Что это и для кого (вместо вступления)
В данной статье я бы хотел рассказать о небольших результатах своей научной деятельности в сфере Text Mining. Этими самыми «результатами» стал небольшой FrameWork, который, пока еще, и до либы то не очень дотягивает, но мы растем =). Данный проект — реализация на практике некоторых, разработанных мною, теоретических положений. Как следствие этого я представляю возможности, которыми он может потенциально обладать в конце внедрения всех идей. Названо сее творение: «Text Mining FrameWork»(TextMF). Давайте в кратце рассмотрим, что именно будет позволять TextMF в своей первой финальной версии и что работает уже сейчас.
Должно быть в финальной версии:
Уже реализовано (доступно частично или проходит тестирование):
Зачем еще одна библиотека по обработке текста?
Дело в том, что цель данного проекта не создать инструмент, используя который можно реализовать какой либо алгоритм обработки текста (как например Python NLTK и схожие), а дать возможность использовать уже готовые алгоритмы. А заодно и апробировть на практике свой собственный алгоритм. Т.е. это не еще один статистический анализатор или набор контейнеров оптимизированных под работу с текстовыми данными. Нет! Это набор эвристик, которые будут работать из коробки, не нуждаясь в дополнительных знаниях.
С какими входными данными работает TextMF: пока только текстовые файлы. Само собой далее планируется поддержка намного больших входных форматов. Так же планируется сделать интеграцию с Веб, дабы можно было-бы спокойно анализировать Веб-странички.
Явки и пароли
Проект распространяется через репозиторий BitBucket.
Клоните его себе и подключаете к своему проекту =) Все предельно просто. В скором времени будут доступны сборки в виде подключаемого jar.
Пример использования
Обработка текста очень часто занимает много времени, особенно если пытаться открыть целую книгу! Так что в целях «на попробовать» настоятельно рекомендую ограничивать себя несколькими страничными текстами с сайтов. Однако, уж очень маленькие тексты так же могут дать не очень хороший результат, из-за недостаточности информации в них.
Как уже говорилось ранее, основная идея в максимальной простоте использования и сокрытие эвристик и алгоритмов. Так что все банально:
Повторюсь, получение темы — довольно долгая процедура, так что вызывая данный метод будьте осторожны;) Само собой будет реализован и асинхронный метод получения темы, но позже. Так же ОЧЕНЬ важно отметить, что качество работы методов растет в зависимости от того, какого размера текст подан на вход. Чем больше информации тем, как правило, больше возможности выучить язык. Однако и время открытия файлов существенно возрастает, при увеличении размеров содержимого.
Небольшая UI-программа
Для наглядной демонстрации некоторых функций программы, моим коллегой по имени Андрей, был на скорую руку написан небольшой UI клиент. На текущей стадии он носит просто ознакомительный характер, так как иногда удобнее воспользоваться им. Написан он на Java FX, и пока не распространяется в виде отдельного jar файла. Для того, что бы его «пощупать», нужно его собрать =(.
Главное окно программы:
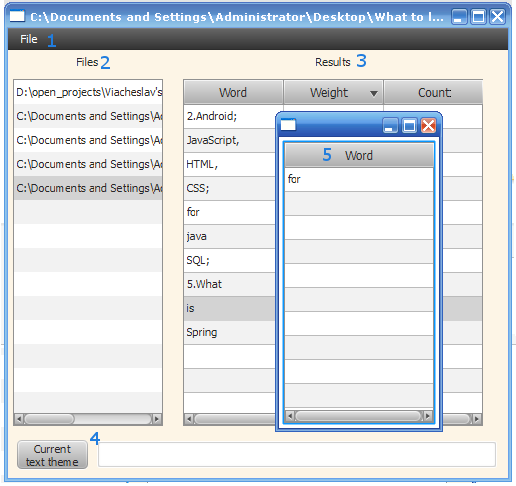
1) Меню выбора текста для обработки;
2) Список выбранных файлов;
3) Результаты работы:
a) слово встречаемое в тексте;
b) вес слова в тексте;
с) количество повторений в тексте
4) Поле для вывода темы текста;
5) Список словоформ.
Давайте посмотрим, что мы можем узнать, используя нашу программу для этого текста: Владельцам «Волг» и «Москвичей» дадут еще один год:
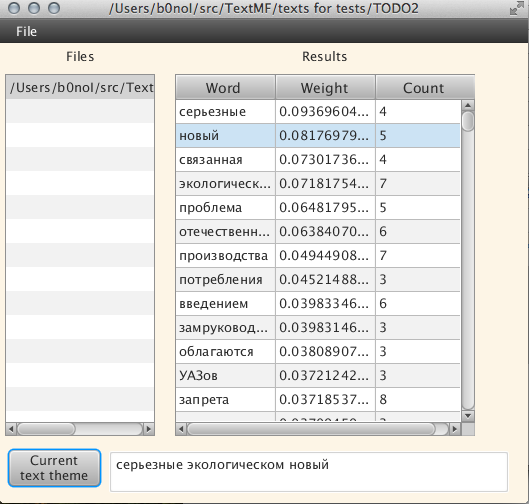
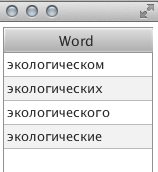
Поиск темы осуществлялся около минуты (долго, согласен). При выборе какого либо отдельного слова, можно посмотреть его словоформы:

или вот:
А теперь попробуем еще один текст: «Пришельцы похитили семью украинцев и рассказали о будущем землян!», наверное один из самых «желтых» текстов =):
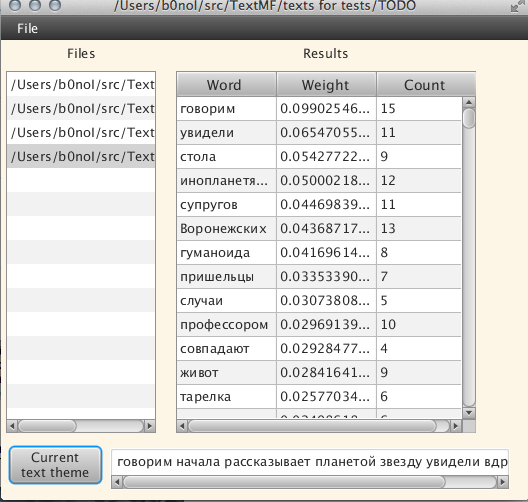
Текст открывался долго, наверное минуту, тему искал где-то так же. Само собой, под темой текста стоит понимать цепочку слов, которые алгоритм посчитал как тему текста. В дальнейшем алгоритм сможет выдавать вывод в читабильном виде, но это будущее, а сейчас
нам нужна Ваша помощь
Само собой, нам очень и очень необходима Ваша помощь! Тасков очень много, а проект то бесплатный. Задачи начинаются от самых простых: заниматься сайтом, писать примеры, документировать код, до самых хардкорных: помогать в оптимизации мат. аппарата и уточнять его. Сейчас, например, неплохо бы было кому-то взять на себя вопрос расширения входных форматов и сделать нечто большее, нежели просто текстовый файл. Так же очень важна помощь в тестировании. У проекта есть домен: www.textmf.com, однако там пусто, и я был бы очень рад, если кто-то помог это исправить =)
По любым предложениям сотрудничества прошу обращаться сюда: Viacheslav@b0noI.com
Ближайшие планы
Из того, что будет в ближайшее время(думаю в пределах месяца-двух) с проектом:
Далекие планы
Сейчас TextMF стал полуфиналистом проекта www.ukrinnovation.com. Так что есть, хоть и маленький, но все же шанс получить инвестиции на развитие.
