Заглянув в OpenShift, я заметил, что приложения стали дольше запускаться и работать медленнее. Дальнейшие изыскания показали, что одна из Node вывалилась из кластера OS. Попытался исправить проблему через ssh. Но вспомнил, что ключ от ssh остался на рабочем компьютере. Надпись Permission denied (publickey,gssapi-keyex,gssapi-with-mic) лишь подтвердила плачевность ситуации . Смотреть на экран виртуалки в консоли гипервизора, без возможности попасть внутрь… Эх!
Ретроспектива восстановления работы Node будет описана ниже. Как говорится, все совпадения и имена героев случайны.
Аварийная загрузка и вход в консоль в систему
Началось всё с аварийной загрузки. Для того чтобы нам получить shell после запуска системы, необходимо добавить определённый параметр ядра. Речь об rd.break.
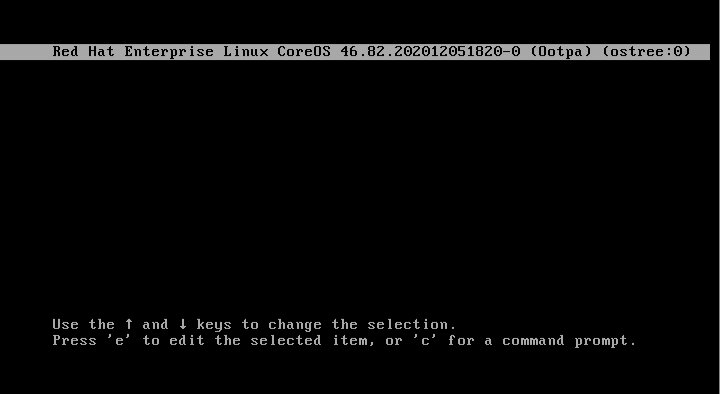
При старте системы отображается меню загрузки grub, нажимаем клавишу E и добавляем rd.break в строку linux:
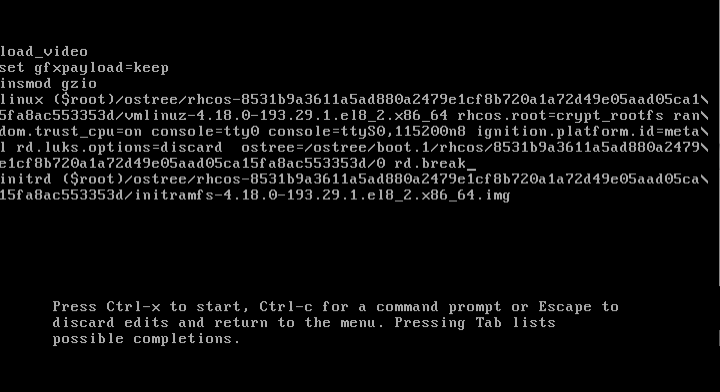
Нажимаю Ctrl+X и жду загрузки системы.
Система загружается, но консоль не появилась. Что же здесь не так?
Оказывается, необходимо было отключить интерактивную консоль. Для этого удалить строки console=tty0 console=ttyS0,115200n8:
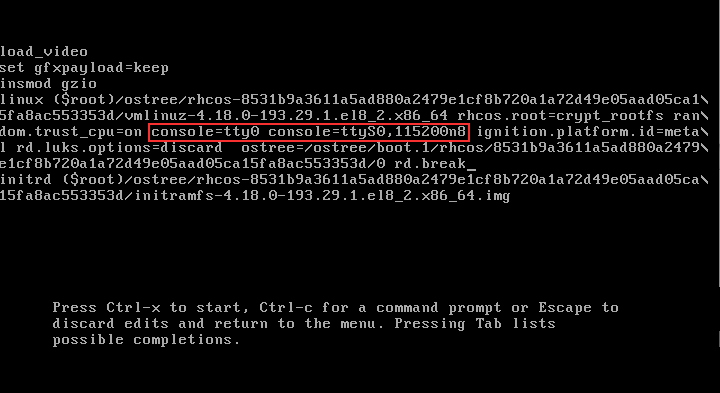
Финальный вариант будет такой:

Нажимаем Ctrl+X, и система загружается.
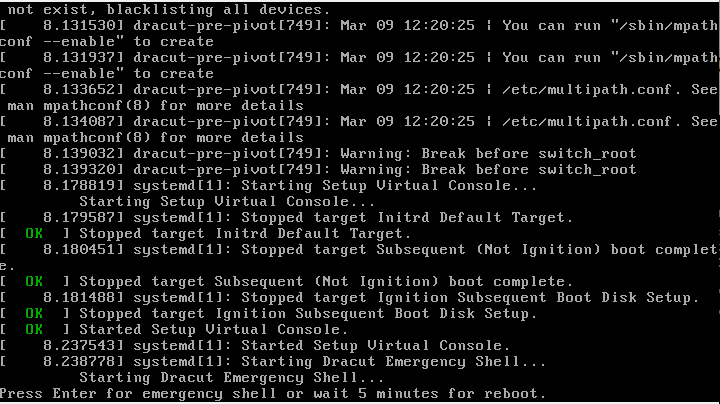
Нажимаем Enter, и становится доступен жизненно важный shell:
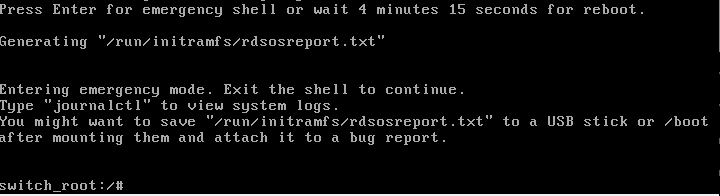
Смена пароля пользователя core
Для того чтобы сменить пароль, временно меняю каталог корневой системы через команду chroot:
mount -o remount,rw /sysroot
chroot /sysroot
passwd coreOpenShift работает при включённом SELinux, и, следовательно, у файла, должны быть соответствующие метки:
ls -Za /etc/shadow
? /etc/shadow/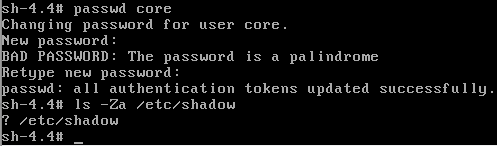
Ставлю необходимую метку:
chcon -h system_u:object_r:shadow_t:s0 /etc/shadowПроверяю:
ls -Za /etc/shadow
system_u:object_r:shadow_t:s0 /etc/shadow
Теперь можно перезагрузить систему командой:
/sbin/reboot -fИли нажать кнопку на перезапуск в панели управления для виртуальной машины или сервера.
Решаем проблему с входом по ssh
По умолчанию в системе разрешён вход только по ssh-ключам, информация о которых сохраняется в файле .ssh/authorized_keys.

Если вы оставили ssh-ключ на работе или просто он где-то потерялся в рабочих буднях, а также при необходимости добавления ещё одного ssh-ключа будем работать с этим файлом. Нужно дописать новый ключ вашего / из вашего id_rsa.pub. Но перед этим стоит проверить, что у файла установлены соответствующие права и метки SELinux:
chmod 600 -Rv ~/.ssh/
chown core:core -Rv ~/.ssh/
chcon -t unconfined_u:object_r:ssh_home_t:s0 ~/.ssh/authorized_keysили
restorecon -v ~/.ssh/authorized_keysРазрешение входа по логину и паролю без ssh-ключей
Внимание, данное действие снижает безопасность системы! Нужно использовать вход с помощью ssh-ключа и пользователя core.
Кардинально решить проблему забытых ssh-ключей может разрешение на вход в систему по логину и паролю. Для этого есть два способа в зависимости от доступной функциональности системы:
Вариант 1. Удалось зайти в систему под пользователем core
Получаю права администратора и доступ к файловой системе:
sudo su
mount -o remount,rw
vi /etc/ssh/sshd_config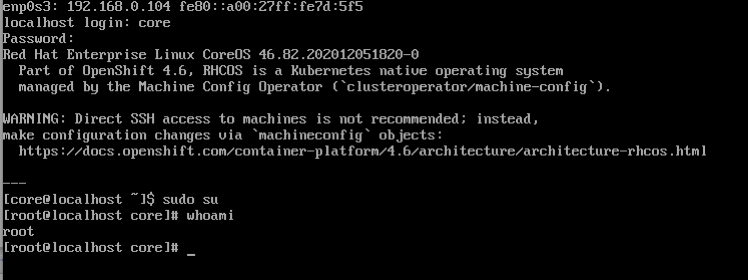
Редактирую файл для активации входа по логину и паролю. Для этого меняю параметр PasswordAuthentication на yes.
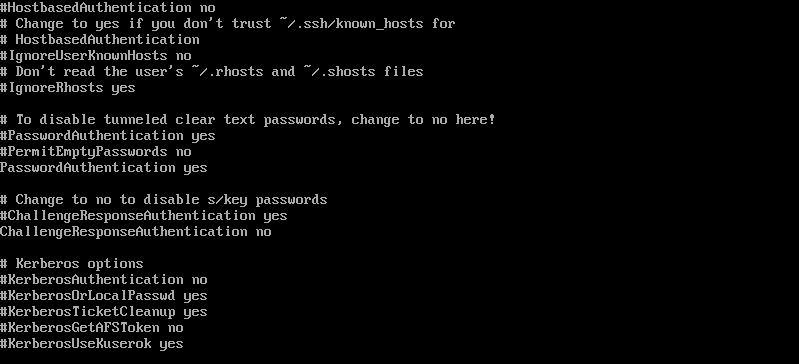
Выхожу из-под пользователя root и перезапускаю сервис:

Дополнительно поверяю метку SElinux у файла. Это пригодится для второго варианта:

Вариант 2. Загрузка в режиме rd.break
Редактирую файл /etc/ssh/sshd_config, аналогично заменив в нём строку на
PasswordAuthentication yes.
Сохраняю и проверяю метки SElinux:

Как видно, контекст-метки SElinux у файла потерялись. Восстановим их:
chcon -h system_u:object_r:etc_t:s0 /etc/ssh/sshd_configНастройка сетевых интерфейсов
Если необходимо восстановить или настроить сетевые интерфейсы у виртуальной машины, используем утилиту nmcli.
Вывести настройки сетевых соединений можно простой командой:
nmcli connection show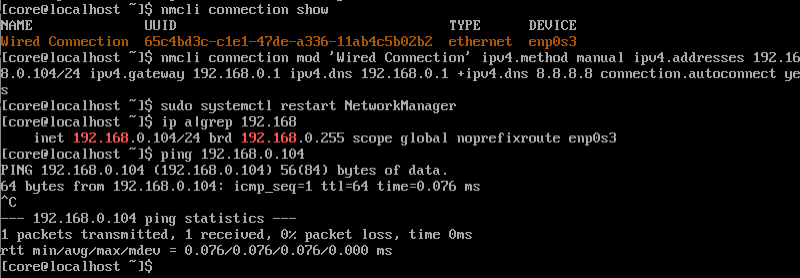
С помощью команды nmcli connection mod «имя соединения» можно отредактировать сетевые настройки и потом перезапустить сетевой интерфейс.
Тюнинг ядра системы
Раз мы уж всё равно так активно используем командную строку, то можно подтюнить ядро. В системах, которые используют rpm-ostree, можно добавлять, удалять параметры ядра, которые задаются при загрузке системы.
Например, можно увеличить быстродействие системы, отключив защиту от уязвимости Spectre v1 и v2. Для этого нужно добавить параметры:
nospectre_v1,nospectre_v2,nospec_store_bypass_disableДелается это следующими командами:
rpm-ostree kargs --append="nospectre_v1" --append="nospectre_v2" --append="nospec_store_bypass_disable"
Staging deployment... done
Kernel arguments updated.
Run "systemctl reboot" to start a reboot
[root@localhost core]# rpm-ostree kargs mitigations=auto,nosmt console=tty0 console=ttyS0,115200n8 ignition.platform.id=metal $ignition_firstboot ostree=/ostree/boot.1/fedora-coreos/0045ea4dd22400fe745be6b98741225cd831069a635d08100f5d25f1c77a13ac/0 root=UUID=de3da0d6-308e-4f4e-b60a-04db75452575 rw rootflags=prjquota boot=UUID=02e3df85-38cd-4173-a672-3b6fb5dfe4b0 nospectre_v1 nospectre_v2 nospec_store_bypass_disableПосле перезагрузки системы можно проверить, что параметры ядра были применены, выполнив команду:
rpm-ostree kargsИ наоборот, если хотим удалить параметры ядра, тогда можно выполнить данную команду:
sudo rpm-ostree kargs --delete="nospectre_v1" --delete="nospectre_v2" —delete="nospec_store_bypass_disable"Справку по данной команде можно посмотреть так:
rpm-ostree kargs –helpДополнительные параметры, которые вам могут понадобиться:
--append="ipv6.disable=1"
--append="quiet"Режим quiet позволит удалить данные сообщения с виртуальной консоли первого экрана в системе:
sudo rpm-ostree kargs --append="quiet"
Staging deployment... done
Kernel arguments updated.
Run "systemctl reboot" to start a rebootПодключение нового диска в систему
Дополнительно рассмотрим подключение второго жёсткого диска. Имя диска может отличаться от вида контроллера жёсткого диска в системе или виртуальной машине. В моём примере это были диски /dev/sd*.
Для начала разобьём жёсткий диск на разделы:
fdisk /dev/sdb
mkfs.ext4 /dev/sdb1 -L disk2_test

Чтобы подключить диск в папку /usr/local/1, необходимо создать такой Unit file systemd:
mkdir -pv /usr/local/1
cat << EOF >/etc/systemd/system/var-usrlocal-1.mount
[Unit]
Description = Mount for Container Storage
[Mount]
#What=/dev/sdb1
What=/dev/disk/by-uuid/7fb1139c-b9c9-404c-91fa-9b2f251fb11c
Where=/var/usrlocal/1
Type=ext4
[Install]
WantedBy = multi-user.target
EOFВключаем автозагрузку и запускаем:
systemctl enable var-usrlocal-1.mount
Created symlink /etc/systemd/system/multi-user.target.wants/var-usrlocal-1.mount → /etc/systemd/system/var-usrlocal-1.mount.
systemctl start var-usrlocal-1.mountПроверим, что подключился наш раздел (df -h):
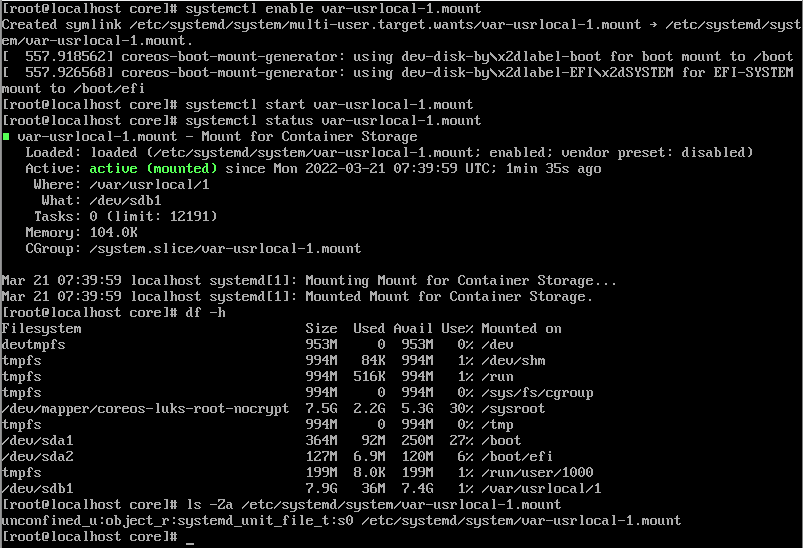
Обязательно обращаем внимание на метки SELinux, которые необходимы для systemd unit файла (system_u:object_r:systemd_unit_file_t:s0).
Если подключаете новый диск в папку /var/lib/containers, посмотрите данную информацию:
А что дальше?
После получения доступа в систему проводим стандартные процедуры по чтению логов служб сервисов. В завершение диагностики и после исправления сбоев, когда Node будет снова в кластере OpenShift, можно использовать стандартные средства для сбора и анализа логов со всех Nodes OpenShift:
oc adm must-gatherЕсли данные, сохранённые на данной Node в PV (Persistent Volume), подключённые в HostPath данной ноды, были сохранены и планируется установить снова систему на пустую виртуалку или сервер, тогда можно воспользоваться краткой шпаргалкой-подсказкой: Installing a cluster on bare metal.
Если ничего не помогло
Если вышеописанные способы восстановления доступа к Node не помогли, то остаётся лишь одно — переустановка системы. Для установки OpenShift можно использовать один из двух популярных образов:
Загрузившись с образа rhcos-4.6.8-x86_64-live.x86_64.iso, вы увидите экран приветствия и информацию-пример core-installer.
В случае ручной установки и подготовки образа запускается установка с помощью coreos-installer, которому передаются параметры для установки, ссылка на url с файлами ignition (для bootstrap, compute node и worker node) и другие дополнительные параметры.
Также могут потребоваться такие настройки: параметры для ядра с назначением необходимого айпи адреса для данной виртуальной машины или сервера, днс имён, адреса, где располагаются образы системы, и тому подобное. Вот один из моих примеров для KVM-виртуализации:
sudo coreos-installer install /dev/vda --ignition-url http://192.168.122.239:8080/okd4/master.ign --insecure-ignition --append-karg rd.neednet=1 --append-karg ip=192.168.122.16::192.168.122.1:255.255.255.0:okd4-control-plane-1.lab.okd.local:ens3:none --append-karg nameserver=192.168.122.1 --append-karg nameserver=192.168.122.239 --image-url http://192.168.122.239:8080/okd4/fcos.raw.xzP. S. Если вы захотите потренироваться на кошках, чтобы всегда быть готовым к ситуации, когда ssh-ключа не будет под рукой, тогда необходимо загрузиться с диска (iso) и провести установку на систему. Например, на VirtualBox: