 В последние пару недель на многих сайтах были заметки о начале производства (на азиатских заводах) отечественных процессоров Multiclet с «прорывной архитектурой и фантастической производительностью», в том числе и на Хабре: Первая опытно-промышленная партия отечественных мультиклеточных процессоров MCp. Все эти заметки в целом рассматривали разработку с позитивной стороны, основываясь на преимуществах в изложении разработчиков. Я всегда интересовался отечественными разработками, и попробую рассказать об этом процессоре чуть более критически, и описать в меру своих возможностей суть этой новой архитектуры.
В последние пару недель на многих сайтах были заметки о начале производства (на азиатских заводах) отечественных процессоров Multiclet с «прорывной архитектурой и фантастической производительностью», в том числе и на Хабре: Первая опытно-промышленная партия отечественных мультиклеточных процессоров MCp. Все эти заметки в целом рассматривали разработку с позитивной стороны, основываясь на преимуществах в изложении разработчиков. Я всегда интересовался отечественными разработками, и попробую рассказать об этом процессоре чуть более критически, и описать в меру своих возможностей суть этой новой архитектуры. Источники информации — ограниченная документация доступная на сайте разработчика, и ответы сотрудников компании на вопросы.
Архитектура
Если отбросить всю словесную шелуху (а её особенно много в данном случае), мультиклет — это в первом приближении любимый в России и СССР EPIC: архитектура с явным параллелизмом. В отличии от VLIW, где компилятор указывает какой блок что должен делать, тут указываются только зависимости инструкций, а по ядрам они растаскиваются уже в процессе выполнения (таких ядер в MCp0411100101 — 4 штуки).
За рубежем эта архитектура известна, и с 2006-года работает в кремнии (Explicit Data Graph Execution / TRIPS), но массового коммерческого успеха за прошедшие 6 лет не видно.
Преимуществ по сравнения с VLIW тут 2: гипотетическая возможность запускать код на процессоре c другим количеством «ядер» и возможность продолжить работу при выходе из строя одного из ядер. Оба преимущества, на мой взгляд, весьма сомнительны:
1) Запуск без перекомпиляции на процессоре бóльшего размера — для embedded применений обычно нет проблемы в перекомпиляции. Помимо этого, оптимальный код для 4 и 16 ядер разный — и запуск без перекомпиляции снижает эффективность (конечно если мы делаем что-то сложнее чем перемножение массивов).
2) Устойчивость к сбою любого ядра — эта «фишка» появилась недавно.
По последней информации, в выпущенной микросхеме устойчивости нет, она может появится в будущем при необходимых изменениях.
Теперь посмотрим на картинку из описания процессора (ПП — память программ, ПД — память данных, ПБ — процессорный блок):
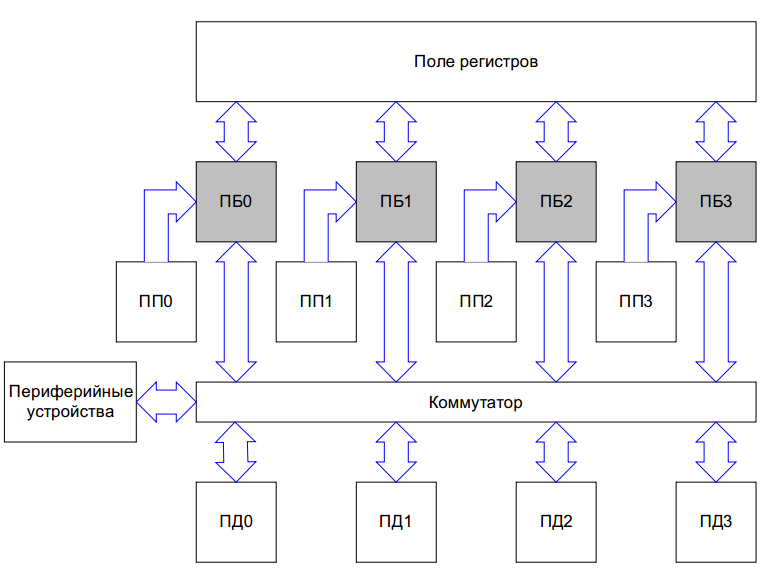
Сразу бросается в глаза — общий регистровый файл и коммутатор, совместный доступ к памяти (когда все ядра могут читать и писать практически что угодно). Обычно такого рода архитектуры работают медленно (из-за чисто физических ограничений), и возможно это причина, почему Мультиклет работает всего на 100Мгц при изготовлении на зарубежной фабрике (
Именно из-за проблем со скоростью все остальные существующие (коммерчески успешные) многоядерные архитектуры не пытаются организовать доступ «все имеют доступ везде» — обычно ядра имеют маленькую локальную память с возможностью редкого медленного доступа в общую память.
Производительность
Казалось бы, 2.4GFLOP декларируемые производителем — весьма существенная производительность. Однако, в компании-разработчике процессора отказались пояснить, каким образом была получена такая производительность при тактовой частоте 100МГц, и не подтвердили, что madd (multiply+add) выполняется за 1 такт. Тем не менее, похоже, мне удалось понять откуда взялась такая цифра.
Мультиклет работает с числами одинарной точности — «single» (32-бит) и есть возможность упаковать комплексное число single-точности в 64 бит (т.е. действительная и мнимая часть по 32 бит). Тогда и получается, что если умножение двух комплексных чисел выполняется за 1 такт, то это дает 6 FLOP за такт: (a + bi)(c + di) = (aс + bd) + (ad + bc)i., и соответственно, 6*4*100Mhz = 2.4GLOP.
Таким образом, сравнивать эту производительность с настольными Pentium-ами всякими конечно нельзя (это любят делать в обсуждении: «вот, почти достали Intel»): в настольных процессорах принято производительность измерять на 64-х битных вещественных числах, а тут озвученные цифры производительности получаются только на 32-бит и только в специфических условиях.
На обычных операциях с неупакованными данными производительность составляет 400 млн. операций в секунду, и нужно иметь ввиду что набор инструкций тут существенно более простой чем в том же арме, т.е. скорость на обычных задачах будет ниже, чем у 400Mhz арма (или Комдива-64).
Т.е. по факту новая архитектура Мультиклета — получилась «тяжелой», и работает с такой маленькой тактовой частотой, что одноядерные процессоры классической архитектуры оказываются в итоге быстрее.
Энергопотребление
К сожалению, тут пока обсуждать нечего, его нужно внимательно тестировать на реальной нагрузке и реальном кристалле. Если есть видимое преимущество по энергопотреблению — то возможно для каких-то задач это будет критерием выбора.
Периферия и прочий фарш
Во первых, обращаем внимание на количество памяти — по 16кб памяти программ и данных.
Контроллера внешней памяти нет, соответственно все разговоры о портировании Linux — это дело далекого и туманного будущего, перед которым нужно еще сделать бакенд к GNUC для этого процессора.
Флеш-памяти для хранения программы нет, и загрузка производится с внешней флешки (в данный момент это Xilinx XCF04S). Естественно это вызвало подозрения, что процессор — перемаркированная FPGA, но на прямой мой вопрос об этом мне ответили:
Вместо Xilinx можно было бы поставить любую флэшку, а кристалл есть кристалл (внимательно посмотрите сайт), на FPGA мы сейчас ничего не делаем. Делали на этапе ОКР, для подтверждения расчётных параметров.Кристалл сделан по 180нм.
Периферия — более-менее понятная для тех, кто работал с микроконтроллерами, за исключением Ethernet и USB — на кристалле нет «физической» части интерфейса, и их нужно ставить на плате отдельными микросхемами.
Софт для разработки — на данный момент только ассемблер. Компилятор С находится на стадии «пузырьковая сортировка работает» (Update: и факториалы). Подробное описание архитектуры, необходимое для разработчиков — не доступно на данный момент.
Резюме
Архитектура Мультиклета —
Достигнутая практическая производительность первого процессора в 400 млн операцией в секунду сравнима, а местами и меньше чем производительность серийных одноядерных процессоров классической архитектуры производимых в России (про зарубежные процессоры и DSP я конечно молчу) — за счет более высокой тактовой частоты и более «мясистого» набора инструкций последних.
Дальнейший рост производительности _на мой взгляд_ обещает быть сложным, т.к. чем больше ядер на кристалле мы размещаем, тем медленнее будет работать каждое ядро из-за того что накладные расходы на поддержание схемы «все ядра имеют доступ везде» быстро растут с ростом количества ядер.
Декларируемая «устойчивость» процессора к сбоям — вопрос туманного будущего, сейчас её нет.
Исходя из всего этого, я не думаю что эта «принципиально новая (пост-неймановская) мультиклеточная архитектура» — прорыв в процессоростроении.
Работает — да. Лучше конкурентов (в том числе Российских) — едва ли.
Буду рад услышать ваши дополнения и корректировки — доступная информация по Мультиклету весьма ограничена, и я вполне могу где-то ошибаться.
Update: Обновлены данные по точности вещественных чисел, 24->32бит, 48бит убрано, переписал в свете этого резюме в более позитивном ключе.
Update: Более явно отделил свои домыслы от фактов.
Update: Благодаря beeruser обнаружили, что эта архитектура (Explicit Data Graph Execution / TRIPS) известна на западе достаточно давно, и назвать её новой нельзя. Т.к. у них она УЖЕ не взлетела, вероятность взлететь у нас — крайне мала.
Update: Получены дополнения от разработчиков — кристалл сделан на 180нм, отказоустойчивость — в текущем процессоре её нет, она может появится в будущем.
