
Хочу рассказать о том, как занимался оптимизацией card raytracer - минимального рейтрейсера, код которого умещается на визитке.
Точнее, это развёрнутая для лучшей читабельности версия, которая в форумной ветке
использовалась как тест скорости разных языков.
Когда я наткнулся на эту ветку, я как раз изучал компиляторы Cи, и конечно немедленно вознамерился всех порвать обогнать. В результате действительно обогнал, но с нарушением правил - слегка поправив структуру данных.
Тем не менее, это хороший пример того, как можно "заточить" код под векторизацию, с сохранением читабельности и умеренным ростом объёма и сложности. Я расскажу, какие есть варианты векторизации, как перестроить код и данные, и наконец, как переложить на компилятор черновую работу по кодогенерации - используется автовекторизация, векторные расширения и совсем немного интринсики.
Наверное, статья будет в большей степени полезна новичкам, но и опытные разработчики (по привычке пишущие SIMD-код интринсиками) могут найти что-то новое.
Компилятор - в основном Clang, можно GCC, в конечном итоге я адаптировал и под MSVC.
1. Первая попытка оптимизации и алгоритм рейтрейсера.
По Сard raytracer на Хабре уже были статьи: с разбором алгоритма, с переписыванием на C#.
Но я рассматриваю предыдущую версию рейтрейс-визитки, более простой, зато более быстрый алгоритм (работает секунды вместо минут). Классика рейтрейса - зеркальные сферы с простым освещением, мягкими тенями и антиалиасингом.
Собственно алгоритм... но честно скажу, я поначалу поленился вникать, а сразу полез писать код. И сейчас будет наглядный пример, почему так делать не надо.
При поверхностном взгляде в исходник можно понять, что в основном он состоит из расчётов с геометрическими векторами [x,y,z]. И самый очевидный метод векторизации - поместить эти вектора в SIMD-регистры и делать, например, сложение векторов одной командой addps вместо 3-х отдельных сложений. Вот здесь в самом начале есть красивая картинка (умножение вместо сложения, но не суть).
Я не стал заморачиваться с интринсиками, а по-быстрому переправил код под векторные расширения Clang, благо это не требует больших изменений. Подробнее о векторных расширениях я расскажу позже, сейчас главное - что получилось в результате.
i5-12400F, Clang 14, -march=haswell -O3 -ffast-math
(базовая версия представляет собой некую смесь card-raytracer-opt/card-raytracer-rwolf c ГитХаба, double заменён на float)
|
|
|
|
|
|
А в результате не получилось никакого ускорения, и проблема не только/не столько в векторных расширениях. Версия с применением интринсиков для некоторых операций тоже не очень впечатляет - ускорение всего на 10% (Raytracer_handofdos_r3experimental не рассматриваю, там попытка использовать многопоточность, а без неё всё намного медленнее базовой версии).
Чтобы понять в чём причина - придётся таки разбираться с алгоритмом.
Псевдокодом его можно описать так:
Для каждого пикселя:
Выпустить с небольшим случайным смещением 64 луча и усреднить результат
Для каждого луча:
Проверить пересечение со сценой (49 сферами), при попадании в сферу рекурсивно считать отражённый луч (снова перечесение с 49 сферами и т.д.).
Становится понятно, что самое "горячее" место - это проверка пересечения луча со сферой, поскольку для каждого пикселя оно делается минимум 64 * 49 = 3136 раз. Проверка попадания делается в функции tracer, которая также проверяет попадание в пол или небо, возвращая 0 для неба, 1 для пола, 2 для сферы. Но пол и небо почти не дают вычислительной нагрузки, основное здесь проверка сфер:
// Сферы хранятся как 2D массив, точнее, для компактности это // 1D массив битовых масок, поэтому у нас двойной цикл - по маскам и по битам // в маске for (int k = 19; k--;) for (int j = 9; j--;) if (G[j] & 1 << k) { // бит установлен - есть сфера в этом месте // формируем вектор центра сферы Vector p = o + Vector(-k, 0, -j - 4); // считаем попадание луча в сферу fltype b = p % d; fltype c = p % p - 1; fltype q = b * b - c; if (q > 0) { // попали // считаем расстояние от начала луча (от камеры для первичного луча) до сферы fltype s = -b - sqrt(q); if (s < t && s > .01f) { // выбираем наиболее близкую сферу и считаем для неё нормаль t = s; n = !(p + d * t); m = 2; } } }
Нужно отметить, что наиболее важна проверка попадания до условия (q > 0), потому что обычно мы НЕ попадаем (процентов 80 лучей не попадают в сферы, а если попадают, то чаще всего в 1 из 49), и код после условия выполняется крайне редко.
