 Понадобилась мне для благого дела таблица частот пар букв (так называемых биграмм или диграмм) для украинского языка. Причем не просто украинского языка, а современного живого интернет-языка, именного того, на котором происходит современное общение в украиноязычной среде. Единственные известные мне результаты были построены на довольно малой выборке, отличной от того, что мне нужно было, да и серьезная преобработка текста в них могла повлиять на результат (и наверное таки повлияла, но об этом далее).
Понадобилась мне для благого дела таблица частот пар букв (так называемых биграмм или диграмм) для украинского языка. Причем не просто украинского языка, а современного живого интернет-языка, именного того, на котором происходит современное общение в украиноязычной среде. Единственные известные мне результаты были построены на довольно малой выборке, отличной от того, что мне нужно было, да и серьезная преобработка текста в них могла повлиять на результат (и наверное таки повлияла, но об этом далее).Задача в общем не сложная, единственной серьезной проблемой является источник материала для обработки — того самого большого куска текста, который можно перелопатить.
Первая идея была сдампить кусок какого-то IRC канала. К сожалению ни одного активного живого флейма с отсечкой по языку я не нашел.
Следующая идея: форум.
В качестве жертвы был выбрано несколько больших украиноязычных форумов. Все админы на просьбу о дампе текстовой части из базы отреагировали негативно, а некоторые даже довольно резко…
… Сами виноваты, сказал я и запустил wget.
Собственно проблем особых не было. Убедится в том, что wget тянет только то, что нужно (только страницы форума, не страницы отдельных сообщений — на форуме-жертве была и такая опция), чуток подтянуть знание powershell-а чтобы перегрести тонну полученых страниц из html в xhtml где-то найденной одноименной утилиткой, опять таки чуток подтянуть xslt для того, чтобы выгрести нужные текстовые элементы, и одновременно отсечь цитаты, а также повторяемые элементы. Результат этого дела уже можно было анализировать, для чего была создана маленькая программа на C#. В целом это все заняло две недели по несколько минут-часов в день.
Немного о результатах.
При помощи wget-а было выкачано около двух гигабайт чистого html, что заняло около полутора суток (точнее не скажу, файлов уже нет:))
После отсечки всех вспомогательных страниц, индексов, содержаний и форумов, перегонки в xhtml и отсечки файлов содержащих ошибки получилось 49492 файла общим размером 2.2GB.
После прогона xslt количество файлов не изменилось, а вот объем уменьшился существенно — до 160MB, при том все равно большую часть этого объема составляют пробелы, оставшиеся после xslt. Чистый размер после удаления сдвоенных пробельных символов, собственно база обработанного текста — 65 525 151 символ, более чем в 10 раз больше чем в предыдущем исследовании.
Собственно результат можно посмотреть здесь. В архиве четыре файла: соответственно обработанный и сырой диграммный и монограммный результаты. Из обработанных результатов выброшено все не относящиеся собственно к алфавиту украинского языка + диграммный результат превращен в таблицу. Если сравнивать с предыдущими результатами, видим отличия уже в первой десятке. Единственное предположение о таком различии состоит в том, что в упомянутом исследовании формы слова канонизировались.
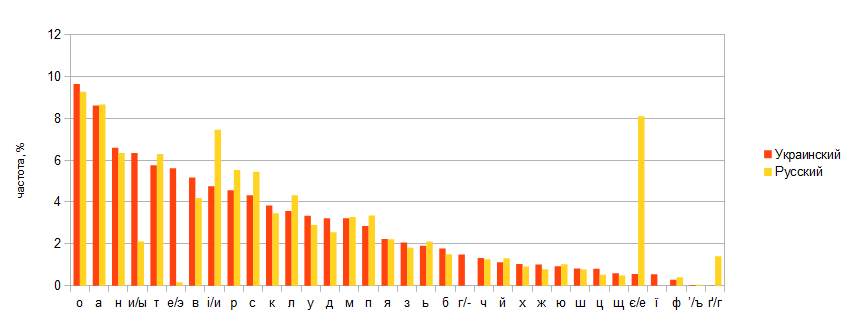
Ниже на рисунке сравнительный график частот букв в русском и украиснком языках по фонетическому критерию:
Открытые вопросы.
1. Отсечка включений на сторонних языках. В основном — русский, английский. Их немного, но все-таки заметно. Даже исходя из того, что можна резать пост по наличию в нему букв из других алфавитов, гарантировать точность результата все равно нельзя. Можно написать довольно длинную строку по-русски, которая не будет содержать ни единого символа отсутствующего в украинском алфавите. И предыдущих четыре предложения тому в подтверждение.
2. Редкие символы «ґ» и «’» (апостроф). Первый практически повсеместно заменяется на «г», поскольку «ґ» на большинстве клавиатур отсутствует как клас, а способ набора через AltGr практически неизвестен. Более того, буква очень сама по себе очень редкая, а много людей так и не привыкли к ней (она была возвращена в алфавит в 1990 году).
В качестве апострофа (аналог русского твердого знака) в основном используется единичная кавычка «'» (что типографически неправильно), но поскольку она отсутствует в раскладках на старых версиях винды, а в новых очень очевидно находиться под эскейпом, также повально или пропускается, или заменяется на любой другой подходящий (или не очень) символ, например звездочку. При анализе я принимал в качестве апострофа единичную кавычку, но результаты в таблицах явно показывают, что она используется не только в качестве апострофа (апостроф по правилам должен идти после б, п, в, м, ф, р и перед я, ю, є, ї. В таблице же видно множество других вхождений).
Заключение.
Надеюсь результаты, размещенные в топике будут кому-то нужны или интересны.
… Ну и одновременно буду рад идеям решения двух открытых проблем.
