Предсказать настроение человека, а тем более женщины, не простая задача. Существует множество методик, к примеру, принимающих во внимание физиологические аспекты, гормональный уровень или фазы луны.
Я же решил пойти своим путём опираясь на логику и статистику.
Прошу читателя не относится слишком серьёзно к данному труду, это исследование носит скорее развлекательный характер нежели научный. И всё же я буду признателен за плюс к карме за приложенные старания и уйму потраченного времени и нервов.
Почти за год мною был собран сет данных, основанный на ежедневных опросах моей спутницы (далее "исследуемый объект" или ИО) по двадцати трём пунктам, как я предположил, способным наиболее выражено повлиять на настроение ИО.

Исследуемый объект. 1. ФИО: данные скрыты; 2. Пол: женский; 3. Возраст: 27 лет; 4. Место проживания: Россия, г. Москва; 5. Профессия: IT разработчик; 6. Место работы: данные скрыты;
Задача
Исходя из статистически значимых признаков определить наиболее важные - влияющие на настроение исследуемого объекта.
В первой части статьи я визуализирую в некой степени очевидные, а зачастую, как оказалось, совершенно неочевидные закономерности, полученные мною в ходе анализа собранных данных. На основе полученных выводов, исследуемому объекту будут выданы рекомендации для прохождения тестового месяца, во время которого я продолжу собирать данные по заявленным ранее 23 фичам.
Во второй части статьи я сравню итоговый показатель настроения в тестовом месяце с аналогичным показателем за прошедший год, а также обучу простенькую модель предсказания на имеющихся тренировочных данных. Качество модели буду проверять данных тестового месяца.
Данные
Признаюсь, мне пришлось вручную заполнить около 10% данных, опираясь на среднемесячные показатели, а в каких-то случаях на логику или память... Не так просто в течении года придерживаться графику ежевечернего заполнения таблицы двум работающим людям, с присущими, как и всем людям, бытовым обязанностям и сложностям.
В список фичей намеренно не попадали такие данные, на которые невозможно повлиять, например курс валюты или количество осадков. В процессе анализа я осознал, что это было ошибкой, ведь если скорректировать свои привычки, скажем в дождливый день, это может весомо повлиять на результат, на настроение.
Так же в сете присутствуют существенные выбросы, что затрудняло интерпретацию результатов, такие как праздники, отпуск или начало боевых действий на Украине.
sense | sleep_inter | sleep_time | phy_cond | tot_work_time | work_h_o | line_code | cook_food | cont_time | cont_platform | serial_time | ind_learn_time | course_time | cardio_time | stretch_time | numb_steps | numb_meals | meat | vegetable | fruit | milk | dessert | alcohol |
4 | 01_09 | 8 | 5 | 40 | 1 | 130 | 1 | 120 | y_tube | 135 | 0 | 0 | 30 | 0 | 1040 | 3 | pork&chiken | 1 | 1 | 0 | 0 | 0 |
Фичи я решил поделить по шести секторам
Физическое состояние
Интервалы сна (sleep_inter). Номинативная переменная
Время сна (sleep_time). Количественная переменная
Общее физическое состояние (phy_cond). Номинативная переменная
Рабочая активность
Общее время работы в минутах (tot_work_time). Количественная переменная
Работа дома/ Работа в офисе (work_h_o). Номинативная переменная
Кол-во строк кода (line_code). Количественная переменная. Как выяснилось фича ни на что не влияет от слова совсем
Готовка еды (cook_food). Номинативная переменная
Еда
Кол-во приёмов пищи (numb_meals). Номинативная переменная
Какое мясо употреблялось в пищу (meat). Номинативная переменная
Отдельно пять номинативных фич - овощи, фрукты, молоко, сладкое, алкоголь
Просмотр контента
Общее время просмотра контента (cont_time). Количественная переменная
Площадка и площадки просмотра контента (cont_platform). Номинативная переменная
Время просмотра сериала/фильма (serial_time). Количественная переменная
Спорт
Кардио тренировка в минутах (cardio_time). Количественная переменная
Растяжка тренировка в минутах (stretch_time). Количественная переменная
Кол-во пройденных шагов за день (numb_steps). Количественная переменная
Самообразование
Самостоятельное образование в минутах (ind_learn_time). Количественная переменная
Образование на курсах в минутах (course_time). Количественная переменная
Анализ
Итак! Всё готово, и я предлагаю безотлагательно приступать. Загодя попрошу прощения за весьма внушительный лонгрид - я правда старался излагать информацию компактно и всячески подкреплять понятными визуальными образами.
Первым делом, взглянув на тепловую карту корреляции переменных между собой, я выделил сектора максимально связанные с целевой переменной настроения (sense). Ожидаемо оными оказались разделы отвечающие за физическое состояние и рабочую активность. Они и станут основными якорями для дальнейшего выявления взаимосвязей.

matrix = np.triu(all_feat_for_corr.corr()) sns.set_style("white") sns.heatmap(all_feat_for_corr.corr(), annot=True, mask=matrix, fmt='.1g', vmin=-1, vmax=1, center=0, cmap='bwr', cbar=False).get_figure().savefig('all_feat.png')
Общее физическое состояние и интервалы сна показывают максимальную корреляцию. Весомо выделяется положительная количество рабочего времени к настроению. Хорошее настроение при плодотворной работе может быть, как причиной, так и следствием, или первым и вторым одновременно.
Рассмотрим какие интервалы сна наиболее благоприятны исходя из настроения и физического состояния.
На обоих графиках лидируют интервалы начинающиеся с часа ночи (01:00-00:08, 01:00-00:09, 01:00-00:10). Восемь часов сна в среднем с часа ночи запомним как оптимальный период сна.

Логично предположить, что в выходные можно позволить себе поспать немногим больше. Проверим эту теорию, построив графики для будних и выходных (вместе с праздничными) днями.
И да, ожидаемо, в будни это интервалы 01:00-00:08 и 01:00-00:09, а по выходным лучше спать 9 часов с часу до десяти.

sns.set(rc={'figure.figsize':(20,5)}) sns.set_style("white") sns.set_context("paper", font_scale=2) colors = ['#7FFFD4', '#6890F0', '#78C850','#F8D030', '#F08030'] gr = sns.countplot(x="sleep_inter", hue="sense", data=sentiment_df, palette=colors) plt.title('Optimal sleep interval (Sense)', fontsize=24) plt.xlabel('Sleep interval', fontsize=18) plt.ylabel('Count', fontsize=18) gr.legend(bbox_to_anchor= (1.2,1), fontsize='18');
Я счёл необходимым подробней рассмотреть взаимосвязь настроения и показателя рабочего времени в минутах. Успешней всего с этим справятся боксплоты. Медианные показатели фиксируют интервал работы 400-420 минут (то есть около 7 часов работы фултайм) при хорошем настроение (4 и 5 балов).
Та же динамика наблюдается и при сравнении с физическим состоянием (не стал визуализировать материал в статье - экономлю Ваше время). Ниже тоже распределение в зависимости от локации - дом или офис (голубые боксы - офис, оранжевые - дом). Результат неоднозначный. В дни с хорошем настроением (4 и 5 балов) ИО меньше работала дома нежели в офисе, а значит дела шли быстрей, а значит зачем "платить" больше при том же результате.

sns.set(rc={'figure.figsize':(5,5)}) colors = ['#7FFFD4', '#F08030'] sns.boxplot(x="sense", y="tot_work_time", hue='work_h_o', data=work_sense_df, palette=colors); sns.stripplot(x="sense", y="tot_work_time", data=work_sense_df, size=2, color=".1", linewidth=0) plt.title('Dependence of mood on\n work time (home or office)', fontsize=22) plt.xlabel("Sense", fontsize=18) plt.ylabel('Total work time, min', fontsize=18);
Изучим эту гипотезу подробней. Возможно, дело в готовке пищи? Ведь если работаешь дома -> освобождается время на проезд, и, следовательно, почему бы не приготовить самому себе пищу. Многим это приносит удовольствие, в частности и нашему объекту (инсайд от автора). И это подтверждают таблицы ниже.
Слева. Распределение кол-ва дней с приготовлением пищи в зависимости от локации работы с указанием среднего показателя времени работы в минутах без учёта настроения. Справа. Тоже самое, только в дни с хорошим настроением.
Предварительный вывод - лучше работать дома, при этом готовить ;)

Наиболее интересный сектор для анализа - сектор еды. Предварительно посмотрим на корреляцию с настроением каждой переменной.
