
Во многих компаниях задумываются о внедрении больших больших языковых моделей для векторизации и в качестве классификатора. Однако здесь есть несколько моментов, которые обычно отпугивают. Во-первых, непрогнозируемость улучшения результатов по сравнению с уже имеющимися решениями. Во-вторых, сложности по внедрению этих моделей в промышленную среду. Мы постарались раскрыть весь путь от идеи до ввода в эксплуатацию, описали проблемы, с которыми столкнулись, и их решение.
В начале
Есть чат-бот, и он нужный и няшный
В далёком 2020 году, в разгар пандемии Домклик решил, что нужно сделать чат-бот. Мотивация была довольно простая: нагрузка на менеджеров чата довольно нестабильная, порой кратно вырастала или падала в зависимости от ситуации на рынке (например, ввели льготную ипотеку «Господдержка 2020»). Держать штат сотрудников, чтобы спокойно закрывать такие всплески во время спада, было бы финансово обременительно, а без него мы понесли бы такие же финансовые потери. Возможность закрывать пики нагрузки без аврального режима позволила бы лучше планировать ресурсы сотрудников, отвечающих в чате. Сразу возникает вопрос, а почему не сделали этого раньше и где все эти новомодные Data Science и иже с ними? В конце концов, Домклик — дочка Сбера, у которого чат-бот уже был. Вопрос правильный, но ответ на него связан со сложностями в работе с клиентами и возникающими задачами, которые часто весьма нетривиальны и требуют индивидуального подхода. Выделение из них автоматизируемых тем было непростой задачей. В Домклике было некоторое подобие чат-бота для решения очевидных вопросов, но это была простейшая конструкция, с которой мы и дожили до 2020 года.
Наконец потенциальная выгода от запуска проекта превысила пределы сопротивления дополнительным затратам, и тогда решили: новому чат-боту — быть!
Устойчивый baseline на Fasttext и бустинге
Для начала, у нас не было ничего: ни тематик для автоматизации, ни сценариев для их решения, ни разметки, ни сервиса. Для того, чтобы оценить распределение тематик обращений клиентов и выявить из них потенциально автоматизируемые, мы выделили довольно опытных сотрудников, работающих с клиентами. Им дали задание сосредоточить усилия на решении этой задачи, а также описать процессы решения выявленных вопросов для построения структуры сценариев. Они к нам вернулись с найденными тематиками, их частотностью и примерным описанием процесса их решения. Отобрав самые горячие темы, мы начали работу. Наши разработчики, опираясь на имеющиеся решения, за месяц сделали сервис, который позволял интегрировать чат-бота в имеющуюся систему. Осталось всего ничего: сделать распознавание намерений и сценарии по полученным описаниям процессов. Намерение в данном случае это запрос от пользователя, который можно решить автоматически, без привлечения оператора, а сценарий — это последовательность действий чат-бота для решения запроса от клиента. Сценарии, очевидно, оставили бизнесовой части команды, а сами сосредоточились на распознавании.
Бизнес-задача представляла собой максимальную автоматизацию обработки обращений клиентов при сохранении точности определения намерений. Этой постановкой определяется метрика, которой мы оцениваем модели — f_beta с перекосом на recall.
Первый подход, который имел высокий TTM (time to market), подразумевал поиск намерений на основе косинусного расстояния и регулярок (все любят регулярки за их «если вы использовали регулярки для решения проблемы, то теперь у вас две проблемы» :) ). Для этого подхода требовалось минимальное количество разметки в виде опорных сообщений, характеризующих намерение, по близости к которым и определялось намерение проверяемого сообщения. Работало неплохо, но иногда были довольно неприятные ошибки. Для повышения качества требовалось увеличение количества опорных сообщений и усложнение регулярок. Первое, по сути, уже полноценная разметка, что, в свою очередь, позволяет решать задачу с помощью классификации. Решив идти по этому пути, мы вписались в процесс системной разметки сообщений, естественно, получив боль от настройки баланса между качеством, скоростью и сложностью разметки. Пожертвовав сложностью в пользу качества и скорости, и ещё некоторым качеством в пользу скорости, мы собрали набор данных достаточного для обучения классификатора размера. Понимая оправданность принятых решений, мы боремся с их последствиями до сих пор. Борьба за качество — наша суровая непрерывающаяся часть реальности, наш крест.
Решая задачу классификации, перебирая различные современные и не очень методы, мы пришли к следующему baseline: для векторизации — обученный на наших текстах размерностью 300 Fasttext + классифицирующая часть на основе градиентного бустинга. Этот вариант показывал лучшее качество на нашем наборе данных и имеющейся разметке, и при этом достаточно спокойно вписывался в продовые мощности.
Как пришли к необходимости использовать большие лингвистические модели
Выстроив решение на новом подходе, встав, так сказать, на ступеньку, мы занялись расширением автоматизации покрытия выявленных ранее тем. Система работала и показывала неплохие результаты. Сценариев становилось всё больше, однако попытки увеличить охват (recall) в рамках одного сценария приводили к падению качества (precision) до неприемлемого уровня. Дополнительной болью было то, что, несмотря на использование подхода, показавшего лучшее качество в моменте, мы имели невысокие метрики 0,65-0,7 f-меры при beta = 1,8. Поэтому по мере накопления новых размеченных данных мы продолжали эксперименты с другими моделями и подходами.
Что пытались сделать
Масса экспериментов с моделями для классификации
Команда попробовала различные подходы к классификации. Сначала решили усложнить архитектуру модели и выбрали классический BERT от DeepPavlov, дообучив его как классификатор. Однако эта модель не дала значимого прироста. Также пробовали CNN c Inception-блоками, LSTM-архитектуры, разные виды AutoML-фреймворков (LAMA, H2O). После этого попробовали Metric Learning при помощи Seamese NN на triplet-loss. Также пробовали подход на графовых нейронках, получили аналогичный результат. Мы это связываем с тем, что наша разметка имела сильный дисбаланс классов, и часть из них, хотя и отвечала за разные намерения, но формулировки запросов клиентов к этим классам были очень близки. Иногда даже опытные разметчики совещались, к какому намерению отнести то или иное сообщение. Сопоставимый с baseline-решением результат дал только градиентный бустинг на эмбеддингах из более сложных языковых моделей (опишем их ниже). В итоге мы решили обучить собственные языковые модели для получения более качественных контекстных эмбеддингов.
Эксперименты с различными языковыми моделями
Baseline удалось пробить только двум моделям: ELMO, дообученной на наших чатах, и SBERT от Sber из коробки. Решили двигаться в сторону обучения трансформерных LM. Проверили также несколько моделей от DeepPavlov, от Sber. Наилучшее качество эмбеддингов из коробки показала GPT-3 от Sber — 0,02 f-меры. Чуть хуже качество было у roBERTa, но модель из коробки уже давала прирост 0,01 f-меры на нашей модельной задаче.
Компромисс между скоростью и качеством
GPT-3 работала на inference достаточно медленно, около 700 мс. Нам показалось, что для рабочего онлайн-решения этого недостаточно. При этом roBERTa отрабатывала за 250 мс. Решили дообучать её на текстах наших чатов.
Учим roBERTa
Ху из мисс Роберта?
roBERTa — большая языковая модель, основанная на архитектуре Transformer. По сути, это довольно сильно оптимизированная архитектура BERT с расширенным словарём (до 50 тыс. токенов вместо 30 тыс.), увеличенным размером обучающего пакета и обучением только на задачу masked language modeling (исключена задача next sentence prediction). По результатам ранее проведённых тестов выбрали архитектуру, уже обученную исследовательским подразделением Сбера на корпусах русских текстов.
Дообучение
Для дообучения выбрали диалоги пользователей с операторами за несколько лет, получилось несколько десятков гигабайтов данных. Обучали на этом корпусе на стандартную задачу MLM. Для отслеживания прогресса мы построили конвейер оценки качества эмбеддингов на целевой задаче с оцениванием результата по нашей основной метрике — f-мере.
В итоге улучшение метрики остановилось на +2 % f-меры. Нам показалось, что этого недостаточно для усилий по выкатке в промышленную среду. В работе с эмбеддингами токенов мы использовали разные подходы к получению эмбеддингов предложений, и в итоге сошлись на применении Sentence Transformer. Выбрали его, так как в него можно было легко встроить дообученую roBERT’у, он имел обучаемую часть для агрегации эмбеддингов токенов в эмбеддинги предложений, и в нём из коробки есть приятные функции, пригодившиеся нам позже. Для обучения собрали сиамскую нейронную сеть и сгенерировали пары близких и далёких предложений. Предполагали, что если фразы клиента и оператора следуют друг за другом, то они близки; далёкие выбирали просто через negative sampling. Обучение этой архитектуры заняло намного меньше времени, чем дообучение самой roBERT’ы, при этом прирост метрики составил еще 0,03 f-меры. Итоговая модель давала 0,05 f-меры на целевой задаче. Этот результат стал весомым для запуска создания и выкатки рабочего решения.
Попытка выкатить в эксплуатацию
Используя тот же шаблон, что и для предыдущего сервиса, работающего на Fasttext, мы, не мудрствуя лукаво, собрали сервис на привычных нам ресурсах, выложили на QA и принялись его тестировать, а заодно проверять время ответа. И тут наступила недолгая немая сцена… среднее время ответа было около 30 секунд.
Проверяли на таких ресурсах:
requested: mem: 3072 CPU: 1000 mCPU
limits: mem: 4096 CPU: 1000 mCPU
Потом посмотрели дашборды и увидели там такие графики:
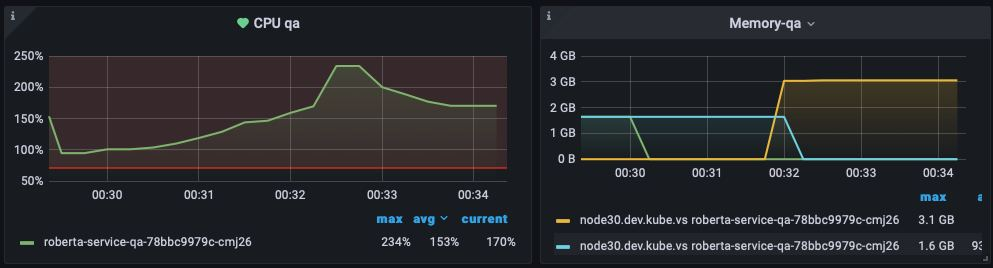
ТТо есть при постоянной нагрузке видим упор в ресурсы процессора. Стало очевидно, — а если бы немного подумали, то стало бы очевидно ранее, — что привычные нам параметры ресурсов, на которых спокойно работал Fasttext, не подошли roBERTa.
Как отбивались
Первое очевидное решение — попробовать увеличить выделенные вычислительные мощности. Обновляем конфигурацию, пробуем катить, и не получается, на QA не хватает для этого ресурсов.
0/__ nodes are available: _ node(s) had taint {__.kubernetes.__/___: }, that the pod didn't tolerate, __ Insufficient cpu, __ Insufficient memory.
К сожалению, за ресурсы наших подов, где располагается roBERTa, конкурируют другие поды сервисов, поэтому просто выделить больше мощностей было нетривиальной задачей, и каждый следующий шаг требовал дополнительных согласований. Так или иначе, через некоторое время, выпросив немного дополнительных мощностей, увеличили до 1500 mCPU и получили такие результаты:

Уже сильно лучше, но 11 секунд всё равно не подходит. Увеличиваем до 2000 mCPU.

Увеличиваем до 3000 mCPU:

С одной стороны, вроде бы вписываемся, но всё равно долго. Поэтому копаем дальше.
Появилась идея использовать TorchServe, потому что были ощущения, что происходят блокировки работы asyncio-сервера при поступлении запросов, и из-за постоянного переключения контекстов сервис в нужный момент не может отдать данные, поскольку поступает другой запрос и опять полностью занимает процессор. Предположили, что в TorchServe этой проблемы не будет, так как там отдельный воркер для обработки запросов и отдельный сервис для HTTP-клиента. Также выдвинули гипотезу обработки пакетами, чтобы обрабатывать не каждый запрос отдельно, а группой.
Переписали на TorchServe, добавили обработку пакетами. Вторая выкатка в прод показала, что, к сожалению, улучшения составили только около 5 %, что, конечно же, не оправдало ожиданий.
Если дерево не идёт к Ходже Насреддину, то Ходжа Насреддин идёт к нему
Если попытки решить вопрос через ресурсы не помогли, ну или помогли не сильно, то надо зайти с другой стороны. Поэтому мы решили уменьшить модель. Как известно, есть различные способы сжать её, и мы решили попробовать квантизацию и дистилляцию. Каждый из них предполагал уменьшение размера и повышение скорости работы модели с понижением качества.
Квантизация
Квантизация — метод уменьшения размера памяти, используемой для нейросети, с помощью замены значений весов на значения меньшей точности. Например, float64 на float32. При этом обычно ускоряются вычисления, так как скорость проведения операция на числах с типами меньшей точности или специализированных типах прилично выше, чем на исходных.
Мы попробовали разные быстрые подходы и получили некоторый рост скорости работы модели и её уменьшение, но в противовес получили значительное падение качества (до уровня baseline) на целевой задаче, которое лишало смысла усилия по внедрению такой модели.
Дистилляция
Так как дистилляция дала нам то, что мы хотели, то про неё расскажем подробнее.
Дистилляцию знаний можно описать как процесс, когда небольшая модель-«ученик» учится имитировать большую модель-«учитель» и использовать её знания для получения такого же или более высокого качества решения задачи.
В нейронной сети знания накапливаются и могут извлекаться из различных источников. Типичная дистилляция знаний использует логиты в качестве источника знаний учителя, но также может быть использована активация промежуточных слоёв или взаимосвязи между различными активациями типа карт внимания.
Существует достаточно много подходов к дистилляции знаний:
дистилляция оффлайн, когда модель учителя уже обучена;
дистилляция с одновременным обучением модели-учителя;
состязательная дистилляция с привлечением методов GAN;
мультидистилляция с ансамблем моделей-учителей;
и другие.
А также есть много способов построения архитектуры модели-ученика:
более простая базовая архитектура;
более лёгкая версия модели-учителя;
квантованная версия модели-учителя;
модель-учитель с оптимизированной архитектурой;
и прочие.
Дополнительные источники информации
Так как наши знания о дистилляции были теоретические, нам нужно было найти источник информации о её практическом применении, и желательно с моделями типа трансформер. Не очень долгий поиск вывел нас на эту статью. В ней авторы дистиллируют трансформер BERT. Модель-ученик представляет собой тоже трансформер, но с уменьшенным количеством слоёв и уменьшенной размерностью эмбеддингов. Это подходило нам, так как мы тоже планировали сделать модель-ученика в виде трансформера, как и модель-учитель, но с уменьшенным количеством слоёв и с сохранением размерности эмбеддингов. Этот вариант позволил бы нам просто подменить модель в конвейере, не меняя ничего в построенных сервисах.
Обучение
Набор для обучения мы взяли тот же, что использовали для дообучения модели-учителя. Модель-ученика мы сделали на основе модели-учителя, только уменьшили количество блоков энкодера. Для инициализации весов модели-ученика взяли веса модели-учителя, то есть можно сказать, что из модели-учителя удалили большую часть блоков энкодера.
Обучали модель на карте Tesla V100 c 32 гигабайтами памяти на борту. Делали это в два этапа (подробности по loss можно посмотреть в вышеуказанной статье). Первый этап:
loss — состоял из MSE-потерь на выходном слое и на слоях внимания;
оптимизатор — Adam;
пакет — 2000 фраз.
Обучали 5 тыс. эпох.

Второй этап (a-la тонкая настройка):
loss — состоял из взвешенной суммы MSE- и KLD-потерь на выходном слое;
оптимизатор — SGD;
пакет — 2000 фраз.
Обучали 10 тыс. эпох.
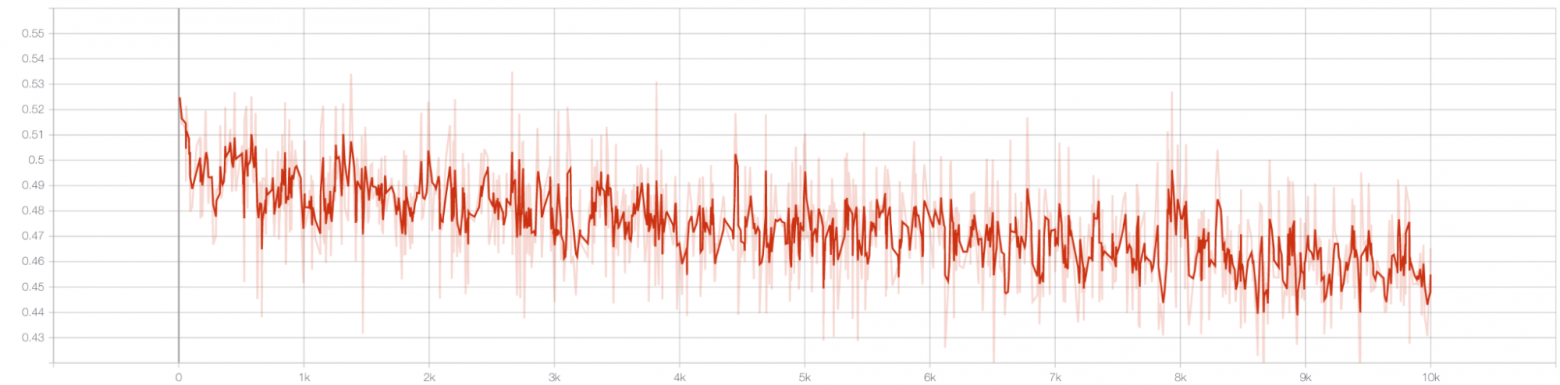
Итоговый результат:
Уменьшение размера почти в три раза. Ускорение в 2-2,5 раза при вычислении на машине, на которой дистиллировали. Целевая метрика уменьшилась всего на несколько сотых (этот момент нам особенно грел душу).
Как видите, подход с дистилляцией дал нам то, что нужно. Так как эта модель используется только для получения эмбеддингов, то период до необходимости переобучения базовой модели и её дистилляции достаточно велик. Для эксплуатации выполнили это всего один раз.
Итоги
Последние актуальные ресурсы, на которых работает сервис с roBERTa:
память: 3500 Мб
процессор: 3000 mCPU
Сейчас roBERTa в эксплуатации работает стабильно. Вот некоторые дашборды:


По среднему времени ответа видно, что большинство запросов укладываются в 250-300 миллисекунд.
Последствия и планы
Описанный выше подход к обучению и встраиванию модели решили использовать в голосовом боте, а также в модели на основе архитектуры GPT-3 в рабочих сервисах команды по борьбе с мошенничеством витрины объявлений.
Использование дистиллированной модели позволило нам повысить качество и практически сохранить время обработки запросов. Такая модель по сравнению с полной позволила сократить время обработки сообщения на 150-200 мс, а качество поднялось на 0,05 f-меры, что составило 10-15 % от количества ошибок классификации.
Планируем продолжить эксперименты с дообучением, дистилляцией и встраиванием больших лингвистических моделей, для этого воспользуемся мощностями суперкомпьютера Cristofary для дообучения LLM и их дистилляции.
Авторы статьи: Алексей Миронов, Павел Пронченко и Александр Пархомин