Рассмотрим проверку подробнее:
fltype b = p % d; fltype c = p % p - 1; fltype q = b * b - c;
Из трёх строк две - это операция %, в нашем случае это dot product, или скалярное произведение векторов (которое даёт косинус угла между векторами - вообще очень ходовая операция в комп. графике). Смотрим реализацию и видим:
fltype operator%(const Vector &l, const Vector &r) { return l.x * r.x + l.y * r.y + l.z * r.z; }
...и видим операцию, которая работает с отдельными компонентами вектора. Вот и ответ на вопрос "почему ничего не ускоряется": сначала мы помещаем вектор в SIMD-регистр, а потом заставляем компилятор выковыривать из него [x,y,z] и работать с ними по отдельности, вместо ожидаемых векторных команд.
Да, можно переписать функцию, чтобы по крайней мере умножение было векторным:
inline fltype dot(const Vector &l, const Vector &r) { Vector v = l * r; return v.x + v.y + v.z; }
Но насколько это поможет? Посмотрим, что генерирует компилятор для оригинального рейтрейсера и для версии на векторных расширениях.
https://gcc.godbolt.org/z/47W4zfTq7
https://gcc.godbolt.org/z/hPGKT8x3f
Оказывается, подобные подсказки компилятору не нужны, он и так в обоих случаях векторизует умножение - видим две команды vmulps (даже если вы плохо знаете ассемблер, векторные SIMD-команды легко отличить от скалярных по предпоследней букве: p - parallel, s - scalar. Сильно упрощая, можно сказать, что чем больше "пэ" сгенерировал компилятор, тем лучше :)).
Но при этом в оригинальной версии удаётся чаще применить команды FMA, умножение и сложение одной операцией (вот эти зубодробительно звучащие vfmadd231ss - 3 вместо 1), и в результате имеем 14 команд вместо 17.
Да, я знаю о специальной команде для скалярного произведения векторов (v)dpps, её можно применить через интринсик, и вроде бы всё красиво, 6 команд вместо 14/17... но по факту так ещё медленнее! 6.70 вместо 4.55/5.08 с. Объяснить это можно невысокой эффективностью dpps, мне попадались утверждения, что даже расписанная вручную на SSE2 арифметика может быть быстрее. Причём это времена SSE4-AVX, a с появлением FMA (Haswell) dpps видимо проигрывает ещё больше.
Но напомню, что FMA у нас сейчас "s", скалярные, что далеко не предел мечтаний. И в целом можно констатировать, что попытка наивной векторизации провалилась, нужны какие-то существенные изменения.
2. Вторая попытка. Автовекторизация
Идея изменений весьма проста - если по структуре данных (вектору [x,y,z]) код векторизуется плохо, получается в лучшем случае две векторных команды на цикл, то надо векторизовать в другом направлении, можно сказать, перпендикулярном: по массиву из 49 сфер.
Кажется логичным задействовать для этого автовекторизацию, потому что она лучше всего работает именно в направлении "по циклу". Как это происходит: вы пишете цикл, в котором обрабатываете один элемент данных, компилятор анализирует его на предмет "а можно ли обрабатывать сразу несколько", и если да, генерирует два цикла - векторный, считающий по несколько элементов сразу, и скалярный для "хвоста" при кол-ве элементов не кратном шагу векторизации. При этом сохраняется простота исходного кода, не нужно изобретать чуть ли не отдельный API для SIMD (из комментариев к статье о векторизации в Net).
Пусть лучше изобретает компилятор в ассемблере: 5 строчек на Си, обрабатывающие 1 байт за итерацию, превращаются... превращаются... в 125 строк ассемблера и 256 байт за итерацию!
Почему так много? Во-первых, достаточно "широкая" система команд AVX2 (-march=haswell означает AVX2+FMA), позволяющая обрабатывать по 32 байта. Во-вторых, наш простой код оставляет свободными много регистров, и это провоцирует Clang в дополнение к SIMD ещё как следует развернуть цикл - на 4 на уровне команд (видно, что команды в ассемблере идут четвёрками) и на 2 на уровне цикла. Так и получается 32 * 4 * 2 = 256.
Этот пример идеален для векторизатора: простой цикл, последовательное чтение, вычисление, запись, итерации независимы друг от друга.
Однако в жизни подобное счастье бывает редко. Возвращаясь к нашему рейтрейсеру, смотрим вместе с компилятором на основной цикл и дружно огорчаемся: двойной, да ещё и с условием.
for (int k = 19; k--;) // 19 итер. for (int j = 9; j--;) // 9 итер. if (G[j] & 1 << k) { ... }
Ну ладно, двойной - не главная проблема, можно переставить циклы наоборот, чтобы внутренним (векторизуемым) был длинный, на 19 итераций. Получается 19 / 8 (AVX) = 2.375 (3) * 9 = 27 итераций, вместо 19 * 9 / 8 = 22 итераций с одинарным циклом - не такая большая разница.
Но остаётся ещё условие. Надо сказать, в SIMD довольно специфическая обработка условий. Операции сравнения выдают числовую маску, в которой true = $FF, false = $00, и дальше есть два варианта:
Посчитать обе ветки if () else (), а потом с помощью маски выбрать нужные значения из двух результатов: dst = (res1 & mask) | (res2 & !mask) - именно так векторизуется пример с ReplaceChr выше. Если ветка одна, просто отбросить ненужное, вместо res2 будет какой-то заведомо невалидный результат. В рейтрейсере у нас есть битовая маска, задающая буквы:

но мы не можем проверять отдельно каждый 0 или 1 - значит на этапе расчётов считаем, что там сплошь 1, а уже из результатов выберем валидные данные. Это может быть выгодно, если отбрасывать небольшой процент элементов, но у нас ноликов в маске явно больше. Можно прикинуть так: в оригинальном коде 19*9=171 итерация, но из них только 49 полновесных, т.к. всего 49 сфер. Векторный цикл даст меньше итераций - 27 вместо 49 - но это означает ускорение максимум в 1.8 раза, а на практике скорее всего хуже. При шаге векторизации 8 не особо впечатляет.
Использовать команду (v)movmskps (интринсик _mm(256)_movemask_ps), которая упаковывает значение SIMD-маски в 32-битный регистр, по которому уже можно сделать обычный джамп с условием "если для хотя бы одного элемента в нашем векторе условие = true, считаем эту итерацию, иначе пропускаем". Применительно к нашей маске - если есть хотя бы одна единичка в пачке из 4-8 штук. И теперь уже проблема в том, что единичек слишком много :) C 8-элементными векторами можно пропустить только две итерации в последних строчках, в результате 25 итераций. С 4-элементными векторами "пустыми" оказываются 11 итераций, для наглядности проиллюстрирую:

но и общее кол-во итераций больше в 2 раза, 60-11 = 49. С тем же успехом можно перебрать сферы по одной...
Кстати, подумал я. Что заставляет терзать эту битовую маску, почему бы не брать сразу координаты 49 сфер? По сути маска нужна из-за (неактуальных для нас) ограничений размеров визитки, и может быть ещё удобно "рисовать" картинку в текстовом редакторе, но в смысле оптимизации с ней сплошные мучения. Можно даже оставить маску как исходную структуру данных, но дополнить массивами на 49 элементов, в которые перегоняются координаты сфер немудрёным кодом:
int const SpCnt = 49; fltype Gxa[SpCnt] attribute ((aligned(32))); fltype Gza[SpCnt] attribute ((aligned(32))); int i = 0; for (int j = 9; j--;) for (int k = 19; k--;) if (G[j] & 1 << k) { Gxa[i] = -k; Gza[i] = -j-4; i++; };
Поскольку векторизация будет по циклу, не нужно упаковывать координаты в структуру, наоборот, лучше разделять, чтобы компилятор мог брать по 8 элементов Gxa/Gza одной командой vmovaps.
И даже если просто переписать цикл на одинарный с использованием этих массивов, безо всяких попыток векторизации:
for (int k = 19; k--;) for (int j = 9; j--;) if (G[j] & 1 << k) { Vector p = o + (Vector){(fltype)-k, 0, (fltype)-j-4}; {...} } -> for (int j = 0; j < SpCnt; j++) { Vector p = o + (Vector){Gxa[j], 0, Gza[j]}; {...} }
...то получаем ускорение почти в полтора раза:
|
|
|
|
Да, по меркам форумного соревнования языков/компиляторов, с которого всё начиналось, это "нечестно", делается меньше работы, чем в оригинальном коде. Поскольку цель была - сравнить языки/компиляторы, то нужно переписывать на одномерные массивы также и код на всех других языках. Но в данном случае я посчитал, что мне важнее тренировка в оптимизации в приближенных к реальным условиям (когда небольшие изменения структуры данных допустимы), чем "победа" на уже мёртвом форуме.
Теоретически векторизация по одномерным массивам может дать солидное преимущество: 49 / 8 = 6.175 -> всего 7 итераций на 49 сфер. Но возможно, мы забежали несколько вперёд, поскольку пока не очевиден ответ на вопрос - а векторизуется ли в принципе код tracer, даже с одинарным циклом? Для этого наиболее важно, чтобы итерации были независимыми друг от друга.
Tracer по сути выполняет 2 задачи: проверка попадания луча в сферы и выбор наиболее близкой сферы. Очевидно, что проверять попадания в сферы мы можем независимо. И попытка векторизовать первую половину tracer (с записью результирующего коэфф-та q в массив) это подтверждает, всё векторизуется без проблем:
https://gcc.godbolt.org/z/vs9dvq8Pf
причём вообще без изменений кода; чтобы было понятнее, как это векторизуется, я сделал версию с отдельными переменными вместо элементов вектора и заинлайнил функции вручную:
https://gcc.godbolt.org/z/8e43jxM35
Относительно нашего цикла почти все данные - константы (ox, oy, oz - начальная точка, dx, dy, dz - направление луча), и 8-компонентные вектора для них компилятор заливает одним значением (vbroadcastss в начале функции).
