Сравнение скорости процессоров dedicated-серверов
2 мин
(на графике по оси абсцисс логарифмическая шкала)

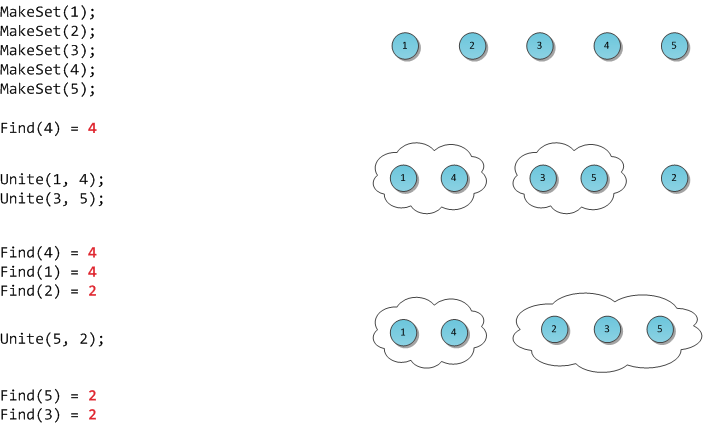
В ходе обсуждения анонса арендуемых серверов на базе атомов по 1500р возник вопрос, насколько атом более медленный, чем остальные платформы.
Вопрос оказался интересным. Вот результаты тестов. В качестве теста использовался sysbench (он есть во многих дистрибутивах Линукса, в т.ч. в Ubuntu и Squeeze).
В тестах различаются два случая — однопоточная и многопточная нагрузка. Типичная нагрузка на посещаемый веб-сервер — многопоточная. Типичная нагрузка для отдельного однопоточного приложения (например, gzip'а на больших данных) — однопоточная.
Хорошо видно, что атомы существенно проигрывают Core/Xeon процессорам, которые в один поток оказываются в полтора-два раза быстрее, чем атом с двумя ядрами и гипертредингом.
Ещё одно интересное наблюдение — на атоме 32-битный и 64-битный режим показывают себя одинаково, на всех остальных процессорах 64-битная архитектура заметно выигрывает у 32-битной.
В качестве эталонного теста использовался вызов nice -20 sysbench --test=cpu --cpu-max-prime=40000 --num-threads=X run (X — число потоков, от 1 до 16).
В ходе обсуждения анонса арендуемых серверов на базе атомов по 1500р возник вопрос, насколько атом более медленный, чем остальные платформы.
Вопрос оказался интересным. Вот результаты тестов. В качестве теста использовался sysbench (он есть во многих дистрибутивах Линукса, в т.ч. в Ubuntu и Squeeze).
В тестах различаются два случая — однопоточная и многопточная нагрузка. Типичная нагрузка на посещаемый веб-сервер — многопоточная. Типичная нагрузка для отдельного однопоточного приложения (например, gzip'а на больших данных) — однопоточная.
Хорошо видно, что атомы существенно проигрывают Core/Xeon процессорам, которые в один поток оказываются в полтора-два раза быстрее, чем атом с двумя ядрами и гипертредингом.
Ещё одно интересное наблюдение — на атоме 32-битный и 64-битный режим показывают себя одинаково, на всех остальных процессорах 64-битная архитектура заметно выигрывает у 32-битной.
В качестве эталонного теста использовался вызов nice -20 sysbench --test=cpu --cpu-max-prime=40000 --num-threads=X run (X — число потоков, от 1 до 16).



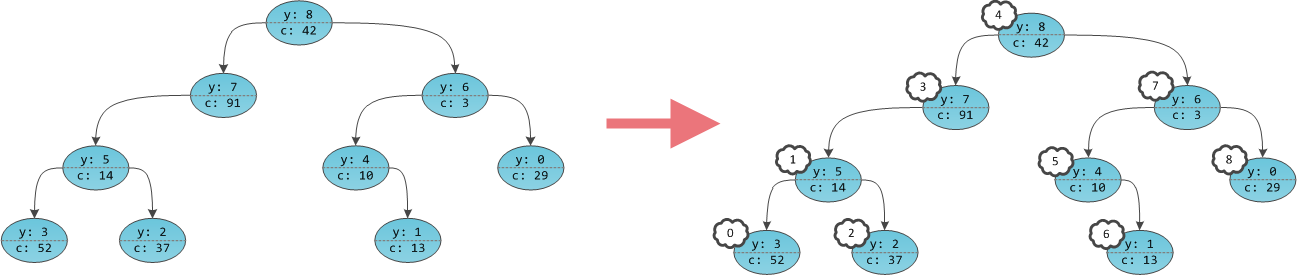
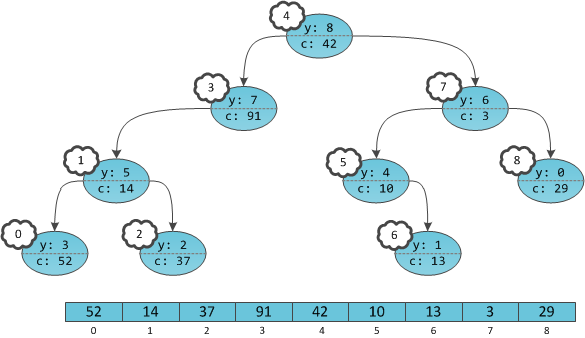
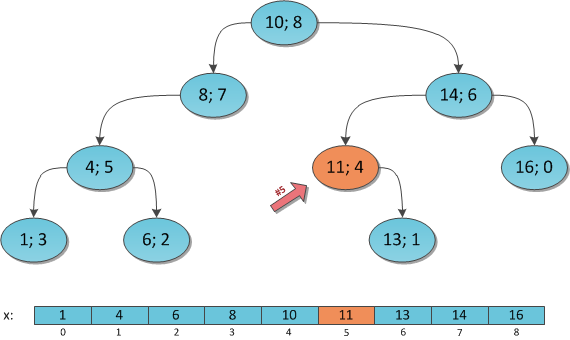
 Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного
Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного