
Дедупликация текстов: поиск неполных дубликатов
Простой
6 мин
Кейс
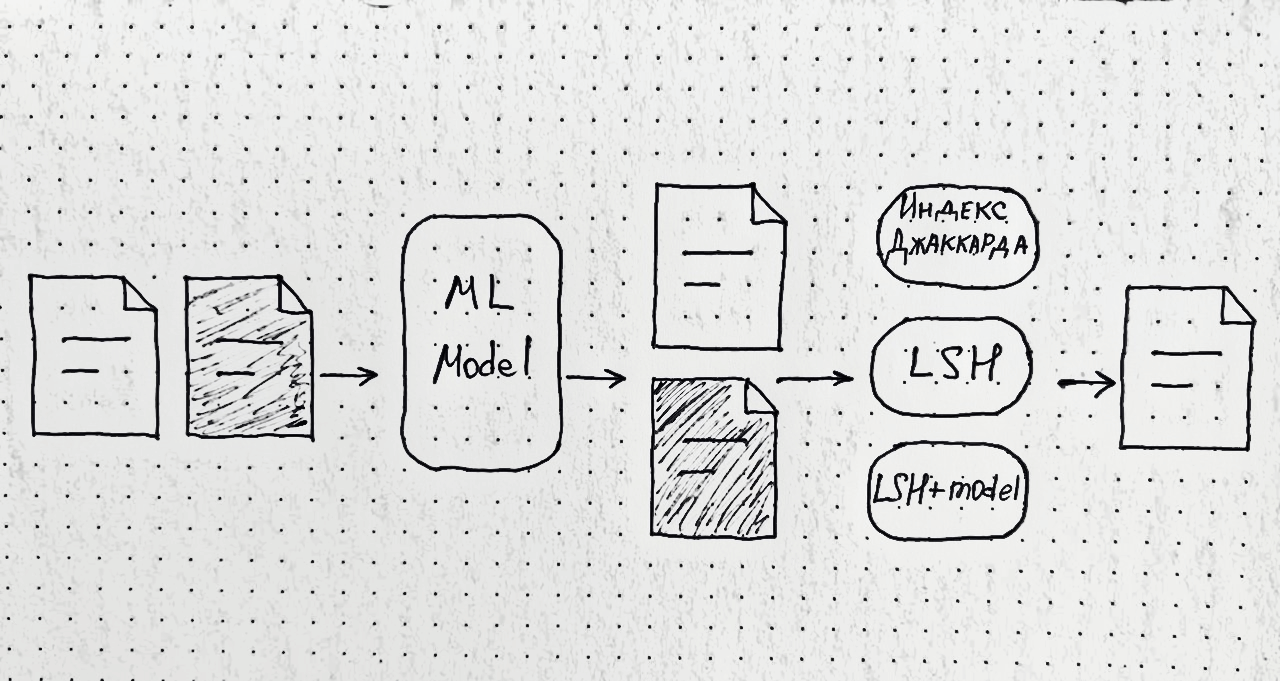
Нам надо искать неполные дубликаты.
При анализе данных могут возникнуть проблемы, если в DataFrame присутствуют дубликаты строк.
Самый простой способ выявить и удалить повторяющиеся строки — это дропнуть их с помощью Pandas, используя метод drop_duplicates(). Но как найти неполные дубликаты, не размечая при этом всех текстовых пар и избегая ложноположительных ошибок?
Нам нужен был такой алгоритм ML, который хорошо масштабируется и работает с пограничными случаями, например, когда разница в парах текстов — только в одной цифре.
Я занимаюсь задачами обработки естественного языка в Газпромбанке. Вместе с DVAMM в этом посте расскажем, какие методы дедупликации мы используем и с какими проблемами столкнулись на практике при детекции неполных дубликатов.