В продолжение статьи Евгения Ческидова «Яндекс. Директ. Анализируем конкурентное окружение» я хочу показать, как при помощи не очень сложных расчетов и API Яндекса вытащить из Директа буквально всю информацию о рекламных кампаниях конкурентов. Сразу скажу, что идея на практике еще не проверялась, сам факт наличия всей информации и, соответственно, возможности этого расчета был показан Ческидовым только вчера, а алгоритм родился буквально сейчас. Но математически вроде бы всё сходится. Осторожно, под катом много формул.
i – это порядковый номер объявления на странице «показать все рекламные результаты».
b[i] = bid, пока неизвестная максимальная ставка i-того объявления. Из правил Директа следует, что
20 ≥ b[1] ≥ b[2] ≥ b[3] ≥…≥ b[i] ≥ b[i+1] ≥… ≥ 0.01 (1)
c[i] – пока неизвестный нам CTR i-того объявления, 0.01 ≤ c[i] ≤ 1.0
a[i] – «эффективная ставка», по которой сортируются объявления в SERP-е, по определению
a[i] = b[i] ∙ c[i] (2)
o[i] – позиция i-того объявления в SERP-е (странице результатов поиска). Порядок в SERPе определяется по a, а не по b, поэтому в общем случае o[i] ≠ i. Подробно этот факт рассматривается в статье Ческидова.
r[j] – есть обратная функция к o[i], то есть r[o[i]] = o[r[i]] = i. Физически это индекс i объявления, которое занимает j-тую позицию в SERPе, если считать, что в спецразмещении находятся объявления с номерами j=1…3, а в правом блоке – с номерами j = 4…10.
Из правил конкуренции объявлений Директа в выдаче SERPa нам известно, что
a[r[1]] ≥ a[r[2]] ≥ … ≥ a[r[j]] ≥ a[r[j+1]] ≥ … (3)
s[i] – это номер стратегии показов по близким ключевым фразам, выбранной для i-того объявления:
• s[i] = 0, если в качестве ключевой фразы используется фраза без кавычек и минус-слов
• s[i] = 1, если используется ключевая фраза с минус-словами
• s[i] = 2, если используется ключевая фраза в кавычках
Случай s[i]=2 можно определить, заметив отсутствие объявления по ключевой фразе с несуществующим словом, например, [розовые слоны фв243ае]. Для определения случая s[i]=1 нужно найти в вордстате самое очевидное (частотное) минус-слово для запроса и проверить наличие объявления по запросу с этим минус-словом, например [розовые слоны бесплатно].
Из «прогноза бюджета» для каждой стратегии s можно вытащить усредненные значения начальных условий b0, c0 и соответственно а0:
b0[s,1] – прогноз цены первого места в спецразмещении
b0[s,3] – прогноз цены входа в спецразмещение
c0[s,3] – прогноз CTR в спецразмещении
b0[s,4] – прогноз цены первого места
c0[s,4] – прогноз CTR первого места
b0[s,10] – прогноз цены входа в гарантированные показы
c0[s,10] – прогноз CTR в гарантированных показах.
Ещё раз отметим, что это усредненные прогнозы, а не настоящие значения параметров, то есть
b0[s,i] ≠ b[i] для всех i > 1
Зато можно утверждать, что эффективная ставка a[i] в прогнозе точно равна реальной эффективной ставке i-того места, то есть
a0[s[i],i]=a[r[i]], а конкретнее
a0[s[3],3] = a[r[3]] (4)
a0[s[4],4] = a[r[4]] (5)
a0[s[10],10] = a[r[10]] (6)
Наконец, обозначим через K[s] общее количество запросов в месяц по ключевой фразе по каждой стратегии.
Как человек просматривает страницу с результатами? Читает первое объявление, с некоторой вероятностью p кликает на него, в противном случае читает второе объявление, опять с некоторой вероятностью кликает, и так далее. Переведем это на язык формул и обозначим через Xi дискретное событие, равное 1, если пользователь кликнул по i-тому объявлению, и 0, если не кликнул:
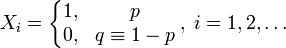
Так как SERP просматривают тысячи пользователей, то такие события независимы. Математики доказали, что в такой модели вероятность клика по i-той позиции подчиняется закону геометрического распределения и равна
P(n) = p ∙ (1-p)n, (7)
где n есть номер объявления, начиная с нуля, а p – это некий параметр, зависящий от конкретной ключевой фразы.
Сама по себе функция P(n) еще не есть CTR, так как учитывает только позицию объявления на странице. В Директе на CTR влияет также выборка, по которой производится показ конкретного объявления (то есть стратегия показов), история позиций (накопленный CTR) и качество самого объявления. Историю можно накопить, если методично сканировать SERP. Что касается качества самих объявлений, то в конкурентных тематиках оно примерно одинаковое, и, так как пользователи не вчитываются в выдачу, а просматривают её по диагонали — большой роли не играет.
Переводя с математического на русский, объявление на 8-ой позиции не может иметь CTR 70% или хотя бы 20%. И наоборот, вы, конечно, можете разместить отвратительное объявление на первом месте спецразмещения и «задавить деньгами», но, какой бы у вас ни был бюджет, по мере набора статистики от пользователей CTR этого объявления упадет и вы неизбежно свалитесь сначала с первого места, а потом и вообще из показов.
Так что в этой статье для простоты я буду рассматривать CTR как функцию от позиции и стратегии. Заинтересованные читатели могут сами учесть такие факторы, как история изменения позиций, вхождение ключевой фразы в текст объявления или релевантность текста объявления остальным объявлениям на странице.
Надо отметить, что небольшое неустранимое расхождение между теорией и практикой всё-таки есть: в математике последовательность предполагается бесконечной, а реальная выдача ограничена. Это приводит к тому, что фактический CTR последних объявлений в блоке немного завышен относительно теоретической вероятности.
Чтобы было хоть немного понятно, о чем шла речь в предыдущих абзацах, приведу два графика:
На первом изображен график зависимости CTR от позиции из доклада Александра Садовского:

На втором графике приведена функция вероятности для геометрического распределения с разными параметрами p (из Википедии)

Зная для каждого объявления его позицию и стратегию, нам нужно оценить ожидаемый CTR этого объявления, то есть вычислить параметр p из формулы (7).
Для правого блока всё просто, ожидаемый CTR первого места в правом блоке даётся нам Яндексом, то есть
pr [s] = c0[s,4] (8)
которое нужно вычислить для всех стратегий s.
Зная pr, мы можем вычислить теоретические значения c1 для всех i по формуле
с1[s,r[i]] = pr[s] ∙ (1 – pr[s])r[i]-4 (9)
Для верхнего блока (там другой параметр p) всё немного сложнее, так как Яндекс раскрывает значение CTR не для первого объявления в спецразмещении, а только для третьего. Придется поискать справочник по математике и решить кубическое уравнение
p3 – 2p2 + p – c0[s,3] = 0 (10)
Далее аналогично (8), только показатель степени будет r[i]-1.
Распишем выражения (1) и (3) в виде системы обычных неравенств
b[1] ≥ b[2]
b[2] ≥ b[3]
…
b[9] ≥ b[10]
b[r[1]] ∙ с[r[1]] ≥ b[r[2]] ∙ c[r[2]]
b[r[2]] ∙ с[r[2]] ≥ b[r[3]] ∙ c[r[3]]
…
b[r[9]] ∙ с[r[9]] ≥ b[r[9]] ∙ c[r[9]]
(для случая с N=10 объявлениями)
Примечание: мы не сможем решить систему, если объявлений больше 10 – мы просто не увидим «вторую страницу директа» и не узнаем соотношения между a[r[i]] для i>10. Объявления-аутсайдеры придется выкинуть из расчетов.
Добавляем в систему граничные условия на b и c и начальные значения, заданные уравнениями (4)...(6).
Таким образом, мы получим систему неравенств второго порядка с 2N неизвестными, 3N неравенствами и тремя уравнениями. Свойство этой системы таково, что для каждой пары неизвестных b[i], c[i] существует небольшая гиперболическая область, в которой эти параметры могут изменяться, не нарушая условий неравенств.
Чтобы разрешить эту неопределенность, нам нужно добавить дополнительные ограничения на b и c таким образом, что b[i] стремятся к нулю при условии сохранения позиций (никто не будет переплачивать просто так), а c[i] стремятся к теоретически ожидаемым значениям.
При этих дополнительных ограничениях мы не сможем найти настоящее значение максимальных ставок, а только минимально-необходимые значения, чтобы объявления заняли наблюдаемые места. На практике это означает, что если самое дорогое объявление имеет ставку 10 у.е., а реально для первого места нужно только 3.01 у.е., мы найдем значение 3.01. Но в нашем случае это неважно, потому что Яндекс и так сообщает нам самую большую ставку по ключевому слову, а все остальные ставки последовательно меньше предыдущей.
Введем в систему «штрафную функцию» — меру, показывающую, насколько приближенное решение не удовлетворяет нашим условиям.
Структура штрафной функции будет примерно такой:
1. Большой штраф за невыполнение неравенств (1) (упорядоченность b[i]), небольшой штраф за «перевыполнение» этих неравенств;
2. Большой штраф за невыполнение неравенств (2) (упорядоченность a[i]), нулевой штраф за их выполнение.
3. Очень большой штраф за невыполнение граничных условий на c[i]
4. Большой штраф за невыполнение уравнений (4)...(6).
5. Некоторый штраф за отклонение c[i]-тых от теоретических значений.
Таким образом, мы получаем обычную задачу оптимизации функции штрафа, то есть поиска таких значений b[i] и c[i], при которых значение штрафной функции будет минимально. Алгоритмы поиска такого решения давно известны из раздела математики, который так и называется — «методы оптимизации». Применив подходящий алгоритм, мы в конце концов получим значения b[i] и c[i], то есть ставки и CTR для всех конкурирующих объявлений.
Теперь самое интересное: зная для каждого объявления ставку, CTR, стратегию и количество показов K[s], мы можем оценить максимальный месячный бюджет каждого объявления по данному ключевому слову. Зная CTR и K[s] – оценить количество переходов и, таким образом, целевой трафик на сайте конкурента. А зная бюджет и количество переходов, мы можем оценить стоимость каждого перехода, то есть качество настройки рекламной кампании. Зная качество ведения рекламной кампании, мы можем сделать далеко идущие выводы, которые, впрочем, никакой математикой уже не описываются)
Наконец, зная семантическое ядро предметной области и подключившись к директу через API, мы можем посчитать суммарный бюджет всех рекламный кампании конкурентов по всему ядру в почти автоматическом режиме. «Почти» — потому что ядро и минус-слова всё-таки придется отбирать вручную.
А зная реальные бюджеты всех конкурентов… ну, вы поняли.
В-общем, Яндекс предоставил всю информацию, чтобы играть в Директе «с открытыми глазами».
Вот такой вот прикладной Data Mining в действии.
1. Для начала введем обозначения:
i – это порядковый номер объявления на странице «показать все рекламные результаты».
b[i] = bid, пока неизвестная максимальная ставка i-того объявления. Из правил Директа следует, что
20 ≥ b[1] ≥ b[2] ≥ b[3] ≥…≥ b[i] ≥ b[i+1] ≥… ≥ 0.01 (1)
c[i] – пока неизвестный нам CTR i-того объявления, 0.01 ≤ c[i] ≤ 1.0
a[i] – «эффективная ставка», по которой сортируются объявления в SERP-е, по определению
a[i] = b[i] ∙ c[i] (2)
o[i] – позиция i-того объявления в SERP-е (странице результатов поиска). Порядок в SERPе определяется по a, а не по b, поэтому в общем случае o[i] ≠ i. Подробно этот факт рассматривается в статье Ческидова.
r[j] – есть обратная функция к o[i], то есть r[o[i]] = o[r[i]] = i. Физически это индекс i объявления, которое занимает j-тую позицию в SERPе, если считать, что в спецразмещении находятся объявления с номерами j=1…3, а в правом блоке – с номерами j = 4…10.
Из правил конкуренции объявлений Директа в выдаче SERPa нам известно, что
a[r[1]] ≥ a[r[2]] ≥ … ≥ a[r[j]] ≥ a[r[j+1]] ≥ … (3)
s[i] – это номер стратегии показов по близким ключевым фразам, выбранной для i-того объявления:
• s[i] = 0, если в качестве ключевой фразы используется фраза без кавычек и минус-слов
• s[i] = 1, если используется ключевая фраза с минус-словами
• s[i] = 2, если используется ключевая фраза в кавычках
Случай s[i]=2 можно определить, заметив отсутствие объявления по ключевой фразе с несуществующим словом, например, [розовые слоны фв243ае]. Для определения случая s[i]=1 нужно найти в вордстате самое очевидное (частотное) минус-слово для запроса и проверить наличие объявления по запросу с этим минус-словом, например [розовые слоны бесплатно].
Из «прогноза бюджета» для каждой стратегии s можно вытащить усредненные значения начальных условий b0, c0 и соответственно а0:
b0[s,1] – прогноз цены первого места в спецразмещении
b0[s,3] – прогноз цены входа в спецразмещение
c0[s,3] – прогноз CTR в спецразмещении
b0[s,4] – прогноз цены первого места
c0[s,4] – прогноз CTR первого места
b0[s,10] – прогноз цены входа в гарантированные показы
c0[s,10] – прогноз CTR в гарантированных показах.
Ещё раз отметим, что это усредненные прогнозы, а не настоящие значения параметров, то есть
b0[s,i] ≠ b[i] для всех i > 1
Зато можно утверждать, что эффективная ставка a[i] в прогнозе точно равна реальной эффективной ставке i-того места, то есть
a0[s[i],i]=a[r[i]], а конкретнее
a0[s[3],3] = a[r[3]] (4)
a0[s[4],4] = a[r[4]] (5)
a0[s[10],10] = a[r[10]] (6)
Наконец, обозначим через K[s] общее количество запросов в месяц по ключевой фразе по каждой стратегии.
2. Статистическая модель пользователя Яндекса
Как человек просматривает страницу с результатами? Читает первое объявление, с некоторой вероятностью p кликает на него, в противном случае читает второе объявление, опять с некоторой вероятностью кликает, и так далее. Переведем это на язык формул и обозначим через Xi дискретное событие, равное 1, если пользователь кликнул по i-тому объявлению, и 0, если не кликнул:
Так как SERP просматривают тысячи пользователей, то такие события независимы. Математики доказали, что в такой модели вероятность клика по i-той позиции подчиняется закону геометрического распределения и равна
P(n) = p ∙ (1-p)n, (7)
где n есть номер объявления, начиная с нуля, а p – это некий параметр, зависящий от конкретной ключевой фразы.
Сама по себе функция P(n) еще не есть CTR, так как учитывает только позицию объявления на странице. В Директе на CTR влияет также выборка, по которой производится показ конкретного объявления (то есть стратегия показов), история позиций (накопленный CTR) и качество самого объявления. Историю можно накопить, если методично сканировать SERP. Что касается качества самих объявлений, то в конкурентных тематиках оно примерно одинаковое, и, так как пользователи не вчитываются в выдачу, а просматривают её по диагонали — большой роли не играет.
Переводя с математического на русский, объявление на 8-ой позиции не может иметь CTR 70% или хотя бы 20%. И наоборот, вы, конечно, можете разместить отвратительное объявление на первом месте спецразмещения и «задавить деньгами», но, какой бы у вас ни был бюджет, по мере набора статистики от пользователей CTR этого объявления упадет и вы неизбежно свалитесь сначала с первого места, а потом и вообще из показов.
Так что в этой статье для простоты я буду рассматривать CTR как функцию от позиции и стратегии. Заинтересованные читатели могут сами учесть такие факторы, как история изменения позиций, вхождение ключевой фразы в текст объявления или релевантность текста объявления остальным объявлениям на странице.
Надо отметить, что небольшое неустранимое расхождение между теорией и практикой всё-таки есть: в математике последовательность предполагается бесконечной, а реальная выдача ограничена. Это приводит к тому, что фактический CTR последних объявлений в блоке немного завышен относительно теоретической вероятности.
Чтобы было хоть немного понятно, о чем шла речь в предыдущих абзацах, приведу два графика:
На первом изображен график зависимости CTR от позиции из доклада Александра Садовского:
На втором графике приведена функция вероятности для геометрического распределения с разными параметрами p (из Википедии)
3. Вычисление теоретического CTR
Зная для каждого объявления его позицию и стратегию, нам нужно оценить ожидаемый CTR этого объявления, то есть вычислить параметр p из формулы (7).
Для правого блока всё просто, ожидаемый CTR первого места в правом блоке даётся нам Яндексом, то есть
pr [s] = c0[s,4] (8)
которое нужно вычислить для всех стратегий s.
Зная pr, мы можем вычислить теоретические значения c1 для всех i по формуле
с1[s,r[i]] = pr[s] ∙ (1 – pr[s])r[i]-4 (9)
Для верхнего блока (там другой параметр p) всё немного сложнее, так как Яндекс раскрывает значение CTR не для первого объявления в спецразмещении, а только для третьего. Придется поискать справочник по математике и решить кубическое уравнение
p3 – 2p2 + p – c0[s,3] = 0 (10)
Далее аналогично (8), только показатель степени будет r[i]-1.
4. Собираем систему уравнений.
Распишем выражения (1) и (3) в виде системы обычных неравенств
b[1] ≥ b[2]
b[2] ≥ b[3]
…
b[9] ≥ b[10]
b[r[1]] ∙ с[r[1]] ≥ b[r[2]] ∙ c[r[2]]
b[r[2]] ∙ с[r[2]] ≥ b[r[3]] ∙ c[r[3]]
…
b[r[9]] ∙ с[r[9]] ≥ b[r[9]] ∙ c[r[9]]
(для случая с N=10 объявлениями)
Примечание: мы не сможем решить систему, если объявлений больше 10 – мы просто не увидим «вторую страницу директа» и не узнаем соотношения между a[r[i]] для i>10. Объявления-аутсайдеры придется выкинуть из расчетов.
Добавляем в систему граничные условия на b и c и начальные значения, заданные уравнениями (4)...(6).
Таким образом, мы получим систему неравенств второго порядка с 2N неизвестными, 3N неравенствами и тремя уравнениями. Свойство этой системы таково, что для каждой пары неизвестных b[i], c[i] существует небольшая гиперболическая область, в которой эти параметры могут изменяться, не нарушая условий неравенств.
Чтобы разрешить эту неопределенность, нам нужно добавить дополнительные ограничения на b и c таким образом, что b[i] стремятся к нулю при условии сохранения позиций (никто не будет переплачивать просто так), а c[i] стремятся к теоретически ожидаемым значениям.
При этих дополнительных ограничениях мы не сможем найти настоящее значение максимальных ставок, а только минимально-необходимые значения, чтобы объявления заняли наблюдаемые места. На практике это означает, что если самое дорогое объявление имеет ставку 10 у.е., а реально для первого места нужно только 3.01 у.е., мы найдем значение 3.01. Но в нашем случае это неважно, потому что Яндекс и так сообщает нам самую большую ставку по ключевому слову, а все остальные ставки последовательно меньше предыдущей.
Введем в систему «штрафную функцию» — меру, показывающую, насколько приближенное решение не удовлетворяет нашим условиям.
Структура штрафной функции будет примерно такой:
1. Большой штраф за невыполнение неравенств (1) (упорядоченность b[i]), небольшой штраф за «перевыполнение» этих неравенств;
2. Большой штраф за невыполнение неравенств (2) (упорядоченность a[i]), нулевой штраф за их выполнение.
3. Очень большой штраф за невыполнение граничных условий на c[i]
4. Большой штраф за невыполнение уравнений (4)...(6).
5. Некоторый штраф за отклонение c[i]-тых от теоретических значений.
Таким образом, мы получаем обычную задачу оптимизации функции штрафа, то есть поиска таких значений b[i] и c[i], при которых значение штрафной функции будет минимально. Алгоритмы поиска такого решения давно известны из раздела математики, который так и называется — «методы оптимизации». Применив подходящий алгоритм, мы в конце концов получим значения b[i] и c[i], то есть ставки и CTR для всех конкурирующих объявлений.
5. PROFIT!
Теперь самое интересное: зная для каждого объявления ставку, CTR, стратегию и количество показов K[s], мы можем оценить максимальный месячный бюджет каждого объявления по данному ключевому слову. Зная CTR и K[s] – оценить количество переходов и, таким образом, целевой трафик на сайте конкурента. А зная бюджет и количество переходов, мы можем оценить стоимость каждого перехода, то есть качество настройки рекламной кампании. Зная качество ведения рекламной кампании, мы можем сделать далеко идущие выводы, которые, впрочем, никакой математикой уже не описываются)
Наконец, зная семантическое ядро предметной области и подключившись к директу через API, мы можем посчитать суммарный бюджет всех рекламный кампании конкурентов по всему ядру в почти автоматическом режиме. «Почти» — потому что ядро и минус-слова всё-таки придется отбирать вручную.
А зная реальные бюджеты всех конкурентов… ну, вы поняли.
В-общем, Яндекс предоставил всю информацию, чтобы играть в Директе «с открытыми глазами».
Вот такой вот прикладной Data Mining в действии.