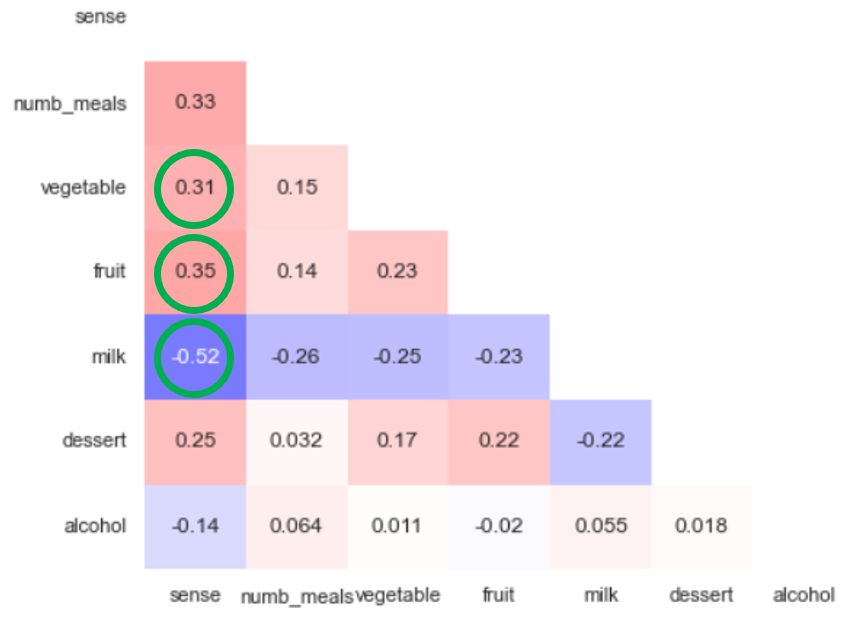
Ожидаемо фрукты и овощи положительно влияют на целевую переменную, а вот отношение с молочными продуктами, лично для меня, стало неожиданностью.
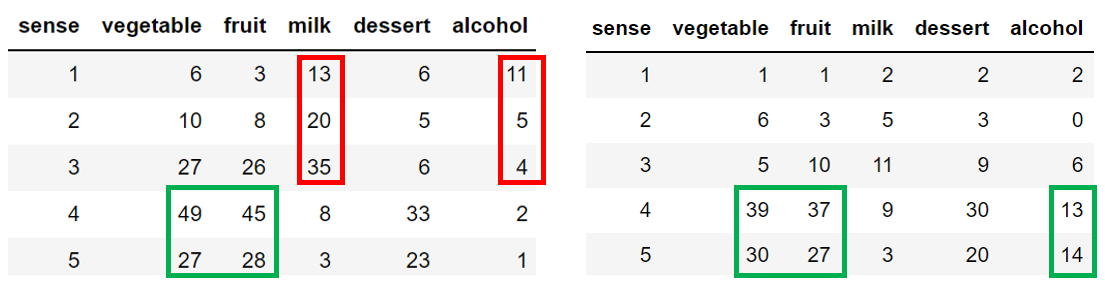
Прежде рассмотрим отдельно употребляемые продукты в рабочие и не рабочие дни в зависимости от настроения (левая и правая таблицы соответственно).
work_day_eat_df = sentiment_df.drop(index=[92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 206, 218, 219, 274, 275, 281, 282]) work_day = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'] work_day_eat_df = work_day_eat_df.loc[work_day_eat_df['day_week'].isin(work_day)] best_eat_wd_df= work_day_eat_df.groupby(['sense'], as_index=False).agg( {'vegetable': 'sum', 'fruit': 'sum', 'milk': 'sum', 'dessert': 'sum', 'alcohol': 'sum'}) rest_day_eatt_df = sentiment_df[~sentiment_df.index.isin(work_day_eat_df.index)] best_eat_rd_df= rest_day_eatt_df.groupby(['sense'], as_index=False).agg( {'vegetable': 'sum', 'fruit': 'sum', 'milk': 'sum', 'dessert': 'sum', 'alcohol': 'sum'})
Употребление молочных продуктов именно в рабочие дни наихудшем образом сказывается на настроение, по выходным же дням распределение близко к нормальному. Фрукты, овощи и сладкое одинаково полезно для настроения в любой день, кто бы сомневался. А вот алкоголь всё же следует употреблять только по выходным, даже без учёта последствий на следующий рабочий день.
Изучим такой немаловажный фактор, как количество приёмов пищи. Построим график распределения приёмов относительно физического состояния, которое напрямую связано с настроением.

С большим отрывом лидирует показатель в три приёма пищи за день. Факт в какой-то степени очевидный, но также требующий доказательств.
В процессе анализа я наткнулся на связь между кол-вом приёмов пищи и средним показателем пройденных за день шагов (таблица ниже).
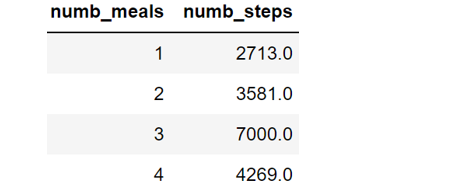
Занимательно наблюдать как пройденное расстояние влияет на аппетит. А "переедание" (4 приёма пищи) напротив свидетельствует о снижение физической активности.
best_eat_for_step_df= sentiment_df.groupby(['numb_meals'], as_index=False).agg({'numb_steps': 'mean'}).round(0)
Самое вкусное напоследок. Выбор мяса, как основу составляющую рацион большинства людей, следует рассмотреть детально.
