В последнее время найти пользователей windows 9x стало сложно, но возможно. Но все таки они есть такие. Так же известно что использовать жесткие диски с разделами NTFS штатными средствами операционной системы нельзя. Попробуем исправить это написав программу позволяющую читать данные с разделов NTFS.
Что будем требовать от своей программы?
Да вообщем то не многое. Разрабатываемая программа должна осуществлять копирование с разделов жесткого диска с файловой системой NTFS5 в разделы FAT. Данная программа должна быть использована в том случае, если Windows 2000 (которая использует NTFS 5) отсутствует или недоступна. Должны поддерживаться длинные имена файлов, а также жесткие диски любой ёмкости (в т.ч. больше 8Гб). Среда функционирования – ОС DOS, Windows 9x. Программа должна иметь «стандартный» двухпанельный «нортоновский» интерфейс.
Определимся с алгоритмом
После запуска программы на экране появляется список существующих разделов с указанием жесткого диска, типа раздела и размера раздела. По умолчанию выбор разделов с типом, отличающимся от NTFS, запрещен (выдается соответствующее сообщение). При выборе раздела с типом NTFS осуществляется проверка по сигнатурам, действительно ли это раздел NTFS. В случае несовпадения выдается соответствующее сообщение. Если раздел опознан как NTFS, на экран выводятся 2 файловые панели. На левой панели отображается список файлов и каталогов в корневом каталоге раздела NTFS. На правой отображается содержимое текущего каталога текущего логического диска.
Пользователь осуществляет необходимые действия (как-то просмотр файлов разделов, копирование с раздела NTFS в раздел FAT) и выходит из программы
Как тут все устроенно
При запуске программы определяются параметры всех жестких дисков, находящиеся в системе. Определяются: геометрия, объем, а также поддержка функций расширенных чтения и записи. Результат на каждый накопитель заносится в следующую структуру:
Стандарные функции чтения/записи (реализованные через функции 02h и 03h прерывания 13h) требуют указания 3-х мерного номера сектора (дорожка-головка-сектор) и работают только для жестких дисков объемом не более 8Гб. Расширенные функции (Int13 Ext) (42h и 43h прерывания 13h) позволяют указывать абсолютный номер сектора и работают на жестких дисках любого объема. Поэтому при наличии такой поддержки чтение секторов выполняется только через эти функции.
Затем для каждого жесткого диска определяются находящиеся на нем разделы. Результат по каждому разделу заносится в структуру:
Процедура поиска разделов рекурсивная, так как наличие расширенных разделов дает в общем случае дерево. Расширенный раздел может иметь один из 2 типов: 05h (для HDD<=8Гб) или 0Fh (для HDD>8Гб). Во втором случае доступ к разделу возможен только через Int13 Ext.
Работа с логическими дисками FAT выполнена стандартным образом (через прерывание 21h), поэтому интереса не представляет. Стоит только отметить, что в зависимости от того, поддерживаются ли длинные имена файлов, используются либо стандартные функции, либо функции группы 71h прерывания 21h.
Работа с разделом NTFS основывается на ручном разборе всех структур. В соответствии со структурой NTFS, последовательность анализа раздела такова (примечание: после считывания каждой записи MFT или индексного блока обязательно производится коррекция области fixup — подробнее см. структуру NTFS):
1. Из Boot-сектора раздела извлекаются 2 важных параметра: количество секторов на кластер и номер кластера, где начинается MFT.
2. Считывается запись MFT номер 3 (информация о томе) и производится попытка извлечь из нее имя (метку) тома. В случае неудачи считается, что том не имеет метки.
3. Считывается запись MFT номер 5 (корневой каталог). По содержащемуся в нем индексу строится список файлов и каталогов.
4. При переходе в какой-либо каталог (над- или под-) считывается запись MFT, отвечающая за требуемый каталог, из нее также извлекается индекс.
5. При обращении к файлу (например, для чтения) считывается и анализируется запись MFT, отвечающая за данный файл.
Если будет интересно, распишу подробнее. Исходные коды здесь.
P.S.:
Исходные коды zip здесь.
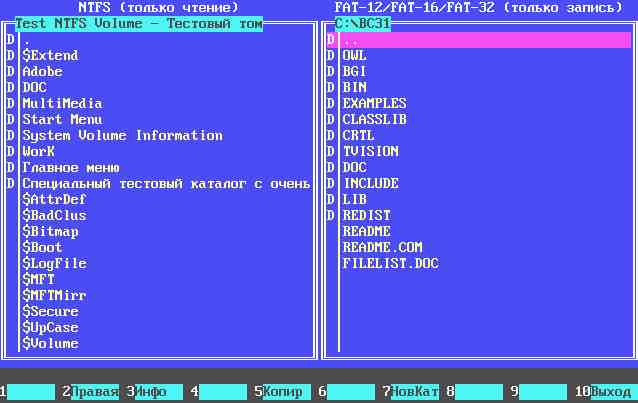
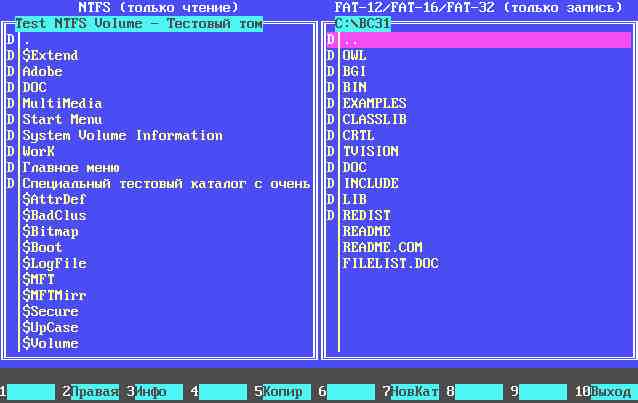
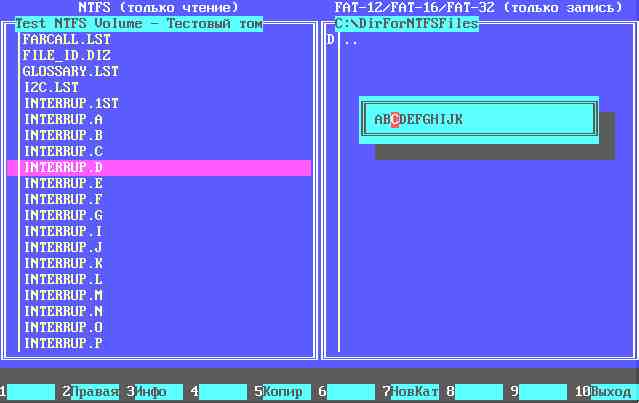
А выглядит в картинках это так:


Что будем требовать от своей программы?
Да вообщем то не многое. Разрабатываемая программа должна осуществлять копирование с разделов жесткого диска с файловой системой NTFS5 в разделы FAT. Данная программа должна быть использована в том случае, если Windows 2000 (которая использует NTFS 5) отсутствует или недоступна. Должны поддерживаться длинные имена файлов, а также жесткие диски любой ёмкости (в т.ч. больше 8Гб). Среда функционирования – ОС DOS, Windows 9x. Программа должна иметь «стандартный» двухпанельный «нортоновский» интерфейс.
Определимся с алгоритмом
После запуска программы на экране появляется список существующих разделов с указанием жесткого диска, типа раздела и размера раздела. По умолчанию выбор разделов с типом, отличающимся от NTFS, запрещен (выдается соответствующее сообщение). При выборе раздела с типом NTFS осуществляется проверка по сигнатурам, действительно ли это раздел NTFS. В случае несовпадения выдается соответствующее сообщение. Если раздел опознан как NTFS, на экран выводятся 2 файловые панели. На левой панели отображается список файлов и каталогов в корневом каталоге раздела NTFS. На правой отображается содержимое текущего каталога текущего логического диска.
Пользователь осуществляет необходимые действия (как-то просмотр файлов разделов, копирование с раздела NTFS в раздел FAT) и выходит из программы
Как тут все устроенно
При запуске программы определяются параметры всех жестких дисков, находящиеся в системе. Определяются: геометрия, объем, а также поддержка функций расширенных чтения и записи. Результат на каждый накопитель заносится в следующую структуру:
struct sDrvInfo { unsigned char Drive; // Номер накопителя (80h..FFh) unsigned char ExtSupp; // Флаг поддержки Int13 Ext (0 - нет) unsigned short NumCyl; // Количество дорожек unsigned short NumHead; // Количество головок unsigned short NumSect; // Количество секторов на дорожку unsigned long NumAll; // Общее количество секторов на накопителе sDrvInfo *Next; // Указатель на следующий элемент };
Стандарные функции чтения/записи (реализованные через функции 02h и 03h прерывания 13h) требуют указания 3-х мерного номера сектора (дорожка-головка-сектор) и работают только для жестких дисков объемом не более 8Гб. Расширенные функции (Int13 Ext) (42h и 43h прерывания 13h) позволяют указывать абсолютный номер сектора и работают на жестких дисках любого объема. Поэтому при наличии такой поддержки чтение секторов выполняется только через эти функции.
Затем для каждого жесткого диска определяются находящиеся на нем разделы. Результат по каждому разделу заносится в структуру:
struct sPartInfo { unsigned char Drive; // Номер накопителя (80h..FFh) unsigned char Type; // Тип раздела unsigned long Start; // Абсолютный номер сектора начала раздела unsigned long Size; // Общий размер раздела в секторах unsigned long Table; // Абсолютный номер сектора с таблицей // разделов, где ссылка на данный раздел unsigned char NumEnt; // Номер входа таблицы разделов sPartInfo *Next; // Указатель на следующий элемент };
Процедура поиска разделов рекурсивная, так как наличие расширенных разделов дает в общем случае дерево. Расширенный раздел может иметь один из 2 типов: 05h (для HDD<=8Гб) или 0Fh (для HDD>8Гб). Во втором случае доступ к разделу возможен только через Int13 Ext.
Работа с логическими дисками FAT выполнена стандартным образом (через прерывание 21h), поэтому интереса не представляет. Стоит только отметить, что в зависимости от того, поддерживаются ли длинные имена файлов, используются либо стандартные функции, либо функции группы 71h прерывания 21h.
Работа с разделом NTFS основывается на ручном разборе всех структур. В соответствии со структурой NTFS, последовательность анализа раздела такова (примечание: после считывания каждой записи MFT или индексного блока обязательно производится коррекция области fixup — подробнее см. структуру NTFS):
1. Из Boot-сектора раздела извлекаются 2 важных параметра: количество секторов на кластер и номер кластера, где начинается MFT.
2. Считывается запись MFT номер 3 (информация о томе) и производится попытка извлечь из нее имя (метку) тома. В случае неудачи считается, что том не имеет метки.
3. Считывается запись MFT номер 5 (корневой каталог). По содержащемуся в нем индексу строится список файлов и каталогов.
4. При переходе в какой-либо каталог (над- или под-) считывается запись MFT, отвечающая за требуемый каталог, из нее также извлекается индекс.
5. При обращении к файлу (например, для чтения) считывается и анализируется запись MFT, отвечающая за данный файл.
Если будет интересно, распишу подробнее. Исходные коды здесь.
P.S.:
Исходные коды zip здесь.
А выглядит в картинках это так:
