Ещё в тот момент, когда я писал первоначальный обзор VP8, я обратил внимание ��а то, что официальный декодер, libvpx, весьма медленный. Нет особенных причин, по которым он должен быть ощутимо быстрее хорошего декодера H.264, но и таким медленным ему тоже быть не с чего! Так что у меня возник план написать луший вариант для FFmpeg вместе с Рональдом Балтьи (Ronald Bultje) и Дэвидом Конрадом (David Conrad). Эта реализация декодера должна была разрабатываться сообществом и быть свободной с самого начала, в отличии от свалки проприетарного кода, которую представла собой библиотека libvpx. Несколько недель назад декодер был достаточно завершен для обеспечения бинарной совместимости видеопотока с libvpx, что сделало его первой независимой и свободной реализацией декодера VP8. Теперь, когда мы завершили первый цикл оптимизаций, он должен был готов к использованию в реальных условиях. Я расскажу о деталях процесса разработки позже, а сейчас давайте перейдем к самой соли этого поста: результатам сравнительного тестирования производительности кодеков.
Мы тестировали декодер на двух 1080p клипах: Parkjoy, снятый вживую, и Sintel trailer, созданный на компьютере. Тестирование выполнялось так:
Мы использовали последнюю на момент этого поста сборку FFmpeg из SVN, последняя ревизия, содержащая оптимизации VP8 декодера была r24471.
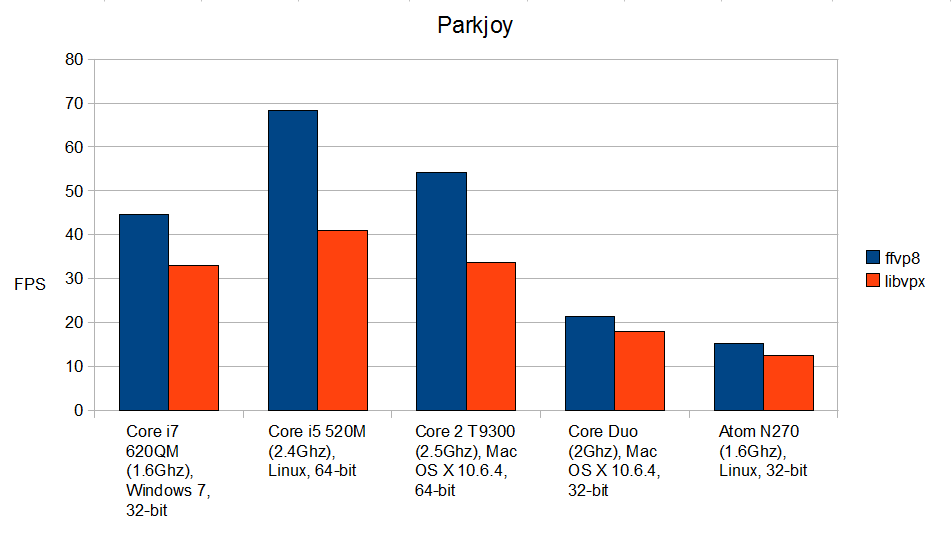
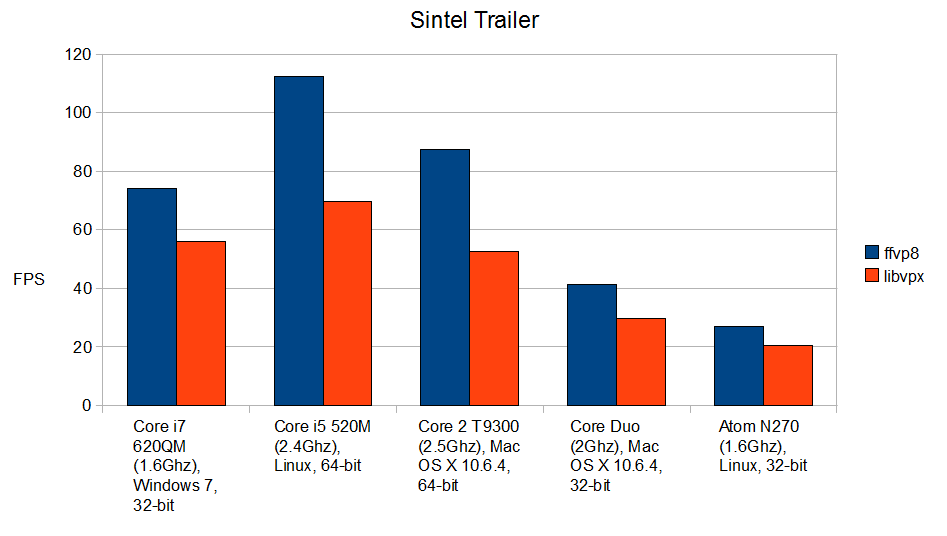
Как показывают эти графики, ffvp8 значительно быстрее libvpx, в особенности, на 64-битных платформах. Даже на процессорах Atom он работает ощутимо быстрее, несмотря на то, что специально для Atom мы его ещё даже не оптимизировали. Во многих случаях от этой разницы в производительности будет зависеть, воспроизводится видео или нет, в особенности, в современных браузерах, движки которых отъедают значительную часть ресурсов процессора. Хотите, чтобы видео в VP8 играло быстрее? Новые версии плееров, основанные на FFmpeg (а это всем известный VLC и многие другие) будут включать библиотеку ffvp8. Хотите, чтобы видео в VP8 быстрее декодировалось в вашем браузере? Общайтесь с его разработчиками, и настаивайте, чтобы они использовали ffvp8 вместо libvpx. Я полагаю, что первым на использование ffvp8 перейдет Chrome, так как они уже используют libavcodec в своей подсистеме воспроизведения видео.
Помните, что разработка ffvp8 на этом не заканчивается, мы будем продолжать улучать и ускорять его. У нас все еще есть очередь оптимизаций, до сих пор не внесенных в основную ветку разработки.
Разработка ffvp8
Первая задача, за которую взялись Дэвид и Рональд, заключалась в воссоздании ядра декодера и доведении его до бинарной совместимости потока с libvpx. Это было непросто, учитывая неполность официальной спецификации. Многие части спецификации вообще были неправильными и противоречили коду libvpx. И уж конечно никак не помог нашей работе тот факт, что набор официальных тестов совместимости даже не покрывает все особенности, которые использует официальный кодер! Для того, чтобы как-то работать дальше при таком положении вещей, нам пришлось начать добавлять свои собственные тесты. Но я уже жаловался на недостаточное качество спецификаций в своих предыдущих постах, так что давайте перейдём к нюансам.
Следующим шагом стало добавление кода SIMD для всех важных функций DSP. В основном нагрузку на процессор в декодере VP8 создает компенсация движения и фильтр деблокинга (компенсации артефактов кодирования, пер.) — так же, как и в H.264. Но, в отличие от H.264, фильтр деблокинга полагается на внутреннюю арифметику с насыщением, которая ничего не стоит в SIMD-реализации, но весьма «прожорлива» в отношении процессора в реализации на C. Разумеется, ни то ни другое не представляет серьезной проблемы, так как во всех нормальных кодеках эти процессы реализованы в виде кода SIMD.
Я помогал Рональду с SIMD для x86, а также написал большую часть компенсации движения, внутреннего предсказания и часть обратных преобразований. Рональд написал оставшуюся часть обратных преобразований и часть компенсации движания. Кроме того, он сделал самую трудную часть: фильтр деблокинга. Эти фильтры — всегда сложная часть, так как в каждом кодеке они разные. Реализация компенсации движения, для сравнения, обычно не слишком отличается в разных кодеках: 6-tap фильтр в любом случае будет 6-tap фильтром, и разница о��ычно только в коэффициентах.
