
Замечали, как часто в ИТ-отрасли появляется модное словечко, и тут же все начинают вставлять его в описание своих продуктов, чтобы привлечь побольше внимания?
Сейчас у нас в тренде observability (наблюдаемость), и многие вендоры уже берут его на вооружение.
Что такое observability? Просто навороченная версия мониторинга? Быстрее, выше, сильнее, настоящий Чак Норрис среди DevOps-инструментов! Так и хочется прикупить себе наблюдаемости, правда?
Давайте не будем поддаваться всеобщему ажиотажу и попробуем разобраться, что это такое и откуда вся шумиха.
Основы мониторинга
Начнём с того, что мы все уже знаем и любим — мониторинг.
Мониторинг — это действие. Мы мониторим свои приложения и системы, чтобы знать, в каком они состоянии. Мы можем просто убедиться, работает сервис или нет, или провести более полную проверку работоспособности и производительности. С помощью мониторинга мы ищем проблемы и аномалии, а потом докапываемся до их причины и анализируем требования к ресурсам и тренды производительности.
Это простейшие задачи, но мониторинг может больше. Например, с его помощью разработчики могут корректировать свой подход к написанию кода, чтобы повысить производительность, а архитекторы — экспериментировать с облачными паттернами и моделями, чтобы найти лучшее соотношение цены и качества.
Мониторинговые решения используют разные приёмы, вроде инструментирования и трассировки, чтобы собирать, обрабатывать, коррелировать и анализировать самые разные метрики в современных стеках приложений. Для полноты картины добавьте сюда синтетические транзакции и аналитику взаимодействия пользователей с приложениями.
Observability: мифы и реальность
Откуда взялось это новое слово — observability? Не такое уж оно, кстати, и новое. Оно пришло к нам из инженерного дела и теории управления.

Как гласит его определение, это показатель того, насколько легко мы можем понять внутреннее состояние системы по её внешним проявлениям. Если мониторинг — это действие, то observability — это свойство системы. Когда наши ИТ-системы и приложения не дают нам заглянуть внутрь, никакой мониторинг тут не поможет. Я не инженер, но это понятно даже мне.
Учитывая характеристики современных приложений и темпы их выпуска, без наблюдаемости не обойтись. Мы упаковываем рабочие нагрузки в контейнеры и разбиваем приложения на микросервисы — к таким динамичным и легко масштабируемым системам не получится по старинке намертво прикрутить инструменты мониторинга. Нам нужны современные методы инструментирования, чтобы лучше понимать свойства приложения и его производительность в сложных распределённых системах на протяжении всего жизненного цикла.
Инструменты observability

Добиться наблюдаемости можно с помощью инструментов, которые сообщают о происходящем в приложении через логи, метрики и события. Трассировка, например, помогает достоверно оценить производительность приложения и состояние сервиса, потому что измеряет все выполняемые действия в разных компонентах. Ещё можно собирать метрики и анализировать их при развёртывании контейнеризованного приложения в Kubernetes. На уровне развёртывания мы можем лучше понять систему по работе, которую она выполняет, при этом динамически меняясь и масштабируясь.
Улучшая observability, мы включаем в поле обзора больше компонентов приложения, от мобильного и веб-фронтэнда до инфраструктуры. Раньше пришлось бы собирать и анализировать информацию из многих источников — логи приложения, данные временных рядов и т. д. Сейчас системы устроены сложнее, и чтобы по-настоящему оценить опыт пользователя, мы должны анализировать данные в контексте того, как он использует и потребляет мобильные и веб-приложения.
Человеческий фактор
Разные инновационные инструменты, конечно, помогают улучшать observability, но давайте не будем забывать о людях. Даже самая эффективная система мониторинга мало что даст, если не использовать её при проектировании, разработке и тестировании приложений. Если систему сложно применять в работе напрямую, она будет стоять и пылиться.

Поэтому нужно максимально органично встроить мониторинг прямо в конвейер развёртывания. Например, как при развёртывании кластера Kubernetes, когда не приходится долго возиться с конфигурацией и прерывать рабочие процессы. Ещё можно повысить наблюдаемость, наладив наблюдение за производительностью приложения на стороне сервера и анализируя время отклика на стороне клиента во время нагрузочного тестирования. Это довольно неплохой способ найти причину проблем при масштабном тестировании. Дело тут не в инновационности подхода, а в его простоте и возможности применять его напрямую.
Чтобы повысить наблюдаемость систем, мы должны менять саму культуру и отношение людей. Если просто отдать приказ и ругать за его нарушение, мы ничего не добьёмся. В этом смысле DevOps-команды всегда будут искать возможности показать, как повысить observability приложений и почему это так ценно. Иногда достаточно несколько минут посидеть над топологией приложения, чтобы выявить узкие места и компоненты, которым не помешало бы инструментирование. Ещё одна хорошая возможность — после серьёзного инцидента или релиза. Главное здесь — сообща работать над улучшениями, а не искать виноватых.

Если вы хотите снизить проценты отказа сервиса и сократить риски при выкатке новых фич, приходить на курс «SRE: База», который стартует 28 февраля.
Мы должны приучить себя и коллег всегда думать о наблюдаемости системы. Можно начать с мелочей, которые быстро принесут результат, а затем мало-помалу формулировать эффективные рекомендации по проектированию системы мониторинга и стратегии совершенствования. Сейчас у многих организаций уже есть своя команда инженеров по observability. Кто-то идёт ещё дальше и включает эту тему в программы обучения новых сотрудников.
Изучите реальный опыт других компаний и отдельных экспертов. Например, почитайте хорошие статьи Синди Шридхаран (Cindy Sridharan) или послушайте спикеров на конференции Monitorama. Все они отлично разбираются в теме и понимают, что observability нельзя просто купить. Это важное свойство сложных приложений, которое требует современных подходов к инструментированию и мониторингу.
10 фактов о observability, которые должен знать каждый технический директор
Больше всего пользы observability принесёт в культуре, где инженеры привыкли искать причину любой ошибки.
Всё самое интересное на тему observability мы слышим от реальных инженеров. Например, специалистов из Twitter и Netflix, управляющих системами, которые усложняются прямо на глазах.
Несложно понять, почему инженеры, работающие с современными облачными системами, так болеют за observability — традиционные подходы к мониторингу не дают той же видимости и практической информации.
Кстати, observability — это не только про сложные облачные системы. Её нужно реализовать на всех уровнях организации, чтобы она проявилась во всей красе.
В этой статье мы собрали рекомендации по observability для технических директоров и других руководителей, которые пусть и не занимаются наблюдаемостью каждый день, но должны понимать, что это такое.
В конце концов, пока инженеры по наблюдаемости не получат полную поддержку руководства, их инициативы редко будут давать ожидаемый результат.
Факт 1. Что такое observability
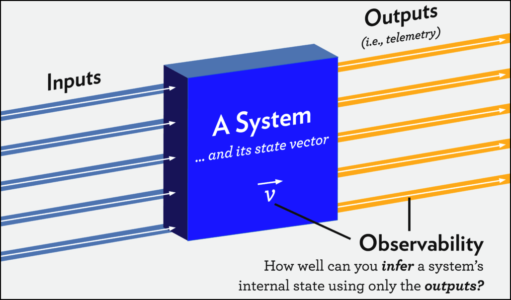
Observability — это показатель того, насколько легко можно понять внутреннее состояние системы по её внешним проявлениям. Это самое общее определение, применимое к любой системе, не только в ИТ.
Например, мы можем собрать данные о производительности (частота и продолжительность запросов, процент ошибок) отдельных микросервисов распределённого приложения, а потом сопоставить эти данные, чтобы оценить работоспособность приложения в целом.
Команда может собирать данные не только из приложений и инфраструктуры, но и из других ресурсов, например конвейеров CI/CD или систем поддержки клиентов, чтобы получить больше контекста. Сопоставляя все эти данные, можно определить, что происходит внутри приложения, и догадаться, из-за каких внешних событий изменилось поведение.
Факт 2. Observability — не просто дань моде
Руководители должны понимать, что observability — это не просто очередной хит сезона. Это совершенно новый подход к мониторингу и контролю производительности приложения.
Чуть позже мы ещё поговорим об истории observability и рассмотрим, чем она отличается от мониторинга и подобных практик. А пока просто знайте, что observability — это полноценная дисциплина, с помощью которой можно понять, что происходит в очень сложных и динамичных распределённых окружениях, где работает современный бизнес.
По поводу наблюдаемости есть разные мнения. Не все восторженные выкрики о наблюдаемости правда. Главное помнить — сама по себе наблюдаемость не решит всех проблем с управлением производительностью в организации.
В этом плане она мало чем отличается от других хайповых понятий, вроде DevOps или облачных вычислений, которые порой обрастают мифами, но все же заметно меняют всю ИТ-отрасль.
Факт 3. Observability появилась не вчера
Это солидная концепция с долгой историей.
Впервые мир услышал о ней ещё в 1960-х годах, когда инженер и изобретатель Рудольф Кальман опубликовал свой труд в области теории управления. В последующие десятилетия observability стала важным понятием в теории управления, теории систем и сфере обработки сигналов.
В ИТ-отрасли на неё обратили внимание только в середине 2010-х, когда о ней заговорили инженеры из крупных ИТ-компаний.
Факт 4. Observability и мониторинг/видимость/телеметрия
Observability — это не синоним мониторинга. Да, оба понятия связаны с пониманием происходящего в системе, но мониторинг показывает сам факт проблемы, а observability помогает понять, что пошло не так и почему это случилось.
Мониторинг | Observability |
Сломалось или нет? | Почему сломалось? |
Реагируем быстро, но после инцидента | Предотвращаем инциденты, сокращаем их продолжительность и последствия |
Сервис работает? | Насколько эффективно работает сервис? |
Разрозненные данные | Тесно связанные данные |
Пассивно потребляем данные и метрики системы | Активно изучаем свою среду |
Observability развивает и продолжает мониторинговые процессы, чтобы мы могли глубже заглянуть в сложные системы. Инструменты мониторинга обычно просто собирают данные и иногда отправляют оповещения, если возникла аномалия или сработал настроенный триггер. Observability позволяет сопоставить данные из отдельных систем, чтобы получить богатый контекст для каждой проблемы, обнаруженной с помощью мониторинга.
От видимости observability отличается тем, что помогает найти причину проблемы, а не просто заметить саму проблему.
Если телеметрия даёт нам голые данные, то observability снабжает их контекстом, чтобы мы могли интерпретировать их.
Получается, что мониторинг, видимость и телеметрия поддерживают наблюдаемость, но наблюдаемость копает глубже и указывает на конкретные меры, которые мы должны принять.
Почему ИТ-отрасль так долго шла к наблюдаемости? Скорее всего потому, что только к 2015 году у разработчиков и ИТ-инженеров возникла необходимость создавать, развёртывать и администрировать очень динамичные распределённые системы, в десятки раз более сложные, чем их предшественники. Когда на смену монолитам и виртуальным машинам пришли контейнеры, мультиоблака и микросервисы, организации стали искать новые способы заглянуть внутрь своих систем, потому что традиционный мониторинг уже не справлялся. Тут-то они и вспомнили про наблюдаемость, которая за несколько десятилетий уже доказала свою состоятельность в инженерных сферах за пределами ИТ.
Факт 5. Observability повышает ROI
С финансовой точки зрения, observability выгоднее, чем только мониторинг и телеметрия.
Отчасти дело в том, что команда быстрее и эффективнее находит и исправляет причины падения производительности, а значит сервисы реже простаивают, а клиенты реже сталкиваются с проблемами, что повышает доходы и лояльность.
Кроме того, инженеры, которые используют инструменты observability, видят проблему в контексте и могут быстрее найти и устранить её причину, чтобы скорее вернуться к другим важным делам. Например, внедрять новые функции, совершенствовать процессы или оптимизировать приложения, чтобы повысить их надёжность и сократить число ошибок.
Факт 6. Observability вписывается в любые системы
Обычно мы говорим о observability в контексте облачных микросервисных приложений, но по сути её можно применить к любой ИТ-среде или архитектуре.
Например, мы можем сопоставлять изменения производительности в монолитном приложении с изменениями в процессах CI/CD, с помощью которых мы его создаём. Точно так же мы можем собирать ценную информацию на локальном сервере или в частном дата-центре.
Конечно, традиционным приложениям observability нужна не так сильно, как облачным, но всё равно принесёт много пользы. На самом деле, наблюдаемость пригодится любому приложению, в любой технологической парадигме.
Факт 7. Чем больше данных, тем лучше
Количество данных о приложении не перерастёт в качество, если мы не сможем переварить такой объём. Просто будем зря платить за лишнее хранилище и вычислительные ресурсы.

К счастью, инструменты наблюдаемости умеют эффективно сопоставлять разрозненные наборы данных, поэтому любые данные принесут пользу. Наблюдаемость нужна, чтобы быстро находить причину проблемы, видеть связь между разными проблемами и обнаруживать падение производительности.
Для этого мы собираем данные отовсюду, а затем анализируем их и выстраиваем контекст, сопоставляя данные из разных систем, например конвейеров CI/CD, платформ обслуживания клиентов и т. д.
В общем, если мы наладили , никакие данные не будут лишними. Чем больше данных и чем больше источников данных, тем проще нам будет выявлять и понимать сложные проблемы.
Урок 8. Observability для всех и каждого
Observability подходит не только для любых систем, но и для любых инженеров.
Информационная безопасность, например, требует специфического набора навыков, а наблюдаемость понятна, приятна и посильна каждому разработчику и инженеру.
Мы уже говорили, что observability используется не только в ИТ, но и в других инженерных дисциплинах, для работы с ней не нужен отдельный диплом.
Факт 9. Observability — это культура
Observability не ограничивается набором инструментов и рабочих процессов. Да, конечно, понадобится специальная платформа для сбора, сопоставления и анализа данных из разных систем, но одной её будет недостаточно.
Нужна целая культура, в которой каждый инженер понимает разницу между observability и мониторингом и инструментирует код в поддержку наблюдаемости.
Больше всего пользы observability принесёт в культуре, где инженеры привыкли искать причину любой ошибки. В развитии культуры наблюдаемости должны участвовать все заинтересованные лица, включая руководство.

SRE-инженеров, которые хотят взять под контроль состояние системы и научиться агрегировать множество SLO/SLI в одну или несколько высокоуровневых метрик, мы приглашаем на курс «SRE: Observability».
Факт 10. Начните прямо сейчас
Рано или поздно всем нам придётся реализовать observability. Это лучший способ управлять производительностью в сложных облачных средах, где сегодня работают ИТ-организации. Даже если вы пока ещё не до конца перешли в облако, наблюдаемость принесёт пользу в локальной среде.
Не думайте, что только избранные ИТ-гиганты могут позволить себе observability. Она доступна и полезна абсолютно всем компаниям во всех отраслях. Было бы ошибкой десять лет ждать развития облачных технологий, прежде чем решиться использовать сервисы в публичных облаках. То же самое можно сказать и о observability.

