Если вдруг кому интересно то я веду телеграм канал где выкладываю интересные статьи на темы DS или ML которые могут быть вам интересны.
Сегодня мы воспользуемся возможностями машинного обучения для анализа шоколадного печенья.

Машинное обучение сегодня стало довольно будничным явлением. Кажется, что эту технологию невозможно понять и применить без глубоких познаний в информатике и математике, но это утверждение далеко от правды. В мире, где ведущие компании были созданы в гаражах, а FOSS (бесплатное и открытое программное обеспечение) есть везде, куда ни глянь, существует несколько библиотек, созданных сообществом, чтобы упростить разработку модели машинного обучения.
Что такое Scikit-Learn?
Scikit-learn — это библиотека машинного обучения для Python. Она построена поверх нескольких библиотек Python, включая NumPy (математические функции), SciPy (нужно больше математики!) и Matplotlib (визуализация данных).
Если вы хоть немного знакомы со сферой машин лёрнинга, вы можете удивиться, почему мы не используем TensorFlow от Google. TensorFlow — это тоже библиотека машинного обучения, но она в основном фокусируется на глубоком обучении и нейронных сетях. Scikit-learn содержит только общие концепции машинного обучения и считается более легким для новичков по сравнению с TensorFlow.
Такие компании, как JPMorgan и Spotify применяют scikit-learn для задач предиктивного анализа или системы рекомендации музыки. Отзывы можно посмотреть здесь.
С чего начать
Для этого туториала вам понадобятся:
Python (версия 3.7 или выше) — в комплекте желательно иметь базовый опыт работы с ним
Сначала установите три пакета с помощью pip в консоли:
pip install notebook pip install numpy pip install scikit-learn
Запустите в консоли jupyter notebook. Ваш дефолтный браузер должен открыть вкладку с проводником файлов. Просто переходите по директории, где вы бы хотели создать программу и создайте там файл Python 3 Notebook (выберите new в правом верхнем углу). Вы увидите такой экран:
Можете переименовать файл, кликнув на «Untitled.»
Время кодить!
Запустите каждую ячейку после завершения ее записи, нажав кнопку Run вверху экрана. В первой ячейке начните с импорта нужных библиотек:
from sklearn.neural_network import MLPClassifier import numpy as np
Теперь время для данных, на которых мы будем обучать нашу модель. Допустим, мы отправимся в магазин печенья и опросим людей о том, какое печенье они пробовали:
# sweet, bitter, good(1) or bad(0) survey = np.array([ [1, 0, 1], [1, 0, 1], [0, 1, 0], [1, 0, 1], [1, 0, 1], [0, 1, 0], [1, 0, 1], [0, 1, 0], ])
Посмотрите на эти данные (обратите внимание на комментарий вверху). Мы быстро определили закономерность: сладкое печенье = хорошо, а горькое = плохо. Этому простому выводу мы и обучим нашу модель.
Теперь мы определяем характеристики и метки наших данных:
features_train = survey[:, 0:2] labels_train = survey[:, 2]
Этот пункт говорит сам за себя — характеристики, по которым мы обучаем модель, это сладость или горечь печенья, а метка — оценка печенья: хорошее оно или нет.
Далее нажмите alt + enter, чтобы создать новую ячейку.
Теперь нам нужно разработать тестовый набор, чтобы проверить нашу модель на данных, которые она просмотрела. Это поможет понять, насколько модель точная.
Нейронные сети
В качестве модели мы будем использовать MLPClassifier от scikit-learn. MLP просто (или не очень просто) означает многослойный перцептрон. В общих чертах, многослойный перцептрон — это искусственная нейросеть с обратной связью, где входы и выходы равны 0 или 1:
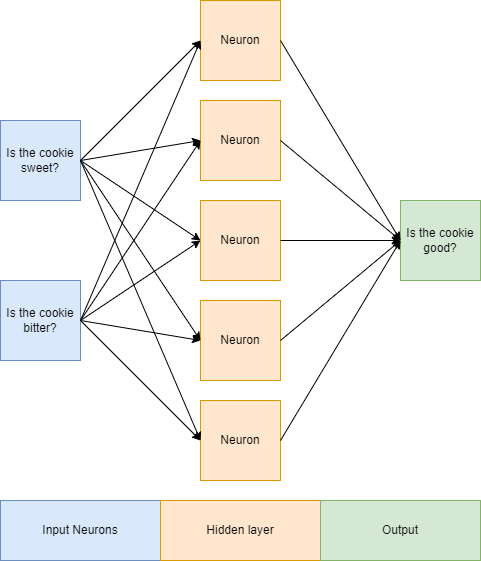
Нейросети так называются не случайно — узлы (или нейроны) в нейронных сетях аналогичны нейронам в мозге человека. Если правильно стимулировать нейроны, они запускаются.