Самая большая сложность в фильтре деблокинга SIMD заключалась в том, чтобы избегать «распаковки», т.е. перехода от 8 битов к 16-ти. Многие операции в таких фильтрах изначально кажутся требующими точности, превышающей 8 бит. Простой пример для x86: abs(a-b), где a и b — целые 8-битные числа без знака. Результат «a-b» требует точности в 9 бит со знаком (так как может быть где угодно в пределах от -255 до 255), так что он не может поместиться в 8 бит. Но вполне возможно решить эту задачу без «распаковки»: (satsub(a,b) | satsub(b,a)), где «satsub» вычисляет разность с насыщением между двумя значениями. Если разница положительная, возвращается результат, в противном случае — ноль, так что выполнение логического ИЛи между результатами работы этих функций как раз дает нам то, что нужно. Это требует 4 ассемблерных инструкций на x86, «распаковка» потребовала бы по меньшей мере 10, включая собственно шаги «распаковки» и «упаковки».
Затем последовала SIMD-оптимизация кода на C, выполнение которого все еще занимало значительную часть времени декодирования. Одна из моих самых больших оптимизаций заключалась в добавлении «умной» предвартельной загрузки, сокращающей количество «промахов» кэша. ffvp8 предзапрашивает кадры, на которые ссылается текущий («ПРЕДЫДУЩИЙ», «ЗОЛОТОЙ» И «АЛЬТЕРНАТИВНАЯ ССЫЛКА», они же PREVIOUS, GOLD и ALTREF), но только тогда, когда они действительно ощутимо используются в данном кадре. Это позволяет нам предзапрашивать все, что нам нужно, и не запрашивать то, что мы вряд ли используем. libvpx, как правило, кодирует кадры, которые почти никогда (но не стоит понимать это как «совсем никогда») не используют кадры GOLDEN или ALTREF, так что эта оптимизация значительно сокращает время, затрачиваемое на предзапросы во многих реальных видеороликах. Кроме того, мы сделали столько оптимизаций в разных местах кода, что все их здесь не перечислить, как, например, оптимизация энтропийного декодера, которую сделал Дэвид. Я также хотел бы поблагодарить Эли Фридмана за его неоценимую помощь в тестировании производительности большинства этих улучшений.
Что дальше? Ассемблерный код Altivec (PPC) фактически отсутствует, есть всего несколько функций из кода компенсации движения Дэвида. Ассемблерного кода для NEON (ARM) нет вообще, а нам он нужен, чтобы работать быстро и на мобильных устройствах. Конечно, все это будет со временем, и, как обычно, мы всегда рады патчам!
Вот цифры, соответствующие приведенным выше графикам, в кадрах в секунду и со стандартными ошибками:
Core i7 620QM (1.6Ghz), Windows 7, 32-bit:
Parkjoy ffvp8: 44.58 ± 0.44
Parkjoy libvpx: 33.06 ± 0.23
Sintel ffvp8: 74.26 ± 1.18
Sintel libvpx: 56.11 ± 0.96
Core i5 520M (2.4Ghz), Linux, 64-bit:
Parkjoy ffvp8: 68.29 ± 0.06
Parkjoy libvpx: 41.06 ± 0.04
Sintel ffvp8: 112.38 ± 0.37
Sintel libvpx: 69.64 ± 0.09
Core 2 T9300 (2.5Ghz), Mac OS X 10.6.4, 64-bit:
Parkjoy ffvp8: 54.09 ± 0.02
Parkjoy libvpx: 33.68 ± 0.01
Sintel ffvp8: 87.54 ± 0.03
Sintel libvpx: 52.74 ± 0.04
Core Duo (2Ghz), Mac OS X 10.6.4, 32-bit:
Parkjoy ffvp8: 21.31 ± 0.02
Parkjoy libvpx: 17.96 ± 0.00
Sintel ffvp8: 41.24 ± 0.01
Sintel libvpx: 29.65 ± 0.02
Atom N270 (1.6Ghz), Linux, 32-bit:
Parkjoy ffvp8: 15.29 ± 0.01
Parkjoy libvpx: 12.46 ± 0.01
Sintel ffvp8: 26.87 ± 0.05
Sintel libvpx: 20.41 ± 0.02
Некоторые термины остались для меня загадкой, например, если кто-нибудь сможет подсказать верный русский перевод 6-tap filter, я буду очень признателен.
