
Всем доброго времени суток! Так как о Data Science мы слышим всё чаще и чаще, предлагаю вам обзор книги, что будет полезна для начинающих.
Публикую обзор книги с моего телеграмм-канала IT-старт t.me/it_begin на книгу "Data Science.Наука о данных для начинающих".
Автор книги Джоэл Грас.
Стоит читать? Да! Почему? Опишу в статье.
Для кого эта книга?
Так как в названии фигурирует "Наука о данных с нуля" - не мудрено, что рассчитана она на тех, кто только начинает свой путь в Data Science :)

Что в самой книге?
Книга сама по себе немаленькая и состоит из 416 страниц.
Для того, чтобы имелась конкретика по размерам книги, производим замеры.

Ширина книги составляет чуть менее 17 см.

Высота книги составляет 23 см.

Глубина книги составляет около 2 см.
Теперь, для предметного и краткого понимания того, с чем мы сможем ознакомиться в данной книге, предлагаю перейти к её оглавлению.




Глав достаточно много, это радует) Всего глав 27.
Далее предметно и главное кратко постараюсь рассказать о том, что полезного и интересного мы сможем найти в этой книге.
Глава 1. Введение

Первая вводная глава начинается с подробного описания тезиса "Воцарение данных" и ответа на вопрос "Что такое наука о данных?".
Здесь повествуется о том, насколько много данных в современном мире и том, что вся информация, что собирается нашими компьютерами, смартфонами, умными часами, при должной обработке, может дать ответы на бессчисленные вопросы.
Более всего понравился пример на странице 26 с Facebook, что думаю примененим ко многим плоскостям исследования, используя практические любые соц. сети.
Также хорошо подчеркнут опыт избирательной компании Барака Обамы в 2012 году и предвыборной компании Дональда Трампа. Предлагаю вам ознакомиться с данным отрывком.

Глава 2. Интенсивный курс языка Python

В данной главе автор на протяжении 30 страниц крайне в сжатом формате старается познакомить нас с языком программирования Python.
По моему мнению, вследствие того, что объяснение крайне поверхностное и имеет ограничение в виде 30 страниц, объяснено всё плохо. Для тех, кто вовсе не имел опыта работы с Python, данная глава, к сожалению, вряд ли поможет.
Как бы, претензий к книги по данному поводу у меня нет, но хотел бы, чтобы вы заранее имели это ввиду, что эта глава не является карманным пособием по Python.
Если вам необходимо изучить основы Python, советую книгу Тони Гэддиса "Начинаем программировать на Python с нуля" - мой обзор

В конце данной главы на странице 69мы видим две особенности книги.
Первая особенность - в конце каждой последующей главы вы увидите полезную сноску под названием "Для дальнейшего изучения", где автор от себя советует, что можно прочитать дополнительно для более глубокого изучения той или иной темы. Считаю это положительным моментом.
Отрицательным моментом качества данной книги являются тонкие страницы, что просвечивают и не доставляют особого удовольствия от этого.
Не сказал бы, что это крайне критично, но и приятного в этом также мало, общее впечательние от книги немного портится.
Всё крайне показательно видно на фото выше.
Глава 3. Визуализация данных

Также яркий пример просвечивающих страниц это столбчатый график, что просвечивает на странице 71)
В третьей главе автор кратко рассматривает библиотеку matplotlib,
В самом начале автор подчеркиват, что считает данную библиотеку устаревающей и что она годна для построения элементарных линейных и столбчатых графиков.
Согласиться с этим или нет? Вопрос сложный и оставлю его открытым на суд аудитории. Интересно ваше мнение по этому вопросу.
Далее в книге рассматриваются столбчатые и линейные графики, диаграммы рассеяния. Что порадовало, это повествование с соответствующим кодом, тут же можно понять, какая строчка кода за что отвечает, считаю это положительным моментом для тех, кто только начинает свой путь.
Завершается глава разделом "Для дальнейшего изучения", где автор оставляет ссылки на такие библиотеки, как seaborn, Altair, D3.js, Bokeh с кратким описанием каждой из них.
Глава 4. Линейная алгебра

В этой главе автор рассматривает векторы и матрицы.
Объяснено достаточно хорошо, вопросов после прочтения остается мало, в конце автор оставляет ссылки на три книги, что также позволят закрепить пройденный материал.
Глава 5. Статистика

В данной главе автор описывает и рассказывает о том, что такое тенденции, вариация, корреляция, корреляционные ловушки.
В главе много кода, подробно всё описание, в целом впечатление от главы положительное.
Но также показалось интересным и хорошо запомнилось описание парадокса Симпсона :)

Глава 6. Вероятность

В этой главе рассмотрены:
Условная вероятность
Теорема Байеса
Случайные величины
Непрерывные распределения
Нормальное распределение
Центральная предельная теорема
Автор раскрывает важность умения работать с анализом вероятности для последующей работы с данными. Вероятность автор рассматривает, как способ количественной оценки неопределенности, что ассоциируется с событиями из некоторого вероятностного пространства.
Глава 7. Гипотеза и вывод

Хотел бы привести в пример "учаток" на странице 116, в подтверждение того, что без опечаток в этой книге не обошлось)
Теперь же о самой главе.
В данной главе автор подчеркивает, что все сведения из теории вероятности и статистики нам нужны для формулирования статистических гипотез и их последующей проверки. Предлагаю взглянуть на фрагмент главы в фото ниже.

Глава 8. Градиентный спуск

Градиент - это вектор, что своим направлением указывает направления возрастания некоторой скалярной величины.
Антиградиент - вектор, что своим направлением показывает направление убывает некоторой скалярной величины.
Градиентный спуск - это метод поиска локального максимума или минимума функции с помощью движения вдоль градиента.
Частично и достаточно понятно подход к максимизации функции описан на странице 128. (Рис. 8)
Глава более чем интересная, рассматривается также использование градиента, выбор правильного размера шага и применение градиентного спуска для подгонки моделей.
Глава 9. Получение данных

Для того, чтобы исследовать данные, нужно сначала их собрать :)
В этой главе автор рассматривает способы подачи данных и также их последующее форматирование.
В главе рассматриваются аспекты чтения файлов, импорт информации из всемирной паутины с помощью html5lib, что такое API и как с этим можно работать.
Глава 10. Работа с данными

В 10 главе автор рассматривает непосредственную работу с данными.
Рассматривается разведывательный анализ данных, классы данных, многочисленные размерности.
Мне же понравилось, что автор не забыл про "чистоту" данных.
На странице 164 об этом как раз таки говорится, что многие данные в реальном мире загрязнены и что важно пред их использованием проводить необходимую обработку, чтобы в дальнейшем не создать себе проблем.

Глава 11. Машинное обучение

В 11 главе автор знакомит нас с машинным обучением.
Так как это обзор книги и он всё же будет немного предвзят с моей стороны по той причине, что у каждого человека есть своё мнение на ту или иную информацию - мне показалась данная глава не для тех, кто начинает с нуля)
Описано в целом по делу всё, но нет уверенности, что люди, ранее не знающие ничего о машинном обучении, после прочтения данной главы всё усвоят.
Глава 12. k ближайших соседей
Метод k-ближайших соседей – это популярный алгоритм классификации, который используется в разных типах задач машинного обучения.
Простыми словами суть метода: посмотри на соседей вокруг, какие из них преобладают, таковым ты и являешься.
Теперь же о том, как всё это описывает автор на примере предсказания результатов на выборах

На примере набора данных о цветках ириса (длина и ширина лепестка, длина и ширина чашелистика) автор пытается построить модель предсказания вида цветка, но т.к. выводимые результаты у него получились четырехмерными, что затрудняет построение графика, автор предлагает взглянуть на диаграммы рассеяния для каждой пары данных результатов измерений.
Порадовало, что в данной главе автор не забыл о проклятии размерности

Глава 13. Наивный Байес
В данной главе автором очень хорошо рассказан принцип работы спам-фильтра социальных систем, как он устроен и что лежит в его основе.
Порадовало то, что в конце данной главы автор ссылается на статью Пола Грэма "План для спама". Статья 2002 г., но менее интересной от этого не становится.

Глава 14. Простая линейная регрессия

В 14 главе автор рассказывает о простой линейной регрессии, описывает применение градиентного спуска, производит оценивание максимального правдоподобия
Глава 15. Множественная регрессия
В данной главе автором рассматривается множественная регрессия, Расширенные допущения модели наименьших квадратов, подгонка модели и её дальнейшая интерпретация.

Глава достаточно большая и много познавательной информации имеет, но мне более всего понравилась трактовка интерпретации моделей
Глава 16. Логическая регрессия
Логистическая регрессия - статистический метод для анализа набора данных, в котором есть одна или несколько независимых переменных, которые определяют результат. Результат измеряется с помощью дихотомической переменной (в которой есть только два возможных результата). Он используется для прогнозирования двоичного результата (1/0, Да / Нет, Истина / Ложь) с учетом набора независимых переменных.
С самого начала главы автор предлагает рассмотреть всё на задаче, что содержит набор данных 200 пользователей, их зарплату, опыт работы и состояние платежей за учетную запись в соц. сетях. Далее описывается то, что такое логистическая функция, применение модели.

Более всего понравилось рассмотрение гиперплоскости, что разделяет параметрическое пространство

Идём далее)
Глава 17. Деревья решений
Одно из толкований дерева решений чаще всего описывает их в качестве представления возможных путей принятия решений.
Автором неплохо показано это на достаточно простом примере.

Глава 18. Нейронные сети
Нейронные сети - то о чём мы всё чаще слышим из средств массовой информации.
В данной книге глава это мягко не особо большая. Всего 10 страниц. Но достаточно информативная. Расскажет о том, что такое нейронные сети, перспептроны, как работают нейронные сети прямого и обратного распространения. Глава интересная!

Глава 19. Глубокое обучение
В данной главе о глубоком обучении автор рассказывает нам, что такое абстракция слоя, о представлении нейронных сетей как последовательности слоёв, о потери и оптимизации функции градиента.
Возможно субъективно, но чтобы до конца понять все вещи в данной главе, пришлось прочитать её дважды. Но думаю, дело не в книге, а во мне :)

Глава 20. Кластеризация
В главе о кластеризации понравилось, что автор пытается объяснить нам, что такое кластеры на +- понятных многим бытовых темах. Если читать ранее не слышал ничего о кластерах, подобное объяснение не является крайне легким, но и базовые основы в голове начнет зарождать. В главе автор рассматривает и описывает восходящую иерархическую кластеризацию, кластерные методы и на примерах объясняет что к чему. Интересная глава.

Глава 21. Обработка естественного языка
В главе об обработке естественного языка автор рассказывает несколько приемов, такие как: облако слов, N-грамматические языковые модели, грамматики. Много поясняющего кода)

Глава 22. Сетевой анализ
В главе про сетевой анализ автор описывает центральность, ориентированные графы, алгоритм PageRank. Мне данная глава "понималась" крайне тяжело, вследствие чего параллельно приходилось заглядывать в Google.

Глава 23. Рекомендательные системы
Та тема, с которой мы ежедневно встречаемся, используя те или иные стриминговые сервисы, соц. сети, поисковые системы - рекомендации :)
Сказали рядом с телефоном "купил собаку" и видите контекстную рекламу о дизайнерских будках на заказ? Это Data Science :)
Глава познавательная. Автор повествует о том, как работает рекомендательная система, что лежит в её основе, что такое коллаборативная фильтрация по схожесте пользователей и многое другое.

Глава 24. Базы данных и SQL
Достаточно сжатая глава о SQL. Рассказывается о том, что такое SQL, о основных командах и разобрано всё на примерах. Всё крайне сжато, но для общего представления совсем неплохо. Но всё же советовал бы дополнительно поискать еще источники информации на тему SQL, если хотите понять тему полноценно.

Глава 25. Алгоритм MapReduce
MapReduce - модель для выполнения параллельной обработки крупных наборов данных. Рассматривается работа самого алгоритма, какие его преимущества и чем он может быть полезен и рассмотренно на примере аналази аобновлений новостной ленты. Всё достаточно подробно описано, вопросов после главы остаётся не так уж и много.

Глава 26. Этика данных
Одна из лучших глав данной книги. Что такое этика данных, почему она важна, для чего используется и к чему может привести её несоблюдение. Познавательный материал, советую.

Глава 27. Идите вперед и займитесь наукой о данных
Заканчивается вся книга главой с призывом идти вперёд и заняться Data Science.
Автор подчеркивает важность компетенций в математической области и о необходимости хорошо разбираться в ней. Также автор кратко описывает популярные библиотеки языка программирования Python и не только.
Глава по своей сути прощальная между автором и читателем, автор же оставляет ту выжимку необходимых мыслей, что он хочет донести до каждого читателя для продолжения путешествия в мир Data Science.

Теперь, тезисно о плюсах и минусах книги
Плюсы книги:
1.Цена.
На первом маркетплейсе цена не такая уж и народная.На втором же, ситуация куда бодрее.
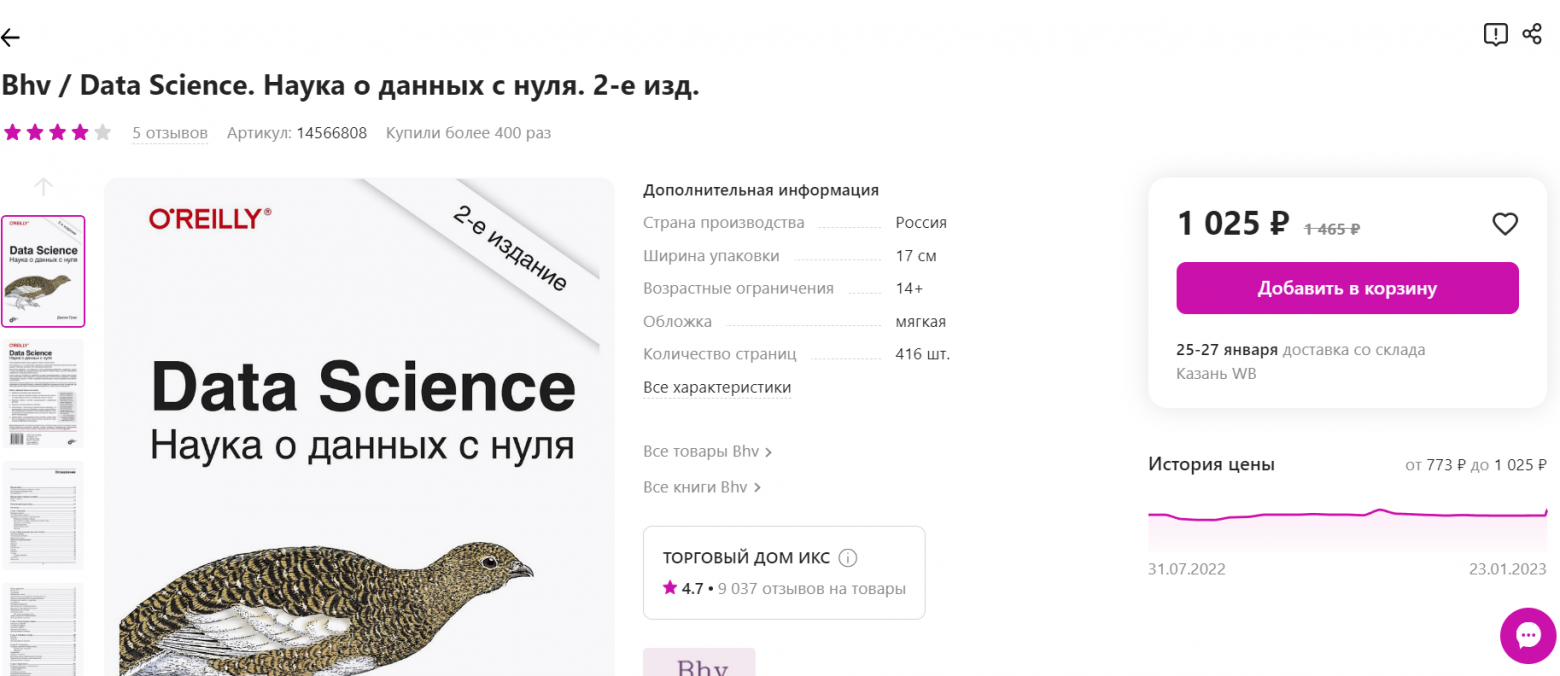
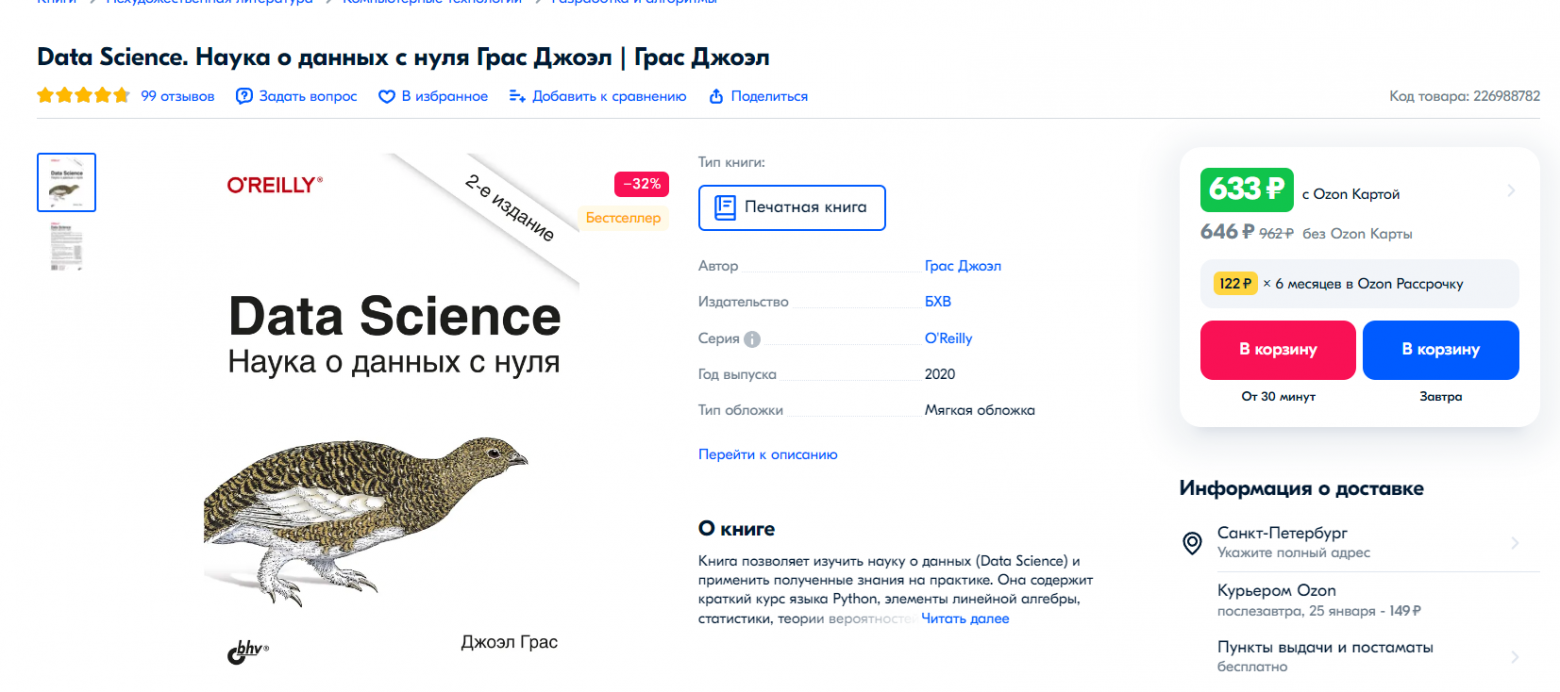
Лично от себя скажу, что в целях экономии, часто беру книги уцененные, с небольшими внешними дефектами книги, что не особо влияет на её содержимое. Или же можно найти интересующую вас книгу на площадках б.у. товаров. Но если захотите приобрести новую книгу, цена в условные 600 руб. считаю более чем приемлимой и подъемной для многих. Выделю цену достоинством книги.
2. Книга крайне ёмкая и обширная. О необъятной теме в объятной книге.
Рассматривается и Python и SQL и методы Data Scince, что и как работает. В рамках одной книги это более чем достойно. Да, временами книга может показаться поверхностной, но думаю, это исходя из ограничений книги. Чтобы написать подробный том о каждой теме, для производства книги потребовалось бы куда больше бумаги :)
Минусы книги:
1. Прозрачные страницы.
Не особо бросается в глаза, когда увлечены чтением, но и приятного в этом мало.
Думаю, на всех фотографиях страниц книг, что сделаны мною, это отчетливо видно. Страницы тонкие и просвечивают. Считаю, что это минус.
2.Иногда крайне сжато подаётся материал, что , не имея под рукой поисковика, трудно понять некоторые вещи. Данная оценка субъективна, но мне показалось именно так. Опять же, не уместить всё-всё в одну книгу, понимаю. Но иногда охото отстраниться от цифрового мира, увлечься чтением интересной книги и не прибегать к помощи персонального компьютера)
Подведение итогов по книге:
Могу посоветовать к прочтению данную книгу. Книга даст базовые знания о Data Science, что опять же позволит вам понять, нужно ли оно вам в принципе, интересно ли всё то, что связано с этой сферой.
Мой канал в телеграмм
Если обзор показался вам интересным, то буду благодарен за подписку на мой
канал IT-старт t.me/it_begin
где я также публикую обзоры технической литературы и полезную информацию как для действующих, так и для начинающих программистов
Ссылка на бесплатную электронную версию книги https://t.me/it_begin/461
Также публикую обзоры книг и интервью на сайте https://russia-it.ru

