Публичный Open Source-релиз Deckhouse состоялся в 2021 году. С тех пор мы много и подробно рассказываем о платформе — на Хабре, на конференциях, в СМИ. Однако когда мы проводим презентации Deckhouse потенциальным клиентам, по-прежнему нередко слышим примерно один и тот же вопрос: «А что вы, вообще, сделали? Взяли Kubernetes и засунули в него разные Open Source-компоненты?»
Я понял, что есть проблема с пониманием продукта и решил рассказать на HighLoad++ 2022, что мы сделали на самом деле.

Видеоверсию доклада можно посмотреть на YouTube (37 минут). Ниже — основная выжимка из него в текстовом виде.
Kubernetes — это не только YAML
Kubernetes — сложная экосистема. Для наглядности воспользуюсь сравнением коллеги
@distolиз его доклада на DevOpsConf 2021: айсбергом.
Если мы смотрим на Kubernetes как обычный пользователь, видим только простые примитивы типа Deployment, Service, Ingress. Создаем их в кластере — и всё, наше приложение работает.

Но если смотреть на Kubernetes так, как это делаем мы, во «Фланте», сразу начинаются вопросы:
как развернуть stateful-приложения;
как настроить масштабирование, балансировку, беспростойные обновления;
как сделать кластер отказоустойчивым, безопасным;
и так далее.
В какой-то момент вы оказываетесь один на один с исходным кодом Kubernetes, у основания айсберга, где холодно и одиноко, а ответы на StackOverflow не гуглятся. Вам приходится самостоятельно разбираться со всеми вопросами.
Мы столкнулись с этой проблемой еще 6 лет назад, когда начали использовать Kubernetes в production. Нам была нужна некая система автоматизации, платформа, которая бы решала эти вопросы внутри компании и предоставляла бы нашим DevOps-инженерам готовые Kubernetes-кластеры.
Наши требования к Kubernetes-платформе
Что нам было нужно:
Надежность и безопасность, потому что мы хотели запускать в K8s-кластерах production клиентов.
Небольшая команда эксплуатации, чтобы обслуживать кластеры минимальными силами.
Идентичные кластеры в любой инфраструктуре, потому что наши клиенты приходят с разного типа инфраструктурой, от публичного облака до закрытого контура.
Снижение нагрузки на пользователей, чтобы им приходилось выполнять минимум операций. В идеале — чтобы это была NoOps-платформа.
В итоге мы сделали Deckhouse — сначала для себя. Но потом поняли, что не только у нас есть такие потребности. Мы открыли код платформы и выложили его на GitHub.
Что же делает Deckhouse
Платформа автоматизирует ключевые операции при работе с кластером:
Подготавливает облачную инфраструктуру или bare-metal.
Разворачивает кластер.
Устанавливает компоненты.
Управляет конфигурацией кластера и всех компонентов.
Обновляет компоненты кластера, сам Kubernetes и внутренние модули платформы.
Таким образом, Deckhouse решает проблему айсберга — скрывает его нижние слои.

Пользователи могут сконцентрироваться на запуске приложений, то есть на том, что приносит основную бизнес-ценность.
Команда
Разработкой и эксплуатацией платформы занимаются 20 инженеров. Но на самом деле команда Deckhouse гораздо больше.

В нее входят, например, DevOps-инженеры «Фланта», которые первыми получают все обновления и приносят обратную связь.
Также у Deckhouse есть Open Source-сообщество, с которым мы активно взаимодействуем, в основном в Telegram. Пользователи приносят нам замечания и пожелания по фичам и документации, рассказывают о трудностях, с которыми сталкиваются.
Жизненный цикл Deckhouse
Планирование
У нас четыре основных источника задач.
Наш roadmap, который сформирован до 2025 года (на GitHub можно посмотреть планы на второй квартал 2023-го). В нем отмечены вехи, которых мы хотим достичь. В ближайших планах, например:
встроенная виртуализации на базе KubeVirt (мы представили модуль виртуализации в феврале — прим. редактора);
пользовательский веб-интерфейс — 1-й квартал (реализация в итоге сдвинулась на 2 квартал 2023-го — прим. редактора.);
managed databases — 3-й квартал.
Иногда мы можем менять планы, так как ИТ-ландшафт быстро меняется.
Обязательная «текучка». Мы регулярно исправляем баги, улучшаем стабильность платформы, дорабатываем CI и тесты, избавляемся от технического долга, обновляем Kubernetes и его компоненты.
DevOps-инженеры «Фланта», а также пользователи нашей услуги Managed Kubernetes и Enterprise-версии Deckhouse. Они помогают нам исправлять баги, улучшать функциональность и документацию.
Сообщество, которое приносит самые интересные задачи. Например, когда мы только выложили платформу на GitHub, в течение двух недель нам завели issues на поддержку, наверное, всех существующих cloud-провайдеров.
Мы планируем задачи на неделю. Сортируем их по источнику, типу — фича, баг, maintenance — и приоритизируем. Все отсортированные задачи можно брать в работу.
Релиз
Минорные версии Deckhouse выходят раз в две недели. Здесь мы следуем практике Kubernetes, у которого пока тоже нет мажорных версий. Ждем, когда выйдет Kubernetes 2.0 :)
Патч-релизы выпускаем по мере необходимости, когда, например, нужно исправить критический баг или поправить уязвимость в уже выпущенных релизах.
Release flow выглядит так:

Open Source-разработка и ее плюсы
Всю разработку мы ведем на GitHub. Раньше использовали автономный GitLab, переезд из которого был болезненным: мы привыкли к GitLab CI, настрадались c GitHub Actions. Но настоящей альтернативы GitHub пока нет — это самый популярный инструмент совместной разработки.
Выложив Deckhouse в Open Source, мы получили два главных преимущества:
клиенты и бизнес нам доверяют;
инженеры могут посмотреть продукт изнутри.
Доверие наших клиентов и бизнеса
Раньше клиентам приходилось спрашивать команду разработки, когда выйдет фича или исправление бага. Сейчас они заходят на GitHub, смотрят, как у нас двигаются Issues, как меняется roadmap. Это максимально прозрачно и удобно.

Открытые исходники — прозрачность для инженеров
Раньше люди могли говорить, что «Флант» сделал какой-то непонятный софт, никто не видел исходников, это vendor lock-in и т. п. Сейчас можно посмотреть на наши исходники и на то, какие решения мы принимали. Это добавляет уверенности в продукте.
Идеология Deckhouse
Мы считаем, что хороший продукт — тот, у которого есть идеология и правильные принципы разработки.
Расскажу, что входит в идеологию Deckhouse.
«Минимум крутилок». Kubernetes — сложная система со множеством параметров, которые можно настраивать. Мы же осознанно ограничиваем возможности настройки. По опыту, мы знаем, что можно подобрать такие значения по умолчанию, которые подойдут 99% пользователей. Мы позволяем управлять конфигурацией, только когда это действительно необходимо.
Это ограничение дает два важных преимущества:
Пользователи меньше думают о настройках — мы снимаем с них когнитивную нагрузку.
Мы можем быть уверены, что даже в закрытых контурах, куда у нас нет доступа, Deckhouse будет работать. Потому что нет параметров, которые можно накрутить так, что платформа сломается.
Собственные интерфейсы, чтобы скрыть реализацию. Например, мы используем machine-controller-manager от Gardener для заказа виртуальных машин в облаках. Над интерфейсами Gardener у нас сделаны свои собственные — NodeGroup, InstanceClass. Это позволяет нам «под капотом» поменять machine-controller-manager на другое решение, например, Cluster API. Для пользователей переезд будет максимально бесшовный, потому что они работают с нашими интерфейсами, а не с интерфейсами Gardener.
NoOps-подход (как следствие предыдущего пункта), благодаря которому пользователи получают безболезненные обновления.
«Ванильность» Kubernetes, никаких форков. Хотя у нас собственные интерфейсы, мы сохраняем «ванильность» Kubernetes и не делаем никаких форков. Любой форк в какой-то момент может перестать поддерживаться. И тогда его будет тяжело синхронизировать с изменениями, которые приехали из upstream Kubernetes. Учитывая, что Kubernetes — это быстро развивающаяся экосистема, форки нам только навредят.
Каждая новая версия Kubernetes, которая поддерживается Deckhouse, проходит официальную сертификацию в CNCF; пример: сертификация Kubernetes 1.25 — прим. редактора.
Еще один плюс «ванильного» Kubernetes: пользователи могут разворачивать приложения с помощью Deckhouse у себя на «железе» и одновременно — в managed Kubernetes от провайдера, который используется в качестве резервной или дополнительной площадки. При этом Helm-чарты приложений одинаковые в обеих инсталляциях (у нас есть такие кейсы).
Наш вклад в upstream Kubernetes и компоненты платформы
Мы считаем, что лучший способ приносить наши идеи в upstream K8s — участвовать в KEP (Kubernetes Enhancement Proposals) и активно работать с сообществом. Только так можно получать всё то новое, что мы хотим от K8s.
")
«Флант» — № 1 среди российских контрибьюторов Kubernetes, а также входит в Топ-150 мировых контрибьюторов за последние 5 лет.
Также мы активно участвуем в разработке других Open Source-компонентов, которые входят в состав платформы. Например:
contaired;
Cilium;
Dex;
LINSTOR;
KubeVirt;
Grafana
и другие.
В блоге на Хабре мы подробно рассказали, как участвовали в доработке Cilium и KubeVirt — прим. редактора.
Open Source-компоненты, которые мы используем, обязательно пересобираем и складываем в свой registry. При этом, если мы изменяем исходный код компонента, делаем мы это через Git-патчи. Обязательно заводим readme, в котором описываем, зачем этот патч делается.
Также мы всегда открываем pull request (PR) в upstream. Главный плюс принятого PR — гарантия того, что наша фича будет работать при обновлении upstream-версии компонента. Это еще и хорошая возможность получить квалифицированную обратную связь.
Пример. До того, как мы ввели практику обязательных pull requests в upstream, мы полгода держали свой патч для containerd. Думали, что он никому не нужен, решает только нашу внутреннюю задачу. Потом решили-таки открыть PR — и получили хорошую обратную связь. Этот PR приняли через две недели.
Тестирование
Мы используем множество разнообразных тестов:
модульные тесты Helm, хуков, OpenAPI;
модульные матричные тесты;
E2E-тесты для каждого провайдера и конфигурации;
E2E-тесты обновления минорной версии Deckhouse;
линтеры кода, линтеры шаблонов, валидаторы и пр.
Но при этом они не могут покрыть все, что можно. Просто потому, что Deckhouse поддерживает много всего:
Публичные облака: Yandex Cloud, AWS, GCP и так далее.
Приватные облака на базе OpenStack, VMware и пр.
Managed Kubernetes от провайдеров.
Bare metal и закрытые окружения.
Несколько схем размещения для каждого публичного и приватного облака.
Два CRI: Docker и сontainerd.
Два CNI: flannel и Cilium.
Несколько десятков модулей.
Мы закрываем проблему с недостаточным покрытием тестами с помощью правильно выстроенного релизного процесса.
Релизный процесс
Правильно выстроенные релизный процесс гарантирует работоспособность релизов.
Для этого у нас есть:
Каналы обновлений: от менее стабильного Alpha-канала до самого стабильного Rock Solid.
Очередность выката: сначала мы выкатываем релиз на Alpha-канале для Deckhouse Flant Edition (FE), двигаемся по каналам дальше и потом таким же образом — на Enterprise Edition (EE) и Community Edition (CE).
Окна обновлений: администратор Deckhouse может выбрать удобное время для автообновления платформы.
Ручные обновления: администраторы получают алерт, что вышла новая версия Deckhouse, и сами решают, когда обновляться.
За этим процессом стоит релиз-инженер, который оповещает пользователей, отслеживает процесс выката релиза с помощью телеметрии и логов, а также первым получает всю информацию о проблемах и инцидентах, которые случаются во время релиза.
В помощь релиз-инженеру есть ответственный за релиз разработчик, это переходящая должность. Ответственный за релиз в первую очередь помогает релиз-инженеру и дает отмашку на то, что можно выкатывать релиз или фикс для релиза.
Инженеры у нас стремятся быть ответственными за релиз, потому что это классный процесс. Когда ты сам разрабатываешь фичи и выкатываешь их в production, испытываешь определенное удовольствие.
Для отслеживания процесса релиза мы собираем логи с deckhouse-controller и kube-apiserver. Также у нас есть телеметрия для сбора информации со всех кластеров, которыми мы управляем в рамках Deckhouse FE.

