В прошлом году была заказана, как казалось на первый взгляд, простая работа: создать систему пакетной обработки файлов — содержащих 12-ти колоночную таблицу, данные из которой экспортировать в БД. Все бы ничего — да вот файлы оказались документами в pdf, а заказчик утверждал что другого формата для обработки предоставить никак не может.
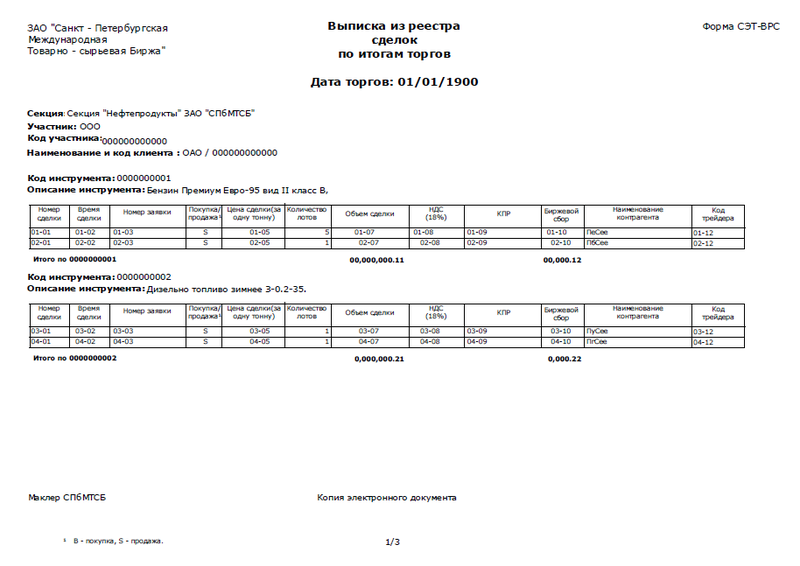
Образец того самого pdf-а — в файле сохранена структура, но подчищены все данные.
Чтож, несмотря на предупреждения знающих людей, а предупреждали они ой как не зря — я за работу взялся и пережил вот такое приключение:
Начался поиск софта для пакетной обработки pdf файлов. Работа производилась на linux — потому первым претендентом оказалась программа из пакета poppler — pdftotext, которую чаще всего в этих целях и используют.
функция легко вызывается из командной строки, и имеет следующий вид:
Но вот результат конвертирования оказался весьма странным:
Выписка из реестра
сделок
по итогам торгов
ЗАО «Санкт — Петербургская
Международная
Товарно — сырьевая Биржа»
Форма СЭТ-ВРС
Дата торгов: 01/01/1900
Секция: Секция «Нефтепродукты» ЗАО «СПбМТСБ»
Участник: ООО
Код участника:000000000000
Наименование и код клиента: ОАО / 000000000000
Код инструмента: 0000000001
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Hомер
сделки
Время
сделки
Hомер заявки
Покупка/ Цена сделки(за Количество
продажа¹
одну тонну)
лотов
01-01
01-02
01-03
S
01-05
5
02-01
02-02
02-03
S
02-05
1
Итого по 0000000001
и так далее…
Мало того: вывод еще менялся от файла к файлу — конечно в таком виде невозможно было написать парсер для выдергивания данных из таблиц.
Потому на горизонте возник второй, на сей раз проприетарный кандидат: Adobe Acrobat Reader for linux.
В данном случае решил, для начала, испытать его возможность «File — Save as Text» в графическом режиме, не сильно углубляясь в командную строку. Как потом выяснилось, правильно сделал — результаты конвертирования моих pdf и в данной программе, не внушали оптимизма:
Код участника:
Секция:
Код инструмента:
Код инструмента:
000000000000
ООО
0000000001
0000000002
00,000,000.11 00,000.12
0,000,000.21 0,000.22
01-12
02-12
03-12
04-12
ЗАО «Санкт — Петербургская
Международная
Товарно — сырьевая Биржа»
Выписка из реестра
сделок
по итогам торгов
Дата торгов: 01/01/1900
Форма СЭТ-ВРС
Наименование и код клиента: ОАО / 000000000000
Участник:
Секция «Нефтепродукты» ЗАО «СПбМТСБ»
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Код
трейдера
Время
сделки Объем сделки
Hомер
сделки
Hомер заявки
Итого по 0000000001
Описание инструмента: Дизельно топливо зимнее З-0.2-35.
Код
трейдера
Время
сделки Объем сделки
Hомер
сделки
Hомер заявки
Итого по 0000000002
и так далее…
Парсить такой вывод, тоже не очень хотелось.
Третьим и, как выяснилось, последним кандидатом оказался pdfedit.
Во всех репозиториях он представлен графической программой с возможностью выполнения скриптов из командной строки. Так же как у Acrobat Reader — первый запуск конвертирования pdf в text произвел из графического окружения «файл — сохранить как текст», результат сильно порадовал:
Получился очень корректный вывод — парсить который легко и приятно. Но не тут то было, путь к завершению эпопеи оказался тернист. Вызвать функцию «сохранить как текст» из командной строки, в стандартно собранном pdfedit, было невозможно:
вывод консольного хелпа давал две утилиты, никак не связанные с конвертированием в текст. Дальнейшее изучение документации на wiki привело к готовому скрипту конвертирования savealltext.qs, но беда в том, что он должен был исполнятся из графического меню. В результате пришлось подробно изучать матчасть:
описание API для создания скриптов в pdfedit
wiki создания скрипта для pdfedit
примеры готовых скриптов
«Курение» уже этого материала + поэтапный разбор представленного в стандартной сборке консольного скрипта /usr/share/pdfedit/delinearize.qs — привело меня к созданию своего savealltext.qs:
будучи помещенным в каталог /usr/share/pdfedit/, скрипт вызывается из командной строки и производит требуемое конвертирование:
Вроде бы все отлично, но подводные камни продолжали всплывать: выяснилось что pdfedit, в консольном режиме, забирает текст с области по умолчанию 612x792 pixels — в разрешении 72 dpi это соответствует А4 листу альбомной ориентации. Поворачивать область сканирования программа никак не хотела, несмотря на присутствие в коде соответствующих инструкций с патча rotate_text_fix.patch.
Поиски определения этой триклятой «дефолтной области» завели меня в исходный код проекта, к файлу: src/kernel/displayparams.h — вот ведь, нашли куда засунуть!
Заменил оба значения на 1584 точек (что соответствует половине ватмана в том же разрешении) и прересобрал проект.
На этом, можно сказать, мучения закончились — pdf-ки обрабатывались из терминала, во всю свою А4-ую дущу альбомной ориентации.
По результатам своих мучений сделал правила для сборки пакетов pdfedit с savealltext для ArchLinux и выложил в AUR:
pdfedit релиз
pdfedit версия из csv
Скоро сказка сказывается, да не скоро дело делается — мне сильно не нравилось что pdfedit для запуска, даже в консольном режиме, требовал наличия в системе qt3:
$ pdfedit -console
pdfedit: error while loading shared libraries: libqt-mt.so.3: cannot open shared object file: No such file or directory
Что привело к рассмотрению ключей конфигурирования программы при сборке из исходников и тут был найден следующий рецепт:
В результате бинарник графического pdfedit не собирается вовсе, зато создается целая куча полезных утилит, среди которых pdf_to_text — производящая необходимую мне конвертацию, применяя те же, что и скрипт savealltext.qs, алгоритмы:
Результаты такой сборки проекта, тоже превратил в PKGBUILD для ArchLinux и выложил в AUR.
Спасибо всем за консультации! Благодаря обсуждению было выявлено еще несколько интересных способов конвертирования pdf в text:
zeliboba предложил применить к pdftotext опцию -layout
Можно без преувеличивания сказать что, файлы проекта из статьи, такой способ конвертирует лучше чем pdfedit:
С другой стороны — не со всеми pdf-ами это правило срабатывает:
«Сегодня экспериментировал с различными pdf файлами, получилась что между pdfedit и pdftotext — все равно нет абсолютного чемпиона, скажем:
Pdftotext — лучше сконвертировал ряд вытянутых в горизонтальном направлении таблиц и одноколоночных журналов.
Pdfedit — лучше работал с многоколоночными журналами(например:linuxformat) и вертикально ориентированными таблицами.
Гдето обе программы показали одинаковый результат (например: журнал Цейнгауз).»
kornerz предложил конвертировать pdf в svg, при помощи inkscape — предварительно разделив pdf-файл на листы (как вариант при помощи pdftk)
Образец того самого pdf-а — в файле сохранена структура, но подчищены все данные.
Чтож, несмотря на предупреждения знающих людей, а предупреждали они ой как не зря — я за работу взялся и пережил вот такое приключение:
Начался поиск софта для пакетной обработки pdf файлов. Работа производилась на linux — потому первым претендентом оказалась программа из пакета poppler — pdftotext, которую чаще всего в этих целях и используют.
pdftotext
функция легко вызывается из командной строки, и имеет следующий вид:
$ pdftotext ваш.pdf ваш.txt
Но вот результат конвертирования оказался весьма странным:
Выписка из реестра
сделок
по итогам торгов
ЗАО «Санкт — Петербургская
Международная
Товарно — сырьевая Биржа»
Форма СЭТ-ВРС
Дата торгов: 01/01/1900
Секция: Секция «Нефтепродукты» ЗАО «СПбМТСБ»
Участник: ООО
Код участника:000000000000
Наименование и код клиента: ОАО / 000000000000
Код инструмента: 0000000001
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Hомер
сделки
Время
сделки
Hомер заявки
Покупка/ Цена сделки(за Количество
продажа¹
одну тонну)
лотов
01-01
01-02
01-03
S
01-05
5
02-01
02-02
02-03
S
02-05
1
Итого по 0000000001
и так далее…
Мало того: вывод еще менялся от файла к файлу — конечно в таком виде невозможно было написать парсер для выдергивания данных из таблиц.
Потому на горизонте возник второй, на сей раз проприетарный кандидат: Adobe Acrobat Reader for linux.
Acrobat Reader
В данном случае решил, для начала, испытать его возможность «File — Save as Text» в графическом режиме, не сильно углубляясь в командную строку. Как потом выяснилось, правильно сделал — результаты конвертирования моих pdf и в данной программе, не внушали оптимизма:
Код участника:
Секция:
Код инструмента:
Код инструмента:
000000000000
ООО
0000000001
0000000002
00,000,000.11 00,000.12
0,000,000.21 0,000.22
01-12
02-12
03-12
04-12
ЗАО «Санкт — Петербургская
Международная
Товарно — сырьевая Биржа»
Выписка из реестра
сделок
по итогам торгов
Дата торгов: 01/01/1900
Форма СЭТ-ВРС
Наименование и код клиента: ОАО / 000000000000
Участник:
Секция «Нефтепродукты» ЗАО «СПбМТСБ»
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Код
трейдера
Время
сделки Объем сделки
Hомер
сделки
Hомер заявки
Итого по 0000000001
Описание инструмента: Дизельно топливо зимнее З-0.2-35.
Код
трейдера
Время
сделки Объем сделки
Hомер
сделки
Hомер заявки
Итого по 0000000002
и так далее…
Парсить такой вывод, тоже не очень хотелось.
Третьим и, как выяснилось, последним кандидатом оказался pdfedit.
pdfedit
Во всех репозиториях он представлен графической программой с возможностью выполнения скриптов из командной строки. Так же как у Acrobat Reader — первый запуск конвертирования pdf в text произвел из графического окружения «файл — сохранить как текст», результат сильно порадовал:
ЗАО "Санкт - Петербургская Выписка из реестра Форма СЭТ-ВРС
Международная сделок
Товарно - сырьевая Биржа" по итогам торгов
Дата торгов: 01/01/1900
Секция: Секция "Нефтепродукты" ЗАО "СПбМТСБ"
Участник: ООО
Код участника:000000000000
Наименование и код клиента : ОАО / 000000000000
Код инструмента: 0000000001
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Hомер Время Hомер заявки
Покупка/ Цена сделки(за Количество
HДС Биржевой Hаименование
Код
Объем сделки КПР
сделки сделки продажа¹
одну тонну)
лотов (18%) сбор контрагента
трейдера
01-01 01-02 01-03 S 01-05 5 01-07 01-08 01-09 01-10 ПеСее
01-12
02-01 02-02 02-03 S 02-05 1 02-07 02-08 02-09 02-10 ПбСее
02-12
Итого по 0000000001 00,000,000.11 00,000.12
Код инструмента: 0000000002
Описание инструмента: Дизельно топливо зимнее З-0.2-35.
Hомер Время Hомер заявки
Покупка/ Цена сделки(за Количество
HДС Биржевой Hаименование
Код
Объем сделки КПР
сделки сделки продажа¹
одну тонну)
лотов (18%) сбор контрагента
трейдера
03-01 03-02 03-03 S 03-05 1 03-07 03-08 03-09 03-10 ПуСее
03-12
04-01 04-02 04-03 S 04-05 1 04-07 04-08 04-09 04-10 ПгСее
04-12
Итого по 0000000002 0,000,000.21 0,000.22
Маклер СПбМТСБ Копия электронного документа
¹ B - покупка, S - продажа. 1/3
Получился очень корректный вывод — парсить который легко и приятно. Но не тут то было, путь к завершению эпопеи оказался тернист. Вызвать функцию «сохранить как текст» из командной строки, в стандартно собранном pdfedit, было невозможно:
$ pdfedit -console PDFedit 0.4.5 Использование: pdfedit -console [имя функции] [параметр(ы) функции] First parameter is name of function to invoke (case insensitive) or its unambiguous part. Остальные параметры передаются вызванной функции. Доступные функции: Delinearizator Описание: Delinearize input file Параметры: [input file] [output file] Flattener Описание: Flatten input file (remove all revisions except the last one) Параметры: [input file] [output file]
вывод консольного хелпа давал две утилиты, никак не связанные с конвертированием в текст. Дальнейшее изучение документации на wiki привело к готовому скрипту конвертирования savealltext.qs, но беда в том, что он должен был исполнятся из графического меню. В результате пришлось подробно изучать матчасть:
описание API для создания скриптов в pdfedit
wiki создания скрипта для pdfedit
примеры готовых скриптов
«Курение» уже этого материала + поэтапный разбор представленного в стандартной сборке консольного скрипта /usr/share/pdfedit/delinearize.qs — привело меня к созданию своего savealltext.qs:
/** Print help for savealltext */
function savealltext_help() {
print(tr("Usage:"));
print("savealltext ["+tr("input file")+"] ["+tr("output file")+"]");
print(" "+tr("Input file must exist"));
print(" "+tr("Output file must not exist"));
exit(1);
}
function savealltext_fail(err) {
print(tr("savealltext failed!"));
print(err);
exit(2);
}
function saveAsText_save(p,f) {
document=loadPdf(p)
qs="";
pages=document.getPageCount();
for (i=1;i<=pages;i++) {
pg=document.getPage(i);
text=pg.getText();
qs+=text;
qs+="\n";
}
saveFile(f,qs);
}
p=parameters();
if (p.length!=2) {
savealltext_help("savealltext "+tr("is expecting two parameters"));
}
inFile=p[0];
outFile=p[1];
if (!exists(inFile)) savealltext_fail(tr("Input file '%1' does not exist").arg(inFile));
if (exists(outFile)) savealltext_fail(tr("Output file '%1' already exist").arg(outFile));
if (inFile==outFile) savealltext_fail(tr("Input and output files must be different"));
if (saveAsText_save(inFile,outFile)) {
} else {
print(tr("savealltext")+" :"+inFile+" -> "+outFile);
}
будучи помещенным в каталог /usr/share/pdfedit/, скрипт вызывается из командной строки и производит требуемое конвертирование:
$ pdfedit -console PDFedit 0.4.5-20111014140242 Использование: pdfedit -console [имя функции] [параметр(ы) функции] First parameter is name of function to invoke (case insensitive) or its unambiguous part. Остальные параметры передаются вызванной функции. Доступные функции: Delinearizator Описание: Delinearize input file Параметры: [input file] [output file] Flattener Описание: Flatten input file (remove all revisions except the last one) Параметры: [input file] [output file] savealltext Описание: savealltext input file Параметры: [input file] [output file]
$pdfedit -console savealltext ваш.pdf ваш.txt
Вроде бы все отлично, но подводные камни продолжали всплывать: выяснилось что pdfedit, в консольном режиме, забирает текст с области по умолчанию 612x792 pixels — в разрешении 72 dpi это соответствует А4 листу альбомной ориентации. Поворачивать область сканирования программа никак не хотела, несмотря на присутствие в коде соответствующих инструкций с патча rotate_text_fix.patch.
Поиски определения этой триклятой «дефолтной области» завели меня в исходный код проекта, к файлу: src/kernel/displayparams.h — вот ведь, нашли куда засунуть!
static const int DEFAULT_PAGE_RX = 612; /**< Default A4 width on a device with 72 horizontal dpi. */
static const int DEFAULT_PAGE_RY = 792; /**< Default A4 height on a device with 72 vertical dpi. */
Заменил оба значения на 1584 точек (что соответствует половине ватмана в том же разрешении) и прересобрал проект.
На этом, можно сказать, мучения закончились — pdf-ки обрабатывались из терминала, во всю свою А4-ую дущу альбомной ориентации.
По результатам своих мучений сделал правила для сборки пакетов pdfedit с savealltext для ArchLinux и выложил в AUR:
pdfedit релиз
pdfedit версия из csv
п.с.:
Скоро сказка сказывается, да не скоро дело делается — мне сильно не нравилось что pdfedit для запуска, даже в консольном режиме, требовал наличия в системе qt3:
$ pdfedit -console
pdfedit: error while loading shared libraries: libqt-mt.so.3: cannot open shared object file: No such file or directory
Что привело к рассмотрению ключей конфигурирования программы при сборке из исходников и тут был найден следующий рецепт:
configure --disable-gui --enable-pdfedit-core-dev --enable-tools
В результате бинарник графического pdfedit не собирается вовсе, зато создается целая куча полезных утилит, среди которых pdf_to_text — производящая необходимую мне конвертацию, применяя те же, что и скрипт savealltext.qs, алгоритмы:
$pdf_to_txt -file ваш.pdf >ваш.txt
Результаты такой сборки проекта, тоже превратил в PKGBUILD для ArchLinux и выложил в AUR.
upd1:
Спасибо всем за консультации! Благодаря обсуждению было выявлено еще несколько интересных способов конвертирования pdf в text:
zeliboba предложил применить к pdftotext опцию -layout
$ pdftotext -layout ваш.pdf ваш.txt
Можно без преувеличивания сказать что, файлы проекта из статьи, такой способ конвертирует лучше чем pdfedit:
ЗАО "Санкт - Петербургская Выписка из реестра Форма СЭТ-ВРС
Международная сделок
Товарно - сырьевая Биржа" по итогам торгов
Дата торгов: 01/01/1900
Секция: Секция "Нефтепродукты" ЗАО "СПбМТСБ"
Участник: ООО
Код участника:000000000000
Наименование и код клиента : ОАО / 000000000000
Код инструмента: 0000000001
Описание инструмента: Бензин Премиум Евро-95 вид II класс B,
Hомер Время Hомер заявки Покупка/ Цена сделки(за Количество HДС Биржевой Hаименование Код
Объем сделки КПР
сделки сделки продажа¹ одну тонну) лотов (18%) сбор контрагента трейдера
01-01 01-02 01-03 S 01-05 5 01-07 01-08 01-09 01-10 ПеСее 01-12
02-01 02-02 02-03 S 02-05 1 02-07 02-08 02-09 02-10 ПбСее 02-12
Итого по 0000000001 00,000,000.11 00,000.12
С другой стороны — не со всеми pdf-ами это правило срабатывает:
«Сегодня экспериментировал с различными pdf файлами, получилась что между pdfedit и pdftotext — все равно нет абсолютного чемпиона, скажем:
Pdftotext — лучше сконвертировал ряд вытянутых в горизонтальном направлении таблиц и одноколоночных журналов.
Pdfedit — лучше работал с многоколоночными журналами(например:linuxformat) и вертикально ориентированными таблицами.
Гдето обе программы показали одинаковый результат (например: журнал Цейнгауз).»
kornerz предложил конвертировать pdf в svg, при помощи inkscape — предварительно разделив pdf-файл на листы (как вариант при помощи pdftk)
$pdftk file.pdf burst
$inkscape -z -f pg_0001.pdf -l output_page1.svg