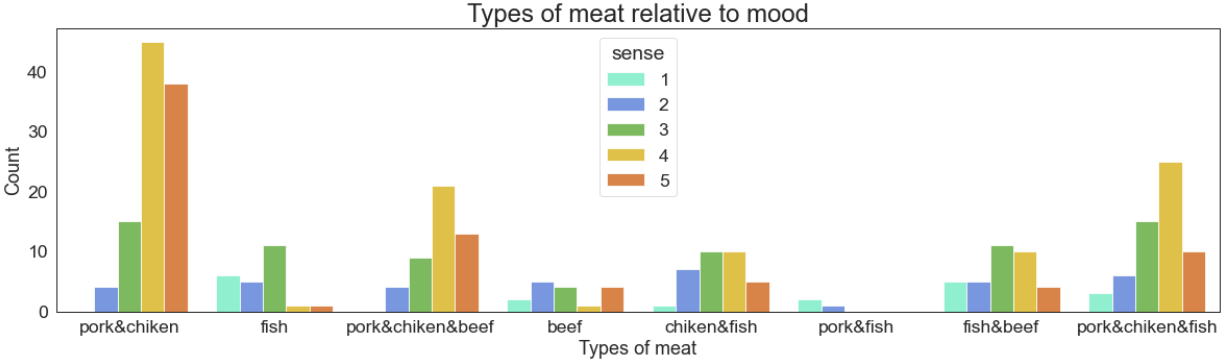
В целом динамика ясна. В таблице ниже приведены соотношения видов мяса со средними значениями большинства значимых фич. Курица+свинина (pork&chiken) и курица+свинина+говядина с отрывом лидируют в пользе для физического состояния и настроения. Такую тенденцию можно отметить и в соотношение с кол-вом пройденных шагов(numb_steps). Употребление же рыбы (pork&fish, fish) приводит к обратному эффекту.
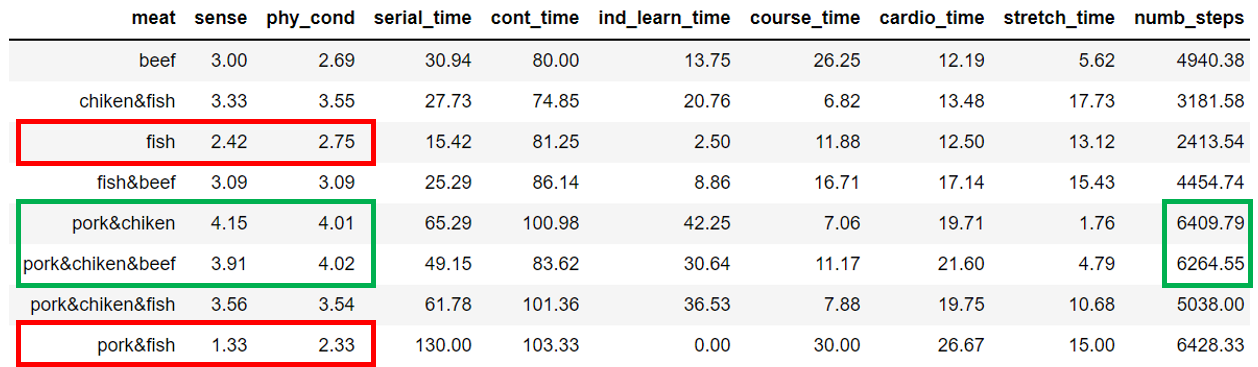
Наученный опытом, я решил изучить закономерности в выборе мяса раздельно, в рабочие и не рабочие дни. В таблице "А" демонстрируется зависимость употребления мясо к среднему показателю рабочего времени в дни приёма, следовательно влияние оного на трудоспособность. И картина представляется уже не столь однозначной. Курица с рыбой (chiken&fish) показывает тождественные результаты с бывшими лидерами. А если взглянуть на туже таблицу, но в дни с хорошем настроением (табл. "Б"), употребление говядины в пищу (beef) демонстрирует существенную пользу. В выходные дни (таблица "В") в рацион рекомендуется добавлять связку рыба+говядина (fish&beef) и свинина+курица+рыба (pork&chiken&fish).
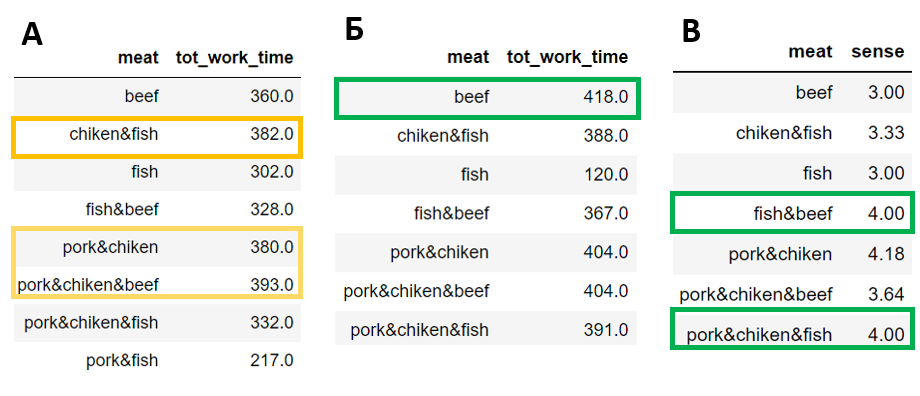
work_meat_notsense_df = work_meat_df.groupby(['meat'], as_index=False).agg({'tot_work_time': 'mean'}).round(0) work_meat_sense_df = work_meat_df.groupby(['sense', 'meat'], as_index=False).agg({'tot_work_time': 'mean'}).round(0) work_meat_sense_df = work_meat_sense_df.loc[work_meat_sense_df['sense'] > 3] work_meat_sense_df = work_meat_sense_df.groupby('meat', as_index=False).agg({'tot_work_time': 'mean'}).round(0) rest_meat_sense_df = sentiment_df[~sentiment_df.index.isin(work_meat_df.index)] rest_meat_sense_df = rest_meat_sense_df.groupby(['meat'], as_index=False).agg({'sense': 'mean'}).round(2)
Переходим к исследованию сектора просмотра контента.
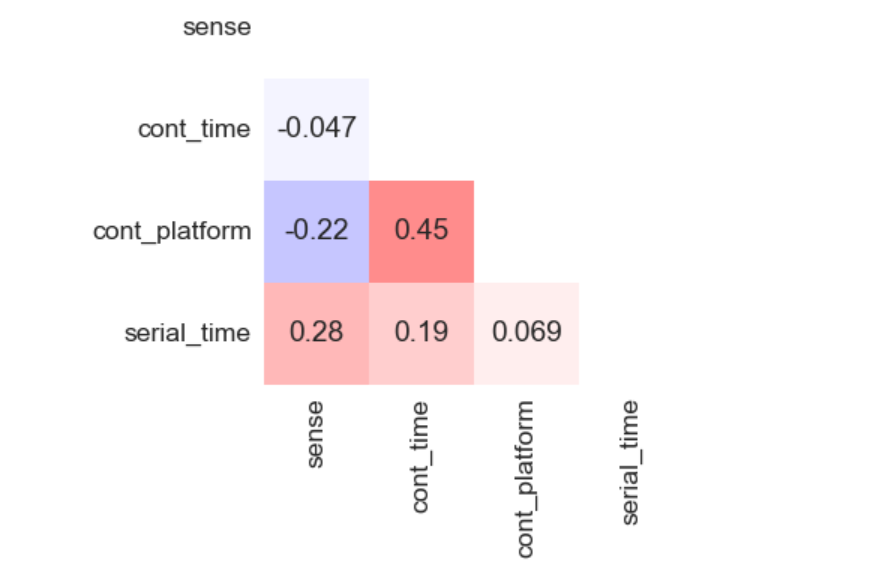
Явную связь демонстрируют признаки времени просмотра контента (cont_time) и площадки просмотра (cont_platform), что подталкивает к идее нахождения оптимальной связки в этом признаке.
Выведем таблицу с указанием максимального времени для площадок, с указанием настроения (табл. "А"). В хорошем настроение исследуемый объект чаще уделяет внимание инстаграму или всем площадкам вместе. Ваш покорный слуга предположил, что ситуация может существенно изменится в зависимости от рабочего графика ИО и не ошибся. В таблице "Б" указано тоже распределение в рабочие дни, а таблице "В" в выходные и праздничные.
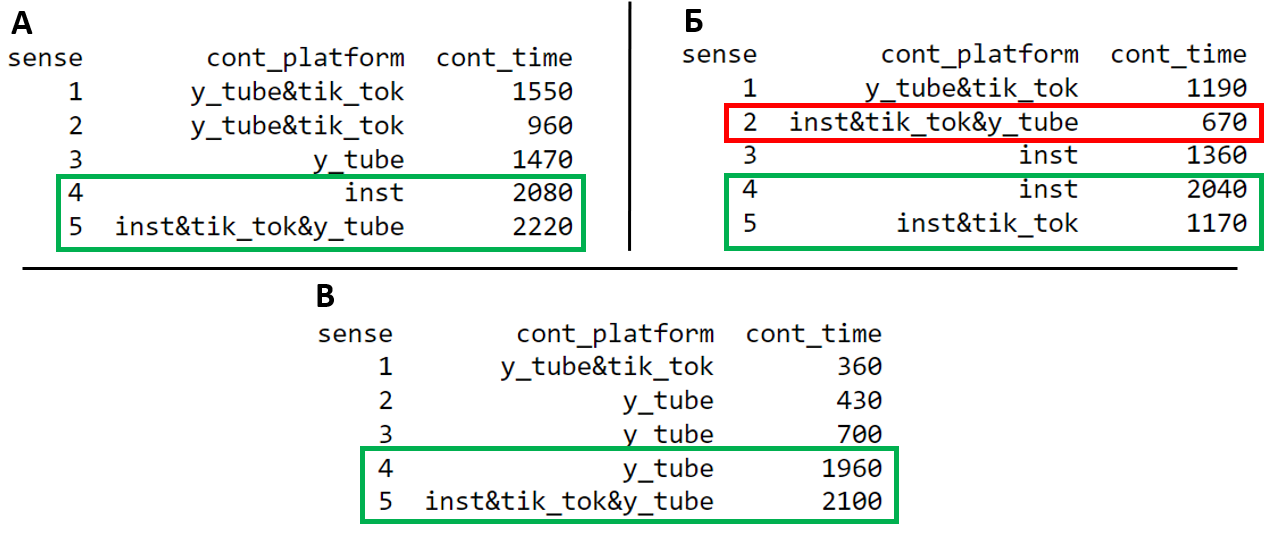
Исходя из предоставленного анализа, берусь заключить что в рабочие дни ИО следует забыть про ютуб (возможно из-за длины роликов длинные сюжеты негативно сказываются на концентрации) и уделить внимание инстаграму и возможно тик-ток. По выходным же дням преимущественно влияет на хорошее настроение просмотр ютуба, либо иных площадок.
Уместно будет определить оптимальное время просмотра контента и сериалов. В данном исследование, считаю, целесообразно отталкиваться от показателей времени работы и настроения в определённый день.
Следуя, графикам, представленным ниже (слева - контент, справа - сериалы), можно заключить, что по рабочим дням (при оптимальном времени работы - 7 часов и хорошем настроение) просматривать контент площадки следует не более часа, а наилучшее время для просмотра фильма или сериала варьируется в интервале 60-90 минут - один фильм или две серии :)

work_cont_df = work_day_cont_df.loc[work_day_cont_df['cont_time'] != 0] sns.set_style("white") sns.set_context("paper", font_scale=1.5) colors = ['#7FFFD4', '#6890F0', '#78C850','#F8D030', '#F08030'] best_cont_time = sns.displot(work_cont_df, x="cont_time", y='tot_work_time', hue="sense", kind="kde", fill=True, palette=colors); plt.title('Viewing time of the content\ndepending on working hours', fontsize=20) plt.xlabel('Viewing time, min', fontsize=16) plt.ylabel('Working time, min', fontsize=16) gr.legend(bbox_to_anchor= (1.2,1), fontsize='16');
А каким образом на интервалы сна может влиять просмотр сериалов накануне. Построим таблицу для дней с хорошим настроением.
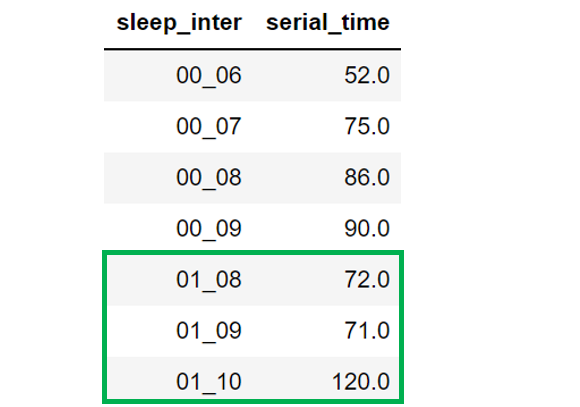
Всё же для лучших интервалов сна в рабочие дни (01:00-00:08 и 01:00-00:09) будет лучше ограничиться одной серией или коротким фильмом. В выходные дни (благоприятный интервал сна 01:00-00:10) возможно позволить себе больше. *Таблицу распечатать и наклеить на ноут бук.
sleep_inter = serial_work_df.sleep_inter.values.tolist() sleep_inter = sleep_inter[1:] sense = serial_work_df.sense.values.tolist() sense = sense[1:] serial_time = serial_work_df.serial_time.values.tolist() serial_time = serial_time[0:204] serial_df = pd.DataFrame({'sleep_inter': sleep_inter, 'serial_time': serial_time, 'sense': sense, serial_df = serial_df.loc[serial_df['serial_time'] != 0] serial_df = serial_df.loc[serial_df['sense'] > 3] serial_df = serial_df.groupby('sleep_inter', as_index=False).agg({'serial_time': 'mean'}).round(0)
Определённо значимый сектор спорта если не для целевой переменной настроения, то для физического состояния определённо.

