
Всем привет.
Мы завершаем цикл статей о том, как BI-платформа «Форсайт» работает с данными в связке «BI+Data Lake». В этом посте мы поговорим про правильные и уместные применения кэша при работе платформы. Расскажем, чем отличается адаптивный in-memory кэш и внутренний файловый MOLAP-сервер в платформе «Форсайт». Поясним, как работает персональный и кросс-сессионный кэш. Определим рекомендации, в каких случаях можно и нужно использовать in-memory в BI-платформе. Также мы будем вам благодарны, если в конце статьи вы проголосуете и укажете, был ли вам полезен подобный цикл статей. Добро пожаловать под кат.
Данная статья является заключением цикла статей про связку «BI+Data Lake». Предыдущие части:
1. Что и как можно кэшировать в BI?
Кэш – достаточно полезная вещь. В случае с высоконагруженными системами он хорошо помогает повысить производительность. Иногда в десятки или даже сотни раз. С другой стороны, при сложной ролевой модели, постоянном редактировании исходных данных/метаданных или одновременной многопользовательской работе кэш воспринимается как страшное зло. Это реально наболело в нашей собственной практике. Вроде все поменял, сохранил, обновил. Но BI-платформа упорно показывает старую версию отчёта, измерения, данные, логику скрипта и т.п. И причина этого – устаревший и/или не обновленный кэш.
1.1. Disclaimer – кэш есть не только у BI
Вопрос кэширования достаточно сложный. В общем случае управление им выходит далеко за рамки возможностей только самой BI-платформы «Форсайт». Еще есть кэш браузера, кэш СУБД, кэш ОС. Всё это напрямую влияет на скорость работы финального ИТ-решения, но сама BI-платформа не может на это технически повлиять. Тут помогают только организационные знания, что и как нужно делать в разных ситуациях, чтобы достичь хорошего результата. Мы, как вендор, систематизируем эту информацию и всегда стараемся делиться ею с нашими заказчиками и сообществом партнёров.
В этой статье нам хотелось бы сфокусироваться только на возможностях кэширования нашей BI-платформы. Другое смежное ПО затрагивать не будем. Всю информацию мы структурировали в виде карты кэширования. Она рассматривается в контексте двух направлений: что можно кэшировать и как можно кэшировать.
1.2. Что кэшировать в BI?
В платформе «Форсайт» можно кэшировать:
структуру справочников и измерений;
данные многомерных кубов и «плоских» таблиц БД;
структуру метаданных (настройки отчетов, дэшбордов, бизнес-процессов, расчетчиков и многое другое);
исполняемые прикладные программные коды интерпретатора платформы (машинный байт-код);
состояние и настройки активных веб-сессий для каждого пользователя (для восстановления в случае обрыва соединения).
1.3. Как кэшировать в BI?
Первый вариант – ничего не кэшировать вообще. Иногда это вполне оправданно и эффективно. Например, когда BI-платформа работает в связке с другими системами. И это не обязательно сценарий с потоковыми данными. Информация или статус активности может меняться достаточно редко. Только если это происходит нерегулярно, но оперативная реакция на эти изменения крайне важна, то кэш не применим в таких ситуациях.
Второй вариант – для каждой сессии пользователя свой собственный персональный кэш. Такой подход хорошо помогает, когда в рамках одного сеанса с BI-платформой пользователь много раз обращается к одним и тем же данным или метаданным. Например, если справочник территорий используется во всех кубах, то после первого обращения логично «держать» его в оперативной памяти BI-сервера и больше не генерировать sql-запросов к БД. При этом персональный кэш поддерживает ролевую модель и другую специфичную бизнес-логику каждого отдельного пользователя. Например, справочник филиалов компании (каждый пользователь может видеть свой состав элементов в этом измерении). Но за такой «индивидуальный подход» приходится платить повышенным расходом оперативной памяти. Причем прямо пропорционально количеству активных сессий у BI-сервера.
Третий вариант – общий для всех пользователей кросс-сессионный кэш. Такой кэш обычно «прогревается» сразу после рестарта BI («холодный» старт) и затем переиспользуется сразу всеми пользователями одновременно. Этот вариант хорошо подходит для чтения данных. Но только когда не требуется сложной ролевой модели, которая разграничивает доступ пользователей к отдельным фрагментам данных. Режим записи данных (write-back) для кросс-сессионного кэша в платформе «Форсайт» тоже возможен (подробно рассмотрим его в разделе 3.5). На рисунке ниже представлена схема функционирования разных режимов кэширования данных для многомерных кубов.

1.4. Карта кэширования в платформе «Форсайт»
В итоге, вот такая карта кэширования у нас получилась (см. рисунок ниже). На пересечении двух осей (что и как) указан текущий статус функциональности нашей платформы.
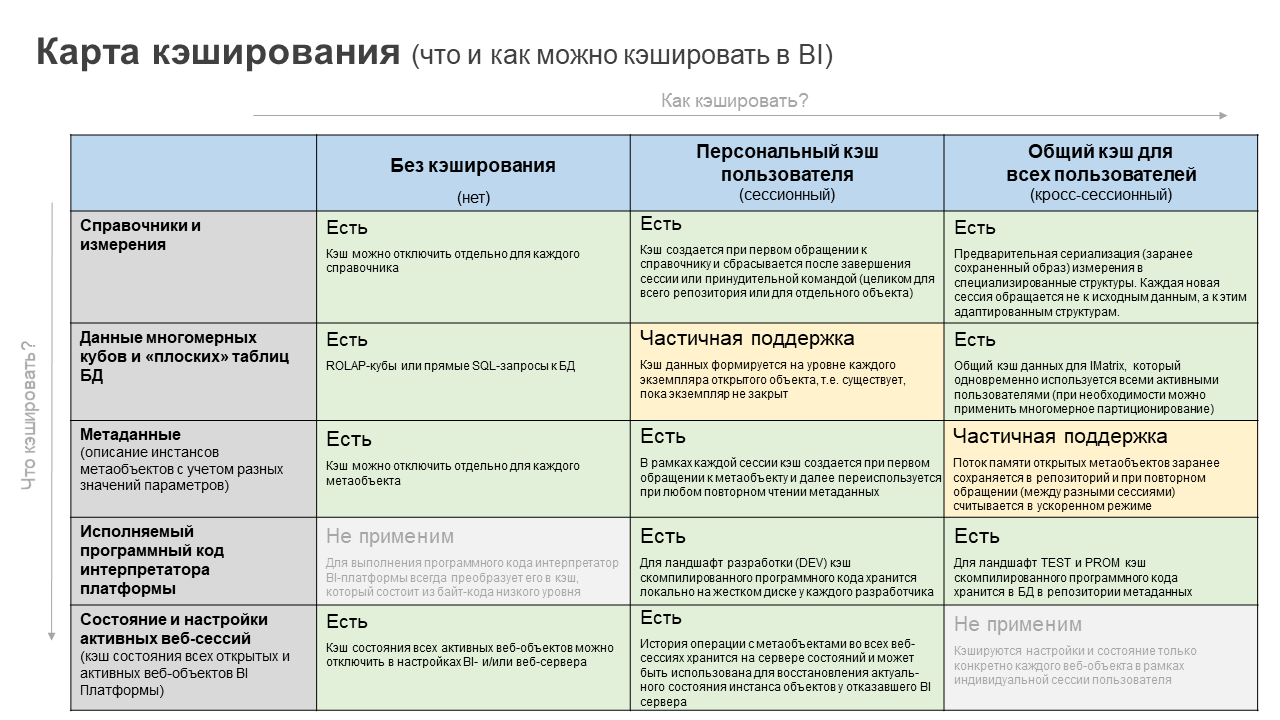
Давайте рассмотрим каждый блок более подробно.
2. Кэширование справочников
По умолчанию для всех справочников включен режим персонального кэша. При необходимости для отдельных справочников кэширование можно отключить. Но чем больше и «сложнее» справочник (количество в нем элементов, атрибутов, связей с другими справочниками и т.п.), тем медленнее без кэша будет работать BI-платформа и серьезно возрастет нагрузка на СУБД. В таблице ниже представлено сравнение времени открытия «условного» измерения с кэшем и без него.

Кросс-сессионный кэш считывает информацию из заранее экспортированных структур данных. Поэтому скорость его открытия самая быстрая. Персональный кэш справочника в каждой сессии BI считывает информацию из исходных структур данных и затем фиксирует результат в оперативной памяти. В связи с этим время первичного обращения увеличивается. Все эти особенности можно увидеть в таблице.
3. Кэш для OLAP-кубов
Кэширование данных, пожалуй, самая сложная и затратная (с точки зрения аппаратных ресурсов сервера) операция. К ней нужно подходить крайне рационально. Совершенно бессмысленно «загонять» в оперативную память терабайты «холодных» или даже «теплых» данных. Это будет дорого, а в какой-то момент и технически неоправданно (т.к. для кэша тоже действует общее правило «чем больше объем, тем медленнее работает»).
3.1. Как BI «Форсайт» взаимодействует с реляционной и многомерной БД
В платформе «Форсайт» процесс получения («добычи») аналитической информации из источников данных проходит несколько уровней абстракции. Эти уровни чем-то похожи на матрёшку. Каждый последующий использует результаты предыдущего и добавляет к данным новые функции, свойства, признаки.
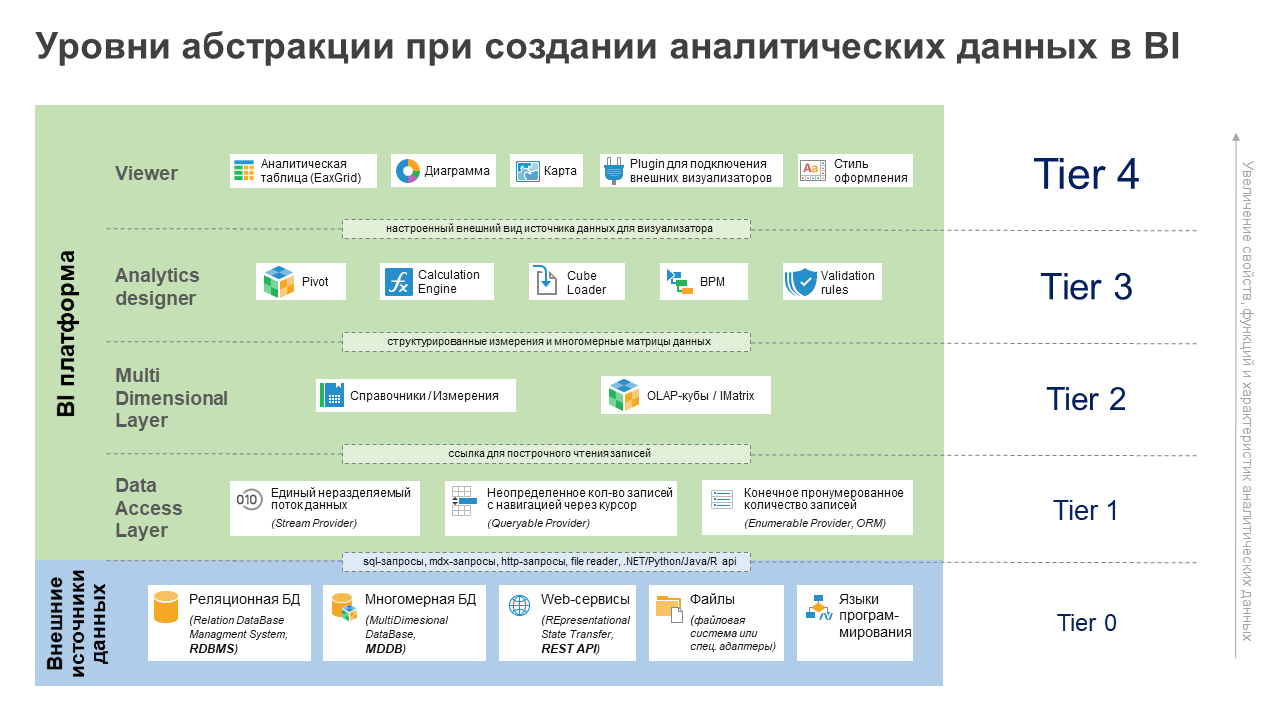
На нулевом уровне (Tier 0) все данные хранятся во внешних источниках. Это могут быть реляционные СУБД, многомерные базы данных, веб-сервисы, файлы, языки программирования и др. С помощью различных универсальных или нативных драйверов платформа подключается к этим источникам и запросами получает плоские данные (sql, mdx, http и другие виды запросов или прямое обращение через API). При необходимости запросы могут выполняться с разными условиями фильтрации.
Как только такие плоские данные поступили в BI – это уже первый уровень абстракции (Tier 1). Здесь происходит конвертация типов данных. Важно понимать, что у разных внешних источников они могут быть различными. Например, в ClickHouse для целого числа есть 6 разных типов (int8, int16 и т.д.), а в PostgreSQL их всего 3 (smallint, integer и bigint). Или другой пример: финансовый тип currency поддерживают далеко не все потенциальные источники данных. И таких примеров достаточно много. При работе с BI-платформой, которая поддерживает гетерогенные источники данных, нам важно и нужно приводить все эти типы данных к «общему знаменателю». А именно к тем типам данных, которые встроены в платформу «Форсайт». Эту задачу решает Data Access Layer в Tier 1.
Три типа провайдеров для чтения «плоских» данных
Доступ к данным на первом уровне абстракции (Tier 1) возможен по одному из трех режимов:
Единый поток данных (stream provider). Например, это файл. Доступ к данным платформа получает целиком в виде потока или текстовой переменной. У этого провайдера каждый раз может быть своя уникальная структура, а количество строк и атрибутов (колонок) заранее неизвестны. Используется для чтения неструктурированных файлов или потоков памяти, а также веб-сервисов.
Курсор для построчного чтения данных из результата запроса (queryable provider). Обычно это реляционные (sql) или многомерные (mdx) запросы, а также структурированные «плоские» файлы. Для этого класса провайдера заранее известны атрибуты (колонки), а количество записей (строк в таблице) – нет. Оно определяется в процессе чтения данных с помощью навигации по курсору (вперед, назад, первый или последний элемент).
Заранее пронумерованный список с доступом к любой записи (enumerable provider/ORM). Этот провайдер обычно используется при информационном взаимодействии платформы с языками программирования (R, Python, Java, .Net) через разные типы переменных. Данные могут быть как сконвертированы к нужному типу из платформы, так и обратно из стороннего языка программирования. При обработке массивов или коллекций все их элементы заранее известны. И к каждому из элементов есть доступ, в том числе с разделением на значения отдельных свойств или полей.
Далее линейные и плоские dataSet начинают структурироваться в упорядоченные/иерархические измерения (Dimensions) или в наборы многомерных данных кубов (IMatrix). Это уже второй уровень абстракции (Tier 2). Он работает в многомерной парадигме. Именно здесь возникает гетерогенность данных, когда для OLAP-кубов в оперативной памяти совмещается информация из «плоских» источников разного происхождения.
На третьем уровне абстракции (Tier 3) многомерные данные начинают «обогащаться» аналитическими функциями BI-инструментов. Например, в Pivot определяется расположение измерений для размещения crosstable. В многомерных расчетах появляются формулы и т.п. Все эти сведения добавляются к данным. И мы уже видим не просто плоские таблицы или многомерные матрицы, а аналитически осмысленные информационные представления.
На последнем, четвертом уровне (Tier 4) к аналитике добавляются свойства визуального отображения: разметка листа, оформление, размеры и т.п.
Зачем мы вам все это рассказываем? Давайте вернемся к вопросу кэширования данных. И постараемся найти ответ на вопрос, куда же тут правильно вставить кэш? Самое оптимальное – на Tier 2. Связано это с тем, что переход информации от Tier 0 до Tier 2 занимает больше всего времени.
Во-первых, на Tier 0 приходит запрос с разными условиями фильтрации. Чем сложнее фильтры и объемнее общее количество записей во внешнем источнике, тем дольше будет обрабатываться такой запрос.
Во-вторых, на Tier 1 информация в большинстве случаев обрабатывается платформой построчно из курсора, который возвращает разные запросы. Такая построчная обработка:
с одной стороны, длительная по времени – скорость чтения данных ограничена скоростью конкретного драйвера реляционной или многомерной БД;
но обладает гибкостью и экономным расходом памяти – загрузить можно только те данные, которые необходимы сейчас и которые попадают под условия фильтрации в запросе.
В-третьих, на Tier 2 каждая запись из полученных «плоских» данных должна пройти проверку на соответствие всем измерениям куба. На тот случай, если в запрос попали «лишние» записи (см. принципы стратегии фильтрации, про которые мы говорили в первой статье). Проверка заключается в поиске (LookUp) элементов измерений, соответствующих ключевым полям записи. Время этой операции напрямую зависит от размеров измерений (кол-ва в них элементов). В итоговую IMatrix попадают только те точки данных, все координаты которых прошли эту проверку.