А переменные только Gxa и Gza, компилятор одновременно берёт их из массива и складывает командами vaddps ymm5, ymm0, ymmword ptr [rax + Gxa]. Далее всё считается пачками по 8 чисел (векторный цикл - строки 16-28 в ассемблере) и эти 8-ки пишутся в массив qa. Результирующий массив обозначен как __restrict - это необходимое условие для автовекторизации, гарантия компилятору, что массив (в Си по факту указатель) не пересекается с другими данными.
Директива #pragma clang loop unroll(disable) отключает развёртку цикла для лучшей читабельности ассемблерного кода, без неё генерируется огромная "простыня" - компилятор просто разворачивает все 6 векторных итераций.
Со второй частью tracer (выбор самой близкой сферы) сложнее - здесь мы имеем сравнение данных, полученных на разных итерациях, то есть зависимость итераций друг от друга, и на первый взгляд это ломает векторизацию. Однако есть довольно простой приём: использовать в качестве аккумулятора вектор, а не скалярное значение, выбирать по N самых близких сфер, а после пройтись по вектору и выбрать самую близкую в векторе.
В некоторых случаях компилятор даже делает такое автоматически. Но в этом, даже если бы мог, он сделал бы неэффективно. Дело в том, что векторизатор не умеет использовать SIMD-джампы через команду (v)movmskps, только хардкор, только расчёт всех веток, что при малой вероятности попадания в сферу совсем не выгодно.
Можно подключить тяжёлую артиллерию в виде интринсиков, но мне хотелось обойтись автовекторизацией.
Поэтому я решил разделить цикл на два - векторный и скалярный. Векторный выполняет основную массу расчётов, сохраняя коэфф-ты q и b в промежуточные массивы, скалярный проходит по массивам и извлекает из них попадания в сферы, если есть.
На тот момент я не читал отчёты компилятора о векторизации, но когда прочитал - оказалось, что компилятор пришёл к тому же выводу.
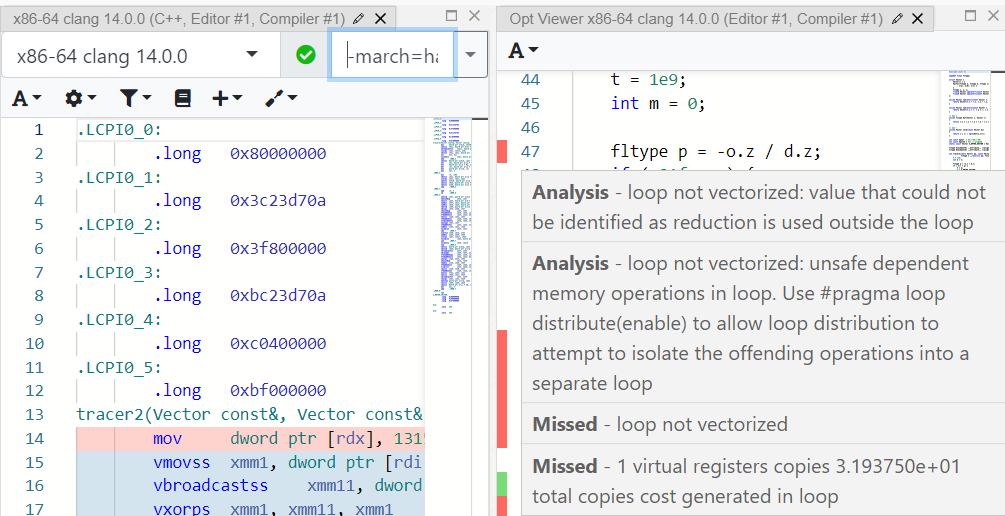
В godbolt есть удобный вывод отчётов Clang - окно Add new (иконка с плюсом) / Optimization, если навести курсор на полоску рядом с началом цикла, Clang сначала советует разрешить ему loop distribution (это и есть то самое разделение циклов), а если разрешить, жалуется, что не может справиться с unsafe dependencies. "Не шмогла"... ладно, делаем разделение вручную.
Векторный цикл выглядит похоже на тестовую функцию, только добавляется ещё сохранение коэфф-та b.
https://gcc.godbolt.org/z/x47varsqz
Лишняя запись в память - нехорошо, но кэш должен вывезти, не такие там большие объёмы.
Кроме того, добавлен счётчик попаданий rHitCnt - по смыслу это флаг "попали во что-то или нет" (можно считать и конкретно как флаг: rHitCnt = rHitCnt | ((q > 0.0f) ? 1 : 0), но эта конструкция в старых версиях компиляторов векторизовалась менее надёжно). Если ни во что не попали, то последующий скалярный цикл на 49 итераций можно пропустить, при 80 процентах проходящих мимо лучей эта проверка имеет смысл.
Внутри это реализуется методом, который я описывал выше - векторный счётчик на 8 элементов, который после цикла суммируется в одну переменную, в данном случае компилятор делает это автоматически.
Скалярный цикл по результату своей работы выдаёт номер самой близкой к лучу сферы.
int mj = -1; if (rHitCnt > 0) // checking spheres - non-vectorized loop (because of (s < t)) for (int j = 0; j < SpCnt; j++) //Does the ray hit the sphere ? if (qa[j] > 0.0f) { //It does, compute the distance camera-sphere fltype s = -ba[j] - sqrt(qa[j]); // find the minimum distance if ((s > .01f) && (s < t)) { t = s; mj = j; } }
В оригинальном коде здесь же считалась и нормаль к сфере - то есть она могла считаться несколько раз, хотя нужна только одна нормаль. Наверное, Пол Хекберт выбрал не совсем оптимальный вариант, чтобы сэкономить место на визитке. Но нам-то место экономить не нужно, и я позволил себе небольшую алгоритмическую оптимизацию, которая, впрочем, мало на что влияет (большинство лучей если и попадает в сферу, то в одну).
Также в оригинальном коде всегда делается проверка попадания в пол, хотя если мы попали в сферу, то очевидно, что до пола луч уже не дойдёт. Это я тоже исправил, и опять-таки эффект очень небольшой из-за простоты проверки и малого процента попаданий в сферы. Основное ускорение ожидается от векторизации:
|
|
|
|
|
|
...и оно есть, 1.5-2.2 раза, смотря как считать, по максимуму относительно base или более честно, относительно 1D-array. С одной стороны, это довольно скромно, ранее я отказывался от потенциального ускорения в 1.5 раз как слишком слабого. С другой - это явно больше, чем интринсиковые 10%, и при этом код остался простым и читабельным. Сохранена портабельность на разные платформы и компиляторы, кроме специфичного для gcc/Clang attribute ((aligned(32))), но это легко поправить. Общий размер кода tracer увеличился в 1.5 раза, для SIMD-оптимизации это очень незначительный прирост.
Бонус-трек: широко известный в узких кругах маньяков-оптимизаторов wc можно ускорить аналогичным образом (векторный цикл - строки 205-251 в ассемблере).
Тестировал давно, ускорение вроде было 1.6 раза, что возможно меньше, чем у других SIMD-реализаций, но зато сохранён оригинальный алгоритм, у других никакого Левенштейна нет и в помине.
3. Третья попытка. Векторные расширения
Когда я думал о дальнейшей оптимизации, меня всё-таки смущал скалярный цикл на 49 итераций, пусть даже легковесный и относительно редко выполняемый. Хотелось от него избавиться, и поэтому я решил сделать вариант на векторных расширениях с реализацией условия if (q > 0) "SIMD-джампом", что позволит объединить циклы.
Что такое векторные расширения? Это расширения языка, которые позволяют писать на CPU в "шейдерном" стиле:
float4 a = {1, 2, 3, 4}; float4 b = {5, 6, 7, 8}; float4 c = a + b; // c = { a[0] + b[0], a[1] + b[1], a[2] + b[2], a[3] + b[3] } = {6, 8, 10, 12}
То есть вместо интринсикового _mm_add_ps(a, b) можно писать куда более читабельное и естественное a+b, при этом оно компилируется в ту же самую инструкцию (v)addps. Возможно, на простых примерах не очень впечатляет, но представьте мало-мальски сложную математику на интринсиках и ужаснитесь. А на векторных расширениях всё будет выглядеть так же или почти так же, как обычный скалярный код.
Заметно упрощаются и различные перетасовки элементов. Это особенно удобно для новичков в SIMD - если нужно, допустим, заполнить 8-элементый вектор двумя скалярными коэффициентами, то мы не лезем в справочник по интринсикам, а прямо так и пишем:
float k1, k2;И получаем вполне эффективный код.
float8 mmk = {k1, k1, k1, k1, k2, k2, k2, k2};
Есть и неинтуитивные моменты, в частности преобразование типов: вместо обычного сишного "(тип)значение" нужно либо расписывать покомпонентно, либо делать цикл, либо использовать специальное заклинание __builtin_convertvector. Причём если Clang во всех случаях выдаёт векторизованный код, то gcc иногда не помогает даже заклинание, векторизацию float[N]<->byte[N] он не осиливает ни в каком виде.
То есть в целом Clang лучше поддерживает векторные расширения, gcc хуже (иногда приходится "патчить" проблемные места интринсиками), а вот "родной" компилятор MSVC, увы, совсем никак. В последних версиях MSVC есть опция "использовать бэкенд Clang", и в разделе тестов я её проверю, но наверное в серьёзном проекте не так просто сменить компилятор. Также есть вариант использовать ICC (он же ставится в IDE MSVC?), который поддерживает gcc-нотацию.
И разумеется, всегда можно слепить некую имитацию, используя перегрузку операторов C++ и получить по крайней мере "естественную" арифметику. Существует и готовые библиотеки, например VectorClass от Агнера Фога, xsimd и пр. Сам я когда-то пробовал VectorClass - в целом неплохо, но раздражает необходимость кроме "просто SIMD" изучать ещё и "SIMD в понимании автора библиотеки" (названия функций, специфический набор этих функций и т.п.). Кроме того, у новичков в C++ со сторонними библиотеками периодически возникают всякие глупые проблемы, поэтому они (мы) предпочитаем векторные расширения "из коробки" :)
Но вернёмся от общих рассуждений к рейтрейсеру.
Чем будет отличаться код на векторных расширениях от заточенного под автовекторизацию? В первую очередь тем, что мы работаем конкретно с "пачками" чисел (в случае рейтрейсера - 8-ками, если считать AVX/float-версию за основную). Вроде бы похоже на интринсики, но есть преимущество: нет жёсткой привязки размера вектора к системе команд. Можно откомпилировать 256-битные вектора под 128-битный SSE и всё будет работать, иногда даже получается прирост за счёт развёртки на 2 (пример: альфа-блендинг картинки, размер типа специально завышен ради развёртки, что давало, если правильно помню, +20%).
Но красивая развёртка получается только если компилятору хватает регистров, а в большинстве случаев наиболее эффективен "родной" размер типа. Также есть возможность откомпилировать код на векторных расширениях вообще без SIMD, не нужно делать отдельную скалярную версию.
Второе следствие того, что фактически мы делаем векторизацию вручную (хотя и с приятным синтаксисом) - нужно обрабатывать "хвост". 49 сфер это 48 / 8 = 6 + 1. Хоть она и одна, но лучше писать для неё цикл, тогда можно с минимальными изменениями пробовать другой шаг векторизации (4, 16).
Приятная новость в том, что поскольку циклы проверки попадания и поиска минимума объединяются, в итоге получим опять-таки 2 цикла.
Но не будем забегать вперёд, начнём с простого - с проверки попаданий, так же как с автовекторизацией:
https://gcc.godbolt.org/z/7z6d77oMY
Что в этом коде примечательного? Объявление векторных типов (строка 30) для Clang я делаю отдельно с использованием OpenCL-стиля, хотя Clang поддерживает и gcc-нотацию с vector_size, но OpenCL-нотация более продвинутая и видимо основная для Clang.
В самой функции, как уже говорилось, мы работаем конкретно с пачками в 8 чисел, поэтому все переменные становятся свосьмерёнными, объявляется структура vector8 (x[8], y[8], z[8]) и функция dot8 для неё, цикл выполняется SpCnt / 8 раз и т.д.
В строке 65 делается сложение скалярной переменной с векторной (p8.x = o.x + Gx8[j]) - да, так можно, причём заполнение вектора значением o.x компилятор сам выносит из цикла.
Результирующий ассемблер очень похож на автовекторизованную версию - те же самые 5 команд FMA на итерацию.
Можно ради интереса покрутить переменную VSize (размер вектора) - c VSize=4 компилятор переключается на xmm-регистры, это имело бы смысл при значительной разнице в частотах между SSE и AVX, но у большинства процессоров она не такая большая. С VSize=16 Clang слегка переглючивает, он выдаёт огромную простыню перетасовок данных в стеке. У gcc получается что-то более читаемое, но есть обращения к стеку в основном цикле - регистров всё-таки не хватает. И полноценного interleaving не получается, когда сдвоенные-счетверённые команды используют каждая свои регистры. Так что ускорения здесь скорее всего не будет, хотя потом протестируем.
Теперь более сложное - второй цикл с выбором мин. расстояния на векторных расширениях. Считаем, что q и b уже посчитаны и передаются извне в массивах.
https://gcc.godbolt.org/z/7r5vrPned
Условие if (q > 0) как редко срабатывающее реализуем "SIMD-джампом" через _mm(256)_movemask_ps, приходится писать именно интринсик, в векторных расширениях нет команды "извлечь биты маски в регистр общего назначения". Сначала у меня был вариант с получением маски сравнения и отрезанием этой маской ненужных элементов:
int8 c = q8 > 0.0f; if (test_bits_any(c)) { <...> s8 = (float8)((int8)s8 & c); <...> }
Я так делал, поскольку опасался вылезания NaN в неиспользуемых слотах. Но и без маски никаких глюков замечено не было, поэтому финальный вариант более простой:if (any_positive(q8)) {...} // any_positive просто возвращает bool
Второе условие - выбор наиболее близкой сферы - сделано методом "смешивание веток true/false по маске". Сначала я использовал для этого интринсик _mm256_blendv_ps, но с современными компиляторами расписанная вручную формула (x1 & mask) | (x2 & !mask) компилируется в ту же самую vblendvps, так что оставлена формула, чтобы не писать несколько вариантов интринсиков под разный размер вектора.
