Все мы пользуемся профайлерами. Традиционная схема работы с ними такова, что приходится изначально запускать программу «под профайлером» а затем, после окончания ее работы, анализировать сырой дамп с помощью дополнительных утилит.
А что делать если мы не имея root'а хотим запрофилировать уже работающую программу, которая долго работала «как надо», а сейчас что-то пошло не так. И хотим это сделать быстро. Знакомая ситуация?
Тогда рассмотрим наиболее популярные профайлеры и принципы их работы. А затем профайлер, который решает именно указанную задачу.
Стоит отметить, что gprof в данном случе точно «знает» и то, сколько раз была вызвана каждая функция. И хотя это может быть необходимым в некоторых ситуациях, это также имеет отрицательный эффект — overhead от замеров может быть сравним или даже больше чем само тело функции. Поэтому, например, для при компиляции C++-кода используют оптимизации приводящие к inline.
Так или иначе, но gprof не работает с уже запущеными программами.
Однако инструмент очень популярен, и простой формат графа вызовов поддерживается отличными средствами визуализации, например, kcachegrind.
Однако это незаменимое средство когда Вам необходимо разобраться с работой всей системы, всего сервера сразу. И особенно незаменимое при профилировании области ядра.
Набор включает серию библиотек нацеленых на ускорение и анализ C/C++ — приложений. Центральной частью является аллокатор tcmalloc, который помимо ускорения распределения памяти несет средства для анализа классических проблем — memory leaks и heap profile.
Второй частью является libprofiler, который позволяет собирать статистику использования CPU. Важно остановиться на том, как он это делает. Несколько раз в секунду (по-умолчанию 100) программа прерывается на сигнал таймера. В обработчике этого сигнала раскручивается стек и запоминаются все указатели инструкций. По-окончанию сырые данные сбрасываются в файл, по которому уже можно строить статистику и граф вызовов.
Интересен принцип действия — программа прерывается лишь N раз в секунду, где N достаточно мало. Это т.н. сэмплирующий профайлер. Его преимущество в том, что он не оказывает существенного влияния на анализируемую программу, сколько бы мелких функций там не вызывалось. Ввиду особенностей работы, он, однако, не позволяют ответить на вопрос «сколько раз вызывалась данная функция».
В случае с google profiler есть еще несколько неприятностей:
Он собирает стек вызовов и выводит наиболее «горячие» части в консоль по нажатию ENTER. Также он умеет сохранять граф вызова в упомянутом ранее формате callgrind. Работает быстро, и как любой другой сэмплирующий профайлер не зависит от сложности вызовов в профилируемой программе.
Исходный код доступен на github. Т.к. утилита создавалась для меня и моих коллег, я вполне допускаю что она может не соответствовать Вашему use-case'у. Так или иначе, спрашивайте.
Соберем crxprof и посмотрим на пример его использования.
Что необходимо: Linux (2.6+), autoconf+automake, binutils-dev (включает libbfd), libunwind-dev (у меня он называется libunwind8-dev).
Для сборки выполняем:
Если libunwind установлен в нестандартное место, используйте:
Для этого просто запустите
И все! Теперь используйте ENTER для вывода профайла в консоль, и ^C для завершения. Crxprof также выведет профайл и по выходу программы.
Как все unix-утилиты, crxprof выводит usage при вызове с ключом --help. Подробную информацию см. в
Для того чтобы привести реальный, но не сложный пример я использую этот код на C. Скомпилируем, запустим его и попросим crxprof сохранить граф вызова функций (4054 — pid профилируемой программы):
По выведенной на консоль статистике видно что:
Визуализация делается по схеме «наибольшие поддеревья — первыми». Таким образом, даже для больших реальных программ можно использовать простую визуализацию в консоли, что должно быть удобно на серверах.
Для визуализации сложных графов вызова удобно использовать KCachegrind:
Картинка, которая получилась у меня, представлена справа.
Вместо заключения, напомню что профайлером пока пользуются лишь несколько моих коллег и я сам. Надеюсь, он будет также полезен и Вам.
А что делать если мы не имея root'а хотим запрофилировать уже работающую программу, которая долго работала «как надо», а сейчас что-то пошло не так. И хотим это сделать быстро. Знакомая ситуация?
Тогда рассмотрим наиболее популярные профайлеры и принципы их работы. А затем профайлер, который решает именно указанную задачу.
Популярные профайлеры
Если вы знаете принципиально другой — напишите о нем в комментах. А пока рассмотрим эти 4:I. gprof
Старый-добрый UNIX профайлер который, по словам Кирка МакКузика, был написан Биллом Джоем для анализа производительности подсистем BSD. Собственно, профайлер «предоставляется» компилятором — он должен расставить контрольные точки в начале и в конце каждой функции. Разница между двумя этими точками и будет временем ее исполнения.Стоит отметить, что gprof в данном случе точно «знает» и то, сколько раз была вызвана каждая функция. И хотя это может быть необходимым в некоторых ситуациях, это также имеет отрицательный эффект — overhead от замеров может быть сравним или даже больше чем само тело функции. Поэтому, например, для при компиляции C++-кода используют оптимизации приводящие к inline.
Так или иначе, но gprof не работает с уже запущеными программами.