Скрытые слои — это то место, где происходит волшебство. Их называют скрытыми, потому что они не видны за пределами сети.
Каждый нейрон скрытого слоя имеет вес, отражающий степень важности его входных данных. Например, если бы мы добавили к нашим данным больше факторов, чем просто «сладкий» или «горький», модель применила бы веса к каждому из этих признаков. И соленость, и сладость помогают получить хорошее печенье, но вес солености может быть меньше (т.е. 0,2х), чем вес сладости (т.е. 0,5х). Так получится, если модель придет к выводу, что сладость для хорошего печенья важнее, чем соленость.
Каждый нейрон также имеет bias — смещение (постоянное число), которое добавляется или вычитается, чтобы компенсировать результат работы нейрона. Слишком сложно для этого туториала, поэтому опустим подробности.
Нейронная сеть, которую мы создаем, это не сеть глубокого обучения. Глубокой нейронной сетью считается сеть, в которой более трех скрытых слоев (3 — общепринятое число). Таким сетям не требуются маркированные данные. Например, классическая нейронная сеть требует участия человека для маркировки наборов данных. Мы так делали, когда маркировали, какие печенья были хорошими, а какие нет — это и называется контролируемым обучением.
С другой стороны, глубокие нейронные сети выполняют так называемое «обучение без учителя». Они могут использовать не маркированные данные и объединять их в различные группы на основе характеристик, которые они определяют самостоятельно.
И наконец, сам код (знаю, звучит не так впечатляюще). Мы просто определяем, что наш скрытый слой будет состоять из 5 слоев, и что мы будем просматривать наши данные 3000 раз.
# Define the model mlp = MLPClassifier(hidden_layer_sizes=(5), max_iter=3000, # epochs )
Снова нажмите alt + enter, чтобы создать новую ячейку.
Теперь мы подгоним или обучим модель к данным, которые мы ей предоставили. Модель пройдет через данные 3000 раз (то есть, завершит 3000 эпох), как мы и определили при создании нашей сети.
Затем мы протестируем нашу модель на тренировочном и тестовом множестве с разработанными весами и смещениями.
# Train the model mlp.fit(features_train, labels_train) print(f"Training set score: {mlp.score(features_train, labels_train):.3%}") print(f"Testing set score: {mlp.score(features_test, labels_test):.3%}\n")
Выход (output):
Training set score: 100.000% Testing set score: 100.000%
Еще раз нажмите alt + enter, чтобы создать новую ячейку.
Наконец, мы можем использовать нашу проверенную модель, чтобы определить, будет ли печенье хорошим или нет. Вот код, который я использовал для тестирования:
features_list=[ {"features": [[1, 0]], "type": "Sweet cookie"}, {"features": [[0, 1]], "type": "Bitter cookie"} ] for item in features_list: print(f"Type: {item['type']}") if mlp.predict(item["features"]) == 1: print("Good cookie!") else: print("Bad cookie!") print("\n")
Помните вывод, который мы сделали на основе полученных данных в самом начале? Наша модель успешно сошлась с нами в мышлении!
Type: Sweet cookie Good cookie! Type: Bitter cookie Bad cookie!
Вывод
Конечно, данные, которые мы использовали в этой модели, не нуждаются в нейронной сети. Но это простая имплементация с простыми данными, и с ней мы можем сфокусироваться на том, как работает машинное обучение.
Вы можете обновлять опросник про печенье и добавлять тестовые наборы на свой вкус. Добавьте, например, больше признаков (хрусткость, соленость и т.д.), и испытайте модель самостоятельно.
Спасибо за чтение! Надеюсь, вам понравился туториал, и вы лучше поняли, как работает машинное обучение.

