Это вторая статья - техническо-практический разбор протоколов и интерфейсов автоматизации сети.
Если хочется исторической справки, я отсылаю читателя к статье-спутнику, в которой мы двигаемся от начала времён в будущее человечества. Какую роль сыграли в нашем настоящем IETF, ISO, олдовые и современные вендоры и даже просто люди.
В этой же мы раскрываем дерево XML, пробуем на вкус капабилити NETCONF, шлём первые RPC и наконец уже расставим в правильном порядке буквы YANG, OpenConfig, gNMI.
Практическую пользу вам принесут только обе прочитанные статьи. Вторая без первой будет непонятна. Первая без второй - беллетристика.

Сразу предупреждаю, что это будет большая и нудная статья, потому что автор в очередной раз решил разобраться в чём-то, и опубликовать это разом. И вам, клянусь, ещё повезло, когда на двухсоттысячном символе я придумал, как её можно разделить на две части.
Тут разберём по косточкам все возможные способы взаимодействия с сетевым железом.
Лишь вскользь мы заденем CLI и SNMP, как не имеющие практической значимости в контексте этой статьи, разберёмся достаточно глубоко с NETCONF - это новый SNMP или всё же у него есть будущее хотя бы с YANG'ом, продолжим RESTCONF'ом и закончим на интригующем - gRPC.
Ну а по ходу неминуемо разберёмся с тем, за что с нашими глазами так поступает XML, с концепцией RPC, моделями данных и успеем посмотреть на OpenConfig.
Все статьи АДСМ
Содержание
CLI - Command Line Interface
CLI - сиэлай, кли, сли, слай, слаи, консоль, терминал, командная строка. Этому механизму уже лет 60. И он никуда не делся. Он живее всех живых - где-то для отладки, где-то для эксплуатации, зачастую для конфигурации и даже для ежедневной работы.
На компьютерах, серверах, виртуальных машинах, коммутаторах, маршрутизаторах, фаерволах, АТС, базовых станциях. Трудно найти такое оборудование, где нет CLI, пусть даже хорошо спрятанного.
И в этом его сила - 100% функциональности на 100% сетевых устройств можно настроить через CLI. Ладно 99,9% - придётся выкинуть некоторое альтернативное оборудование.
Это породило миллионы строк кода на Perl, PHP, Python, Go, Ruby, развесистые джинджа-шаблоны и по 300 экспектов в каждом скрипте. И дало работу тысячам кодеров, выросших из сетевиков и админов.Вот уже лет 30, а то и больше мы старательно пишем скрипты, которые с той или иной степенью успеха прикидываются человеком перед сетевой коробкой.
И ещё долго мы не останемся без дела - выпускают всё новые версии софта, ещё более другие модели железа, постоянно меняется CLI, и там, где вчера был string, завтра будет integer. И там, где вчера было no some shitty service enable, завтра будет some shitty service disable. Там, где вчера на вопрос интерфейса надо было ответить yes, завтра вылезет ошибка.
Клянусь, это увлекательное путешествие продлится ещё десятилетия.
А чем же оно увлекательно?
Модели конфигурации не формализованы.
Модель и поведение не зафиксированы.
CLI интерактивен.
Формат данных не структурированный.
Нет явного признака успешности операции.
Сложно вычислять разницу между целевой и текущей конфигурацией.
Сложно считать конфигурационный патч.
Транзакционность не всегда доступна.
Поддержание целевого состояния – задача инженера.
Выше 9 смертных грехов CLI, которые обусловили рождение моделей данных конфигурации, языков их описания, протоколов, как SNMP, NETCONF и gNMI.
Если всё по каждому из них понятно, просто пропускайте следующую секцию.
9 грехов CLI
1. Модели конфигурации не формализованы
Есть такое? Есть такое.
Как мы узнаём, какие команды с какими аргументами в каком порядке надо дать?
Правильно - идём в Command reference guide на сайте производителя и дальше методом проб и ошибок разбираемся в терминале. Или в обратном порядке. Но эти два способа (и ещё помощь друга) - это то, как мы узнаём модель данных конфигурации.
И скажем так: она наверняка есть - ведь каждый раз одна и та же команда приводит к одному и тому же результату (правда ведь? Правда?).
Знаем как настраивать интерфейсы, знаем как они должны называться, где будет IPv4, а где IPv6 адреса? Если мы введём что-то неправильно, CLI ругнётся, но мы не отправим OS в kernel panic или ASIC в рестарт?
Просто эта модель не формализована. Или по крайней мере нам об этом не говорят.
И да, своим естественным интеллектом мы рано или поздно такую модель в своей голове выстраиваем и научаемся ею пользоваться.
Но для того, чтобы написать код, нам придётся её хорошо или плохо самим формализовать - иерархия, порядок ввода команд, последовательность аргументов, типы значений. И скорее плохо, конечно.
2. Модель и поведение не зафиксированы
Всё, что мы изучили на предыдущем этапе может поменяться в новой версии - и мы сначала переобучаем себя, потом переписываем код.
3. CLI интерактивен
expect("Вы точно хотите выключить bgp-сессию, mpls на всей коробке [Y/n]?"] Yes!expect("Вы точно хотите выключить электричество в серверной [Y/n]?"] No!
4. Формат данных не структурированный
Мы засылаем туда неструктурированный текст. Мы получаем оттуда неструктурированный текст. Мы его крафтим, мы его парсим. Мы пишем jinja-шаблоны и regexp'ы. Мы прожигаем свою жизнь.
Лучше json'ы перекладывать.
Строго говоря, будь-то json или вывод
show version, в итоге это всё равно поток байтов и по сути текст. Только в одном случае в нём есть структура, а в другом - это просто набор символов.
5. Нет явного признака успешности операции
Вывод CLI не означает ни успех, ни провал. Warning ещё не означает, что что-то пошло не так. Отсутствие вывода - ещё не признак успешности.
6. Сложно вычислять разницу между целевой и текущей конфигурацией
Казалось бы нужно просто подифать два текста. Вот только в этих текстах имеет значение, порядок строк. Одна и та же конфигурация может быть (и будет) разной для разных версий ПО. Различающийся же регистр напротив может ничего не значить в одном месте, а в другом значить. Одна и та же команда, в разных контекстах может означать разное (выключите MPLS на интерфейсе или в глобальном режиме - посмотрите на последствия). Даже IPv6-адреса могут быть записаны в сокращённом или полном виде.
7. Сложно считать конфигурационный патч
Как следствие предыдущего пункта - выяснить, какие команды нужно применить - тоже нетривиально. Но не только это. Дело в том, что нужно уметь не только правильно добавлять, но и правильно удалять - а способов - не один и не два. Обратная команда не всегда формируется как отрицание прямой. Часто нужны не все её параметры. В каком порядке отменять - и не поломает ли это чего-то ещё? Даже не всегда команды после применения выглядят так же, как их применяли.
8. Транзакционность не всегда доступна
В целом мы уже избалованы коммитами - многие вендоры его поддерживают. Но многие ещё нет. А те, кто поддерживает, может это делать тоже собственным уникальным способом, как например валидация ввода только при коммите, или коммит заключается в последовательном применении всех команд без вычисления дельты.
9. Поддержание целевого состояния – задача инженера
Ооо, это самое интересное - а как собственно привести конфигурацию к тому состоянию, которое мы желаем увидеть, а не просто применить новую конфигу? Кто и как должен посчитать конфигурационный патч, применить только его и проверить за собой, что рантайм соответствует эталону?
Но тут стоит быть чуть более честным - не всегда CLI настолько плох. Некоторые вендоры генерируют CLI-интерфейс из YANG-модели, что гарантирует чёткое соответствие между тем, что и как конфигурируется через CLI или любые другие интерфейсы.
Например, в Nokia SR Linux интерфейс командной строки, а так же gNMI, JSON-RPC и внутренние приложения работают с единым API -
mgmt_srv- поэтому не только формализованы из одной и той же YANG-модели, но и имеют одинаковые возможности по чтению/записи конфигурации.Дифы, коммиты, датасторы и прочее, тоже могут быть сделаны с умом - как у той же Nokia или у Juniper.
Но это всё, конечно, не отменяет факта работы с неструктурированным текстом.
Этого всего, как мне кажется, достаточно для того, чтобы даже не приступать к написанию полноценной системы автоматизации, основанной на CLI.
Далее был опыт с SNMP и всеми связанными протоколами (приглашаю пройти в первую статью). Признаем его удачным лишь по той простой причине, что он позволил сформулировать требования к новым интерфейсам и протоколам.
Не исчерпывающий список можно сформулировать так:
Представление данных в структурированном виде,
Разделение конфигурационных и операционных данных,
Читаемость для человека исходных данных и самой конфигурации,
Воспроизводимость - задачу на исходных данных можно запустить повторно - проиграть,
Механизм основан на формальных моделях,
Транзакционность изменений и их откат,
Поддержание целевого состояния.
Не все они появились сразу. Не все они появились. Но это понятная и приятная цель.
И на замену SNMP, в подмогу CLI зародился NETCONF, эксплуатирующий идею RPC - Remote Procedure Call. Что за RPC, какое у него отношение с API вы так же можете узнать из первой статьи. Ну, только если коротко.
Концепция RPC - Russian Pravoslavnaya Church
RPC - клиент-серверный механизм, который позволяет запустить исполнение кода процедуры на другой машине так, словно бы он исполнялся локально. То есть разработчик просто привычным образом обращается к процедуре, не задумываясь о том, где и как она исполняется - главное, чтобы она ответ вернула. А программа уже сама реализует взаимодействие с удалённой машиной.
Прелесть этого подхода в том, что он, во-первых, позволяет скрыть удалённый характер работы. А, во-вторых, на той, другой, стороне совершенно неважно, какая операционная система, архитектура, язык программирования и окружение - главное, чтобы они подчинялись одному протоколу. Например из-под винды в exe-шнике, написанном на Delphi, вы можете исполнить удалённую программу, написанную на го, запущенную на линуксе. И никто вам не сможет помешать!
Но что, по большому счёту, мы делаем, когда, зайдя по SSH, выполняем какую-то команду на коммутаторе или маршрутизаторе? Запускаем определённый код. Например, сообщаем подсистеме BGP, что нужно теперь пробовать установить соединение с новым пиром.
Но только представьте, как было бы восхитительно, если бы для вызова этого кода, не нужно было заходить на железку по SSH и вбивать команду?!
Постойте! Да ведь именно об этом мы и говорим в данном разделе.
Большую оставшуюся часть статьи мы посвятим именно RPC.
Пример
Абстрактно взаимодействие с сетевым оборудованием выглядеть может примерно так. Для начала мы определяем спецификацию - это некий контракт, который гарантирует, что у клиента и сервера одинаковое понимание процедуры: имя, параметры, типы данных итд.
Наша убер-платформа автоматизации вызывает некую функцию
add_bgp_peer_stub(ip="10.1.1.1", as="12345").Функция
add_bgp_peer_stubоткрывает спецификацию для протокола, реализующего RPC, и согласно ей упаковывает полученные параметры, которые станут payload'ом для сообщения. Такая упаковка называется маршалинг.Далее формирует пакет и передаёт его вниз по стеку и - в сеть.
На другой стороне - на устройстве - приложение получает пакет.
Функция, принявшая сообщение, вытаскивает из него параметры процедуры, согласно той же самой спецификации и формирует список параметров. Это называется демаршалинг.
Приложение выполняет функцию - настраивает BGP-соседа 10.1.1.1 с AS 12345. Проверяет успешность выполнения.
Далее функция формирует на основе всё той же спецификации сообщение-ответ и передаёт его в ответном пакете.
Наша локальная сторона, с которой мы инициировали выполнение RPC, получает ответ, словно бы его вернула локальная функция.
Воаля.
В целом RPC - это концепция, не говорящая ничего о реализации. Она постулирует, что на стороне клиента есть так называемый стаб - фрагмент кода, который реализует взаимодействие по RPC. Именно стабы делают для разработчика прозрачным вызов функции. Ключевая часть RPC - спецификация - и ещё её называют IDL - Interface Definition Language - язык, описывающий как стабы должны маршалить и демаршалить (формировать и разбирать) сообщения. Иными словами, на основе IDL создаются клиентский и серверный стабы. Это может быть, например, набор классов в питоне, имеющих функции для удалённого вызова, с которыми разработчик работает так, словно всё происходит локально.
Мы дальше разберём два протокола, которые используются под капотом RPC и при этом позволяют управлять сетевым железом.
NETCONF
gNMI (использующий gRPC)
NETCONF
Ох, как я вился вокруг этого нетконфа в своё время, ожидая, что это серебряная пуля, решающая если не все, то 99,99% всех проблем сетевых инженеров.
Спойлер: это не так.

Если вам по какой-то причине кажется, что стандарты рождаются где-то в недрах институтов, оторванных от жизни, то вот вам контр-пример.
В 1996 был основан Juniper Networks, в недрах которого создали легендарный М40 и лучший в мире интерфейс командной строки. До сих пор никто не сделал ничего лучшего - все только повторяют. Операционка, предоставляющая клиенту обычный текстовый интерфейс, на самом деле перекладывает команды в XML, который фактически является интерфейсом для управления устройством. Если вы сейчас к любой show-команде на джуне добавите | display xml, то увидите ответ в формате XML:
eucariot@kzn-spine-0> show system uptime | display xml <rpc-reply xmlns:junos="http://xml.juniper.net/junos/18.3R3/junos"> <multi-routing-engine-results> <multi-routing-engine-item> <re-name>localre</re-name> <system-uptime-information xmlns="http://xml.juniper.net/junos/18.3R3/junos"> <current-time> <date-time junos:seconds="1641211199">2022-01-03 14:59:59 MSK</date-time> </current-time> <time-source> LOCAL CLOCK </time-source> <system-booted-time> <date-time junos:seconds="1614866046">2021-03-04 16:54:06 MSK</date-time> <time-length junos:seconds="26345153">43w3d 22:05</time-length> </system-booted-time> <protocols-started-time> <date-time junos:seconds="1614866101">2021-03-04 16:55:01 MSK</date-time> <time-length junos:seconds="26345098">43w3d 22:04</time-length> </protocols-started-time> <last-configured-time> <date-time junos:seconds="1638893962">2021-12-07 19:19:22 MSK</date-time> <time-length junos:seconds="2317237">3w5d 19:40</time-length> <user>scamp</user> </last-configured-time> <uptime-information> <date-time junos:seconds="1641211200">3:00PM</date-time> <up-time junos:seconds="26345160">304 days, 22:06</up-time> <active-user-count junos:format="1 users">1</active-user-count> <load-average-1>0.20</load-average-1> <load-average-5>0.17</load-average-5> <load-average-15>0.20</load-average-15> <user-table></user-table> </uptime-information> </system-uptime-information> </multi-routing-engine-item> </multi-routing-engine-results> <cli> <banner>{master:0}</banner> </cli> </rpc-reply>
В корне вы можете видеть <rpc-reply>, что означает, что был какой-то <rpc>-request. И вот так вы можете увидеть, каким RPC-запросом можно получить такие данные:
eucariot@kzn-spine-0> show version | display xml rpc <rpc-reply xmlns:junos="http://xml.juniper.net/junos/18.3R3/junos"> <rpc> <get-software-information> </get-software-information> </rpc> <cli> <banner>{master:0}</banner> </cli> </rpc-reply>
Внимание, работает только для Juniper!
Так вот, их CLI и способ взаимодействия его с системой оказался настолько естественным и удачным, что его и положили в основу стандарта. Не без участия Juniper Networks, конечно же, появился RFC4741. Будем честны, один только джунипер там и постарался. И то тут, то там будут проскакивать его куски, начиная с commit confirmed и заканчивая candidate config.
Вот как NETCONF был определён в 2006-м году:
Abstract
The Network Configuration Protocol (NETCONF) defined in this document
provides mechanisms to install, manipulate, and delete the
configuration of network devices. It uses an Extensible Markup
Language (XML)-based data encoding for the configuration data as well
as the protocol messages. The NETCONF protocol operations are
realized on top of a simple Remote Procedure Call (RPC) layer.
И определение с тех пор не менялось - вся суть NETCONF в этом параграфе.
А теперь давайте разбираться с очень непростым NETCONF и его составными частями.
NETCONF и его команды
Если совсем коротко, NETCONF - это четырёхуровневый стек, согласно которому через SSH передаётся RPC, где указана операция и конкретный набор действий (контент).
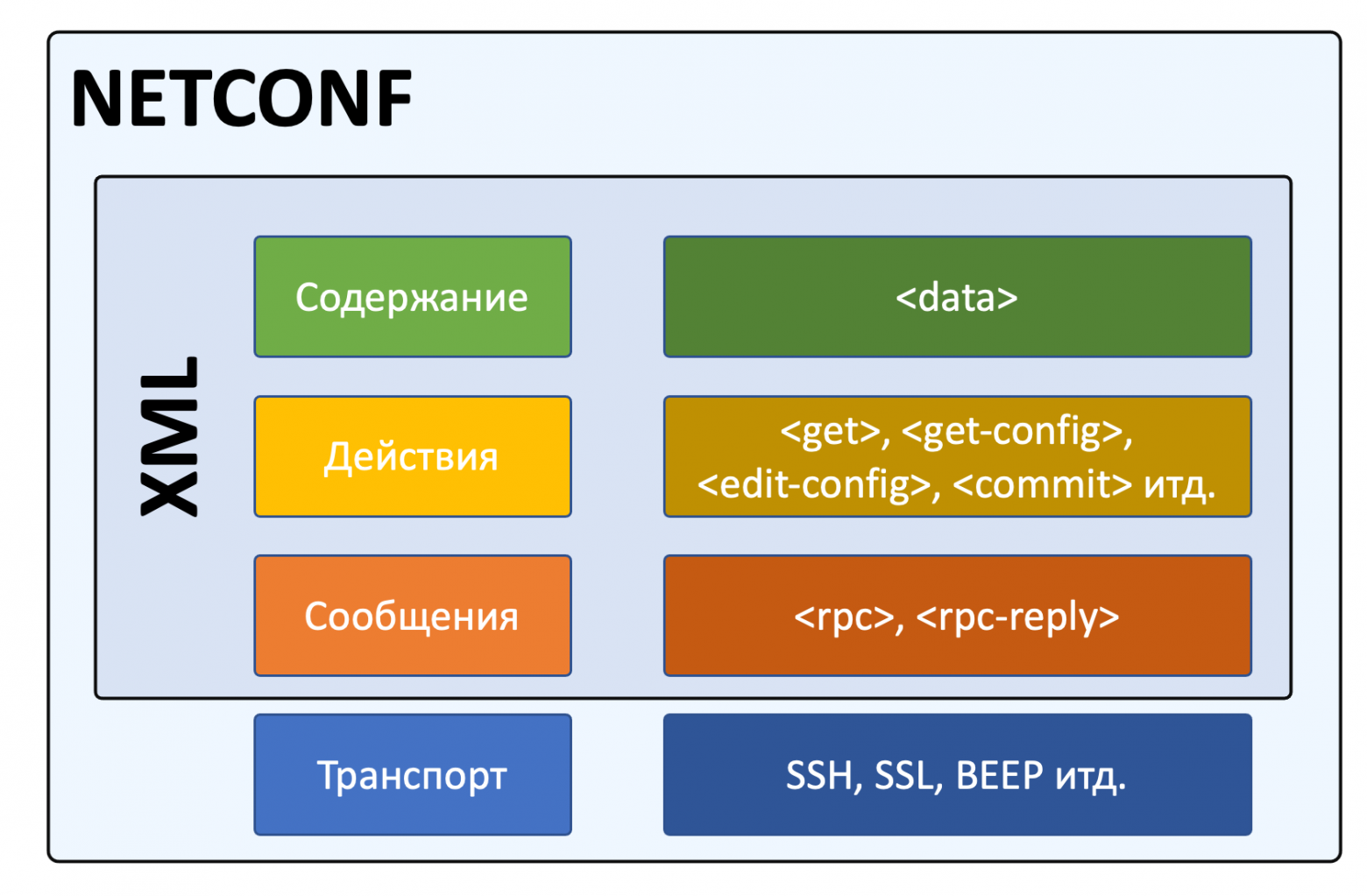
Стек NETCONF
Итак, в качестве транспорта NETCONF использует SSH. На самом деле, там есть и другие протоколы: SSH, SOAP, BEEP, TLS - но мы их опустим - SSH стал де-факто стандартом.
Каждый NETCONF запрос содержит элемент (или сообщение):
<rpc>- это собственно запрос на вызов процедуры с необходимыми параметрами.<rpc-reply>- ответ на RPC.<rpc-error>- очевидно, ответная ошибка, когда RPC некорректен.<ok>- rpc корректен и отработал.
<notification>- сообщение о событии, инициированное сетевой коробкой - аналог трапа в snmp (из RFC6241).
Это всё сообщения, внутри которых определённым образом сформированные XML.
Внутри сообщения определяется какая операция (действие) исполняется. В таблице ниже полный их список, определённый в RFC:
Operation | Description |
| Retrieve running configuration and device state information |
| Retrieve all or part of a specified configuration datastore |
| Edit a configuration datastore by creating, deleting, merging or replacing content |
| Copy an entire configuration datastore to another configuration datastore |
| Delete a configuration datastore |
| Lock an entire configuration datastore of a device |
| Release a configuration datastore lock previously obtained with the <lock> operation |
| Request graceful termination of a netconf session |
| Force the termination of a netconf session |
Каждый вендор может расширять список операций хоть до бесконечности. Так, у кого-то, например, есть <copy-config>.
И далее уже сам контент. Это самая сложная часть. Но забегая вперёд - он никак не формализован, не описан, и, возможно, это величайшая претензия к нетконф, как стандарту, позволившему благую идею превратить в очередного зомби. Даже удивительно, что после опыта с SNMP, где необходимость языка моделирования стала очевидна со временем, NETCONF родился сам по себе без какого-либо языка спецификации для данных. Уже много позже для этого подтянули YANG.
Установка сессии и Capabilities
Так, сначала включаем SSH NETCONF. На примере джунипер.
set system services netconf
Это значит, что SSH будет использоваться как транспорт для указанной подсистемы.
Для netconf IANA установила специальный порт 830, хотя часто используется и обычный для SSH 22.
И пробуем подключиться. Для того, чтобы указать, что это не просто подключение по SSH, мы используем вызов подсистемы:
ssh kazan-spine-0.juniper -s netconf <!-- No zombies were killed during the creation of this user interface --> <!-- user eucariot, class j-super-user --> <hello xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <capabilities> <capability>urn:ietf:params:netconf:base:1.0</capability> <capability>urn:ietf:params:netconf:capability:candidate:1.0</capability> <capability>urn:ietf:params:netconf:capability:confirmed-commit:1.0</capability> <capability>urn:ietf:params:netconf:capability:validate:1.0</capability> <capability>urn:ietf:params:netconf:capability:url:1.0?scheme=http,ftp,file</capability> <capability>urn:ietf:params:xml:ns:netconf:base:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:candidate:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:confirmed-commit:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:validate:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:url:1.0?protocol=http,ftp,file</capability> <capability>http://xml.juniper.net/netconf/junos/1.0</capability> <capability>http://xml.juniper.net/dmi/system/1.0</capability> </capabilities> <session-id>15420</session-id> </hello> ]]>]]>
Мы ещё ничего не успели сделать, а железка нам уже насыпала в терминал. Это сообщение NETCONF Hello, которое заставляет на берегу договориться, что поддерживается в данной сессии, а что нет. Внутри - список капабилитей - возможностей, поддерживаемых коробкой. RFC4741 определял базовый набор функций, который должен поддерживаться каждым клиентом и каждым сервером.
При этом базовые могут расширяться другими стандартизированными capability и даже проприетарными. Давайте рассмотрим сначала стандартные, а потом самые интересные расширенные. Ну и будем называть их "способностями", а то капабилитя - это почти как капибара.
NETCONF Standard Capabilities (стандартные способности)
Candidate configuration
Эта способность говорит о том, что коробка поддерживает отдельный кандидат-конфиг, содержащий полную конфигурацию, с которой можно работать без влияния на фактически применённую конфигурацию. Аналоги candidate-config на Juniper.Confirmed commit
Опять же аналог джуниперовоского commit confirmed - откат изменений после коммита, если не было подтверждения коммита.Validate
Способность проверить желаемую конфигурацию до её применения.Rollback-on-error
Способность отмены изменений при ошибке. Работает, если поддерживается способность candidate configuration.Writable-running
Такая способность говорит о том, что устройство позволяет писать непосредственно в running-конфигурацию, в обход candidate.Distinct startup
Способность задавать startup конфигурацию отличную от running и candidate.Notification
Аналог SNMP-trap. Коробка может слать аварии и события клиенту.
И ещё несколько более других способностей, которыми грузить вас не хочу, ибо в лучшем виде они описаны в RFC. Посмотрите, кстати, какие способности отдал джунипер, а какие нет.
NETCONF Extended Capabilities (сверх-способности)
Их тьма. Из самых интересных:
YANG push
Способность отсылать данные с коробки на клиент - периодически или по событию.YANG-library
Способность сервера сообщить клиенту о поддерживаемых параметрах относительно YANG: версия, модель, неймспейсы итд.Commit-description
Самоговорящее название.
Формат названия capability строго регламентирован:
urn:ietf:params:netconf:capability:{name}:1.0.
Последние два значения - это имя и версия - и только они могут меняться. Так urn:ietf:params:netconf:base:1.1 - это имя базовой капабилити для версии 1.1.
В ответ на <hello> сервера клиент в свою очередь должен послать свои capability:
<hello> <capabilities> <capability>urn:ietf:params:xml:ns:netconf:base:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:candidate:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:confirmed-commit:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:validate:1.0</capability> <capability>urn:ietf:params:xml:ns:netconf:capability:url:1.0?protocol=http,ftp,file</capability> <capability>xml.juniper.net/netconf/junos/1.0</capability> <capability>xml.juniper.net/dmi/system/1.0</capability> </capabilities> </hello> ]]>]]>
Чего почти нигде не пишут, но что очень важно: если вы пробуете взаимодействовать с коробкой по нетконф руками, то нужно обязательно вручную отослать такую последовательность ]]>]]>, сообщающую, что ввод закончен. Она называется Framing Marker или Message Separator Sequence.
Есть важный нюанс, описанный в RFC6242,
]]>]]>- это старый End-of-Message Framing Marker, который был выбран из соображений, что такая последовательность не должна встречаться в well-formed XML. Однако жизнь показала, что она встречается. Поэтому в NETCONF 1.1 придумали новый механизм, который делит данные на блоки - чанки - и нумерует их. Так он и называется: Chunked Framing Mechanism.Каждый чанк данных начинается с
##X, гдеX- это число октетов в нём.Это одно из фундаментальных отличий между 1.0 и 1.1 :). Другие менее значительны.
Сейчас NETCONF-сессия установлена и можно заслать какой-то RPC.
Посылаем свой первый RPC
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <running/> </source> <filter type="subtree"> <configuration> <system> <host-name/> </system> </configuration> </filter> </get-config> </rpc> ]]>]]>
<rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:commit-seconds="1644510087" junos:commit-localtime="2022-02-10 16:21:27 UTC" junos:commit-user="eucariot"> <system> <host-name>kzn-spine-0</host-name> </system> </configuration> </data> </rpc-reply>
Мы отправили элемент <rpc>, в котором запросили <running>-конфигурацию с помощью операцию <get-config>. И ещё на сервере отфильтровали по интересной ветке.
А в ответ пришёл <rpc-reply> с ответом. И в запросе, и в ответе можете найти message-id - по ним можно отслеживать на что именно ответ - ведь режим работы NETCONF асинхронный и можно засылать следующее сообщение, пока предыдущее ещё не было обработано.
Здесь вы видите некоторую структуру XML. Её легко можно скормить XML-парсеру, который превратит его в JSON или python dict или что угодно другое, с чем удобно работать в скриптах и программах. И далее извлечь по ключам нужные данные.
Но почему XML? За что? Как вообще с этим быть?
Ох. Зря вы спросили.
В общем дальше 10 000 знаков про XML. Если вы не готовы это выдержать, милости прошу дальше. Но будьте готовы, что практика NETCONF тогда пройдёт мимо вас. Или вы мимо неё. В общем разминётесь.
Так за что же так с нами?
<XML>
По всей видимости наиболее точный и честный ответ - "исторически сложилось".
Судьба XML в чём-то похожа на MPLS - оба были созданы для одной задачи, а популярность снискали в другой.
XML намеревался стать метаязыком для создания языков разметки документов. Но очень быстро его адаптировали под формат сериализации данных при передаче. И к моменту, когда Juniper выбирал формат, в котором API будет принимать запросы, XML стал уже проверенным, зрелым кандидатом.
Сегодня, вероятно, победил бы JSON, но тогда он только начинал свой путь к славе.

YAML и protobuf тогда ещё не существовали. Ну и вообще YAML подходит лучше для описания конфигураций, которые редактируются руками, нежели как формат обмена данными.
Прелюбопытная историческая справка по XML, JSON и YAML: YAML: The Missing Battery in Python.
В общем выбор в те дни был предопределён - XML был сверхсовременным и суперудобным,
Сложность читаемости XML компенсируется простотой его программной обработки. Чёткая иерархическая структура, понятные начало, конец и значение. В том же питоне xmltodict изящно любой валидный XML разворачивает в словарь. А вообще вот годная статья про то, как предполагается работать с XML средствами стандартной библиотеки.
Но давайте разбираться с тем, что же в себе интересного таит XML.
У меня нет задачи подвергнуть читателя пыткам и мучительной смерти через зачитывание стандартов, поэтому сильно глубоко мы погружаться не будем, но какую-то скучную базу дать придётся.
XML сам по себе не делает ничего - это только формат представления информации, в отличие от HTML, который как раз таки призван отрисовать содержимое.
XML описывает что за данные внутри, а его теги не определены заранее, опять же в отличие от HTML.
То есть это два брата, похожих друг на друга внешне, но очень разных внутри.
Давайте сначала на отвлечённом примере поразбираемся?
<?xml version="1.0" encoding="UTF-8"?> <bookstore> <book> <title>Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <instock> </instock> </book> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <instock /> </book> </bookstore>
Тут у нас XML, описывающий книжный магазин и имеющиеся в нём книги. У каждой книги есть свой набор атрибутов - название, автор, год выпуска, наличие в магазине.
Всё начинается с
XML Prolog
<?xml version="1.0" encoding="UTF-8"?>
Это так называемый XML Prolog. Он опционален, однако обычно присутствует и должен идти первой строкой. Версия всегда строго 1.0, кодировка по умолчанию - UTF-8.
Коль скоро он опциональный, далее мы его опускаем.
Дерево элементов
XML представляет из себя дерево, состоящее из отдельных элементов. Оно может быть произвольной вложенности. Самый первый элемент называется корневым - root, все последующие - его дети. В примере выше это <bookstore>. Элемент представляет из себя открывающий и закрывающий теги и содержимое. Теги заключены в угловые скобки и чувствительны к регистру. <bookstore> и <Bookstore> - это разные теги. Соответственно между каждой парой определены отношения - родитель-ребёнок или сёстры (siblings).
Детьми корневого элемента являются элементы <book>. Разные элементы <book> друг для друга являются сёстрами. Как такового понятия списка в XML нет, но по имени элемента мы (и код) понимаем, что они представляют из себя именно список. У элемента <book> есть дочерние элементы. Их состав совсем не обязательно должен быть одинаковым - XML этого не требует, однако этого может (и скорее всего будет) требовать приложение.
Главное правило XML - каждый открывшийся тег должен быть закрыт: сказал <a> - говори и </a>. Элемент может быть пустым, просто выражая факт своего существования, тогда запись <instock></instock> можно заменить на просто <instock/>.
Атрибуты
Взглянем на другой пример:
<bookstore> <book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> </book> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> </book></bookstore>
Теперь внутри тега появилась строка вида category="cooking". Она описывает дополнительные данные об элементе. Своего рода метаданные.
При этом вот эти две записи абсолютно равноправны с точки зрения XML:
<book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> </book>
и
<book> <category>cooking</category> <title>Everyday Italian <lang>en</lang> </title> <author>Giada De Laurentiis</author> <year>2005</year> </book>
То есть XML в терминах ни синтаксиса, ни семантики понятия дочерний элемент и атрибут не разделяет. Это остаётся исключительно на совести составителя/разработчика.
В целом к этому следует относиться именно как к метаданным - информации об информации. То есть если это не является неотъемлемым свойством объекта или нужно в служебных целях, то его можно вынести в атрибуты.
Чтобы далеко не уходить, вот пример из netconf:
<rpc message-id=”101″> <get-config> <source> <running/> </source> </get-config> </rpc>
Здесь message-id - это атрибут элемента RPC, который не имеет непосредственного отношения к передаваемым далее данным, но позволяет отследить по message-id ответ сервера (он вставит его в <rpc-reply>).
Ещё один пример, который мы будем разбирать дальше: <interfaces operation="replace">. Атрибут operation="replace" не является частью конфигурации интерфейса, он лишь говорит, что то, что существует сейчас на коробке в ветке <interfaces>, нужно заменить на то, что описано в данном XML.
Ну и замечу, что пусть с точки зрения XML атрибут и дочерний элемент взаимозаменяемы, когда вы придумываете свою схему обмена или хранения, однако NETCONF вам такого не простит. Да и любой другой интерфейс, в который вы встраиваетесь - ведь в нём уже определена схема XML.
Namespaces
Хух. Я откладывал много лет момент, когда придётся разобраться с неймспейсами в XML. На самом деле ничего тут нет хитрого. Если мы определили два разных элемента с одинаковыми именами, то появляется неоднозначность - какой именно элемент мы имеем в виду, обращаясь к нему по имени? Например, элемент <name> может быть как у интерфейса, так и у пользователя и у влана итд. Их можно разнести в разные NS, хотя это не обязательно, потому что они находятся под разными родителями. А если на одном уровне могут оказаться совпадающие имена - это уже настоящая проблема. Например,
<root> <address> <city> <name>Moscow</name> <street>Novocheremushkinskaya, 50</street> </city> </address> <address> <ipv6>2a01:ba80:e:20::32</ipv6> <ipv4>185.127.149.137</ipv4> </address> </root>
В первом случае имеется в виду почтовый адрес, во втором - IP.
Здесь уже однозначно будет конфликт. Надо решать.
Сделать это можно несколькими способами.
Прямо объявляем неймспейсы с префиксами:
<root> <postal:address xmlns:postal="https://www.linkmeup.ru/postal_address/"> <postal:city> <postal:name>Moscow</postal:name> <postal:street>Novocheremushkinskaya, 50</postal:street> </postal:city> </postal:address> <ip:address xmlns:ip="https://www.linkmeup.ru/ip/"> <ip:ipv6>2a01:ba80:e:20::32</ip:ipv6> <ip:ipv4>185.127.149.137</ip:ipv4> </ip:address> </root>Теперь это полное, fully qualified, имя безо всяких ограничений. Обращаемся из приложений, соответственно, по полному имени.
postalиip- это короткие префиксы. Само имя namespace - это произвольная строка. Но негласная договорённость, что все используют URI. Он может вести на страницу с описанием этого неймспейса, а может и не вести.Но указание префикса в каждом теге может показаться не очень удобным, тогда есть второй способ.Определяем default namespace
<root> <address xmlns="https://www.linkmeup.ru/postal_address/"> <city> <name>Moscow</name> <street>Novocheremushkinskaya, 50</street> </city> </address> <address xmlns="https://www.linkmeup.ru/ip/"> <ipv6>2a01:ba80:e:20::32</ipv6> <ipv4>185.127.149.137</ipv4> </address> </root>Область действия дефолтного неймспейса - сам элемент и все его потомки, если он нигде не переопределяется.
