
Привет, Хабр! Буквально недавно стали известны итоги открытого соревнования по машинному обучению Data Fusion Contest 2022. Это уже второе соревнование, причём более масштабное, чем первое. В конкурсе с общим призовым фондом 2 млн рублей приняли участие более тысячи человек. Участники соревновались не один и не два дня, битва умов продолжалась целых 3,5 месяца. За это время организаторы получили 6,5 тыс. решений.
Что нужно было делать участникам? Если кратко, то главная задача была такой: при помощи машинного обучения решить проблему сопоставления из двух совершенно разных массивов данных. Требовалось сопоставить данные клиентов из датасета с транзакциями клиентов ВТБ по банковским картам и данные кликстрима (информация о посещении web-страниц) клиентов Ростелекома. Нужно было установить соответствие между клиентами двух организаций. Оно устанавливалось, если два клиента из датасетов – один и тот же человек. Конечно же, данные были деперсонализированы, сохранялась лишь весьма ограниченная информация о самом поведении пользователей. Сопоставлять всё это обучали искусственный интеллект. Подробности – под катом. А ещё там будет ссылка на исходники крутой библиотеки для ИИ, которую использовали победители конкурса. Поехали!

Зачем всё это?
Технологии Data Fusion и алгоритмы слияния данных становятся всё более востребованными в арсенале специалистов по анализу данных. Благодаря этим технологиям, с одной стороны, появляется возможность оперативно решать задачи бизнеса, с другой – удаётся сохранять высокий уровень безопасности клиентских данных, не выводя их за пределы компании.
Сложности с получением очищенных, деперсонализированных и размеченных данных, по мнению аналитиков Сбера, – один из главных барьеров для дальнейшего развития искусственного интеллекта. Это проблема, которая стоит на пути создания новых продуктов и сервисов, дающих возможность решать важнейшие научные и социально значимые задачи. Свободный доступ к инструментам, которые позволяют готовить такие данные, – важное условие для преодоления барьера, которое ускорит разработку и внедрение систем искусственного интеллекта, что простимулирует конкуренцию и даст толчок экономическому развитию.
Сбер создал и опубликовал в открытом доступе программную библиотеку PyTorch-LifeStream, содержащую несколько алгоритмов построения эмбеддингов событийных данных.
Эмбеддинг (Embedding) – преобразования сложноструктурированных данных, например слов, текстов, атрибутов событий, событий и их последовательностей, в машинно-читаемый набор чисел – числовой вектор.
Событийные данные – разные последовательности. Это истории посещений сайтов, банковских транзакций, истории мобильных звонков, истории покупок, событий в онлайн-играх и т. п. Сгенерированный на основе алгоритмов библиотеки эмбеддинг такой последовательности не содержит каких-либо персональных данных.
В библиотеке реализован уникальный алгоритм применения нейросетевого контрастного обучения к событийным данным, созданный и запатентованный в Лаборатории по искусственному интеллекту Сбера.
Про задачу
Самой популярной из трёх задач соревнования стала главная – Matching. Всего было представлено более 3 тысяч вариантов её решения от 84 команд. От участников требовалось сделать решение, которое устанавливало бы соответствие между клиентами крупного банка и интернет-провайдера, о чём говорилось выше. В качестве ответа для каждого клиента банка нужно было предоставить 100 наиболее вероятных клиентов провайдера. Оценка велась для ранжирования – то есть чем ближе правильный ответ был к началу списка, тем выше оценка.
Решения, предложенные участниками, оценивались и ранжировались автоматически. Победителей номинаций выбирали члены жюри – организаторы соревнования и приглашённые эксперты. Принять участие в Data Fusion Contest 2022 могли все желающие, если им исполнилось 17 лет.
Команда Сбера Sberbank AI Lab пришла на соревнование, имея обширный опыт работы с событийными данными. Участники – учёные из Лаборатории по искусственному интеллекту Сбера. Стоит отметить, что и для них всё было непросто – конкурсная задача матчинга позволила удачно применить разработанный в Лаборатории ИИ метод генерации эмбеддингов транзакционных данных одновременно для двух разных доменов событийных данных (транзакции и кликстрим – атрибуты посещения веб-страниц).
Предложенное решение оценивалось автоматически по метрике оценки качества, так что команда Сбера заняла первое место и получила главный приз в полмиллиона рублей. В команду вошли управляющий директор по исследованию данных Лаборатории ИИ СберБанка Дмитрий Бабаев и руководители направления по исследованию данных Лаборатории ИИ Иван Киреев и Никита Овсов. Победители создали лучшее решение благодаря применению собственной библиотеки PyTorch-LifeStream, которая позволила ускорить разработку решения, так как содержит много готовых инструментов для работы с событийными данными, и дала возможность стать фаворитом престижного конкурса.
Про данные
Всего в датасете было 15,4 млн транзакций для 17581 уникального клиента банка и 94,8 млн событий кликстрима для 14671 уникального клиента провайдера. Примерно 16,6% клиентов банка были без матчинга. Кроме того, организаторы предоставили неразмеченные данные в виде датасета из 4952 клиентов банка с 4,4 млн транзакций и столько же клиентов интернет-провайдера с 32 млн кликов. Вот как выглядели сами данные. Сопоставленные пары идентификаторов клиентов в банке и у провайдера:

Банковские транзакции:
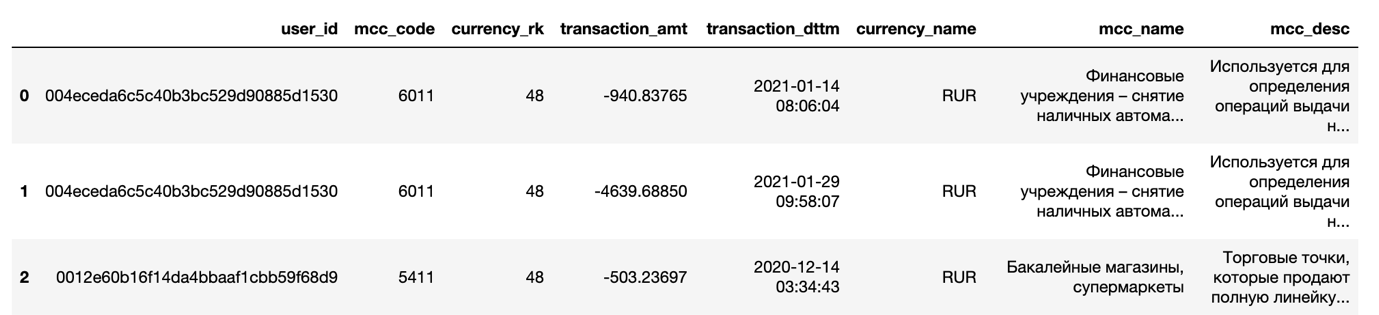
ID клиента, mcc-код и два поля с его текстовым описанием, код валюты с расшифровкой, сумма транзакции и время транзакции.
Кликстрим – данные о веб-сёрфинге:

Кроме ID клиента была указана категория страницы и три уровня иерархии с уменьшением детализации, время клика и идентификатор устройства, с которого посещалась страница.
Базовое решение
Организаторы соревнования предложили baseline, в котором в качестве фичей считались простые статистики (sum, mean, count) по сумме транзакции или количеству кликов в разрезе каждого mcc-кода или категории. Фичи для транзакций и кликов объединялись и подавались в алгоритм бустинга. Алгоритм обучался как задача бинарной классификации. Правильным ответом была 1, если транзакции и кликстрим соответствуют одному человеку (есть мэтч). Ну и 0 получался, если клиенты были разными людьми. Для каждого клиента банка был доступен один правильный клиент интернет-провайдера (соответствие из разметки) и несколько случайно выбранных из всей выборки неправильных примеров. На public leaderboard базовое решение получило оценку качества R1 = 0.2217.
Первоначально у команды Сбера получилось улучшить бейзлайн до R1 = 0.2757, но основные усилия команде хотелось приложить именно к решению задачи с помощью нейронных сетей. В качестве примера подхода, основанного на генерации признаков для бустинга, доступен код решения, занявшего второе место в задаче Matching.
Модель Sberbank AI Lab
Команда решила использовать схему обучения, похожую на сиамскую сеть. Она кодирует входную последовательность транзакций или кликстрим в вектор. Вероятность матчинга объектов определяется расстоянием между их векторами. Такая схема часто применяется для установления соответствия между данными из разных доменов, например картинок и подписей к ним. Участники предложили гипотезу, что этот подход сработает и для событийных данных разных типов. Вот схема обучения:

Сеть включает два этапа:
TrxEncoder, который преобразует каждую отдельную транзакцию или клик в векторное представление.
SequenceEncoder, который сжимает последовательность векторов из TrxEncoder в один конечный вектор.
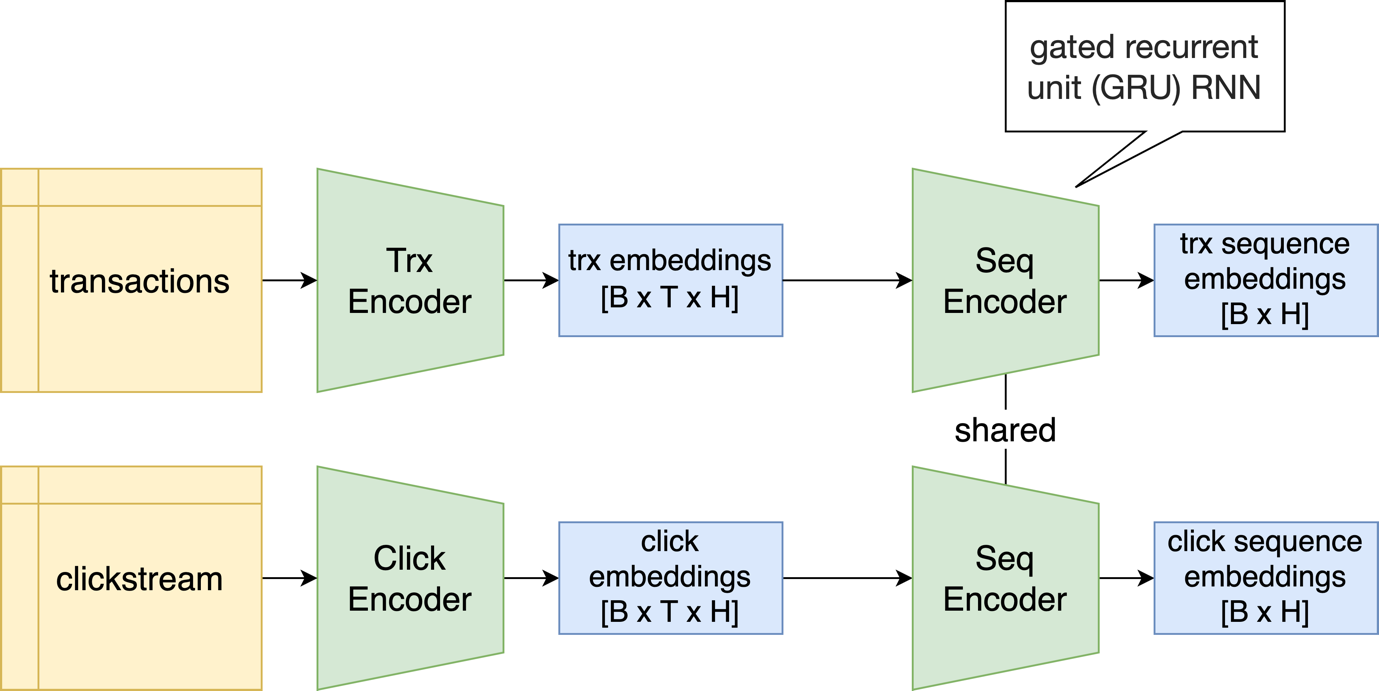
В качестве кодировщика транзакций был взят готовый слой из библиотеки TrxEncoder. Его работа показана на схеме:

Обучающий батч содержит 128 пар пользователей банк-провайдер. Это короткие последовательности событий - по две выборки на основе транзакций в банке и по две выборки на основе его истории посещений сайтов. Таким образом, есть 256 образцов последовательностей транзакций для 128 пользователей банка и 256 образцов последовательностей кликов для 128 пользователей провайдера. Затем создаётся матрица 256*256 с попарными расстояниями L2 и матрица с совпадением-несовпадением меток. Метки использованы для выборки положительных и отрицательных образцов для функции потерь Softmax Loss.
SequenceEncoder – рекурентно-нейронная сеть (RNN), совместно используемая для транзакций и кликов. Веса инициализируются случайным образом. TrxEncoder представляет собой конкатенацию обучаемых векторов (эмбеддингов) категориальных признаков и нормализованных числовых значений.
Команду вдохновила архитектура BERT для предварительной подготовки. Поэтому использована схема TrxEncoder + TransformerEncoder и задача MLM (Masked Language Model). TransformerEncoder предсказывает маскированные векторы TrxEncoder. TrxEncoder обучается транзакциями, а затем отдельный TrxEncoder обучается на данных кликов.
Аугментации
На всех этапах обучения сети использовались аугментации.
Первый способ аугментации устранял повторы в последовательностях. Повторяющиеся mcc или категории выбрасывались, а исходное количество транзакций записывалось в отдельные поля как отдельный признак. Это позволило сократить длины последовательностей, особенно для кликстрима, где встречались очень длинные цепочки повторяющихся категорий.
При втором способе аугментации вырезалась часть из всей последовательности. Длина и место начала семпла выбирались случайно. Параметры семплирования были заданы так, что в обучение попадали как очень короткие последовательности (порядка 64 событий), так и очень длинные (до 2000 событий, примерно половина всей последовательности). На коротких последовательностях сеть быстрее учится. На длинных – получает больше информации.
Ансамблирование
В финальном варианте решения команда добавила использование ансамбля сетей. Несколько сетей обучались с разными random seeds. Каждая сеть выдавала матрицу попарных расстояний, а эти матрицы усреднялись по всем сетям ансамбля. В итоге это дало самый большой прирост качества: для ансамбля из пяти моделей метрика качества R1 выросла с 0.2819 до 0.2949. Вот график зависимости качества от количества сетей в ансамбле:
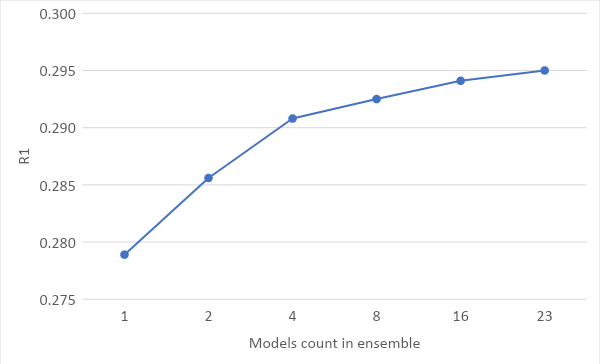
В финальном решении удалось уместить 11 сетей, вычисление ответа для которых выполнялось почти за час. Можно было ускорить инференс и взять больше моделей в ансамбль, если бы команда вовремя заметила, что GPU в контейнер не подключилось. Позже были проведены точные замеры на локальной машине, оказалось, что с GPU инференс с пятью моделями в ансамбле работает 2 минуты, из них полторы – это предобработка данных.
Итоговое решение команды Сбера доступно на GitHub.
Что же, на этом всё. Если вам интересны подробности решения либо есть другие вопросы – пишите в комментариях, а мы обязательно ответим.