Знаю, что пока это мечты, но если бы у меня спросили какой функционал я вижу в конце, то я бы ответил: библиотека, используя которую можно написать чат-бота, который пройдет тест Тюринга. Если говорить более реальное, то скорее всего движки для динамического отслеживания информации в интернете. Отслеживание связей и контроль за их изменениями. Ну и, само собой, нечто для создания каких либо локальных поисковых систем.
Сама идея имеет огромный потенциал, тут и спам-фильтры, и поисковые системы, и системы автоматического реферированная, и еще много-много чего того, что можно построить на базе такого framework.
Авторы TextMF:
Ваш покорный слуга Вячеслав В Ковалевский и
разработчик UI Андрей Прищепа (vinglfm@gmail.com)
В данной статье я бы хотел рассказать о небольших результатах своей научной деятельности в сфере Text Mining. Этими самыми «результатами» стал небольшой FrameWork, который, пока еще, и до либы то не очень дотягивает, но мы растем =). Данный проект — реализация на практике некоторых, разработанных мною, теоретических положений. Как следствие этого я представляю возможности, которыми он может потенциально обладать в конце внедрения всех идей. Названо сее творение: «Text Mining FrameWork»(TextMF). Давайте в кратце рассмотрим, что именно будет позволять TextMF в своей первой финальной версии и что работает уже сейчас.
Должно быть в финальной версии:
- Статистический анализ текста;
- Поиск всех слов и словоформ каждого слова в тексте;
- Ранжирование слов по весу в тексте;
- Поиск субъектов в тексте, о которых идет речь;
- Связи между субъектами в тексте (прямые и не прямые связи);
- Реферирование текста;
- Определение темы текста;
- Обучение языку;
- Организация взаимодействия с пользователем по средствам общения (чата).
Уже реализовано (доступно частично или проходит тестирование):
- Статистический анализ текста (пока реализовано очень частично);
- Поиск всех слов и словоформ в тексте;
- Сортировка слов по их весу в данном тексте;
- Поиск персон в тексте;
- Определение темы текста (идет тестирование и юстировка формул).
Зачем еще одна библиотека по обработке текста?
Дело в том, что цель данного проекта не создать инструмент, используя который можно реализовать какой либо алгоритм обработки текста (как например Python NLTK и схожие), а дать возможность использовать уже готовые алгоритмы. А заодно и апробировть на практике свой собственный алгоритм. Т.е. это не еще один статистический анализатор или набор контейнеров оптимизированных под работу с текстовыми данными. Нет! Это набор эвристик, которые будут работать из коробки, не нуждаясь в дополнительных знаниях.
С какими входными данными работает TextMF: пока только текстовые файлы. Само собой далее планируется поддержка намного больших входных форматов. Так же планируется сделать интеграцию с Веб, дабы можно было-бы спокойно анализировать Веб-странички.
Явки и пароли
Проект распространяется через репозиторий BitBucket.
Клоните его себе и подключаете к своему проекту =) Все предельно просто. В скором времени будут доступны сборки в виде подключаемого jar.
Пример использования
Обработка текста очень часто занимает много времени, особенно если пытаться открыть целую книгу! Так что в целях «на попробовать» настоятельно рекомендую ограничивать себя несколькими страничными текстами с сайтов. Однако, уж очень маленькие тексты так же могут дать не очень хороший результат, из-за недостаточности информации в них.
Как уже говорилось ранее, основная идея в максимальной простоте использования и сокрытие эвристик и алгоритмов. Так что все банально:
// Открываем и парсим текстовый файл, который лежит по адресу TEXT_FILE_NAME Text text = new Text(TEXT_FILE_NAME); // Получаем список слов отранжированных по весу List<Word> words = text.getWords(); // Получаем тему текста List<Word> theme = text.getThem(); // Получаем первое слово в списке слов Word word = words.get(0); // Получаем лист всех словоформ List<String> wordForms =word.getWordForms(); // Получаем количество вхождений слова в текст long count = word.getCount(); // Получаем все персоны, которые встречаются в тексте List<Word> objects = text.getObjects(); // Смотрим вес слова double weight = text.getWordWeight(word);
Повторюсь, получение темы — довольно долгая процедура, так что вызывая данный метод будьте осторожны;) Само собой будет реализован и асинхронный метод получения темы, но позже. Так же ОЧЕНЬ важно отметить, что качество работы методов растет в зависимости от того, какого размера текст подан на вход. Чем больше информации тем, как правило, больше возможности выучить язык. Однако и время открытия файлов существенно возрастает, при увеличении размеров содержимого.
Небольшая UI-программа
Для наглядной демонстрации некоторых функций программы, моим коллегой по имени Андрей, был на скорую руку написан небольшой UI клиент. На текущей стадии он носит просто ознакомительный характер, так как иногда удобнее воспользоваться им. Написан он на Java FX, и пока не распространяется в виде отдельного jar файла. Для того, что бы его «пощупать», нужно его собрать =(.
Главное окно программы:
1) Меню выбора текста для обработки;
2) Список выбранных файлов;
3) Результаты работы:
a) слово встречаемое в тексте;
b) вес слова в тексте;
с) количество повторений в тексте
4) Поле для вывода темы текста;
5) Список словоформ.
Давайте посмотрим, что мы можем узнать, используя нашу программу для этого текста: Владельцам «Волг» и «Москвичей» дадут еще один год:
Поиск темы осуществлялся около минуты (долго, согласен). При выборе какого либо отдельного слова, можно посмотреть его словоформы:
или вот:
А теперь попробуем еще один текст: «Пришельцы похитили семью украинцев и рассказали о будущем землян!», наверное один из самых «желтых» текстов =):
Текст открывался долго, наверное минуту, тему искал где-то так же. Само собой, под темой текста стоит понимать цепочку слов, которые алгоритм посчитал как тему текста. В дальнейшем алгоритм сможет выдавать вывод в читабильном виде, но это будущее, а сейчас
нам нужна Ваша помощь
Само собой, нам очень и очень необходима Ваша помощь! Тасков очень много, а проект то бесплатный. Задачи начинаются от самых простых: заниматься сайтом, писать примеры, документировать код, до самых хардкорных: помогать в оптимизации мат. аппарата и уточнять его. Сейчас, например, неплохо бы было кому-то взять на себя вопрос расширения входных форматов и сделать нечто большее, нежели просто текстовый файл. Так же очень важна помощь в тестировании. У проекта есть домен: www.textmf.com, однако там пусто, и я был бы очень рад, если кто-то помог это исправить =)
По любым предложениям сотрудничества прошу обращаться сюда: Viacheslav@b0noI.com
Ближайшие планы
Из того, что будет в ближайшее время(думаю в пределах месяца-двух) с проектом:
- добавим сборку jar файла;
- проект будет разделен на ядро и UI, т.е. добавится еще один репозиторий;
- начнется реализация долгосрочной памяти;
- анализ связей между персонами;
- появится возможность реферирования текста;
- создание самодостаточного jar с UI.
Далекие планы
Сейчас TextMF стал полуфиналистом проекта www.ukrinnovation.com. Так что есть, хоть и маленький, но все же шанс получить инвестиции на развитие.
Знаю, что пока это мечты, но если бы у меня спросили какой функционал я вижу в конце, то я бы ответил: библиотека, используя которую можно написать чат-бота, который пройдет тест Тюринга. Если говорить более реальное, то скорее всего движки для динамического отслеживания информации в интернете. Отслеживание связей и контроль за их изменениями. Ну и, само собой, нечто для создания каких либо локальных поисковых систем.
Сама идея имеет огромный потенциал, тут и спам-фильтры, и поисковые системы, и системы автоматического реферированная, и еще много-много чего того, что можно построить на базе такого framework.
Авторы TextMF:
Ваш покорный слуга Вячеслав В Ковалевский и
разработчик UI Андрей Прищепа (vinglfm@gmail.com)
