

Привет! Меня зовут Миша, я работаю в Ozon Tech — руковожу направлением базовых сервисов в платформе. Ozon сегодня — это порядка 4000 разработчиков и более 3500 сервисов. Разработка постоянно развивается, количество сервисов увеличивается, и одна из сложных задач — это найти удобный для всех способ управлять тем, что происходит под капотом.
Для этого мы сделали платформу: это внутренние стандарты, сервисы, процессы, инфраструктура для разработки. Можно сказать, что это такой «сервис для продуктовых разработчиков», который предоставляет удобные инструменты во все команды, обеспечивает единообразие подходов в разных командах, помогает внедрять изменения и новые технологии. Для нас платформа теперь — основа для разработки, на ней строятся все информационные системы, и сложно представить Ozon без неё.
В этой статье я расскажу, как и на каких принципах мы построили нашу платформу, зачем она нужна и куда движется. Будет полезно и интересно всем, кто связан с разработкой больших приложений с множеством микросервисов.
История: зачем нужна и как появилась платформа
В 2018 году один мой друг и коллега хотел переходить в Ozon. Я его очень сильно отговаривал, говорил: «Серьёзно? Женя, вот это вот всё тебе надо? Вот эта Windows, этот .NET. Ты будешь что-то переписывать. Зачем?». На тот момент в компании было меньше 100 инженеров, на серверах стояла Windows, были огромные монолиты MS SQL Server с тысячами хранимых процедур и десктопные приложения на Delphi.

В это время в компании происходили большие и важные изменения после смены топ-менеджмента. И вот спустя четыре года мы с Женей вместе работаем в Ozon и продолжаем строить большую и классную компанию. Ozon образца 2022 года — это огромный маркетплейс, на котором продают и покупают всё, что душе угодно. Мы выросли почти в 40 раз. У нас несколько дата-центров и тысячи серверов, а наша система из нескольких больших монолитов превратилась в огромную распределённую систему, которая состоит из нескольких тысяч сервисов, обрабатывающих порядка 3 млн запросов в секунду. Больше никакого Delphi — только современные технологии.

Несколько лет назад мы столкнулись с трудностями: из-за масштабов и сложности разработки продуктовые команды зачастую вынуждены были тратить время на решение технических и инфраструктурных задач. Это увеличивало time to market, негативно влияло на мотивацию и усложняло коммуникацию.
Мы задались целью — сделать так, чтобы каждая продуктовая команда могла заниматься только продуктовыми задачами, не отвлекаясь на инфраструктурные. Чтобы технологии использовались одинаково во всех командах, нужно предоставлять их максимально удобно: с верхнеуровневыми абстракциями и готовыми решениями для самых распространённых кейсов.
Так появилась наша платформа. Это прежде всего набор практик, решений, конвенций, подходов. И это команда, которая занимается поиском и внедрением всего этого. Также мы занимаемся стандартизацией всего и вся — от железа до библиотек и кода. Например, у нас есть механизм для внедрения крупных изменений – сhange management с точки зрения инфраструктуры и кода.
Платформа помогает уменьшать time to market, с ней разработка происходит быстрее и удобнее, а бизнес продолжает эффективно развиваться.
Как устроена платформа: архитектура
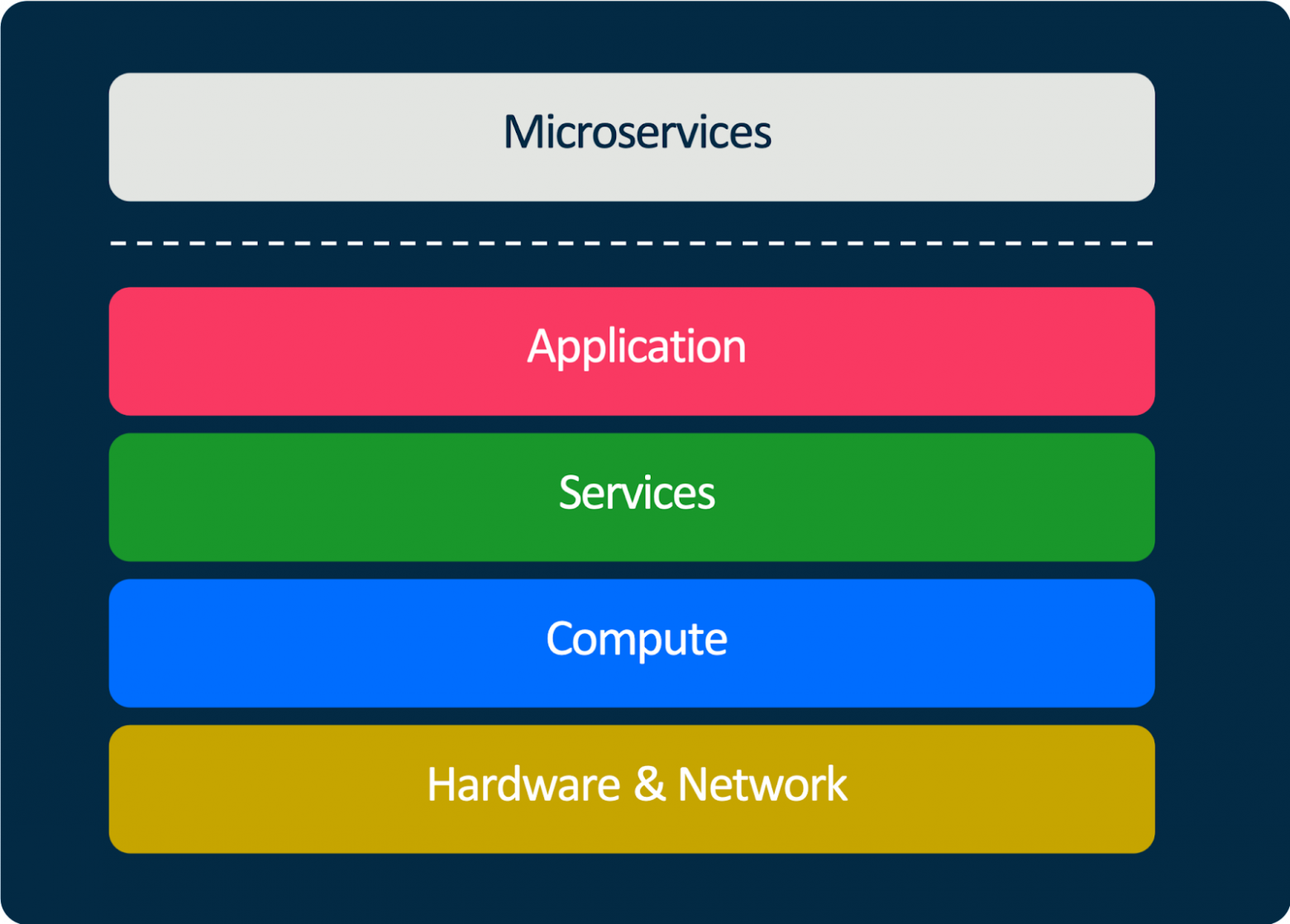
Нашу платформу можно представить в виде нескольких слоёв.
В самом низу находится железо — базовая инфраструктура. Это сеть, это дата-центры, это огромные складские комплексы. И там же ребята занимаются тестированием. Мы тестируем разное новое железо, чтобы понимать, какое оборудование наиболее эффективно использовать в тот или иной момент времени.
На основе базовой инфраструктуры строится вычислительный слой. Это вычислительные мощности: виртуалки, контейнеры и т. д. У нас несколько дата-центров и несколько кластеров Kubernetes. Весь бэкенд, все приложения запускаются в них. Виртуалки мы используем для баз и для решения ряда других задач.
Выше располагается сервисный слой. Это различные сервисы, базы данных, кеши, очереди — всё, чем могут пользоваться прикладные сервисы в своей работе.
Следующий слой — слой библиотек и фреймворков, на основе которых строятся все приложения.
И на самом верху находятся все микросервисы и все компоненты, которые мы строим.
Можно сказать, что платформа — это технологический фундамент, на котором строится весь Ozon.
Конвенции и стандарты
Одни из первых и базовых вещей, которые появились, когда мы начали создавать платформу, — конвенции и стандарты. В большой компании со сложной архитектурой они имеют особое значение.
Как говорится, лучше безобразно, но однообразно. Это, конечно, шутка, но при больших объёмах очень важно находить баланс между однообразием и увеличением энтропии — прежде всего для того, чтобы система не превратилась в хаос и у вас не было огромного количества технологий и языков.
Четыре года назад у нас появился один из основных документов, приближающих нас к этому балансу. Он называется «Конвенция по микросервисам». Между собой мы шутим, что это в некотором роде конституция разработчика Ozon. Этот документ описывает то, как нужно писать сервисы, версионировать API в них, как они должны конфигурироваться, используя различные параметры, и взаимодействовать.
Мы используем gRPC для реализации взаимодействия между сервисами. Для внешних пользователей все сервисы предоставляют HTTP интерфейс, некоторые также используют GraphQL. И вся информация о том, что можно использовать в каком случае, содержится в этом документе.
Также он покрывает очень важную часть, связанную с телеметрией, регламентируя:
+ как он должен писать логи, в каком формате,
+ какие там должны быть обязательные поля,
+ какие метрики сервис должен репортить и в каком виде,
+ как должен работать трейсинг
+ и т.д.
Это суперважно. Без такого документа процесс превращается в хаос, потому что ни в одном техническом споре стороны не могут договориться. А с таким документом всегда можно сказать: «В конвенции написано вот так, поэтому давайте делать так».
Естественно, это не что-то, высеченное в камне. Мы постоянно меняем и расширяем этот документ — он достаточно гибкий.
Помимо конвенции по микросервисам, у нас есть более детальные конвенции по языкам и технологиям, которые её дополняют. В этих конвенциях описаны правила, относящиеся к языкам программирования, например то, какие версии языков и компиляторов мы можем использовать. У нас есть механизм, который позволяет ограничивать набор версий внешних зависимостей библиотек и автоматически обновлять их в сервисах. Также для некоторых языков есть правила написания кода, потому что это же любимое занятие разработчиков — спорить о том, где табы, а где пробелы. Так что к этим конвенциям тоже можно обращаться при разногласиях.
Как платформа помогает создавать сервисы
Мы используем пять языков, на которых пишем бэкенд. В основном это Go, C# и Java — на них пишем сервисы, которые обрабатывают пользовательские запросы. JS и Python тоже есть, они используются в некоторых нишевых проектах. Но глобально весь бэкенд Ozon написан на первых трёх языках.
Для Go, C# и Java у нас есть языковая платформа. Это генератор сервисов, при запуске которого вы можете скормить ему proto-файл, а на выходе получить правильную структуру проекта, все нужные системные файлы, настройки для Kubernetes, GitLab, ещё ряда наших внутренних компонентов. Мы используем gRPC, соответственно, любой сервис имеет описание в формате proto.
Результат работы генератора — базовая реализация имплементации всех методов. У нас полностью сгенерирован весь RPC-слой. Есть gRPC и есть gRPC-Gateway, чтобы предоставлять HTTP-слой. В случаях с Go и .NET они встроены непосредственно в бинарник. В случае с Java мы умеем генерировать сайдкар рядом. Есть Swagger для документации. Есть кастомизация — можно настраивать rate limit и circuit breaker по разным умным правилам. И есть телеметрия на все случаи жизни. То есть, любое взаимодействие сервиса со всем остальным миром покрыто сотнями метрик.
Ещё есть поддержка онлайн-конфигурации. Это очень классная штука. Использовать Twelve-Factor App и конфигурировать всё через переменные не очень удобно, на наш взгляд, потому что конфигурация в этом случае получается статической. А некоторые вещи (даже какие-то системные настройки) мы хотим иметь возможность модифицировать онлайн.
Для этого мы написали небольшую систему, которая позволяет описать все нужные параметры в некоем манифесте — простой YAML-файл. Причём к тому набору параметров платформы, которые мы хотим распространять на все языки, разработчики могут добавлять свои параметры для конкретной бизнес-логики. Это могут быть какие-то коэффициенты, тумблеры и т. д.
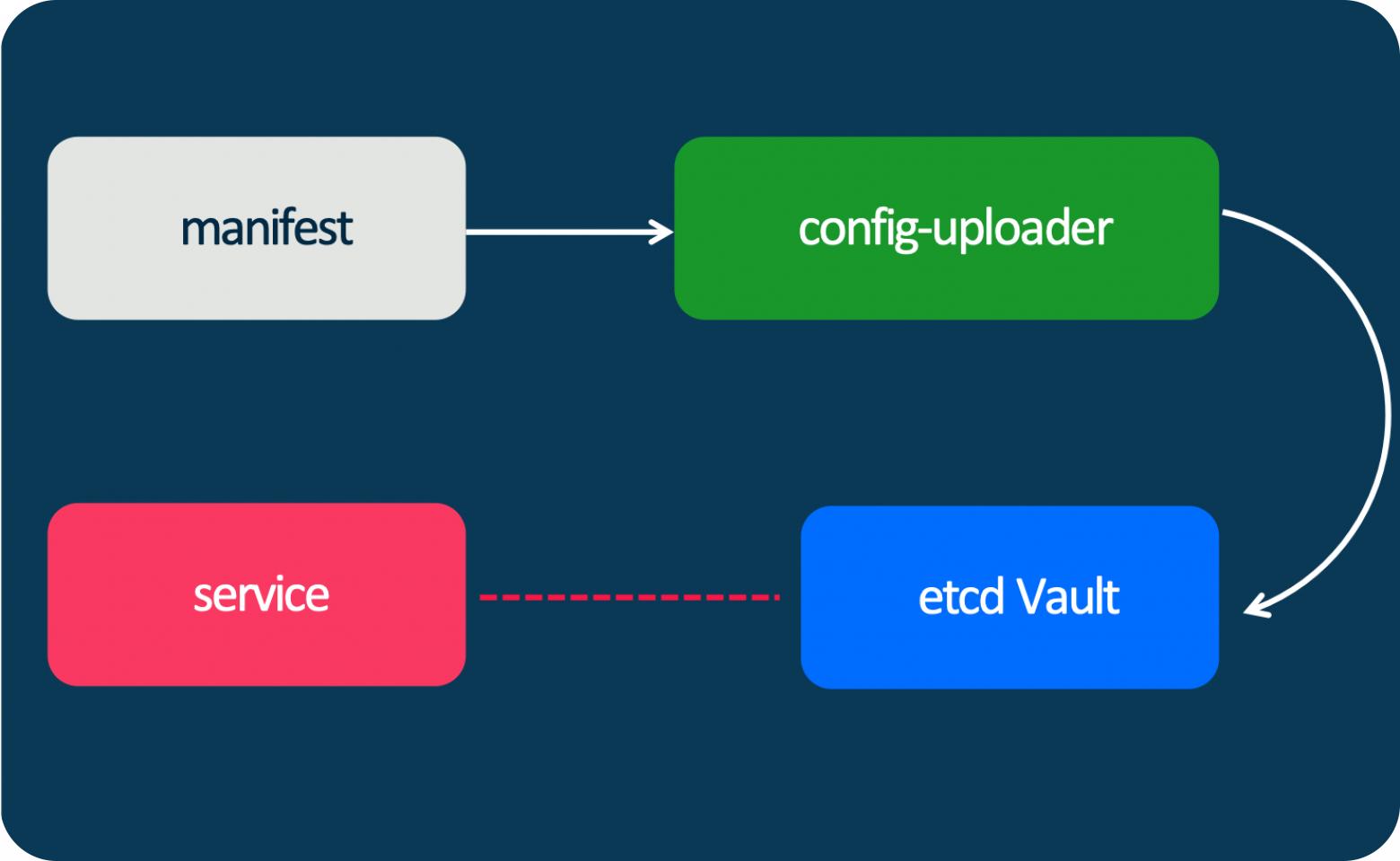
В итоге этот манифест с помощью простой утилиты загружается в etcd Vault, если нужно хранить секреты. Сервис подписывается на etcd и получает информацию о том, что какой-то параметр изменился, — и разработчик может написать очень простой колбэк и что-то сделать внутри своего приложения. А для управления всем этим мы генерируем автоматически веб-интерфейс, в котором есть все параметры. Здесь на скриншоте приведён пример одного из сервисов на Go. Есть параметры, которые относятся непосредственно к рантайму: настройки сборщика мусора, настройки gRPC-сервера и т. д.
Если разработчик добавляет что-то кастомное, у него в интерфейсе точно так же появляется новая строчка. Можно написать какой-то хелпер, можно задать какие-то правила валидации. В общем, поддержка онлайн-конфигурации — очень удобная вещь.
Как платформа помогает налаживать взаимодействие между сервисами
Сервисы не живут в вакууме — они должны взаимодействовать. Для этого нам нужно понимать, какие методы есть у каждого сервиса, как взаимодействовать с ним. Нам нужны клиенты к сервисам. Да, мы используем gRPC, и клиенты легко генерируются. Но вот проблема: у нас 3000 сервисов, 3000 контрактов — где их хранить, какой сервис и каким образом должен генерировать клиенты?
Три-четыре года назад, когда мы начинали работать над этим, всё было очень печально. Мы особо не занимались этой историей, и разработчики делали так, как хотели. У нас вообще не было никаких правил написания proto-файлов. Люди разделяли их на множество файлов, использовали неймспейсы, не использовали… Кто-то генерировал клиенты самостоятельно и мог для Go-сервиса сгенерировать клиент только на Go, а как будет жить какая-нибудь команда, которая пишет на .NET, его мало волновало. Другие копировали proto-файлы из чужого репозитория, то есть просто сохраняли копию файла на какую-то дату. Сервис мог обновляться, но сервис-клиент, естественно, не узнавал про эти обновления. Не работала gRPC Reflection (достаточно важная штука).
В 2020 году сервисов стало так много и это стало такой большой проблемой, что мы поняли: надо с этим что-то делать. Начали стандартизировать процессы написания proto-файлов и генерации клиентов. Мы написали достаточно простую CLI-утилиту Protogen, которая делала нечто похожее на то, что делает менеджер зависимостей для языка. Утилитка парсила proto-файл, понимала, какие в нём есть зависимости (можно специально указать репозиторий и версию для каждой зависимости), рекурсивно резолвила все зависимости, формировала локально дерево proto-файлов и занималась генерацией кода на основе protoc или Buf. Этот шаг позволил нам внедрить первые стандарты.
Т.к. до сих пор в индустрии нету единого подхода к управлению зависимостями proto-файлов, то логика в нашей утилите менялась достаточно часто, потому что находились всякие сложные кейсы и часто приходилось просить ребят обновить . В итоге мы решили сложный кусок, связанный с резолвингом, вытащить из клиента, а сам клиент сделать максимально простым. Написали серверную реализацию Protogen’a, которая работает очень просто: берёт нужный proto-файл и отправляет его на сервер. Сервер осуществляет всю сложную логику и отправляет обратно правильно собранный архив с каталогом proto-файлов правильных версий, который точно сгенерируется нужными плагинами. Очень классно и удобно. Возможно, когда-нибудь мы эту штуку заопенсорсим, потому что эта проблема мало кем решалась до нас.
Для сборки и деплоя приложений мы используем GitLab. У нас есть сложные большие пайплайны для всех языков. На скриншоте приведён пример пайплайна сервисов на Go:
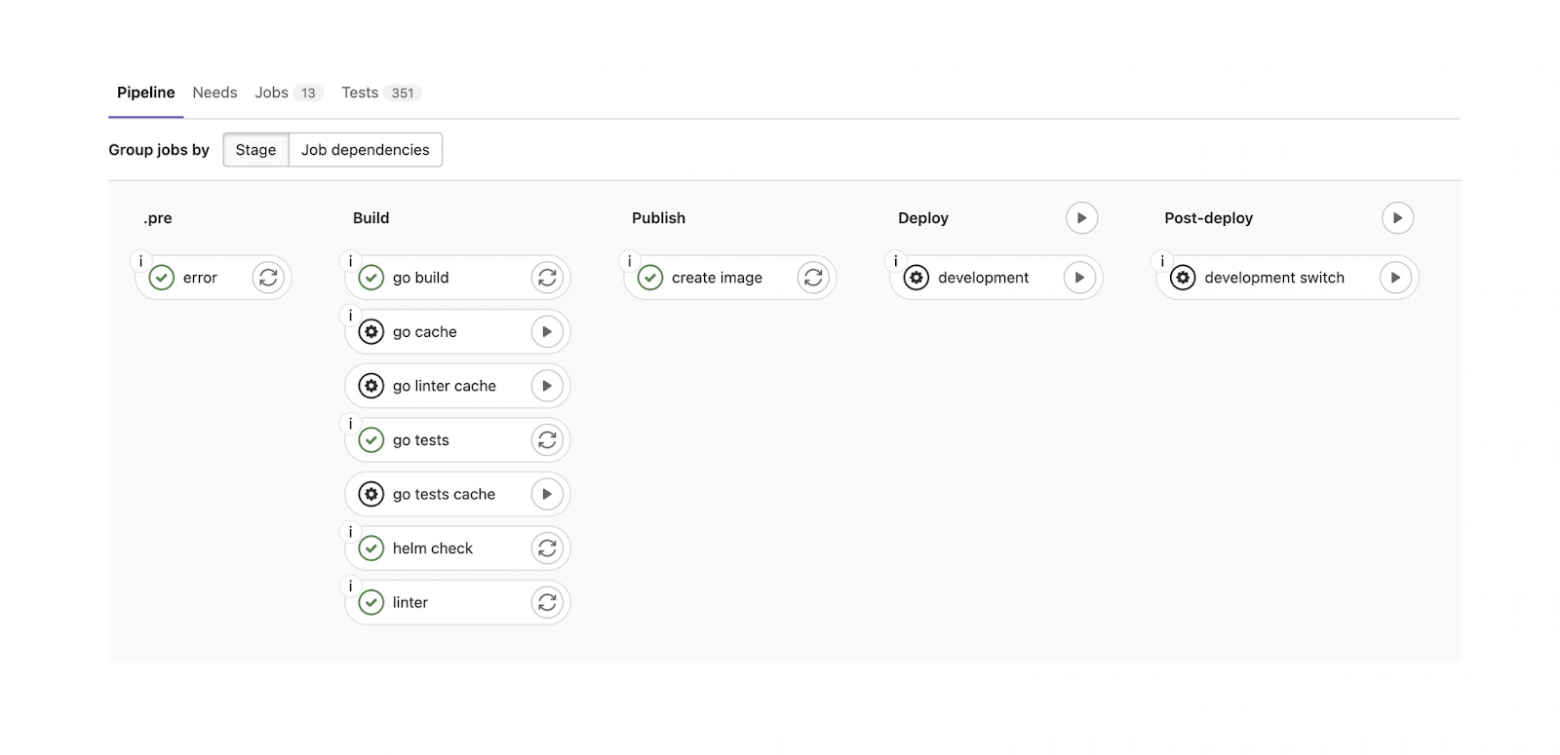
Мы запускаем линтеры, тесты, проверку системных файликов, собираем образы. Можем задеплоить сервис в девелопмент-окружение. Если все проверки прошли, всё хорошо, можно деплоить этот сервис и в продакшен. Для этого у нас есть ещё более объёмный пайплайн, который делает ещё более сложные вещи. Он повторно прогоняет множество тестов и пытается найти секреты в коде (потому что периодически команды оставляют в коде пароли или кладут ключи внутрь репозитория и забывают об этом).
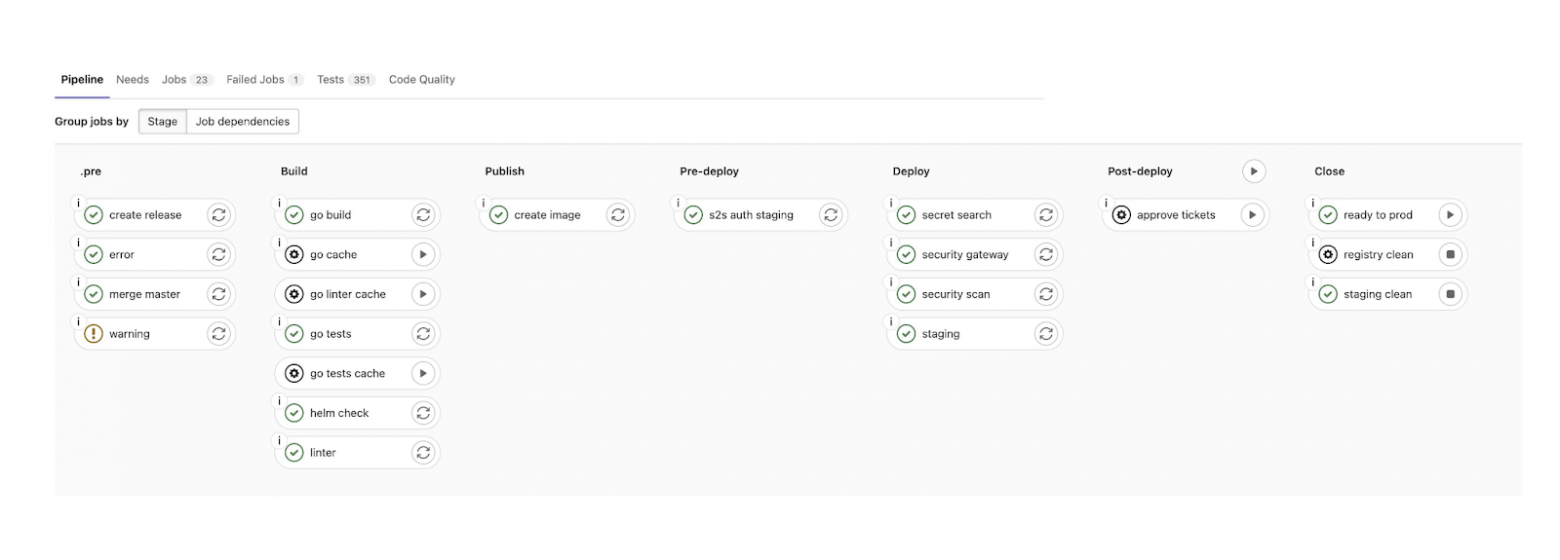
Например, “secret search” обнаруживает такие вещи и говорит: «Сначала удали этот пароль, и только после этого мы будем тебя деплоить». Security Scan проверяет внешние зависимости на наличие каких-то уязвимостей. Эти шаги пайплайна очень сильно нам помогли весной этого года, когда по всем известным причинам нужно было очень быстро и аккуратно оградить себя от внешнего мира, чтобы не скачать какие-нибудь неправильные зависимости и не уронить весь продакшен.
Вообще обо всём, что связано с нашим деплоем, пайплайнами и общими принципами доставки кода в продакшен, есть доклад моего коллеги Дани — не будем погружаться в это здесь.
Service mesh
Мы шутим, что Service mesh — это как подростковый секс. Все о нём говорят, но мало кто это действительно делает. И все это делают очень по-разному. Вот и у нас есть своя реализация.
В далёком 2018 году, когда мы только начинали строить нашу инфраструктуру и у нас появился Kubernetes, мы стали интересоваться, что есть на рынке. Одним из перспективных проектов был Linkerd. Глобально это работает так: у нас есть пользователь, он отправляет какой-то запрос; этот запрос в Kubernetes попадает через Ingress, дальше попадает в первый сервис — и дальше сервисы общаются друг с другом не напрямую, а через Linkerd.
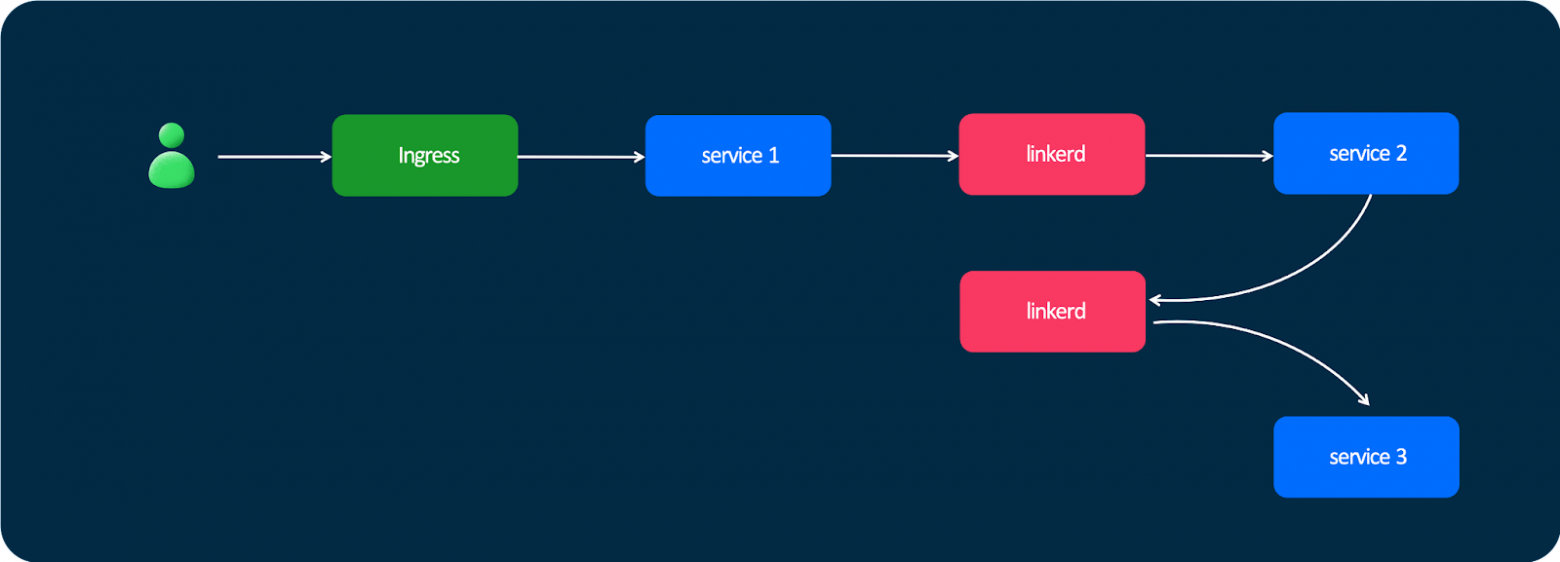
Вроде бы всё классно, но были проблемы. Мы столкнулись с очень большими задержками.
Linkerd написан на Java. Мы принципиально не деплоили его в виде сайдкаров: когда у вас есть маленькие приложения на Go, которые занимают десятки мегабайт оперативки, а рядом — такая Java-история, это не лучший вариант.
Мы сделали для себя вывод, что инструмент классный, его многие любят, но мы — не очень, и отказались от него.
После этого встал вопрос, что делать дальше: сервисам всё равно надо общаться между собой. И мы подумали: «А ведь у нас есть Ingress». Это встроенный в Kubernetes функционал. Какая разница, откуда пришёл запрос: от пользователя или от другого сервиса? И мы переехали на такую схему: пользователь отправляет запрос в Ingress, запрос попадает в сервис — и дальше запросы проходят через такие же Ingress’ы. . Это работает из коробки. Очень удобно.
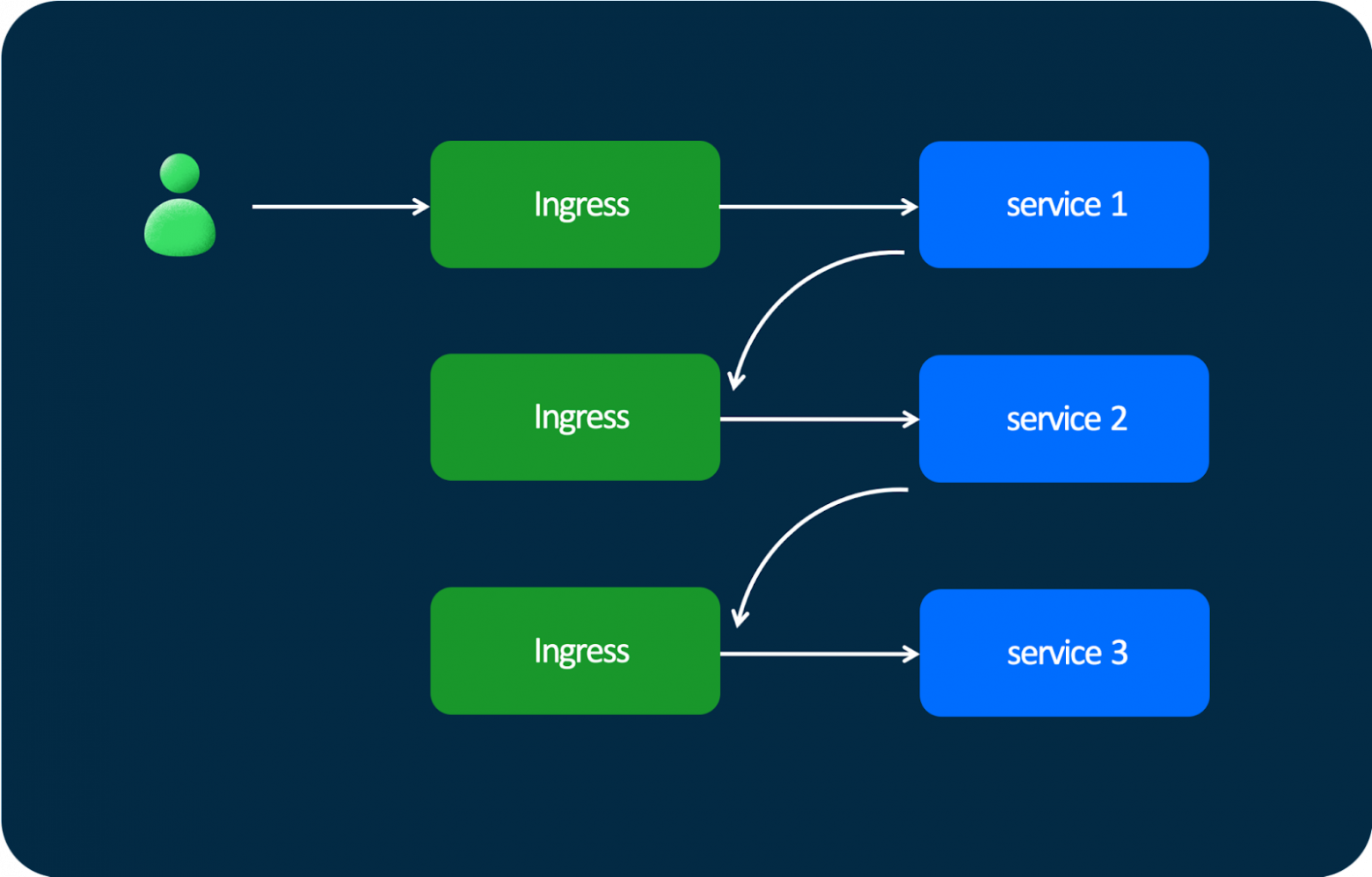
Небольшие задержки есть, потому что есть промежуточные хопы, но нас всё устраивало. Но концептуально так делать неправильно, ведь Ingress должен использоваться только как входная точка в Kubernetes и это очень не нравилось команде куберменов.
Поэтому мы решили написать свою систему для service discovery — Warden. Если коротко, работает она так: есть сервис, который подписывается на кучу событий из Kubernetes, получает оттуда апдейты, строит глобальную карту того, где и как задеплоен каждый сервис (в каком дата-центре, в какой стойке, какая у него версия). А ещё Warden предоставляет очень простой API для других сервисов, с помощью которого сервис №1 может подписаться на изменения сервиса №2 и получать информацию о том, что сервис №2 имеет такие-то IP-адреса и порты. Надёжно, быстро, просто.
В 2020 году мы сделали пилотную реализацию этого проекта — и поняли, что надо его развивать.
Что мы получили? Ingress перестал использоваться как какой-то промежуточный балансировщик — теперь он действительно используется, как и положено для Ingress. У нас нет дополнительных задержек, потому что нет лишних хопов, трафик летает напрямую между подами. И у нас нет никаких sidecar’ов, которые накладывают оверхед (потому что в случае с sidecar’ами количество контейнеров на каждой машине увеличивается, докеру становится хуже). Вся эта логика реализована в виде библиотеки, которая работает с API Warden.
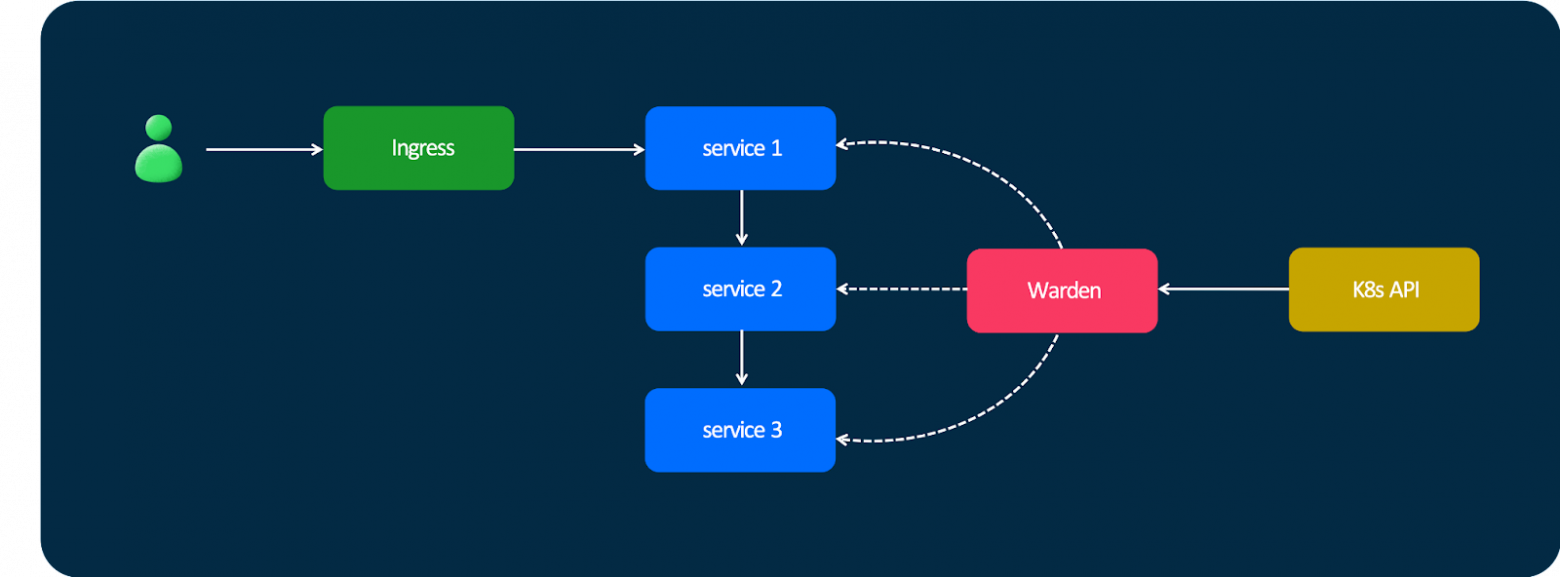
На текущий момент Warden — большая сложная система, которая вышла за пределы сервисов. Она предоставляет единый API для всего, что есть: для баз, для различных кешей (Redis/Memcached). Ещё может дискаверить кластеры Kafka. Она поддерживает разные алгоритмы балансировки: WRR, P2C. Также у разработчиков есть возможность задавать кастомные алгоритмы. И на базе Warden со всеми этими плюшками у нас строятся «канареечные» деплои: мы можем очень удобно вручную тестировать новые версии сервисов.
Мы локализуем трафик. Мы можем настроить систему таким образом, что если трафик прилетает в какой-то дата-центр, то все запросы к другим сервисам будут отправляться в пределах этого дата-центра. Либо можем сделать так, что трафик будет гулять между всеми дата-центрами. Также мы решаем проблему большого количества сервисов. Про subsetting я тоже расскажу ниже.
«Канареечный» деплой на схеме выглядит очень просто. Есть сервис №1 и есть две версии сервиса №2. Мы можем настроить трафик так, чтобы 90% шло в версию А, а 10% — в версию В. При этом с точки зрения API отдаётся IP, а у каждого эндпоинта отдаётся соответствующий вес. Поэтому библиотека внутри сервиса №1 знает, куда сколько трафика отправить.
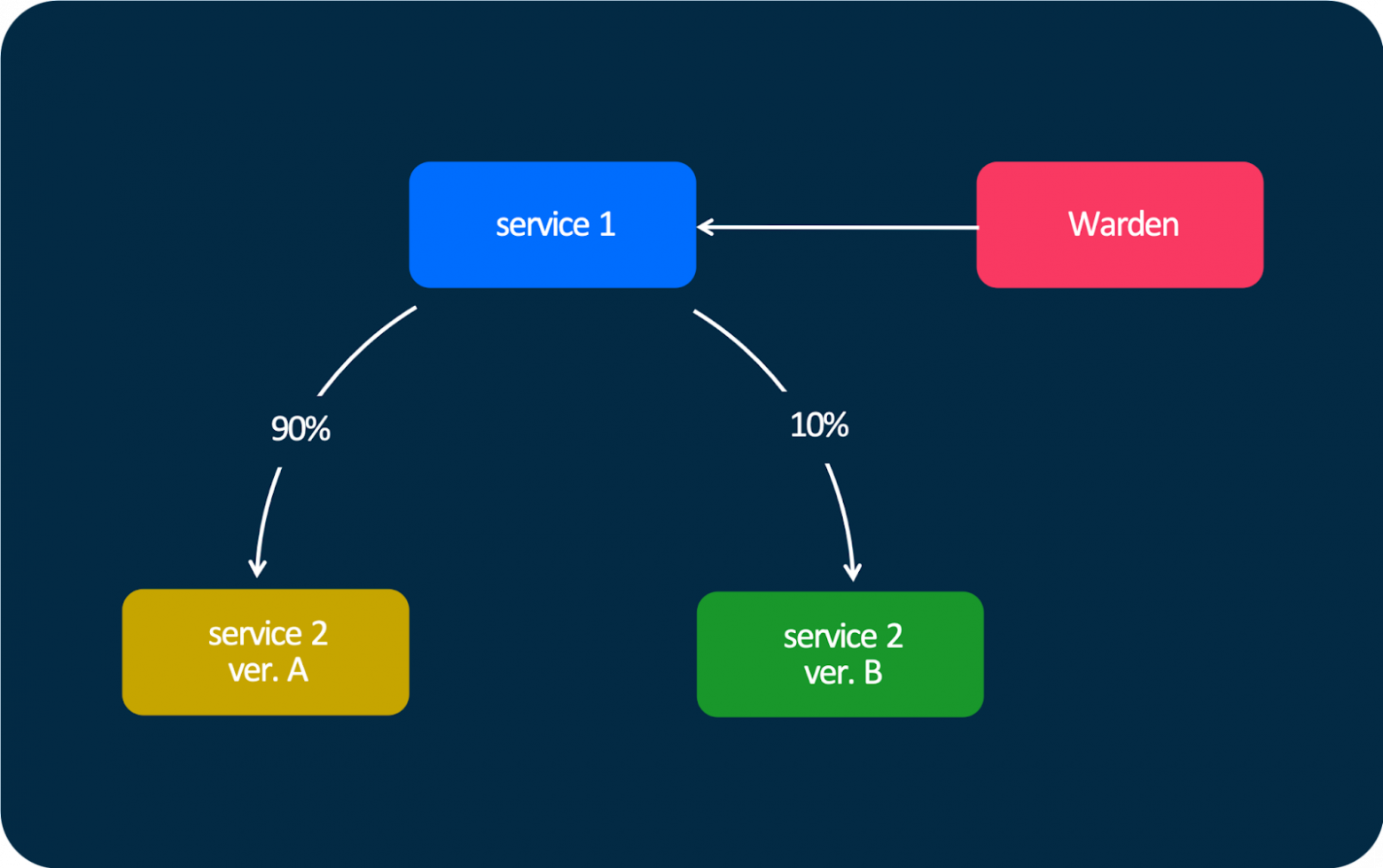
Также есть очень классная штука, которая позволяет принудительно отправить запрос в нужную версию сервиса с помощью специального заголовка — x-o3-meshversion.
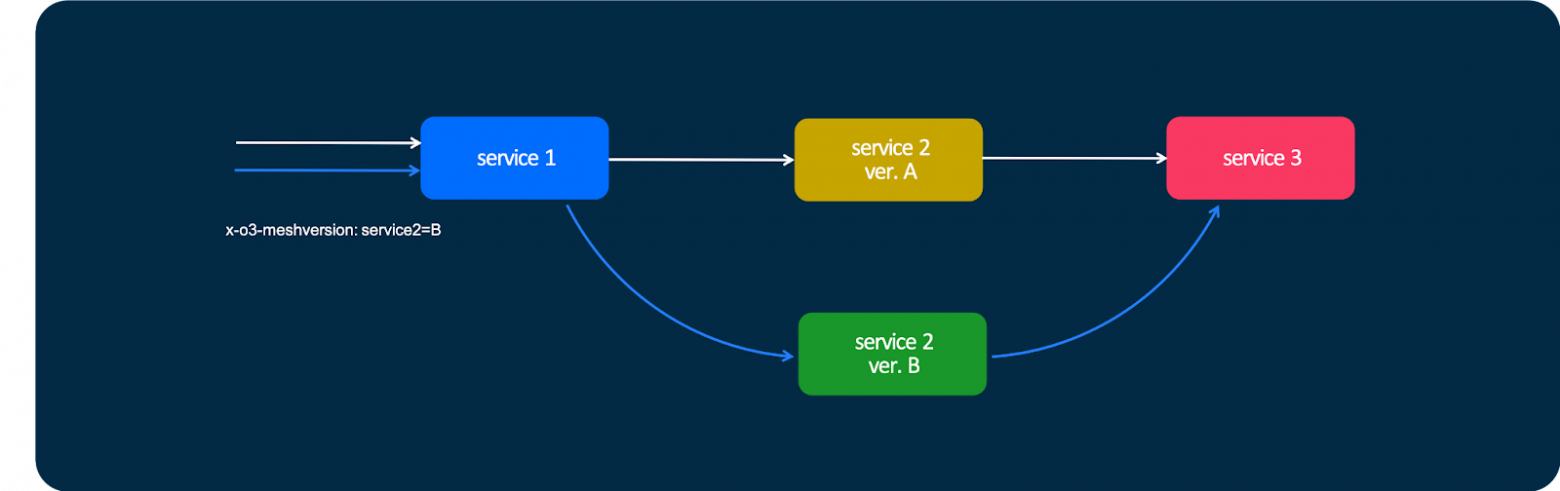
Смысл заключается в следующем: в случае стандартного запроса трафик идёт в сервис №1, в дефолтную версию сервиса №2 и потом — в сервис №3. Но можно сделать так, чтобы для конкретного запроса использовалась не версия А, а версия В. Я могу отправить этот заголовок — и тогда мой трафик пойдёт через другую версию сервиса. Таким образом, мы можем выложить новую версию сервиса в продакшен и, не включая «канарейку», не раскатывая релиз на какой-то процент живых пользователей, потестировать новую версию сервиса самостоятельно. В том числе мы умеем делать это для мобильных приложений.
Эта схема может быть и сложнее. Она работает на любом уровне взаимодействия сервисов. Если граф или цепочка вызовов состоит из десятка или двух уровней, мы можем на любом уровне сказать: «В пятнадцатый сервис пойди по альтернативному пути». И также Warden умеет делать subsetting. Вот пример с несколькими клиентами и многими копиями сервиса №2:
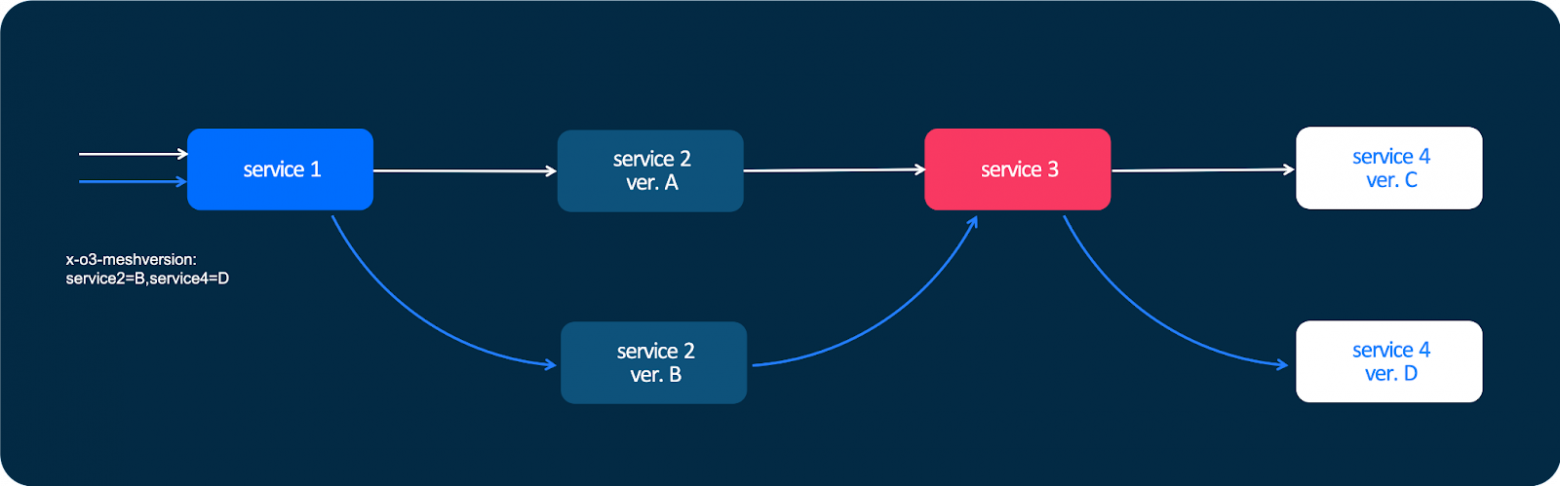
В большой системе, в которой сервисов не единицы, а десятки или сотни, нет никакого смысла устраивать такой full mesh, когда каждый клиент соединяется с каждым сервисом. Это очень накладно. Достаточно каждому клиенту дать какое-то подмножество инстансов сервиса №2, чтобы они взаимодействовали между собой.
Кажется, что это очень простая задача, но на самом же деле алгоритм достаточно сложный — нужно гарантировать, что на каждый сервис №2 будет одинаковая нагрузка. Но это действительно очень полезная штука. При любом TCP-соединении, если у вас 100 клиентов и 100 инстансов, вы получите 10 000 соединений, которые вам на самом деле не нужны. Каждое соединение, независимо от того, на каком языке вы пишете, требует накладных ресурсов. В случае с Go это несколько горутин. В случае с другими языками всё равно появляются какие-то абстракции — хотя бы даже память для обслуживания этого соединения.
Телеметрия
Мы очень любим телеметрию и вкладываем в неё много ресурсов, потому что наша система — очень сложная. В Ozon работают тысячи человек, но никто из нас до конца не представляет, как вся система функционирует в целом, потому что компонентов действительно очень много. Нам, как платформе, нужно предоставлять продуктовым командам большое количество информации, которое поможет им понять, как их сервисы и продукты работают.
Что мы вкладываем в понятие телеметрии? Это достаточно стандартный набор: метрики, трейсинг, логи и continuous profiling.
Давайте начнём с метрик. Мы снимаем системные метрики со всех серверов. Операционная система не имеет значения. Мы снимаем метрики с Kubernetes, с Containerd — со всего, до чего можно дотянуться. Также, если говорить о приложениях, мы сохраняем метрики из рантайма языка. Неважно, это Go, .NET или Java — можно покопаться и получить огромное количество информации о том, что происходит внутри приложения: сколько потоков, сколько памяти, как часто работает сборщик мусора и т. д.
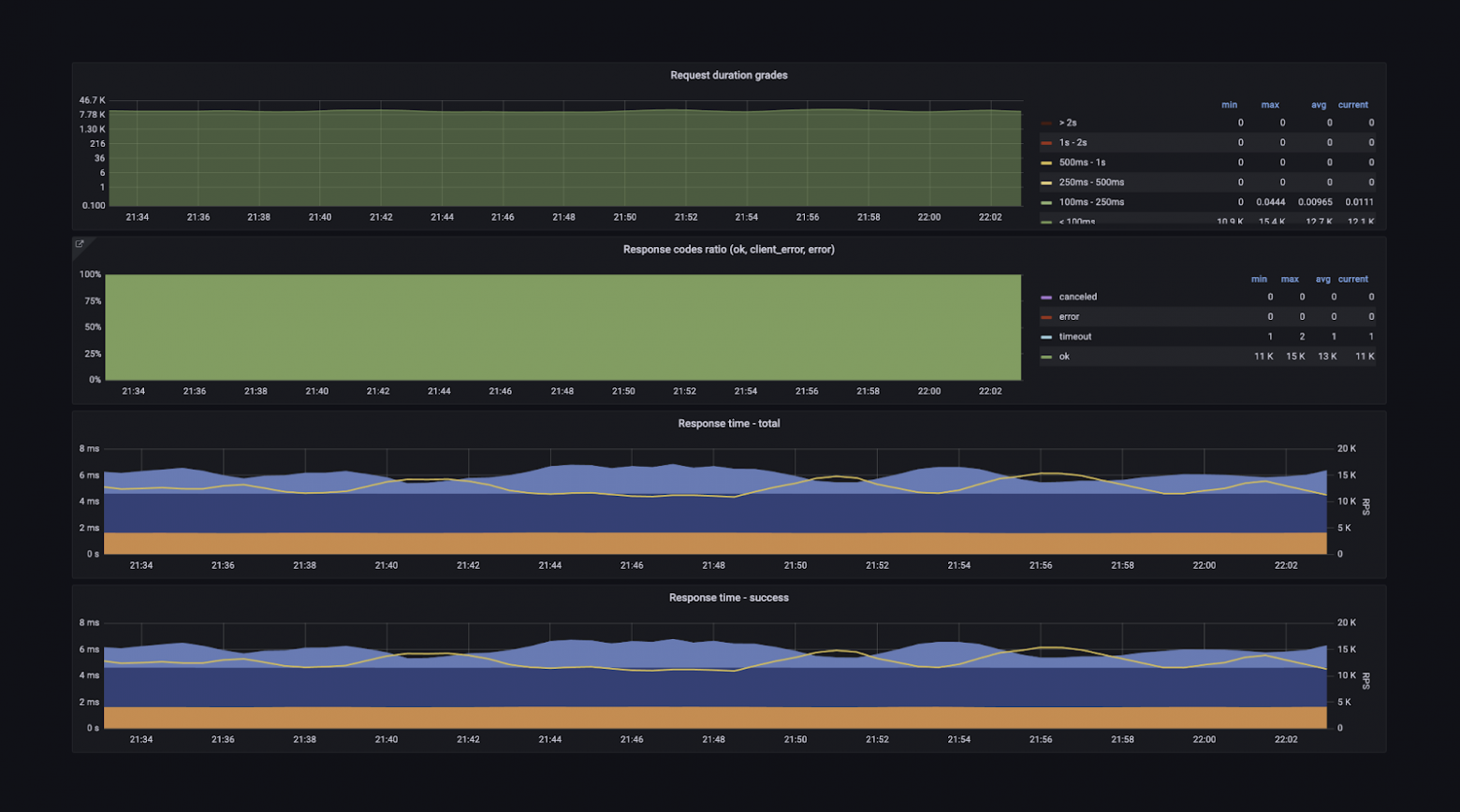
У нас есть суперподробные метрики обо всём RPC-слое (входящие и исходящие запросы), о взаимодействии сервиса с любыми внешними зависимостями. На основе этих метрик (благодаря тому, что они унифицированы и зафиксированы в тех самых конвенциях) мы строим общие дашборды, которыми очень легко пользоваться. Вот пример:
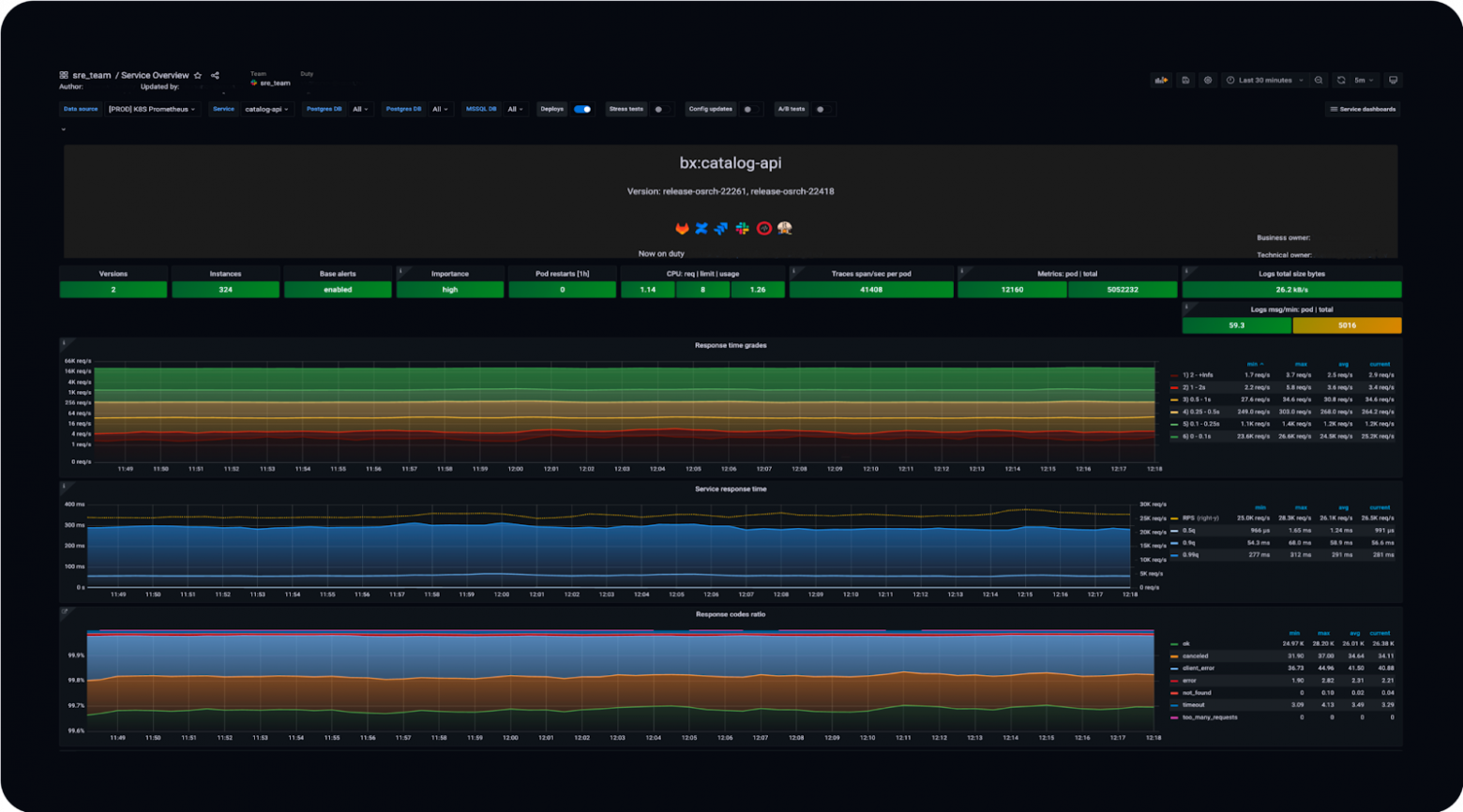
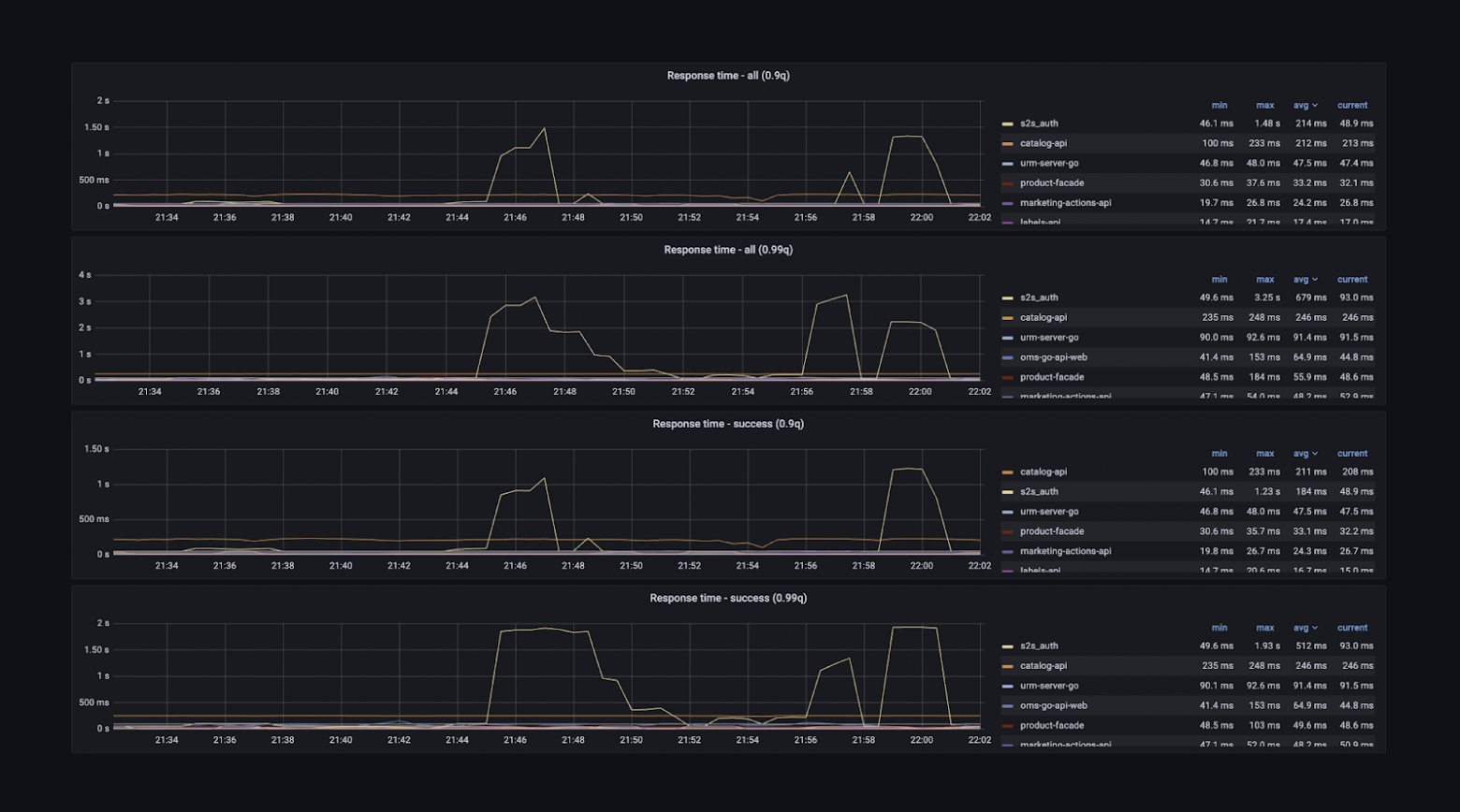
Здесь есть количество RPS, время ответа сервиса в различных квантилях и ещё куча информации — несколько десятков вкладок на все случаи жизни. Можно посмотреть граф зависимостей и понять, кто приходит в мой сервис и в какие сервисы хожу я. Можно получить детальную информацию о хендлерах — понять, что тот или иной хендлер используется, на него приходит 1000 RPS, а на все остальные — 10 000.
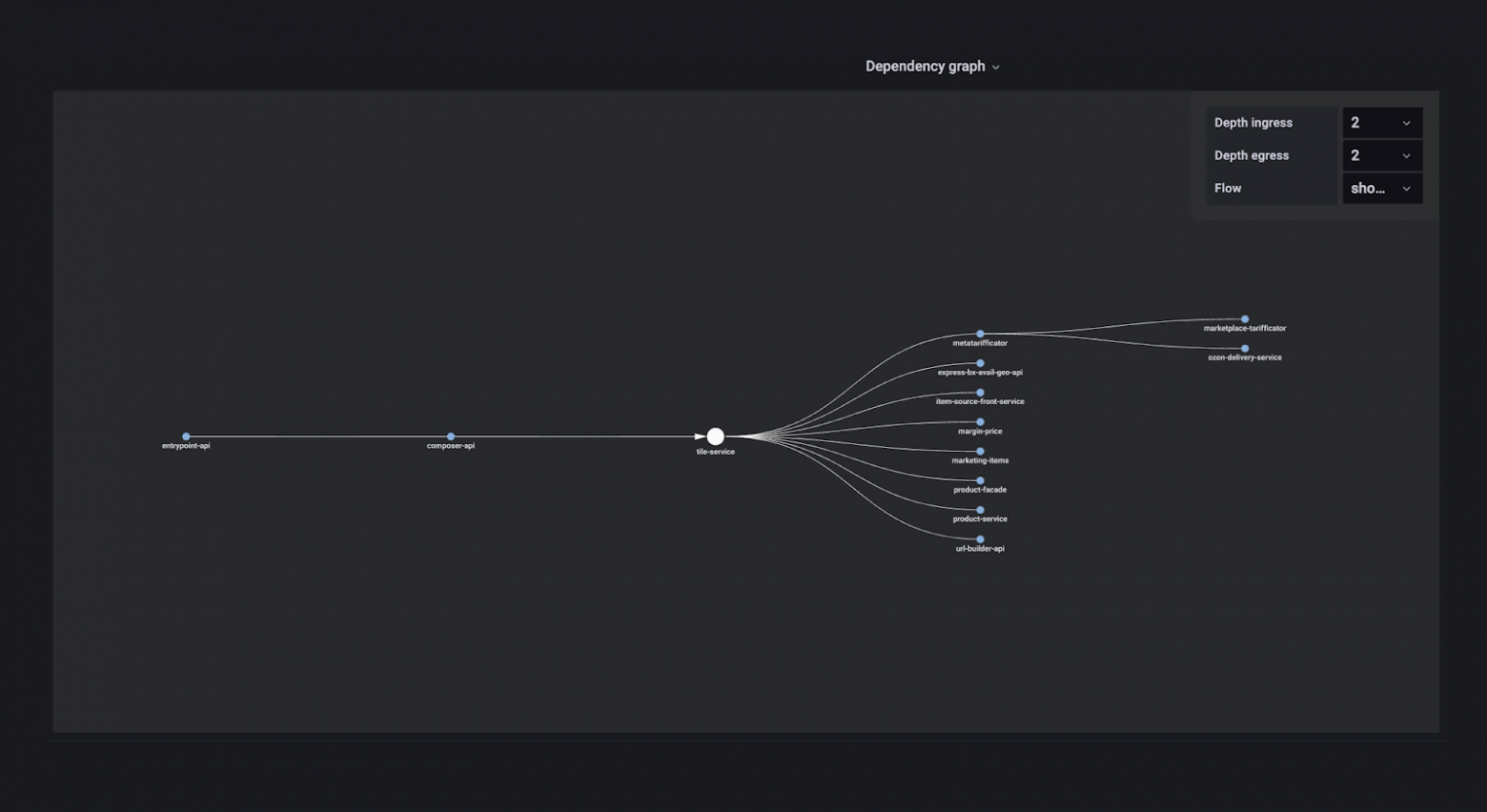
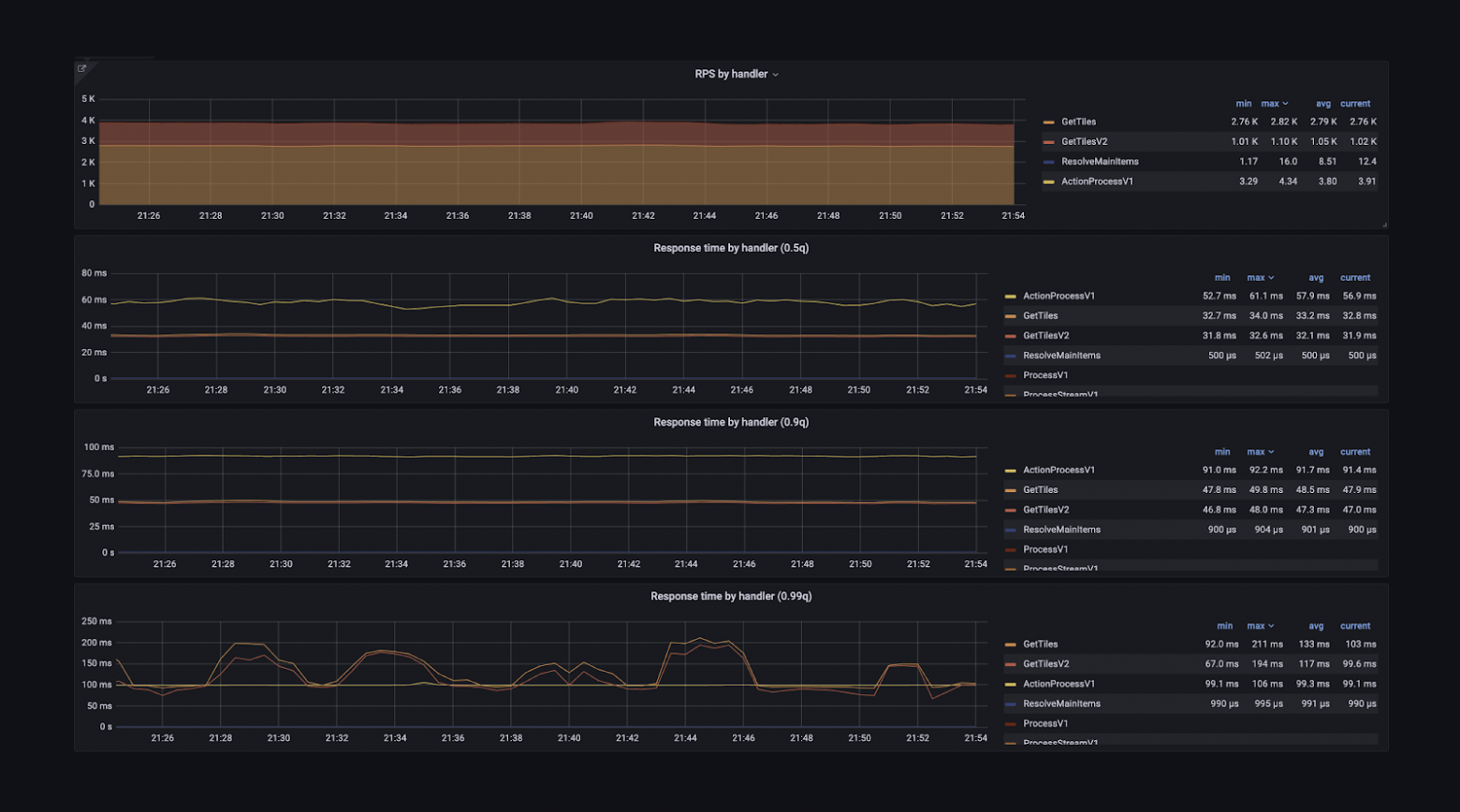
Можно посмотреть время ответа каждого сервиса. Можно понять, как сервисы работают в разных дата-центрах, ведь в них стоит разное железо, потому что запускались они не одновременно.
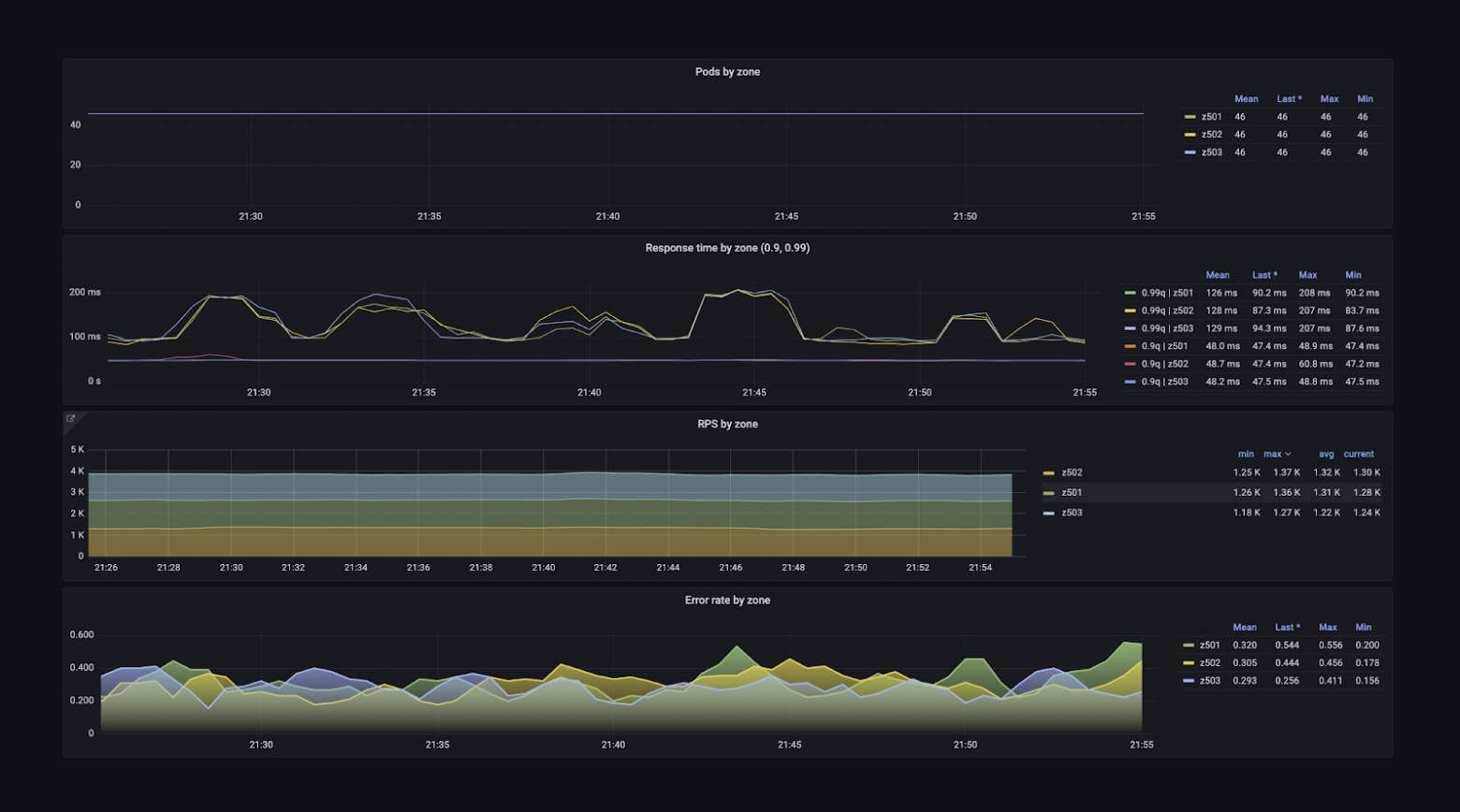
Есть информация о каждом протоколе взаимодействия — gRPC, HTTP. Есть метрики из рантайма языков: количество горутин, запусков сборщика мусора, потоков.
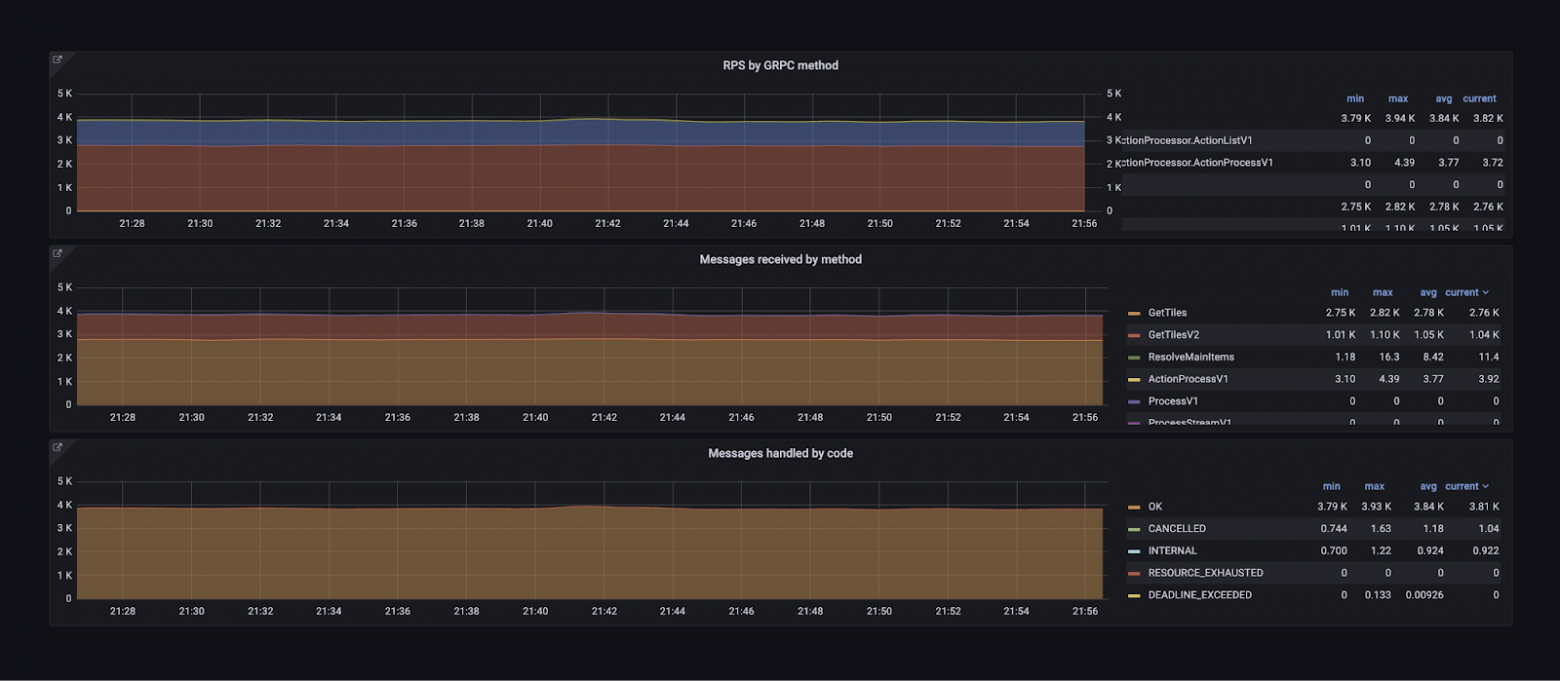
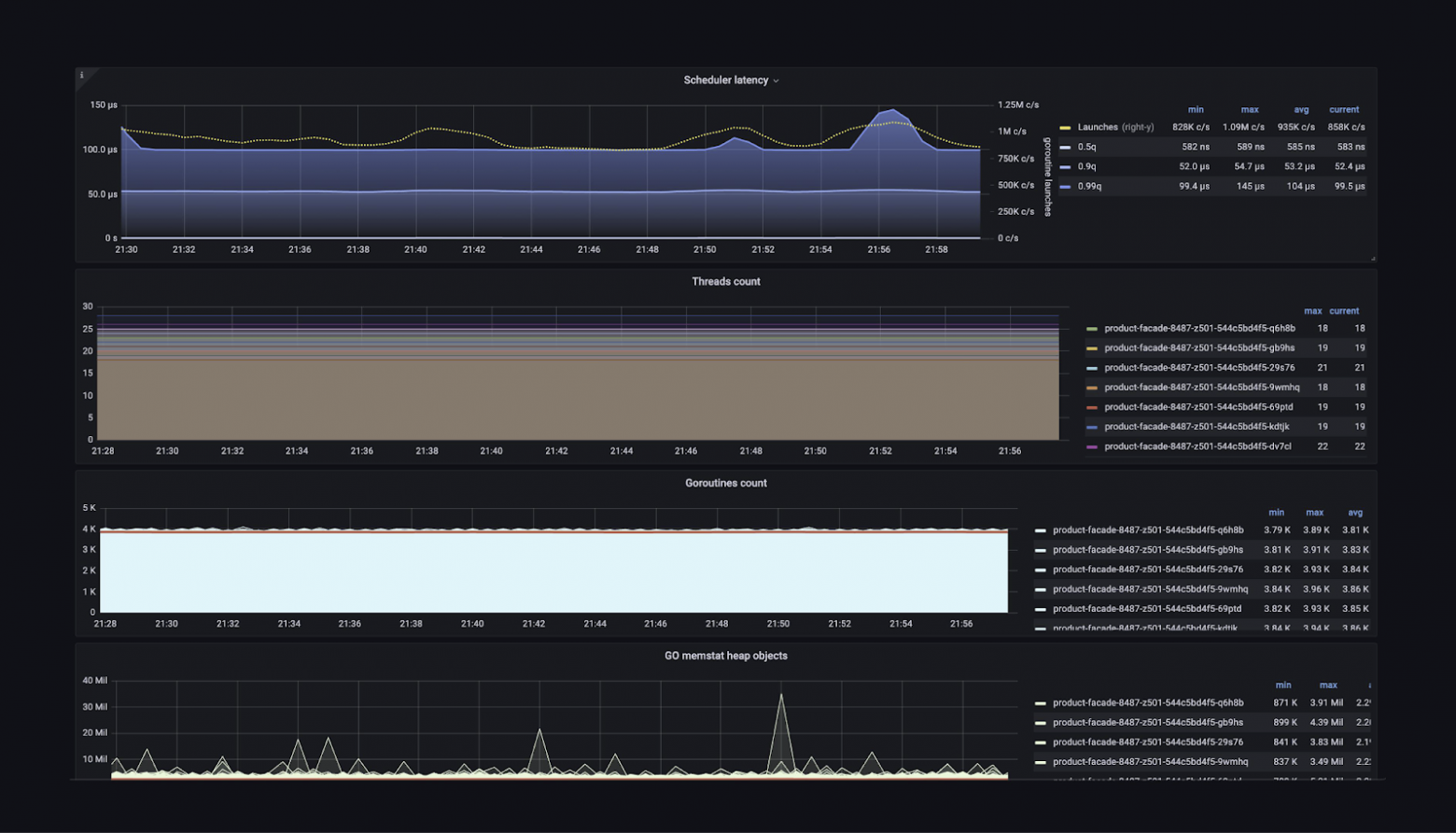
Можно посмотреть, сколько ресурсов использует сервис: CPU, памяти, сети — как в целом, так и в разрезе по подам. Есть детальная информация о внешних запросах, о том, как сервис видит взаимодействие с другими сервисами.
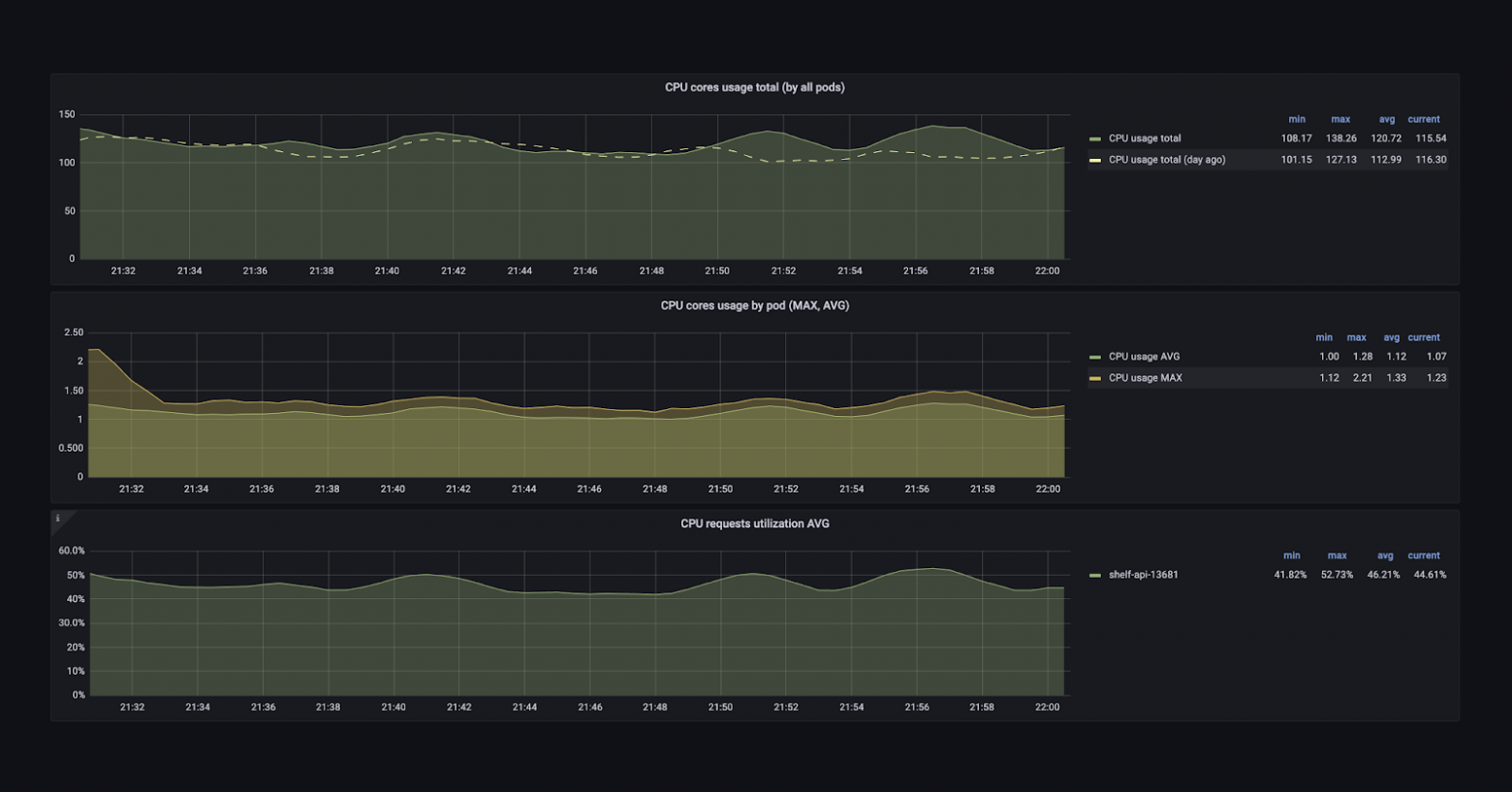
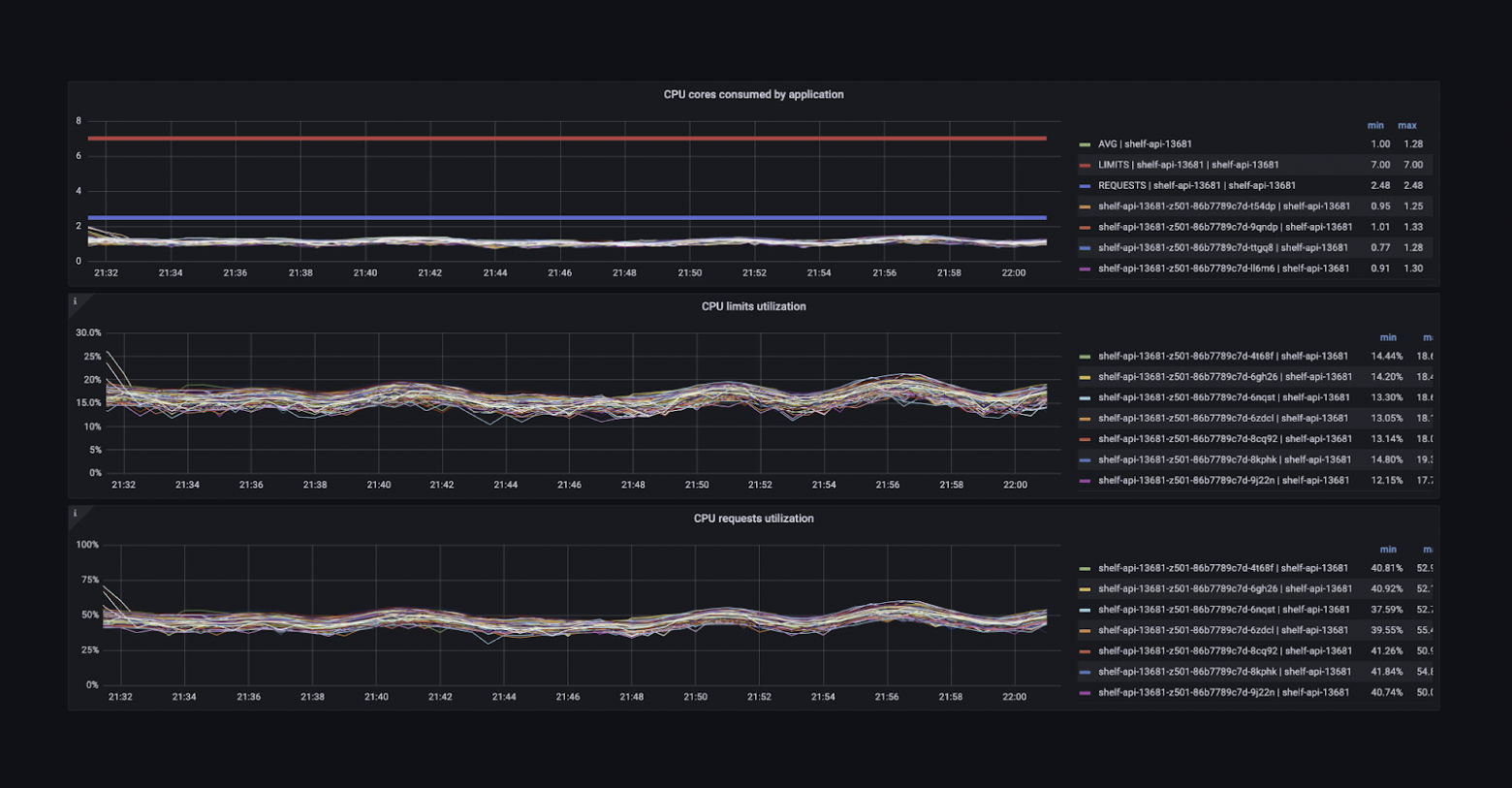
Также у нас есть большое количество базовых алертов, которые позволяют командам разработки не думать о том, какую метрику взять или как написать выражение. Им нужно только установить правильные пороги. «Пожалуйста, присылай мне уведомления, если мой сервис отвечает дольше 50 мс или у него теперь такой процент ошибок».
Переходим к трейсингу. В 2018 году мы начинали с ванильного Jaeger. Наверное, многие из вас за эти годы успели поработать с ним. Но мы достаточно быстро поняли, что Jaeger прикольный, но из коробки он скорее красивая игрушка, чем полезный инструмент. Он удовлетворял не все наши потребности, и в 2019 году мы целиком переписали бэкенд Jaeger, оставив от него только интерфейс. А в 2020 году перешли на OpenTelemetry с точки зрения протокола (бэкенд остался прежним — нашим).
Что мы умеем теперь? Мы храним абсолютно все трейсы и данные обо всех запросах, которые происходят на бэкенде Ozon за последние 10-15 минут. Мы умеем делать умное семплирование, то есть сохранять эти трейсы по разным параметрам, которые можно настраивать. Умеем вычислять критический путь и получать много другой прикольной статистики. Здесь я рассказал о том, как мы строили нашу инфраструктуру трейсинга.
Что мы добавили поверх того, что есть в Jaeger, с точки зрения интерфейса? Я думаю, многие из вас видели эту картинку с «колбасками»:
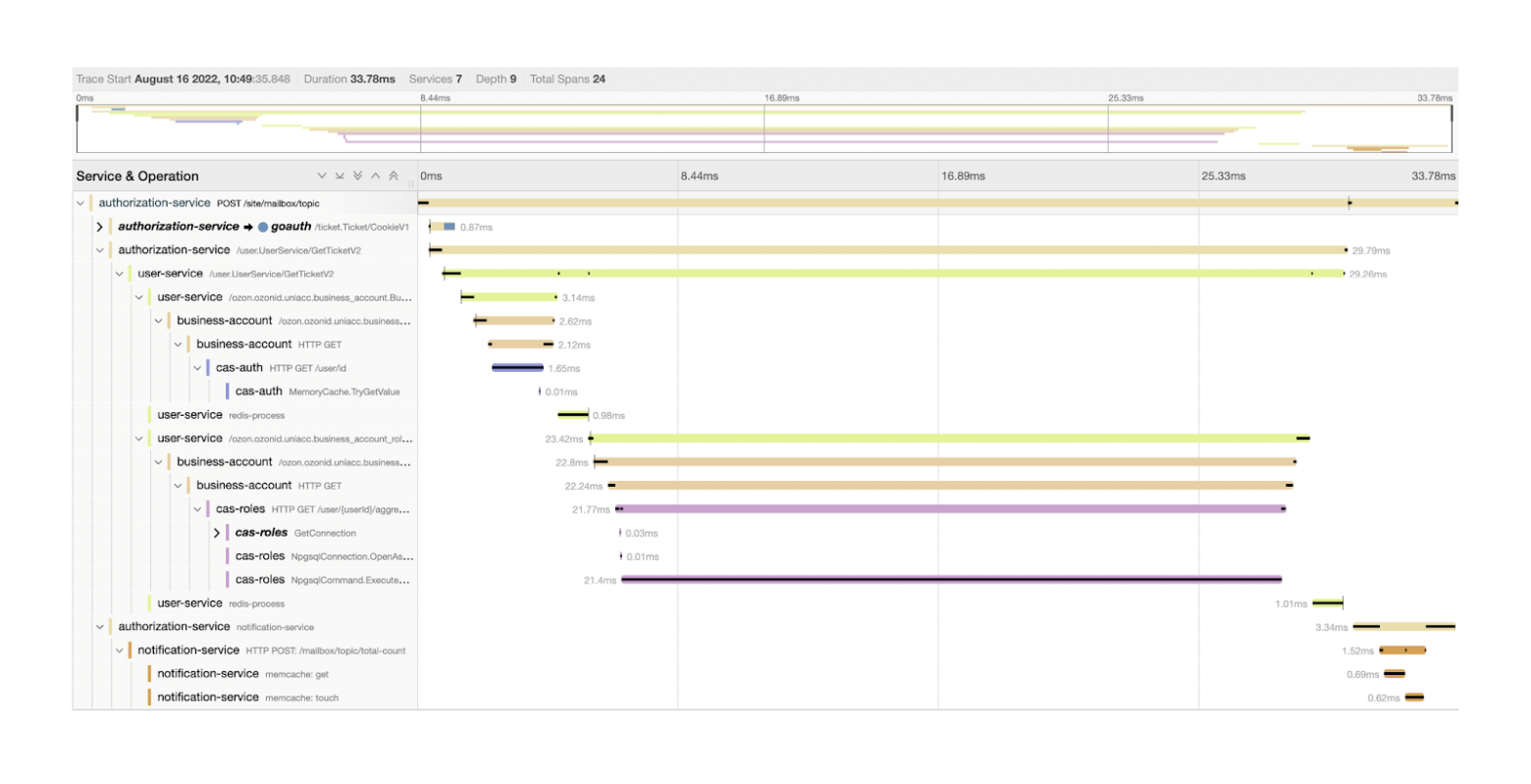
Из интересного здесь есть чёрные полоски внутри «колбасок», которые показывают так называемый критический путь запроса, то есть то, на что было потрачено больше всего времени в рамках выполнения пользовательского запроса. Приведу формальное определение: какой-то спан находится на критическом пути в момент времени t тогда и только тогда, когда уменьшение его длины в момент времени t уменьшит общее время выполнения запроса.
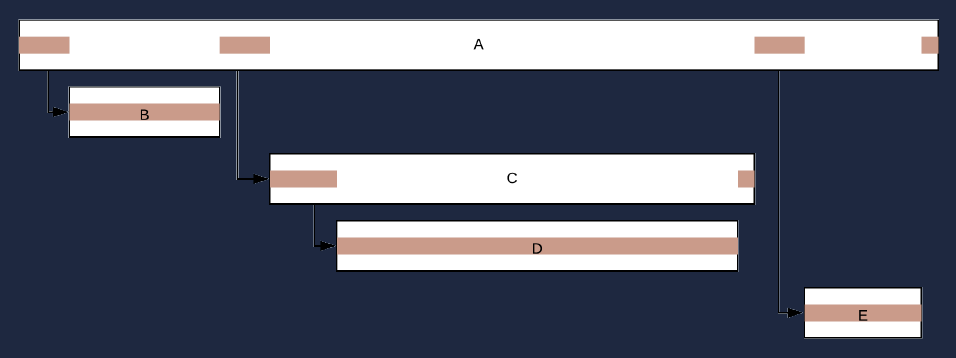
Если говорить очень простым языком, то если вы уменьшите время работы D, весь запрос станет выполняться быстрее. Вычислить этот критический путь не всегда просто. Без визуализации вы, скорее всего, не поймёте, что вам в первую очередь нужно оптимизировать, и можете пойти по неправильному пути.
Но изучать эти штуки на каком-то одном трейсе не так интересно, поэтому ребята из команды трейсинга решили сделать шаг вперёд и построили суперсложный дашборд, который представляет критические пути в виде графов. Он умеет их сравнивать за разные периоды и даёт возможность понять, какую операцию оптимизировать, чтобы все запросы выполнялись быстрее.
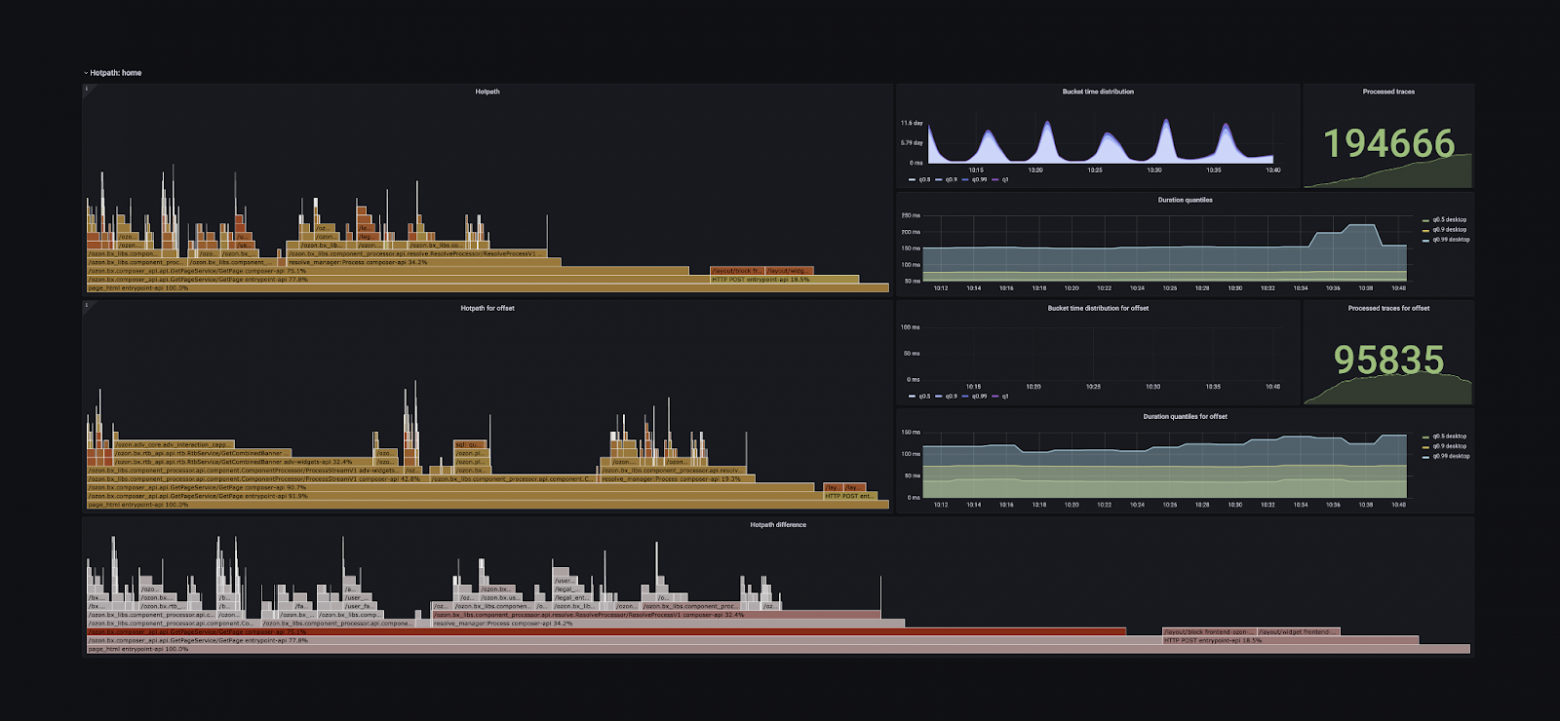
Наконец, continuous profiling. Мы регулярно собираем с разных приложений внутреннюю информацию о том, как они работают: сколько CPU и памяти тратят, на что. С некоторыми языками это делать очень просто. Например, Go предоставляет такую возможность из коробки. И мы немного пошаманили над нашими фреймворками для .NET и Java, чтобы они тоже могли это делать. То есть, раз в пять-десять минут мы собираем со всех приложений эту информацию, сохраняем её и предоставляем интерфейс, который позволяет узнать, что в таком-то сервисе в такое-то время ресурсы CPU тратились на такие-то вещи. На скриншоте ниже в правой половине — интерфейс того, что предоставляет тулинг Go.
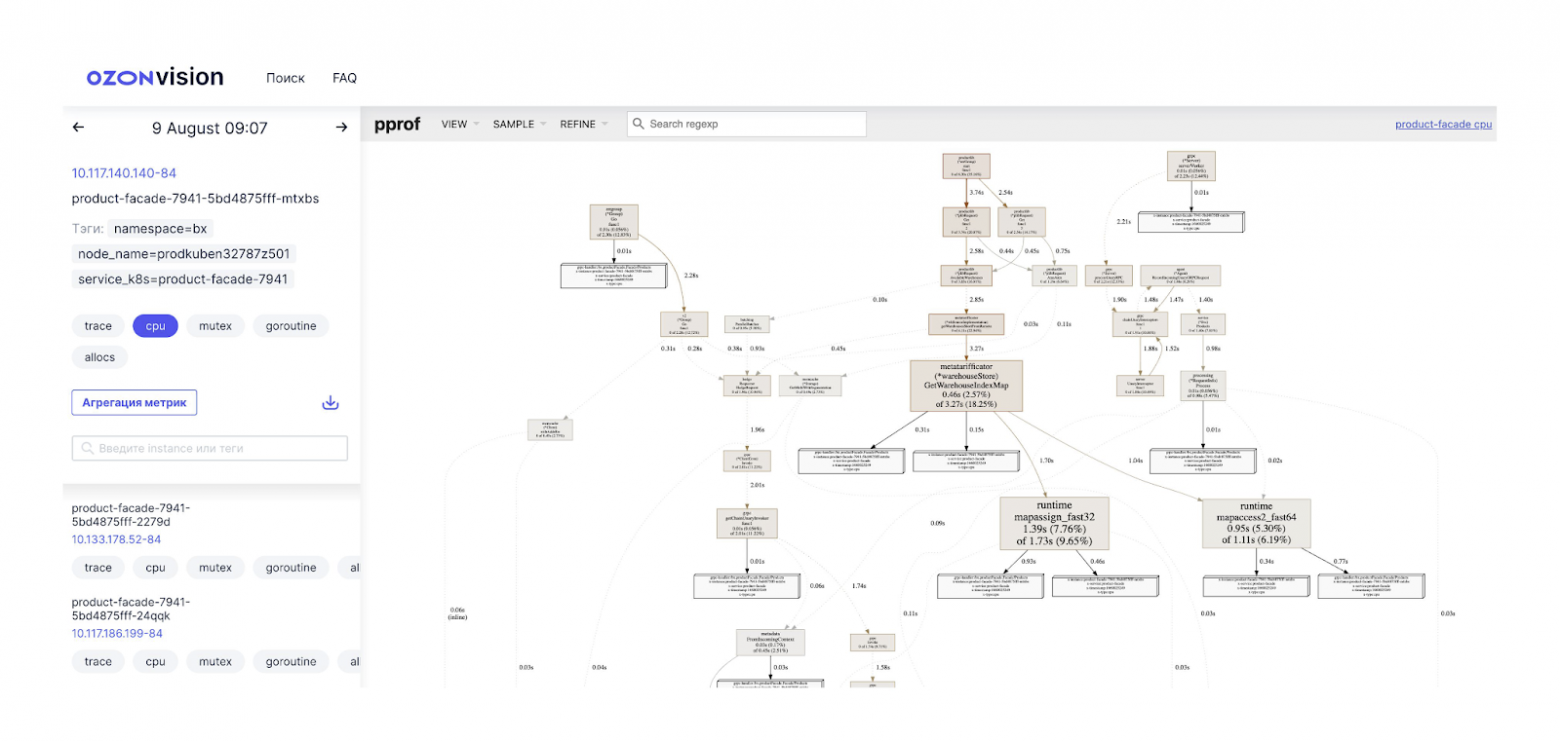
Это актуально, например, когда вы хотите найти ответ на вопрос, что случилось с вашим сервисом вчера в три часа ночи, когда он упал. Благодаря этому инструменту всегда можно вернуться в прошлое и посмотреть, что там происходило.
У нас есть планы заопенсорсить эту историю. Правда, мы говорим об этом уже пару лет, но я думаю, что это всё же когда-нибудь случится.
PaaS
И последняя большая тема, которую я хочу осветить, — PaaS. Это то, чем мы занимаемся в течение последнего года и во что активно вкладываемся.
Какое-то время назад у нас бывали такие ситуация: команда готовит большой релиз, ей нужна база данных. Коллеги приходят и говорят, что релиз завтра и нужно запустить базу. Чтобы это произошло, команде нужно было создать тикет, этот тикет должен был подхватить какой-то дежурный, он должен был пойти, создать эту базу, скинуть креды и т. д. Было очень много ручной работы.
Нам не хотелось заниматься этой ручной работой — и мы хотели сделать так, чтобы разработчикам стало легче жить и всё можно было делать по кнопке. Чтобы если я, например, хочу PostgreSQL, я мог нажать на кнопку — и она бы запустилась.
Мы решили начать делать технологии-as-a-service. Для команд разработки они должны были уменьшить время реагирования на запросы за счёт отсутствия в процессе человека, который занимается решением задачи.
В общем виде технология *-as-a-service выглядит так:
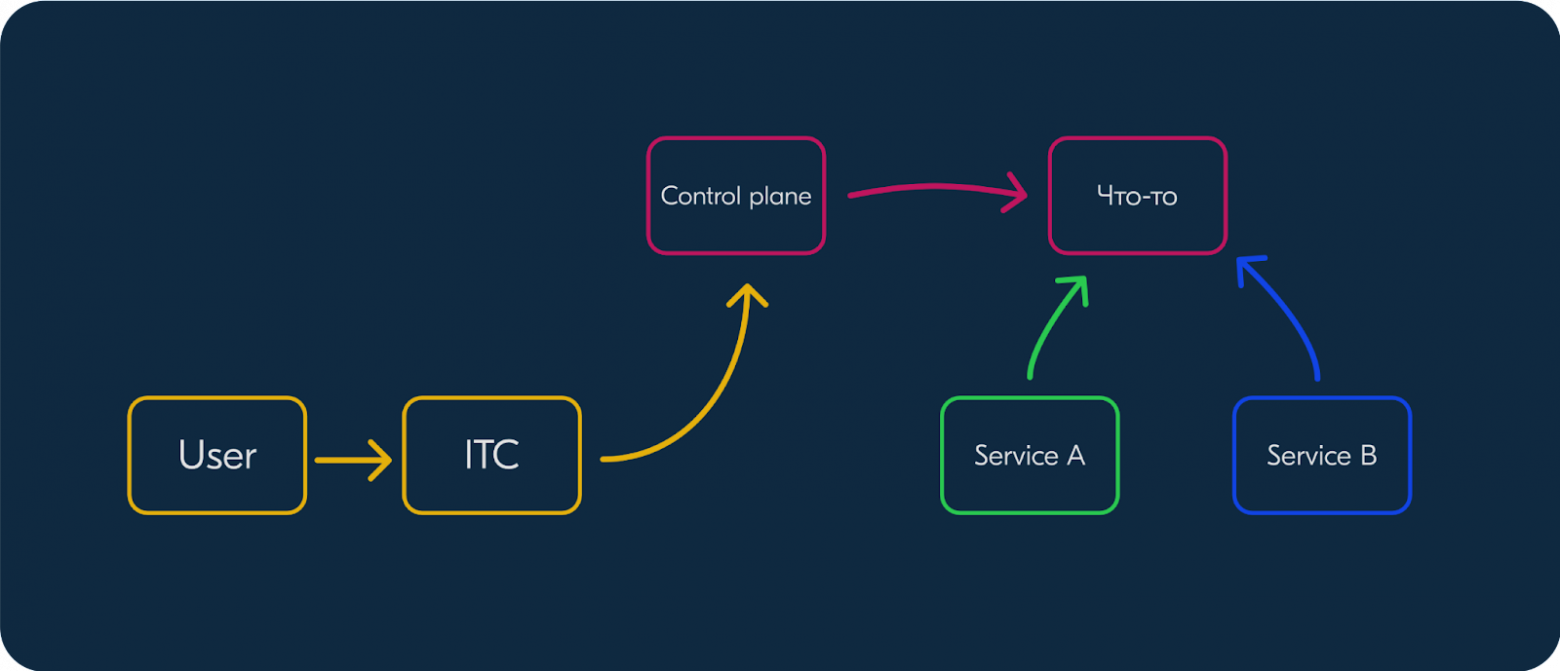
У нас есть что-то, что мы хотим автоматизировать. Есть сервисы, которые хотят этим пользоваться. Нам нужно написать control plane, который позволит запускать и создавать это что-то. ITC — это наш внутренний интерфейс для управления облаком. Он взаимодействует с control plane.
И мы воплотили эту идею в жизнь. Разработчики получили мониторинг, алерты, красивые дашборды и возможность настраивать доступ. А для нас из плюсов можно отметить стандартизацию. Мы говорим: «Хотите использовать PostgreSQL — используйте её вот так». Есть различные конфигурации, но их количество ограниченно. Мы контролируем всё — от железа до библиотек, которые умеют работать с той или иной технологией.
На текущий момент мы умеем предоставлять в таком формате следующие технологии:
- PostgreSQL
- S3
- Memcached
- Redis
- Kafka
- ClickHouse
Размер этого списка увеличивается каждый квартал. Мы начинали с самым популярных технологий внутри компании и продолжаем адаптацию всех остальных. Следующий важный этап — построение сервисов более высокого уровня, которые основаны на уже существующих.
Например, для PostgreSQL уже сейчас можно запустить обычный кластер, который будет состоять из мастера, одной синхронной и нескольких асинхронных реплик, которые распределены по разным дата-центрам. Такая конфигурация позволяет сервису переживать отказ как одной конкретной реплики, так и любого дата-центра: благодаря Warden’у сервис получает обновленную конфигурацию и продолжает работать как ни в чем не бывало. Также, совсем недавно мы запустили шардированный PostgreSQL: можно создать кластер, состоящий из нескольких шардов. Автоматика умеет их перевозить с сервер на сервера, а библиотека предоставляет удобный API для работы с шардами.
Создание любого ресурса происходит очень легко. Тем, кто работал с публичными облаками, интерфейс будет знаком. Вы выбираете, сколько ресурсов хотите потратить, нажимаете на кнопку «Создать», ждёте несколько секунд — и всё, можно пользоваться. Берём библиотеку для любого языка, говорим ей, как называется кластер, — и она делает всю магию. Всё классно работает.
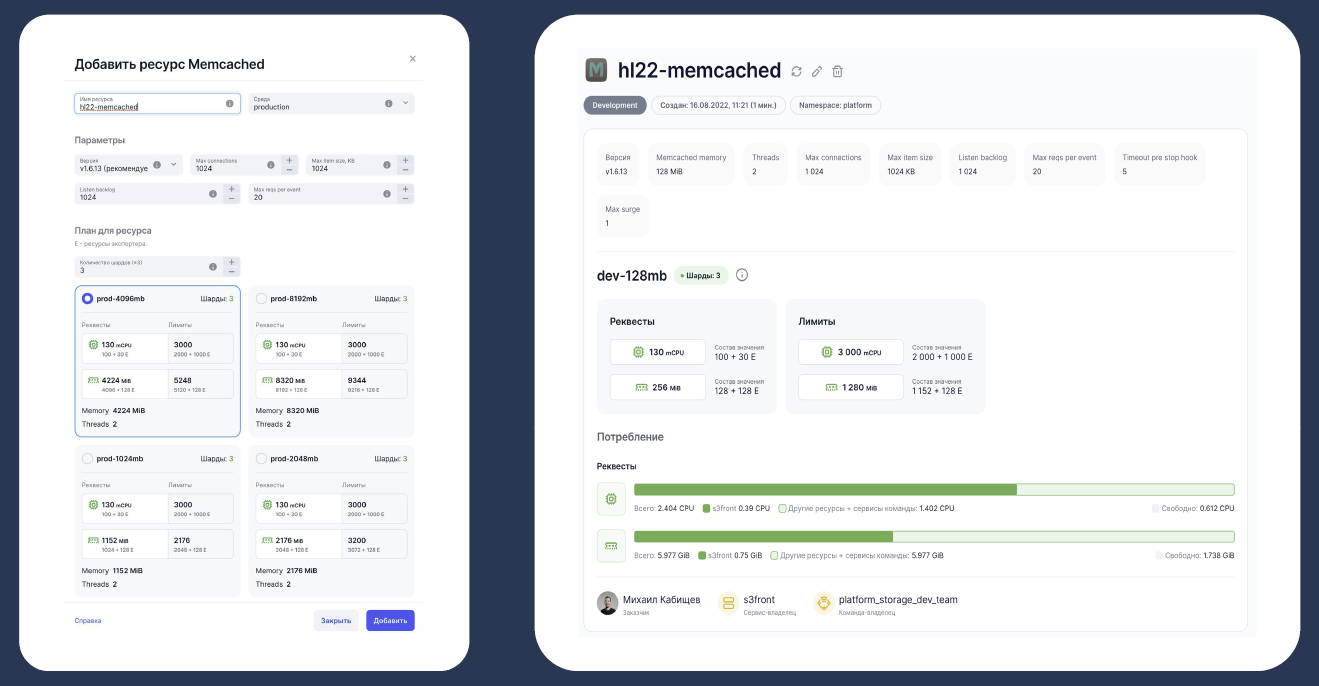
Пока у нас не было этой системы, мы всё делали вручную, и тикеты терялись. Люди, которые их заводили, увольнялись, переходили в другие команды. В какой-то момент мы не всегда могли ответить на вопрос, кто за какой ресурс отвечает. С этой системой мы теперь точно знаем:
что такой-то ресурс принадлежит такому-то сервису
сервис принадлежит такой-то команде
у команд есть квоты на запуск ресурсов
Благодаря этому мы можем считать бюджет как в ядрах, терабайтах и т.п., так и в деньгах. И это сильно помогает нам при планировании мощностей и закупок.
Заключение
Для Ozon платформа стала настоящим фундаментом для разработки — на ней сейчас строятся все информационные системы, которые у нас есть. Платформа обеспечивает нам нужную скорость, удобство (и для разработки, и для управления), внедрение новых технологий, телеметрию, безопасность, стандарты. Если у вас в компании сложный ИТ-ландшафт, то подобная платформа очень поможет устранить типичные для больших проектов трудности.
Но при этом не нужно забывать, что команды разработки — наши главные клиенты. Всё, что мы делаем в платформе, мы делаем не потому, что мы где-то прочитали, что это прикольно, а потому, что хотим упростить жизнь разработчикам. Если у какой-то команды возникает потребность в использовании новой технологии — и это обоснованно — то мы внедряем поддержку этой технологии в платформу. Платформа не должна мешать или ограничивать разработку, это очень важно.