По результатам нашего тестирования, на Tier 0, 1, 2 обычно уходит минимум от 50% до 70% (а при сложных запросах и все 90%) от общего времени прохождения всех шагов. Поэтому организовав на Tier 2 слой кэширования для IMatrix, можно существенно повысить скорость работы всей BI-платформы. Именно так в итоге мы и сделали в нашей платформе.
3.2. Мифы и реальность кэширования данных в BI
Но не все так просто. Многоступенчатая трансформация данных по уровням абстракции сделана не случайно. У каждого Tier свои задачи и цели. Tier 0 запрашивает нужные подвыборки данных из разных источников. Tier 1 преобразовывает их в типы данных платформы и упорядочивает в последовательные итераторы. Tier 2 формирует многомерное представление. Если просто заменить эти шаги на заранее сохраненный кэш у IMatrix, то все эти преимущества теряются. Удалили элемент из измерения – кэш уже не соответствует структуре куба. Добавили запись в БД из внешних систем – «горячий» кэш данных в оперативной памяти BI-сервера опять стал невалидным.
Именно поэтому при связке «BI+Data Lake» мы не рекомендуем использовать кэш или in-memory OLAP целиком для всех данных. Точнее, можно, но это будет история про Self Service BI, данные для которого должны быть размещены в озере в отдельной аналитической витрине (часто сразу с применением in-memory СУБД) или импортированы во внутренние форматы хранения. Для Enterprise BI сложно ограничиться только отдельной витриной. Мы часто встречаем примеры из своей практики, когда для отчетности или аналитических материалов нужно было одновременно использовать информацию сразу из всех слоёв озера данных (первичные, детализированные, аналитические, консолидированные). Причем всегда «свежую» и актуальную, т.е. режим Live connection.
Тем не менее и в Enterprise BI существует ряд сценариев, для решения которых кэширование данных подходит практически «идеально»:
Use-case #1: на BI постоянно транслируются одни и те же данные из источника. Если объем данных небольшой (десятки или сотни млн записей), ролевая модель не используется и не требуется ввод и сохранение данных, то вариант кэширования тут подходит идеально. Самый распространенный сценарий использования – интерактивные дэшборды руководителей. Быстро, компактно, удобно.
Use-case #2: большой объем данных нужно получить или обработать (рассчитать) в BI за короткое время. Тогда кэш используется как промежуточный буфер, а все его данные регулярно (каждую ночь, в выходные или асинхронно после финального утверждения) копируются в основное хранилище. Например, это сценарии для многомерных расчетов с большими объемами данных. Здесь обрабатываемых данных настолько много, что трансформировать их за требуемое короткое время через Tiers 0-2 невозможно. Или другой пример – сбор (загрузка) в систему сведений о деятельности подотчетных компаний. С поэтапной валидацией и утверждением всех данных. Тут объем информации не такой большой, но обрабатывать и перемещать их в разные слои согласования нужно очень оперативно. При этом скорость сохранения в транзакционную БД по времени быстродействия не подходит.
Use-case #3: разные выборки данных со сложными условиями фильтрации. В первой статье мы уже немного затрагивали эту тему. Для BI условия фильтрации в sql- или mdx-запросах сильно зависят от бизнес-логики и структуры куба. Например, в 10 измерениях с объемом элементов по 100 тыс. нужно в каждом из измерений выбрать все четные элементы. Тогда в условия запроса начинают попадать длинные перечисления. Базам данных ничего не остается делать, как выполнять все эти проверки, что увеличивает время работы на Tier 0. Чем больше исходных данных и «длиннее» условия в запросе, тем больше деградирует скорость. Кэш данных в платформе «Форсайт» имеет собственную систему двойной индексации, которая хорошо адаптирована для обработки многомерных данных из IMatrix. Поэтому выборка данных для больших многомерных условий (IMatrixQuery) в ряде случаев в кэше будет выполняться намного быстрее, чем на стороне СУБД. На рисунке ниже представлен график изменения скорости выполнения запроса в зависимости от количества отмеченных элементов. Чем их больше, тем сложнее будет набор предикатов существования в sql- или mdx-запросе. Как видно из рисунка, для транзакционных и массивно-параллельных СУБД рост скорости линейно зависит от сложности предикатов. Для колоночных или in-memory СУБД этот коэффициент роста намного меньше. А запрос из кэша BI самый оптимальный по времени.

3.3. Потребление оперативной памяти
При активации режима кэширования очень актуальным становится вопрос расходования оперативной памяти. Для платформы «Форсайт» в общем случае можно использовать следующую формулу расчета:

Для примера, 10 млн данных в одном кубе из 15 измерений с одним числовым фактом будут занимать чуть менее 1 Gb оперативной памяти. Далее пропорция линейная. Как в сторону увеличения объема данных, так и для количества используемых измерений или типов данных в фактах (см. график ниже). Штрихпунктирная черная линия на правом графике показывает объем оперативной памяти, который занимает система индексации точек данных куба. Она хранит координаты его измерений. На размер памяти для индекса влияет только количество измерений, и он одинаковый для любого типа факта. Остальную память, выше штрихпунктирной линии, занимают уже непосредственно сами значения точек куба, на которые ссылается индекс. И вот тут тип данных факта напрямую влияет на её размеры, что видно из графика.
