Обучение с подкреплением и имитация поведения человека с помощью MineRL
В случайно сгенерированном мире Minecraft найдём алмазы с помощью ИИ. Как обученный с подкреплением агент проявит себя в одной из самых сложных задач игры? Подробностями делимся к старту флагманского курса по Data Science.
Minecraft — масштабная игра с большим количеством механик и сложных последовательностей действий. Чтобы просто научить людей играть в эту игру, написали целую энциклопедию на 8000 страниц.

Обсуждаемое не ограничивается только Minecraft; подход можно применять в таких же сложных средах. Строго говоря, мы реализуем два разных метода, которые станут основой нашего интеллектуального агента.
Но, прежде чем обучать агента, необходимо понять, как взаимодействовать со средой. Начнём со скриптового бота и познакомимся с синтаксисом. Работать мы будем с MineRL — потрясающей библиотекой для создания приложений искусственного интеллекта в Minecraft.
Код из статьи доступен в Google Colab. Это упрощённая и доработанная версия потрясающих блокнотов, написанных организаторами турнира MineRL 2021 (лицензия MIT).
I. Скриптовый бот
MineRL позволяет запускать Minecraft в Python и взаимодействовать с игрой. Взаимодействие реализовано через популярную библиотеку gym:
env = gym.make('MineRLObtainDiamond-v0') env.seed(21)

Мы стоим перед деревом. Как вы видите, разрешение довольно низкое. В низком разрешении используется меньше пикселей, что ускоряет работу. К счастью для нас, нейронным сетям не нужно разрешение 4К, чтобы понять происходящее.
Мы хотим взаимодействовать с игрой. Что может делать наш агент? Вот список возможных действий:

Первый шаг при поиске алмазов — добыть древесину для изготовления верстака и деревянной кирки.
Давайте постараемся подойти к дереву поближе. То есть нам нужно удерживать кнопку Forward меньше секунды. В MineRL обрабатывается по 20 действий в секунду: нам не нужна целая секунда, поэтому давайте повторим действие Forward 5 раз и подождём ещё 40 тактов:
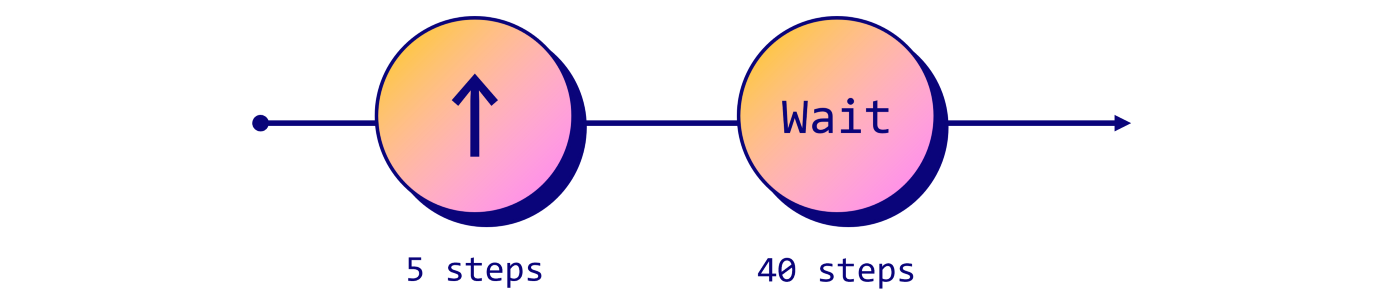
# Define the sequence of actions script = ['forward'] * 5 + [''] * 40 env = gym.make('MineRLObtainDiamond-v0') env = Recorder(env, './video', fps=60) env.seed(21) obs = env.reset() for action in script: # Get the action space (dict of possible actions) action_space = env.action_space.noop() # Activate the selected action in the script action_space[action] = 1 # Update the environment with the new action space obs, reward, done, _ = env.step(action_space) env.release() env.play()

Отлично, а сейчас срубим дерево. В общей сложности от нас требуется 4 действия:
Forward — встать перед деревом;
Attack — срубить дерево;
Camera — посмотреть вверх или вниз;
Jump — получить готовый кусок древесины.