Ниже, в комментариях к заметке, автор дает ответы на некоторые вопросы читателей, часть которых я счел уместным привести и здесь. Это не прямой перевод вопросов и ответов, скорее, краткое изложение их сути.
В: Сможет ли ffvp8 использовать улучшения, которые вносятся в libvpx?
О: Фактически, все оптимизации, которые показались интересными — уже взяты оттуда. Но надо понимать, что простым слиянием (merge) исходников тут не обходится, поскольку архитектура у декодеров принципиально различается.
В: Нет ли опасности, что ffvp8 не сможет поддерживать совместимость с экспериментальной веткой разработки libvpx?
О: Такая задача и не стоит, так как на данный момент экспериментальная ветка не предназначена для использования в реальных условиях. Не гарантируется даже совместимость экспериментальной ветки с текущей libvpx.
В: Кто спонсирует разработку FFmpeg?
О: Целиком проект — никто, но некоторые разработчики получают деньги за реализацию фич, необходимых конкретным заказчикам. Насколько известно автору, разработка ffvp8 была полностью некоммерческой.
В: Увеличение производительности связано с одним каким-то глобальным недостатком libvpx, или просто сложилось множество оптимизаций тут и там?
О: В целом, скорее второе. Но основной прирост производительности дало то, что libvpx проходит по кадру несколько раз (аналогичным образом поступают и все предыдущие кодеки On2), а ffvp8 делает все операции за один проход.
В: Планируется ли разработка собственного энкодера VP8 в FFmpeg?
О: Это очень большая работа, и, если честно, я сомневаюсь, что она когда-нибудь будет сделана. Фактически, единственный «родной» энкодер, который есть в FFmpeg — это энкодер mpeg, и вряд ли найдется способ сделать энкодер VP8 только на базе имеющегося фреймворка, во всяком случае, простым этот способ не будет. Но, конечно, если кто-то хочет попробовать…
В: Но если для FFmpeg единственный родной энкодер — mpeg, тогда каким образом эта библиотека поддерживает кодирование видео не только в mpeg, но и в WMV 7/8, H.261/3 и другие форматы без использования других библиотек?
О: Все эти энкодеры фактически используют внутренний mpeg энкодер с небольшими вариациями для каждого формата. Следует иметь в виду, что энкодер — большая и сложная программа, состоящая из многих частей, и единственная значительная разница между энкодерами перечисленных форматов — это алгоритм энтропийного кодирования и заголовки. И то и другое может быть легко заменено без необходимости менять весь остальной код. Вот почему в FFmpeg столько «энкодеров», которые все основаны на основном энкодере mpeg: фактически, разница между этими алгоритмами не столь существенна (все они представляют собой подобия MPEG, основанные на дискретном косинусном преобразовании блоков 8х8 пикселей), так что для всех них может быть использован в значительной степени один и тот же код.
Этим, кстати, и объясняется отсутствие в FFmpeg энкодера WMV9 — этот алгоритм слишком отличается от предыдущих версий, чтобы его можно было легко реализовать на базе того, что есть.
В: Может ли ffvp8 также декодировать VP4, 5, 6 и 7?
О: Может, но только VP4, 5 и 6, так как никто пока не подвергал VP7 обратной разработке. Но, скорее всего, поддержка VP7 появится в ближайшем будущем, учитывая открытие VP8, так как есть у меня подозрение, что VP7 и VP8 по большей части совпадают.
В: Где можно взять свежие SVN-сборки Media Player Classic HomeCinema и FFDshow tryouts, чтобы посмотреть самим на новый декодер под Windows?