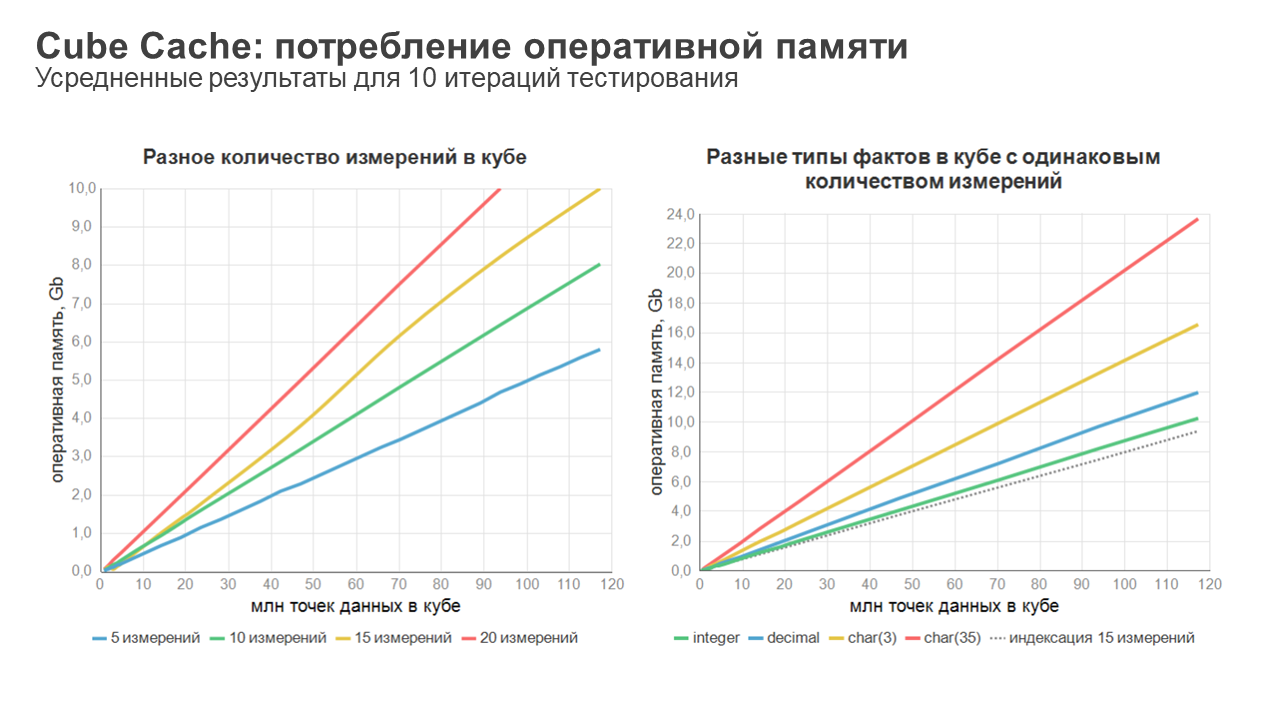
Формула расчета потребления оперативной памяти показывает нам, что самым «прожорливым» и «непредсказуемым» является кэширование строковых данных. Для случая с реестровыми данными это становится еще более актуально, когда значения строковых атрибутов начинают повторяться. Например, перечисление длинного названия отдела и департамента у групп сотрудников или тематика общей программы у списка инвестиционных проектов и т.п. Для таких случаев у кэша в платформе «Форсайт» можно активировать механизм дедупликации. При таком режиме работы индексация происходит для каждой заполненной координаты куба, но все повторяющиеся значения хранятся в отдельном списке без учета дублей. Этот механизм можно использовать опционально, и он позволяет существенно оптимизировать потребление оперативной памяти для ряда случаев (см. график ниже, эффект от дедупликации – объем оперативной памяти выше зеленой зоны).

3.4. Скорость работы
Скорость прогрева (формирования кэша) данных для куба во многом зависит от структуры его таблицы фактов («широкая» или «длинная» витрина), а также от степени разрежённости этих данных. «Широкий» формат для BI всегда предпочтительнее «длинного», и это сказывается на времени. Причем эта логика сохраняется как для кэшированных данных, так и для режима Live connect.
Объяснение тут очень простое. Чисто технически из «длинного» источника в Data Access Layer поступает больше информации, т.к. часть ключей элементов измерений повторяется для всех фактов (такова структура его хранения). Поэтому платформа выполняет больше операций для конвертации этих типов данных. И времени на это соответственно уходит больше. Но в итоге количество точек данных в IMatrix у куба будет одинаковым как для широкой, так и для длинной витрины.

На графиках ниже представлена усредненная (для 10 итераций тестирования) статистика замеров по «прогреву» кэша для куба с 15 измерениями и разной степенью разрежённости данных. Чтение информации происходит из СУБД PostgreSQL. Полный объем «плотных» данных составляет 120 млн точек. Как видно из графиков, чем плотнее (менее разрежённые) данные, тем выше эффект для разницы между широкой и длинной витринами.


После массового «прогрева» кэша, пользователю доступно не только чтение, но и пополнение (изменение) в нем данных. При этом скорость записи в уже сформированный кэш происходит в несколько раз быстрее операции «прогрева» (см. график ниже). При этом не важно, изменяем мы значения уже существующих в IMatrix точек или добавляем новые значения. Высокая скорость работы кэша в режиме записи создает большой потенциал для его использования при вычислениях в оперативной памяти (in-memory computing). Для многомерных расчетов режим вычисления в ОЗУ позволяет повысить время в десятки и даже сотни раз по сравнение с тем, если бы в алгоритмах использовались ROLAP-кубы в качестве источников данных, а не механизмы in-memory.
Стоит отметить, что когда для получения данных используется язык программирования (например, расчеты на R или Python), то расход оперативной памяти нужно учитывать с двух сторон. Память для создания внутренних переменных в платформе «Форсайт» и их «зеркальные» переменные в самом языке программирования.

Скорость передачи данных между платформой и внешним языком программирования при таких интеграциях достаточно высокая, и можно передавать миллионы значений (см. график). В рамках теста в платформе массив из N элементов (см. ось X на графике) через параметр передавался в функцию на внешнем, для платформы, языке программирования. В функции, уже средствами внешнего языка программирования, массив корректировался и передавался обратно в платформу. Таким образом мы эмитировали передачу первичных данных и обратное получение уже обработанных данных между платформой и разными языками, что и отражено на графике.
3.5. Сегментация и партиционирование кросс-сессионного кэша
Рассматривая вопрос кэширования данных в платформе «Форсайт», важно понимать две вещи. Первое – это то, что объем информации в кэше будет влиять на скорость ее обработки. Тут все как в любой СУБД (время выполнения запроса для таблицы в 1 млн записей или в 1 млрд записей будет разное). Второе – не все данные в кэше нужны одновременно. Например, расчет по сценариям или обработка данных по филиалам (доступным пользователю в рамках его ролевой модели).
Иными словами, есть много случаев, когда кэш не стоит формировать как единый неделимый монолит информации (полный кэш, FullCache). Часто бывает целесообразно разделить его на отдельные фрагменты/партиции данных (PartialCacheByParam). И далее в разные моменты времени работать с разными фрагментами. Такое разделение в платформе «Форсайт» реализовано через параметры метаобъектов. Вы определяете для куба параметр (один или несколько). Далее для каждой комбинации значений этих параметров формируете свой фрагмент кэша. «Прогрев» каждой такой партиции (фрагмента) кэша управляется отдельно и любую из них всегда можно добавить или очистить из общего пула фрагментов.
Если рассмотреть операцию write-back, то она доступна и для полного, и для параметризированного кэша, но при многопользовательском режиме работает по-разному:
Для полного кэша все одновременно изменяемые в разных сессиях записи выстраиваются «в очередь» и будут записываться в общую IMatrix последовательно. Это регулирует диспетчер управления потоками данных в кэше (он называется RWMutex). Так реализовано потому, что IMatrix имеет сложную внутреннюю систему многомерной индексации данных, и параллельно для нескольких новых значений формировать ее нельзя.
Параметризированный кэш тоже использует IMatrix, но для каждой комбинации значений параметров создает в оперативной памяти отдельную локальную матрицу. За счет этого запись в PartialCacheByParam в рамках разных партиций может выполняться параллельно (каждый поток в свою матрицу). Это очень удобно при одновременном выполнении высоконагруженных расчетов или загрузки данных по разным сценариям. Сохранение данных для всех сценариев выполняется одновременно, каждый из них идет в своем потоке в свою локальную матрицу. При этом за счет виртуализации данных разные локально параметризированные матрицы затем можно объединить в виртуальном кубе и в отчетности увидеть общий результат и сравнить их между собой.
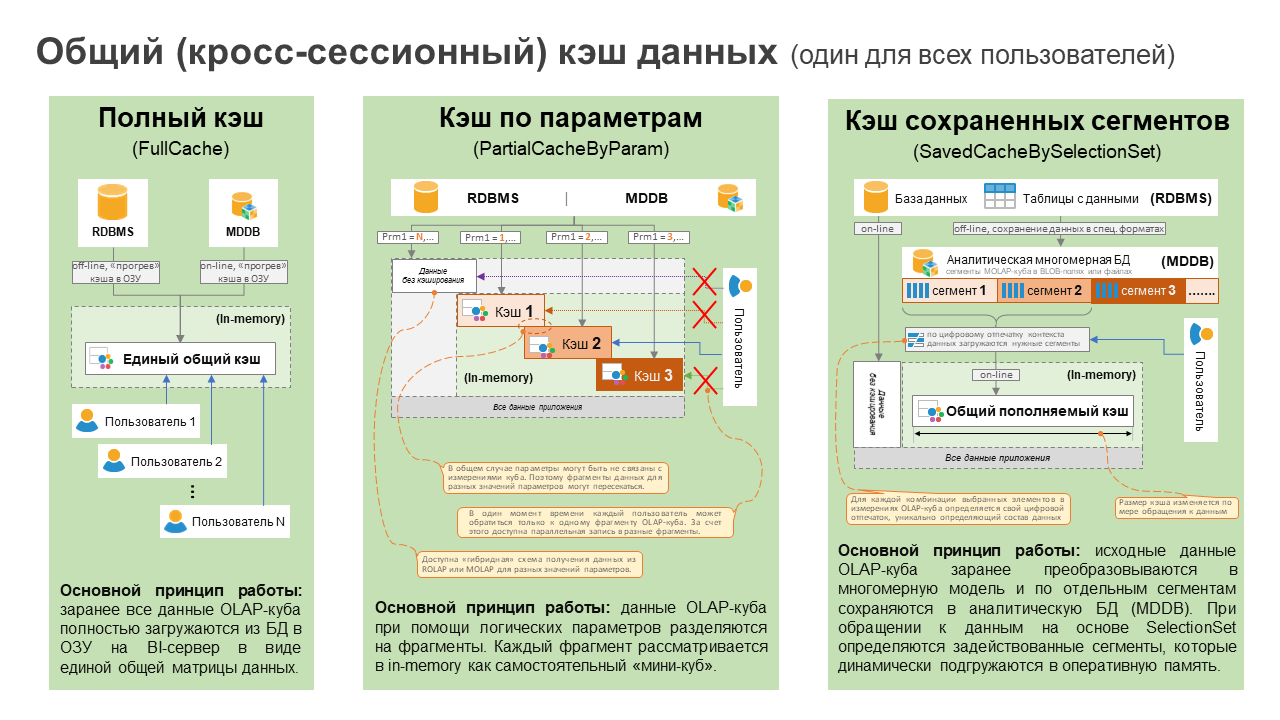
В платформе «Форсайт» существует и третий вариант работы с кэшем данных (SavedCacheBySelectionSet). Он актуален при ограниченном объеме оперативной памяти. С его помощью при достижении заданного лимита памяти новые данные будут вытеснять из кэша неиспользуемые или редко используемые страницы данных.
Для работы такого варианта кэширования информация из внешних источников заранее должна быть импортирована в специальный внутренний формат хранения. При импорте все данные разделяются на сегменты (страницы данных). Далее пользователь выбирает в кубе необходимые ему элементы измерений (SelectionSet), и на их основе платформа вычисляет, какие сегменты нужно догрузить в кэш с учетом выбранных элементов.
3.6. Бэкапирование и быстрое восстановление кэша
Сформированный в оперативной памяти кэш может быть сохранен (импортирован) в специализированном формате на жестком диске. Об этом уже упоминали в предыдущем разделе. Затем из этих сохраненных образов кэш куба можно загрузить обратно в оперативную память за более короткое время, чем «прогрев» из реальных внешних источников.
В платформе «Форсайт» доступно два формата сохранения кэша:
сохранение в реляционную таблицу всего потока памяти IMatrix целиком в бинарном формате (статичный хранимый кэш данных);
набор связанных файлов на жестком диске с сохранением каждой точки данных из IMatrix (инкрементальный файловый кэш данных).
Каждый из этих форматов сохраняет кэш в многомерном виде (внутренний MOLAP-сервер платформы «Форсайт»), но есть разница в способе хранения и доступа к данным. Статичный кэш требует наличия доступа к СУБД. Доступ к данным при таком варианте, как и у ROLAP-кубов, организован с помощью реляционных запросов. Но в одной записи таблицы БД хранится вся матрица данных целиком. Все данные сохраняются в бинарном формате в поле c типом blob. Тем самым, прочитав одну запись, многомерная матрица в оперативной памяти сразу заполняется закэшированными данными. Сохраняется как бы «слепок» всей матрицы.
Если для куба активирован PartialCacheByParam, то каждая локальная матрица хранится в таблице БД как отдельная запись. Какую именно запись прочитать – определяется значением параметров. Важный момент: формат статичного кэша позволяет считать и записать данные для IMatrix только целиком. Он не поддерживает частичного обновления информации. Такая технологическая особенность реализации этого формата. Через поток ОЗУ сохраняется и читается сразу вся матрица. Но зато это формат самый быстрый по скорости восстановления и сохранения кэша. Его актуально использовать для архивных данных или как режим бэкапа информации (чтобы потом можно было быстро «прогреть» закэшированные данные).
Файловый кэш хранит данные на жестком диске BI-сервера в виде набора связанных файлов. База данных здесь уже не нужна. При обращении к сегменту данных востребованная часть информации из файла загружается в оперативную память (именно для этого формата доступен режим SavedCacheBySelectionSet). В отличие от blob-кэша, информацию в сохраненных файлах можно обновлять частично, в том числе до одной точки матрицы. Измененное значение будет сохранено в нужный сегмент. Это позволяет организовать частичную корректировку данных в файле кэша.
При необходимости можно сохранить связь файлового кэша с источником-оригиналом. Тогда изменение данных будет дублироваться (как во внутреннем файле, так и в самом внешнем источнике).
Если нужно регулярное обновление кэша актуальными данными из источника, то в платформе «Форсайт» можно настроить соответствующую операцию в планировщике задач. По расписанию можно обновлять как blob-кэш целиком, так и часть файлового кэша.
4. Кэширование метаданных
Для работы любой ИТ-системы важны не только сами данные, но и метаданные. Они содержат описание и структуру всех метаобъектов платформы. Метаслой дает возможность эффективной организации и управления как самими этими данными, так и BI-инструментами для их обработки. Но чем сложнее ИТ-решение, тем больше объектов (записей) метаданных. Простой пример: отчет использует несколько гетерогенных кубов, в каждом кубе по несколько реляционных таблиц-источников. Плюс справочники, иерархии, группы, стиль оформления, контейнер сегментов доступа для ролевой модели, макросы-обработчики и т.п. Для одного отчета количество метаобъектов может составлять несколько десятков, а иногда и сотни.
При этом модель структуры хранения метаданных сложно упорядочить. Связано это с необходимостью регулярных изменений версий метаданных (при активном развитии BI-платформы), а также наличием большого количества опциональных свойств у метаобъектов. Поэтому описание метаобъекта хранится в одном общем бинарном blob-поле. Информация кодируется во внутреннем формате нашей платформы. Её размеры для описания одного сложного метаобъекта могут достигать десятки мегабайт. Процесс сериализации и десериализации занимает определенное время, что, несомненно, будет снижать скорость реакции BI-платформы на действия пользователя.
В связи с этим, информация о метаобъектах также кэшируется в нашей платформе. Но с учетом часто используемой сложной ролевой модели кросс-сессионный кэш метаданных на практике не получил распространенного применения. Все сводится к кэшированию метаданных на уровне персональных сессий.
Почему сложно кэшировать метаданные?
Для повышения производительности можно и нужно кэшировать слой метаданных на сервере BI. Это, с одной стороны, повысит скорость работы BI-платформы. Но с другой стороны, с этим связан ряд ограничений:
Ролевая модель и доступ пользователя к метаобъектам. Многие метаобъекты связаны между собой, причем по принципу русской сказки «Репка». Отчет «тянет» за собой куб, куб – измерения, измерения – таблицы БД и т.п. Отсутствие прав доступа хотя бы к одному метаобъекту делает невозможным обращение пользователя к отчету. При кросс-сессионном кэшировании метаобъектов нельзя просто обратиться к глобальному кэшу метаданных. Дополнительно нужно проверить условия их использования в соответствии с ролевой моделью для клиентской сессии.
Метаданные зависят от данных, которые могут изменяться. Например, измерения, которые формируются на внешних таблицах-справочниках. Изменения информации в источнике требует обновления кэша метаобъекта, т.к. может измениться состав элементов, их иерархия, порядок следования и т.п. Таким образом, глобальный кэш метаданных не может быть статичным, а должен анализировать изменения в метаслое.
Параметризация метаобъектов. Как уже рассказывали выше, разные экземпляры метаобъектов могут быть сформированы с разным набором значений параметров. При формировании объекта параметры могут учитываться везде: какие данные использовать, условия для правил фильтрации, права доступа, стили оформления и многое другое. Поэтому кэш должен быть организован с учетом этого. Один набор параметров – одна запись в кэше.