Концепция namespace с одной стороны проста, с другой стороны и там есть место тёмным пятнам. Если хочется подетальнее изучить, то есть парочка полезных FAQ про них.
Xpath - XML Path
Сначала правильно, но непонятно: XPath - это способ выбрать ноды или множество нод из XML документа.
Теперь неправильно, но понятно: это способ представить иерархию XML в виде "привычного" нам пути, где элементы отделены друг от друга знаком "/".
Например, в XML из примера выше путь к элементу <title> будет записан в виде /bookstore/book/title
Ну а теперь и правильно, и понятно, но долго.
XPath - это очень гибкий и мощный инструмент, позволяющий внутри XML делать разнообразные запросы. Он поддерживает различные функции: sum, count, avg, min, starts-with, contains, concat, true, false - над разными типами данных: числа, строки, булевы.
Так с помощью XPath можно выбрать названия всех книг с ценою выше 35: /bookstore/book[price>35]/title
XPath оперирует нодами, которыми являются элементы, атрибуты, текст, неймспейсы и другое.
Соответственно помимо того, что мы можем запросить часть XML по конкретному пути, можно делать разные хитрые запросы.
Например:
Вернуть BGP-группу, в которой есть peer 10.1.1.1;
Вернуть интерфейс, на котором число ошибок больше 100;
Вернуть список интерфейсов, на которых native-vlan 127;
Вернуть количество интерфейсов, в имени которых есть "Ethernet".
В контексте NETCONF вы можете его встретить, но это не самая популярная capability. В общем, знать про него полезно, но глубоко копать не будем. Если хочется поподробнее почитать, то это можно сделать например, тут.
Схема
Что такое XML - это удобный способ передавать структурированные данные между приложениями. Но это лишено какого-либо смысла, есть нет контракта о том, как данные в этих файлах должны храниться - где какие элементы и какого они типа.
Представьте, что информацию об IP-адресах мы будем помещать непосредственно в элемент <interface>, а читать его пытаются из элемента <unit>?
Или дату мы передаём в формате YYYY-MM-DD, а читать её пытаются в MM-DD-YYYY (больные ублюдки). При этом сам XML будет абсолютно "Well Formed", что называется - то есть соответствовать синтаксису XML. Для этого и существует Схема. В отдельном XML-файле описывается схема данных для основного XML.
Это позволяет
двум сторонам использовать один и тот же способ хранения и распаковки данных.
описывать содержимое документа
определять ограничение на данные
проверять корректность XML
Называется это хозяйство XML Schema Definition - или коротко XSD.
Поскольку это тот же самый XML, он должен как-то обозначать себя, что является схемой. Для этого есть ключевой элемент <schema>. Вот так будет выглядеть XSD для кусочка XML выше:
<?xml version="1.0" encoding="utf-8"?> <xs:schemaxmlns:xs="http://www.w3.org/2001/XMLSchema"> <xs:elementname="address"> <xs:complexType> <xs:sequence> <xs:elementname="country_name" type="xs:string"/> <xs:elementname="population" type="xs:decimal"/> </xs:sequence> </xs:complexType> </xs:element> </xs:schema>
При этом в самом XML можно дать ссылку на XSD
<note xmlns="https://www.linkmeup.ru" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://www.linkmeup.ru/404.xsd">
Самостоятельное продолжение изучения XSD.
Лучшая сторона XSD - это то, что на его основе можно автоматически генерировать объекты в языках программирования. То есть XSD описывает, какие именно объекты и структуры должны быть созданы, а конкретный XML - наполняет экземпляр, пользоваться которым значительно удобнее, чем крафтить XML.
С схемами и моделями мы будем разбираться дальше.
Надеюсь получилось, не утопая в деталях, дать понимание, что из себя представляет XML. Далее для нас это будет важным.
</XML>
NETCONF Again
И вот теперь время взглянуть на операции NETCONF и попрактиковаться.
Один из принципов NETCONF - это отделение конфигурационных данных от операционных.
Поэтому отдельными операциями он позволяет управлять конфигурацией, а отдельными - забирать информацию о состоянии.
Вот базовый неполный список операций NETCONF:
<get><get-config><edit-config><copy-config><delete-config><lock><unlock><close-session><kill-session>
Но зачастую вендоры определяют свои собственные операции.
Действия, операции
<get>
Эта операция возвращает текущие (running) операционные и конфигурационные данные.
Выполните просто
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get/> </rpc> ]]>]]>
И в ответ получите несколько экранов XML.
Ответ приходит в <rpc-reply>. В случае ошибки внутри <rpc-reply> сервер вернёт <rpc-error> с текстом ошибки.
Для получения ошибки можно просто сформировать некорректный XML.
Например, забудем закрывающий тег </get>:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <rpc-error> <error-type>protocol</error-type> <error-tag>operation-failed</error-tag> <error-severity>error</error-severity> <error-message>syntax error, expecting <filter> or </get></error-message> <error-info> <bad-element>interfaces</bad-element> </error-info> </rpc-error> </rpc-reply>
Или запросить несуществующую ветку:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> <interfaces/> </get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <rpc-error> <error-type>protocol</error-type> <error-tag>operation-failed</error-tag> <error-severity>error</error-severity> <error-message>syntax error, expecting <filter> or </get></error-message> <error-info> <bad-element>interfaces</bad-element> </error-info> </rpc-error> </rpc-reply>
В зависимости от вендора в ответе на <get> будет содержаться либо вообще всё, что вам может дать устройство - полный конфиг и вся информацию по состоянию, либо какую-то часть.
Так, Juniper возвращается конфиг и совсем немного данных сверху. Для того, чтобы забрать операционные данные нужно использовать специальные операции, например <get-interface-information>:
<rpc> <get-interface-information/> </rpc>
Вот такой будет ответ: https://pastebin.com/2xTpuSi3.
Этому, кстати, сложно найти объяснение. Довольно неудобно для каждой ветки операционных данных иметь собственный RPC. И более того, непонятно как это вообще описывается в моделях данных.
Очевидно, это не всегда (никогда) удобно. Хотелось бы пофильтровать данные. NETCONF позволяет не просто отфильтровать результат, а указать NETCONF-серверу, какую именно часть клиент желает запросить. Для этого используется элемент <filter>.
<filter>
С его помощью можно указать какую именно часть информации вы хотите получить. Можно указывать атрибут фильтрации, поддерживаются subtree и xpath. По умолчанию используется subtree, но обычно его задают явно, дабы избежать двусмысленности.
Давайте на примере get пофильтруем ответ. Без фильтра совсем данные вернутся полностью.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get/> </rpc> ]]>]]>
Вот такой будет ответ: https://pastebin.com/MMWXM2eT.
С пустым фильтром не вернётся никаких данных.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> <filter type="subtree"> </filter> </get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <database-status-information> <database-status> <user>eucariot</user> <terminal></terminal> <pid>31101</pid> <start-time junos:seconds="1644636396">2022-02-12 03:26:36 UTC</start-time> <edit-path></edit-path> </database-status> </database-status-information> </data> </rpc-reply> ]]>]]>
Вот таким запросом можно вытащить операционные данные по всем интерфейсам:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> <filter type="subtree"> <configuration> <interfaces/> </configuration> </filter> </get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:changed-seconds="1644510087" junos:changed-localtime="2022-02-10 16:21:27 UTC"> <interfaces> <interface> <name>ge-0/0/0</name> <unit> <name>0</name> <family> <inet> <address> <name>169.254.0.1/31</name> </address> </inet> </family> </unit> </interface> <interface> <name>ge-0/0/2</name> <unit> <name>0</name> <family> <inet> <address> <name>169.254.100.1/31</name> </address> </inet> </family> </unit> </interface> <interface> <name>em0</name> <unit> <name>0</name> <family> <inet> <address> <name>192.168.1.2/24</name> </address> </inet> </family> </unit> </interface> </interfaces> </configuration> <database-status-information> <database-status> <user>eucariot</user> <terminal></terminal> <pid>31101</pid> <start-time junos:seconds="1644636721">2022-02-12 03:32:01 UTC</start-time> <edit-path></edit-path> </database-status> </database-status-information> </data> </rpc-reply> ]]>]]>
Если вы хотите выбрать не все элементы дерева, а только интересующую вас часть, то можно указать, какие именно нужны:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> <filter type="subtree"> <configuration> <interfaces> <interface> <name/> <description/> </interface> </interfaces> </configuration> </filter> </get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:changed-seconds="1644637011" junos:changed-localtime="2022-02-12 03:36:51 UTC"> <interfaces> <interface> <name>ge-0/0/0</name> <description>kzn-leaf-0</description> </interface> <interface> <name>ge-0/0/2</name> <description>kzn-edge-0</description> </interface> <interface> <name>em0</name> <description>mgmt-switch</description> </interface> </interfaces> </configuration> <database-status-information> <database-status> <user>eucariot</user> <terminal></terminal> <pid>31316</pid> <start-time junos:seconds="1644637103">2022-02-12 03:38:23 UTC</start-time> <edit-path></edit-path> </database-status> </database-status-information> </data> </rpc-reply> ]]>]]>
При этом если хочется забрать данные только по конкретному интерфейсу:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> <filter type="subtree"> <configuration> <interfaces> <interface> <name>ge-0/0/0</name> </interface> </interfaces> </configuration> </filter> </get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:changed-seconds="1644637011" junos:changed-localtime="2022-02-12 03:36:51 UTC"> <interfaces> <interface> <name>ge-0/0/0</name> <description>kzn-leaf-0</description> <unit> <name>0</name> <family> <inet> <address> <name>169.254.0.1/31</name> </address> </inet> </family> </unit> </interface> </interfaces> </configuration> <database-status-information> <database-status> <user>eucariot</user> <terminal></terminal> <pid>31316</pid> <start-time junos:seconds="1644637321">2022-02-12 03:42:01 UTC</start-time> <edit-path></edit-path> </database-status> </database-status-information> </data> </rpc-reply> ]]>]]>
Соответственно можно совместить запрос конкретного интерфейса и только тех его полей, которые интересны.
В одном get-запросе можно выбрать несколько удовлетворяющих деревьев.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get> <filter type="subtree"> <configuration> <interfaces> <interface> <name>ge-0/0/0</name> <description/> </interface> </interfaces> </configuration> </filter> </get> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:changed-seconds="1644637011" junos:changed-localtime="2022-02-12 03:36:51 UTC"> <interfaces> <interface> <name>ge-0/0/0</name> <description>kzn-leaf-0</description> </interface> </interfaces> </configuration> <database-status-information> <database-status> <user>eucariot</user> <terminal></terminal> <pid>31316</pid> <start-time junos:seconds="1644637396">2022-02-12 03:43:16 UTC</start-time> <edit-path></edit-path> </database-status> </database-status-information> </data> </rpc-reply> ]]>]]>
Ещё немного про subtree filtering.
В случае Juniper <get> ничем практически не отличается от <get-config>. Для того, чтобы забрать операционные данные, нужно воспользоваться другими операциями - специфическими под каждую задачу.
Узнать их можно достаточно просто:
show version | display xml rpc
С помощью операций <get> удобно забирать операционные данные с устройства. Например, для мониторинга. Или для отладки. Можно выбрать всех BGP-соседей в состоянии Idle, или все интерфейсы с ошибками, данные по маршрутам. Да, понятно, что для всего этого есть и более удобные способы, но всё же такой путь есть.
<get-config>
Позволяет забрать конфигурацию устройства. Могло показаться, что <get-config> - это поддерево <get>, но это всё-таки не так.
С помощью <get-config> можно указать из какого источника мы хотим получить конфигу - running, candidate, startup итд.
Ну и можно быть уверенным, что в ответе будут только конфигурационные данные.
Хотя по своему опыту вам скажу, что вендоры тут могут отличаться изобретательностью, подмешивая оперданные к конфиге.
Забираем текущий конфиг:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <running/> </source> </get-config> </rpc> ]]>]]>
<get-config> так же, как и <get> позволяет использовать элемент <filter>. Например:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <running/> </source> <filter type="subtree"> <configuration> <system> <host-name/> </system> </configuration> </filter> </get-config> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:commit-seconds="1644637011" junos:commit-localtime="2022-02-12 03:36:51 UTC" junos:commit-user="eucariot"> <system> <host-name>kzn-spine-0</host-name> </system> </configuration> </data> </rpc-reply> ]]>]]>
В запросе самые внимательные обратили внимание на элемент <source>.
Configuration Datastores
Это место для хранения полной конфигурации. Хотя слово "хранения", возможно, и не очень точное. Обязательным является только <running> - это текущая актуальная конфигурация.
В зависимости от вендора и поддерживаемых капабилитей могут быть так же <candidate>, <startup> и какие-то другие.
Соответственно запросить конфигурацию можно из разных Datastores при их наличии, указывая соответствующий элемент внутри <source>.
Как увидим далее, менять конфигурацию так же, можно в разных datastores через <target>.
И тут разные вендоры ведут себя по-разному, кто-то разрешает менять сразу в <running>, а кто-то только <candidate> с последующим <commit>.
<edit-config>
ЕЙ богу, самая интересная штука во всём NETCONF! Операция, с помощью которой можно привести конфигурацию к нужному состоянию. Серебряная пуля, панацея, окончательное решение конфигурационного вопроса. Ага, щаз!
Идея в теории прекрасна: мы отправляем на устройство желаемую конфигурацию в виде XML, а оно само шуршит и считает, что нужно применить, а что удалить. Давайте идеальный случай и разберём сначала.
<edit-config> позволяет загрузить полную конфигурацию устройства или его часть в указанный datastore. При этом устройство сравнивает актуальную конфигурацию в datastore и передаваемую с клиента и предпринимает указанные действия.
А какие действия могут быть указаны? Это определяется атрибутом operation в любом из элементов поддерева <configuration>. Operation может встречаться несколько раз в XML и быть при этом разным. Атрибут может принимать следующие значения:
Merge - новая конфига вливается в старую - что необходимо заменить - заменяется, новое - добавляется, ничего не удаляется.
Replace - заменяет старую конфигурацию новой.
Create - создаёт блок конфигурации. Однако, если он уже существует, вернётся
<rpc-error>Delete - удаляет блок конфигурации. Однако, если его не существует, вернётся
<rpc-error>Remove - удаляет блок конфигурации. Однако, если его не существует, проигнорирует. Определён в RFC6241.
Если тип операции не задан, то новая конфигурация будет вмёржена в старую. Задать операцию по умолчанию можно с помощью параметра <default-operation>: merge, replace, none.
В дереве <configuration> задаётся собственно целевая конфигурация в виде XML.
Безусловно, самая интересная операция внутри<edit-config> - это replace. Ведь она предполагает, что устройство возьмёт конфигурацию из RPC и заменит ею ту, что находится в datastore. А где-то там под капотом и крышкой блока цилиндров система сама просчитает дельту, которую нужно отправить на чипы.
Практика edit-config
Давайте сначала что-то простое: поменяет hostname:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <edit-config> <target> <candidate/> </target> <config> <configuration> <system> <host-name>just-for-lulz</host-name> </system> </configuration> </config> </edit-config> </rpc> ]]>]]>
Проверяем, что в кандидат-конфиге эти изменения есть, а в текущем - нет
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <candidate/> </source> <filter type="subtree"> <configuration> <system> <host-name/> </system> </configuration> </filter> </get-config> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:changed-seconds="1644719855" junos:changed-localtime="2022-02-13 02:37:35 UTC"> <system> <host-name>just-for-lulz</host-name> </system> </configuration> </data> </rpc-reply> ]]>]]>
Проверяем running:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <running/> </source> <filter type="subtree"> <configuration> <system> <host-name/> </system> </configuration> </filter> </get-config> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:commit-seconds="1644637011" junos:commit-localtime="2022-02-12 03:36:51 UTC" junos:commit-user="eucariot"> <system> <host-name>kzn-spine-0</host-name> </system> </configuration> </data> </rpc-reply>
Значит, надо закоммитить изменения.
<rpc> <commit/> </rpc> ]]>]]> <rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos"> <ok/> </rpc-reply>
Проверяем running:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <running/> </source> <filter type="subtree"> <configuration> <system> <host-name/> </system> </configuration> </filter> </get-config> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:commit-seconds="1644720065" junos:commit-localtime="2022-02-13 02:41:05 UTC" junos:commit-user="eucariot"> <system> <host-name>just-for-lulz</host-name> </system> </configuration> </data> </rpc-reply>
На Juniper доступны в NETCONF те же функции коммитов, что и в CLI. Например, commit confirmed и confirmed-timeout.
А теперь что-то посложнее и с операцией replace: заменим список BGP-пиров:
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <edit-config> <target> <candidate/> </target> <config> <configuration> <protocols> <bgp operation="replace"> <group> <name>LEAFS</name> <type>external</type> <import>ALLOW</import> <family> <inet> <unicast> </unicast> </inet> </family> <export>EXPORT</export> <neighbor> <name>169.254.0.0</name> <peer-as>64513.00000</peer-as> </neighbor> </group> <group> <name>EDGES</name> <type>external</type> <import>ALLOW</import> <family> <inet> <unicast> </unicast> </inet> </family> <export>EXPORT</export> <neighbor> <name>222.222.222.0</name> <peer-as>65535</peer-as> </neighbor> </group> </bgp> </protocols> </configuration> </config> </edit-config> </rpc> ]]>]]>
Коммит
<rpc> <commit/> </rpc> ]]>]]>
Проверяем running
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <get-config> <source> <running/> </source> <filter type="subtree"> <configuration> <protocols> <bgp> <group> <neighbor/> </group> </bgp> </protocols> </configuration> </filter> </get-config> </rpc> ]]>]]> <rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:commit-seconds="1644720678" junos:commit-localtime="2022-02-13 02:51:18 UTC" junos:commit-user="eucariot"> <protocols> <bgp> <group> <name>LEAFS</name> <neighbor> <name>169.254.0.0</name> <peer-as>64513.00000</peer-as> </neighbor> </group> <group> <name>EDGES</name> <neighbor> <name>222.222.222.0</name> <peer-as>65535</peer-as> </neighbor> </group> </bgp> </protocols> </configuration> </data> </rpc-reply>
Всё сработало)
А теперь попробуем операцию merge при добавлении нового пира.
<rpc message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <edit-config> <target> <candidate/> </target> <config> <configuration> <protocols> <bgp operation="merge"> <group> <name>LEAFS</name> <type>external</type> <import>ALLOW</import> <family> <inet> <unicast> </unicast> </inet> </family> <export>EXPORT</export> <neighbor> <name>169.254.0.0</name> <peer-as>64513.00000</peer-as> </neighbor> </group> <group> <name>EDGES</name> <type>external</type> <import>ALLOW</import> <family> <inet> <unicast> </unicast> </inet> </family> <export>EXPORT</export> <neighbor> <name>222.222.222.0</name> <peer-as>65535</peer-as> </neighbor> <neighbor> <name>169.254.100.0</name> <peer-as>65535</peer-as> </neighbor> </group> </bgp> </protocols> </configuration> </config> </edit-config> </rpc> ]]>]]>
Коммит
<rpc> <commit/> </rpc> ]]>]]>
Проверка:
<rpc-reply xmlns:junos="http://xml.juniper.net/junos/14.1R1/junos" message-id="100" xmlns="urn:ietf:params:xml:ns:netconf:base:1.0"> <data> <configuration xmlns="http://xml.juniper.net/xnm/1.1/xnm" junos:commit-seconds="1644721481" junos:commit-localtime="2022-02-13 03:04:41 UTC" junos:commit-user="eucariot"> <protocols> <bgp> <group> <name>LEAFS</name> <neighbor> <name>169.254.0.0</name> <peer-as>64513.00000</peer-as> </neighbor> </group> <group> <name>EDGES</name> <neighbor> <name>222.222.222.0</name> <peer-as>65535</peer-as> </neighbor> <neighbor> <name>169.254.100.0</name> <peer-as>65535</peer-as> </neighbor> </group> </bgp> </protocols> </configuration> </data> </rpc-reply> ]]>]]>
Вот он новенький пир, и старые на месте.
То есть достаточно очевидна разница между работой replace и merge.
Operation replace
С replace следует иметь в виду некоторые нюансы. Например, что нужно передавать полную конфигурацию того или иного сервиса или функциональности - не просто новые параметры - ведь железка натурально заменит то, что было, тем, что прилетело. Едва ли вы хотите создав один интерфейс в OSPF Area, удалить остальные?
Некоторые сущности не могут быть удалены, такие, например, как физические интерфейсы. Поэтому при формировании соответствующего блока конфигурации нужно быть аккуратнее - в целевой конфигурации должны все они присутствовать, иначе в лучшем случае вернётся <rpc-error>, а в худшем вы чего-то поудаляете.
Использовать replace можно как на уровне отдельных частей конфигурации, так и на верхнем уровне, требуя заменить всё поддерево.
Однако ещё один нюанс заключается в том, что в зависимости от реализации вычисление дельты может занять много ресурсов CPU. Поэтому, если собираетесь кинуть диф на 13 000 строк политик BGP, то дважды подумайте и трижды оттестируйте, что после этого происходит с коробкой.
<commit>
Ещё одно свидетельство того, что модель NETCONF скалькирована с API Juniper - это возможность commit'a candidate-конфигурации в running. Доступна она, конечно, только в том случае, если при обмене capability сервер сообщил, что поддерживает candidate datastore.<commit> не замещает running на candidate, как это делает <copy-config>, а выполняет именно применение конфигурационной дельты, как это происходит в CLI.
Как и в CLI у commit может быть параметр confirmed, заставляющий откатить изменения, если commit не был подтверждён. За это отвечает отдельная capability: confirmed-commit.
<commit> не входит в число базовых операций, поскольку как раз зависит от поддерживаемых возможностей сервера.
<copy-config>
Операция заменяет одну конфигурацию другой. Имеет два параметра: source - откуда - и target - куда.
Может использоваться как для применения новой конфигурации на коробку, так и для бэкапа активной. Если коробка поддерживает capability :url, то в качестве source и/или target может быть указан URL.
<delete-config>
Очевидно, удаляет конфигурацию из target datastore. Без хитростей.
<lock/unlock>
Аналогично Juniper CLI ставит блок на target datastore от совместного редактирования, чтобы не было конфликта. Причём блок должен работать как на NETCONF, так и на другие способы изменения конфигурации - SNMP, CLI, gRPC итд.
<close-session>
Аккуратно закрывает существующую NETCONF-сессию, снимает локи, высвобождает ресурсы.
<kill-session>
Грубо разрывает сессию, но снимает локи. Если сервер получил такую операцию в тот момент, когда он дожидается confirmed commit, он должен отменить его и откатить изменения к состоянию, как было до установки сессии.
Инструменты разработчика для NETCONF
Ну вот как будто бы необходимый базис по NETCONF набрали.
Я в этой статье не ставлю перед собой задачу выстроить какую-то систему автоматизации.
Просто хочу показать разные интерфейсы в теории и на практике.
И я думаю, к этому моменту вам уже очевидно, что отправка XML через SSH с ручным проставлением Framing Marker (]]>]]>) - не самый удобный способ. Давайте посмотрим на существующие библиотеки.
netconf-console
Прежде чем писать какой-то код, обычно стоит проверить всё руками. Но вот руками крафтить XML и проставлять framing marker'ы тоскливо. Тут отца русской автоматизации спасёт netconf-console - главный и, возможно, единственный CLI-инструмент для работы с NETCONF.
Может работать в режиме команды:
netconf-console --host 192.168.1.2 --port 22 -u eucariot -p password --get-config
А может в интерактивном:
netconf-console2 --host 192.168.1.2 --port 22 -u eucariot -p password -i netconf> hello
Чуть больше про библиотеку у Романа Додина.
NCclient
Это, пожалуй, самая известная библиотека для работы с NETCONF. Она для питона и достаточно зрелая.
Начать пользоваться очень легко:
from ncclient import manager if __name__ == "__main__": with manager.connect( host="kzn-spine-0.juniper", ssh_config=True, hostkey_verify=False, device_params={'name': 'junos'} ) as m: c = m.get_config(source='running').data_xml print(c)
Дабы уберечь читателя от многочасовых мук с отладкой аунтентификации, небольшая подсказка тут.
Текущая версия
paramikoна момент написания статьи (>=2.9.0), которую подтягиваетncclient, в ряде случае не может работать с OpenSSH-ключами и падает с ошибкой "Authentication failed". Рекомендую в этом случае устанавливать 2.8.0. На гитхабе открыта куча issue на эту тему. И, кажется, его даже починили, но я не проверял.И вроде бы даже есть решение, но и это я не проверял.
Так же работают filter:
from ncclient import manager rpc = """ <filter> <configuration> <system> <host-name/> </system> </configuration> </filter> """ if __name__ == "__main__": with manager.connect( host="kzn-spine-0.juniper", ssh_config=True, hostkey_verify=False, device_params={"name": "junos"} ) as m: c = m.get_config("running", rpc).data_xml print(c)
С таким вот результатом:
<?xml version="1.0" encoding="UTF-8"?> <rpc-reply message-id="urn:uuid:864dd143-7a86-40ca-8992-5a35f2322ea0"> <data> <configuration commit-seconds="1644732354" commit-localtime="2022-02-13 06:05:54 UTC" commit-user="eucariot"> <system> <host-name> kzn-spine-0 </host-name> </system> </configuration> </data> </rpc-reply>
На текстовый XML смотреть не надо - парсим библиотечкой xmltodict:
from ncclient import manager import xmltodict rpc = """ <filter> <configuration> <system> <host-name/> </system> </configuration> </filter> """ if __name__ == "__main__": with manager.connect( host="kzn-spine-0.juniper", ssh_config=True, hostkey_verify=False, device_params={"name": "junos"} ) as m: result = m.get_config("running", rpc).data_xml result_dict = xmltodict.parse(result) print(f'hostname is {result_dict["rpc-reply"]["data"]["configuration"]["system"]["host-name"]}')
С уже таким результатом:
hostname is kzn-spine-0
При работе с сетевыми коробками по NETCONF xmltodict, пожалуй, самая практичная библиотека, преобразующая XML-данные в объект Python. Она использует C-шный парсер pyexpat, так что недостатков у такого подхода фактически нет.
Точно так же можно обновить конфигурацию в два действия: <edit-config> в <candidate> и <commit>:
from ncclient import manager import xmltodict rpc = """ <config> <configuration> <interfaces> <interface> <name>ge-0/0/0</name> <description>Mit der Dummheit kämpfen Götter selbst vergebens.</description> </interface> </interfaces> </configuration> </config> """ if __name__ == "__main__": with manager.connect( host="kzn-spine-0.juniper", ssh_config=True, hostkey_verify=False, device_params={"name": "junos"} ) as m: result = m.edit_config(target="candidate", config=rpc).data_xml m.commit() result_dict = xmltodict.parse(result) print(result_dict) OrderedDict([('rpc-reply', OrderedDict([('@message-id', 'urn:uuid:93bde991-81f9-42d6-a343-b4fc267646c2'), ('ok', None)]))])
Дальше пока копать не будем. Тем более, бытует мнение "без всяких сомнений, самый ублюдочно написанный Python код, что я видел в opensource" ©
scrapli-netconf
NCclient был первым и классным, но отсутствие поддержки async в нём сильно ограничивает его использование.
Тут нас выручает Карл Монтанари, который уже подарил миру scrapli.
Но для тех, кто достаточно смел, чтобы использовать на своей сети NETCONF, создали scrapli-netconf.
Давайте взглянем на пару примеров работы.
from scrapli_netconf.driver import NetconfDriver rpc = """ <filter> <configuration> <system> <host-name/> </system> </configuration> </filter> """ device = { "host": "kzn-spine-0.juniper", "auth_strict_key": False, "port": 22 } if __name__ == "__main__": with NetconfDriver(**device) as conn: response = conn.get_config("running", rpc) print(response.result)
Scrapligo и scrapligo-netconf
Для Go тоже не придумано ничего лучше, чем scrapligo, в котором есть модуль для работы через netconf. Так что если вы сетевик, осваивающий Го, путь для вас уже проложен.
Как это использовать
Мониторинг
NETCONF предоставляет возможность собирать операционные данные:
Состояния протоколов (OPSF, BGP-пиринги).
Статистику интерфейсов.
Утилизацию ресурсов CPU.
Таблицы маршрутизации
Другое.
При этом возвращаются структурированные данные, с которыми легко работать без сложных процедур парсинга.
Поэтому NETCONF вполне можно использовать для целей мониторинга.
Тут вы спросите: а зачем, если есть SNMP? А я отвечу. Точнее постараюсь.
Используем безопасный SSH, не используем SNMP.
Не несём дополнительные протоколы в сеть.
Полная свобода того, какие данные мы собираем, без необходимости разбираться в OID'ах и MIB'ах.
При этом есть возможность собирать данные в соответствии с YANG-моделью.
Гипотетическая возможность оформить подписку на события в системе.
Выполнение отдельных операций
Используя NETCONF, можно выполнять какие-то конкретные задачи: собрать данные с сети или изменить какую-то часть конфигурации.
Например, вы хотите периодически собирать MAC-адреса с сети или список коммитов.
Или вам нужно переключать порт коммутатора в другой VLAN.
Или например, у вас есть скрипт, который проверяет, что устройство в порядке - правильные настройки сислог-сервера, корректное время и пинги, куда полагается, работают.
Это всё можно сделать и на парсинге CLI, безусловно, но структурированные данные - это структурированные данные, а regexp - это regexp.
Configuration Management
Да, это тоже возможно, если
Оборудование поддерживает 100% конфигурации через NETCONF.
Увы, я на своём веку повидал ситуаций, когда некоторые секции просто-напросто отсутствовали в NETCONF и никакого способа настроить нужную функцию нет.
Оборудование честно поддерживает операцию "replace", без этого вычисление конфигурационной дельты ложится вновь на сетевиков.
Однако, в том виде, в котором мы познакомились с темой на данный момент, дальше начинается Jinja-программирование. Каждому, кто этим занимался, обычно неловко, и он стыдливо избегает разговора на эту тему.
Задача решается примерно следующим образом:
Пишем циклопические развесистые jinja-шаблоны с ифами и форами, внутри которых XML. Шаблоны под каждого вендора, конечно, свои собственные, поскольку и схемы данных у них разные. Но при этом они универсальные в плане ролей устройств - не нужно для свитчей доступа и маршрутизаторов ядра писать разные шаблоны - просто в зависимости от роли будут активироваться те или иные их части. Здесь в нужных местах сразу описаны типы операций - где merge, где replace.
Каким-то образом формируем под каждое устройство файлы переменных, в которых указаны хостнеймы, IP-адреса, ASN, пиры и прочие специфические вещи. Эти файлы переменных в свою очередь, напротив, вендор-нейтральны, но будут отличаться от роли к роли.
Рендерим конфигурацию в формате XML, накладывая переменные на шаблоны. Получаем целевую конфигурацию в виде дерева XML, где в нужных местах проставлена операция
replace.Этот XML с помощью ncclient, ansible, scrapli-netconf или чего-то ещё подпихиваем на коробку.
NETCONF-сервер на коробке получает RPC и вычисляет конфигурационный патч, который фактически применит. То есть он находит разницу между целевой конфигурацией в RPC и текущей в
<running>. Применяет эту конфигурацию.
Как бы это могло выглядеть я уже показывал в предыдущем выпуске АДСМ.

Ручная правка файлов переменных - это очень неудобно, конечно же. Просто мрак, если мы говорим про какие-то типовые вещи, как например датацентровые регулярные топологии. Новая пачка стоек - сотни и тысячи строк для копипащения и ручного изменения. Но на самом деле их можно создавать автоматически на основе данных из централизованной базы данных - DCIM/IPAM.
Почему я об этом говорю так уверенно?
Потому что мы у себя (в Яндексе) полностью построили весь жизненный цикл отдельного сегмента сети на основе описанной схемы. И любые изменения на сеть могут применяться только через подобный конвейер и NETCONF. Любые временные конфигурации на железе перетрутся следующим же релизом.
Что тут хорошо:
Изменения в Jinja-шаблонах версионируются через git и проходят проверку другими инженерами перед применением. Это систематические изменения, влияющие на большое количество устройств.
Изменения в переменных - точно так же. Это точечное изменение конкретного устройства.
Только после согласования изменений в пунктах выше, можно сгенерировать новую конфигурацию и далее уже её отправить на проверку в git.
Если соблюдать процесс, то отсутствует конфигурационный дрейф.
Что тут плохо?
Ну, очевидно, Jinja-программирование
Работа с текстом, вместо объектов языка.
Отсутствие возможности взглянуть на конфигурационный диф до его применения.
На этом на самом деле заканчивается первая большая часть этой статьи, которая позволяет просто уже взять и получать пользу от NETCONF в задачах автоматизации.
Я вот прям серьёзно сейчас, ей богу! Не туманные абстракции - берём NETCONF - и на многих вендорах уже можно с ним работать выстраивая автоматизацию того или иного объёма.
Как вам ощущения от составления XML? А представьте, что вам нужно всю конфигурацию на несколько тысяч строк описать? А приправить это всё Jinja-программированием? А описывать в ямлах переменные?
Но абсолютное большинство тех, кто использует сегодня NETCONF, именно так и делают. (!) Мнение автора. Change my mind!
В то время как есть YANG и набор инструментов вокруг него?
Хух. Давайте просто не будем об этом сейчас? Просто не сейчас? Попозже. После RESTCONF и gRPC?
RESTCONF
Просто пара слов об этом мертворожденном протоколе.
Это помесь RESTAPI и NETCONF, которая была призвана упростить управление сетью для WEB-приложений.
Внутри идеологически это NETCONF с его datastores и способами работать с конфигурацией, однако в качестве транспорта - HTTP с набором операций CRUD, реализованных через стандартные методы (GET, POST, PUT, PATCH, DELETE). Данные передаются в формате JSON или XML. В качестве модели данных используется YANG.