О: xhmikosr.1f0.de
Если возникнут какие-нибудь вопросы к автору заметки, я готов перевести их и опубликовать в его блоге.
Мы тестировали декодер на двух 1080p клипах: Parkjoy, снятый вживую, и Sintel trailer, созданный на компьютере. Тестирование выполнялось так:
time ffmpeg -vcodec {libvpx or vp8} -i input -vsync 0 -an -f null -Мы использовали последнюю на момент этого поста сборку FFmpeg из SVN, последняя ревизия, содержащая оптимизации VP8 декодера была r24471.
Как показывают эти графики, ffvp8 значительно быстрее libvpx, в особенности, на 64-битных платформах. Даже на процессорах Atom он работает ощутимо быстрее, несмотря на то, что специально для Atom мы его ещё даже не оптимизировали. Во многих случаях от этой разницы в производительности будет зависеть, воспроизводится видео или нет, в особенности, в современных браузерах, движки которых отъедают значительную часть ресурсов процессора. Хотите, чтобы видео в VP8 играло быстрее? Новые версии плееров, основанные на FFmpeg (а это всем известный VLC и многие другие) будут включать библиотеку ffvp8. Хотите, чтобы видео в VP8 быстрее декодировалось в вашем браузере? Общайтесь с его разработчиками, и настаивайте, чтобы они использовали ffvp8 вместо libvpx. Я полагаю, что первым на использование ffvp8 перейдет Chrome, так как они уже используют libavcodec в своей подсистеме воспроизведения видео.
Помните, что разработка ffvp8 на этом не заканчивается, мы будем продолжать улучать и ускорять его. У нас все еще есть очередь оптимизаций, до сих пор не внесенных в основную ветку разработки.
Разработка ffvp8
Первая задача, за которую взялись Дэвид и Рональд, заключалась в воссоздании ядра декодера и доведении его до бинарной совместимости потока с libvpx. Это было непросто, учитывая неполность официальной спецификации. Многие части спецификации вообще были неправильными и противоречили коду libvpx. И уж конечно никак не помог нашей работе тот факт, что набор официальных тестов совместимости даже не покрывает все особенности, которые использует официальный кодер! Для того, чтобы как-то работать дальше при таком положении вещей, нам пришлось начать добавлять свои собственные тесты. Но я уже жаловался на недостаточное качество спецификаций в своих предыдущих постах, так что давайте перейдём к нюансам.
Следующим шагом стало добавление кода SIMD для всех важных функций DSP. В основном нагрузку на процессор в декодере VP8 создает компенсация движения и фильтр деблокинга (компенсации артефактов кодирования, пер.) — так же, как и в H.264. Но, в отличие от H.264, фильтр деблокинга полагается на внутреннюю арифметику с насыщением, которая ничего не стоит в SIMD-реализации, но весьма «прожорлива» в отношении процессора в реализации на C. Разумеется, ни то ни другое не представляет серьезной проблемы, так как во всех нормальных кодеках эти процессы реализованы в виде кода SIMD.
Я помогал Рональду с SIMD для x86, а также написал большую часть компенсации движения, внутреннего предсказания и часть обратных преобразований. Рональд написал оставшуюся часть обратных преобразований и часть компенсации движания. Кроме того, он сделал самую трудную часть: фильтр деблокинга. Эти фильтры — всегда сложная часть, так как в каждом кодеке они разные. Реализация компенсации движения, для сравнения, обычно не слишком отличается в разных кодеках: 6-tap фильтр в любом случае будет 6-tap фильтром, и разница о��ычно только в коэффициентах.
Самая большая сложность в фильтре деблокинга SIMD заключалась в том, чтобы избегать «распаковки», т.е. перехода от 8 битов к 16-ти. Многие операции в таких фильтрах изначально кажутся требующими точности, превышающей 8 бит. Простой пример для x86: abs(a-b), где a и b — целые 8-битные числа без знака. Результат «a-b» требует точности в 9 бит со знаком (так как может быть где угодно в пределах от -255 до 255), так что он не может поместиться в 8 бит. Но вполне возможно решить эту задачу без «распаковки»: (satsub(a,b) | satsub(b,a)), где «satsub» вычисляет разность с насыщением между двумя значениями. Если разница положительная, возвращается результат, в противном случае — ноль, так что выполнение логического ИЛи между результатами работы этих функций как раз дает нам то, что нужно. Это требует 4 ассемблерных инструкций на x86, «распаковка» потребовала бы по меньшей мере 10, включая собственно шаги «распаковки» и «упаковки».
Затем последовала SIMD-оптимизация кода на C, выполнение которого все еще занимало значительную часть времени декодирования. Одна из моих самых больших оптимизаций заключалась в добавлении «умной» предвартельной загрузки, сокращающей количество «промахов» кэша. ffvp8 предзапрашивает кадры, на которые ссылается текущий («ПРЕДЫДУЩИЙ», «ЗОЛОТОЙ» И «АЛЬТЕРНАТИВНАЯ ССЫЛКА», они же PREVIOUS, GOLD и ALTREF), но только тогда, когда они действительно ощутимо используются в данном кадре. Это позволяет нам предзапрашивать все, что нам нужно, и не запрашивать то, что мы вряд ли используем. libvpx, как правило, кодирует кадры, которые почти никогда (но не стоит понимать это как «совсем никогда») не используют кадры GOLDEN или ALTREF, так что эта оптимизация значительно сокращает время, затрачиваемое на предзапросы во многих реальных видеороликах. Кроме того, мы сделали столько оптимизаций в разных местах кода, что все их здесь не перечислить, как, например, оптимизация энтропийного декодера, которую сделал Дэвид. Я также хотел бы поблагодарить Эли Фридмана за его неоценимую помощь в тестировании производительности большинства этих улучшений.
Что дальше? Ассемблерный код Altivec (PPC) фактически отсутствует, есть всего несколько функций из кода компенсации движения Дэвида. Ассемблерного кода для NEON (ARM) нет вообще, а нам он нужен, чтобы работать быстро и на мобильных устройствах. Конечно, все это будет со временем, и, как обычно, мы всегда рады патчам!
Приложение: голые цифры
Вот цифры, соответствующие приведенным выше графикам, в кадрах в секунду и со стандартными ошибками:
Core i7 620QM (1.6Ghz), Windows 7, 32-bit:
Parkjoy ffvp8: 44.58 ± 0.44
Parkjoy libvpx: 33.06 ± 0.23
Sintel ffvp8: 74.26 ± 1.18
Sintel libvpx: 56.11 ± 0.96
Core i5 520M (2.4Ghz), Linux, 64-bit:
Parkjoy ffvp8: 68.29 ± 0.06
Parkjoy libvpx: 41.06 ± 0.04
Sintel ffvp8: 112.38 ± 0.37
Sintel libvpx: 69.64 ± 0.09
Core 2 T9300 (2.5Ghz), Mac OS X 10.6.4, 64-bit:
Parkjoy ffvp8: 54.09 ± 0.02
Parkjoy libvpx: 33.68 ± 0.01
Sintel ffvp8: 87.54 ± 0.03
Sintel libvpx: 52.74 ± 0.04
Core Duo (2Ghz), Mac OS X 10.6.4, 32-bit:
Parkjoy ffvp8: 21.31 ± 0.02
Parkjoy libvpx: 17.96 ± 0.00
Sintel ffvp8: 41.24 ± 0.01
Sintel libvpx: 29.65 ± 0.02
Atom N270 (1.6Ghz), Linux, 32-bit:
Parkjoy ffvp8: 15.29 ± 0.01
Parkjoy libvpx: 12.46 ± 0.01
Sintel ffvp8: 26.87 ± 0.05
Sintel libvpx: 20.41 ± 0.02
Примечания переводчика
Некоторые термины остались для меня загадкой, например, если кто-нибудь сможет подсказать верный русский перевод 6-tap filter, я буду очень признателен.
