Представим процесс отладки программы на С++: перед нами есть указатель на какую-то переменную, и мы хотим знать, на что он указывает. Два варианта: если переменная глобальная, то любой современный отладчик назовет ее имя, и мы будем довольны. А вот если переменная локальная, то никакой полезной информации мы не получим.

В этом посте я расскажу, как писал скрипт, который позволяет отладчику LLDB говорить подробнее об указателях на локальные переменные: называть указываемую переменную, определять в каком стекфрейме и потоке исполнения она живет.
О себе и о проекте
Я Георгий Кукса, учусь в питерской ВШЭ на “Прикладной математике и информатике”. Интересуюсь разработкой на С++, после первого курса стажировался в команде Яндекса, разрабатывающей бэкенд сервиса Услуг.
Этот проект я выбрал в рамках осенней практики от JetBrains. Глобально команда разработки хочет улучшить пользовательский опыт при отладке программ на С++ в CLion IDE. Моя задача во время практики — показ информации об указателях.
У IDE нет “своего” отладчика – используются форки таких опенсорс-решений как LLDB или GDB, поэтому если получим решение для одного из отладчиков, то сможем применить это в CLion.
Что сейчас умеет отладчик vs что мы хотим
Рассмотрим следующую программу на С++:
int foo_global; int main() { int baz_local; int *ptr1 = &foo_global; int *ptr2 = &baz_local; }
Представим, что нам понадобилось в конкретный момент времени узнать значение указателей. Для этого добавим отладочный вывод запустим бинарник под отладчиком и выведем значение указателей (подробнее о процессе отладки здесь).
Мы увидим следующее:
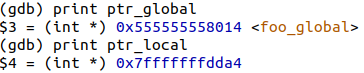
И не увидим то, что ptr_local указывает на baz_local, а хотелось бы. Этому и будем пытаться учить отладчик.
Какие трудности?
Пререквизит: о том, как именно устроено адресное пространство программы, что такое стек, куча и отображение адресов, можно прочесть здесь и здесь.
Сперва поймем, почему с указателями на глобальные переменные все работает. Дело в том, что глобальные переменные живут в отдельном адресном пространстве программы – Data section – которое не меняется по ходу исполнения, и отладчику ничего не стоит узнать эту информацию.
Про локальные переменные можно сказать следующее:
Может быть несколько локальных переменных, живущих в разных потоках исполнения;
Может быть несколько локальных переменных с одним именем, которые живут в разных стекфреймах;
Они живут по заранее неизвестным адресам.
Поэтому локальная переменная определяется своим именем, потоком и стекфреймом, в котором она живет. Такой информации у отладчика по умолчанию нет.
Какие инструменты у нас есть?
Разные отладчики имеют разное API, поэтому привести две реализации за время практики я бы не успел, а LLDB показался более привлекательным с точки зрения документации – так мы решили написать прототип именно под LLDB, включая реализацию под Linux и Windows.
Сперва поймем, что в LLDB есть встроенный интерпретатор питона, что позволяет нам импортировать python-скрипт, обладающий нужными точками входа, как описано здесь.

Далее, в нашем распоряжении также имеется публичное python-API, из которого нам понадобятся следующие сущности:

Дальше нужно понимать следующее:
У процесса можем попросить список потоков;
У каждого потока можем попросить список стекфреймов;
У каждого стекфрейма можем попросить список объявленных в нем переменных.
Как решать поставленную задачу?
Как мы заметили, локальная переменная определяется потоком, стекфреймом и именем.
Зная, какие инструменты у нас есть, мы можем предложить очень простое решение:
Перебираем каждый поток;
В каждом потоке перебираем каждый стекфрейм;
Перебираем каждую переменную из стекфрейма;
Сравниваем адрес переменной с адресом данного нам указателя.
Супер, мы получили работающее решение! Или нет?
Проблемы
Первая проблема, с которой мы столкнемся – мы могли взять указатель на поле внутри класса:
struct Foo { int bar; double baz; }; int main() { Foo foo{}; int *ptr1 = &foo.bar; double *ptr2 = &foo.baz; }
И если в случае с ptr1 мы ошибемся не так сильно и наш скрипт скажет, что мы указываем на foo (потому что адрес структуры совпадает с адресом первого аргумента), то случае с ptr2 наш скрипт вообще не найдет объект.
Для этого поймем, что у структуры SBValue в API есть поле children, которое описывает поля структуры, а у массива – элементы для каждого индекса. Переберем их и проверим адреса.
Затем вспомним, что поле структуры может представлять из себя другую структуру. Это говорит нам о том, что искать объект нужно рекурсивно: идем вглубь, если указатель указывает во внутрь объекта.
child = var.GetChildAtIndex(i) location = int(child.location, 16) size = child.size if location <= pointer < location + size: result.extend(traverse_var_tree(pointer, child, pointee_type))
Кусочек из реализации: получаем адрес переменной (child) в hex-формате, и проверяем, что указатель внутри диапазона.
Здесь также можем разобраться еще с одной трудностью – указатель со сдвигом; в подобных случаях просто будем возвращать самый глубокий объект, до которого дошли, а выводить будем в формате address + offset.
Следующий класс проблем связан с типом данного указателя. Мы не можем отличить адрес самой структуры и адрес первого элемента этой структуры.
Аналогичная проблема есть у структуры объединения (union, подробнее об этом) — это тип класса, в котором все данные разделяют одну и ту же область памяти, причём нет никаких указаний, какое поле сейчас "активно".
union Union1 { int A; double B; }; union Union2 { struct { float x; int y; } A; struct { int w; int z; } B; };
Это пример юниона — одновременно хранится только объект А, либо B.
То есть теперь помимо адреса объекта мы должны брать во внимание тип объекта и сравнивать его с типом указателя.
А вот если указатель имеет тип void * тут уже ничего не спасет – придется выводить все объекты, в которые попадает наш указатель, поскольку мы не можем знать на какой объект действительно взят указатель.
В определенный момент мы увидели еще случай, который хотелось бы покрывать: пусть мы хотим пройтись по массиву, а в наличии у нас есть только указатель на начало массива и на его конец (элемент за массивом, аналог std::end):
int foo[3]; int *end = foo + 3; for (int *start = foo; start != end; start++) { // ... }
Текущий алгоритм не скажет, что end указывает на какой-нибудь объект, а все-таки хотелось бы видеть, что он указывает на самом деле на foo[3].
Здесь пойдем на хитрость: в API можно получать искусственные объекты (“synthetic children”) – в случае массива при обращении к индексам большим, чем размер массива, будут создаваться объекты

Оптимизации
При интеграции в CLion скорее всего будет использоваться C++ и его C++ API. Однако оптимизировать прототип все еще хочется, к тому же некоторые оптимизации не зависят от выбора языка.
Сперва поймем, что не стоит перебирать все переменные внутри потока, если диапазон адресов этого потока не содержит данный указатель. К несчастью для нас, в API нет такого метода, который бы возвращал для каждого потока диапазон адресов его стека. Тогда мы решили спросить эту информацию у операционной системы:
На Linux прочтем файл /proc/{pid}/maps (где pid – id отлаживаемого процесса) – подробнее об этом здесь и здесь. Он содержит диапазоны адресов отображенных в памяти; среди этих диапазонов есть те, которые соответствуют потокам

Затем у данного потока, возьмем какой-нибудь адрес, например адрес стека первого стекфрейма, – осталось найти диапазон, который содержит этот адрес.
На Windows имеется такая структура, как Thread Information Block, которая хранит в себе нужные адреса.

Осталось заполучить эту сущность через WinAPI — возьмем обработчики процесса, потока и вызовем NtQueryInformationThread.
Под macOS реализацию не приводили из-за ограничений по длительности практики. Впрочем ожидается, что аналогом proc/{pid}/maps является утилита vmmap.
Хорошо, сделали отсечение по потокам. Давайте по аналогии игнорировать стекфреймы, которые не содержат нужный адрес. Ориентироваться будем по frame pointer – адрес стека, с которого начинают располагаться локальные переменные фрейма (подробнее об устройстве стека)

Среди всех фреймов найдем такой, у которого меньше всего frame pointer, но еще больше значения данного указателя – такой фрейм содержит искомый объект.
Затем мы решили запустить программу под профайлером PyCharm’а. И там мы обнаружили, что мы очень неоптимально делаем вызовы API.

Когда хотим перебрать детей объекта (будь то потоки процесса, фреймы потока, или переменные фрейма) мы вызывали список Object.children и итерировались по нему. Однако внутри библиотеки список Object.children конструировался последовательным запуском children[i] = Frame.getChildAtIndex(i) – то есть мы выделяем память под массив, который нам нужен единожды и лишний раз смотрим на объект, прежде чем к нему обратиться. Решение: делать вызовы напрямую – getChildAtIndex, аналогично с потоками и фреймами.
Нагружали этот скрипт с помощью программы на 300 потоков, по 1000 фреймов в каждом – время отклика примерно 0.05c на машине с 8гб RAM и Intel Core i7-4700HQ 3.4GHz.
Итог
Рассмотрим следующий кусок кода:
#include <thread> #include <chrono> using namespace std::chrono_literals; union Bar { double x; int y[3]; }; struct Foo { Bar bar; }; int *some_ptr; void calc() { Foo foo{}; foo.bar.y[0] = 0; some_ptr = &foo.bar.y[2]; std::this_thread::sleep_for(60s); } int main() { std::thread thread(calc); thread.join(); }
Вот как может выглядеть пример использования:

Здесь мы создаем объект foo внутри потока thread и берем указатель на “глубокий” элемент в нашей структуре: &foo.bar.y[2] и кладем его в some_ptr. А хотим посмотреть на указатель из основного потока – для этого ставим breakpoint, импортируем скрипт, запускаем процесс (подробнее об отладке в LLDB). Далее печатаем значение указателя и передаем адрес написанной нами функции – tp <hex_address> (trace poiter), который нам рассказывает куда указывает данный адрес, в каком потоке и фрейме живет указываемый объект. Также реализована функция vp (visualise pointers), которая распечатывает информацию для всех указателей, видных из текущего фрейма.
Заключение
Представленный прототип показывает, как можно получить информацию об указателях на локальные переменные. В статье не упомянуто, как в принципе интегрировать это решение в CLion — а такой вопрос приходилось обсуждать, поскольку мы рассматривали вариант сделать Pull Request непосредственно в LLVM, но тогда было бы сложнее встраивать и использовать алгоритм из CLion, поэтому мы решили этого не делать. Я надеюсь, что этот концепт будет когда-нибудь реализован и облегчит отладку кода разработчикам.
Другие проекты наших студентов:

