Здравствуйте хабровчане, в этой статье я хочу рассказать о взаимодействии двух технологий MPI(mpich2) и NVIDIA CUDA. Упор я хочу сделать именно на саму структуру программы и настройку вышеописанных технологий для работы в одной программе. И так поехали…

Для удобства, я написал небольшой план по которому мы будем двигаться:
1) Подготовка системы для работы.
2) Установка библиотеки mpich2.
3) Установка NVIDIA CUDA.
4) Написание программного кода (структура программы)
5) Настройка компилятора.
6) Компиляция и запуск исполняемого файла.
Или же при желании вы можете поставить все прямо из терминала.
Либо Alt+f2:
и в поиске прописать:

Выбрать найденный пакет и установить его. Так же при желании вы можете установить и другие с вашей точки зрения полезные пакеты связанные с mpi или mpich2. Желательно установить документацию. Далее проверим, что у нас получилось, создадим файл test.cpp и добавим в него следующий код:
Скомпилируем его:
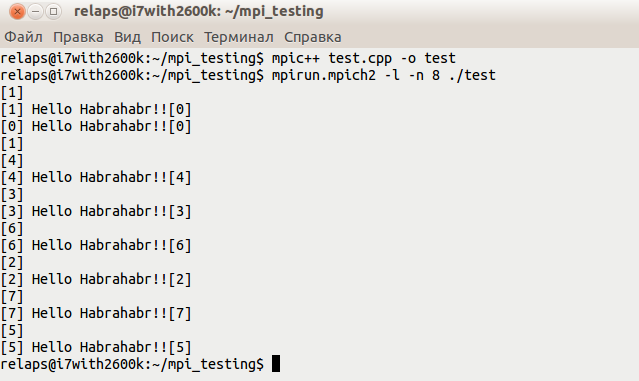
Запустим:
В итоге должно получиться что-то вроде этого:
main.cu
head.h // здесь будут содержаться хедерные файлы.
GPU.cu // код предназначенный для гпу.
CPU.cpp // код предназначенный для процессора.
main.cu — здесь напишем простейший mpi код, который послужит для запуска программы на нескольких ядрах. В функциях gpu и cpu происходит обычное умножение, с той лишь разницей, что в функции gpu умножение происходит на видео карте.
head.h — здесь опишем необходимые инклюды.
GPU.cu — непосредственно код который умножает два числа на видео карточке.
CPU.cpp — данный код, скорее для проверки умножения происходящего на гпу и в принципе больше полезности ни какой не несет.
Созданные файлы положить в папку ../src. В итоге должно получиться как-то так:

И так теперь необходимо всего лишь перейти в папку с проектом и собрать его.
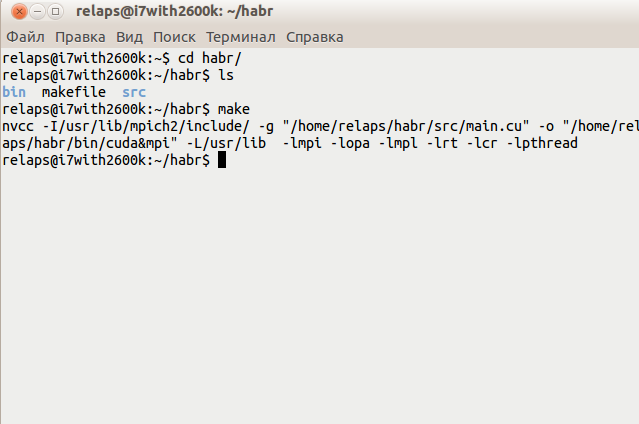
Собираем:
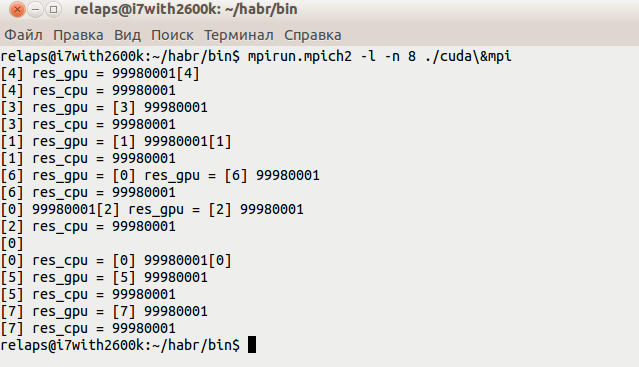
Запускаем, получается что-то вроде этого:
Ну собственно на этом работа закончена, в итоге у нас получилась программа в которой задействованы и видео карточка, и несколько ядер процессора. Конечно пример с умножением двух чисел представленный в данном контексте, совершенно не актуален для данных технологий, но повторюсь — я ставил перед собой задачу показать, что mpi и cuda могут вполне сосуществовать в одной программе(считаю, что код элементарный за исключением директив cuda и mpi, поэтому особо его не пояснял). Естественно, если взять более сложную программу, то возникает сразу много нюансов, начиная от структуры кластера и т.п., продолжать тут можно долго, каждая такая программа требует индивидуального рассмотрения. Но в итоге оно того стоит.
p.s. В следующем посте, вероятнее всего, попытаюсь рассказать про основы nvidia cuda.
Для удобства, я написал небольшой план по которому мы будем двигаться:
1) Подготовка системы для работы.
2) Установка библиотеки mpich2.
3) Установка NVIDIA CUDA.
4) Написание программного кода (структура программы)
5) Настройка компилятора.
6) Компиляция и запуск исполняемого файла.
Пункт 1
Возможно стоило назвать его как-то по-другому, но тем не менее. Я использую операционную систему Ubuntu 12.04 и теоретически для всей настройки достаточно пакетного менеджера — synapticsudo apt-get install synapticИли же при желании вы можете поставить все прямо из терминала.
Пункт 2
И так приступим. Что же такое MPI? Немного перефразирую википедию — это некий API который позволяет обмениваться данными между процессами, выполняющими одну задачу. Проще говоря, это одна из нескольких технологий параллельного программирования. Более подробно можно почитать на википедии. Мы будем использовать MPICH2 — библиотека в которой реализован стандарт MPI, т. к. данная библиотека является самой распространенной. Для ее установки необходимо в терминале прописать:sudo apt-get install mpi-default-devsudo apt-get install mpich2sudo apt-get install libmpich2-devЛибо Alt+f2:
gksu synaptic
и в поиске прописать:
mpi-default-devmpich2libmpich2-devВыбрать найденный пакет и установить его. Так же при желании вы можете установить и другие с вашей точки зрения полезные пакеты связанные с mpi или mpich2. Желательно установить документацию. Далее проверим, что у нас получилось, создадим файл test.cpp и добавим в него следующий код:
#include <mpi.h> #include <iostream> int main (int argc, char* argv[]) { int rank, size; MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank); MPI_Comm_size (MPI_COMM_WORLD, &size); std::cout<<"\nHello Habrahabr!!"<<std::endl; MPI_Finalize(); return 0; }
Скомпилируем его:
mpic++ test.cpp -o testЗапустим:
mpirun.mpich2 -l -n 8 ./test
В итоге должно получиться что-то вроде этого:
Пункт 3
Данный процесс я описывал в своем прошлом посте.Пункт 4
Предположим, что у нас есть папка habr, создадим в ней следующие файлы:main.cu
head.h // здесь будут содержаться хедерные файлы.
GPU.cu // код предназначенный для гпу.
CPU.cpp // код предназначенный для процессора.
main.cu — здесь напишем простейший mpi код, который послужит для запуска программы на нескольких ядрах. В функциях gpu и cpu происходит обычное умножение, с той лишь разницей, что в функции gpu умножение происходит на видео карте.
#include "head.h" int main(int argc, char* argv[]){ int rank, size; int x = 9999; int y = 9999; MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank);//номер текущего процесса MPI_Comm_size (MPI_COMM_WORLD, &size);//число процессов int res_gpu = gpu(x, y); int res_cpu = cpu(x, y); std::cout<<"res_gpu = "<<res_gpu<<std::endl; std::cout<<"res_cpu = "<<res_cpu<<std::endl; MPI_Finalize(); return 0; }
head.h — здесь опишем необходимые инклюды.
#include <iostream> #include <mpi.h> #include <cuda.h> #include "CPU.cpp" #include "GPU.cu"
GPU.cu — непосредственно код который умножает два числа на видео карточке.
#include <cuda.h> #include <iostream> #include <stdio.h> __global__ void mult(int x, int y, int *res) { *res = x * y; } int gpu(int x, int y){ int *dev_res; int res = 0; cudaMalloc((void**)&dev_res, sizeof(int)); mult<<<1,1>>>(x, y, dev_res); cudaMemcpy(&res, dev_res, sizeof(int), cudaMemcpyDeviceToHost); cudaFree(dev_res); return res; }
CPU.cpp — данный код, скорее для проверки умножения происходящего на гпу и в принципе больше полезности ни какой не несет.
int cpu(int x, int y){ int res; res = x * y; return res; }
Созданные файлы положить в папку ../src. В итоге должно получиться как-то так:
Пункт 5
Тут самое интересное, необходимо настроить компилятор nvcc для компиляции не только CUDA кода, но и MPI кода, для этого напишем небольшой make файл:CXX = nvcc LD = $(CXX) LIBS_PATH = -L/usr/lib LIBS = -lmpi -lopa -lmpl -lrt -lcr -lpthread INCLUDE_PATH = -I/usr/lib/mpich2/include/ FLAGS = -g TARGET = "/home/relaps/habr/src/main.cu" OBIN = "/home/relaps/habr/bin/cuda&mpi" all: $(TARGET) $(TARGET): $(LD) $(INCLUDE_PATH) $(FLAGS) $(TARGET) -o $(OBIN) $(LIBS_PATH) $(LIBS)
И так теперь необходимо всего лишь перейти в папку с проектом и собрать его.
Пункт 6
Здесь я думаю комментарии излишни на скриншоте все видно.Собираем:
Запускаем, получается что-то вроде этого:
Ну собственно на этом работа закончена, в итоге у нас получилась программа в которой задействованы и видео карточка, и несколько ядер процессора. Конечно пример с умножением двух чисел представленный в данном контексте, совершенно не актуален для данных технологий, но повторюсь — я ставил перед собой задачу показать, что mpi и cuda могут вполне сосуществовать в одной программе(считаю, что код элементарный за исключением директив cuda и mpi, поэтому особо его не пояснял). Естественно, если взять более сложную программу, то возникает сразу много нюансов, начиная от структуры кластера и т.п., продолжать тут можно долго, каждая такая программа требует индивидуального рассмотрения. Но в итоге оно того стоит.
p.s. В следующем посте, вероятнее всего, попытаюсь рассказать про основы nvidia cuda.
