Каждые несколько лет IT-индустрия переживает очередной ренессанс. Мы пишем новые языки программирования - Rust для безопасной работы с памятью, Go для идеальной конкурентности, Swift для экосистемности. Мы плодим новые фреймворки, стандарты и сетевые протоколы, пытаясь превзойти существующие ограничения.
Но в погоне за оптимизацией мы не замечаем главного: мы продолжаем строить новые "небоскребы" на старом, потрескавшемся логическом фундаменте. И этот фундамент - это не кремний и не машинный код. Это естественный человеческий язык, на котором думают создатели этих IT-технологий.
Проблема современного "зоопарка" технологий, усложнения синтаксиса и бесконечных архитектурных компромиссов кроется в том, что мы перетащили баги человеческой речи в парадигмы программирования. Не понимая, что этот лингвистический фундамент и есть наше главное ограничение.
Энтропия языков и гипотеза "Искусственного API"
Прежде чем говорить об IT-архитектуре, давайте посмотрим, как развивались языки с точки зрения теории информации.
Любая сложная система, предоставленная сама себе, подчиняется закону возрастания энтропии. В лингвистике это означает, что язык с течением веков "размывается". Народы мигрируют, культуры смешиваются, и строгие первоначальные правила обрастают костылями, исключениями и заимствованиями. Так рождается "лингвистический legacy-код". Современные английский или русский языки - это прекрасные, но невероятно запутанные системы, полные исторических "багов", которые мы заучиваем наизусть просто потому, что "так исторически сложилось".
Но что, если отмотать историю назад? Лингвисты и антропологи давно ищут праязык - исходный код человечества. Базовый протокол, из которого вышли все остальные диалекты.
Если посмотреть на древнейшие языки через призму системного анализа, возникает поразительный парадокс. Некоторые лингвистические системы обладают настолько идеальной, стопроцентной математической логикой, что возникает крамольная мысль: а могла ли слепая эволюция создать настолько совершенный API? В IT-мире, когда мы видим безупречно структурированный код без единого костыля, мы понимаем - у этого кода был высокоуровневый системный архитектор. Изучая материалы исследований (таких как "Тартар и Я"), мы сталкиваемся с феноменом праязыка, структура которого не похожа на продукт хаотичного развития. Она выглядит как искусственно спроектированный фундамент, переданный нам в готовом виде (возможно, цивилизацией совершенно иного порядка) для максимально точной передачи информации.
И этот фундамент сохранился до наших дней. Чтобы понять, почему этот "древний протокол" - ключ к будущему современных IT-технологий, давайте разберем, как человечество вообще пишет код реальности, и сравним типы языков с парадигмами программирования.
Лингвистический ликбез: Как мы пишем код реальности
В лингвистике языки делятся на несколько базовых типов. И если присмотреться, каждая языковая группа породила свою парадигму в IT.
1. Аналитические языки: Процедурный код и позиционная зависимость Яркий пример - английский или китайский. В этих языках сами слова (морфемы) практически не меняются. Смысл предложения выстраивается исключительно за счет жесткого порядка слов и предлогов.
"The manager gave the developer a task" и "The developer gave the manager a task". Набор элементов идентичен, но из-за перестановки позиций смысл меняется на противоположный.
IT-проекция: Это классическое процедурное программирование и скриптовые языки. Логика жестко привязана к последовательности команд и позиционным аргументам функций. Стоит перепутать порядок передачи переменных, и скрипт выдаст критическую ошибку. Зависимость от позиции делает систему хрупкой при масштабировании.
2. Флективные языки: Тяжелое ООП и скрытые состояния К этой группе относятся русский, латынь, немецкий. Это языки, где слово меняет свое окончание, суффикс, а зачастую и сам корень в зависимости от рода, числа и падежа. Одно окончание может нести сразу несколько смыслов, а правила зависят от контекста и имеют сотни исключений.
IT-проекция: Это Объектно-Ориентированное Программирование (ООП) в его самом тяжелом проявлении и монолитные архитектуры. Флексия - это мутация состояния. Корень слова ведет себя как родительский класс, который непредсказуемо меняет форму дочерних элементов в зависимости от внешнего контекста. Вы вносите изменение в одном месте, и это вызывает каскад мутаций во всей структуре. Отсюда растут проблемы side effects, неявных зависимостей и необходимости писать тонны тестов.
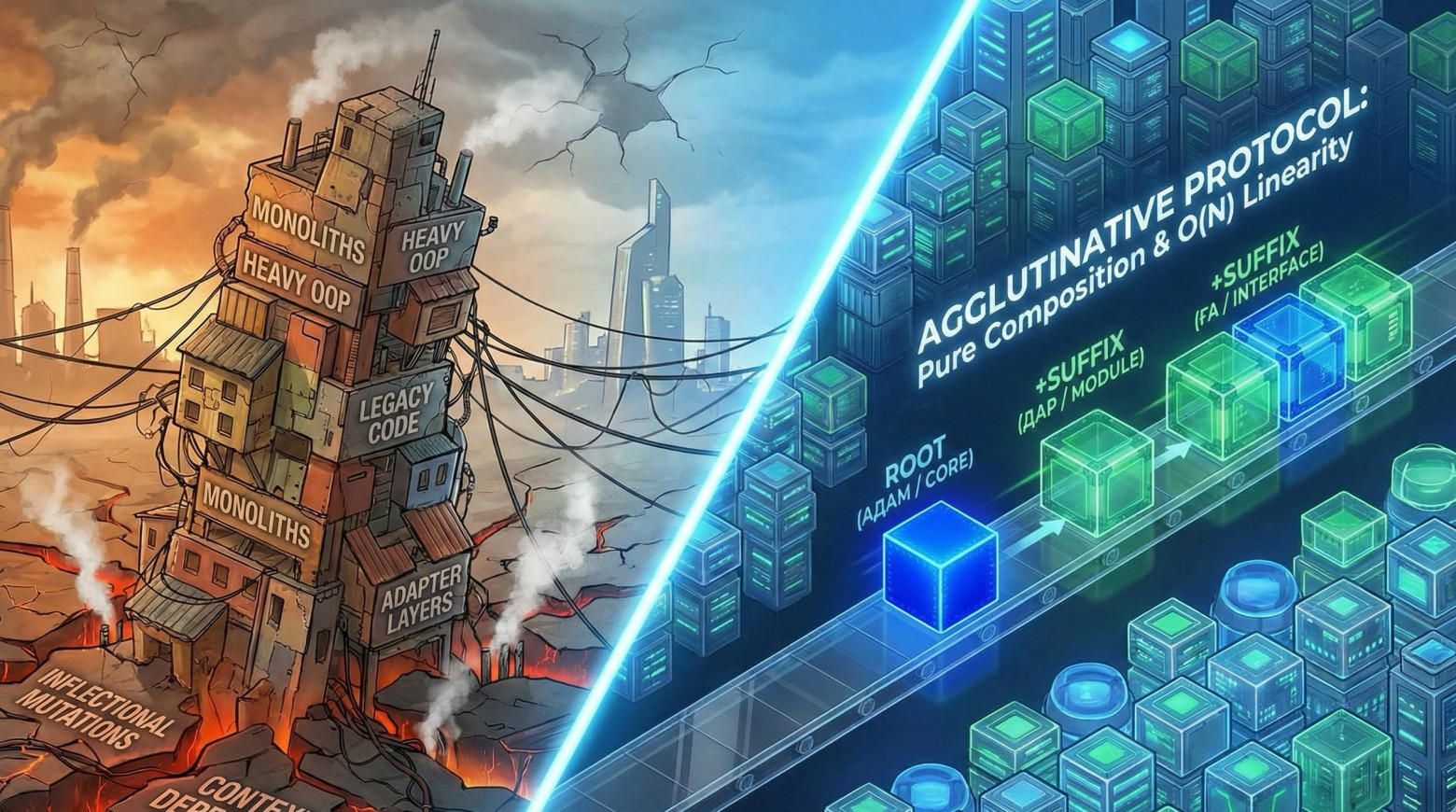
Агглютинативный фундамент: Идеальная архитектура и нулевой технический долг
А теперь мы подходим к главному. Агглютинативные языки (от лат. agglutinatio - приклеивание) - это модель, где к неизменному корню последовательно присоединяются однозначные суффиксы.
Многие ошибочно полагают, что все языки этой группы одинаково стройны. Однако лингвистическая реальность такова, что большинство из них в процессе исторического развития накопили технический долг - примеси флективности и исключения.
Если мы составим матрицу чистоты агглютинативной логики, мы увидим следующую картину:
Язык | Типология | Степень математической чистоты |
Казахский | Агглютинативный | 100% |
Кыргызский | Агглютинативный | 95–97% |
Узбекский | Агглютинативный / смешанный | 85–90% |
Туркменский | Агглютинативный | 85–88% |
Татарский | Агглютинативный | 80–85% |
Башкирский | Агглютинативный | 80–83% |
Как видно из таблицы, даже родственные языки требуют от «парсера» знания исключений из-за исторического слияния с другими языковыми группами. В IT даже 5% отклонений от стандарта означают необходимость писать тысячи строк кода для обработки краевых случаев (edge cases).
Но существует математически чистый эталон - казахский язык. Это пример стопроцентной агглютинативной архитектуры без примесей.
Здесь действует железное правило: Корень слова иммутабелен (никогда не меняется). К нему, как кубики Lego, строго последовательно и предсказуемо «приклеиваются» однозначные аффиксы.
Один суффикс = строго одна функция. Никаких скрытых смыслов, никаких исключений.
Например: "Адам" (человек, базовая сущность) -> "Адам-дар" (люди, добавление модуля множественного числа) -> "Адам-дар-ға" (людям, добавление интерфейса направления). Корень "адам" остался неизменным. Мы просто навесили на него два независимых декоратора.
IT-проекция: Это Святой Грааль архитектуры - чистые функции, строгая модульность и композиция. Это идеальный Unix-way, где каждый компонент делает только одну вещь и передает результат дальше. Это предсказуемость, где нет скрытых состояний, а компиляция смыслов происходит линейно и однозначно.
Конец "зоопарка": Единый стандарт и кратный рост производительности
Сегодня мир IT похож на Вавилонскую башню. Когда мы проектируем высоконагруженные системы, мы сталкиваемся с тем, что бизнес-логика всё еще опирается на контекстозависимое («флективное») мышление. Чтобы заставить разные системы понимать друг друга, мы строим монструозные слои-переводчики: ORM, API-шлюзы, адаптеры. Мы пишем boilerplate-код просто для того, чтобы согласовать форматы данных.
Что произойдет, если мы перейдем на 100% агглютинативный фундамент в проектировании языков программирования, протоколов и архитектурных стандартов? Мы получим рост производительности не на проценты, а в разы. И вот почему:
1. Алгоритмическая простота парсинга (Сложность O(N))
Компиляторам больше не придется строить сложные деревья абстрактного синтаксиса (AST) с оглядкой на контекст. Парсинг агглютинативной структуры, где корень неизменен, выполняется за один проход с предсказуемой алгоритмической сложностью O(N). Это означает мгновенную машинную обработку протоколов без затрат на «понимание» контекста.
2. Устранение когнитивной перегрузки инженеров
В современных флективных архитектурах разработчику нужно держать в голове всё состояние системы. В агглютинативной IT-парадигме когнитивная нагрузка снижается на порядки. Разработчик видит "корень" (базовый сервис) и цепочку "аффиксов" (мидлвары). Логика читается слева направо. Порог входа в такие системы минимален.
3. Единый протокол вместо "зоопарка"
Нам больше не придется выбирать между REST, gRPC или GraphQL. Представьте сетевой протокол, работающий по модели казахского языка: у вас есть неизменный байтовый корень (сама транзакция) и стандартизированный набор "прилипающих" заголовков-суффиксов (маршрутизация, тип валюты, статус). Никакой вложенной JSON-матрешки, требующей рекурсивного разбора. Только плоская, однозначная и математически выверенная структура.
Заключение
Мы подошли к пределу сложности, которую может переварить человеческий мозг, используя старые парадигмы. Попытки строить новые IT-системы на фундаменте логики, изобилующей исключениями и мутациями - это тупик.
Будущее IT - за чистой модульностью. Изучение и перенос 100% агглютинативной логики, эталоном которой является казахский язык, в архитектуру информационных систем - это не лингвистический эксперимент. Это инженерная необходимость. Только так мы сможем устранить зоопарк технологий, объединить разрозненные протоколы в единый стандарт и получить отказоустойчивые системы, которые проще в понимании и кратно быстрее в работе.
Язык | Группа | Уровень "чистоты" (Immutability) | IT-Аналогия |
Казахский | Тюркская | ~99-100% | Pure Functional Language. Корень - константа. Аффиксы - чистые функции. O(N) парсинг. |
Кыргызский | Тюркская | ~95-97% | Почти эталон, минимальные фонетические мутации. |
Турецкий | Тюркская | ~90-95% | Структурно чист, но имеет исторические наслоения (лексический "легаси"). |
Японский | Японская | ~80-85% | Агглютинативный строй, но с контекстной зависимостью, сложной вежливостью и исключениями. |
Финский / Эстонский | Финно-угорская | ~70-75% | Legacy Codebase. Агглютинация есть, но корень мутирует (чередование ступеней). Парсеру нужно знать контекст, чтобы восстановить исходную форму. |
Русский / Немецкий | Флективные | ~0-10% | Spaghetti Monolith. Сплошные мутации состояний, исключения и зависимости. |
