Comments 61
Было бы хорошо автоматически определять наличие лица и обрезать ту часть, где находится оно.
Но для этого скрипт должен уметь отличать лицо от попы.
Но для этого скрипт должен уметь отличать лицо от попы.
Не, nginx — это хорошо, но скалинг изображений ИМХО не должен ложиться на плечи веб сервера.
есть, кстати, чуйство, что воркер при таких операциях затыкается.
Это же кроп. А вот х.з. — в бэкграунд отправлять на демона какого? А если нам та картинка не нужна?
Было уже что-то подобное на хабре — пришли к выводу, что зависит от условий.
Есть много диска и не жалко проц — делаем заранее. Надо более гибко? Режем в прямом эфире.
Было уже что-то подобное на хабре — пришли к выводу, что зависит от условий.
Есть много диска и не жалко проц — делаем заранее. Надо более гибко? Режем в прямом эфире.
Я вот не понял, а зачем каждый раз при отдаче нарезать? Не проще ли нарезать один раз при заливке?
После нарезки картинка кладётся в кеш, это далеко не «каждый раз нарезать». Если нарезать при заливке, то однажды наступит ситуация, когда нужно будет нарезать ещё один размер для 200 миллионов картинок.
А, ну тогда ладно )
А как часто возникает ситуация, когда нужно нарезать еще один размер?
И даже если это происходит каждую неделю, почему нельзя нарезать «лениво»? Ну то есть, вот пришел запрос, нарезали и положили (раз уж для вас нарезать на лету вполне приемлемо). Неужели места жалко?
И даже если это происходит каждую неделю, почему нельзя нарезать «лениво»? Ну то есть, вот пришел запрос, нарезали и положили (раз уж для вас нарезать на лету вполне приемлемо). Неужели места жалко?
Ситуация возникает достаточно часто, чтобы делать так, как делается. Мы лениво нарезаем и кладём в быстрый кеш вместо медленного диска. Места не жалко, жалко io.
Кеш это понятно. Я имею в виду, почему нельзя класть на диск, а в следующий раз брать (и класть в кеш) уже с диска вместо нарезания снова. Вы замеряли, сколько занимает нарезка фотки и как часто протухает кеш? И каков, кстати, процент попадания в кеш?
Ну смотрите, картинка 5 мегабайт, нарезанные копии по 20кб x 5 штук. Итого в ясную погоду 5 скачков (это ещё без метаданных) по диску. Ежели оставить только 5 мегабайт, то остаётся одно чтение (для нарезки чтения будут из кеша) + cpu. Окружающая ситуация такова, что cpu гораздо дешевле disk seek. Нарезка фотки занимает гораздо меньше времени, чем поднятие фотки с диска.
Нарезка фотки занимает гораздо меньше времени, чем поднятие фотки с диска.
Да, если не считать, что нарезка фотки включает в себя поднятие с диска оригинала фотки. То есть, в случае нарезки это время поднятия + время нарезки. В случае с уже нарезанным файлом, это только время поднятия с диска. При чем поднять 5 МБ или 20 КБ тоже разница есть.
В общем, насколько я понял, вы сейчас не упираетесь в производительность, поэтому такого решения вам вполне достаточно.
Да, если не считать, что нарезка фотки включает в себя поднятие с диска оригинала фотки. То есть, в случае нарезки это время поднятия + время нарезки. В случае с уже нарезанным файлом, это только время поднятия с диска. При чем поднять 5 МБ или 20 КБ тоже разница есть.
В общем, насколько я понял, вы сейчас не упираетесь в производительность, поэтому такого решения вам вполне достаточно.
5 мегабайт поднимается один раз, потом он берётся из кеша. Линейное и рандомное чтение — две большие разницы, прочитать подряд 5 мегабайт проще, чем три раза по 20кб.
5 мегабайт поднимается один раз, потом он берётся из кеша
Что это за кеш такой интересный, что 5МБ фотка туда кладется, а ее ресайз в 20КБ нет?
Линейное и рандомное чтение — две большие разницы, прочитать подряд 5 мегабайт проще, чем три раза по 20кб.
Как вы гарантируете, что ваши 5МБ не фрагментированы и читаются последовательно? И зачем читать три раза по 20КБ?
Мы, видимо, немного о разном говорим )
Что это за кеш такой интересный, что 5МБ фотка туда кладется, а ее ресайз в 20КБ нет?
Линейное и рандомное чтение — две большие разницы, прочитать подряд 5 мегабайт проще, чем три раза по 20кб.
Как вы гарантируете, что ваши 5МБ не фрагментированы и читаются последовательно? И зачем читать три раза по 20КБ?
Мы, видимо, немного о разном говорим )
Линейность записи фотки гарантируется сервером, который эту фотку у себя держит.
Ресайз фотки кладётся в кеш, но чтобы его туда положить, нужно сначала с диска прочитать. Если мы ресайзим на лету, то после первого чтения оригинальных 5 мегабайт, они лягут в кеш уровня сервера данных. Ресайзы лягут кеш, который выше ресайзеров. При пустом кеше три размера получаются как одно чтение с диска 5мб + 2 чтения из кеша + 3 ресайза.
В вашем варианте при пустом кеше три размера получаются как 3 чтения с диска.
Ресайз фотки кладётся в кеш, но чтобы его туда положить, нужно сначала с диска прочитать. Если мы ресайзим на лету, то после первого чтения оригинальных 5 мегабайт, они лягут в кеш уровня сервера данных. Ресайзы лягут кеш, который выше ресайзеров. При пустом кеше три размера получаются как одно чтение с диска 5мб + 2 чтения из кеша + 3 ресайза.
В вашем варианте при пустом кеше три размера получаются как 3 чтения с диска.
Понятно, у вас хранилище а-ля FB Haystack. А если не секрет, все же, сколько времени занимает ресайз фотки в вашем случае и чтение фотки из вашего хранилища? Наверняка же какие-то тесты делали.
Прямо сейчас ресайз + чтение в среднем 66ms, чтение с диска 15ms.
Это если 5 мегабайт не фрагментированы по диску :)
Мы так делаем, у нас работает хорошо. Почти 20млрд картинок, если считать вместе с ресайзнутыми, всего на 6 машинках, в трёх копиях. Размеров штук по 6 на каждую картинку + при заливке пытаемся детектить лица и вырезать тот кусок, где лицо. Не получилось — ну тогда просто ресайз с, возможно, кропом, чтобы в квадратик вписать (не для всех размеров).
Одно непонятно: как вы узнаете какой параметр передавать image_filter_offset в nginx, чтобы получилось лицо?
Мы делаем допущение, что лицо у людей растёт на голове, которая сверху. image_filter offset center top; у нас :)
Ну сами понимаете, что решение так себе получается. Не интерпрайз.
Лучший вариант это дать юзеру возможность самостоятельно отрезать себе голову в нужных размерах и пропорциях.
Лучший вариант это дать юзеру возможность самостоятельно отрезать себе голову в нужных размерах и пропорциях.
Люди могут загрузить 100 фотографий и не захотеть выбирать, где у них там по^W лицо, а превьюшки показывать нужно, вот и приходится вставлять разного рода подпорки.
Но вообще предлагать выбрать важные части тела при загрузке правильно, тут не поспоришь.
Но вообще предлагать выбрать важные части тела при загрузке правильно, тут не поспоришь.
В контактике же тоже так сделано, он по дефолту берет верхнюю часть картинки, а если что-то не нравится, то можно уже и вручную подредактировать.
«Лучший вариант это дать юзеру возможность самостоятельно отрезать себе голову»
Так гораздо лучше.
Так гораздо лучше.
Говоря простым языком, торец украшает переднюю часть бубна.
Так а что если фотка таки горизонтальная и еще оно там лежит? Тут точно нет гарантии, что лежит слева направо, а не наоборот. Или вообще не лежит, а широко улыбается ;)
О чем автор говорит — о сайте знакомств. А такое впечатление, что никогда там не бывал! Посмотрите на фото девчонок там, какие там фотки? Большинство девчонок либо на скамейках, либо на кроватях, либо на пляже. И они там лежат. И фото там горизонтальные. И лица то справа, то слева. А в центре фото — хм… хотя нет, автор явно бывал на сайтах знакомств и знает что обрезать! :)
Когда-то что-то слышал про Topface и думал, что уж вот у кого самые крутые методы определения лица на фотографиях должны быть. А после прочтения поста — *facepalm*

Могу ошибаться, но если это превьюшка фотки, то сервер не должен иметь права сам решать, что ему обрезать. Сервер имеет право только уменьшить оригинал до заданных размеров превьюшки. И не важно, как там на фотке расположено изображение, вытянуто вертикально или горизонтально. Превьюшка должна быть уменьшена пропорционально до требуемых размеров, например, 200х200px. Либо позволить пользователю самому задавать часть фотки, из которой делается превьюха, благо это сделать совсем не сложно.
Особенно вдохновляют примеры картинок.
У вас на сайте в рейтинге фото лидируют длиннокот, лыжница без головы и замороженная капуста? о_0
У вас на сайте в рейтинге фото лидируют длиннокот, лыжница без головы и замороженная капуста? о_0
Раз появилась такая тема, тоже подниму вопрос рациональности такого ресайза, операции io должны быть дешевле, судя по текущим ценам на рынке, по этому возвращаюсь к вопросу по презентации «node.js for millions of images», уже задавал, но так и не получил ответа
«А что за диски использовались/используются sata, sas, ssd, какого объема один диск, в каком raid-массиве они собраны и используется ли lvm?»
«А что за диски использовались/используются sata, sas, ssd, какого объема один диск, в каком raid-массиве они собраны и используется ли lvm?»
SATA 1Tb, один диск под один логический сервер со своим куском данных, без raid и lvm.
Операции io дешевле чем cpu? Не путаете с объёмами дисков? :)
Операции io дешевле чем cpu? Не путаете с объёмами дисков? :)
Посмотрите на raid10, я бы предложил raid6, производительность выше, но проблем с ним бывает намного больше http://ru.wikipedia.org/wiki/RAID#RAID_10, при этом по возможности собирать это из дисков 500gb, потому, как я понял, вам не хватает IOPS, а на один диск выдает определенное кол-во, вне зависимости от объема.
По поводу цены, смотрите, процессор такое дело, максимальная тактовую частота находится на определенное границе и рост пока не ожидается, а из дисков могут собирать вполне производительные san'ы, вот пример. Сравнивать 8 ядерные Xeon'ы c даже 500gb SAS, думаю, нет необходимости
По поводу цены, смотрите, процессор такое дело, максимальная тактовую частота находится на определенное границе и рост пока не ожидается, а из дисков могут собирать вполне производительные san'ы, вот пример. Сравнивать 8 ядерные Xeon'ы c даже 500gb SAS, думаю, нет необходимости
И сразу еще один вопрос, почему не заюзать сторонний CDN для картинок?
Лица можно находить с помощью OpenCV буквально за 3 строчки:
cascade = cv2.CascadeClassifier()
cascade.load('/opencv/data/haarcascades/haarcascade_frontalface_alt.xml')
faces = cascade.detectMultiScale(img)
cascade = cv2.CascadeClassifier()
cascade.load('/opencv/data/haarcascades/haarcascade_frontalface_alt.xml')
faces = cascade.detectMultiScale(img)
Вот тут можно определить голову кота, например. Правда слишком медленно.
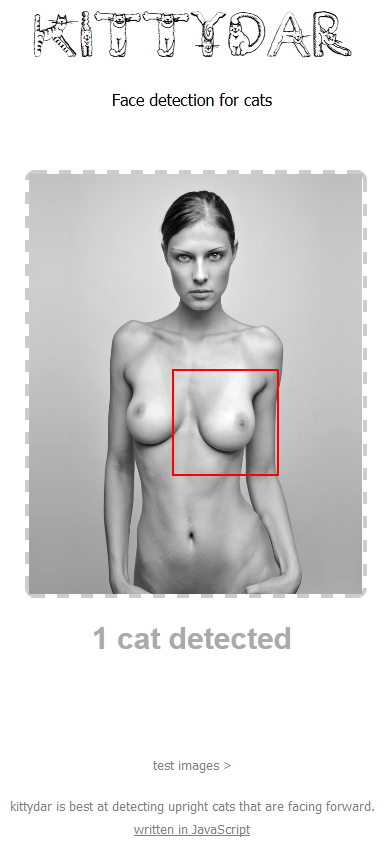{kind=link}
штука конечно хорошая, но мы заранее не знаем где на картинке лицо, а где что пониже… и предугадать не всегда получится…
так что всегда возникнет ситуация, что у одних будет отображено лицо, а у некоторых то что пониже…
так что всегда возникнет ситуация, что у одних будет отображено лицо, а у некоторых то что пониже…
Коммент на гитхабе доставляет:
Балин… Че к чему nginx ещё не на гитхабе (мирор не в счет)? Так бы можно было этот модуль форкнуть и запулреквестить, чтобы в основной веточке появилось.
Попробуйте связаться с тов. Дуниным, чтобы сюда замерджить:
trac.nginx.org/nginx/browser/nginx/trunk/src/http/modules/ngx_http_image_filter_module.c
ps: Коммент кинул на гитхабе: github.com/bobrik/nginx_image_filter/commit/bf6535355f508abbdab25cc719fdbe7aa7715cb7
en: Humans usually have faces at the top of their photos
ru: Люди обычно имеют лица в верху их фото
Балин… Че к чему nginx ещё не на гитхабе (мирор не в счет)? Так бы можно было этот модуль форкнуть и запулреквестить, чтобы в основной веточке появилось.
Попробуйте связаться с тов. Дуниным, чтобы сюда замерджить:
trac.nginx.org/nginx/browser/nginx/trunk/src/http/modules/ngx_http_image_filter_module.c
ps: Коммент кинул на гитхабе: github.com/bobrik/nginx_image_filter/commit/bf6535355f508abbdab25cc719fdbe7aa7715cb7
Sign up to leave a comment.
Отрезаем голову в nginx