Рассматривая тепловую карту, на фоне остальных выделяется фича кол-ва шагов в день (numb_steps). Тем не менее далее я представлю результат анализа не очевидных связей в этом секторе.
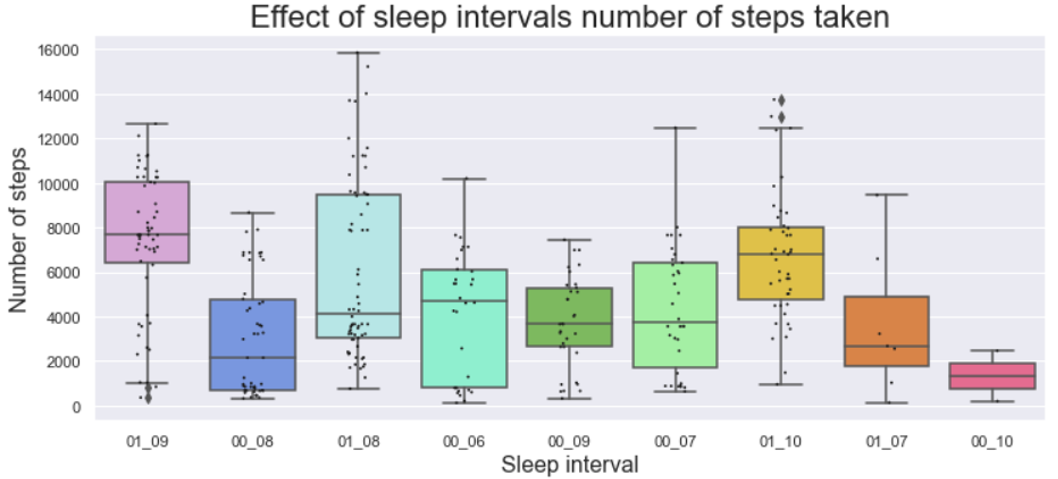
Сначала разберёмся с шагами. На боксе ниже довольно чётко выражена связь пройденных шагов с интервалами сна. Определённые ранее, оптимальные интервалы в среднем показывают большее кол-во пройденных шагов за день, которые в свою очередь неплохо коррелируют с настроением и физическим состоянием. Всё сходится, лучше спишь -> больше ходишь -> лучше общее состояние и настроение.
А какое оптимальное кол-во шагов нужно пройти за день исходя из интервала сна? Зная это, в теории :)) возможно повлиять на своё настроение! Ответ в таблице ниже...

** Таблицу распечатываем и крепим к входной двери квартиры (с внутренней стороны).
best_sleep_interval = sentiment_df.groupby(['sense', 'sleep_inter'], as_index=False).agg({'numb_steps': 'mean'}).round(0) best_sleep_interval = best_sleep_interval.loc[best_sleep_interval['sense'] == 5] best_sleep_interval = best_sleep_interval.drop('sense', axis=1)
Не менее интересную закономерность я вывел, построив таблицу зависимости кардио тренировки (cardio_time) с интервалами сна. Средние показатели тренировки максимальны перед благоприятными интервалами сна. Больше бегаешь -> лучше спишь. Выходит, для хорошего сна требуется пробежать не менее 50 минут...

По аналогии работы с фичёй кол-ва шагов, построим таблицу для кардио тренировки и узнаем сколько полезно бегать после определённого сна.
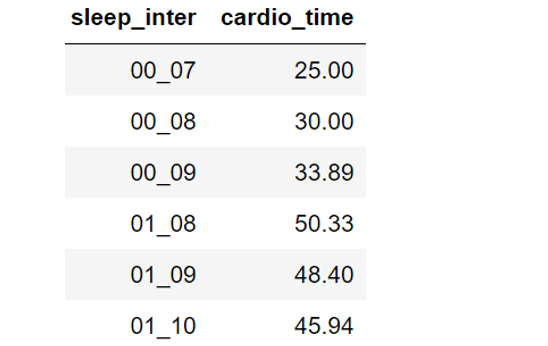
*** Таблицу распечатываем и кидаем в спортивную сумку
Растяжка в тренировочном процессе ИО длится всегда одинаковое количество времени - 45 минут. В связи с этим я решил, проанализировать сколько занятий растяжкой в неделю будут благоприятно сказываться на средних значениях статистически значимых для настроения признаков.