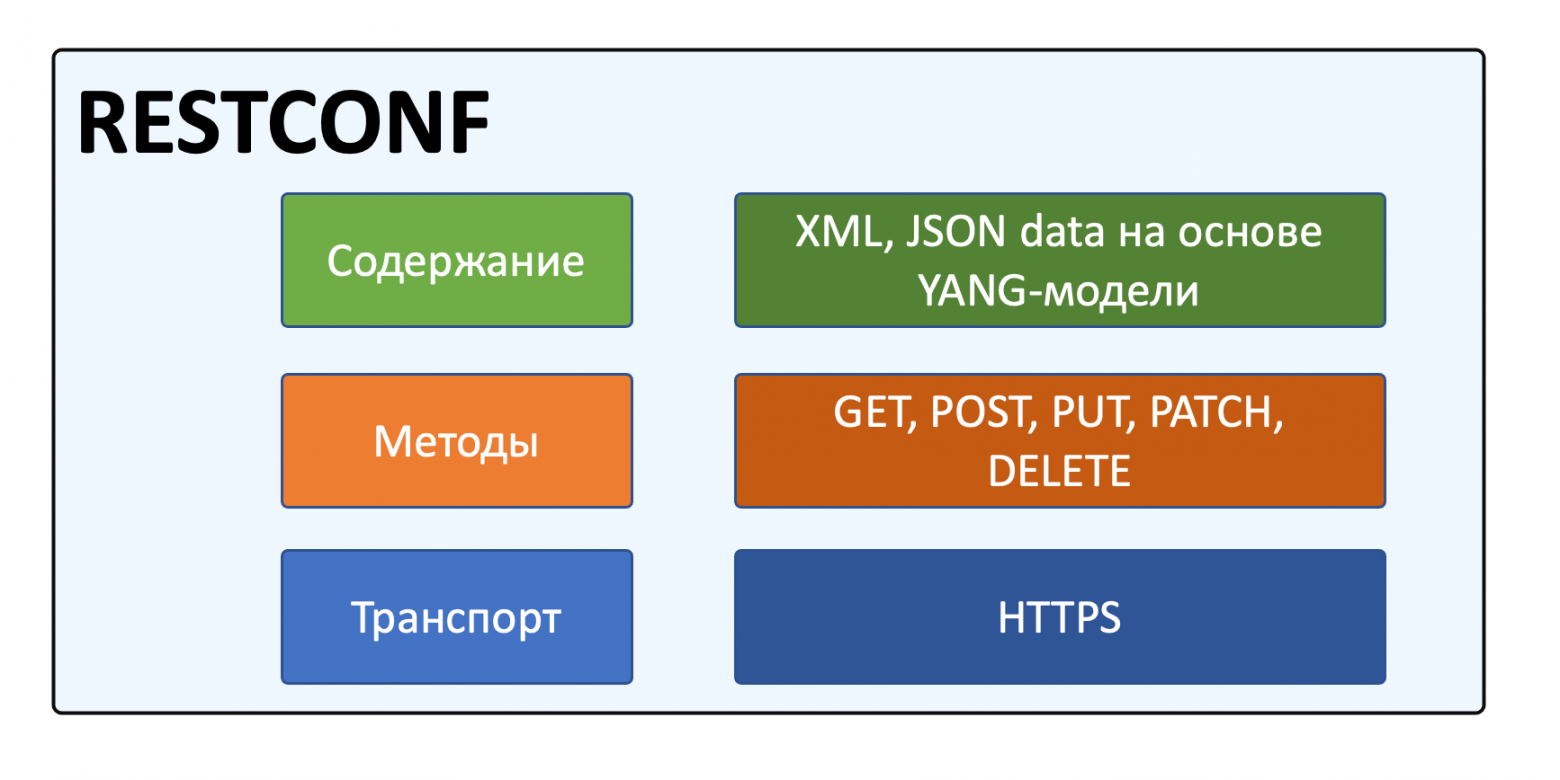
Описан в RFC8040.
Не могу отказать себе в удовольствии попробовать.
Возьмём на этот раз Arista veos-4.21.
Что нужно настроить, чтобы заработал restconf:
Выпускаем самоподписанный сертификат
security pki certificate generate self-signed restconf.crt key restconf.key generate rsa 2048 parameters common-name restconf certificate:restconf.crt generatedРазрешаем доступ на устройство по порту 6020 - правим
control-plane aclСмотрим то, что разрешено сейчас - это readonly acl.
show ip access-lists default-control-plane-aclКопируем правила и создаём копию ACL. Добавляем правило, разрешающее доступ по порту 6020:
ip access-list control-plane-acl-with-restconf 9 permit tcp any any eq 6020 30 permit udp any any eq bfd ttl eq 255 40 permit udp any any eq bfd-echo ttl eq 254 50 permit udp any any eq multihop-bfd 60 permit udp any any eq micro-bfd 70 permit ospf any any 80 permit tcp any any eq ssh telnet www snmp bgp https msdp ldp 90 permit udp any any eq bootps bootpc snmp rip ntp ldp 100 permit tcp any any eq mlag ttl eq 255 110 permit udp any any eq mlag ttl eq 255 120 permit vrrp any any 130 permit ahp any any 140 permit pim any any 150 permit igmp any any 160 permit tcp any any range 5900 5910 170 permit tcp any any range 50000 50100 180 permit udp any any range 51000 51100 190 permit tcp any any eq 3333 200 permit tcp any any eq nat ttl eq 255 210 permit tcp any eq bgp any 220 permit rsvp any anyПрименяем ACL на Control-Plane:
control-plane ip access-group control-plane-acl-with-restconf inВключаем сервис RESTCONF:
management api restconf transport https test ssl profile restconfНастраиваем SSL:
management security ssl profile restconf certificate restconf.crt key restconf.keyНастраиваем SSL.
Теперь проверяем, что порт открыт:
nc -zv bcn-spine-1.arista 6020 Connection to bcn-spine-1.arista 6020 port [tcp/*] succeeded!
И собственно курлим:
curl -k -s GET 'https://bcn-spine-1.arista:6020/restconf/data/openconfig-interfaces:interfaces/interface=Management1' \ --header 'Accept: application/yang-data+json' -u eucariot:password
Так мы извлекли информацию про интерфейс Management1.
А вот так можно получить данные по BGP:
curl -k -s GET 'https://bcn-spine-1.arista:6020/restconf/data/network-instances/network-instance/config/protocols' \ --header 'Accept: application/yang-data+json' -u eucariot:password | jq
Строка URL формируется следующим образом:
https://<ADDRESS>/<ROOT>/data/<[YANG-MODULE]:CONTAINER>/<LEAF>/[?<OPTIONS>]
<ADDRESS>- адрес RESTCONF-сервера.<ROOT>- Точка входа для запросов RESTCONF. Можно найти тут : https://<ADDRESS>/.well-known/data- прям так и остаётся<[YANG MODULE:]CONTAINER>- Базовый контейнер YANG. Наличие YANG Module - не обязательно.<LEAF>- Отдельный элемент в контейнере<OPTIONS>- Опциональные параметры, влияющие на результат.
Пробуем выяснить <ROOT>:
curl -k https://bcn-spine-1.arista:6020/.well-known/host-meta <XRD xmlns=’http://docs.oasis-open.org/ns/xri/xrd-1.0’> <Link rel=’restconf’ href=’/restconf’/> </XRD>
Ну можно и настроить что-нибудь:
К примеру hostname.
curl -k -X PUT https://bcn-spine-1.arista:6020/restconf/data/system/config \ -H 'Content-Type: application/json' -u eucariot:password \ -d '{"openconfig-system:hostname":"vika-kristina-0"}' {"openconfig-system:hostname":"vika-kristina-0"}
Проверим?
curl -k -X GET https://bcn-spine-1.arista:6020/restconf/data/system/config \ --header 'Accept: application/yang-data+json' \ -u eucariot:password {"openconfig-system:hostname":"bcn-spine-1","openconfig-system:login-banner":"","openconfig-system:motd-banner":""}
Что? Не поменялось?! И оно действительно не поменялось. Я не смог заставить это работать.
В общем знакомство с RESTCONF пока скорее травматично: документации исчезающие мало, большая часть ссылок - на космические корабли, бороздящие просторы неизученной Вселенной, примеры работы с RESTCONF все как один однообразны, а некоторые просто не работают. С той же аристой использование разных моделей - ietf, openconfig приводит к одному ответу в виде OpenConfig.
В конце концов отсутствие в выдаче хоть сколько-то серьёзных работ по автоматизации с помощью RESTCONF говорит о том, что это всё не более чем баловство. И я намеренно не пишу слово "пока". Лично я в него не верю
Хотя ощутимые удобства присутствуют - это использование чуть более привычного интерфейса и существующих библиотек. И с точки зрения разработчика несколько проще - он теперь имеет дело со знакомым с пелёнок WEB-сервисом.
При этом CRUD не очень гладко ложится на RPC-подход, да и в идее держать открытым на сетевом железе HTTP есть что-то противоестественное, согласитесь?
Просто жаль сил, вложенных в этот протокол. Потому что на пятки ему наступает gRPC/gNMI.
На самостоятельное изучение: RESTCONF intro with Postman - Part 1
Call-Home
Это, что называется, звонок домой - способ инициировать соединение с NETCONF/RESTCONF-сервера к клиенту, то есть с сетевой коробки на систему управления.
На устройстве настраивается IP-адрес NETCONF/RESTCONF-клиента, куда оно отсылает периодически данные по своему состоянию. Либо обращается для того, чтобы зарегистрироваться в системе и забрать свою конфигурацию.
Применимо для сценариев, когда
Новое устройство должно сообщить о себе в систему управления.
Устройство находится за NAT или фаерволом.
Администратор считает, что безопаснее иметь закрытые порты на сетевых элементах и открывать только well-known порт на системе управления.
Подробно тут останавливаться не будем.
gRPC/gNMI
За последние лет семь gRPC уже всем уши прожужжали. И только самые ловкие разработчики могли избежать реализации взаимодействия с какой-нибудь системой по gRPC.
g в gRPC, кстати, означает вовсе не "google".
Реализация фреймворка поверх gRPC в мире сетевой автоматизации получила название gNMI - gRPC Network Management Interface.
В основе gNMI лежит gRPC, для моделирования данных использует YANG (но не обязательно), внутри уже определяются конкретные RPC. Кроме того gNMI изначально предоставляет возможность естественным образом реализовать telemetry - потоковую передачу телеметрических данных.
В любом случае я не я, если перед gNMI я не разберу gRPC. Поэтому простите за отступление, но без него статья превратится в бесполезное поверхностное хауту.
gRPC
Без теории - за ней прошу в первую статью.
В любом случае после голой теории вот только такие ощущения:

Есть, правда, и более последовательная инструкция.
Хотя точно стоит сказать о том, что gRPC использует Protocol Buffers (или коротко protobuf). Термин этот довольно нагруженный -
это и спецификация, в которой описано, как данные должны выглядеть. Ещё это называется прото-спека.
это и IDL (Interface Definition Language), позволяющим разным системам друг с другом на одном языке общаться
это и формат сериализованных данных, в котором информация передаётся между системами
То есть всего лишь один proto-файл (или их набор), определяет сразу все эти три вещи.
То есть когда вы пишете gRPC-приложение, формирование protobuf - это важнейший шаг.
Пишем ping!
Спецификация
Описываем protobuf:
service Ping { rpc SendPingReply (PingRequest) returns (PingReply) {} }
Сначала определяем сервис - Ping. А в нём есть метод - SendPingReply - это собственно и есть RPC - та самая процедура, которую мы дёрнем удалённо - процедура отправить Ping Reply.
В качестве атрибута она принимает параметр PingRequest, а вернёт ответ PingReply.
А что такое эти PingRequest и PingReply?
message PingRequest { string payload = 1; }
PingRequest - это одно из пересылаемых сообщений между клиентом и сервером.
Так объявляется факт его существования, и его содержимое. В этом случае внутри сообщения передаётся одно поле payload типа string.
payload - это произвольное имя, которое мы можем выбрать, как хотим.
string - определение типа.
1 - позиция поля в сообщении - для нас не имеет значения.
message PingReply { string message = 1; }
Всё точно то же самое. Именем поля может быть даже слово message.
Вот так будет выглядеть полный proto-файл:
syntax = "proto3"; option go_package = "go-server/ping"; package ping; // The ping service definition. service Ping { // Sends a ping reply rpc SendPingReply (PingRequest) returns (PingReply) {} } // The request message containing the ping payload. message PingRequest { string payload = 1; } // The response message containing the ping replay message PingReply { string message = 1; }
То есть именно вот так и выглядит спецификация, описывающая схему данных на обеих сторонах. И сервер и клиент будут использовать один и тот же proto-файл и всегда знать, как разобрать то, что отправила другая сторона. Даже если они написаны на разных языках.
Сохраняем как protos/ping.proto - он будет один для всех.
Ну ладно спецификация есть. И что с ней теперь делать?
А теперь мы напишем пинг-клиент на Python, а пинг-сервер на Go.
gRPC Client
Сгенерированный Код
Создадим директорию python-client. Далее на основе спецификации сгенерируем код. Для этого нужно будет установить grpcio-tools.
pip install grpcio-tools
И используя его уже нагенерить нужные классы:
python3 -m grpc_tools.protoc \ -I protos \ --python_out=python-client \ --grpc_python_out=python-client \ protos/ping.proto
Сразу после этого в каталоге, где мы это выполнили, появятся два файла: ping_pb2.py и ping_pb2_grpc.py - это сгенерированный код.
Если вы зяглянете вовнутрь, то обнаружите там кучу классов. Это классы, реализующие сообщения, сервисы для сервера (PingServicer) и для клиента (PingStub). Там же у класса Ping есть и метод SendPingReply. И куча других штуковин.
Эти файлы нам никогда не придётся менять вручную - мы будем их только импортировать и использовать.
Очевидно, что эти py-файлы это только реализация интерфейса взаимодействия. Ровным счётом ничего тут не говорит, как этот сервис будет работать.
Бизнес-логика описывается уже отдельно - и вот она делается нами.
Пока структура выглядит так:
. ├── ping_client.py ├── ping_pb2.py └── ping_pb2_grpc.py
Давайте писать gRPC-клиент.
Клиент будет совсем бесхитростным. В цикле он будет пытаться выполнить RPC SendPingReply на удалённом хосте 84.201.157.17:12345. В качестве аргумента передаём payload, который считали из аргументов запуска скрипта.
В функции run мы устанавливаем соединение к серверу, подключаем stub и выполняем RPC SendPingReply, которому передаём сообщение PingRequest с тем самым payload.
import sys import time from datetime import datetime import grpc import ping_pb2 import ping_pb2_grpc server = "84.201.157.17:12345" def run(payload) -> None: with grpc.insecure_channel(server) as channel: stub = ping_pb2_grpc.PingStub(channel) start_time = datetime.now() response = stub.SendPingReply(ping_pb2.PingRequest(payload=payload)) rtt = round((datetime.now() - start_time).total_seconds()*1000, 2) print(f"Ping response received: {response.message} time={rtt}ms") if __name__ == "__main__": payload = sys.argv[1] while True: run(payload) time.sleep(1)
Если запустить его сейчас, клиент вернёт StatusCode.UNAVAILABLE - сервера пока нет, порт 12345 никто не слушает.
Давайте теперь писать
gRPC-сервер
на Go. Я его развернул на облачной виртуалочке, поэтому какое-то время он будет доступен и читателям.
Всё, что делает сервер - получает какую-то строку в payload, добавляет к нему "-pong" и возвращает это клиенту.
Сгенерированный Код. Тут нам тоже понадобится дополнительный код, реализующий интерфейс. Создаём рабочую директорию go-server, внутри которой ещё ping - для хранения спецификации и кода интерфейса.
protoc --go_out=. --go-grpc_out=. protos/ping.proto
И получается так:
. ├── go.mod ├── go.sum └── ping ├── ping_grpc.pb.go ├── ping.pb.go └── ping.proto
Дальше сам код сервера. Я его тоже взял из примеров для go.
Мы тут опускаем часть про установку go, protoc, потому что это всё есть в документации grpc.io.
package main import ( "context" "flag" "fmt" "log" "net" "google.golang.org/grpc" pb "ping-server/ping" ) var ( port = flag.Int("port", 12345, "The server port") ) type server struct { pb.UnimplementedPingServer } func (s *server) SendPingReply(ctx context.Context, in *pb.PingRequest) (*pb.PingReply, error) { log.Printf("Received: %v", in.GetPayload()) return &pb.PingReply{Message: in.GetPayload() + "-pong"}, nil } func main() { flag.Parse() lis, err := net.Listen("tcp", fmt.Sprintf("10.128.0.6:%d", *port)) if err != nil { log.Fatalf("failed to listen: %v", err) } s := grpc.NewServer() pb.RegisterPingServer(s, &server{}) log.Printf("server listening at %v", lis.Addr()) if err := s.Serve(lis); err != nil { log.Fatalf("failed to serve: %v", err) } }
Вся бизнес логика описана в функции SendPingReply, ожидающей PingRequest, а возвращающей PingReply, в котором мы отправляем сообщение message: payload + "-pong" (GetPayload). Естественно, там может быть более изощрённая логика.
Ну, а в main мы запускаем сервер на адресе 10.128.0.6.
Почему не на 84.201.157.17, на который стучится клиент? Тут без хитростей - это внутренний адрес ВМ, на который натируются все запросы к публичному адресу.
Я положу его в
. └── ping-server └── main.go
$ go run ping-server/main.go 2022/01/30 04:26:11 server listening at 10.128.0.6:12345
Всё, сервер готов слушать.
Пример сервера на питоне, если хочется попробовать.
Используем сразу asyncio, это же сервер, нельзя тут блочиться.
Для того, чтобы запустить сервер, нужно доставить пакет grpcio.
python -m pip install grpcio
Запускаем?
❯ python ping_client.py piu Ping response received: piu-pong time=208.13ms Ping response received: piu-pong time=165.62ms Ping response received: piu-pong time=162.89ms
У-хууу, ё-моё, grpc-заработал!!!!
А давайте теперь попробуем подампать трафик? Я запустил сервер удалённо и снял трафик.

По умолчанию, Wireshark не декодирует HTTP2, давайте научим его?
Analyze -> Decode As.
Вот тут уже видно почти все наши объекты, которые передаются между клиентом и сервером.
Кайф!!
Давайте ещё раз проговорим, что мы сделали.
Описали спецификацию сервиса - какие методы доступны, какими сообщениями с какими полями они обмениваются.
Сгенерировали из этой спецификации код как для сервера на Go, так и для клиента на Python.
Написали логику сервера и клиента
Клиент сделал вызов удалённого метода на сервере. Список доступных методов мы знаем из proto-файла.
Сервер вернул результат работы процедуры клиенту.
Итак, разобрались с gRPC. Ну, будем так считать, по крайней мере.
Внутри гугла gRPC удалось адаптировать даже к задачам сети. То есть gRPC стал единым интерфейсом взаимодействия между разными компонентами во всей компании (или одним из - мы не знаем).
gNMI
gNMI довольно новый протокол. Про него нет страницы на вики, довольно мало материалов и мало кто рассказывает о том, как его использует в своём проде.
Он не является стандартом согласно любым организациям и RFC, но его спецификация описана на гитхабе.
Что нам важно знать о нём для начала? gRPC Network Management Interface. Это протокол управления сетевыми устройствами, использующий gRPC как фреймворк: транспорт, режимы взаимодействия (унарный и все виды стриминга), механизмы маршаллинга данных, прото-файлы для описания спецификаций.
В качестве модели данных он может использовать YANG (а может и не использовать - в протобафы можно же засунуть всё, что угодно).
Как того требует gRPC, на сетевом устройстве запускается сервер, на системе управления - клиент. На обеих сторонах должна быть одна спецификация, одна модель данных.
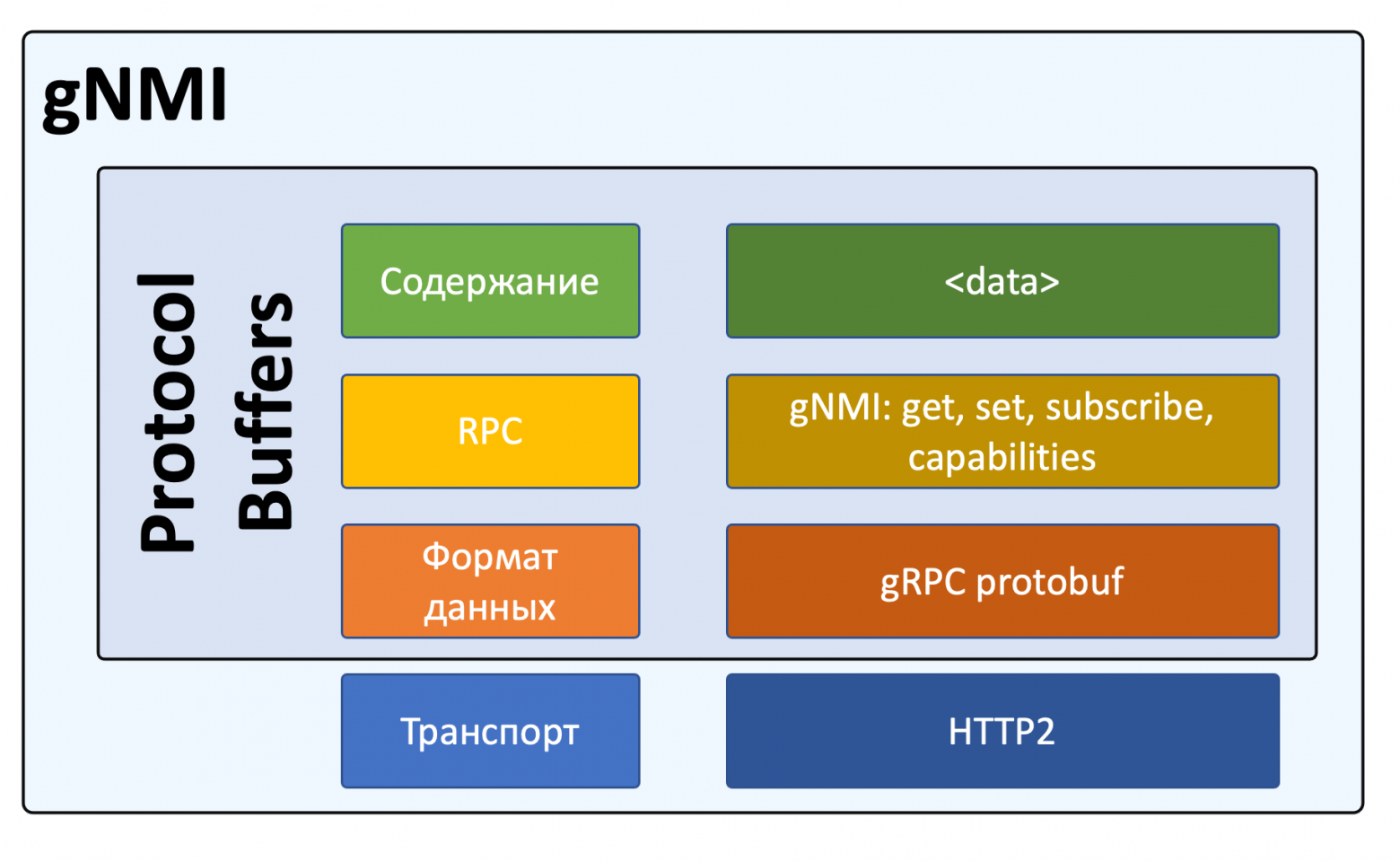
Поскольку это конструкт над gRPC, в нём определены конкретные сервисы и RPC:
servicegNMI{ rpcCapabilities(CapabilityRequest) returns(CapabilityResponse); rpcGet(GetRequest) returns(GetResponse); rpcSet(SetRequest) returns(SetResponse); rpcSubscribe(streamSubscribeRequest) returns(streamSubscribeResponse); }
Более наглядное представление полного прото-файла можно увидеть на интерактивной карте, которую нарисовал Роман Додин:
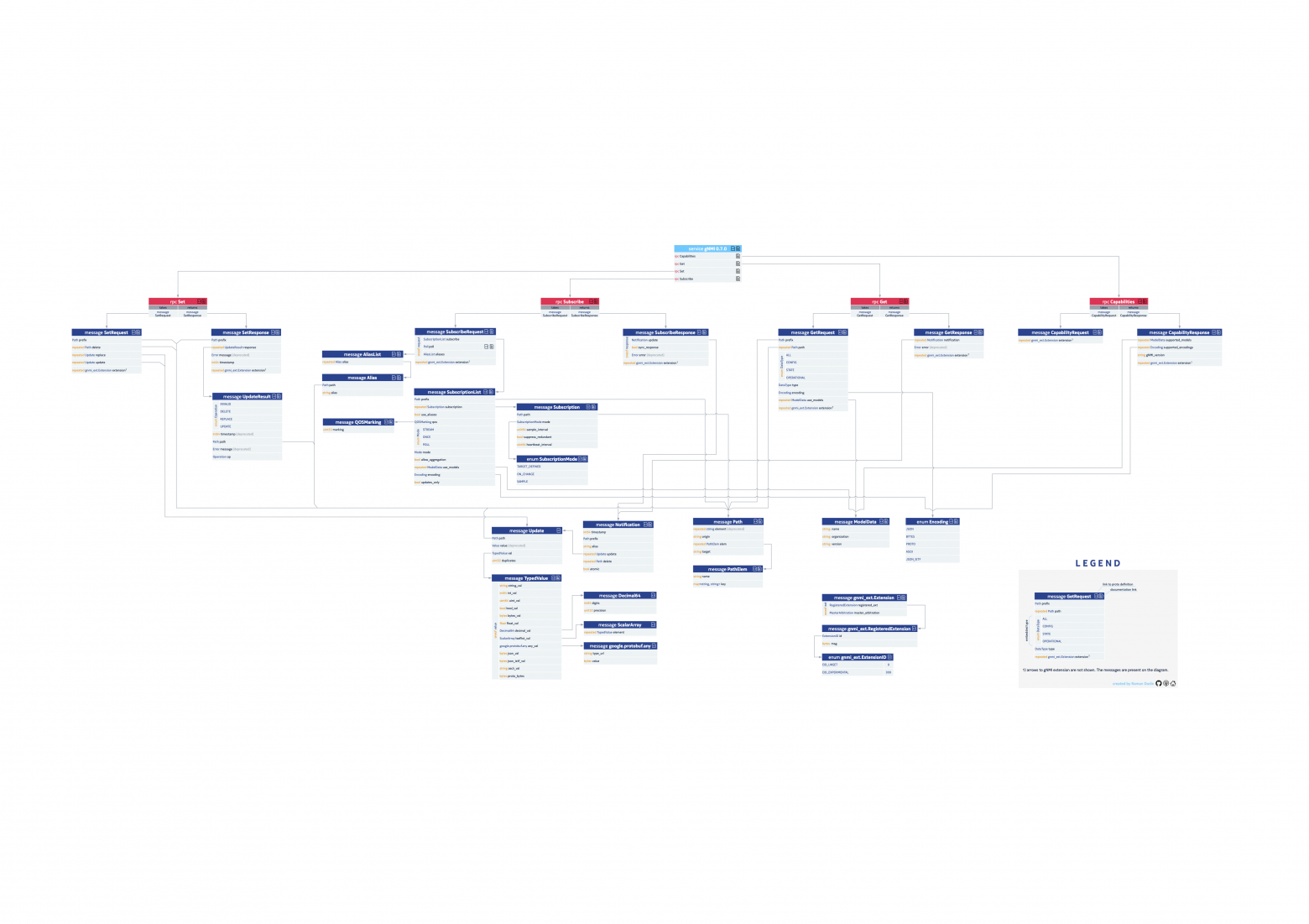
Здесь каждый RPC расписан на сообщения и типы данных, и указаны ссылки на прото-спеки и документацию.
Не могу сказать, что это удобное место для того, чтобы начать знакомиться с gNMI, но вы точно к нему ещё много раз вернётесь, если сядете на gNMI.
Предлагаю попробовать на практике вместо теорий.
Вообще gNMI, как плоть от плоти gRPC не очень удобен для использования человеком. Прото-файлы пиши, код пиши, исполняй. Нельзя как в REST API просто curl отправить и получить текстовый ответ - это вообще известная боль.
Но для gNMI напридумывали клиентов.
И тут google в лучших традициях делает прекрасные инфраструктурные вещи и ужасный пользовательский интерфейс. gNXI, OpenConfig gNMI CLI client.
gNMIc
Нас и тут спасает Роман Додин, поучаствоваший в создании классного клиента gNMI, совместно с Karim Radhouani - gNMIc.
Устанавливаем по инструкции:
bash -c "$(curl -sL https://get-gnmic.kmrd.dev)"
Теперь надо настроить узел.
interface Management1 ip address 192.168.1.11/24 username eucariot secret <SUPPASECRET> management api gnmi transport grpc default ip access-list control-plane-acl-with-restconf-and-gnmi 8 permit tcp any any eq 6030 … control-plane ip access-group control-plane-acl-with-restconf-and-gnmi in
Попробуем выяснить capabilities:
gnmic capabilities \ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
А в ответ пара экранов текста, полного возможностей:
gNMI version: 0.6.0 supported models: - arista-exp-eos-multicast, Arista Networks <http://arista.com/>, - arista-exp-eos, Arista Networks <http://arista.com/>, - openconfig-if-ip, OpenConfig working group, 2.3.0 … supported encodings: - JSON - JSON_IETF - ASCII
Тут видно, что устройство поддерживает три вида кодирования. Нам интересен JSON.
А так же, несколько десятков моделей данных, как OpenConfig, так и IETF и проприетарные.
Дальше нет времени объяснять, откуда я это взял, просто пробуем собрать IP-адреса всех интерфейсов:
gnmic get \ --path "/interfaces/interface/subinterfaces/subinterface/ipv4/addresses/address/config" -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "interfaces/interface[name=Management1]/subinterfaces/subinterface[index=0]/ipv4/addresses/address[ip=192.168.1.11]/config", "values": { "interfaces/interface/subinterfaces/subinterface/ipv4/addresses/address/config": { "openconfig-if-ip:ip": "192.168.1.11", "openconfig-if-ip:prefix-length": 24 } } }, { "Path": "interfaces/interface[name=Ethernet3]/subinterfaces/subinterface[index=0]/ipv4/addresses/address[ip=169.254.101.1]/config", "values": { "interfaces/interface/subinterfaces/subinterface/ipv4/addresses/address/config": { "openconfig-if-ip:ip": "169.254.101.1", "openconfig-if-ip:prefix-length": 31 } } }, { "Path": "interfaces/interface[name=Ethernet2]/subinterfaces/subinterface[index=0]/ipv4/addresses/address[ip=169.254.1.3]/config", "values": { "interfaces/interface/subinterfaces/subinterface/ipv4/addresses/address/config": { "openconfig-if-ip:ip": "169.254.1.3", "openconfig-if-ip:prefix-length": 31 } } } ] } ]
Из ответа видно полный путь к каждому интерфейсу, запрошенный путь и результат в модели OpenConfig.
Один ультра-полезный аргумент в gNMIc, это --path "/" - он вернёт просто всё, что может.
Полезен он тем, что можно из вывода пореверсинжинирить где что искать.
gnmic get --path "/" -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
Ответа будет много.
И оттуда можно понять, что посмотреть конфигурацию BGP-пиров можно, используя путь "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config":
gnmic get \ --path "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config" -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "network-instances/network-instance[name=default]/protocols/protocol[identifier=BGP][name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config", "values": { "network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config": { "openconfig-network-instance:auth-password": "", "openconfig-network-instance:description": "", "openconfig-network-instance:enabled": true, "openconfig-network-instance:local-as": 0, "openconfig-network-instance:neighbor-address": "169.254.1.2", "openconfig-network-instance:peer-as": 4228186112, "openconfig-network-instance:peer-group": "LEAFS", "openconfig-network-instance:route-flap-damping": false, "openconfig-network-instance:send-community": "NONE" } } }, { "Path": "network-instances/network-instance[name=default]/protocols/protocol[identifier=BGP][name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.101.0]/config", "values": { "network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config": { "openconfig-network-instance:auth-password": "", "openconfig-network-instance:description": "", "openconfig-network-instance:enabled": true, "openconfig-network-instance:local-as": 0, "openconfig-network-instance:neighbor-address": "169.254.101.0", "openconfig-network-instance:peer-as": 0, "openconfig-network-instance:peer-group": "EDGES", "openconfig-network-instance:route-flap-damping": false, "openconfig-network-instance:send-community": "NONE" } } } ] } ]
А такой, чтобы проверить состояние пира: "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/state/session-state"
gnmic get \ --path "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/state/session-state" -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "network-instances/network-instance[name=default]/protocols/protocol[identifier=BGP][name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/state/session-state", "values": { "network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/state/session-state": "ACTIVE" } }, { "Path": "network-instances/network-instance[name=default]/protocols/protocol[identifier=BGP][name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.101.0]/state/session-state", "values": { "network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/state/session-state": "ACTIVE" } } ] } ]
И получается, вполне очевидное деление на конфигурационные и операционные данные.
Вот данные по конфигурации ветки system:
gnmic get \ --path "/system/config" \ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "system/config", "values": { "system/config": { "openconfig-system:hostname": "bcn-spine-1", "openconfig-system:login-banner": "", "openconfig-system:motd-banner": "" } } } ] } ]
А вот по состоянию:
gnmic get \ --path "/system/state" \ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "system/state", "values": { "system/state": { "openconfig-system:boot-time": "164480684820", "openconfig-system:current-datetime": "2022-02-19T13:24:54Z+00:00", "openconfig-system:hostname": "bcn-spine-1", "openconfig-system:login-banner": "", "openconfig-system:motd-banner": "" } } } ] } ]
Ну, и последний практический пример в этой секции: настроим чего полезного на железке, Set RPC.
Сначала посмотрим значение AS у одного из BGP-пиров:
gnmic get \ --path "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config/peer-as"\ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p passowrd \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "network-instances/network-instance[name=default]/protocols/protocol[identifier=BGP][name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config/peer-as", "values": { "network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config/peer-as": 4228186112 } } ] } ]
Теперь поменяем значение:
gnmic set \ --update-path "/network-instances/network-instance[name=default]/protocols/protocol[name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config/peer-as" \ --update-value "4228186113" \ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p passowrd \ --insecure
{ "source": "bcn-spine-1.arista:6030", "timestamp": 1645281264572566754, "time": "2022-02-19T06:34:24.572566754-08:00", "results": [ { "operation": "UPDATE", "path": "network-instances/network-instance[name=default]/protocols/protocol[name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config/peer-as" } ] }
Проверяем ещё раз:
gnmic get \ --path "/network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config/peer-as"\ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
[ { "source": "bcn-spine-1.arista:6030", "time": "1969-12-31T16:00:00-08:00", "updates": [ { "Path": "network-instances/network-instance[name=default]/protocols/protocol[identifier=BGP][name=BGP]/bgp/neighbors/neighbor[neighbor-address=169.254.1.2]/config/peer-as", "values": { "network-instances/network-instance/protocols/protocol/bgp/neighbors/neighbor/config/peer-as": 4228186113 } } ] } ]
Уиии!
Я чуть не вскочил с места, когда получилось.
А ещё у gNMIc есть автокомплишн.
Ну нам бы сейчас полезно было бы посмотреть на примеры работы с кодом?
Но вместо того, чтобы всё делать руками, воспользуемся готовым инструментом.
Сам gNMIc может быть импортирован как зависимость в Go-программу, поскольку имеет зрелую подсистему API.
pyGNMI
Эта библиотека написана Антоном Карнелюком (и снова русский след). Заметно удобнее всего остального и активно развивается.
Да на неё даже ссылается Arista из своей Open Management.
Соберём capabilities:
#!/usr/bin/env python from pygnmi.client import gNMIclient import json host = ("bcn-spine-1.arista", 6030) if __name__ == "__main__": with gNMIclient(target=host, username="eucariot", password="password", insecure=True) as gc: result = gc.capabilities() print(json.dumps(result))
По-get-аем что-нибудь:
#!/usr/bin/env python from pygnmi.client import gNMIclient import json host = ("bcn-spine-1.arista", 6030) if __name__ == "__main__": paths = ["openconfig-interfaces:interfaces/interface/subinterfaces/subinterface/ipv4/addresses/address/config"] with gNMIclient(target=host, username="eucariot", password="password", insecure=True) as gc: result = gc.get(path=paths, encoding='json') print(json.dumps(result))
Ну и осталось теперь что-то поменять, например, тот же hostname:
#!/usr/bin/env python from pygnmi.client import gNMIclient import json host = ("bcn-spine-1.arista", 6030) set_config = [ ( "openconfig-system:system", { "config": { "hostname": "bcn-spine-1.barista-karatista" } } ) ] if __name__ == "__main__": with gNMIclient(target=host, username="eucariot", password="fpassword", insecure=True) as gc: result = gc.set(update=set_config) print(json.dumps(result))
poetry run python gc_set.py | jq { "timestamp": 1645326686451002000, "prefix": null, "response": [ { "path": "system", "op": "UPDATE" } ] }
В репе ADSM можно найти пример по изменению BGP peer-as.
gNMIc и pyGNMI - это всего лишь частные инструменты для работы через gNMI. Ничто не мешает вам самим реализовать набор методов удобным образом.
