и как она исполняется - главное, чтобы она вернула ответ. А программа уже сама реализует взаимодействие с удалённой машиной.
Прелесть этого подхода в том, что он, во-первых, позволяет скрыть удалённый характер работы. А, во-вторых, на той, другой, стороне совершенно неважно, какая операционная система, архитектура, язык программирования и окружение - главное, чтобы они подчинялись одному протоколу.
Можно провести аналогию с TCP - не важно, какие операционные системы на хостах, желающих друг с другом общаться, - важно, чтобы они следовали спецификациям протокола TCP и его конкретной реализации - и тогда данные, отправленные одним хостом, будет возможно интерпретировать на другом.
Так в случае RPC, из-под винды в питоне, например, вы можете исполнить удалённую программу, написанную на Go, запущенную на линуксе. И никто вам не сможет помешать!
Но что, по большому счёту, мы делаем, когда, зайдя по SSH, выполняем какую-то команду на коммутаторе или маршрутизаторе? Запускаем определённый код.
Например, сообщаем подсистеме BGP, что нужно теперь пробовать установить соединение с новым пиром.
Только представьте, как было бы восхитительно, если бы для вызова этого кода, не нужно было заходить на железку по SSH и вбивать команду?!
Взаимодействие между приложениями через RPC используется преимущественно в условиях, когда требуется обеспечить тесную связь между ними, когда они все формируют единую систему.
В то же время REST API наоборот требуется, когда компоненты должны быть достаточно изолированы и развиваться независимо.
Так REST обычно предоставляют внешним клиентам, B2B, смежным, но малосвязанным командам. Например, публикация постов в соц.сетях или агрегаторы авиабилетов при обращении к сервисам авиакомпаний. А RPC - там, где компоненты составляют часть чего-то большего, например, узлы банковской системы или микросервисные архитектуры.
В целом RPC - это концепция, не говорящая ничего о реализации. Она постулирует, что на стороне клиента есть так называемый стаб (stub) - фрагмент кода, который реализует взаимодействие по RPC. Именно стабы делают для разработчика прозрачным вызов функции - из приложения вызывается этот стаб с набором параметров, а уже стаб делает удалённый вызов.
Ключевая часть RPC - спецификация - штука, которая на стороне сервера и клиента определяет, как работать с данными - как упаковать, как распаковать. Без участия человека, конечно же.
Язык, на котором пишется спецификация - IDL - Interface Definition Language. Иными словами, на IDL пишется спецификация, на основе которой создаются и серверный интерфейс, и клиентский стаб. Это может быть, например, набор классов в питоне, имеющих функции для удалённого вызова, с которыми разработчик работает так, словно всё происходит локально - для клиента. И набор объектов Go - для сервера.
Наевшись с CLI и SNMP, сетевики придумали два протокола, которые используют под капотом RPC и при этом позволяют управлять сетевым железом:
NETCONF
gRPC
NETCONF
Сытые 0-е и по ныне
Если вам по какой-то причине кажется, что стандарты рождаются где-то в недрах институтов, оторванных от жизни, то послушайте вот эту историю. Скорбно при этом помним про ISO.
В 1996 выходец из Ксерокса Прадип Синдху и Скот Кринс из StrataCom, купленной Циской, основали Juniper Networks. Идея создания мощного пакетного маршрутизатора пришла в голову Синдху, и он стал CTO компании, а второго наняли на роль CEO.

Вместе они создали легендарный М40 и лучший в мире интерфейс командной строки. До сих пор никто не сделал ничего лучшего - все только повторяют. Операционка, предоставляющая клиенту обычный текстовый интерфейс, на самом деле перекладывает команды в XML, который используется для управления оборудованием..
Так вот, их CLI и способ взаимодействия его с системой оказался настолько естественным и удачным, что его и положили в основу стандарта NETCONF в 2006-м году. Не без участия Juniper Networks, конечно же, появился RFC4741. Будем честны, один только джунипер там и постарался в практической части. И то тут, то там будут проскакивать его куски, начиная с set и заканчивая candidate config.
Вот как он был определён в нулевых:
Abstract The Network Configuration Protocol (NETCONF) defined in this document provides mechanisms to install, manipulate, and delete the configuration of network devices. It uses an Extensible Markup Language (XML)-based data encoding for the configuration data as well as the protocol messages. The NETCONF protocol operations are realized on top of a simple Remote Procedure Call (RPC) layer.
И определение с тех пор не менялось - вся суть NETCONF в этом параграфе.
Но как так получилось, с чего началось? Да с того, что в начале 2000-х IAB проснулся в одно недоброе утро и осознал, что все планы по CMIP мир провалил, SNMP прорастил свои корни глубоко и перестал быть Simple, никто из вендоров так и не реализовал на 100% его поддержку, в самой аббревиатуре SNMP "M" вместо "Management" стала обозначать "Monitoring", и к тому же единой модели данных конфигурации не получилось. Хуже того - появился этот выскочка Juniper, который везде суёт свой нос.
В общем умники из IAB крепко призадумались. И собрались снова - на этот раз в офлайне 4-го июня 2002-го года в Рестоне (это в Штатах - любопытный городок - почитайте), чтобы "продолжить важный диалог, начатый между операторами и протокол-девелоперами".
Сели, похаяли SNMP, покекали с аббревиатур COPS, SPPI, PIB, CIM, MOF и записали это всё в тик-ток RFC3535.
Выхлопом этой встречи стали 33 наблюдения и 8 рекомендаций. Среди них есть действительно важные, определившие наше настоящее.
1. Программные интерфейсы должны предоставлять полное покрытие, иначе они не будут использоваться операторами, поскольку они будут вынуждены использовать CLI. 5. Необходимо строгое разделение между конфигурационными и операционными данными. 8. Необходимо иметь возможность выгрузить и загрузить конфигурацию в текстовом формате в единообразной манере между всеми вендорами и типами устройства. 9. Желательно иметь механизм доставки конфигурации в условиях транзакционных ограничений. 14. Необходимо, чтобы устройства поддерживали как программный, так и пользовательский интерфейс. 15. Внутренние операции на устройстве должны быть одинаковы как для программного, так и для пользовательского интерфейсов. 26. Должна быть возможность произвести операцию над указанной секцией конфигурации. 27. Должна быть возможность выяснить возможности устройства. 28. Необходимы безопасный транспорт, механизмы аутентификации и авторизации, поддерживаемые текущей инфраструктурой. 30. Полная конфигурация устройства должна быть применима через один протокол.
Часть из них мы воспринимаем сегодня как самоочевидное, мол, а как вы ещё иначе могли бы такое сделать? Но это не воспринималось так тогда. Просто вспомним как устроен SNMP :)
А ещё были явно полезные рекомендации:
Рабочее совещание рекомендует прекратить форсить рабочие группы предоставлять конфигурационные MIB'ы;
Рабочее совещание рекомендует не тратить время на CIM, COPS-PR, SPPI PIB.
В общем-то какие претензии к SNMP и его компании заставили уважаемых людей собраться на три дня?
Проблемы масштабирования. Забирать большие объёмы данных с большого количества устройств он не был рассчитан.
Транзакционность изменений на устройстве, и тем более на сети, должна была поддерживаться не протоколом и устройством, а системой инструментов.
Откат также лежал на инструментах.
Writable MIB не покрывали большей части задач по настройке устройства.
Весь этот куст OID'ов был крайне сложночитаем для человека. Понять, что произойдёт после работы скрипта было очень сложно. Сколькие из вас отчаялись, пытаясь его понять?
Не было никакого инструмента, который позволял бы повторно выполнить те же действия идемпотентно на этом же устройстве или на другом.
Контроль состояния тоже отсутствовал.
В итоге протокол, призванный решать вопрос автоматизации, не особо-то для этого подходил. Короткий итог встречи: IETF всё это время что-то там придумывал, разрабатывал, чтобы сделать жизнь операторов проще, а те не будь дураками, пришли и наконец сказали, что, мол, вы тут штаны просиживаете, а ничего полезного для нас не делаете, а делаете вы бесполезное! И ISO туда же!
И в этот момент Juniper из-за угла приоткрывает полу своего XML-API. И он оказывается настолько более лаконичным (это XML-то!) и удобным, что рабочая группа внезапно решает принять его концепции в качестве стандарта NETwork CONFiguration protocol - RFC4741 . Упор на Configuration в названии - это, видимо, гиперкомпенсация отсутствия режима конфигурации в SNMP.
Вот так в итоге скромно упомянут джунипер в этом RFC:
In the late 1990's, some vendors started to use the Extensible Markup Language (XML) [XML] for describing device configurations and for protocols that can be used to retrieve and manipulate XML formatted configurations.
А через 5 лет, в 2011, исправленное и дополненное издание вышло под номером RFC6241. Там уже потрудились несколько университетов и компаний. Одной из них стала восходящая звезда сетевой автоматизации Tail-f, купленная и погубленная в 2014-м году циской.
И вот в операторские сети на белом коне въезжает NETCONF.
Работает по SSH (и не только),
Представляет данные в структурированном виде,
Разделяет конфигурационные и операционные данные,
Имеет несколько операций над данными: create, merge, replace, delete, remove,
Может обеспечить контроль целевого состояния конфигурации,
Поддерживает концепцию нескольких версий конфигурации (datastores),
Может поддерживать commit конфигурации. Обеспечивает транзакционность,
И вообще красавчик.
Причём Juniper его поддерживает с нулевого дня. И в полной мере, потому что для него это максимально естественно - это и есть его API. А вот внутренний API той же Циски или Хуавэя не ложится так гладко на XML и какую-либо простую схему. Для них поддержка NETCONF - это большая работа, которую они выполняют с переменным успехом. Коммиты, операция replace - это всё даётся тяжело. А именно в них вся сила.
Datastores - это различные версии конфигурации на устройстве: running, candidate, saved и, возможно, другие. Они позволяют не менять на лету работающую конфигурацию.
Commit обеспечивает три буквы ACID - Атомарность, Консистентность и Изолированность.
Операция Replace - мощнейшая штука - позволяет заменять всю или часть конфигурации на новую.
Мы привыкли, что в CLI нам нужно сформировать список команд, добавляющих новую конфигурацию, и команд - удаляющих старую - ненужную. Довольно простая операция для человека, но чудовищно сложная для автоматики. Мы настолько привыкли, что это даже не вызывает раздражения у нас. А с NETCONF replace - мы просто суём ту конфигурацию, которую хотели бы видеть, а коробка сама считает, что нужно сделать, чтобы к ней прийти из текущего состояния. Это и есть тот самый декларативный путь, к которому мы так стремимся.
Для работы с NETCONF есть библиотеки для питона (и синхронные, и асинхронные), для го, плагины для Ансибл. Вроде бы всё - бери и пользуйся. Но не все производители его поддерживают. И совсем немногие поддерживают его в полной мере. Где-то нельзя настроить DHCP-Relay, где-то нет секций IPv6-vpn AF в BGP, где-то replace не поддерживается или поддерживается, но работает через delete/create - ух, неспасибо за это.
В итоге пара пунктов из вышеупомянутого RFC3535 нарушены: не всё можно настроить через этот новый протокол, а для настройки всех возможных функций нужен как минимум CLI.
Но своё место NETCONF уже прочно занял и будет дальше только расширять и углублять. Несколько вендоров действительно его поддерживают в полной мере. А на других точечные операции всё равно многократно удобнее через программный интерфейс со структурированными данными выполнять. Плюс своё давление оказывают крупные заказчики, требующие его.
RESTCONF
Буйные 10-е и забыли
The workshop recommends, with strong consensus from the operators and rough consensus from the protocol developers, that the IETF/IRTF should not spend resources on developing HTML-based or HTTP-based methods for configuration management.
SSH - это хорошо. Но на сетевую автоматизацию случился спрос, а за ним наплыв сил разработчиков. А вот эти разработчики хорошо шарят в REST, но на курле крутили все эти наши SSH и парсинг текста. В компаниях, где начинают заниматься автоматизацией сети, обычно уже есть свой штат разработчиков, инструменты, практики. И они в лучшем случае рассматривают сеть, как ещё одни сервера, а то и ещё один сервис.
И вот REST API с CRUD им очень знаком.
Вот и решили парни из циски, джунипера и tail-f: "а почему бы не запилить REST API в сетевые коробки?". Ну пошли и запилили - делов-то. И назвали RESTCONF - всё ещё отзываются боли SNMP.
Драфт был опубликован в 2014-м, а в 2017 мир увидел RFC8040.
Это помесь RESTAPI и NETCONF, которая была призвана упростить управление сетью для WEB-приложений.
Внутри идеологически это NETCONF с его datastores и способами работать с конфигурацией, однако в качестве транспорта - HTTP с набором операций CRUD, реализованных через стандартные методы (GET, POST, PUT, PATCH, DELETE).
Конфигурационные данные передаются в формате JSON или XML. В качестве модели данных используется только те, что написаны на языке YANG - тут уже никакой самодеятельности.
С самого начала RESTCONF не затевался как замена NETCONF, а только как более удобный для WEB-приложений способ работать с сетевыми устройствами. То есть они должны сожительствовать. При этом обычно на устройстве реализуется один бэкенд, обрабатывающий запросы на работу с конфигурацией и опер.данными от разных фронтов - NETCONF или RESTCONF. То есть в основе одни и те же datastores, один и тот же движок, вычисляющий конфигурационные дельты, но сложность транзакционности и нескольких разных видов конфигураций (running, candidate, saved) от пользователя скрыта в случае RESTCONF.
С другой стороны отсутствие в выдаче поисковиков хоть сколько-то серьёзных работ по автоматизации с помощью RESTCONF и даже популистских статей от больших игроков говорит о том, что это всё не более чем баловство. И я намеренно не пишу слово "пока". Лично я в него не верю.
При этом CRUD не очень гладко ложится на RPC-подход, да и в идее держать открытым на сетевом железе HTTP есть что-то противоестественное, согласитесь? Нет? Ну ладно.
Просто жаль сил, вложенных в этот протокол. Потому что на пятки ему наступает gRPC/gNMI
Однако вернёмся к NETCONF: в чём его фундаментальная проблема? Да в том, что он вышел в мир один одинёшенек. Не было предложено никаких схем, языка, стандартов для семантики. И всё пошло вразнос.
Модели были нужны, но языка для их описания не было. До 2010 (на самом деле больше) каждый вендор писал их кто во что горазд.
YANG, который (по-)меняет мир
Очень странно это, конечно, вышло. Для SNMP IETF много думали, работали и выпустили сначала язык спецификации SMI, а потом даже замахнулись на SMIng - nextgen, так сказать.
То есть необходимость языка описания спецификации была очевидна уже тогда - в 90-е, однако к NETCONF язык не приложили почему-то.
Впрочем это всё-таки довольно быстро стало понятно - в 2008 из осколков рабочих групп по SNMP слепили рабочую группу IETF NETMOD, которая в срочном порядке занялась разработкой языка. Не мудрствуя лукаво, они взяли синтаксис SMIng и "адаптировали" его. Уже в 2010 они выпускают YANG 1.0, а в 2016 - 1.1.
YANG - Yet Another Next Generation - по сути - это язык описания моделей. То есть это не данные и даже не конкретные модели - только язык. Как русский - это не произведение и не слова.
А уже с помощью этого языка создаются непосредственно модели, которые обычно так и называют - YANG-модели. Модели на языке YANG далее могут преобразовываться в XML/JSON-схемы или в gRPC Protobuf'ы или во что угодно другое, что станет спецификацией для протокола. И уже на основе этой спецификации можно генерировать конфигурации или проверять их валидность.
Четырёх лет задержки оказалось достаточно, чтобы вендоры понаделали кучу своего, на что завязали инструменты и они сами, и их заказчики. Четыре года задержки откинули внедрение Model-Driven подхода лет на десять. Только сегодня хоть что-то похожее на практическое применение начинает выходить за пределы гуглов и фейсбуков.
Кстати, будьте аккуратнее, когда ищете "yang models" в интернетах, серьёзно вам говорю.
Виды моделей
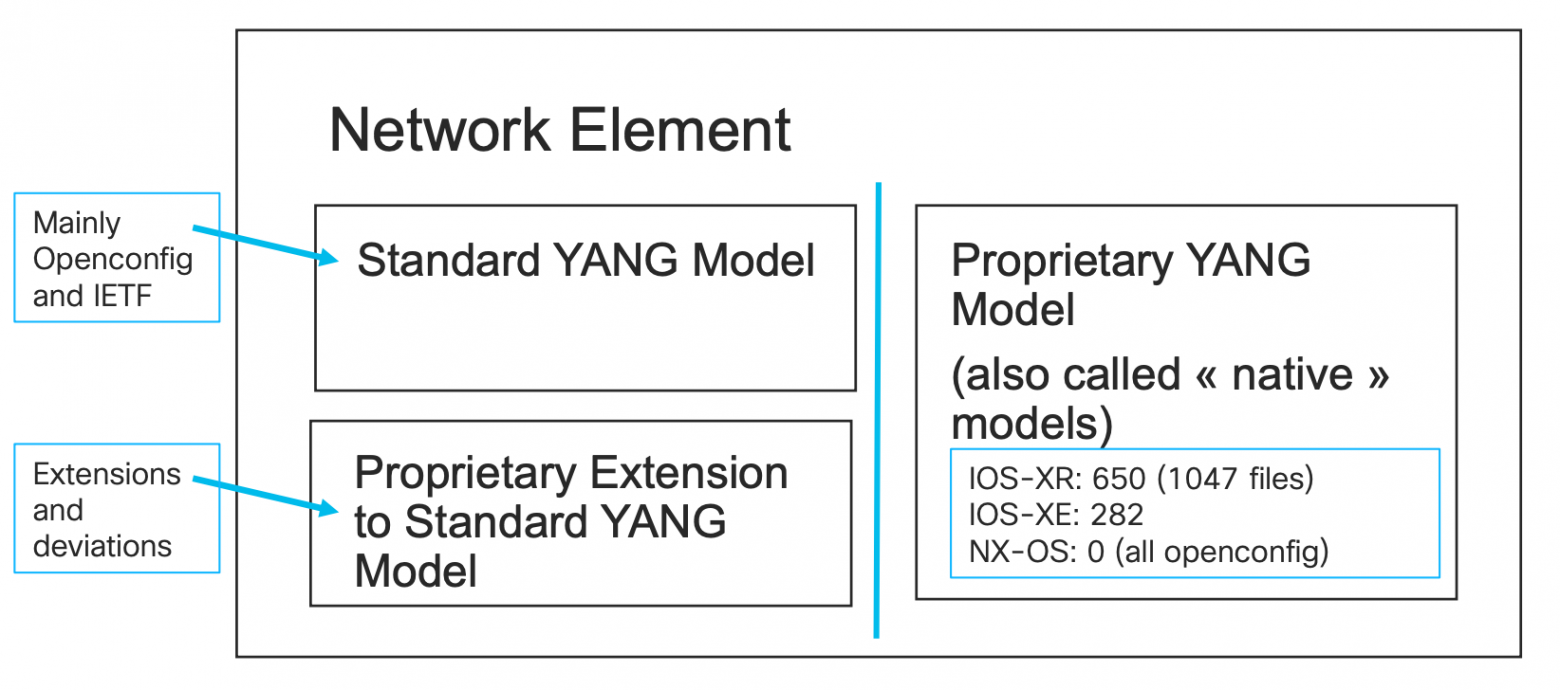
Вендоры очень быстро сориентировались в ситуации на самом деле - и довольно скоро насоздавали YANG-модели для своих устройств.
Проприетарные, они же Native
У каждого производителя набор моделей свой собственный, никоим образом несовместимый с любыми другими. А зачастую просто даже ничего похожего между ними нет. Но это уже большое дело - теперь вся ваша автоматика может полагаться на них при генерации и валидации конфигурации, при сборе статистических данных, при разборе телеметрии. Известно какого типа и в какой ветке иерархии вернутся те или иные значения.
Где их можно взять?
Говорят, что можно прям запросить с устройства YANG-модель через операцию <get-schema>, но не все вендоры это поддерживают. Говорят, некоторые вендоры выкладывают модели в GitHub, но не все и не всё. Говорят, что можно скачать модели с сайта производителя.
Пусть говорят: но универсального пути тут нет, увы.
Главное: с этим уже можно было жить. Инженерам стало нужно чуть меньше думать об интерфейсах и форматах сообщений, но с глубоким вниманием подходить к содержимому сообщений всё ещё приходилось, оказывая разные знаки почтения разным вендорам.
При этом казалось бы - вся сеть - это конечный набор одинаковых сервисов, если выбросить всякие IGRP, HSRP, RRPP и прочие проприетарные выдумки. Ну, всем же нужен IP, OSPF, BGP? Всем нужна аутентификация на устройствах и SSH? Они не могут иметь очень уж принципиальные отличия, как минимум из-за необходимости поддерживать совместимость друг с другом и соответствовать RFC.
Так почему мы делаем это сотней разных способов?
Сделать по отдельности у каждого вендора Configuration State Management - одноразовая, решаемая (а много где и решённая) задача. А вот договориться между всеми производителями, как должна выглядеть универсальная модель - так же сложно, как и любая другая задача, где людям нужно договориться.

Но ни один из зарождавшихся и выживших стандартов или не ставил целью унификацию вообще, или пытался поднять этот вопрос, но был выброшен в окно штаб-квартиры вендора.
Хотя вру. IETF предприняли отчасти успешную попытку написать универсальную модель.
IETF-модели
Разработав язык YANG, инженеры IETF поняли, что напрашивается и мультивендорная модель.
Ещё в 2014-м году были сделаны первые коммиты с этой моделью в репозиторий YANG.
С тех пор много накоммичено, но мало фактически сделано. Общепризнанно, что IETF-модель очень медленно развивается, у неё низкое покрытие, а схема не выдерживает критики.
С IETF-модели рекомендуют начинать, потому что она якобы проще, а уже потом переходить на OpenConfig, но как по мне - это напрасная трата времени.
Будущее её туманно, если не сказать непроглядно. Однако вендоры её поддерживают. Ну, кстати, Openconfig-модель из IETF-модели тоже кое-что импортирует, например, частично интерфейсы.
Заказчиков и пользователей беспокоили ущербность модели и инертность IETF, но один в поле не воин - тысячи разрозненных автоматизаторов по всему миру не могли ничего с этим сделать. А вот большие компании могли.
Когда надо настроить тысячу свитчей, а каждый месяц запускать новый датацентр, когда на сети пять разных поколений дизайна, а катить изменения нужно дважды в день, начинаешь несколько иначе смотреть на все этим ваши сиэлаи и вендор-специфичные эксэмэли.
Могу только предположить, что в недрах гугла это происходило примерно так:
Вот была сеть из дюжины вендоров, были некие драйверы, которые могут доставлять конфигурацию на сетевые коробки. А ещё была где-то далеко стоящая база данных с переменными. А между ними 2 миллиметра антивещества.
Скорее всего, сначала появился некий дизайн сети, которые в суперпозиции с БД давал вендор-нейтральную конфигурацию.
Этот дизайн сети уже опирался на разработанную внутри модель данных - ведь в нём нужно было описать все нюансы конфигурации. То есть или уже была или параллельно с дизайном появлялась модель данных.
А вместе с тем набирал обороты gRPC. И на каком-то из удачно расположенных кофе-поинтов пересеклись парни из соседних отделов и подумали:
- Слышь, а зачем вам эти полумеры? Давай из вашей модели сразу же в коробку перекладывать? Мы вам поможем агента написать
- Да, но у нас циски, проприетарная ось.
- Да это фигня. О, Джон, здоров. Давай парням линукс на свитчи вкорячим?
- Так давай, изян. Через сколько месяцев надо?
- Подождите, подождите, там типа чип, SDK, памяти маловато
- Хей, Рони, алло! Нам нужен свитч, на который мы можем свою операционку поставить
- Без базы, ща, в R&D запустим.
Ну как-то так я себе представляю рождение OpenConfig.
OpenConfig - мечта, становящаяся явью
Возможно, впервые за шестидесятилетнюю историю телекоммуникаций у нас появился шанс изобрести свой USB Type C. Представьте мир, в котором Cisco, Juniper, Nokia и Mikrotik настраиваются одними и теми же командами и это к тому же приводит к одинаковому результату?
Я не могу.
OpenConfig - это открытая YANG-модель, которая предполагается единой для всех вендоров. Одна стандартизированная модель для сбора операционных данных с устройств, управления конфигурацией и анализа телеметрии.
Итак, OpenConfig появился в Google, как они сами сказали на наноге в 2015, как ответ на следующие вызовы:
20+ ролей сетевых устройств;
Больше полудюжины вендоров;
Множество платформ;
4M строк в конфигурационных файлах;
30K изменений конфигураций в месяц;
Больше 8M OIDs опрашиваются каждые 5 минут;
Больше 20K CLI-команд выполняется каждые 5 минут;
Множество инструментов и поколений софта, куча скриптов;
Отсутствие абстракций и проприетарные CLI;
SNMP не был рассчитан на столь большое количество устройств и на столько большие объёмы данных (RIB).
Это всё настолько знакомые ежедневные трудности, что любой может приписать их себе, просто уменьшив цифры.
Вскоре после этого в том же 2015м был сделан первый коммит в публичную репу openconfig/public.
Так начал своё шествие по индустрии OpenConfig.
Вот тут все модели данных, разработанные и опубликованные в OpenConfig.
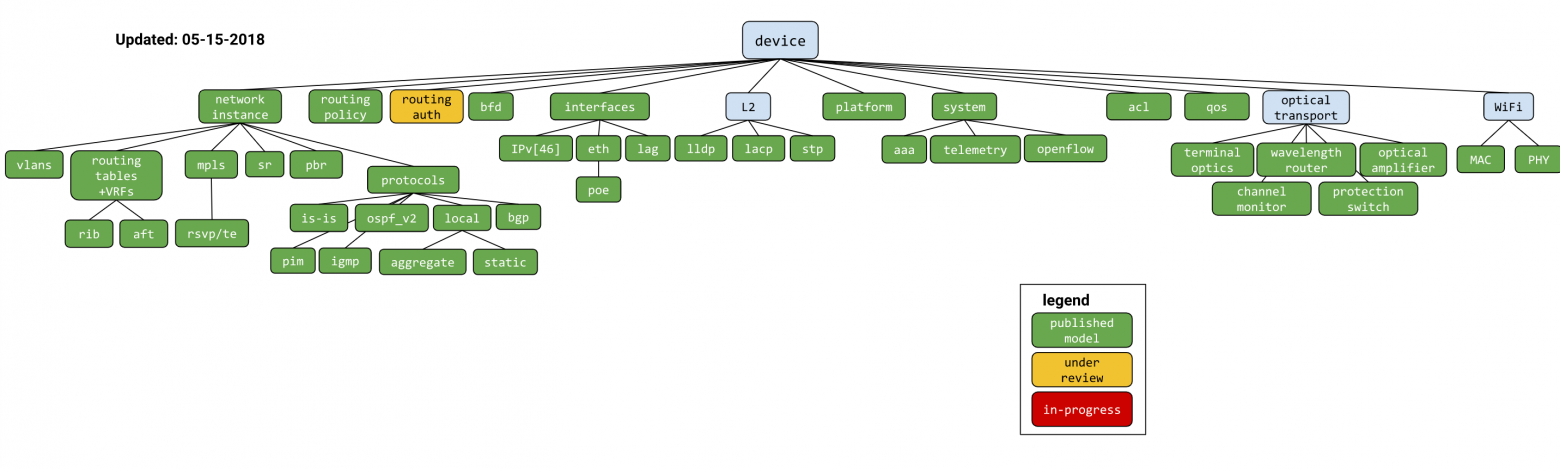
Никаким стандартом он не стал, в RFC не превратился, но вендоры его подхватили. Ещё бы они его не подхватили - очень быстро к гуглу подтянулись и другие гиганты!
Есть только пара проблем - карта старовата и некоторые ссылки на сайте ведут на 404 :)
Но репозиторий живёт насыщенной жизнью.
Есть и ещё пара проблем посерьёзнее, но о них в конце главы.
OpenConfig сегодня даёт возможность настройки стандартных сервисов, таких как интерфейсы, IP-адреса, NTP, OSPF и прочее. Безусловно, речь не идёт про вещи, завязанные на аппаратные особенности: QoS, управление буферами и ресурcами чипа, сплиты портов, работа с трансиверами. И в каком-то хоть сколько-то обозримом будущем этого ждать не стоит.
Хуже того, на сегодняшний день многие вендоры, ввязавшиеся в поддержку OC, не реализуют все 100%, а лишь часть - ту, которая нужна им, а точнее, их заказчикам.
Но BGP с OSPF настроить точно можно.
И что же делать, если брать 5 разных несвязанных Native-моделей не хочется, а OC-модель не покрывает всех необходимых функций?