Важно: мы не собираем телеметрию и метрики с кластеров под управлением Deckhouse CE и EE.
Процесс автоматического обновления Deckhouse
Мы складываем все наши образы в registry.deckhouse.io. Для каждого канала есть специальный образ с метаданными release.yml и тегом, имя которого соответствует каналу стабильности.
Допустим, текущая стабильная версия Deckhouse — 1.35.9:

Deckhouse периодически проверяет образ с метаданными. Если в этом образе обновилась информация, что на канале Stable появилась новая версия — специально протегированный образ 1.36.3, — Deckhouse создаёт в кластере объект Deckhouse Release:
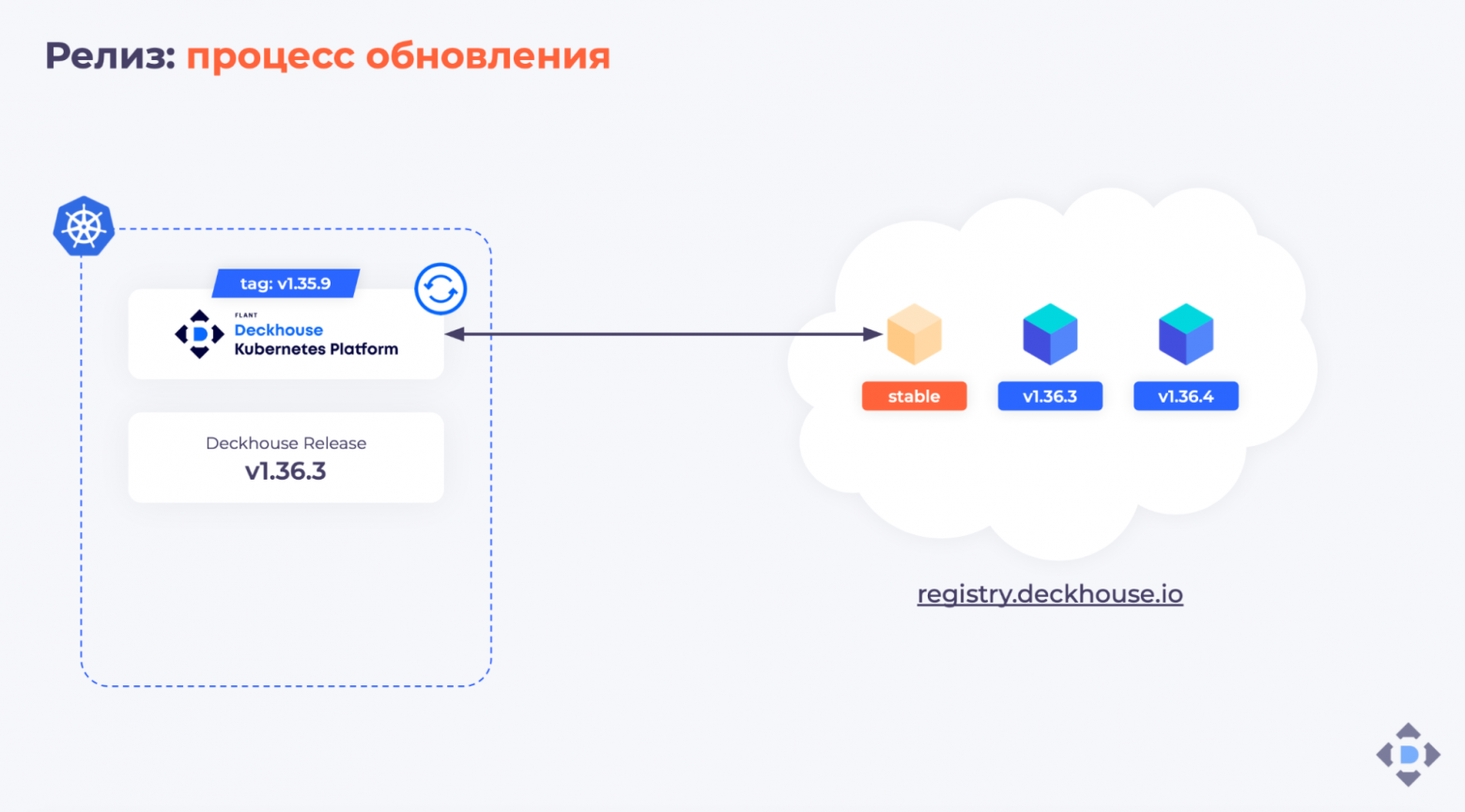
Далее Deckhouse проверяет, что все требования для релиза выполнены. Если всё хорошо, проставляет себе новый тег образа 1.36.3 в Deployment, и в кластере запускается новая версия:

Патч-версии (в нашем примере это v1.36.4) мы выкатываем без учета окон обновлений, потому что в таких версиях содержатся исправления критических проблем. Мы хотим, чтобы они как можно быстрее доезжали до production клиентов.
Вроде бы всё гладко и красиво. Но, естественно, бывают проблемы.
Интересные случаи из практики
Самый забавный пример — когда мы сломали собственный механизм автообновления. Мы выкатили минорный релиз Deckhouse, после чего deckhouse-controller начал падать с паникой. Нам здорово помогли каналы обновлений и то, что мы сначала выкатили новый релиз в кластеры, к которым у нас есть доступ (FE-редакция). В итоге пришлось вручную в каждом кластере менять тег на правильный. Из этого мы сделали вывод, что нам срочно нужен E2E-тест, который проверяет, что обновление минорной версии релиза прошло корректно.
Также был случай с Docker 18.09: при обновлении kubelet у нас зависали узлы. Обновлялась только патч-версия kubelet. Нас спасло то, что на канале Early Access мы используем canary deployment, с помощью которого мы отловили проблему; пострадало не более 15% кластеров. Мы поняли, что нам срочно нужно прекращать поддержку старых версий Docker. Быстро выпустили патч-релиз и запретили обновлять Deckhouse, если не обновлен Docker.
Бывали и чисто менеджерские истории. Например, однажды мы уведомили клиентов, что в Kubernetes версии 1.22 устаревший API. Наши инженеры получили эти алерты, прошлись по сотням репозиториев, обрадованные подумали, что можно больше ничего не делать. Буквально через пару релизов мы сказали, что в 1.25 будут дополнительные deprecations. Инженерам пришлось пройтись еще раз по тем же репозиториям. То тесть мы подкинули двойную работу. И это был совсем не NoOps. Поэтому мы решили, что нужно всегда ставить себя на место пользователей. Мы стали чаще общаться с нашими DevOps-командами, с командами клиента, чтобы обсуждать, как определенное изменение в Deckhouse на них повлияет.
Важные моменты, которые мы поняли для себя относительно процесса релиза:
Обязательная ретроспектива релиза.
Делать выводы из ошибок.
Не катать по ночам.
Роль инженеров эксплуатации в развитии Deckhouse
У Deckhouse уже большая сервисная история, что неудивительно: «Флант» — изначально сервисная компания. Разработчики Deckhouse примерно половину времени уделяют разработке, половину — эксплуатации. Как и наши клиенты, в продукте мы в первую очередь ценим сервис.
За сервис в Deckhouse отвечают:
Дежурный инженер — обрабатывает входящие инциденты и обращения от клиентов Enterprise-версии и клиентов managed K8s.
Дежурный по установке кластеров — отвечает, соответственно, за установку кластеров. В том числе помогает с установкой Deckhouse в частных облаках, которая не всегда так же проста, как установка, например, в публичных облаках.
Дежурные сильно разгружают команду. Инженер, который не дежурит, спокойно работает над плановыми задачами. Но если для решения инцидента дежурному требуется помощь, ему помогает вся команда. Она всегда на связи, тем более если речь идет о решении клиентских проблем.
Еще у нас регулярно бывают демо, пилоты и внедрения, когда нужно привлекать нескольких членов команды.
Также мы помогаем с проблемами на стыке, которые напрямую не относятся к Deckhouse.

Например, бывают кейсы, когда клиенты выкатывают новый релиз в production, liveness-проверки не проходят, и это явно не из-за платформы. Мы обязательно помогаем.
Мы уже не раз слышали от клиентов, что главная ценность Deckhouse — сервис. Инженер может оперативно созвониться с клиентом, чтобы решить его проблему, и приложение спокойно продолжит работать в production.
Итоги
У продукта должна быть идеология и правила.
Протестировать всё невозможно, но помогают правильные процессы.
Релизы нужно катать часто, но безопасно и незаметно для пользователей.
Клиенты зачастую больше ценят сервис, чем фичи.
Обязательно нужно проводить ретроспективу и анализировать ошибки.
И напоследок хочется вернуться к упомянутому в начале вопросу: «А что вы, вообще, сделали? Взяли Kubernetes и засунули в него разные Open Source-компоненты?»
Мой ответ: сделать свою production-ready-платформу, которая работает 24х7 и обслуживает высоконагруженные проекты, очень затратно. Для этого требуется:
много времени;
большая команда людей;
большое вовлечение;
много ресурсов не только на разработку, но и на эксплуатацию.
Видео и слайды
Видеозапись выступления (37 минут):
Презентация:
P.S.
Читайте также в блоге «Фланта»:

