Новаторская работа в области компьютерного зрения показала эффективность моделей с одним кодером, предварительно обученным классификации изображений, для захвата обобщённых визуальных представлений, эффективных в других задачах. Подробности рассказываем к старту флагманского курса по Data Science.
Часто ML-разработчики начинают проектирование моделей с помощью основной универсальной модели, которая обучается с масштабированием, а её возможности переносимы на широкий спектр последующих задач. При обработке естественного языка ряд основных популярных, «базовых» моделей, включая BERT, T5, GPT-3, предварительно обучаются на данных веб-масштаба и демонстрируют широкий потенциал многозадачности при обучении без попыток [zero-shot learning], обучении с несколькими попытками или в трансферном обучении. По сравнению с обучением излишне специализированных индивидуальных моделей предварительное обучение базовых моделей для большого количества задач может амортизировать затраты на обучение, позволить преодолеть ограничения ресурсов при построении крупномасштабных моделей.
Эта новаторская работа в области компьютерного зрения показала эффективность моделей с одним кодером, предварительно обученным классификации изображений, для захвата обобщённых визуальных представлений, которые эффективны для других последующих задач. Совсем недавно изучены подходы контрастного двойного кодирования (CLIP, ALIGN, Florence) и генеративного кодера-декодера (SimVLM), обученные с использованием зашумлённых пар изображение-текст в масштабе веба.
Модели с двойным кодером демонстрируют замечательные возможности классификации изображений без попыток, но не столь эффективны в визуальном и языковом распознаваниях. С другой стороны, методы кодер-декодер хороши для подписей к изображениям и визуальных ответов на вопросы, но не могут выполнять такие задачи как поиск.
В статье «CoCa: Contrastive Captioners are Image-Text Foundation Models» мы представляем унифицированную модель компьютерного зрения под названием Contrastive Captioner (CoCa). Наша модель — это новый кодер-декодер, который одновременно генерирует выровненные одномодальные изображения, текстовые вложения и объединённые мультимодальные объекты, что делает модель достаточно гибкой для непосредственного применения при решении всех типов последующих задач.
В частности, CoCa достигает самых передовых результатов в решении ряда визуальных и визуально-языковых задач, охватывающих визуальное распознавание, кросс-модальное выравнивание и мультимодальное распознавание. Кроме того, эта модель обучается на очень общих представлениях, поэтому может работать не хуже, чем полностью настроенные модели, обученные без попыток, или кодерами с фиксированными весами.
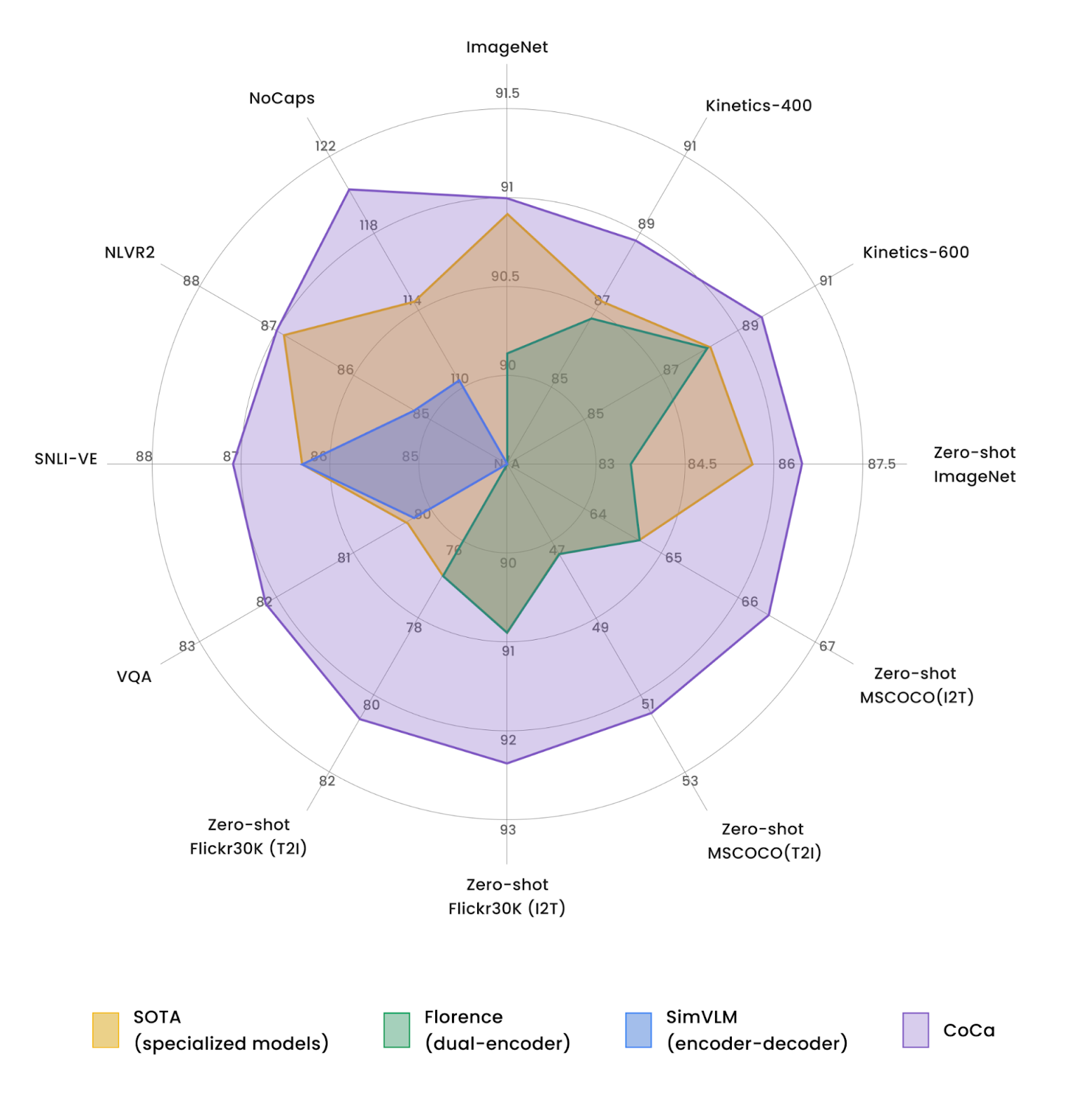
 |
|---|
Обзор Contrastive Captioners (CoCa) по сравнению с моделями с одним кодером, с двумя кодерами и моделями кодер-декодер. |
Метод
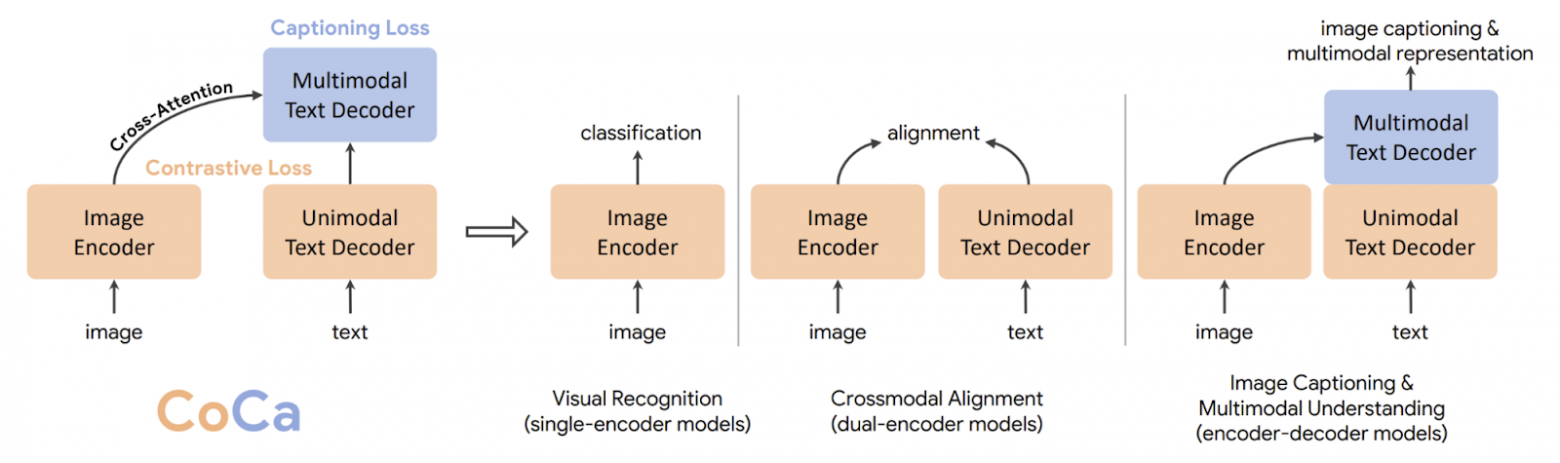
Мы предлагаем CoCa, унифицированную ML-модель, которая сочетает потери контраста и потери подписей к изображениям в одном потоке обучающих данных, состоящем из аннотаций изображений и зашумлённых пар изображение-текст, эффективно объединяя парадигмы одиночного кодера, двойного кодера и кодера-декодера.
С этой целью мы представляем новую архитектуру кодер-декодер, в которой кодер представляет собой визуальный трансформер (ViT), а трансформер декодера текста разделён на две части — это декодер одномодального текста и декодер мультимодального текста.
Мы пропускаем перекрёстное внимание в слоях одномодального декодера, чтобы кодировать текстовые представления для контрастной потери, и каскадируем слои мультимодального декодера с перекрёстным вниманием к выходным данным кодера изображений, чтобы изучить мультимодальные объекты изображение-текст для потери подписей к изображениям.
Такой дизайн максимально увеличивает гибкость и универсальность модели для решения широкого спектра задач, и в то же время её можно эффективно обучать с помощью одного прямого и обратного распространения для обеих целей обучения, что сводит затраты на вычисления к минимуму. Таким образом, модель может быть обучена от начала до конца с нуля с затратами на обучение, сравнимыми с простой моделью кодер-декодер.
 |
|---|
Иллюстрация прямого распространения, используемого CoCa для потерь контраста и потерь подписей к изображениям. |
Сравнительные результаты
Модель CoCa можно непосредственно настроить для многих задач с минимальной адаптацией. Таким образом, наша модель достигает ряда самых современных результатов в популярных визуальных и мультимодальных базах данных, включая:
визуальное распознавание: ImageNet, Kinetics-400/600/700 и MiT;
мультимодальное распознавание: VQA, SNLI-VE, NLVR2 и NoCaps.
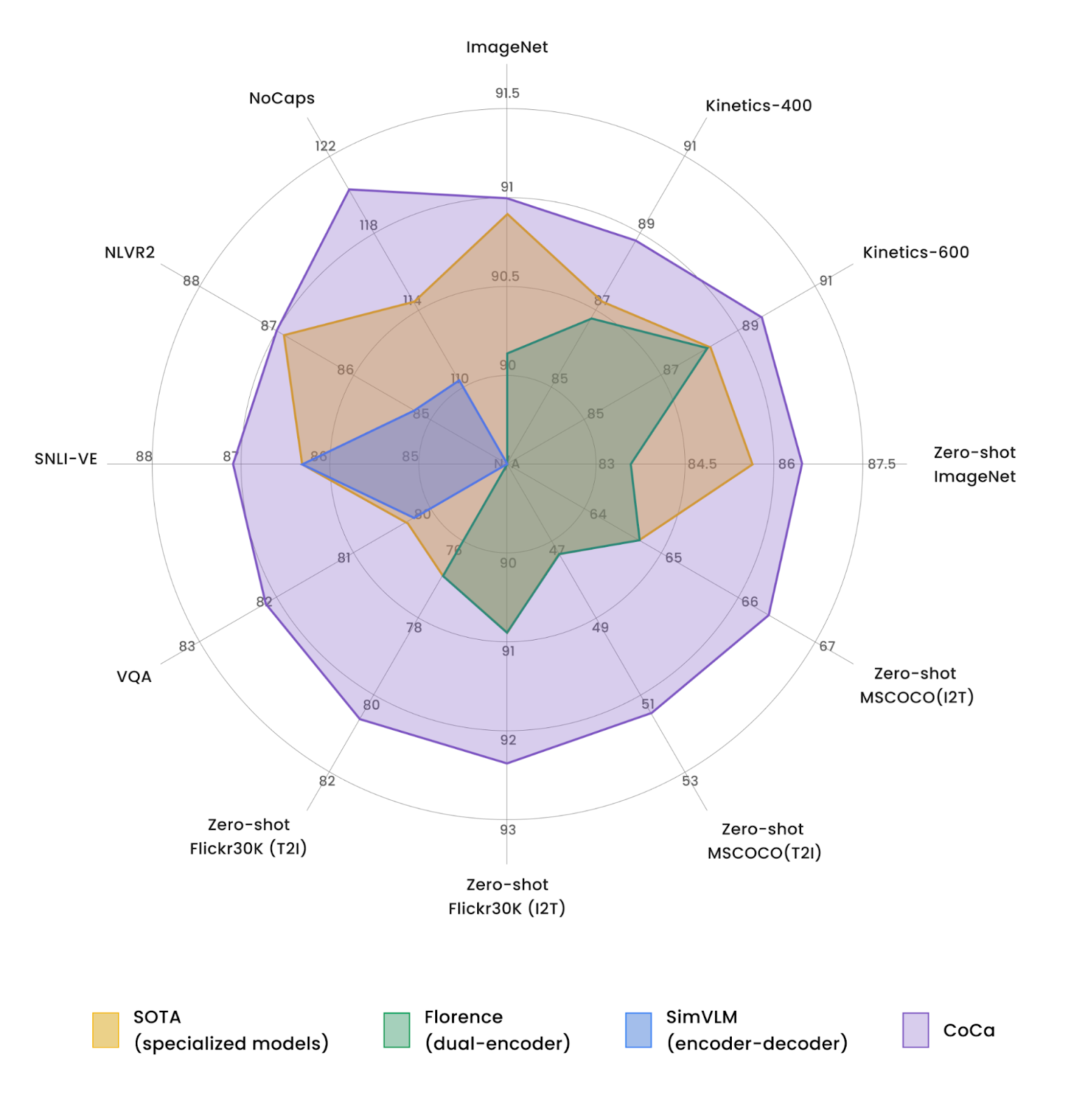 |
|---|
Сравнение CoCa с другими основными моделями изображение-текст (без настройки под конкретные задачи) и несколькими современными специализированными моделями, настроенными под конкретные задачи. |
Примечательно, что CoCa достигает этих результатов как единая модель, адаптированная под все задачи, и при этом часто более лёгкая, чем предыдущие высокопроизводительные специализированные модели. Например, CoCa даёт 91,0% предсказательной точности ImageNet используя менее половины параметров предшествующих современных моделей. Кроме того, CoCa обладает мощными генеративными возможностями для создания высококачественных подписей к изображениям.
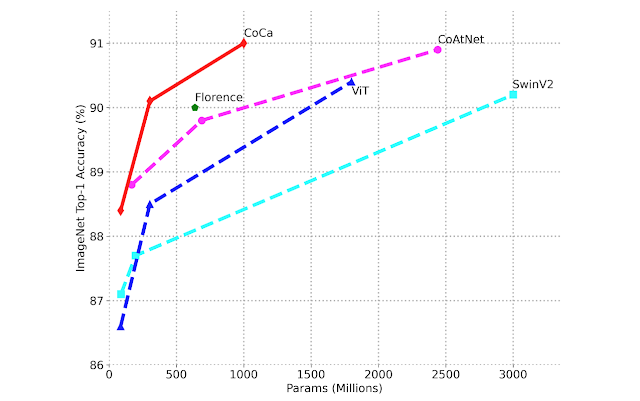 |
|---|
Сравнение производительности масштабирования системы классификации изображений с тонко настроенной предсказательной точностью ImageNet с размером модели. |
 |
|---|
Текстовые подписи, сгенерированные CoCa на изображениях NoCaps |
Безупречная производительность
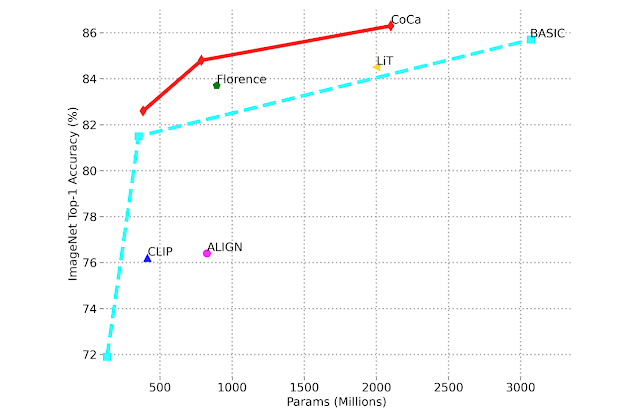
Помимо достижения отличной производительности благодаря точной настройке, CoCa превосходит предшествующие современные модели в задачах обучения без попыток, включая классификацию изображений и кросс-модальный поиск. CoCa обеспечивает точность обученной без попыток модели 86,3% на ImageNet, а также значительно превосходит предшествующие модели в сложных вариантах тестов, таких как ImageNet-A, ImageNet-R, ImageNet-V2 и ImageNet-Sketch. Как показано на рисунке ниже, CoCa обеспечивает лучшую точность нулевого сигнала при меньшей размерности модели по сравнению с предыдущими методами.
 |
|---|
Сравнение производительности масштабирования системы классификации изображений с отлаженной предсказательной точностью нулевого выстрела ImageNet с размером модели. |
Представление кодера c фиксированными весами
Особенно интересное наблюдение заключается в том, что CoCa достигает результатов, сравнимых с лучшими отлаженными моделями, используя только визуальный кодер с фиксированными весами, в котором признаки, извлечённые после обучения модели, используются для обучения классификатора, а не для трудоёмкой точной настройки модели.
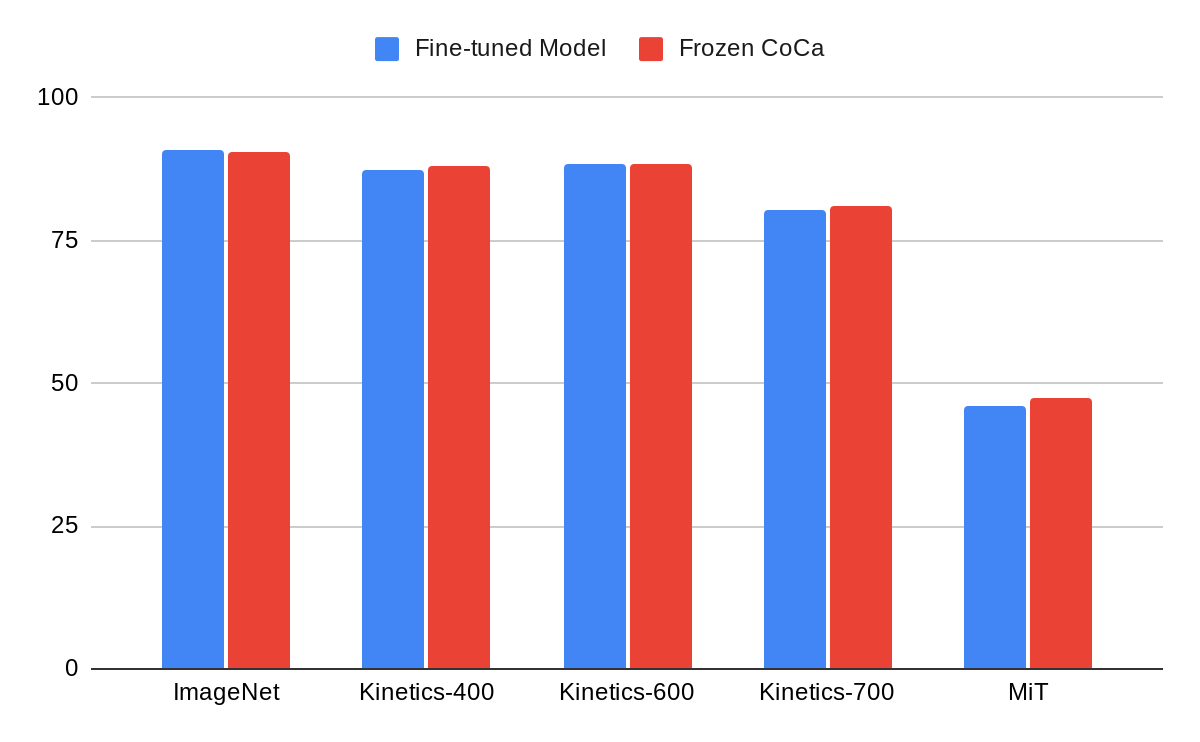
В ImageNet кодер с фиксированными весами CoCa с обученной головой внимания к классификации даёт 90,6% предсказательной точности, что лучше, чем производительность полностью отлаженных базовых моделей (90,1%).
Мы также считаем, что эта модель очень хорошо работает с распознаванием видео. Мы загружаем образцы видеокадров в кодер изображений CoCa с фиксированными весами по отдельности и объединяем выходные признаки путём пулинга внимания перед применением обученного классификатора.
Этот простой подход с использованием кодера изображений с фиксированными весами CoCa обеспечивает 88-процентную предсказательную точность распознавания действий на видео из набора данных Kinetics-400 и демонстрирует, что CoCa изучает очень общее визуальное представление с комбинированными целями обучения.
 |
|---|
Сравнение визуального кодера c фиксированными весами CoCa с (несколькими) наиболее эффективными тонко настроенными ML-моделями. |
Заключение
Мы представляем Contrastive Captioner (CoCa), новую парадигму предварительного обучения для базовых моделей изображение-текст. Этот простой метод широко применим ко многим типам визуальных и языковых задач, и позволяет получить современную производительность с минимальной адаптацией к конкретной задаче или даже без неё.
А пока совершенствуются модели, мы поможем вам прокачать навыки или с самого начала освоить профессию, актуальную в любое время.
Выбрать другую востребованную профессию.