В приведённой ниже таблице, со значительным перевесом побеждает одна тренировка в неделю, хорошая новость для ИО :))
stretch_time_df = sentiment_df.drop(index=[0, 316, 317, 318]) df_stretch_for_week = pd.DataFrame() while stretch_time_df.shape[0] > 0: week_df = stretch_time_df[:7] stretch_time_df = stretch_time_df[7:] new_frame_dict = {'sense': week_df["sense"].mean(), 'phy_cond': week_df["phy_cond"].mean(), 'sleep_time': week_df["sleep_time"].mean(), 'numb_meals': week_df["numb_meals"].mean(), 'stretch_time': week_df["stretch_time"].sum()//45} temp_df = pd.DataFrame(new_frame_dict, index=[0]) df_stretch_for_week = pd.concat([df_stretch_for_week, temp_df], axis=0) df_stretch_for_week = df_stretch_for_week.groupby('stretch_time', as_index=False).agg( {'sense': 'mean', 'phy_cond': 'mean', 'sleep_time': 'mean', 'numb_meals': 'mean', }).round(2)
Наконец крайний по счёту, но не по важности сектор саморазвития исследуемого объекта. Основная задача в том, чтобы исходя из статистики определить, как и сколько правильней заниматься самообразованием. Принципиальный триггер для образования — это время, в частности время рабочего дня.
Ниже представлены графики корреляции времени, потраченного на образование, ко времени рабочего дня. Слева демонстрируется данные для самообразования, справа для организованного образования на курсах соответственно.
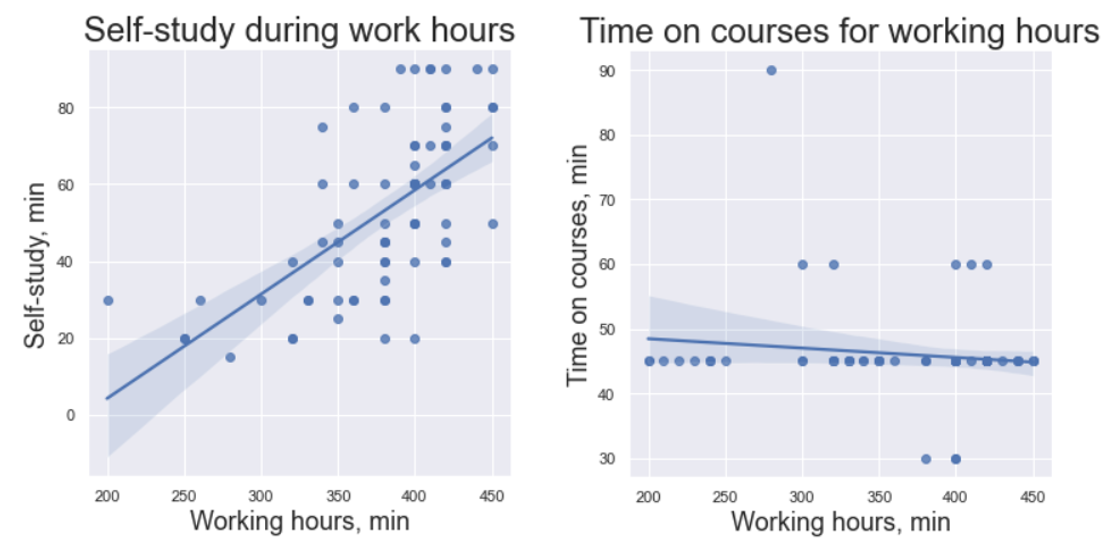
На реальных данных довольно редко можно увидеть такую прямую как на виде слева, но это случилось! Время, потраченное на самообразование близко к 1 коррелирует с рабочем временем. На тепловой карте подобного не наблюдалось, так как изымалась статистика по всем дням, включая выходные и праздники. Исходя из предположения, что возрастание времени работы положительно сказывается на настроение, можно смело заключить, что самообразование положительно влияет на настроение. Больше учишься -> лучше настроение...
И, напротив, динамика обучения на курсах совершенно не соотносится со временем работы (вид справа). Можно ли из данного исследования заключить, что обучение на курсах негативно влияет на настроение? Очень сомневаюсь…
По итогу вышеупомянутого исследования, считаю необходимым определить оптимальное время для обучения, так же опираясь на время работы и показатели настроения в эти дни. Ниже представлены графики для обоих видов обучения соответственно. Немногим более часа требуется уделять самообразованию в обоих случаях в рабочие дни.

Итог
В ходе анализа скромного объёма данных, я попытался найти наиболее благоприятные значения для каждого имеющегося признака. На момент написания статьи ИО проводит тестовый месяц, стараясь следовать моим рекомендациям :) и уже совсем скоро, во второй части статьи я напишу о достигнутых результатах.
Спасибо за внимание!

