
Предыстория
Несколько лет назад Аурига по заданию известного медицинского стартапа разрабатывала решение, связанное с параллельной обработкой нескольких потоков видеоданных. Данные имели критическое значение для успеха малоинвазивной хирургической операции и являлись единственным источником информации для хирурга. Результатом обработки каждого кадра была полоска шириной в один пиксель. Требовалось добиться следующих характеристик передачи данных: синхронная обработка параллельных потоков данных с общей частотой 30 кадров в секунду, 400 мс на прохождение кадра от драйвера устройства до дисплея врача.
Существовали следующие ограничения:
Поток создавался узкоспециализированным аппаратным устройством, имевшим драйвер только под Windows
Алгоритмы обработки кадра реализовались командой заказчика на Python версии 3.7
Концепт решения
Во время работы аналоговое устройство генерировало 16 потоков данных. Драйвер устройства писал их в необработанном виде в кольцевой буфер в неблокирующем режиме работы.
Инициализацией устройства и препроцессингом данных занимается программа, реализованная на языке С++. В её ответственности находился старт/стоп устройства, работа с драйвером, пересортировка и отбраковка кадров согласно информации из служебных каналов потока и конфигурации приложения, а также дальнейшая передача потока данных в следующий компонент.
Вся вычислительно‑сложная математика (Гильбертово преобразование, преобразования Фурье, адаптивная фильтрация и прочие преобразования) проводились в модулях на Python с помощью библиотек numpy и scipy. Из‑за наличия GIL не приходилось рассчитывать на истинную многопоточность. Поэтому приходилось запускать отдельные экземпляры обработчика на Python в виде отдельного процесса ОС для каждого потока данных.
Итоговые сильно похудевшие данные передавались в UI на PyQt.
Первая итерация решения
Математика на тот момент обсчитывала кадр примерно за 150 мс, в оставшееся время (250мс) требовалось уложить все остальные этапы от драйвера до изображения на экране. Тесты производительности нескольких разных очередей MQ (ActiveMQ, Mosquitto, RabbitMQ, ZeroMQ) показали недостаточную стабильность и скорость передачи данных — происходила рассинхронизация независимых потоков, и по проектным требованиям приходилось полностью отбрасывать весь срез остальных кадров с других потоков, что приводило к заметным провалам в визуализации и не могло обеспечить достаточный уровень качества для медицинского изделия.
По первоначальной оценке передаваемых данных, требовалось обеспечить приём и передачу суммарного потока в 25 Мбит/с и размером кадра в 100 килобайт.
С таким потоком вполне могло справиться соединение через TCP‑сокеты, которое легко реализовать с обоих сторон потока — и на С++, и на Python. Тестовые прогоны показали приемлемую производительность и стабильность. Однако продолжавшиеся исследования в области оптической части устройства потребовали передачи и обработки большего объёма данных.
Потребовалось значительно увеличить детализацию считываемых данных, увеличив размер одного кадра со 100 килобайт до 1.1 мегабайта, что увеличило поток данных до 26 Гбит/с., а время обработки одного кадра — до 250–300 мс. В то время, как на стенде заказчика TCP сокет показывал максимальную скорость 1.7 Гбит/с на синтетических тестах.
Несоответствие на порядок располагаемых и требуемых скоростей передачи данных приводило к мгновенному переполнению буферов TCP и последующей каскадной потере пакетов. Требовалось найти новое решение.
Вторая итерация
Следующим кандидатом на среду для передачи были именованные или анонимные каналы. Синтетический тест на стенде показал скорость порядка 21.6 Гбит/с, что вплотную приблизилось к требованиям. Однако уже при старте реализации возникли технические сложности.
Проблемы именованных каналов для передачи большого потока данных
Скорость получения данных превышала скорость передачи, что привело к неконтролируемому росту буферов анонимных каналов, которые были ограничены только доступной памятью. На суточных стресс‑тестах сначала заканчивалась оперативная память, система начинала активно использовать своп до тех пор, пока не заканчивался и своп, что приводило к зависанию стенда.
В процессе работы по этой же причине время прохождения пакета данных по каналу было непредсказуемым — от 50 до 150 мс, что опять же приводило к рассинхронизации каналов и потере данных.
Процессы, считавшие математику, сильно грузили процессор Intel Xeon Gold 40 ядер. Операционной системой они распределялись по разным ядрам таким образом, что каждому обработчику кадра доставалось отдельное ядро, и несколько оставшихся ядер отдавались на нужды операционной системы.
На фоне всего вышесказанного появилась ещё одна, ранее не встречавшаяся проблема: минут через 10–15 после запуска на всех занятых ядрах нагрузка резко взлетала с ~80% до 100%, а время обработки одного кадра при этом увеличивалось в два раза с приемлемых 300 мс до 600–700 мс.
Для изучения этой проблемы использовались инструменты Intel vTune и Windows Performance Toolkit с WPR (Windows Performance Recorder) и WPA (Windows Performance Analyzer).
Анализ снятого event trace log показал резкое увеличение времени выполнения системных вызовов KeZeroPages, что помогло понять, что происходит. Большое спасибо статье Hidden Costs of Memory Allocation
При освобождении региона памяти, ранее выданного процессу, операционная система заполняет его нолями в целях обеспечения безопасности.
Делается это в низкоприоритетном системном процессе, который запущен, по наблюдениям, на самом последнем ядре и тихо делает своё дело — но только до тех пор, пока он успевает занулить всю освобождаемую память.
Как только он перестаёт с этим справляться — задача зануления памяти начинает выполняться в контексте использовавшего его процесса.
Итого у нас имелось:
большой объём кадра
буферизация потока в памяти
множество вызовов NumPy с созданием временных переменных, содержащих в себе обрабатываемый пакет данных
сильная нагрузка на ядра
Совокупность этих факторов привела к тому, что системный процесс зануления страниц не справился с работой в фоне и перекинул её на родные ядра процессов, ещё сильнее увеличив при этом нагрузку из‑за частых переключений контекста на ядре.
Рефакторинг работы с NumPy заметно снизил количество производимой «грязной» памяти, но полностью проблему не решил. Требовалась быстрая и экономная передача данных на стыке C++ и Python, где объём передаваемых данных был максимальным. Альтернатива в виде портирования математики из Python в C++ значительно не укладывалась ни во временные ограничения, ни в бюджет проекта.
Требования к передаче данных
Реализация собственного IPC протокола — задача хоть и не часто встречающаяся, но вполне известная. Немного экзотики добавляли только разные языки программирования. По результатам исследований пришли к следующим требованиям:
Использование кольцевого буфера в shared memory
Фиксированный размер сообщения, задаваемый при старте приложения.
Эксклюзивный издатель / эксклюзивный подписчик
Неблокируемая запись, отбрасывание сообщений при переполнении буфера
Блокирующее чтение
Никаких требований к безопасности: работа в изолированной системе.
Кастомный IPC
В реализации собственного IPC использовался пакет PyWin32 для работы с семафорами через win32api, что позволило получить доступ к одному и тому же семафору из независимых приложений. Для координации доступа к одному буферу, расположенному в shared memory, использовалось два семафора: один на запись и один на чтение.
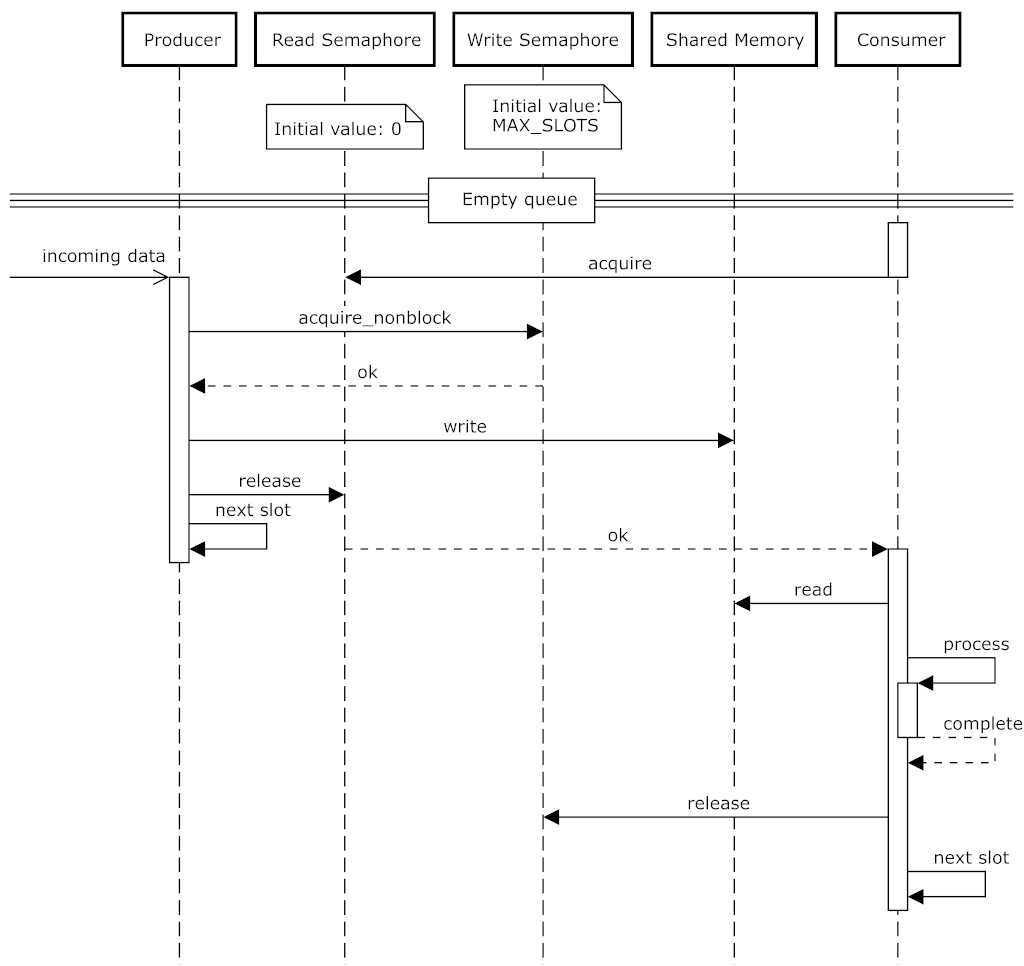
Тестовые прогоны на стенде показали, что буфера длиной в 5 элементов достаточно для сглаживания джиттера передаваемых данных. В редких случаях отсутствия свободного места в буфере, отправляемые данные отбрасывались без блокирования очереди записи.

Примитивность, как протокола, так и передаваемых данных позволила достичь средней скорости передачи одного кадра за 5 мс. Синтетический тест показал нам максимальную пропускную способность порядка 84.7 Гбит/с, с большим запасом перекрывая требования по объёму передаваемых данных и времени доставки.
Выводы
Пройдя путь от использования типовых рекомендуемых протоколов передачи данных для межпроцессного взаимодействия, решение эволюционировало до разработки собственного протокола. Прототипирование и написание собственных синтетических тестов позволило избежать множественных итераций в разработке и неприятных сюрпризов на тестах в составе целевого устройства. Стоит также отметить, что особенности каждой ОС оказывают критическое влияние на итоговую производительность на высоконагруженных задачах. Последующий перенос решения на Linux‑подобную ОС прошел уже без сюрпризов. Также не дали заметного результата попытки изменения конфигурации процессора в BIOS и ручное управление назначением ядер процессам. Итогом можно сказать, что для специфических задач требуются специфические решения.

