 В сети и на github появилась разработка парсера Esprima, позиционированного на парсинг вообще и для javascript в частности. Он написан на Javascript и переводит скармливаемый текст в структуру JSON, которую затем можно анализировать, например, для препроцессирования кодов, создания сахарных обёрток для JS, автоматизированного поиска ошибок без запуска кода, преобразования языков (кросс-компиляции), преобразования серверного JS в клиентский или наоборот, для минификации кода или наоборот, для разбора обфусцированного. Но это — всё идеи для будущего. Появился архив совсем недавно (в середине ноября — первый коммит с 2000 строк кода), но уже приобрёл своих иследователей, судя по форкам. Формат парсинга совместим с Mozilla SpiderMonkey Parser API.
В сети и на github появилась разработка парсера Esprima, позиционированного на парсинг вообще и для javascript в частности. Он написан на Javascript и переводит скармливаемый текст в структуру JSON, которую затем можно анализировать, например, для препроцессирования кодов, создания сахарных обёрток для JS, автоматизированного поиска ошибок без запуска кода, преобразования языков (кросс-компиляции), преобразования серверного JS в клиентский или наоборот, для минификации кода или наоборот, для разбора обфусцированного. Но это — всё идеи для будущего. Появился архив совсем недавно (в середине ноября — первый коммит с 2000 строк кода), но уже приобрёл своих иследователей, судя по форкам. Формат парсинга совместим с Mozilla SpiderMonkey Parser API.Проверить работу парсера в текущем состоянии можно, даже не скачивая библиотеку из хранилища — на сайте есть демо-страница. Вносим в её поле ввода небольшой кусок скрипта (чтобы результат был обозреваемым) — и смотрим полученное дерево-хеш. (Что с этим деревом делать дальше — уже другой вопрос.) Видим, что в дереве отмечены и распознаны синтаксические конструкции языка. Кстати, поле ввода использует онлайн-среду редактирования CodeMirror с подсветкой синтаксиса и поддерживает работу с табами, групповым добавлением пробелов к строкам по выделению, отступы при вводе скобок, поэтому довольно удобно код набирать прямо в браузере. Парсинг выполняется в реальном времени и немедленно реагирует на ошибки в коде, по крайней мере, когда кода в окне мало. Однако, работает он очень резво, как чистый парсинг, так и отображение на странице. Например, перерисовка всего парсинга исходного кода jQuery (250 КБ) занимает около секунды (Fx8\Linux\i7-2600 CPU, embed. video intel), а чистый парсинг, как утверждает автор программы — менее 0.1 с. (В этой статье много любопытных данных о скорости парсинга на разных JS-движках.)
Поддерживаются, как минимум, такие браузеры: IE 8+, Firefox 3.5+, Safari 4+, Chrome 7+ и Opera 10.5+ и nodeJS+npm.
Разработчик (Ariya Hidayat) на своём сайте запустил программу онлайнового тестирования различных парсеров, действующую прямо на вашем клиентском компьютере. В забегах участвуют 4 библиотеки исходных кодов и 4 парсера: Esprima, Narcissus, parse-js, ZeParser. Как подчёркивает разработчик, все цифры не следует воспринимать слишком серьёзно (потому что данные выводятся в разных форматах и у каждого есть пути оптимизации), а лишь для того, чтобы убедиться, что новый парсер стоит в одном ряду с другими и не даёт слишком плохих результатов, скромно умалчивая о том, что он в тестах обходит всех остальных. Вот что получилось у меня:

Вот — визуализированные результаты тестов в сравнении с одним из лучших парсеров, полученные разработчиком:
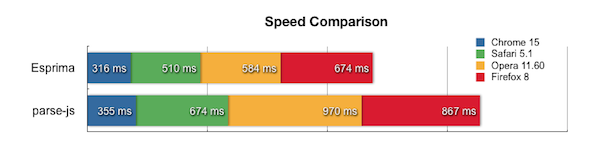
Парсеры JS, написанные на JS: Narcissus (используется в движке Mozilla JS), parse-js (используется в минификаторе UglifyJS), ZeParser. Несколько ключевых слов и ссылок можно найти на stackoverflow, по поиску и на сайтах разработчиков.
Разработчик, опять же, в онлайне, поддерживает юнит- и прочее тестирование своего кода. Хороший ход, потому что он сможет получить сообщения от различных пользователей о результатах проведённых тестов в различных окружениях.
На некотором этапе реализации Esprima стал поддерживать выделение комментариев в виде отдельного массива comments[] в конце дерева, с номерами строк, что может тоже найти применение для автоматического создания документации.
В планах у разработчика — поддержка особенностей языка типа 8-ричных чисел, более полная поддержка IE, улучшение собственного сайта и представления тестов на нём.
Такие проекты интересны ещё тем, что, используя только JS, можно поддерживать разработку связки фронтенда и nodeJS на более высоком уровне, чем
