
Исходники: https://github.com/dagster-io/dagster
Документация: https://docs.dagster.io
Лицензия: распространяется под Apache License 2.0
Dagster — это оркестратор, предназначенный для организации конвейеров обработки данных: ETL, проведение тестов, формирование отчетов, обучение ML-моделей и т.д. Как и в большинстве других оркестраторов планирование заданий в нем осуществляется посредством направленного ациклического графа (DAG).
Основной и наиболее известный конкурент Dagster’а – Airflow.
Функционал Dagster'а позволяет нам:
Создавать хорошо структурированные конвейеры на основе кода Python.
Запускать конвейеры по расписанию и по событию.
Отслеживать, мониторить и управлять конвейерами.
Основные абстракции Dagster’а:
Assets (Активы) — это специальная абстракиция Dagster’а, которая состоит из двух элементов – функции, которая генерирует контент и физического объекта, который необходимо где-то сохранить (датасет, файл или модель машинного обучения и т.д.).
Op (Операции) и Job (Задачи) – Ops являются основной единицей вычислений в Dagster’е. Как правило, они выполняют относительно простые задачи, такие как выполнить запрос к БД, что-то посчитать, отправить сообщение и т.д. А Job это группировка Операций в единый в DAG вычислений.
Для демонстрации работы Dagster’а мы разработаем простой пайплайн обучения ML-модели.
Начнем с установки…
Установка
Выполните в консоли следующую команду:
pip install dagster dagit
Она установит:
Dagster – ядро Dagster’а, содержащая все абстракции программные интерфейсы.
Dagit – пользовательский интерфейс Dagster’а для просмотра и взаимодействовать с объектами Dagster.
Новый проект
Создайте на локальном диске папку под новый проект. Перейдите в нее в консоли и выполните команду (далее все консольные команды выполняются из папки проекта):
dagster project scaffold --name my-dagster-project
Она создаст новый проект с дефолтной структурой.
Альтернативно вы можете скопировать структуру с одного из типовых примеров:
dagster project from-example \ --name my-dagster-project \ --example project_fully_featured
С полным списком примеров и их содержанием вы можете ознакомится здесь: https://github.com/dagster-io/dagster/tree/master/examples
Сформированная структура представляет собой пакет Python, который может быть установлен с помощью pip. Это необходимо чтобы установить все зависимости, входящие в пакет. Выполните команду:
pip install -e ".[dev]"
Запустим интерфейс Dagster’а, выполнив консольную команду:
dagit
Dagit по умолчанию запускается по 3000 порту. Откройте в браузере localhost:3000, чтобы полюбоваться пустым интерфейсом Dagster’а :)
Активы (Asset)
Начнем исследование возможностей Дагстера с Активов.
Создайте в папке <project>\assets\ файл phone.py с таким содержимым:
import pandas as pd from dagster import asset, get_dagster_logger from sklearn.model_selection import train_test_split from catboost import Pool, CatBoostRegressor from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
Это заготовка, с необходимыми импортами. Далее мы его будем постепенно дополнять…
Assets это дефолтная папка для хранения всех Активов. Хотя вы и можете разместить их в другом месте проекта.
Добавим в наш DAG три Актива. Дополните phone.py такими строчками:
@asset def df_android() -> None: url = 'https://raw.githubusercontent.com/shanealynn/Pandas-Merge-Tutorial/master/android_devices.csv' df = pd.read_csv(url) df = df.rename(columns={'Retail Branding':'brand'}) df.to_pickle('df_android.pkl') @asset def df_device(): url = 'https://raw.githubusercontent.com/shanealynn/Pandas-Merge-Tutorial/master/user_device.csv' df = pd.read_csv(url) return df @asset def df_usage(): url = 'https://raw.githubusercontent.com/shanealynn/Pandas-Merge-Tutorial/master/user_usage.csv' df = pd.read_csv(url) return df
Здесь мы определяем три Актива просто повесив над функцией, которая генерирует контент, декоратор @asset. Причем два из них обычные – обрабатывают данные и возвращают результат (это стандартный и рекомендуемый подход). А третий ничего не возвращает – просто сохраняет данные на диск (это сделано специально для демонстрации – дальше объясню почему).
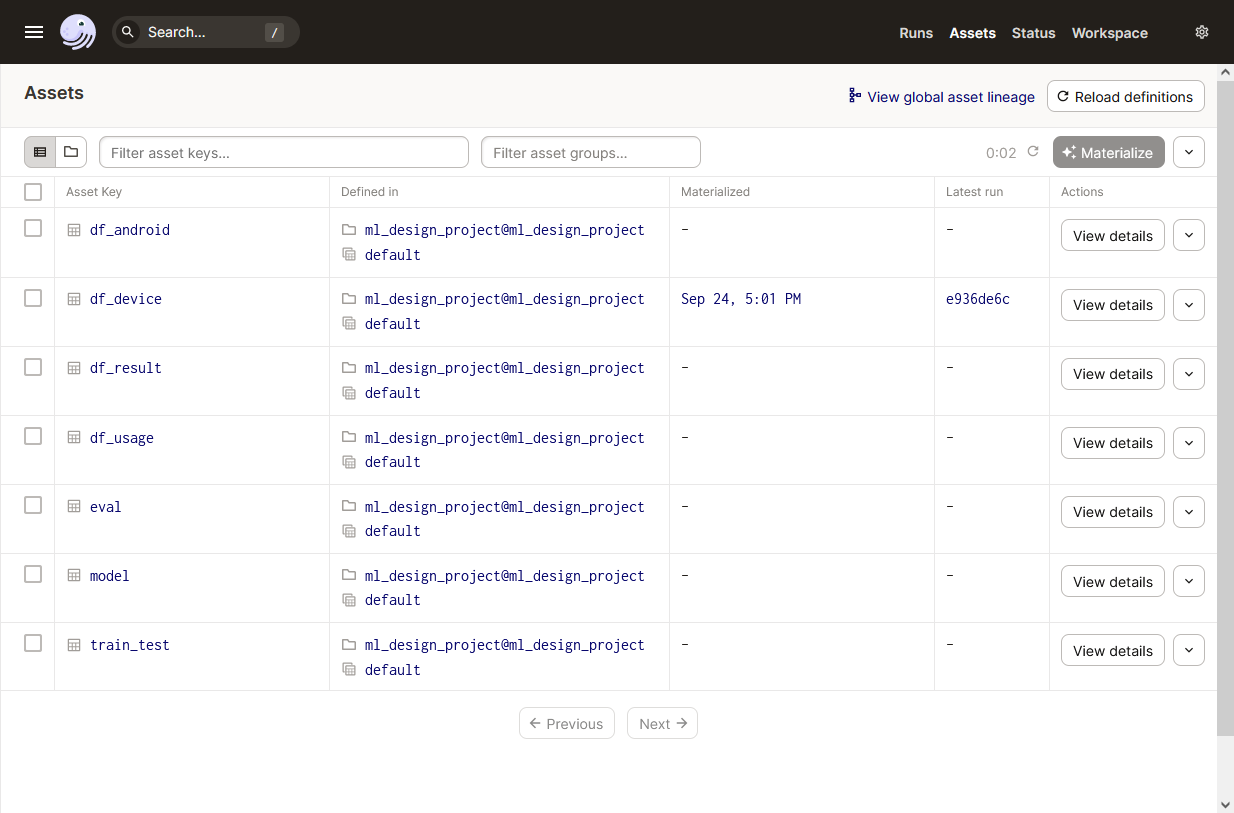
Перейдите в интерфейсе Дагстера в раздел Assets и нажмите Reload Defenitions – вы увидите три Актива.

Провалитесь в Актив df_device и нажмите Materialize.

Материализация Актива означает вычисление его содержимого и последующую запись его в постоянное хранилище. По умолчанию Dagster оборачивает в pickle значение, возвращаемое функцией, и сохраняет его в локальной файловой системе, используя имя Актива в качестве имени файла. После материализации (если Актив возвращает значение) появится ссылка на сохраненный файл.
Где и как хранится содержимое Актива, полностью настраивается. Вы можете хранить их на локальном диске, в базе данных или в облачном хранилище.
Кликните в ID Ran’а и вы увидите подробный лог запуска.

Добавим еще два Актива в .py файл:
@asset(non_argument_deps={"df_android"}) def df_result(df_device, df_usage): df_android = pd.read_pickle('df_android.pkl') df = (df_usage .merge(df_device[['use_id','platform','platform_version','device']], on='use_id') .merge(df_android[['Model','brand']], left_on='device', right_on='Model')) df = df.drop(columns=['use_id','device','Model','platform']) return df @asset def train_test(df_result): train_test = train_test_split(df_result, test_size=0.3, random_state=42) return train_test
Что тут происходит:
df_result – в нем мы объединяем три загруженных датафрейма в один. Поэтому мы определяем, что на вход ему идут три ранее созданных Актива.
Два из них определены напрямую – названия Активов перечислены как входящие параметры функции. И то, что было определено в них на выходе придет на вход текущему Активу. Так мы типизируем зависимости между Активами. При этом Дагстер в фоне сохранит предыдущий актив в хранилище, и подтянет его в зависимый Актив.
Для df_android мы в параметрах декоратора указали, что от него зависим, но ничего напрямую не передаем. Поэтому нам приходится самостоятельно подгружать ранее сохраненный датасет в теле функции. Это сделано просто для демонстрации, потому что в жизни вы не всегда сможете передавать данные между Активми напрямую. Например, очень большие датасеты или если вы используете функционал, который сам производит сохранение (например, консольная утилита разархивирования).
train_test – здесь мы просто делим датасет на train/test. По идее можно было поместить этот код в предыдущий Актив, но тут нужно соблюдать определенную атомарность операций. Если по какой-либо причине Вам потребуется перезапустить только Актив train_test, то Дагстер не будет повторно выполнять предыдущие активы, а просто возьмёт ранее сохраненный файл.Добавьте последние два Актива в .py файл
Добавьте последние два Актива в .py файл
@asset def model(train_test): train, _ = train_test X_train, y_train = train.drop(columns='monthly_mb'), train['monthly_mb'] model = CatBoostRegressor() model.fit(X_train, y_train, cat_features=['brand'], verbose=False) return model @asset def eval(model, train_test): _, test = train_test X_test, y_test = test.drop(columns='monthly_mb'), test['monthly_mb'] y_pred = model.predict(X_test) scores = { 'r2': r2_score(y_test, y_pred), 'MAE': mean_absolute_error(y_test, y_pred), 'MSE': mean_squared_error(y_test, y_pred) } get_dagster_logger().info(scores) return scores
Здесь два Актива – один выполняет обучение модели, второй – оценивает модель на тестовой выборке. Обратите внимание в Активе eval мы добавили рассчитанные метрики в лог исполнения.
В интерфейсе Дагстера на вкладке Assets нажмите Reload Defenitions – Дагстер подтянет все созданные Активы (один из них уже материализован).
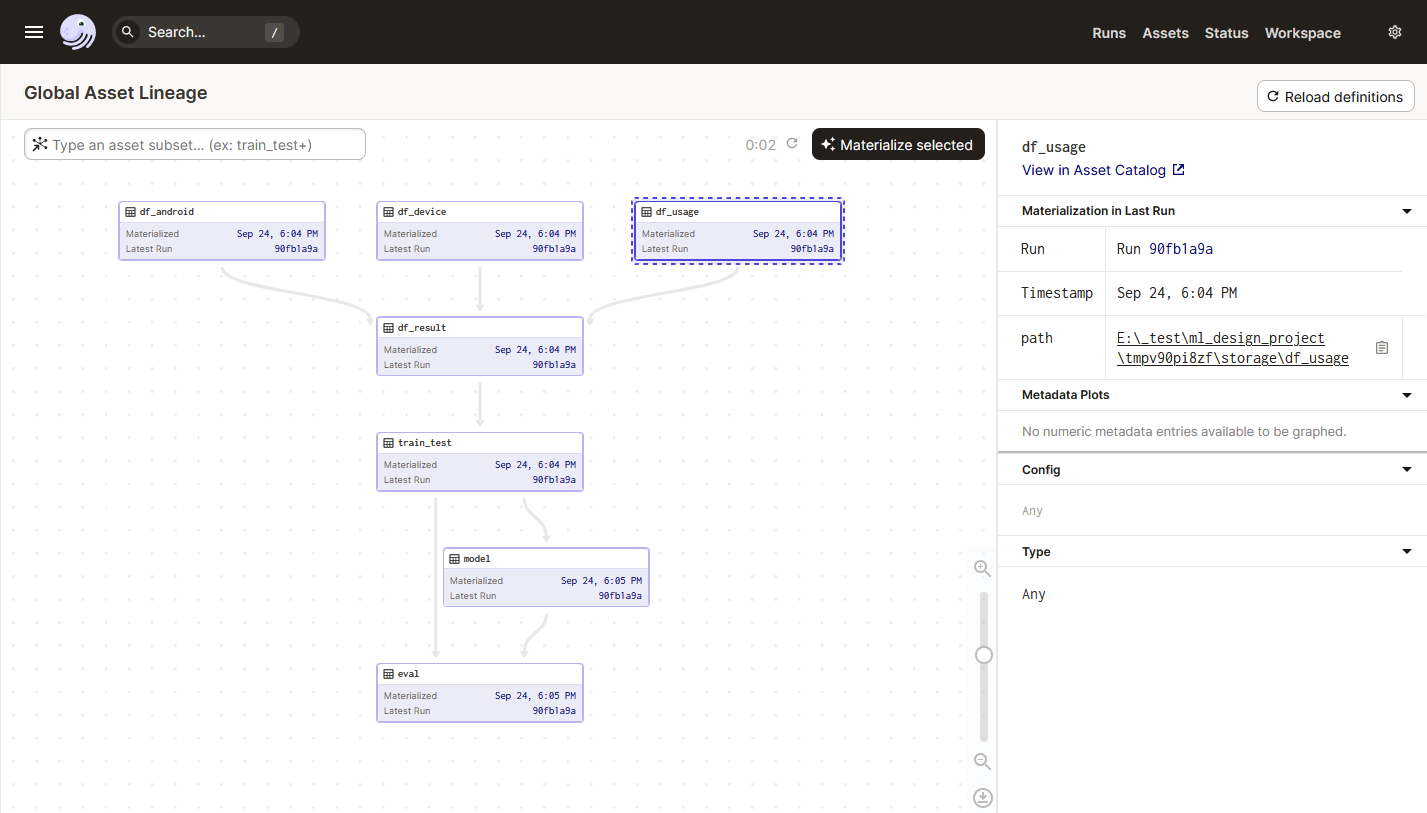
Кликните View global asset lineage – вы увидите DAG взаимосвязей между Актвами. Кликните на Materialize All – Дагстер начнет пересчет всех Активов – строго в заданной (зависимостями) последовательности.
Обратите внимание, что у всех Активов один и тот же ID Run - щелкните по нему и вы увидите лог всего процесса целиком. Тут вы можете выполнять различные фильтрации, чтобы увидеть только то что вам нужно.

По итогу: Активы представляют собой очень интересный функционал, автоматизирующий операции ввода/вывода между задачами и оставляя на вас только написание бизнес-логики.
Из интересных возможностей Активов, рассмотрение которых выходит за рамки данного туториала:
Активы могут рассчитывается автоматически посредством планировщиков и сенсоров.
Материализацию Актива также можно запустить кодом.
Можно материализовать Актив одновременно в нескольких средах хранения.
Если Активы большие, то их можно разделить на партиции и управлять ими по отдельности.
Операции (Op) и Задачи (Job)
Op и Job это еще один уровень абстракции в Дагстере.
Op (Операции) — это минимальные вычислительные единицы в Дагстере, которые объединяются в Задачи (Job). Те же Активы построены поверх Операций, но в отличии от Активов на Операции не возложена функция автоматического хранения и передачи ресурсов между узлами DAG’а.
Op это наиболее близкое понятие к таскам Airflow, хотя между ними есть серьезные различия.
Операции предназначены для простых вычислений:
Выполнение запроса в базе данных.
Запуск Spark-задач.
Выполнение запрос к API.
Отправка электрической почты.
и т.д.
Для демонстрации напишем совсем игрушечный пример:
Создайте в корне проекта файл test_op.py с таким содержимым:
from dagster import job, op, get_dagster_logger import random @op def get_random(): return random.randint(0, 10) @op def get_multi(rnd): return rnd*10 @op def get_plus(rnd): return rnd+10 @op def print_result(multi, plus): get_dagster_logger().info(f'Operation: {multi/plus}') @job def serial(): rnd = get_random() multi = get_multi(rnd) plus = get_plus(rnd) print_result(multi, plus)
Здесь четыре простых Op и один Job, который объединяет их в один DAG.
Выполните в консоли команду (если у вас уже запущен Дагстер, то сначала закройте его):
dagit -f test_op.py
Откройте интерфейс Дагстера (localhost:3000) – вы увидите построенный DAG. Заметите, что мы всего лишь передели параметры на вход функциям, а Дагстер самостоятельно выстроил все связи.

Перейдите на вкладку Launchpad. Большая центральная область предназначения для задания/изменения параметров Задачи (если они предусмотрены) непосредственно перед запуском.
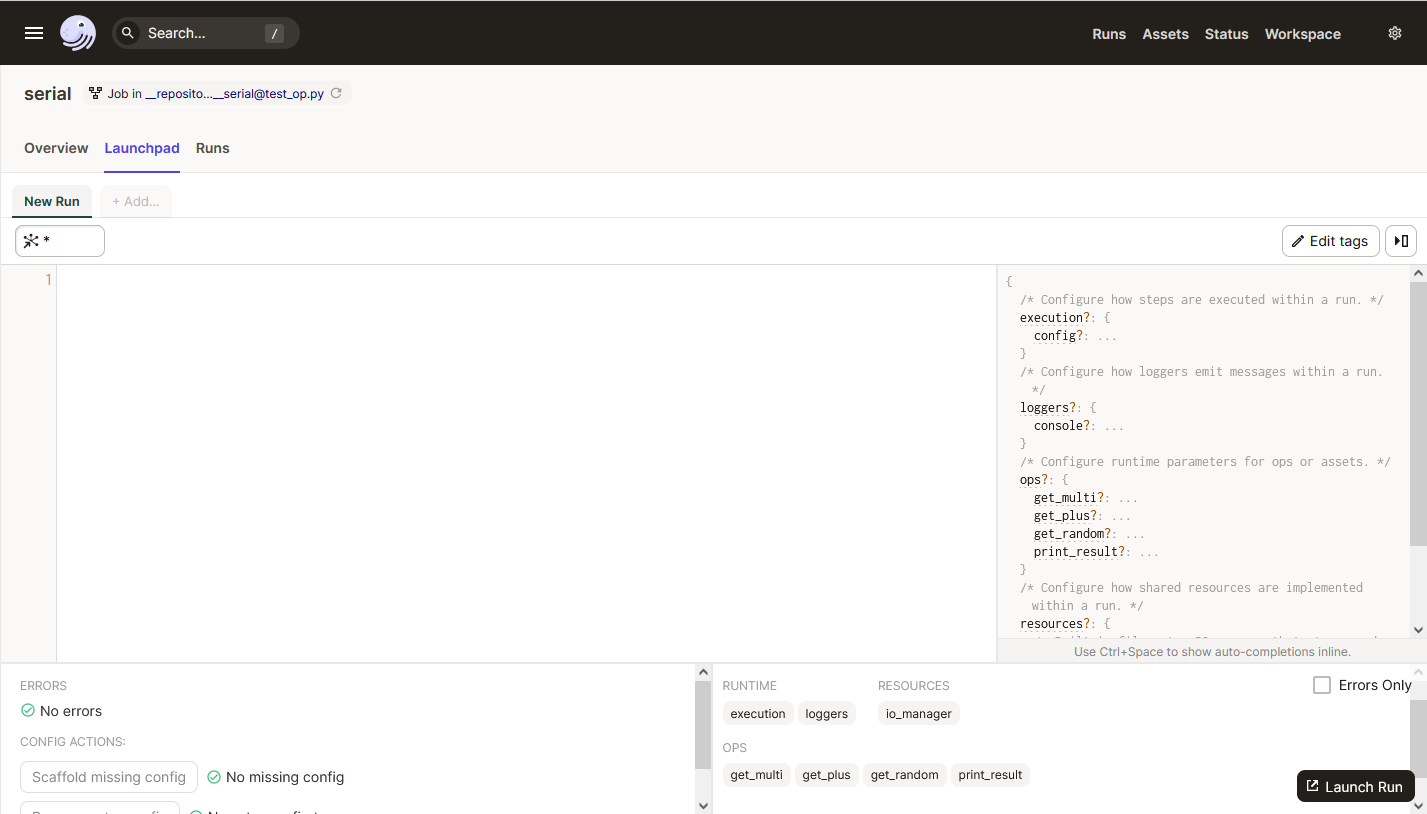
А пока просто нажмите Launch Run – начнется выполнение Задачи в режиме реального времени (с динамическим выводом логов и отрисовкой диаграммы). Здесь такие же возможности фильтрации лога как и в Активах.
Функционал Операций и Задач гораздо шире, включая возможности ветвления, строгую типизацию, тестирование Операций, вывод дополнительно контекста и т.д. Со всем этим вы сможете ознакомится в документации.
Абстракции
Помимо Активов, Операций и Задач в Дагстере много других абстракций:
Schedules (Планировщики) – отвечают за автоматическую выполнение задач по расписанию.
Sensors (Сенсоры) – ждут и реагирую на какое-либо событие, после чего запускают какую-либо задачу.
Graphs (Графы ) – позволяют реализовывать сложные DAG, например, с условным выполнение той или иной ветки DAG’а, с вложенным графми и т.д.
Repositories (Репоизиторий) – группируют Активы, Задачи, Графы и Сенсоры и загружают все это вместе в интерфейс Дагстера.
IO Managers (Менеджеры ввода/вывода) – управляют сохранением Активов в определенных хранилищах.
Run Configuration (Конфигурации) – позволяют настраивать и передавать в пайплан выполнения необходимые параметры.
Интерфейс
Посмотрим какие основные окна есть в интерфейсе Дагстера:
Runs (Запуски) – содержит информацию о всех запущенных DAG’ах.

Assets (Активы) – мы их уже видели :)

Status (Статус) – показывает выполняемые в текущий момент задачи, содержит информацию о текущих сенсорах и планировщиках.
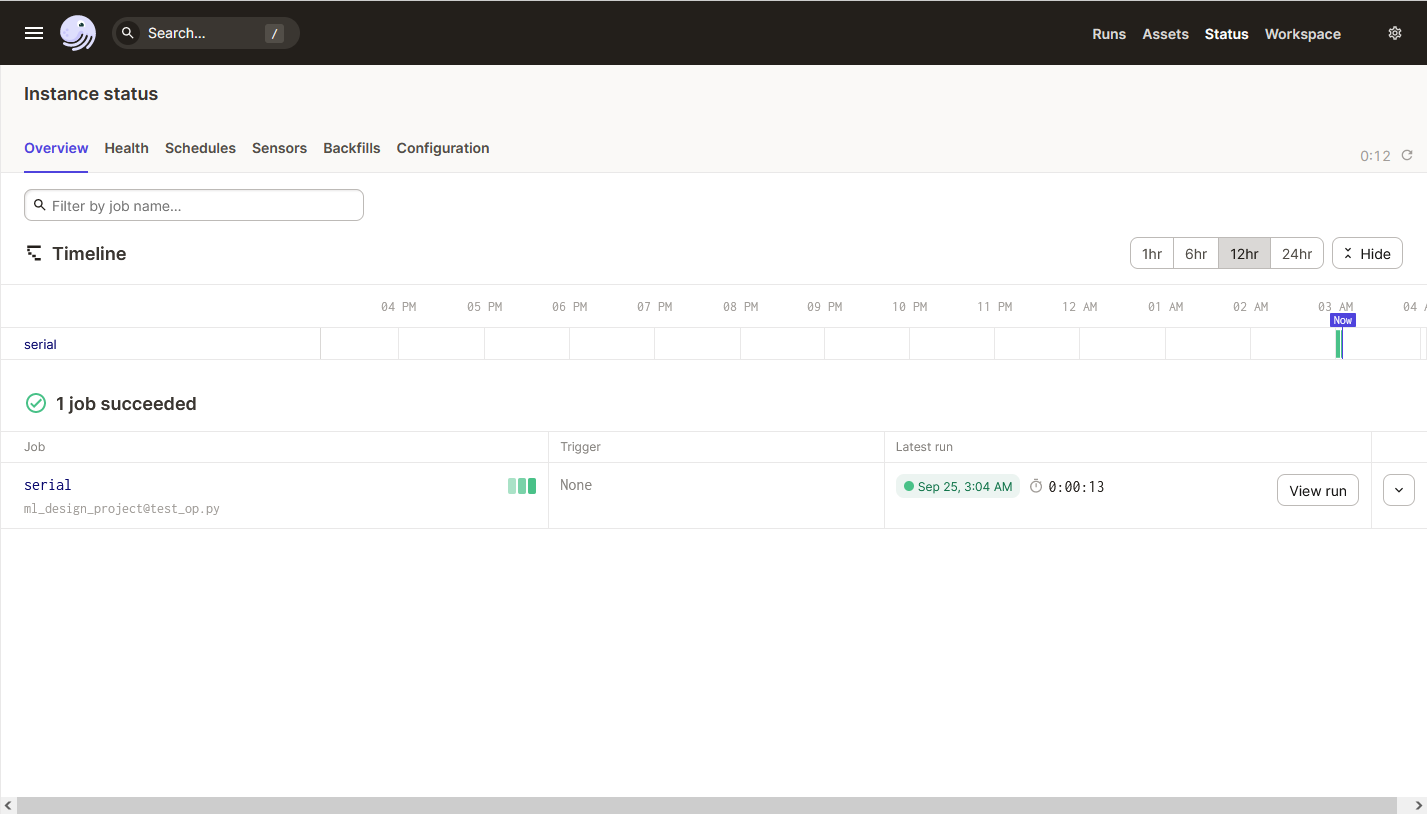
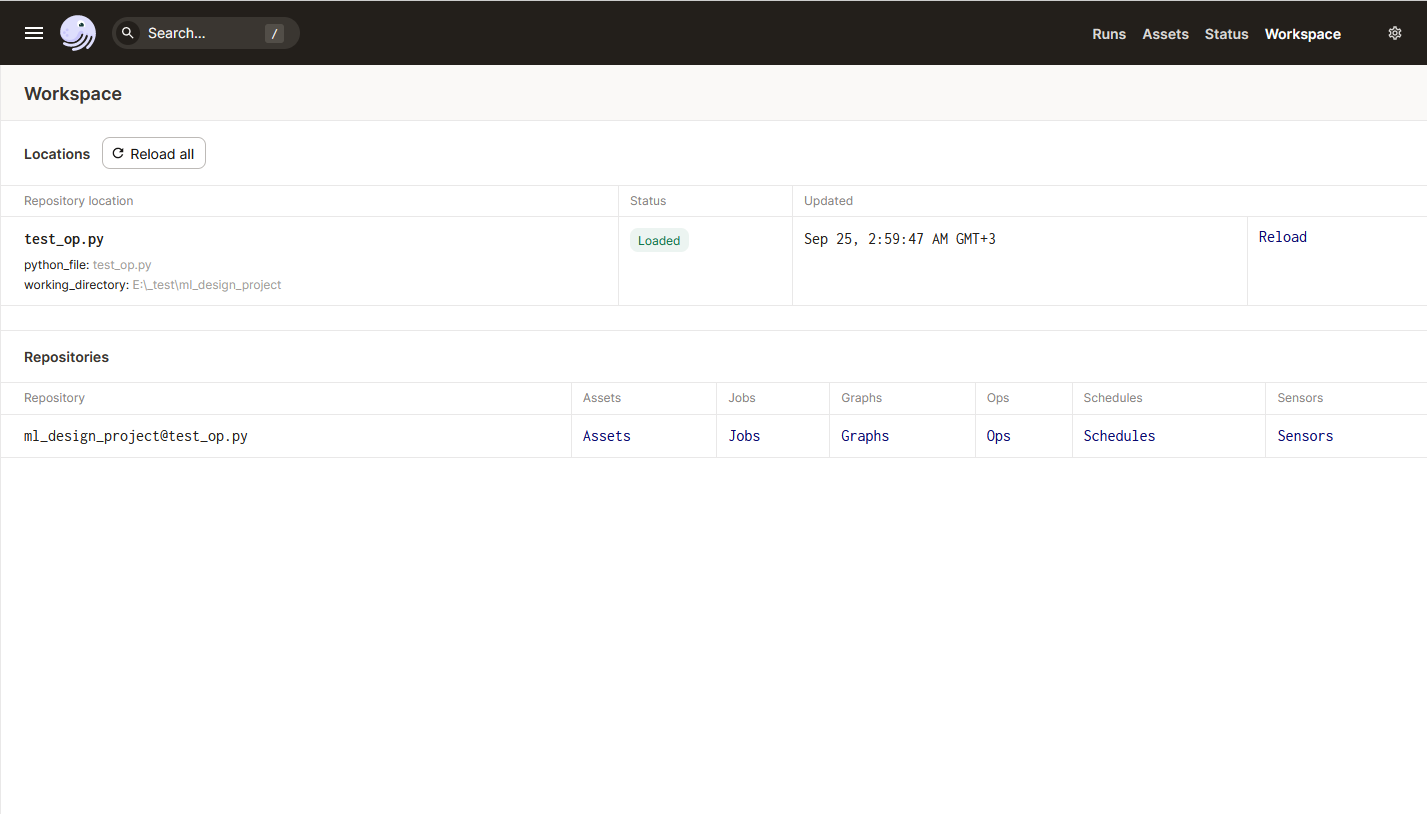
Workspace (Рабочая область) – выводит информацию о всех подключенных репозиториях и их объектах.
Промышленная эксплуатация
Примеры, которые мы запускали выше игрушечные, т.к. Дагстер мы поставим локально и дергали задачи вручную. В продакшене вам понадобится развернуть Дагстер на отдельном сервере: https://docs.dagster.io/deployment/open-source
З.Ы.1. Дагстер имеет встроенную поддержку кучи систем: https://docs.dagster.io/integrations
З.Ы.2. Чтобы разрабатывать и тестировать сенсоры и планировщики локально, откройте еще одну консоль и из нее запустите сервис:
Dagster-Daemon Run
Вывод
По работе я много работаю с Airflow (версии 1.x и 2.x). По сравнении с ним Dagster предоставляет:
На порядок лучший пользовательский интерфейс.
На порядок лучшее логирование и интерфейс взаимодействия с ним.
Лучший способ взаимодействия между отдельными задачами пайплайна.
Позволяет дополнять задачи своими методанными, чтобы отслеживать их свойства в процессе выполнения DAG’а.
Очевидных недостатка пока два:
Слабее развито комьюнити.
Если по Airflow на stackoverflow можно найти ответ практически на любой вопрос, то Дагстером все гораздо скромнее.Подводные камни.
Хотя и декларуют, что в Дагстере очень хорошо разделены системные и пользовательские процессы, что должно повысить стабильность и надежность системы. Но как это все будет работать под реально нагрузкой можно испытать только самому.
Мои курсы: Разработка LLM с нуля | Алгоритмы Машинного обучения с нуля