И есть два пути.
Один из них - брать OC и видоизменять его с помощью добавления или убирания каких-либо его частей. Когда вендор хочет расширить покрытие модели - он делает augmentation, встраивая его в нужное место. Если он хочет поменять какое-то поведение или удалить функционал - он описывает deviation к базовой модели.
Этот способ, конечно, не покрывает все потребности.
Другой - совмещать OC и Native. В целом рекомендуют (даже сами вендоры), использовать OC там, где это возможно, а где нет - прибегать к Native. Главное - не настраивать одно и то же с помощью разных моделей.
")
Если вам всё ещё кажется, что так можно жить, то пришло время сказать, что разные вендоры, оборудование и даже версии ПО могут использовать разные версии OC-модели и быть не полностью совместимыми. Вам всё ещё придётся думать о том, что и куда вы деплоите.
OpenConfig входит в наш мир в ногу с gNMI, как это и задумывал Google. Но в качестве транспорта может быть как gNMI, так и NETCONF и RESTCONF - это не принципиально, потому что OC - это только YANG-модель, которая далее может быть переложена уже хоть в JSON-схему, хоть в gRPC protobuf'ы.
gRPC/gNMI
Сверхлихие 20-е
За последние лет семь gRPC уже всем уши прожужжали. И только самые ловкие разработчики могли избежать реализации взаимодействия с какой-нибудь системой по gRPC.
"g" в gRPC, кстати, означает вовсе не "google".
gRPC
Вообще-то RPC вроде бы как начал давным давно уходить в тень, уступая место REST и ему подобным. Но в недрах гугла он цвёл, эффективно связывая между собой микросервисы, и назывался Stubby. Ровно до тех пор пока, в 2015 они не решили его переписать и заопенсорсить, чтобы нанести непоправимую пользу миру.
Долгое время в изученной Вселенной не существовало никаких общедоступных библиотек, позволяющих реализовать какой-то типовой RPC. Разработчики сами описывали и сообщения, и формат данных в них, и как их интерпретировать. Поэтому и популярности особой он не сыскал.
А тут вот, пожалте: готовый протокол, стек, формат данных и библиотеки для кучи языков.
Что же он из себя представляет?
Это фреймворк, позволяющий приложениям, запущенным в совершенно разных окружениях, взаимодействовать друг с другом посредством RPC. Делает gRPC концептуально ровно то, что предполагается самой идеологией RPC, но есть несколько вещей, которые обусловили его успех и популярность:
Строгий IDL (Interface Definition Language), диктующий то, как именно описывать спецификации - protocol buffers или protobufs.
Готовый формат данных и механизм их маршалинга и демаршалинга - тоже protocol buffers (protobufs).
Библиотеки для разных языков программирования, которые на основе спецификации генерируют объекты языка (классы, методы итд) - разработчику остаётся только использовать их. Как для сервера, так и для клиента.
То есть. Поставил себе пакет grpc: перед тобой сразу язык спецификации, генераторы кода, интерфейсы, форматы данных, транспорт. Красота-тра-та-та!
Мы не знаем сколько лет внутри гугла gRPC набирал популярность и проникал всё глубже в межсервисное взаимодействие. Но что теперь известно точно, так это то, что у них менеджмент с яйцами, а сетевые инженеры достаточно гибки и пытливы, чтобы и к сети адаптировать этот единый протокол.
При этом не забываем, что на проприетарные джуносы, иосы и врп никто не притащит свой бинарничек, чтобы удобный для себя интерфейс реализовать. Это значит, что white-box коммутаторы с собственной linux OS у гугла появились задолго до того как их увидел мир.
Что и неудивительно - с железом они работать умеют, с Linux и подавно - дело было за малым - собрать команду Network R&D, в которой будут ребята, которые занимались разработкой своих серверов и адаптацией интерфейсов и инструментов, и найти достаточно гибкого вендора. А за последним дело не встанет, когда вы закупаете килограмм свичтей в секунду.

Вообще для обывателей всё началось 24 сентября 2015, когда OpenConfig consortium выпустил OpenConfig в мир. Весь FANG (кроме Amazon) поучаствовал в этом консорциуме. Но начал всю заварушку и продолжает её паровозить гугл. Естественно, среди них и крупные телекомы, вроде Level3, AT&T, Verizon, Bell.
И пока OpenConfig прокладывал себе дорогу, раскидывая в сторону вендорские и IETF модели, гугл сделал следующий шаг - как раз таки реализовал gNMI.
Итак, в 2016-м мир увидел плод труда инженеров гугл - протокол gNMI, реализующий весь стек технологий для программного взаимодействия с железом.
И что с того?! Ведь к тому времени буйным цветом шёл NETCONF и к тому же почти одновременно с gNMI уже почти сформировался RFC 8040, описывающий RESTCONF со вполне ещё модным на тот момент REST.
Как в таких условиях пробиться ещё одному протоколу и не стать героем известной картинки?

Так вот, рассказываю: собрались как-то сетевики гугл вместе, пришли на встречу IETF 98 в Чикаго на секцию Routing Area Working Group и прямым текстом им заявили, что то, что те навыдумывали, пора пришла заменить на молодёжные технологии.
Шёл 2017-й год. Марат устроился в Яндекс.
И... Ничего не изменилось.
В 2018 они, видимо, поняли, что их не услышали и на IETF 101 снова пришли с рассказом про gNMI, и уже более явно сообщали, что он пришёл на замену этим вашим x-CONF'ам. Слышите вы, старпёры? Ало?! gNMI пришёл!
И тут завертелось! Сообщество сетевых автоматизаторов из вендоров, телекомов и просто одиноких пассионариев понесло благую весть в народ.
Как вы видите, gNMI молодой и дерзкий протокол. Про него нет страницы на вики, довольно скромное количество материалов и мало кто рассказывает о том, как его использует в своём проде. Он не является стандартом согласно любым организациям и RFC, но его спецификация описана на гитхабе.
Однако свою дорогу в мир прокладывает. Медленно, но, похоже, что верно.
Что нам важно знать о нём? gRPC Network Management Interface.
Это протокол управления сетевыми устройствами, использующий gRPC как фреймворк: транспорт, режимы взаимодействия (унарный и все виды стриминга), механизмы маршаллинга данных, proto-файлы для описания спецификаций. В качестве модели данных он может использовать YANG-модели, а может и не использовать - protobuf'ы можно сгенерировать на основе чего угодно, и даже просто написать вручную.
Как того требует gRPC, на сетевом устройстве запускается сервер, а на системе управления - клиент. На обеих сторонах должна быть одна спецификация, одна модель данных. gNMI в мир пришёл под руку с OpenConfig, но неразрывно они друг с другом не связаны.
В этой статье я не копаю глубоко в каждый протокол и фреймворк, не разбираюсь, как они устроены, а даю только взгляд на историю развития автоматизации. За деталями приглашаю во вторую статью.
Ну и пришло время подводить итоги?
Настоящее сетевой автоматизации
Итого, что же творится в мире сетевой автоматизации сейчас?
Тут на самом деле вопрос, где вопрошающий и отвечающий находятся на спектре от чед-инженера "руками фигакну тыщу свичей, хорошо, если есть Excel" до непорочного инженера, кругом обложившегося gRPC и OpenConfig'ом с сетевым CI/CD-пайплайном.
А посередине спектра и ансибль, и питон, и перл, и баш, и го. Где-то CLI, куда-то NETCONF уже внедрили, кто-то по gNMI что-то настраивает и телеметрию снимает. Да добрая половина и SNMPv2 ещё не выключила.
У многих конфигурация Day-0 и Day-1 плюс-минус автоматизирована - это правда легко.
Day-N у кого-то решается в полностью ручном режиме, иные раскатывают обновления скриптом или простым Ansible playbook'ом, кто-то даже готовит развесистые плейбуки, основанные на модулях, "поддерживающих" состояние.
У кого-то есть крутая CLI-автоматизация, умеющая по-настоящему поддерживать состояние.
Самые продвинутые укладывают всё в NETCONF, собрав полноценный замкнутый цикл релиза конфигурации.
А совсем оторванные от земли заставляют производителей поддерживать новую функциональность в OpenConfig.
В целом описать всё многообразие проявлений автоматизаторской фантазии сегодня просто невозможно. Мы сейчас в мире, в котором чёрный параллелепипед ещё не был признан стандартом в области форм-факторов смартфонов.
Видимое будущее
Тут на самом деле два направления развития.
Во-первых, совершенно очевидно будут стремительно набирать популярность программные интерфейсы взаимодействия с железом и набивший оскомину на конференциях model-driven programmability.
Рано или поздно он сойдёт со слайдов и начнёт свой путь в каждое домохозяйство.
gNMI слишком хорош, чтобы пройти мимо него. Да и NETCONF, настоенный на YANG'е, тоже.
Будем видеть всё больше статей, больше лаб, разборов. Всё больше вендоров будет нормально поддерживать их и увеличивать покрытие.
Такие требования начнут появляться в RFI.
И это очень-очень-очень хорошо.
Другое направление более интересное и многообещающее.
Whitebox-оборудование. Лет 5 назад это было таким же шумом, как сейчас gNMI. Это - где-то там, у них - у больших и сильных - есть и железо, и софт, и штат R&D для этого интересного.
Сегодня Cumulus, Switchdev, Onos, SONiC - уже вполне зрелые операционные системы, на которых работает прод. Broadcom опубликовал свой SDK на github - это вообще из разряда "что происходит?!"
Выпуском железа занимаются уже давно не только новоиспечённые игроки, вроде mellanox'а (у нас с ними был подкаст), delta Xpliant, Barefoot (у нас и с ними был подкаст), но и вендоры - так называемые Britebox - Branded white box - cisco, huawei итд.
Почему это важно? И почему эта информация вообще получила место в статье про историю автоматизации?
А всё просто. С появление Whitebox в мир сетевых операционных систем приходит Linux.
"Да он там и до этого был" - скажут некоторые. Не секрет, что почти все проприетарные сетевые ОС основаны на Linux или FreeBSD. И что с того, если доступа к консоли обычно нет, не говоря уж о руте?
А на Whitebox'ах стоит самый что ни на есть честный Linux, на который можно установить пакеты из репозитория, притащить любой файл, любой бинарник, любой скрипт.
Он превращается в обычный сервер с о-о-очень модными сетевыми карточками с чипом на 12,8 тера.
На нём есть файлы конфигурации, systemd, cron.
А это означает, что обслуживать его можно как обычный Linux-сервер.
Можно поднять nginx и совершенно любое REST-приложение за ним. Ну или gRPC-сервер.
Поставить телеграф-агент - и сливать метрики в коллекторы.
И здесь совершенно чудесно ложится идея разделения управления устройством и сервисами, которые на нём запущены.
Есть Linux-тачка. На ней CPU, память, интерфейсы, пользователи, мониторинги системы и всё такое прочее: но весьма ограниченный набор. Доступ - по SSH. Инструмент - любой, используемый для управления физическими машинами - Ansible, Salt, Chef.
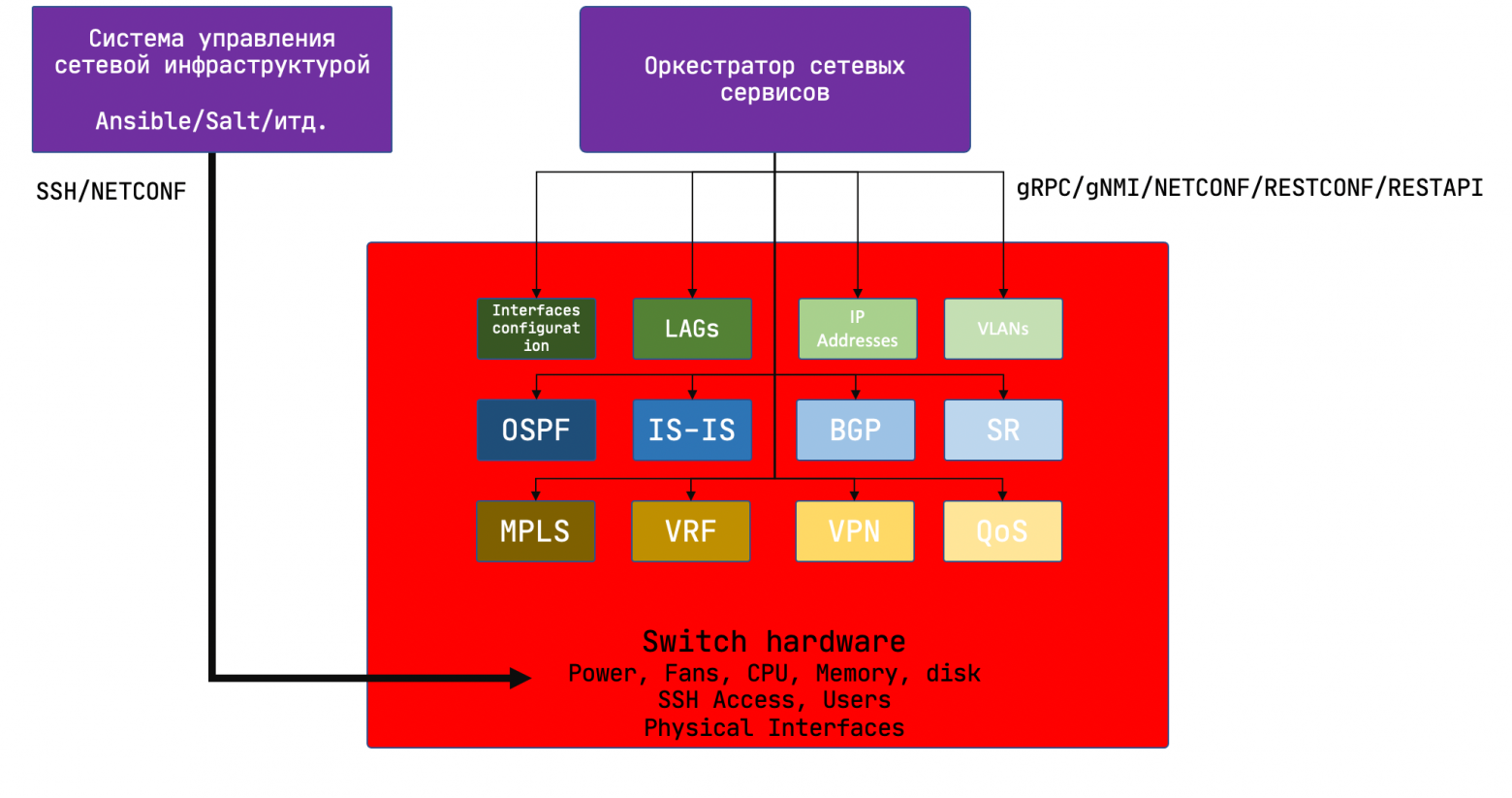
А есть сервисы - BGP, VPN, VxLAN, который на физической машине запущен. И вот они могут управляться через REST, gRPC, ну или хотя бы путём подсовывания конфигурационных файлов.
И менеджмент конфигурации сети становится задачей других, уже существующих отделов: серверной инфраструктуры и config-плейна. Без размазывания компетенций и накладных расходов.
Сетевики всё ещё нужны, очевидно - для определения того, что именно нужно настраивать, как будет выглядеть архитектура сети, набор протоколов, модель данных.
Сюда же можно подтащить версионирование работающих приложений, в которое можно включить и конфигурацию, запуск двух версий side-by-side и где-то не за горизонтом даже полноценный CI маячит.
А все заморочки с ансиблом, питон-скриптами, притворяющимися человеком с руками и какой-никакой головой, поддержанием стейта конфигурационной портянки текста - они просто испаряются в предрассветном тумане.
И попробуйте после этого взглянуть на существующую модель работы с сетевым железом - какой кривой и инертной она выглядит.
Но есть "Но".
Во-первых, это требует глобальной перестройки всех процессов и вообще-то сознания. Такие вещи за 5 лет не происходят в индустрии - мы ещё долго будем развивать NETCONF.
Во-вторых, это требует всё же некий R&D - в штате должны быть крепкие инфраструктурщики и разработчики. В то время как идеально вылизанное вендорское железо и софт - требуют весьма ограниченное количество человеческих ресурсов на обслуживание.
В-третьих, это всё сейчас и ещё долгое время будет касаться ДатаЦентров со сравнительно простой сетью, построенной преимущественно на свитчах. В гораздо меньшей степени это применимо к энтерпрайзной сети. А уж когда это докатится до операторов нам будут рассказывать наши внуки. При том что NETCONF там тоже плюс-минус состоялся.
И всё же этот мир прекрасен.
Шаг за горизонт
А что если я вам теперь скажу, что мы делаем всё неправильно?
Мысль не свежая и принадлежит не мне.
А людям, которые в сети приходят из разработки или других смежных профессий.
У сети в целом очень простая задача - доставить данные из точки А в точку Б.
Концепция пакетной маршрутизации в основе своей понятна и красива - глядя на IP-адрес назначения, принимать решение на каждой новой точке. От конца до конца одна логика.
Но сразу же появляется необходимость в протоколах маршрутизации. И тут первый раз становится сложно: Тут - OSPF, там - BGP, где-то - статика. Ещё OSPF не всегда подходит - нужен какой-то IS-IS.
У каждого протокола триллион параметров: помним про virtual-links, MED, sham-links, DN bit, Local Preference, Overload bit, никому не нужный стек OSI.
Мы придумываем RPKI и болезненно его внедряем, потому что все сетевики в прошлом джентльмены - и мы безоговорочно доверяем друг другу.
А потом кончаются IPv4-адреса потому что кто-то когда-то не подумал заранее. Ломается принцип end-to-end связности, появляется триста видов NAT, часть из которых призвана обеспечить хождение данных между IPv4 и IPv6 мирами.
А в маленьких сегментах сети, где находятся компьютеры, нужно ещё не забыть, что в Ethernet забыли заложить TTL и организовали широковещательные рассылки. Для этого придумали пяток несовместимых друг с другом протоколов, каждый из которых устраивал в своё время инцидент масштаба как минимум города, а то и региона.
Кстати, спасибо ребятам, в L2-сегменте мы не можем утилизировать все линки одновременно, поэтому придумываем ещё несколько протоколов защиты дефолтного шлюза, которые нет-нет да страдают от сплит-брейна.
Учитывая, что L2-пространство плоское, пришлось придумать сначала dot1q, потом, когда оказалось, что 4094 мало, qinq и разные виды маппингов и стекингов.
Всё это призвано решить только задачи транспорта. Но есть ещё сервисы. А там пересекающиеся IP-пространства, данные, которые нужно спрятать, или даже вовсе не IP, а Ethernet или какой-нибудь IPX или ATM.
Появляются оверлеи. Просто перечислим их виды? IPinIP, GREinIP, BGP MPLS L3VPN, BGP MPLS L2VPN, VPLS Compella, VPLS Martini, MPLS over GRE, MPLS over UDP, VxLAN, несколько режимов работы IPSEC. И ещё не вспоминаем тыщу разных видов VPN, как L2TP, PPTP, SSTP, OpenVPN, SSH-туннели.
Каждый раз, строя сеть, пробуем разобраться, что из этого поддерживается какими вендорами и какими железками. А поддерживается только в Control Plane или в Data Plane тоже? А через CPU или через ASIC? А как настроить?
Как вы знаете, недостаточно положить IP в GRE и снова в IP - мы используем MPLS. Технология, нашедшая себя в совершенно не в той сфере, в которую её сватали.
Идея в Data Plane выглядит ещё более или менее понятной, пока мы не касаемся FRR, bandwidth allocation и Affinity.
Но тут у нас есть LDP в разных режимах, RSVP-TE, remote LDP, BGP - всё только чтобы распространять метки. И это рождает монстров вроде LDPoverTE, MPLS TE Hotstandby с Fast Reroute и ручного назначения и слежения за bandwidth.
Кому-то ведь даже приходится хорошо помнить (на собесах, например), сдвиги октетов, в которых находится RRO объект в RSVP-TE Path message.
BGP вот, кстати, стал козлом отпущения, сам того не желая (как будто это бывает иначе). В его NLRI насовали всего, что только могли - BGP всё стерпит. Отсюда же у нас и в некоторых случаях отсутствие обязательного атрибута NextHop.
Ещё сетям свойственно перегружаться и ронять пакеты на пол. С такими потерями имеют дело дюжина механизмов Congestion Avoidance и ещё столько же Congestion Management. Tail-drop, RED, WRED, RR, WRR, PQ, CBWFQ, ECN, CWR. Мы знаем, что такое HoLB, VoQ, Pause Frames, PFС, CAM, TCAM, SerDes, Traffic Manager - и как они все поступают с пакетами. И вообще мы эксперты по аббревиатурам - найдите, в какой профессии их больше - устроим батл!
И давайте не будем трогать мультикаст?

В итоге как может выглядеть жизнь одного байта, который вы отправили из виртуальной машины в облаке клиенту с телефоном?
Выходя из виртуалки, он содержится внутри TCP/IP/Ethernet - в качестве адреса назначения - клиентский IPv4-адрес. Далее его перехватывает виртуальный рутер (vRouter) на хосте-гипервизоре, снимает Ethernet, навешивает на него метку MPLS потом UDP, и ещё один IP-заголовок - теперь IPv6 и новый Ethernet - и отправляет на свой Gateway. Но фактически пакет попадет на стоечный коммутатор, внутри которого создан отдельный VRF, далее он идёт по маршруту, изученному по OSPFv3, перескакивая с хопа на хоп через выделенные для него VLAN'ы внутри одного физического линка. Пока не достигнет последнего коммутатора, который должен из своих таблиц ND и MAC-адресов извлечь в какой порт и в какой VLAN отправить этот пакет с какими MAC'ами.
На хосте его перехватит vRouter, снимет заголовки Ethernet, IP, UDP и изначальный пакет доставит до Gateway, который суть другая виртуальная машина. Уже этот Gateway знает, что для 0/0 у него некстхоп - это адрес бордера, но нужно упаковать данные в MPLS. Эта информация изучена по BGP.
Gateway навешивает сервисную метку MPLS и ещё сверху транспортную и отправляет в свитч.
Цепочка свитчей выполняет MPLS-коммутацию, на основе информации, изученной с помощью BGP Labeled Unicast, и доносит пакет до MPLS-магистрали, где существующий пакет упакуется в ещё несколько заголовков MPLS, которые должен донести пакет через магистраль до бордера. Информация, о том, какие именно MPLS-метки проставить и как с ними дальше быть появляется из Segment Routing, работающего поверх IS-IS.
Далее на магистрали за одно устройство до точки выхода снимаются все MPLS-метки, потому что PHP.
Бордер шлёт пакет в одного из своих транзитов. Далее побитый судьбой, пройдя через множество оптических каналов, маршрутизирующих систем, обросший неизвестным количеством меток он приходит на бордер оператора связи, в котором находится клиентский терминал.
Бордер теперь должен доставить пакет до ядра мобильной сети в том регионе, где находится клиент. Через магистраль оператора связи. На этот раз она поддерживается механизмом RSVP-TE. Тут у оператора могут быть десятки разных каналов, которые управляются Affinity, Bandwidth constraints и даже Explicit routes.
Пакет обрастает одной, двумя или тремя метками MPLS и отправляется в долгий путь. А по пути случается обрыв трассы между городами, срабатывает Fast Reroute и пакет обзаводится ещё одной MPLS-меткой.
Так или иначе он добирается до ядра сети в регионе, где принимается решение о том, как доставить его до базовой станции. Чтобы это случилось, пакет сначала весь раздевается почти до изначального состояния, а потом должен обратно обрасти новыми заголовками, один из которых ключевой для мобильных сетей - это GTP - ещё один туннель. В плане опорной сети у операторов тут тоже без фантазий - оптическое кольцо по области, сверху которого накручены OSPF или IS-IS, MPLS как транспорт или BGP L3VPN для выделения сервиса мобильного интернета в отдельный VRF. Пакет попадает в это кольцо, направляется нагруженный метками к точке назначения. И тут рвётся один из линков, размыкая кольцо. Срабатывает снова FRR, который перенаправляет трафик к тому же некстхопу, но через противоположное направление по кольцу, опять же навешав MPLS-метку. И доходит.
Но на этом жизнь его не кончается. В этом месте от кольца начинается цепочка старинных радиорелеек, не поддерживающая MPLS, которая ведёт к глухой деревне. Скидываются все метки, пакет идёт по проброшенному VLAN'у.
А на одном из сегментов для организации канала используется Е1, где нужно Ethernet конвертировать в E1 тайм-слоты, а потом обратно расконвертировать.
И вот базовая станция клиента, где пакет, полученный из одной радиосреды, нужно передать в другой - в LTE, при этом не забыв все его заголовки и радио-маркеры привести в требуемый вид.
После этого терминал наконец получает пакет, потрёпанный, поцарапанный, побитый, раздавленный, и ... дропает его, потому что истекло время ожидания.
А сколько радости доставляет каждому сетевику и разработчику вендора интероп разных вендоров?
И всё это только потому, что сеть - это самый фундамент инфраструктуры. Нужно поддерживать как новейшие технологии, так и чудовищные ископаемые.
Новенькие облака должны смочь дотянуться до старинных Token Ring. Недовытравленные сети SDH должны жить одновременно с 400Гб/с Ethernet. Серые IPv4 сети должны иметь возможность добраться до IPv6-only сервисов.
Сетевые устройства и технологии вынуждены тащить за свой хвост легаси длинной в 60 лет, продолжая наращивать его всё больше и больше. И это всё лишь для того, чтобы доставить байты из точки А в точку Б.
Расскажите сетевикам про проклятое легаси и обратную совместимость?
Самое обидное, что тащить его через ворох такого старья приходится не только глобально по миру, но и внутри вполне себе контролируемого контура. Мы можем выдумывать какие угодно изящные схемы, но это не имеет смысла, если их нельзя реализовать в железе.
И тут проприетарный вендорский софт всячески вставляет палки в колёса.
А вот программируемые конвейеры обещают небывалую гибкость. Whitebox и P4 могут стать теми, кто поменяет правила игры. Если у вас есть десятки коробок с запущенным Linux, и вы можете программировать обработчики в чипе, то перед вами открываются совершенно иные возможности.
Центральный контроллер, принимающий решение о том, как направить трафик в магистрали, учитывая утилизацию, как нагружать внешние линки, программируя нужные инкапсуляции на источнике - это ли не мечта?
И какой-нибудь протокол, как Segment Routing v6, может тут сыграть свою достойную роль. В пределах своего домена используем контроллер и SRv6 для транспорта трафика, на конечных узлах с помощью P4 программируем обработку инкапсуляций на мощном и гибком ASIC'е, а Control Plane сгружаем на обычные сервера. И больше не нужны гигантские вендорские мангалы, не нужно платить за 80% функциональности, которой так никогда и не воспользуешься, этот проприетарный софт, и бесконечные баги.
А потом вы начинаете задавать себе и другим вопросы, вроде - а нужен ли Ethernet?
Заключение
Конечно, я очень размазал последнюю часть, непонятно как это сделать, непонятно даже что я имел в виду, возможно. Но это совершенно удивительный мир не просто автоматизации сети, а новой парадигмы строительства и управления сетью.
Я думаю, что об этом я напишу ещё не одну статью.
И, надеюсь, этой статьёй мне удалось немного раскрыть длинную историю сетевой автоматизации, показать, что мы живём в эпоху Кембрийского взрыва инструментов и интерфейсов. И перед нами сейчас открыты разные пути, каждый из которых сулит как минимум интересное развитие событий.
Рекомендую к прочтению вторую часть этой публикации.
Полезные ссылки
Главные RFC:
Концепция RPC: Remote Procedure Call (RPC)
Сайт OpenConfig: openconfig.net
Хорошая вводная в NETCONF и немного YANG: YANG Data Modelling and NETCONF
Продолжение про YANG и немного про NETCONF: The Road to Model Driven Programmability
На русском про NETCONF. Начало
Если жить не можете, хочется на русском про YANG, и вы воспринимаете художественную речь: YANG — это имя для вождя
Спецификация gNMI в его же репозитории
RESTCONF Tutorial - Everything you need to know about RESTCONF in 2020
Серия статей про RESTCONF, но рекомендую я её из-за того, что там хорошо разобраны примеры с YANG-моделями: RESTCONF, NETCONF and YANG
Яндекс Nextop. Про использование CLI для Configuration Management
Благодарности
Роману Додину за дельные комментарии как по теоретической, так и по практической частям. А так же за полезный блог и инструменты. GitHub.
Кириллу Плетнёву за наведение порядка с NETCONF и YANG - язык, модели, спецификации, форматы данных. И за уместные и остроумные замечания по языками и библиотекам. GitHub, fb.
Александру Лимонову за несколько идеологических замечаний и исправлений фактических ошибок.


{kind=link}