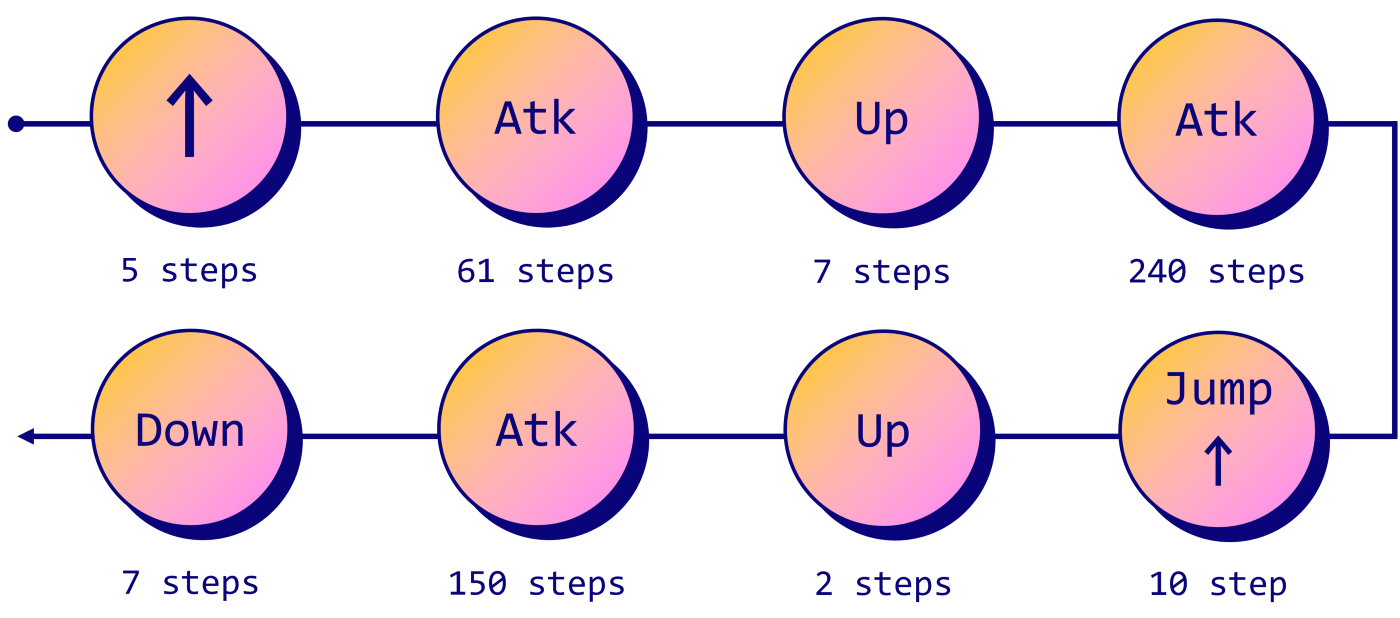
Управляться с камерой может быть трудновато. Для упрощения синтаксиса мы задействуем функцию str_to_act из этого GitHub-репозитория (лицензия MIT). Новый скрипт теперь выглядит так:
script = [] script += [''] * 20 script += ['forward'] * 5 script += ['attack'] * 61 script += ['camera:[-10,0]'] * 7 # Look up script += ['attack'] * 240 script += ['jump'] script += ['forward'] * 10 # Jump forward script += ['camera:[-10,0]'] * 2 # Look up script += ['attack'] * 150 script += ['camera:[10,0]'] * 7 # Look down script += [''] * 40 for action in tqdm(script): obs, reward, done, _ = env.step(str_to_act(env, action)) env.release() env.play()
Агент успешно срубил целое дерево. Неплохо для начала, но от ИИ хотелось бы побольше самостоятельности…
II. Глубокое обучение
Наш бот хорошо работает в фиксированной среде. Но что случится, если мы поменяем затравку или её начальную точку? Всё прописано в скрипте, так что агент, скорее всего, попытается срубить несуществующее дерево.
Такой подход слишком статичен для наших целей: нам нужно что-то, что могло бы адаптироваться к новым средам. И вместо заданных в скрипте команд нам нужен искусственный интеллект, который бы знал, как рубить деревья. Конечно же, подходящей основой для обучения такого агента служит обучение с подкреплением. Если точнее, то подходящим вариантом будет глубокое обучение с подкреплением, поскольку мы обрабатываем изображения, из которых выбираются правильные действия.
Существует два способа реализации глубокого обучения с подкреплением:
Истинное глубокое обучение с подкреплением: агент обучается с нуля, взаимодействуя со средой. Он поощряется каждый раз, когда срубает дерево.
Имитационное обучение: агент учится, как рубить деревья, исходя из набора данных. Здесь данные — это последовательность действий по рубке деревьев, выполняемая человеком.
Оба подхода дают один и то же результат, но они не одинаковы. Авторы турнира MineRL 2021 пишут, что одинаковый уровень производительности достигается в обучении с подкреплением за 8 часов, а в имитационном обучении — за 15 минут.
У нас нет столько времени, поэтому что мы останавливаемся на варианте с имитационным обучением. Эта техника также называется клонированием поведения, то есть простейшей формой имитации.
Обратите внимание, что имитационное обучение не всегда бывает эффективнее обучения с подкреплением. Если хотите почитать подробнее, то Кумар с соавторами написал об этом отличную статью в блоге.

Проблема сводится к задаче классификации с несколькими классами данных. Набор данных состоит из видео в mp4, так что мы воспользуемся свёрточной нейронной сетью (CNN), чтобы перевести данные изображения в соответствующие действия. Кроме того, наша цель — ограничить количество возможных действий (классов). Таким образом, у CNN останется меньше доступных вариантов, и обучение пройдёт эффективнее:
class CNN(nn.Module): def __init__(self, input_shape, output_dim): super().__init__() n_input_channels = input_shape[0] self.cnn = nn.Sequential( nn.Conv2d(n_input_channels, 32, kernel_size=8, stride=4), nn.BatchNorm2d(32), nn.ReLU(), nn.Conv2d(32, 64, kernel_size=4, stride=2), nn.BatchNorm2d(64), nn.ReLU(), nn.Conv2d(64, 64, kernel_size=3, stride=1), nn.BatchNorm2d(64), nn.ReLU(), nn.Flatten(), nn.Linear(1024, 512), nn.ReLU(), nn.Linear(512, output_dim) ) def forward(self, observations): return self.cnn(observations) def dataset_action_batch_to_actions(dataset_actions, camera_margin=5): ... class ActionShaping(gym.ActionWrapper): ...
В этом примере мы вручную определили 7 подходящих действий: Attack — атака, Forward — движение вперёд, Jump (прыжок) и движение камеры влево, вправо, вверх и вниз. Ещё один популярный подход — использовать метод k-средних для автоматического подбора релевантных действий человека. В любом случае смысл в том, чтобы убрать самые бесполезные для решения задачи действия. Наша задача — изготовление (крафтинг) вещей.
Давайте обучим нашу CNN на наборе данных MineRLTreechop-v0. Другие наборы данных можно найти здесь. Мы выбрали скорость обучения 0,0001 и 6 эпох с размером пакетов в 32:
# Get data minerl.data.download(directory='data', environment='MineRLTreechop-v0') data = minerl.data.make("MineRLTreechop-v0", data_dir='data', num_workers=2) # Model model = CNN((3, 64, 64), 7).cuda() optimizer = torch.optim.Adam(model.parameters(), lr=0.0001) criterion = nn.CrossEntropyLoss() # Training loop step = 0 losses = [] for state, action, _, _, _ \ in tqdm(data.batch_iter(num_epochs=6, batch_size=32, seq_len=1)): # Get pov observations obs = state['pov'].squeeze().astype(np.float32) # Transpose and normalize obs = obs.transpose(0, 3, 1, 2) / 255.0 # Translate batch of actions for the ActionShaping wrapper actions = dataset_action_batch_to_actions(action) # Remove samples with no corresponding action mask = actions != -1 obs = obs[mask] actions = actions[mask] # Update weights with backprop logits = model(torch.from_numpy(obs).float().cuda()) loss = criterion(logits, torch.from_numpy(actions).long().cuda()) optimizer.zero_grad() loss.backward() optimizer.step() # Print loss step += 1 losses.append(loss.item()) if (step % 4000) == 0: mean_loss = sum(losses) / len(losses) tqdm.write(f'Step {step:>5} | Training loss = {mean_loss:.3f}') losses.clear()
Step 4000 | Training loss = 0.878 Step 8000 | Training loss = 0.826 Step 12000 | Training loss = 0.805 Step 16000 | Training loss = 0.773 Step 20000 | Training loss = 0.789 Step 24000 | Training loss = 0.816 Step 28000 | Training loss = 0.769 Step 32000 | Training loss = 0.777 Step 36000 | Training loss = 0.738 Step 40000 | Training loss = 0.751 Step 44000 | Training loss = 0.764 Step 48000 | Training loss = 0.732 Step 52000 | Training loss = 0.748 Step 56000 | Training loss = 0.765 Step 60000 | Training loss = 0.735 Step 64000 | Training loss = 0.716 Step 68000 | Training loss = 0.710 Step 72000 | Training loss = 0.693 Step 76000 | Training loss = 0.695
Модель обучена. Теперь мы можем создать экземпляр объекта среды и посмотреть, как поведёт себя модель. Если обучение прошло успешно, модель должна безостановочно рубить все деревья в зоне видимости.
В этот раз мы воспользуемся обёрткой ActionShaping. Она нужна для сопоставления массива чисел, созданного с помощью dataset_action_batch_to_actions, с дискретными действиями из MineRL.
Нашей модели нужно наблюдение от первого лица в корректном формате, а на выходе она выводит логиты. С помощью функции softmax эти логиты можно перевести в распределение вероятностей в наборе из 7 действий. Далее случайным образом выбираем действие по его вероятности. Выбранное действие реализуется в MineRL через env.step(action).
Этот процесс можно повторять сколько угодно раз. Повторим его 1 000 раз и посмотрим, что получится:
model = CNN((3, 64, 64), 7).cuda() model.load_state_dict(torch.load('model.pth')) env = gym.make('MineRLObtainDiamond-v0') env1 = Recorder(env, './video', fps=60) env = ActionShaping(env1) action_list = np.arange(env.action_space.n) obs = env.reset() for step in tqdm(range(1000)): # Get input in the correct format obs = torch.from_numpy(obs['pov'].transpose(2, 0, 1)[None].astype(np.float32) / 255).cuda() # Turn logits into probabilities probabilities = torch.softmax(model(obs), dim=1)[0].detach().cpu().numpy() # Sample action according to the probabilities action = np.random.choice(action_list, p=probabilities) obs, reward, _, _ = env.step(action) env1.release() env1.play()
Наш агент довольно хаотичный, но в этой новой, незнакомой среде у него всё-таки получается рубить деревья. А теперь… как же найти алмазы?
III. Скрипт + имитационное обучение
Простой, но действенный подход — комбинировать скриптовые действия с действиями искусственного интеллекта. Учим всему скучному и записываем знания в скрипт.
В этой парадигме нам нужна свёрточная сеть, которая позволит получить большой объём древесины (3 000 шагов). Затем в скрипте прописывается последовательность действий для изготовления досок, палок, верстака, деревянной кирки и приступаем к добыче камня (он должен быть у нас под ногами). Этот камень можно использовать для изготовления каменной кирки, которой можно добывать железную руду.

Вот здесь всё и начинает усложняться: железная руда встречается довольно редко, поэтому для поиска её залежей придётся на какое-то время запустить игру. Далее нужно создать печь и расплавить руду, чтобы получить железную кирку. И, наконец, придётся спуститься ещё глубже и суметь получить алмаз, не упав в лаву.
Как видите, это выполнимо, но результат — непредсказуем. Мы могли бы обучить второго агента искать алмазы, а третьего — создавать железную кирку. Если вам интересны более сложные подходы, то можете почитать про результаты турнира MineRL Diamond 2021. Канервисто с соавторами описал несколько решений на основе разных хитроумных методов, включая архитектуры сквозного глубокого обучения. Надо сказать, что это сложная задача, и ни одной команде не удавалось находить алмазы постоянно… если они вообще хоть что-то находили.
По этой причине в примере ниже ограничимся созданием каменной кирки, но код можно изменить и пойти дальше:
obs = env_script.reset() done = False # 1. Get wood with the CNN for i in tqdm(range(3000)): obs = torch.from_numpy(obs['pov'].transpose(2, 0, 1)[None].astype(np.float32) / 255).cuda() probabilities = torch.softmax(model(obs), dim=1)[0].detach().cpu().numpy() action = np.random.choice(action_list, p=probabilities) obs, reward, done, _ = env_script.step(action) # 2. Craft stone pickaxe with scripted actions for action in tqdm(script): obs, reward, done, _ = env_cnn.step(str_to_act(env_cnn, action)) env_cnn.release() env_cnn.play()
Видно, что в первые 3 000 шагов агент рубит деревья как сумасшедший, а затем срабатывает скрипт, и выполняется задача. Возможно, это не так очевидно, но команда print(obs.inventory) показывает каменную кирку. Обратите внимание, что это избранный пример; большинство запусков завершаются не так успешно.
Существует несколько причин, почему агент терпит неудачу: он может попасть во враждебную среду (вода, лава и т. д.), в область без леса или даже упасть и погибнуть. Если вы поэкспериментируете с разными затравками, то сможете лучше понять всю сложность проблемы и, надеюсь, получите идеи по созданию ещё более «талантливых» агентов.
Заключение
Надеюсь, вам понравилось это небольшое руководство по обучению с подкреплением в Minecraft. Это не просто популярная игра, но и интересная среда для проверки агентов ИИ, обученных с подкреплением. Здесь, как и в NetHack, нужно очень хорошо разбираться в игровой механике, чтобы спланировать точную последовательность действий в процедурно-сгенерированном мире. В данной статье мы:
узнали, как пользоваться MineRL;
рассмотрели 2 подхода (скрипт, клонирование поведения) и их комбинацию;
показали действия агента в коротких роликах.
Основная проблема среды — низкая скорость её обработки. Minecraft — не такая лёгкая игра, как NetHack или Pong, поэтому агентам нужно много времени на обучение. Если для вас это проблема, рекомендую присмотреться к средам полегче, например Gym Retro.
Спасибо за внимание! Если вам интересно, как использовать ИИ в видеоиграх, то подписывайтесь на меня в Twitter. А мы поможем прокачать ваши навыки или с самого начала освоить профессию, актуальную в любое время:
Выбрать другую востребованную профессию.