Финальный вариант: https://gcc.godbolt.org/z/661Wcq5aK
Тесты:
|
|
|
|
|
|
|
|
|
|
Получили 14% (а завышенный размер вектора делает только хуже). Не слишком впечатляюще, с другой стороны, можно порадоваться тому, что автовекторизованный вариант достаточно эффективен. Также отмечу, что на старом процессоре с AVX1, на котором я начинал свои эксперименты, прирост был больше (около 40%), из-за более сложной обработки счётчика попаданий rHitCnt в автовекторизованном варианте. В AVX1 нет 256-битных целочисленных команд, для выполнения операций со счётчиком компилятор вынужден переходить на 128-битные регистры, что требует 5-6 команд; а в AVX2 счётчик инкрементируется одной командой.
Длина функции (из-за "хвоста") опять увеличилась, 75 строк вместо 38 оригинальной функции, а если считать со всеми дополнительными декларациями/обёртками, то 124 строки. По крайней мере читабельность хорошая, если не заглядывать в обёртки.
4. Random, многопоточность, тесты
В самой оптимистичной трактовке мы получили ускорение в 4.55 / 1.77 = 2.57 раза - кажется, что это всё-таки маловато для идеального на вид ассемблера с векторными FMA.
Стоит задуматься о том, что же ещё может тормозить. В обсуждениях рейтрейсера на форуме высказывались подозрения о Random, и действительно, если заменить return (fltype) rand() / RAND_MAX на return 0.0f, то всё ускоряется в 2 с лишним раза - отчасти из-за попадания лучей в одно место, но и из-за медленного rand() тоже.
Заменяем rand() на упрощённую функцию, которая генерирует по 8 псевдо-случайных числа на луч, что даёт визуально приемлемый (хотя и несколько другой) результат:
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
В базовой версии влияние Random менее заметно (хотя 30% - тоже не так мало), а в оптимизированной оно вырастает до 2-х раз. И благодаря упрощённому Random мы наконец получили солидное ускорение base/vext = 4 раза. А отличия в картинке - смотрите сами, сможете их разглядеть?

Далее, многопоточность. Почему я взялся за неё в последнюю очередь? Ну вроде как известно, что трассировщики прекрасно параллелятся, и поэтому эта оптимизация мне казалась наименее интересной. Всего-то и нужно, что переделать вывод картинки с файла на массив и воткнуть #pragma omp parallel for на внешний (вертикальный) цикл по пикселям в main (и ещё немного повозиться с линковкой omp). Просто взять и воткнуть... кажется, такое уже было в начале, да?
i5-12400 serial / parallel 0.832 / 0.167 = 4.98
Не так плохо на самом деле, результат близок к кол-ву ядер (6), и можно кивнуть на закон Амдала и успокоиться.
Но если знать, что циклы параллелятся двумя основными методами:
кол-во итерации делится на кол-во ядер и каждый поток/ядро работает со своим фрагментом;
динамическое раскидывание итераций по пулу потоков, более гибкий подход, но даёт некоторые накладные расходы.
...то можно предположить, что по умолчанию omp использует 1-й подход - то есть картинка делится на 12 полосок по вертикали, и эти полоски могут давать очень разную нагрузку, где-то только потолок/пол, где-то много сфер, поэтому потоки отрабатывают за разное время. Значит, нужно переключить на 2-й вариант: #pragma omp parallel for schedule(dynamic)i5-12400 serial / parallel 0.832 / 0.107 = 7.66
Вот теперь таки "прекрасно параллелится", даже гипертрединг помог и добавил 1.66 ядра. Кстати, в форумном архиве на ГитХаб тоже есть многопоточная версия, и она достаточно эффективна - но заметно усложняет код по сравнению с моей практически одной строчкой.
Финальный результат i5-12400 (с упрощённым Random):
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Максимальное "маркетологическое" ускорение base+serial / vext+parallel - 32 раза, более честное 1D+serial / vext+parallel - 20, что тоже неплохо.
А уж 16-ядерный Ryzen 5950 и вовсе отрада маркетолога:
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
76 раз! Ну да, со всеми положенными оговорками...
Интересно, что у обоих процессоров векторизация и многопоточность усиливают друг друга, какая-то у них прямо-таки синергия. У Ryzen особенно заметно, добавляется ещё полтора раза на ровном месте.
Поэтому, хотя по результатам этого раздела поначалу хочется сделать вывод "векторизация нафиг не нужна"... ну ладно, "многопоточность приоритетнее векторизации, потому что даёт бОльшую выгоду при куда меньших усилиях" - да, всё так, при условии, что ваш алгоритм хорошо параллелится. 13 раз определённо лучше, чем 4 - но 76 раз ещё лучше, и получается только соединением того и другого. Так что векторизацию не стоит сбрасывать со счетов.
На красивой цифре "76 раз" мы заканчиваем оптимизацию, хотя потенциал конечно ещё есть, начиная с алгоритмических трюков (например bounding box/rect для букв, чтобы быстро отбрасывать лучи, не попадающие в сферы, или традиционные для графики quadtree/octree) и заканчивая GPU (алгоритм другой, но результат внешне похож, и работает в реальном времени).
5. Компиляторы
Любимая многими рубрика "кит против слона", точнее, пара китов clang и gcc против скромного слоника MSVC. Кроме тестов, я расскажу об особенностях установки clang/gcc под Windows.
|
| |
|
|
|
|
|
|
|
|
|
В соревновании китов лучшим оказывается Clang, причём эффект наиболее заметен на неоптимизированном коде. Хотя в разных поколениях компиляторов бывало по-разному, когда-то gcc давал немного лучший результат (точно не помню, но наверное во времена Clang 5 или 7, когда я начинал эксперименты с рейтрейсером). Так что gcc ещё может себя показать.
У MSVC проблемы начинаются с того, что не поддерживаются векторные расширения - но автовекторизованная версия должна быть не хуже? Нет, обычная autovec-версия не векторизуется и выдаёт 7 секунд, MSVC не нравятся обращения к полям структур, переделайте на обычные переменные (отдельно "радует", что человеческим языком он об этом сказать не может, ищите сами код ошибки).
Ладно, здесь MSVC повезло, у меня уже есть версия с отдельными переменными, и она векторизуется успешно:
https://gcc.godbolt.org/z/fnfedhExM
Векторный цикл - строки 177-203, там развёртка на 2, но по сути это те же 5 FMA-команд на итерацию.
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
Результат близок к gcc в режиме autovec, но возможно это недоработка gcc, он менее активно применяет FMA в этой функции - 3 вместо 5 (хотя оставшиеся 2 заменены на 2 умножения и 1 сложение, вроде бы не так плохо?). И от топовых результатов MSVC всё равно заметно отстаёт, больше чем в полтора раза.
Я также обещал попробовать Clang как бэкенд для MSVC - нужно сначала установить его в инсталляторе MSVC, потом переключить "Набор инструментов платформы" в настройках проекта.
Вариант с векторными расширениями поначалу выдал неверную картинку. Оказалось, что дело в вырезании неиспользуемых слотов после условия if (q > 0), которое я опрометчиво убрал т.к. "никаких глюков нет и так". Пришлось вернуть, хотя оно немного (в пределах 5%) замедляет.
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ну что сказать - почти, почти как настоящий Clang, но всё-таки на 20% медленнее. Вряд ли дело в разных версиях компилятора, если сравнить 13-ю и 14-ю версии в godbolt, результат почти одинаковый, нюансы в паре команд и в скалярном цикле, который не имеет особого значения.
Аналогично по функциональности - ветка с векторными расширениями компилируется, но при этом не работают обращения к элементам вектора как .x, .y - такое ощущение, что откатывается на gcc-стиль вместо "родного".
В общем, мне не очень понравился Clang в версии Microsoft, хотя и понимаю, что для многих привычная IDE куда ценнее всех этих нюансов.
В основных тестах я использовал простую (и несколько архаичную в сравнении с гламурной MSVC) IDE Code::Blocks и установленные через msys2 Clang и gcc.
Code::Blocks - классическое приложение, с ним при желании можно разобраться самостоятельно, а по msys2 поясню подробнее. Это linux-style менеджер пакетов, позволяющий получить под Windows последние версии "свободных" C/C++ компиляторов, на 12.08.2022 это были gcc 12.1 и clang 14.0.6.
После установки msys2 нужно выполнить в консоли команды:
pacman -Syuu // несколько раз, пока не скажет, что обновлять нечего
pacman -S mingw-w64-x86_64-gcc
pacman -S mingw-w64-x86_64-clang
(32-битные компиляторы отдельно: mingw-w64-i686-gcc mingw-w64-i686-clang)
Отладчик тоже ставится отдельно:
mingw-w64-x86_64[i686]-gdb, как вариант, можно поставить
mingw-w64-x86_64[i686]-toolchain, поставит gcc, gdb, но и много всего другого, компиляторы Фортрана и Ады, например.
Потом можно обновлять компиляторы той же командой pacman -Syuu. В IDE указать [путь к msys2]\mingw64 или mingw32.
На этом всё, исходники прилагаются. Надеюсь, было интересно.