Атрибутивный статус метаобъекта. В платформе реализована модель контроля доступа, основанная на анализе правил для атрибутов объектов (ABAC-правила). Изменения значений этих атрибутов могут производиться пользователями в процессе работы ИТ-системы. Например, в рамках бизнес-процесса.
В связи с этими особенностями, управление кэшем метаданных – это сложная задача. Для персонального кэша метаданных она решается в автоматизированном режиме. Для кросс-сессионного – все намного сложнее и требует ручной настройки с учетом индивидуальной специфики ИТ-системы.
5. Кэширование исполняемого программного кода
Платформа «Форсайт» одновременно является и No/Low code инструментом и Full code фреймворком. Кроме специализированных простых мастеров для бизнес-пользователей, в ней есть собственная среда разработки. Она одновременно поддерживает работу с внутренним проприетарным языком программирования Fore и популярными языками программирования Python, Java, .Net, при необходимости R или VBA. В метаслое можно создавать модули, писать в них программные скрипты, выполнять и отлаживать их работу.
Такой подход позволяет на платформе «Форсайт» создавать ИТ-системы любой степени сложности для совершенно разных предметных областей. Если чего-то нет «из коробки» – это всегда можно запрограммировать. Но получая такую гибкости всегда возникает противоположный вопрос: какая скорость работы таких прикладных программных расширений? Ведь интерпретатор обычно выполняет код не очень быстро. Для облегчения и ускорения работы интерпретатора в платформе «Форсайт» используется байт-код. Он тоже кэшируется, и это существенно ускоряет выполнение программных модулей.
При кэшировании байт-кода нужно рассматривать 2 сценария:
Одновременная разработка программного кода на Dev-ландшафте. Язык программирования платформы «Форсайт» является объектно-ориентированным, поддерживает классы, интерфейсы и наследование, а также переиспользование одних модулей в других (как библиотеки). Таким образом, у каждого разработчика из команды должна быть целостная и компилируемая версия всего программного кода. Для этих целей платформа может быть подключена к системе контроля версий (tfs или git), а также кэш байт-кода для всех модулей хранится локально у каждого разработчика (персональный кэш). Таким образом, внесенные изменения первое время будут доступны только автору и не «испортят» работу других.
Исполнение программного кода на Prod-ландшафте. Работа ИТ-решения в промышленном режиме отличается от ландшафта разработки. Тут уже больше важно не обеспечить совместимость разных веток реализации, а максимально повысить скорость его выполнения. Для этих целей байт-код формируется заранее, сохраняется в репозиторий метабазы BI-платформы и далее загружается в глобальный (кросс-сессионный) кэш. Тут нужно исходить из предпосылок, что изменений кода не будет (или изменения будут централизованными и не такими частыми). При обращении к кэшу происходит сравнение даты и времени его формирования. Это обеспечивает всегда актуальный байт-код даже для тех случаев, когда модули на Prod-среде все же были изменены.
6. Кэширование состояний активных веб-сессий
Для отказоустойчивой работы в платформе «Форсайт» рекомендуется создавать кластер BI-северов (как минимум active и standby). Но из-за трехзвенной архитектуры и сложной бизнес-логики связь клиента и BI-сервера организованы в форме «липких сессий». Это означает, что балансировщик при старте новой сессии пользователя закрепляет ее за определенной нодой BI-сервера и далее всегда перенаправляет туда все её запросы. Так сделано потому, что инструменты платформы – это сложный механизм с системой взаимосвязанных функций. Каждое новое действие неразрывно связано с результатами предыдущих операций системы и пользователя. Например, открыли отчет, выбрали нужные параметры фильтрации, сформировался куб и его кросс-таблица, ввели данные, сохранили их в БД и т.д. Все эти операции выполняются на одной и той же ноде кластера и формируют текущее состояние отчета. Направлять разные действия на разные BI-сервера просто невозможно. Там не будет актуального состояния у инстанса отчета.
Но давайте рассмотрим, что произойдет в случае отказа ноды, к которой была «прилеплена» эта сессия? Да, есть резервный сервер. Да, балансировщик поймёт, что нода active не отвечает и нужно перенаправлять все запросы уже на другой работающий сервер (standby). Но на нем нет актуального инстанса для нужного метаобъекта. Объекты необходимо заново открывать из метабазы и приводить к актуальному виду. Чтобы это сделать, в платформе «Форсайт» реализован сервер состояний. Его задача – хранить историю всех команд пользователя в рамках каждой веб-сессии. И затем на её основе восстанавливать актуальное состояние инстансов метаобъектов.
Балансировщик все запросы направляет параллельно и на кластер BI-серверов, и на сервер состояний (если он активирован). На сервере состояний все изменения сохраняются в Redis в оперативной памяти. Такое кэширование даже при большом количестве операций и одновременных сессий позволяет быстро восстановить все коннекты при сбое одного из BI-серверов.
7. Заключение
Кэширование в оперативной памяти – достаточно сложный, но очень нужный механизм для BI платформы. В некоторых ситуациях он помогает существенно повысить производительность вашего ИТ-решения. Но его использование требует серьезного погружения в принципы его работы и часто ручного управления при настройке. Наше заключение – кэширование и технологию in-memory можно и нужно использовать для связки «BI+Data Like». Она является хорошим технологическим механизмом и, несмотря на свои минусы, должна быть использована в уместных для этого ситуациях.
Итак, мы завершили наш первый комплексный цикл публикаций о связке платформы «Форсайт» и озёр данных. Но у нас есть много другого интересного и полезного материала из сферы BI. Нам было бы очень важно и полезно узнать ваше мнение о представленных публикациях, их формате, акцентах.

