
Всем привет! Меня зовут Евгений Симигин, я занимаюсь внедрением DevOps-практик в Центре компетенций по разработке облачных и интернет-решений МТС Digital. В этой статье – обзор Argo Rollouts, я покажу несколько примеров применения и отмечу интересные места в документации. Хотите быстро освоить Argo Rollouts и разобраться в этом решении? Тогда эта статья для вас.

Встала тут передо мной задача организовать A/B-релизы на новом проекте, причем с вот с какими вводными: скорость решения поставлена во главу угла, а CRD использовать нельзя. Первая идея была такой: создать ручные задачи в CI, которые просто будут патчить ingress/services и подменять service/labels. Да, не слишком изящно, но для начала пойдет, а потом докрутим, подумал я.
Немного погуглив, я выяснил, что задачу мне может частично облегчить родной функционал Ingress – canary. Вкратце опишу что это, ведь Rollouts могут работать и с ним. Для использования применяются следующие аннотации:
nginx.ingress.kubernetes.io/canary: "true" – включает механизм;
nginx.ingress.kubernetes.io/canary-by-header: "header-name" – вы попадете на canary,
если выставите заголовок "header-name" со значением, отличным от "never" (кое-где пишут, что нужно ставить "always", но у меня работало с любым);nginx.ingress.kubernetes.io/canary-by-header-value: "value" – работает в паре с
предыдущей аннотацией и задает строгое значение заголовка;nginx.ingress.kubernetes.io/canary-by-header-pattern: "pattern" – значение задается
паттерном;nginx.ingress.kubernetes.io/canary-by-cookie: "cookie-name" – при наличии куки с именем;
nginx.ingress.kubernetes.io/canary-weight: "0-100" – в процентном соотношении.
Пример итоговых аннотаций:
nginx.ingress.kubernetes.io/canary: "true" nginx.ingress.kubernetes.io/canary-by-header: canary-version nginx.ingress.kubernetes.io/canary-by-header-value: $release-version nginx.ingress.kubernetes.io/canary-weight: "0"
Приоритет обработки canary-by-header -> canary-by-cookie -> canary-weight.В нашем случае мы будем попадать всегда на canary ingress, при установке заголовка сanary-verion=$release-version, а для перевода части боевого трафика мы будем добавлять canary-weight и наводить суету. Естественно, что есть несколько нюансов:
«канареечный» ingress работает только в паре с основным и деплоится строго после него. Если нет основного или канареечный был создан ранее – не будут работать оба;
нет возможности «поменять местами»: если перенести все лейблы и аннотации – все сломается;
если основному ingress добавить аннотацию nginx.ingress.kubernetes.io/canary – все сломается; :)
если удалить основной ingress – все сломается. Если создадите новый – все будет лежать до тех пор, пока вы не удалите старые canary из предыдущей связки. Хотя в ряде экспериментов удалось пережить пересоздание основного Ingress без последствий (возможно если удаление и создание попадает в один reload конфигурации ingress), но надеяться на это я не стал.
Временное решение на баше выглядит приблизительно так (в процессе, кстати, выяснилось, что jsonpath не обрабатывает условия «И» и пришлось обходить на jq):
#ищем свой канареечный ингресс, и поднимаем ему $WEIGHT, чтобы переключить часть трафика CANARY_INGRESS=$(kubectl -n $HELM_NAMESPACE get ingresses -o json | jq -r ".items[] | select(.metadata.annotations.\"meta.helm.sh/release-name\" == \"$RELEASE\" and .metadata.annotations.\"nginx.ingress.kubernetes.io/canary\" == \"true\") | .metadata.name") kubectl -n $HELM_NAMESPACE annotate ingress $CANARY_INGRESS nginx.ingress.kubernetes.io/canary-weight="$WEIGHT" --overwrite # если мы решили поменять (пропатчить сервис) основного CANARY_INGRESS=$(kubectl -n $HELM_NAMESPACE get ingresses -o json | jq -r ".items[] | select(.metadata.annotations.\"meta.helm.sh/release-name\" == \"$RELEASE\" and .metadata.annotations.\"nginx.ingress.kubernetes.io/canary\" == \"true\") | .metadata.name") CANARY_SERVICE=$(kubectl -n $HELM_NAMESPACE get ingresses -o json | jq -r ".items[] | select(.metadata.annotations.\"meta.helm.sh/release-name\" == \"$RELEASE\" and .metadata.annotations.\"nginx.ingress.kubernetes.io/canary\" == \"true\") | .spec.rules[0].http.paths[0].backend.service.name") CURRENT_INGRESS=$(kubectl -n $HELM_NAMESPACE get ingresses -o=jsonpath='{.items[?(@.metadata.annotations.current=="true")].metadata.name}') kubectl -n $HELM_NAMESPACE patch ingress $CURRENT_INGRESS --type="json" -p="[{\"op\":\"replace\",\"path\":\"/spec/rules/0/http/paths/0/backend/service/name\",\"value\":\"$CANARY_SERVICE\"}]" kubectl -n $HELM_NAMESPACE annotate ingress $CANARY_INGRESS nginx.ingress.kubernetes.io/canary-weight="0" --overwrite
Общий принцип действия: находим наши объекты по аннотациям, выдергиваем имена сервисов и патчим основной ingress. После того, как все подперли костылями «временное» технологическое решение было реализовано, я решил изучить, какие продукты есть на рынке и чем они могут нам помочь.
На просторах интернета чаще всего попадаются Flux/flagger и Argo Rollouts. Flux/flagger считается зрелым продуктом и про него написано много статей, а Argo Rollouts – «догоняющий», информации о нем не так много. Поэтому было принято решение протестировать Argo Rollouts и поделиться впечатлениями с сообществом.
Установку контроллера и консольного плагина рассматривать не будем, она отлично описана в документации.
Архитектура решения (взято из официальной документации продукта):
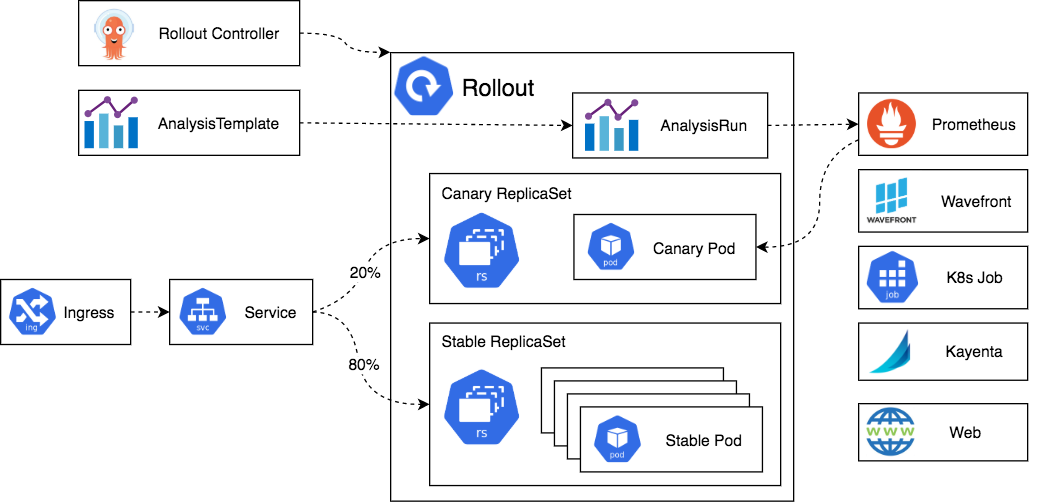
Контроллер обрабатывает наши CRD, запускает инстанс AnalysisRun, который способен анализировать метрики в разных бэкэндах и автоматически манипулирует service/ingress. Тут стоит уточнить, что распределение трафика на уровне сервиса 20/80 работает только на mesh-решениях. В нашем случае распределение будет на Ingress-контроллерах.
В отличии от Argo CD тут нет отдельной системы учетных записей. В нашем случае это огромный плюс: если уeмы хотим затащить подобное решение в коммунальный kubernetes, то разграничение прав будет реализовано родным RBAC и скоро корпоративная команда получит запрос на внедрение :)
Решение поставляет нам 5 новых crd:
Rollout – позиционируется как расширенный deployment. Добавляет новые стратегии деплоя: blueGreen и canary. В процессе выкатки может запускать новые версии в отдельных replicaset, анализировать метрики и принимать решение о дальнейшей выкатке/отмене;
AnalysisTemplate – namespaced-шаблон анализа: метрики, которые будем мониторить;
ClusterAnalysisTemplate – clusterwide-шаблон;
AnalysisRun – инстанс задачи анализа, созданный из шаблона. Можно провести аналогию с Jobs;
Experiment – возможность запустить отдельные инстансы приложения и провести сравнение метрик.
Основное отличие Experiment от AnalysisRun – в том, что в первом случае мы разворачиваем сферический инстанс в вакууме и сами генерируем трафик, а во втором – контроллер переключает часть реального трафика пользователей и следит за метриками в системе мониторинга согласно настройкам в Rollout.
Для тестирования возьмем официальные мануалы и репозиторий Rollouts. Первый тест – манифест rollout-bluegreen.yaml, а вот вариант с helm.
rollout-bluegreen.yaml
apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata: name: rollout-bluegreen spec: replicas: 2 revisionHistoryLimit: 2 selector: matchLabels: app: rollout-bluegreen template: metadata: labels: app: rollout-bluegreen spec: containers: - name: rollouts-demo image: argoproj/rollouts-demo:blue imagePullPolicy: Always ports: - containerPort: 8080 strategy: blueGreen: activeService: rollout-bluegreen-active previewService: rollout-bluegreen-preview autoPromotionEnabled: false --- kind: Service apiVersion: v1 metadata: name: rollout-bluegreen-active spec: selector: app: rollout-bluegreen ports: - protocol: TCP port: 80 targetPort: 8080 --- kind: Service apiVersion: v1 metadata: name: rollout-bluegreen-preview spec: selector: app: rollout-bluegreen ports: - protocol: TCP port: 80 targetPort: 8080
Rollout позиционируется как замена deployment и в одном из докладов было сказано, что spec: в пятой строке по синтаксису соответствует (но это не точно) spec: deployment, позже мы попробуем примонтировать configmap и узнаем, так это или нет. Тестирование начнем с механизма bluеGreen – блок, ради которого все и затевалось:
strategy: blueGreen: activeService: rollout-bluegreen-active previewService: rollout-bluegreen-preview autoPromotionEnabled: false
Он отвечает за всю логику наката/отката ревизии, с ним мы и будем экспериментировать. Обратите внимание: в файле содержатся 2 сервиса, но по селекторам они попадают на одни и те же поды. Это не ошибка, в процессе выкатки релизов контроллер будет патчить эти сервисы и добавлять свой кастомный селектор.
kubectl apply -n rollouts -f rollout-bluegreen.yaml kubectl -n rollouts get all --show-labels

# если мы посмотрим содержимое сервисов, то на обоих мы увидим новый селектор ... selector: app: rollout-bluegreen rollouts-pod-template-hash: 6f64454c95 ... # посмотрим статус выкатки через консольный плагин kubectl argo rollouts get rollout -n rollouts rollout-bluegreen

Поменяем тэг у контейнера и применим повторно. Обратите внимание, что apply мержит манифесты и несмотря на то, что контроллер добавил на них селектор, в выводах консоли получаем unchanged:

После наката green-версии появятся новые replicaset и поды. У сервиса, который был объявлен как previewService: rollout-bluegreen-preview поменяется селектор, на тот который выделен красным на рисунке. Status: paused так как мы объявили autoPromotionEnabled: false.
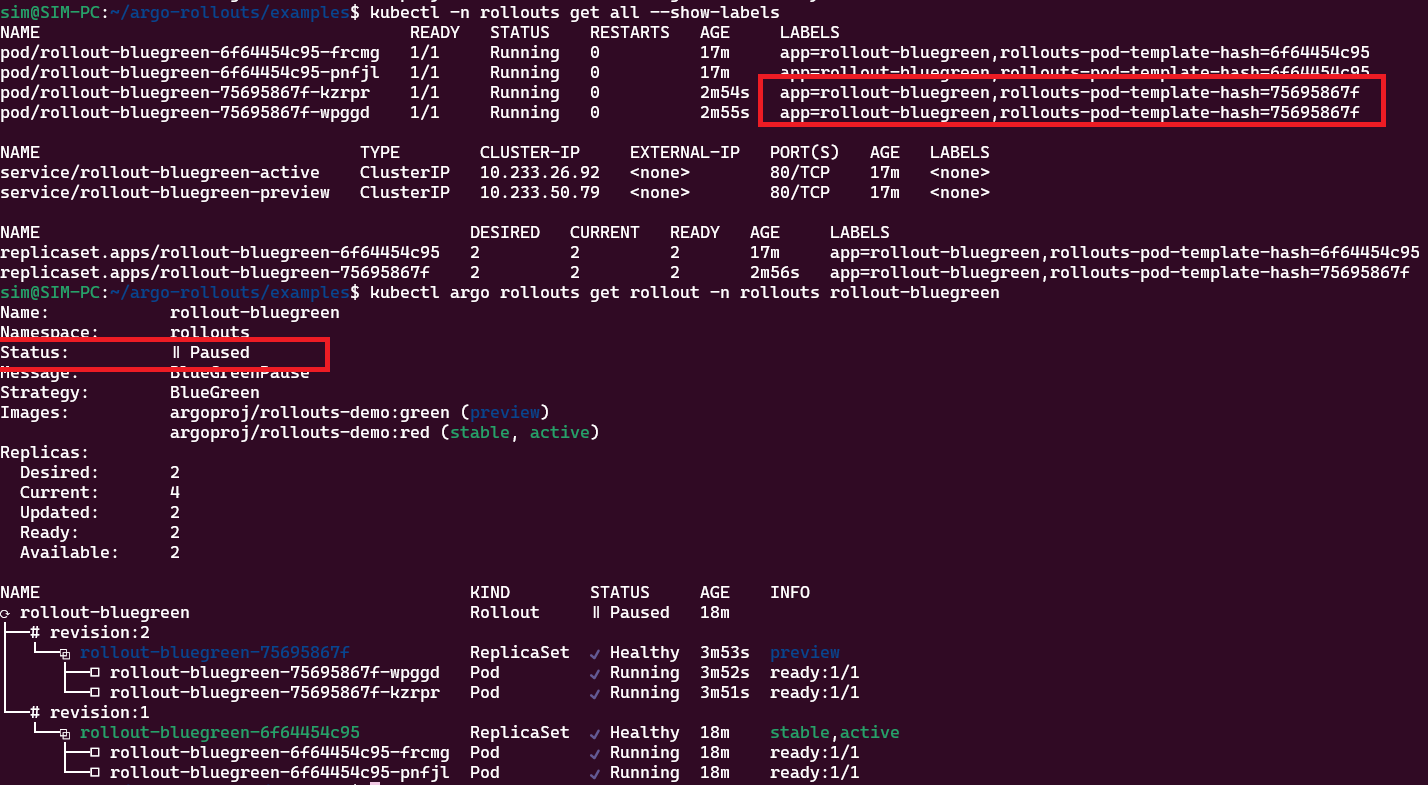
Если я поменяю образ и в третий раз выполню накат – создадутся новые объекты, а объекты второй ревизии будут «скукожены» (ScaledDown, на все уходит секунд 30):


В этом варианте подразумевается, что мы вручную все протестировали и потом вручную переключаем версию kubectl argo rollouts promote -n rollouts rollout-bluegreen:
итоговый вариант
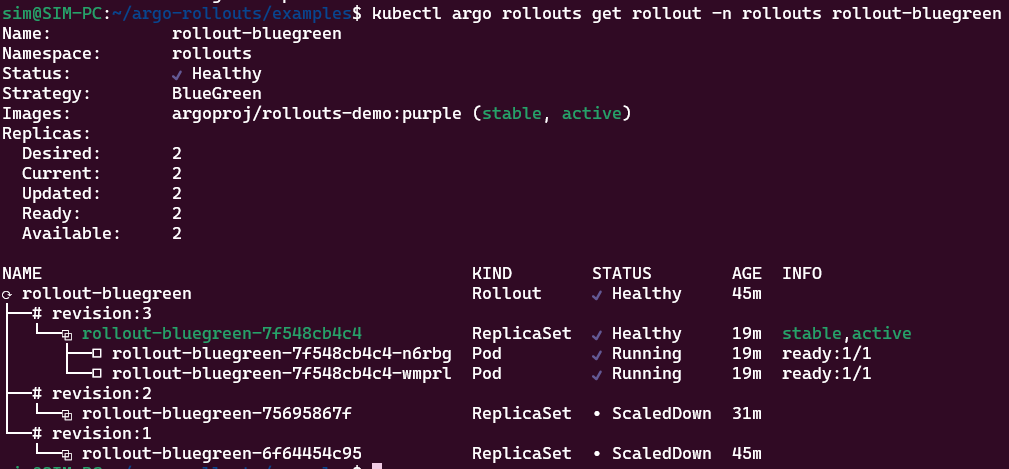
Согласно документации механизм canary действует несколько иначе. В базовом варианте он подбирает лучшее (best effort) соотношение реплик новой и старой ревизии, согласно тому, что вы заказывали. Например:
spec: replicas: 10 strategy: canary: steps: - setCanaryScale: weight: 10 - setWeight: 90 - pause: {duration: 10} # ожидание 10сек - pause: {} # остановка и ожидание команды promote
В этом случае он уменьшит число реплик текущей ревизии до 9 и выкатит 1 новый под, при этом все они будут попадать под селектор основного сервиса. Все становится интереснее, когда мы включаем dynamicStableScale: trueи trafficRouting:
strategy: canary: stableService: rollout-canary-active canaryService: rollout-canary-preview dynamicStableScale: true trafficRouting: nginx: stableIngress: blue-green # required additionalIngressAnnotations: # добавочные заголовки canary-by-header: X-Canary canary-by-header-value: iwantsit steps: - setWeight: 20 # выкатываем 20% новых подов и canary-weight: 20 - pause: {} # встаём на паузу и ожидаем, когда человек скомандует promote - setWeight: 40 # выкатили подов до 40% - pause: {duration: 10} # перекур 10 секунд - setWeight: 60 # погнали дальше - pause: {duration: 10} - setWeight: 80 - pause: {duration: 10}
Основной принцип работы такой же как у blueGreen – меняются лейблы на сервисах. Но в этом случае контроллер автоматически создает canary-ingress (базовый вы создаете самостоятельно). За счет steps у вас более гибкие возможности по переключению клиентского трафика. Помимо Ingress поддерживаются и другие trafficRouting-решения: istio, ambassador, traefik, но принцип работы остается тем же.
Вывод: продукт простой и позволяет автоматизировать ряд действий, которые обычно делаются вручную.
Статья получилась достаточно объемной, вторую ее половину опубликуем через несколько дней. Из нее вы узнаете:
как привязываться к текущим деплойментам и творить с ними чудеса;
как ссылаться на текущие деплойменты и сэкономить время на переписывании манифестов;
а еще мы рассмотрим механизмы анализа и экспериментов (они встраиваются в
steps: и в случае ошибок просто откатят релиз обратно).
Если у вас есть свой опыт работы с rollouts и способы управления релизами имеются – обязательно расскажите о них в комментариях!
