
Перевод статьи "(How to Write a (Lisp) Interpreter (in Python))" Питера Норвига. В данной статье Питер довольно кратко, но емко описывает принцип работы интерпретаторов и показывает как можно написать совсем крошечный (всего 90 строк на Python) интерпретатор подмножества языка Scheme. Перевод публикуется с разрешения автора.
 Питер Норвиг (англ. Peter Norvig) — американский ученый в области вычислительной техники. В данный момент работает директором по исследованиям (ранее — директор по качеству поиска) в корпорации Google. Ранее являлся главой Подразделения вычислительной техники в исследовательском центре Амес NASA, где он руководил штатом из двухсот ученых, занимающихся разработками NASA в областях анатомии и робототехники, автоматизированной разработке ПО и анализа данных, нейроинженерии, разработки коллективных систем, и принятия решений, основанном на симуляции.
Питер Норвиг (англ. Peter Norvig) — американский ученый в области вычислительной техники. В данный момент работает директором по исследованиям (ранее — директор по качеству поиска) в корпорации Google. Ранее являлся главой Подразделения вычислительной техники в исследовательском центре Амес NASA, где он руководил штатом из двухсот ученых, занимающихся разработками NASA в областях анатомии и робототехники, автоматизированной разработке ПО и анализа данных, нейроинженерии, разработки коллективных систем, и принятия решений, основанном на симуляции.Эта статья преследует две цели: в общих чертах описать имплементацию интерпретаторов языков программирования, а так же продемонстрировать реализацию подмножества языка Scheme, диалекта Lisp, используя Python. Я назвал свой интерпретатор Lispy (lis.py). Год назад я показывал как написать интерпретатор Scheme на Java, а так же на Common Lisp. На этот раз целью является демонстрация, кратко и доступно насколько возможно, того, что Алан Кей назвал «Уравнения Максвелла программного обеспечения» (Maxwell's Equations of Software).
Синтаксис и семантика Lispy
Большинство языков программирования имеют различные синтаксические соглашения (ключевые слова, инфиксные операторы, скобки, приоритет операторов, точечная нотация, точки с запятой, и т.д.), но как у члена семьи языков Lisp, весь синтаксис Scheme основан на списках в скобочно-префиксной нотации. Эта форма может показаться незнакомой, но она имеет преимущества в простоте и согласованности. Некоторые шутят, что «Lisp» означает «Много Раздражающих Глупых Скобок» (Lots of Irritating Silly Parentheses), я считаю, это означает «Lisp синтаксически чист» (Lisp Is Syntactically Pure). Смотрите:
| Java | Scheme | |
|---|---|---|
if (x.val() > 0) {<br> z = f(a * x.val() + b);<br>} |
(if (> (val x) 0)<br> (set! z (f (+ (* a (val x)) b)))) |
Обратите внимание, что восклицательный знак не является специальным символом в Scheme, это просто часть имени "
set!". Только скобки являются специальными символами. Список, такой как (set! x y), со специальным ключевым словом в начале называется специальной формой в Scheme; красота языка заключается в том, что нам необходимо всего лишь 6 специальных форм, плюс 3 синтаксические конструкции — переменные, константы и вызов процедур:| Форма | Синтаксис | Семантика и Пример |
|---|---|---|
| ссылка на переменную |
var |
Символ интерпретируется как имя переменной, его значение — значение переменной. Пример: x |
| константный литерал |
number |
Число означает само себя. Примеры: 12 или -3.45e+6 |
| цитата |
(quote exp) |
Возвращает exp литерально, не вычисляя его. Пример: |
| условный |
(if test conseq alt) |
Вычислить test; если истина, вычислить и вернуть conseq; иначе вычислить и вернуть alt. Пример: (if (< 10 20) (+ 1 1) (+ 3 3)) ⇒ 2 |
| присваивание |
(set! var exp) |
Вычислить exp и присвоить значение переменной var, которая должна быть ранее определена (с помощью define или как параметр процедуры).Пример: (set! x2 (* x x)) |
| определение |
(define var exp) |
Определить новую переменную в самой вложенной среде и дать ей значение вычисления выражения exp. Примеры: (define r 3) или (define square (lambda (x) (* x x))). |
| функция |
(lambda (var...) exp) |
Создать функцию с параметром(-ами) с названиями var... и выражением в теле. Пример: (lambda ( r ) (* 3.141592653 (* r r))) |
| определение последовательности | (begin exp...) |
Вычислить каждое выражение слева-направо и вернуть последнее значение. Пример: (begin (set! x 1) (set! x (+ x 1)) (* x 2)) ⇒ 4 |
| вызов процедуры |
(proc exp...) |
Если proc не if, set!, define, lambda, begin, или quote то она рассматривается как процедура. Она вычисляется по тем же правилам, которые определены здесь. Все выражения вычисляются, и затем функция вызывается со списком выражений в аргументе.Пример: (square 12) ⇒ 144 |
В этой таблице, var должен быть символом — идентификатором, таким как
x или square; number — должно быть целым или числом с плавающей точкой, в то время как остальные выделенные курсивом слова могут быть любыми выражениеми. Обозначение exp... означает ноль или более повторений exp.Чтобы узнать больше о Схеме обратитесь к следующим замечательным книгам (Friedman и Fellesein, Dybvig, Queinnec, Harvey и Wright или Sussman и Abelson), видео (Abelson и Sussman), введениям (Dorai, PLT, или Neller), или справочному руководству.
Что делает интерпретатор языка
Интерпретатор состоит из двух частей:
- Разбор: компонент разбора получает на вход программу в виде последовательности символов, проверяет ее в соответствии с синтаксическими правилами языка и переводит программу во внутреннее представление. В простом интерпретаторе внутреннее представление выглядит как древовидная структура, которая точно отражает структуру вложенных операторов и выражений в программе. В языковом трансляторе, называемом компилятор, внутреннее представление — это последовательность инструкций, которые могут быть напрямую выполнены компьютером. Как сказал Стив Егге (Steve Yegge), «Если вы не знаете как работают компиляторы, значит вы не знаете как работают компьютеры». Егге описал 8 сценариев, которые могут быть решены с помощью компиляторов (или, что эквивалентно, интерпретаторами). Парсер Lispy реализован при помощи функции
parse.
- Выполнение: внутреннее представление обрабатывается в соответствии с семантическими правилами языка, тем самым проводятся вычисления. Выполнение осуществляется функцией
eval(обратите внимание, она скрывает встроенную функцию Python).
Вот так выглядит картина процесса интерпретации и интерактивной сессии, показывающая как
parse и eval обрабатывают короткую программу:
>> program = "(begin (define r 3) (* 3.141592653 (* r r)))"
>>> parse(program)
['begin', ['define', 'r', 3], ['*', 3.141592653, ['*', 'r', 'r']]]
>>> eval(parse(program))
28.274333877
Мы используем простейшее внутреннее представление, где списки, числа и символы Scheme представлены списками, числами и строками Python соответственно.
Выполнение: eval
Каждый из девяти случаев из таблицы выше имеет одну, две или три строки кода. Для определения
eval больше ничего не нужно:def eval(x, env=global_env):
"Evaluate an expression in an environment."
if isa(x, Symbol): # variable reference
return env.find(x)[x]
elif not isa(x, list): # constant literal
return x
elif x[0] == 'quote': # (quote exp)
(_, exp) = x
return exp
elif x[0] == 'if': # (if test conseq alt)
(_, test, conseq, alt) = x
return eval((conseq if eval(test, env) else alt), env)
elif x[0] == 'set!': # (set! var exp)
(_, var, exp) = x
env.find(var)[var] = eval(exp, env)
elif x[0] == 'define': # (define var exp)
(_, var, exp) = x
env[var] = eval(exp, env)
elif x[0] == 'lambda': # (lambda (var*) exp)
(_, vars, exp) = x
return lambda *args: eval(exp, Env(vars, args, env))
elif x[0] == 'begin': # (begin exp*)
for exp in x[1:]:
val = eval(exp, env)
return val
else: # (proc exp*)
exps = [eval(exp, env) for exp in x]
proc = exps.pop(0)
return proc(*exps)
isa = isinstance
Symbol = str
Вот и все, что нужно eval!.. ну, за исключением сред. Среда — просто отображение символов на значения принадлежащих им. Новые связи символ/значение добавляются с помощью
define или (lambda выражение). Давайте взглянем на пример того, что происходит, когда мы объявляем и вызываем функцию в Scheme (подсказка
lis.py> значит, что мы взаимодействуем с интерпретатором Lisp, а не Python):lis.py> (define area (lambda (r) (* 3.141592653 (* r r))))
lis.py> (area 3)
28.274333877
Когда мы выполняем
(lambda ( r ) (* 3.141592653 (* r r))), мы попадаем в ветку elif x[0] == 'lambda' в eval, присваиваем трем переменным (_, vars, exp) соответствующие элементы списка x (и сигнализируем об ошибке, если длина x не 3). Мы создаем новую функцию, которая будучи вызванной, вычислит выражение ['*', 3.141592653 ['*', 'r', 'r']] в среде, сформированной связкой формальных параметров функции (в данном случае, только один параметр r) с аргументами в вызове функции, а так же используя текущую среду для любых переменных, которые не являются параметрами (в примере, переменная *). Значение этой новоявленной функции затем присваивается в качестве значения area в global_env.Теперь, что произойдет, когда мы вычислим
(area 3)? Т.к. area не является специальной формой символов, значит это вызов функции (последний else: в eval), и весь список выражений выполниться за раз. Вычисление area возвращает функцию, которую мы только что создали; вычисление 3 возвращает 3. Тогда (в соответствии с последней строкой eval) вызывается только что созданная функция со списком аргументов [3]. Это значит выполнение exp, которое ['*', 3.141592653 ['*', 'r', 'r']] в среде, где r равно 3 и внешняя среда является глобальной, и поэтому * является функцией умножения.Теперь мы готовы к пояснению деталей класса
Env:class Env(dict):
"An environment: a dict of {'var':val} pairs, with an outer Env."
def __init__(self, parms=(), args=(), outer=None):
self.update(zip(parms,args))
self.outer = outer
def find(self, var):
"Find the innermost Env where var appears."
return self if var in self else self.outer.find(var)
Обратите внимание, что класс
Env является подклассом dict, это означает, что на нем работают обычные словарные операции. Кроме того есть два метода, конструктор __init__ и find для поиска правильного окружения для переменной. Ключом к пониманию этого класса (а так же к причине того, что мы не используем просто dict) является понятие внешней среды. Рассмотрим следующую программу: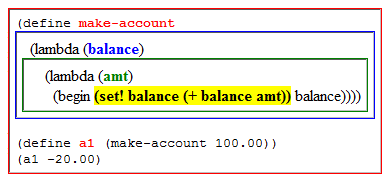
Каждый прямоугольник представляет среду, а его цвет соответствует цвету переменных, которые были определены в этой среде. В последних двух строчках мы определяем
a1 и вызываем (a1 -20.00); эти две строчки представляют создание банковского аккаунта с балансом $100 и последующим снятием $20. В процессе выполнения (a1 -20.00) мы вычисляем выражение выделенное желтым цветом. В этом выражении задействованы 3 переменные. Переменная amt может быть найдена незамедлительно в самой вложенной (зеленой) среде. Но balance не определена здесь, мы будем искать во внешней среде относительно зеленой, т.е. в синей. И наконец, переменная + не найдена ни в одной из этих сред, нам надо сделать еще один шаг в глобальную (красную) среду. Этот процесс поиска, от внутренней среды шагая к внешним называется лексическим определением контекста (lexical scoping). Procedure.find находит правильную среду в соответствии с лексической областью видимости.Все что осталось — определить глобальную среду. Необходимо иметь
+ и все остальные встроенные в Scheme функции. Мы не будем беспокоиться о реализации их всех, мы получим кучу необходимого импортировав модуль math в Python и затем явно добавив 20 популярных из них: def add_globals(env):
"Add some Scheme standard procedures to an environment."
import math, operator as op
env.update(vars(math)) # sin, sqrt, ...
env.update(
{'+':op.add, '-':op.sub, '*':op.mul, '/':op.div, 'not':op.not_,
'>':op.gt, '<':op.lt, '>=':op.ge, '<=':op.le, '=':op.eq,
'equal?':op.eq, 'eq?':op.is_, 'length':len, 'cons':lambda x,y:[x]+y,
'car':lambda x:x[0],'cdr':lambda x:x[1:], 'append':op.add,
'list':lambda *x:list(x), 'list?': lambda x:isa(x,list),
'null?':lambda x:x==[], 'symbol?':lambda x: isa(x, Symbol)})
return env
global_env = add_globals(Env())
Разбор: read и parse
Теперь про функцию
parse. Разбор традиционно разделяется на две части: лексический анализ, в процессе которого входная строка символов разбивается на последовательность токенов, и синтаксический анализ, в процессе которого токены собираются во внутреннее представление. Токены Lispy это скобки, символы (такие как set! или x), и числа. Вот как это работает:>>> program = "(set! x*2 (* x 2))"
>>> tokenize(program)
['(', 'set!', 'x*2', '(', '*', 'x', '2', ')', ')']
>>> parse(program)
['set!', 'x*2', ['*', 'x', 2]]
Есть куча инструментов для лексического анализа (например, lex Майка Леска и Эрика Шмидта), но мы пойдем простым путем: используем питоновский
str.split. Мы просто добавим пробелы вокруг каждой скобки, а затем получим список токенов, вызвав str.split.Теперь о синтаксическом анализе. Мы увидели, что синтаксис Lisp очень простой, но некоторые Lisp интерпретаторы сделали работу по синтаксическому анализу еще проще, принимая в качестве программы любую строку символов, которая представляет собой список. Другими словами, строка
(set! 1 2) будет принята синтаксически правильной программой, и только во время выполнения интерпретатор будет ругаться, что set! ожидает первым аргументом символ, а не число. В Java или Python эквивалентное присваивание 1 = 2, будет распознано как ошибка во время компиляции. С другой стороны, Java и Python не требуют обнаружения во время компиляции ошибки в выражении x/0, поэтому как вы видите не всегда строго определено, когда ошибки должны быть распознаны. Lispy реализует parse используя read, функцию, которая читает любое выражение (число, символ или вложенный список).Функция
read работает, передавая read_from токены, полученные после лексического анализа. Имея список токенов, мы смотрим на первый токен; если это ')' — синтаксическая ошибка. Если это '(', то мы начинаем строить список выражений пока не доберемся до соответствующей ')'. Все остальное должно быть символами или числами, которые являются полными выражениями сами по себе. Последний трюк заключается в знании, что '2' представляет целое число, '2.0' число с плавающей точкой, а x представляет символ. Мы позволим Python сделать эти различия: для каждого «не скобочного» токена сначала попытаемся интерпретировать его как целое число, а затем как число с плавающей точкой и в конце концов как символ. Следуя этим инструкциям получим:def read(s):
"Read a Scheme expression from a string."
return read_from(tokenize(s))
parse = read
def tokenize(s):
"Convert a string into a list of tokens."
return s.replace('(',' ( ').replace(')',' ) ').split()
def read_from(tokens):
"Read an expression from a sequence of tokens."
if len(tokens) == 0:
raise SyntaxError('unexpected EOF while reading')
token = tokens.pop(0)
if '(' == token:
L = []
while tokens[0] != ')':
L.append(read_from(tokens))
tokens.pop(0) # pop off ')'
return L
elif ')' == token:
raise SyntaxError('unexpected )')
else:
return atom(token)
def atom(token):
"Numbers become numbers; every other token is a symbol."
try: return int(token)
except ValueError:
try: return float(token)
except ValueError:
return Symbol(token)
И наконец, мы добавим функцию
to_string, для того чтобы конвертировать выражение обратно в удобочитаемую Lisp строку, а так же функцию repl, которая нужна для цикла read-eval-print в форме интерактивного интерпретатора:def to_string(exp):
"Convert a Python object back into a Lisp-readable string."
return '('+' '.join(map(to_string, exp))+')' if isa(exp, list) else str(exp)
def repl(prompt='lis.py> '):
"A prompt-read-eval-print loop."
while True:
val = eval(parse(raw_input(prompt)))
if val is not None: print to_string(val)
Вот наш код в работе:
>>> repl()
lis.py> (define area (lambda (r) (* 3.141592653 (* r r))))
lis.py> (area 3)
28.274333877
lis.py> (define fact (lambda (n) (if (<= n 1) 1 (* n (fact (- n 1))))))
lis.py> (fact 10)
3628800
lis.py> (fact 100)
9332621544394415268169923885626670049071596826438162146859296389521759999322991
5608941463976156518286253697920827223758251185210916864000000000000000000000000
lis.py> (area (fact 10))
4.1369087198e+13
lis.py> (define first car)
lis.py> (define rest cdr)
lis.py> (define count (lambda (item L) (if L (+ (equal? item (first L)) (count item (rest L))) 0)))
lis.py> (count 0 (list 0 1 2 3 0 0))
3
lis.py> (count (quote the) (quote (the more the merrier the bigger the better)))
4
Насколько мал/быстр/завершен/хорош Lispy?
Будем судить Lispy по следующим критериям:
- Размер: Lispy крошечный, 90 строк без комментариев, менее 4K исходного кода. Строк стало меньше по сравнению с первой версией, которая имела 96 строк — я принял предложение Эрика Купера убрать определение класса
Procedureи использовать вместо него питоновскуюlambda. Самая маленькая версия моей Scheme на Java (Jscheme) состояла из 1664 строчек и 57К исходного кода. Jsceheme изначально назывался SILK (Scheme in Fifty Kilobytes, Scheme в 50 килобайт), но я уложился в этот лимит только в отношении результирующего байт-кода. Я думаю, это удовлетворяет требованию Алана Кея от 1972 года, что вы могли бы определить «самый мощный язык в мире» в «странице кода».
bash$ grep "^\s*[^#\s]" lis.py | wc
90 398 3423
- Скорость: Lispy вычисляет
(fact 100)за 0.004 секунды. По мне, это достаточно быстро (хотя намного медленнее большинства других способов посчитать его).
- Завершенность: Lispy не полностью соответствует стандарту Scheme. Вот главные недостатки:
- Синтаксис: отсутствуют комментарии, цитирование/квазицитирование, # литералы, производные типы выражений (такие как
cond, производный отif, илиlet, производный отlambda), и точечная нотация списка.
- Семантика: отсутствуют call/cc и хвостовая рекурсия.
- Типы данных: отсутствуют строки, единичные символы, булевский тип, порты (ports), векторы, точные/неточные числа. Списки в Python на самом деле ближе к векторам в Scheme, чем к парам и спискам.
- Функции: отсутствуют более 100 примитивных функций, большая часть которых предназначена для отсутствующих типов данных, плюс некоторые другие (такие как
set-car!иset-cdr!, т.к. мы не можем реализоватьset-cdr!полностью используя Python списки).
- Обработка ошибок: Lispy не пытается обнаружить ошибки, сделать приемлемый отчет о них или восстановиться. Lispy ожидает от программиста совершенства.
- Синтаксис: отсутствуют комментарии, цитирование/квазицитирование, # литералы, производные типы выражений (такие как
- Хорош: это решать читателям. Я нахожу его хорошим для моей цели объяснить интерпретаторы Lisp.
Правдивая история
Возвращаясь к идее, что знание того как работают интерпретаторы может быть очень полезно, расскажу историю. В 1984 году я писал докторскую диссертацию. Это было еще до LaTeX, до Microsoft Word — мы использовали troff. К сожалению, troff не имел никакой возможности делать ссылки на символические метки: я хотел иметь возможность писать «Как мы увидим на странице @theoremx», а затем написать что-то вроде "@(set theoremx \n%)" в соответствующем месте (troff резервировал \n% как номер страницы). Мой товарищ Тони Дероз чувствовал ту же необходимость, и вместе мы набросали простую программу на Lisp, которая работала как препроцессор. Однако, оказалось, что Lisp, который мы имели в это время, был хорош для чтения Lisp выражений, но был настолько медлен для чтения всего остального, что это раздражало.
Мы с Тони пошли по разным путям. Он считал, что сложной частью был интерпретатор для выражений, ему нужен Lisp для этого, но он знал как написать маленькую подпрограмму на C для повторения не-Lisp'вых символов и связи их с программой на Lisp. Я не знал как сделать это связывание, но я считал, что написание интерпретатора для этого тривиального языка (все что в нем было — установка значения переменной, получение значения переменной и объединение строк) было простой задачей, поэтому я написал этот интерпретатор на C. Забавно, что Тони написал программу на Lisp, потому что был программистом на C, а я написал программу на C, потому что был Lisp программистом.
В конце концов, мы оба достигли результата.
Всё вместе
Полный код Lispy доступен для скачки: lis.py