Ниже, в комментариях к заметке, автор дает ответы на некоторые вопросы читателей, часть которых я счел уместным привести и здесь. Это не прямой перевод вопросов и ответов, скорее, краткое изложение их сути.
В: Сможет ли ffvp8 использовать улучшения, которые вносятся в libvpx?
О: Фактически, все оптимизации, которые показались интересными — уже взяты оттуда. Но надо понимать, что простым слиянием (merge) исходников тут не обходится, поскольку архитектура у декодеров принципиально различается.
В: Нет ли опасности, что ffvp8 не сможет поддерживать совместимость с экспериментальной веткой разработки libvpx?
О: Такая задача и не стоит, так как на данный момент экспериментальная ветка не предназначена для использования в реальных условиях. Не гарантируется даже совместимость экспериментальной ветки с текущей libvpx.
В: Кто спонсирует разработку FFmpeg?
О: Целиком проект — никто, но некоторые разработчики получают деньги за реализацию фич, необходимых конкретным заказчикам. Насколько известно автору, разработка ffvp8 была полностью некоммерческой.
В: Увеличение производительности связано с одним каким-то глобальным недостатком libvpx, или просто сложилось множество оптимизаций тут и там?
О: В целом, скорее второе. Но основной прирост производительности дало то, что libvpx проходит по кадру несколько раз (аналогичным образом поступают и все предыдущие кодеки On2), а ffvp8 делает все операции за один проход.
В: Планируется ли разработка собственного энкодера VP8 в FFmpeg?
О: Это очень большая работа, и, если честно, я сомневаюсь, что она когда-нибудь будет сделана. Фактически, единственный «родной» энкодер, который есть в FFmpeg — это энкодер mpeg, и вряд ли найдется способ сделать энкодер VP8 только на базе имеющегося фреймворка, во всяком случае, простым этот способ не будет. Но, конечно, если кто-то хочет попробовать…
В: Но если для FFmpeg единственный родной энкодер — mpeg, тогда каким образом эта библиотека поддерживает кодирование видео не только в mpeg, но и в WMV 7/8, H.261/3 и другие форматы без использования других библиотек?
О: Все эти энкодеры фактически используют внутренний mpeg энкодер с небольшими вариациями для каждого формата. Следует иметь в виду, что энкодер — большая и сложная программа, состоящая из многих частей, и единственная значительная разница между энкодерами перечисленных форматов — это алгоритм энтропийного кодирования и заголовки. И то и другое может быть легко заменено без необходимости менять весь остальной код. Вот почему в FFmpeg столько «энкодеров», которые все основаны на основном энкодере mpeg: фактически, разница между этими алгоритмами не столь существенна (все они представляют собой подобия MPEG, основанные на дискретном косинусном преобразовании блоков 8х8 пикселей), так что для всех них может быть использован в значительной степени один и тот же код.
Этим, кстати, и объясняется отсутствие в FFmpeg энкодера WMV9 — этот алгоритм слишком отличается от предыдущих версий, чтобы его можно было легко реализовать на базе того, что есть.
В: Может ли ffvp8 также декодировать VP4, 5, 6 и 7?
О: Может, но только VP4, 5 и 6, так как никто пока не подвергал VP7 обратной разработке. Но, скорее всего, поддержка VP7 появится в ближайшем будущем, учитывая открытие VP8, так как есть у меня подозрение, что VP7 и VP8 по большей части совпадают.
В: Где можно взять свежие SVN-сборки Media Player Classic HomeCinema и FFDshow tryouts, чтобы посмотреть самим на новый декодер под Windows?
О: xhmikosr.1f0.de
Если возникнут какие-нибудь вопросы к автору заметки, я готов перевести их и опубликовать в его блоге.