Важно здесь заметить то, что у gNMI нет концепции Data Stores и как следствие функционала коммитов конфигурации - мы работаем с сервисом.
gNMI заставляет нас вывернуть привычный взгляд на сеть иголками внутрь. Мы к ней теперь должны относиться как к ещё одному сервису, которым можно легко управлять через единообразный интерфейс. Сам же gNMI обеспечивает транзакционность всех изменений, передаваемых в одном RPC.
Представьте себе, что вы пишите в базу данных и нужно потом сделать ещё коммит, чтобы эти изменения сохранить - звучит нелогично. Вот так и с сетью - транзакционность есть, коммитов - нет.
Для инфраструктурной команды сеть - это больше не какой-то свой собственный особенный мир, находящийся где-то там за высокой стеной CLI, окружённый рвами, заполненными проприетарным синтаксисом.
Нам следует разделить сетевое устройство, к которому мы всю жизнь относились как к чему-то в целостному, потому что покупаем сразу всё это в сборе, на следующие части:
железный хост - коммутаторы и маршрутизаторы, со всеми их медными и оптическими проводочками, куском кремния под вентилятором и трансиверами,
операционная система - софт, который управляет жизнью железа и запускаемыми приложениями,
приложения, реализующие те или иные сервисы или доступ к ним - аутентификация, интерфейсы, BGP, VLAN'ы, или gNMI, дающий доступ к ним ко всем.
Да, влияние проблем на сетевом устройстве имеет больший охват. Да, можно оторвать себе доступ одним неверным движением. Да, поддержка целевого состояния на все 100% - всё ещё сложная задача.
Но чем, в конце концов это отличается от обычного Linux'а, на котором крутится сервис?
То есть сервисный интерфейс (gNMI, gRPC, REST, NETCONF) следует рассматривать как способ управления собственно сервисами, в то время как для обслуживания хоста никуда не девается SSH+CLI - для отладки, обновления, управления приложениями. Впрочем и тут есть Ansible, Salt. Вот только идеально для этого, чтобы сетевая железка стала по-настоящему открытой - с Linux'ом на борту.
Кроме того есть
gNOI
gRPC Network Operations Interface от OpenConfig - набор микросервисов, основанных на gRPC, позволяющих выполнять операционные команды на хостах. Если проще, то можно запустить ping, traceroute, почистить разные таблицы, сделать Route Refresh BGP-соседу, скопировать файл - всё то, что относится не к конфигурации, а скорее к отладке и эксплуатации.
На самом деле там на сегодняшний день уже достаточно внушительный список операций.
А ещё по аналогии с gNMIc существует и gNOIc.
Обратили, кстати, внимание, что здесь в вызовах не было ничего специфичного для Аристы?
На самом деле некая неявная привязка есть - это пути, они могли бы отличаться для Аристы и Хуавэя. Но внимание на слово "openconfig" в этих путях. Что это? Что за Открытый конфиг?
Сложность с автоматизацией сети - она ведь в чём? В том, что прежде чем отправлять конфигурацию на устройство, человек должен сесть и прям-таки разобраться в структуре CLI или XML и руками накидать шаблоны для конфигурации.
Даже просто для того, чтобы настроить IP-адрес на интерфейсе, нужно знать иерархию секций конфигурации или конкретное поддерево XML.
А ещё выяснить, в каком формате надо передавать адрес: fe80::1/64, fe80::1 64, fe80::1 link-local, address: fe80::1, mask: 64, FE8:0:0:0:0:0:0:1, 0000111111101000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000000 0000000000000001 или там вообще не поддерживается IPv6. И надо ли сначала как-то энейблить IPv6, а MTU заимствуется с интерфейса или для IPv6 отдельный?
И так для каждого вендора по отдельности. Знаете, сетевых автоматизаторов спасает только то, что они до этого лет 10 ели на завтрак циски да джуниперы - и как свои два пальца знают все тонкости CLI.
Оно же их и губит.
NETCONF поел овса из-за того, что не предложил никакой стандартизации для моделирования данных. Именно поэтому вендоры успели наплодить своих собственных, несовместимых моделей, про которые мы и поговорим ниже.
Модели данных
Собственно то, в какой иерархии представлена конфигурация - и есть модель данных. Говорится об этом или нет, но такая модель есть всегда и у любого интерфейса. Она может быть плоской или иерархической, может быть простой или запутанной. Если бы её не было, то вы бы просто не смогли настроить устройство, а команды конфигурации могли бы видоизвиняться случайным образом. Говорят, в Router OS 7 подвезли такую функцию.
Так, мы знаем, что например, в случае Juniper нужно войти в контекст system->login, чтобы настроить нового пользователя, а формат команды будет set <USERNAME> <OTHER PARAMETERS>.
А настройка IP-адреса управления при этом будет происходить в контексте interface -> em0 -> unit 0 -> family inet. И так будет всегда. Во всяком случае на этой железке и этой версии софта.
То есть модель данных - это контракт между пользователем и операционной системой - как она интерпретирует переданные команды в зависимости от контекста.
Это верно для CLI, SNMP, NETCONF, gNMI и даже прямых вызовов чипового SDK.
Просто бОльшую часть истории нам не нужно было знать об этих моделях. Есть аксиома - у каждого вендора она своя. А мы в голове, сознательно или нет, её выстраивали, воссоздавали.
И вендор может менять эту модель по своему усмотрению от версии к версии. А мы как люди к этому адаптируем свою внутреннюю модель, приспосабливаемся - по законам эволюции.
Native
Так было всегда, но это поменялось с приходом автоматизации. Вендоры, как будто бы думали, что рост сетей можно поддерживать постоянным докидыванием людей на их настройку. Но людям это не нравилось, они начали писать инструменты автоматизации на perl'ах, php, python'ах с expect'ами, попытками отловить все возможные ответы CLI, правильно на них среагировать. Но количество скорби в этом мире только множилось. Все рано или поздно приходили к пониманию, что долго притворяться робот человеком не может.
Так и появились NETCONF и RESTCONF (так появлялся и SNMP). Они дали возможность работать со структурированными данными, а также создавать более явные контракты между клиентом и сервером.
Автор утилиты/библиотеки, опираясь на этот контракт, пишет код, а вендор обязуется принять данные, которые ему прислали. Если вы присылаете соответствующие контракту данные, а вендор говорит, что вы ерунду прислали, вы идёте в суд (в TAC).
Первые реализации NETCONF были настолько же закрытыми, как и сам CLI. У джуна - меньше, у циски - больше. У кого-то RPC перекладывались собственно в вызове CLI.
Но необходимость приводить это всё к каким-то явным схемам становилась всё очевиднее с каждым днём. К этому же подталкивал и расцвет NMS, берущих на вооружение NETCONF.
И так появились первые модели данных - NATIVE. У каждого вендора своя, но уже модель, и уже открытая.
Вендоры с достаточно высокой социальной ответственностью выкладывают свои модели в публичный репозиторий.
Наличие модели позволяет уже как минимум не рыскать в попытках вслепую нащупать, как составить XML, а пойти, посмотреть, в каком виде ожидает данные коробка.
А при желании модель читать программно и руками даже ничего не делать.
Вендор-нейтральные модели
С этим уже можно было жить.
Инженерам нужно было чуть меньше думать об интерфейсах и форматах сообщений, но с глубоким вниманием подходить к содержимому сообщений всё ещё приходилось, оказывая разные знаки почтения разным вендорам.
При этом казалось бы - вся сеть - это конечный набор одинаковых сервисов, если выбросить всякие IGRP, HSRP, RRPP и прочие проприетарные выдумки. Ну, всем же нужен IP, OSPF, BGP? Всем нужна аутентификация на устройствах и SSH? Они не могут иметь очень уж принципиальные отличия, как минимум из-за необходимости поддерживать совместимость друг с другом и соответствия RFC.
Так почему мы делаем это сотней разных способов?
Juniper | Nokia | Cisco | |
Настройка интерфейса |
|
|
|
Настройка BGP |
|
|
|
Сложность ведь не в транспорте и не в интерфейсе, а в модели данных. Сделать у каждого вендора Configuration State Management - одноразовая решаемая (а много где и решённая) задача. А вот договориться между всеми производителями, как должна выглядеть модель - так же сложно, как и любая другая задача, где людям нужно договориться.

Но ни один из зарождавшихся и выживших стандартов или не ставил целью унификацию вообще, или пытался поднять этот вопрос, но был выброшен в окно штаб-квартиры вендора.
Хотя вру. IETF предприняли отчасти успешную попытку написать универсальную модель.
IETF-модель
Ещё в 2014-м году были сделаны первые коммиты в её репозиторий.
С тех пор много накоммичено, но мало фактически сделано. Общепризнанно, что IETF -модель очень медленно развивается, у неё низкое покрытие, а архитектура - так себе.
С IETF-модели рекомендуют начинать, потому что она якобы проще, а уже потом переходить на OpenConfig, но как по мне - это напрасная трата времени. Она мертворождённая и никому особо не нужна. Хотя вендоры поддерживают. Заказчиков и пользователей беспокоила обрезанность модели и инертность IETF.
Но один в поле не воин - тысячи разрозненных автоматизаторов по всему миру не могли ничего с этим сделать. А вот большие компании могли. Когда надо настроить тысячу свитчей, а каждый месяц запускать новый датацентр, когда на сети 5 разных поколений дизайна, а катить изменения нужно дважды в день, начинаешь несколько иначе смотреть на все этим ваши сиэлаи и вендор-специфичные эксэмали.
Так гугл придумал OpenConfig. Он не стал размениваться на IETF-модели и торги со стариканами из института.
OpenConfig - мечта, становящаяся явью
Возможно, впервые за шестидесятилетнюю историю телекоммуникаций у нас появился шанс изобрести свой USB Type C. Представьте мир, в котором Cisco, Juniper, Arista и Mikrotik настраиваются одними и теми же командами и это к тому же приводит к одинаковому результату?
Я не могу.
OpenConfig - это открытая YANG-модель, которая предполагается единой для всех вендоров. Одна стандартизированная модель для управления конфигурацией, сбора операционных данных с устройства и телеметрии. Одна для всех поддерживающих OC вендоров.
Итак, OpenConfig появился в 2015 году в Google как ответ на следующие вызовы:
20+ ролей сетевых устройств;
Больше полудюжины вендоров;
Множество платформ;
4M строк в конфигурационных файлах;
30K изменений конфигураций в месяц;
Больше 8M OIDs опрашиваются каждые 5 минут;
Больше 20K CLI-команд выполняется каждые 5 минут;
Множество инструментов и поколений софта, куча скриптов;
Отсутствие абстракций и проприетарные CLI;
SNMP не был рассчитан на столь большое количество устройств и на столько большие объёмы данных (RIB).
Как работать с openconfig мы уже немного попрактиковались выше.
Полезным было бы взглянуть на структуру этой модели. Но это мы сделаем в следующей главе про YANG.
OpenConfig сегодня даёт возможность настройки базовых сервисов. Безусловно речь не идёт про вещи, завязанные на аппаратные особенности: QoS, управление буферами и ресурсами чипа, сплиты портов, работа с трансиверами. И в каком-то хоть сколько-то обозримом будущем этого ждать не стоит.
Хуже того, на сегодняшний день многие вендоры, ввязавшиеся в поддержку OC, не реализуют все 100%, а лишь часть.
Но BGP с OSPF настроить точно можно.
Что делать в этом случае?
И есть два пути.
Один из них - брать OC и видоизменять его с помощью добавления или убирания каких-либо его частей.
Когда вендор хочет расширить покрытие модели - он делает augmentation, встраивая его в нужное место.
Если он хочет поменять какое-то поведение или удалить функциональность - он описывает deviation к базовой модели.
Этот способ, конечно, не покрывает все потребности.Другой - использовать вендорские Native модели, покрытие которых намного больше.
Абсолютно нормально совмещать OC и Native - главное, не настраивать одно и то же с помощью разных моделей.В целом рекомендуют (даже сами вендоры), использовать OC там, где это возможно, а где нет - прибегать к native.
")
Google привёл в наш мир OpenConfig в одной руке, а gNMI - в другой.
Но в качестве транспорта для OC может быть как gNMI, так и NETCONF и RESTCONF - это не принципиально. В то же время, для gNMI OpenConfig в частности и YANG вообще не единственные возможные модели и языки.
Так что же это за мифический
YANG
Оооо, как долго я шёл к этому, как долго я ждал, чтобы разобраться с этой темой.
Такой манящий и такой недоступный - YANG - Yet Another Next Generation, который решит все мои дилеммы автоматизатора, который снимет с меня груз парсинга CLI и приведёт нас всех в новый дивный мир.
Почему-то казалось, что стоит только понять, что такое YANG - и дальше самой сложной задачей останется оттраблшутить Ансибль и высадиться на Марсе.
YANG, а точнее модели, написанные на нём, не стали серебряной пулей, как не стали ей (пока) NETCONF, OpenConfig, gNMI.

И вообще YANG - вещь весьма академическая. Это просто язык описания моделей. Модели у каждого производителя и под каждую задачу могут быть совершенно разными, но, учитывая, что они все написаны на одном языке, мы можем применять одни и те же подходы и инструменты для работы с ними, и не отращивать ещё новые нейронные связи.
Вообще-то модели может не быть вовсе, или она может быть описана по-английски или по-русски, вместо YANG. Но при этом в JunOS/VRP/IOS по-прежнему будет какая-то структура данных. Просто в этом случае у вас не будет контракта, и в суд вы обратиться не сможете.
Это собственно то, как мы и жили прежде.
Вообще-то YANG пришёл на помощь NETCONF'у, когда стало понятно, что достаточно разврата - откапывайте SNMP SMI без моделей дальше никуда ни шагу - и уже достаточно ошибок было совершено.
YANG - достойный сын SMIng. Когда парни из Network Working Group поняли, что с SNMP у них как-то не выгорело, весь накопленный багаж знаний они пустили на пользу обществу.
В общем-то, не мудрствуя лукаво, ребята из IETF взяли синтаксическую структуру и базовые типы из SMIng и запилили YANG.
При разработке YANG решили не совершать ошибок SMIng, который должен был стать универсальным языком под общие задачи, отчего немало страдал - нет, YANG нацеливался исключительно на NETCONF.
И какова ирония: RESTCONF и gNMI тоже решили использовать YANG - как язык моделирования. Ну логично ведь - не выдумывать 13-й стандарт же (хотя, подождите)?
Но гугл пошёл ещё дальше - gNMI может работать как с YANG-моделями, так и нет. Свободу вариативности! Что, впрочем, вполне логично, ведь в основе gNMI - protobuf'ы gRPC. А они могут как быть созданы на основе YANG-модели, так и просто придуманы из головы, или модель может быть написана не на YANG.
Как видно, благими намерениями уже тогда - был устлан путь к хьюман-ридабл, мэшин-парсибл.
Давайте мы не будем закапываться в сам язык - пожалуй, это нужно не очень большому числу людей. Нам интереснее практическая сторона - конкретные модели, как в них найти глазами нужные вещи, как с ними работать программно, какая вообще от них польза.
Дальше в качестве практики возьмём модель OpenConfig.
Препарируем YANG-модель
Давайте ещё раз вспомним пример, как мы собирали данные по конфигурации интерфейсов.
gnmic get \ --path "/interfaces/interface/subinterfaces/subinterface/ipv4/addresses/address/config" \ -a bcn-spine-1.arista:6030 \ -u eucariot \ -p password \ --insecure
Откуда взялся этот замысловатый путь?
Для этого нам понадобится взглянуть на открытый репозиторий OpenConfig.
Пристально смотрим…
Ещё немного…
Понятно?
И мне не очень. Чтобы такое читать, надо всё же разбираться с самим языком.
Нам лень.
Поэтому воспользуемся помощью библиотеки pyang.
Pyang
Продолжим с примером про интерфейсы.
sudo pip install pyang
В рабочий каталог склоним репу:
git clone https://github.com/openconfig/public
И дадим вот такую команду:
pyang -f tree -p yang/oc/public/release/models/ yang/oc/public/release/models/interfaces/openconfig-interfaces.yang
И дальше вываливается много текста:
module: openconfig-interfaces +--rw interfaces +--rw interface* [name] +--rw name -> ../config/name +--rw config | +--rw name? string | +--rw type identityref | +--rw mtu? uint16 | +--rw loopback-mode? boolean | +--rw description? string | +--rw enabled? boolean +--ro state | +--ro name? string | +--ro type identityref | +--ro mtu? uint16 | +--ro loopback-mode? boolean | +--ro description? string | +--ro enabled? boolean | +--ro ifindex? uint32 | +--ro admin-status enumeration | +--ro oper-status enumeration | +--ro last-change? oc-types:timeticks64 | +--ro logical? boolean | +--ro management? boolean | +--ro cpu? boolean | +--ro counters | +--ro in-octets? oc-yang:counter64 | +--ro in-pkts? oc-yang:counter64 | +--ro in-unicast-pkts? oc-yang:counter64 | +--ro in-broadcast-pkts? oc-yang:counter64 | +--ro in-multicast-pkts? oc-yang:counter64 | +--ro in-discards? oc-yang:counter64 | +--ro in-errors? oc-yang:counter64 | +--ro in-unknown-protos? oc-yang:counter64 | +--ro in-fcs-errors? oc-yang:counter64 | +--ro out-octets? oc-yang:counter64 | +--ro out-pkts? oc-yang:counter64 | +--ro out-unicast-pkts? oc-yang:counter64 | +--ro out-broadcast-pkts? oc-yang:counter64 | +--ro out-multicast-pkts? oc-yang:counter64 | +--ro out-discards? oc-yang:counter64 | +--ro out-errors? oc-yang:counter64 | +--ro carrier-transitions? oc-yang:counter64 | +--ro last-clear? oc-types:timeticks64 +--rw hold-time | +--rw config | | +--rw up? uint32 | | +--rw down? uint32 | +--ro state | +--ro up? uint32 | +--ro down? uint32 +--rw subinterfaces +--rw subinterface* [index] +--rw index -> ../config/index +--rw config | +--rw index? uint32 | +--rw description? string | +--rw enabled? boolean +--ro state +--ro index? uint32 +--ro description? string +--ro enabled? boolean +--ro name? string +--ro ifindex? uint32 +--ro admin-status enumeration +--ro oper-status enumeration +--ro last-change? oc-types:timeticks64 +--ro logical? boolean +--ro management? boolean +--ro cpu? boolean +--ro counters +--ro in-octets? oc-yang:counter64 +--ro in-pkts? oc-yang:counter64 +--ro in-unicast-pkts? oc-yang:counter64 +--ro in-broadcast-pkts? oc-yang:counter64 +--ro in-multicast-pkts? oc-yang:counter64 +--ro in-discards? oc-yang:counter64 +--ro in-errors? oc-yang:counter64 +--ro in-unknown-protos? oc-yang:counter64 +--ro in-fcs-errors? oc-yang:counter64 +--ro out-octets? oc-yang:counter64 +--ro out-pkts? oc-yang:counter64 +--ro out-unicast-pkts? oc-yang:counter64 +--ro out-broadcast-pkts? oc-yang:counter64 +--ro out-multicast-pkts? oc-yang:counter64 +--ro out-discards? oc-yang:counter64 +--ro out-errors? oc-yang:counter64 +--ro carrier-transitions? oc-yang:counter64 +--ro last-clear? oc-types:timeticks64
Неплохо. С такими аргументами pyang представляет модель в виде дерева, выбрасывая несущественные данные.
Здесь сразу видно, на каком уровне иерархии что находится, какой у него тип и режим - rw или ro.
Постойте, но где же ipv4, который в запросе gnmic? Тут его явно нет. А в запросе и ответе явно был - то есть где-то он должен существовать и в модели.
Взглянем ещё раз на директорию. И повторим pyang:
poetry run pyang -f tree -p yang/oc/public/release/models/ yang/oc/public/release/models/interfaces/openconfig-if-ip.yang | head -n 10 module: openconfig-if-ip augment /oc-if:interfaces/oc-if:interface/oc-if:subinterfaces/oc-if:subinterface: +--rw ipv4 +--rw addresses | +--rw address* [ip] | +--rw ip -> ../config/ip | +--rw config | | +--rw ip? oc-inet:ipv4-address | | +--rw prefix-length? uint8
Вот и он во всей красе. И тут видно, что это аугментация к модели /oc-if:interfaces/oc-if:interface/oc-if:subinterfaces/oc-if:subinterface.
А что такое oc-if?
less yang/oc/public/release/models/interfaces/openconfig-interfaces.yang | grep '^ *prefix' prefix "oc-if";
Итак, у модели есть короткий префикс для более удобного обращения к ней. Он используется в другой модели, чтобы сделать его аугментацию.
Так можно просто проверить корректность:
poetry run pyang -p yang/oc/public/release/models/ yang/oc/public/release/models/interfaces/openconfig-interfaces.yang
Ключ -f позволяет конвертировать в разные форматы: tree, yin, yang, jstree, uml и другие.
Для нас интереснее всего tree и uml, потому что вот такие крутые картинки можно рисовать для визуалов

С помощью pyang, конечно, можно работать не только с моделями OpenConfig, но и с любыми другими, написанными на языке YANG.
Место, где неплохо описан pyang.
А тут бравые парни из Австралии пишут свою модель. С этой работой будет полезно ознакомиться тем, кто хочет разобраться поглубже в языке YANG.
На сегодняшний день многие вендоры поддерживают YANG-схему для своих NETCONF/gNMI-интерфейсов.
Есть несколько мест, где их можно раздобыть:
Тут есть ссылки на гитхабы вендоров, которые публикуют свои модели.
Но Huawei, например, хранит свои YANG-и в нескольких местах.
Отдельно так же лежат схемы аристы.
Некоторые вендоры могут хранить их на своих сайтах.
В общем, собираем с репы по коммиту.
Замечательная новость в том, что все коробки, заявляющие своё соответствие RFC6022 должны уметь возвращать всю YANG-схему по запросу с операцией <get_schema>.
Отвратительная новость в том, что не все вендоры эту операцию поддерживают.
Что нужно знать про YANG?
Это способ описать структуру данных, но не сами данные.
Сами данные могут быть представлены в любом формате, поддерживающем структуры: XML, JSON, Protobuf, объекты Python.
YANG придумывали не для того, чтобы решить общую задачу, он нацелен на конкретно NETCONF и конкретно XML-кодирование. Но его смогли присобачить и к другим интерфейсам.
Я бы взял на себя смелость сказать, что NETCONF/YANG - это как TCP/IP. То есть там и про NETCONF, и про YANG. Однако не только NETCONF.
Очевидно, YANG - огромная тема, которой будет тесно даже на страницах отдельной книги. В этой статье мне хотелось только приоткрыть первый её разворот, на котором ещё нет пугающих выкладок.
Возможно, когда-то, если я осознаю неизбежность его повсеместного проявления, я напишу отдельную огромную статью и о нём. А пока положим достаточным эти едва ли заметные тропинки.
Model Driven Programmability
Так что же это такое? Ведомая моделью программируемость? Теперь, после двух статей, нам хватит пары минут, чтобы разобраться что это такое.
Давайте вернёмся к 4-й части АДСМ, где я использовал позаимствованную у Дмитрия Тесля картинку.

Она ведь очень понятная? Inventory, Git с шаблонами конфигурации, рендер, валидация, применение.
Где закопаны два мешка с человеко-неделями? Под шаблонами с генераторами и под системами применения конфигурации.
Со вторым пытаются бороться NETCONF, RESTCONF, gNMI.
А с первым - модели.
Проблема в том, что шаблоны мы составляем руками на основе изучения документации, интерфейса коробки и действуем методом проб и ошибок, вообще-то. Если нужна проверка типов, диапазонов, если меняется иерархия - будьте добры сами всё это написать и обработать. И, окончив, уехать в сумасшедший дом, учить друзей джинджа-программированию.
Model Driven меняет картину следующим образом:

Здесь шаблоны конфигурации заменяются на YANG-модель (в данном случае OpenConfig).
Из инвентарки (топологии) и этих моделей рендерится конфиг, который с помощью RPC (тут gRPC) прогружается на коробку.
Model Driven означает тут, что мы
А) не думаем (или думаем меньше) про иерархию, типы данных. Перестаём мыслить тегами XML.
Б) Модель определяет, как будет выглядеть конфигурация, как с ней работать.
В) Использование точно такой же модели на устройстве гарантирует, что отправленное нами, будет принято и валидно на той стороне, коль скоро оно валидно на этой.
Иными словами именно модель управляет тем, как мы и железо будет работать с конфигурацией.
Вот и вся суть.
Всё вместе
Ух, какую же большую кучу из разных технологий и идей мы свалили с начала статьи. Пора бы её разобрать и по коробкам разложить.
Итак,
Транспорт
SSH,
HTTP,
HTTP/2
SNMP тоже, конечно же, возможен, но не нужен.
Интерфейс
CLI
SNMP
NETCONF
RESTCONF
gRPC
Формат данных
Текст
XML
JSON
Protocol Buffers
Способ описания спецификации - он же может называться схемой
XSD
JSON schema
Protocol Buffers
MIB
Проприетарный способ, придуманный вендором и описанный в документации.
YANG-модели данных конфигурации
OpenConfig
Проприетарные модели
IETF
Проприетарная модель, придуманная вендором и неописанная в документации
Языки описания моделей
YANG
SMI/SMIng
Проприетарный язык, придуманный вендором и не описанный в документации
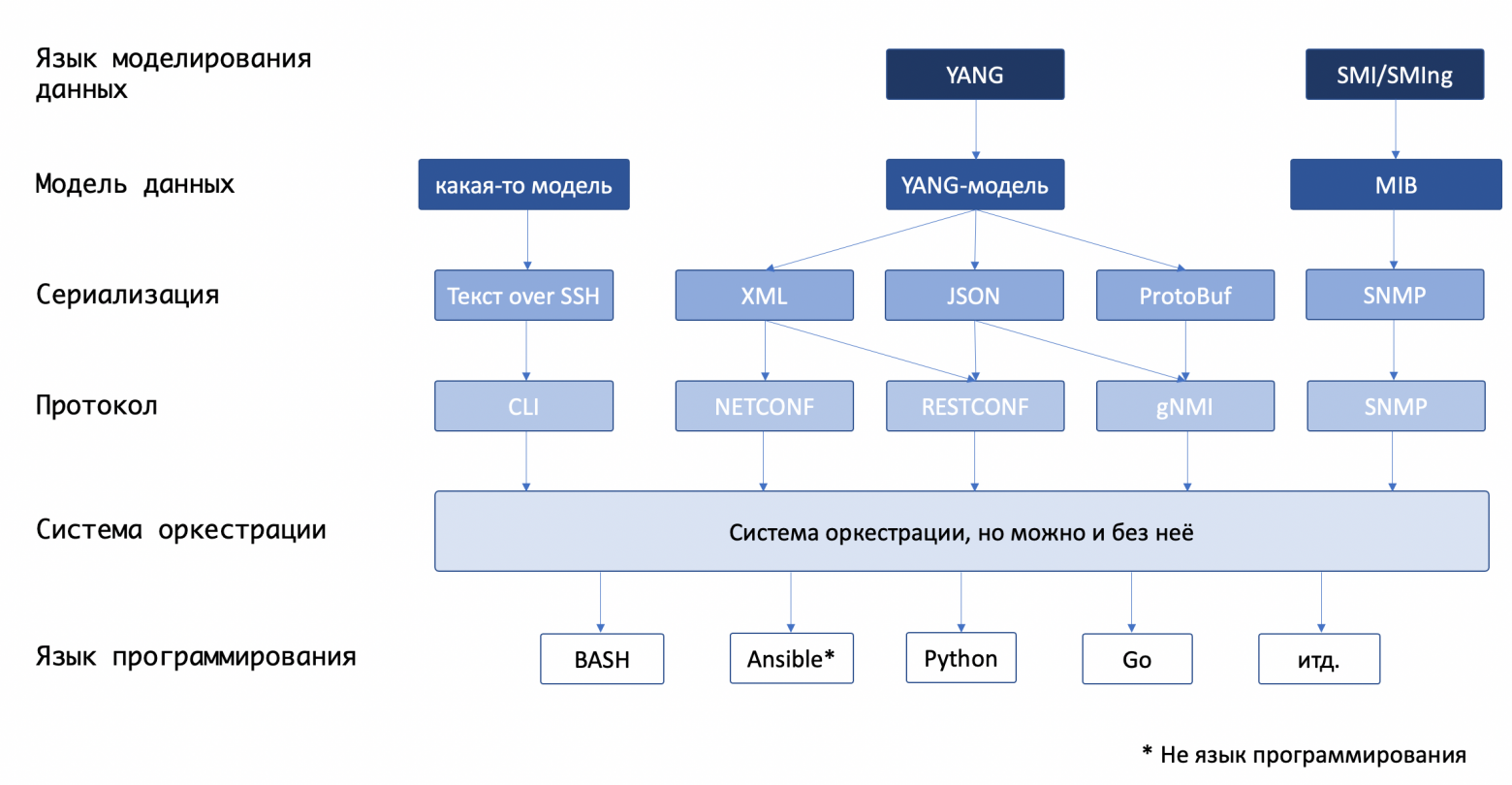
И ещё другими словами
YANG - язык моделирования данных, но не сами модели,
YANG-модели - конкретные модели, написанные на языке YANG, но ещё не сами данные и не их схема,
OpenConfig - вендор-независимая YANG-модель данных конфигурации сетевого оборудования,
Native-модели - вендорские проприетарные YANG-модели данных сетевой конфигурации,
XML, JSON, Protobuf - синтаксис по представлению структур данных в виде, пригодном для передачи (например, строка), иными словами - сериализация,
XML-схемы (XSD), JSON-схемы, proto-спецификации - репрезентация YANG-модели в соответствующем формате, схема
NETCONF - протокол взаимодействия с сетевым железом, работающий поверх SSH. В качестве формата данных использует XML. Структура XML может быть основана на YANG-модели, но не обязательно,
RESTCONF - аналог NETCONF, но работающий через HTTP. Данные представляются в JSON или XML на основе какой-либо YANG-модели,
gRPC - фреймворк для межсервисного взаимодействия, которые реализует интерфейс, протокол, формат данных и спецификации (protocol buffers). Непосредственно к сетям отношения не имеет,
Protobuf - он же protocol buffers - спецификация для gRPC, а так же формат передачи данных в нём,
gNMI - протокол на основе gRPC для взаимодействия с сетевым оборудованием. Всегда основан на модели, представленной в формате protobuf-спецификации, но это не обязательно должна быть YANG-модель.
И чтобы окончательно запутаться разобраться в терминах, давайте разложим по полочкам: схема, спецификация, IDL.
Схема - это широкий термин. Это то, что описывает, как данные должны быть представлены и чему соответствовать: структура, иерархия, типы итд.
Думаю, что слова "схема" и "спецификация" мы можем считать синонимами. Для каждого формата данных будет так же и свой формат написания схем. Для XML - это XSD, для JSON - JSON-schema, для gRPC - protobuf.
А уже конкретный файл/текст, описывающий какие-либо данные - это и будет сама схема. Соответственно данные можно провалидировать по схеме - убедиться, соответствуют ли они ей.
Из схемы/спецификации можно создать объекты языка программировани, чтобы было удобнее работать с ними. То есть из XML-схемы создаём классы, например, питона, работаем с ними привычным образом, далее преобразуем в XML, который можно уже проверить на соответствие изначальной схеме. Или данные, полученные из какой-то внешней системы, можно проверить на такое соответствие, прежде чем начинать обрабатывать.
IDL - его назначение прямо следует из названия - язык определения интерфейса. Если схема описывает как данные выглядят вообще, то IDL определяет, как две системы должнц представлять данные, чтобы взаимодействовать друг с другом. То есть это уже контракт между ними, а схема - это инструмент, позволяющий этого добиться.
Таким образов в gRPC protobuf является и IDL и способом описания спецификацией. В случае NETCONF формат данных - это XML, способ описания спецификации - это XSD, а в качестве IDL выступает сам NETCONF - ведь именно он и определяет интерфейс.
Модель же определяет то, как будет выглядеть сама спецификация/схема. То есть это ещё более абстрактная конструкция. И нужна модель для того, чтобы на её основе была возможность создать как proto-спеку, так и JSON-схему, так и XSD.
Заключение
Думаю, что хорошее заключение было в первой статье, к которой я и отсылаю читателя.
Путь нас ожидает неблизкий. Туман медленно рассеивается, открывая новые развилки дорожек, из которых нужно выбирать перспективную.
Но вот что следует держать в голове. Нам обо всём этом рассказывают на конференциях и пишут в длинных статьях как о свершившемся факте, в то время, как многие вещи всё ещё не работают, а в конце обычно есть приписка "Adding support of OpenConfig gNMI paves the way for future network automation".
приложение получает пакетаПолезные ссылки
Главные RFC:
Концепция RPC: Remote Procedure Call (RPC)
Про форматы данных: YAML: The Missing Battery in Python
Детальный разбор XML во всём его многообразии: XML Tutorial
XML разобран по кусочкам и мило иллюстрирован (русский): Что такое XML
Сайт OpenConfig: openconfig.net
Хорошая вводная в NETCONF и немного YANG: YANG Data Modelling and NETCONF
Продолжение про YANG и немного про NETCONF: The Road to Model Driven Programmability
На русском про NETCONF. Начало
Если жить не можете, хочется на русском про YANG, и вы воспринимаете художественную речь: YANG — это имя для вождя
Спецификация gNMI в его же репозитории
Совершенно чудесный и обязательный к употреблению сайт от Аристы с описанием и примерами разных интерфейсов и инструментов: Open Management
RESTCONF Tutorial - Everything you need to know about RESTCONF in 2020
Серия статей про RESTCONF, но рекомендую я её из-за того, что там хорошо разобраны примеры с YANG-моделями: RESTCONF, NETCONF and YANG
Достаточно обстоятельный разбор телеметрии поверх gNMI: Три года Телеметрии в IOS XR
Блог Романа Додина в общем. И в частности:
Блог Антона Карнелюка в общем. И в частности:
OpenConfig. Part 1. How open is OpenConfig
Но на сайте поехала вёрстка - до чего-то приходится докапываться самому.
Блог Михаила Кашина в общем. И в частности:
Репозиторий с PyangBind, позволяющим генерировать классы Python из YANG-моделей
Для любителей изучать Питон по Луцу: NETCONF XML Management Protocol Developer Guide
Сложный, но полезный джуниперовский документ: Understanding OpenConfig and gRPC on Junos Telemetry Interface. Я не читал ;)
Благодарности
Роману Додину за дельные комментарии как по теоретической, так и по практической частям. А так же за полезный блог и инструменты. GitHub.
Кириллу Плетнёву за наведение порядка с NETCONF и YANG - язык, модели, спецификации, форматы данных. И за уместные и остроумные замечания по языкам и библиотекам. GitHub, fb.
Александру Лимонову за несколько идеологических замечаний и исправлений фактических ошибок.


{kind=link}