II. Callgrind
Callgrind является частью Valgrind'а — отличного фреймворка для построения средств динамического анализа кода. Valgrind запускает программу «в песочнице», фактически используя виртуализации. Callgrind производит профилирование основываясь на брейкпоинтах на инструкциях типа call и ret. Он значительно замедляет анализируемый код, как правило, от 5 до 20 раз. Таким образом, для анализа на больших данных в runtime он, как правило, не годен.Однако инструмент очень популярен, и простой формат графа вызовов поддерживается отличными средствами визуализации, например, kcachegrind.
III. OProfile
OProfile is a system-wide profiler for Linux systems, capable of profiling all running code at low overhead.OProfile является общесистемным профайлером. Т.е. он не нацелен на работу с отдельными процессами, профилируя вместо этого всю систему. OProfile собирает метрики считывая не системный таймер, как gprof или callgrind, а счетчики CPU. Поэтому для запуска демона он требует привелегий.
Однако это незаменимое средство когда Вам необходимо разобраться с работой всей системы, всего сервера сразу. И особенно незаменимое при профилировании области ядра.
Новая версия OProfile 0.9.8
Для версий 0.9.7 и в более ранних профайлер состоял из драйвера ядра и демона для сбора данных. С версии 0.9.8 этот метод заменен на использование Linux Kernel Performance Events (требует ядро 2.6.31 или более свежее). Релиз 0.9.8 также включает в себя программу 'operf', позволяющую непривилегированным пользователям профилировать отдельные процессы.
IV. Google perftools
Этот профайлер является частью набора Google perftools. Я не нашел на хабре его обзора, поэтому очень кратко опишу.Набор включает серию библиотек нацеленых на ускорение и анализ C/C++ — приложений. Центральной частью является аллокатор tcmalloc, который помимо ускорения распределения памяти несет средства для анализа классических проблем — memory leaks и heap profile.
Второй частью является libprofiler, который позволяет собирать статистику использования CPU. Важно остановиться на том, как он это делает. Несколько раз в секунду (по-умолчанию 100) программа прерывается на сигнал таймера. В обработчике этого сигнала раскручивается стек и запоминаются все указатели инструкций. По-окончанию сырые данные сбрасываются в файл, по которому уже можно строить статистику и граф вызовов.
Здесь некоторые детали того как это делается
1. По-умолчанию сигналом таймера выбирается таймер ITIMER_PROF, который тикает лишь при использовании программой CPU. Ведь, как-правило, нам не очень интересно где была программа ожидая ввод с клавиатуры или поступления данных по сокету. А если все же интересно, используйте
2. Стек вызова раскручивается либо с помощью libunwind, либо вручную (что требует --fno-omit-framepointer, всегда работает на x86).
3. Имена функций впоследствии узнаются с помощью addr2line(1)
4. Как и прочие средства Google perftools, профайлер может быть слинкован явно, а может быть и предзагружен средствами
env CPUPROFILE_REALTIME=12. Стек вызова раскручивается либо с помощью libunwind, либо вручную (что требует --fno-omit-framepointer, всегда работает на x86).
3. Имена функций впоследствии узнаются с помощью addr2line(1)
4. Как и прочие средства Google perftools, профайлер может быть слинкован явно, а может быть и предзагружен средствами
LD_PRELOAD.Интересен принцип действия — программа прерывается лишь N раз в секунду, где N достаточно мало. Это т.н. сэмплирующий профайлер. Его преимущество в том, что он не оказывает существенного влияния на анализируемую программу, сколько бы мелких функций там не вызывалось. Ввиду особенностей работы, он, однако, не позволяют ответить на вопрос «сколько раз вызывалась данная функция».
В случае с google profiler есть еще несколько неприятностей:
- этот профайлер также не предназначен для работы с уже работающими программами
- последние версии не работают с fork(2), порой затрудняя его использование в демонах
Crxprof
Как и обещал, теперь про другой профайлер, который написан именно для решения обозначенной выше проблемы — легкое профилирование уже запущенных процессов.Он собирает стек вызовов и выводит наиболее «горячие» части в консоль по нажатию ENTER. Также он умеет сохранять граф вызова в упомянутом ранее формате callgrind. Работает быстро, и как любой другой сэмплирующий профайлер не зависит от сложности вызовов в профилируемой программе.
Некоторые детали работы
В основном, crxprof работает также как perftools, но использует внешнее профилирование через ptrace(2). Подобно perftools он использует libunwind для раскрутки стека, а вместо тяжелой работы по преобразованию в имена функций, вместо addr2line(1) используется libbfd.
Несколько раз в секунду программа останавливается (SIGSTOP) и с помощью libunwind «снимается» стек вызова. Загрузив при старте crxprof карту функций профилируемой программы и связанных с ней библиотек, мы можем быстро найти какой функции пренадлежит каждый отделый IP (instruction pointer).
Параллельно выстраивается граф вызова, полагая что есть некая центральная функция — точка входа. Обычно это __libc_start_main из библиотеки libc.
Несколько раз в секунду программа останавливается (SIGSTOP) и с помощью libunwind «снимается» стек вызова. Загрузив при старте crxprof карту функций профилируемой программы и связанных с ней библиотек, мы можем быстро найти какой функции пренадлежит каждый отделый IP (instruction pointer).
Параллельно выстраивается граф вызова, полагая что есть некая центральная функция — точка входа. Обычно это __libc_start_main из библиотеки libc.
Исходный код доступен на github. Т.к. утилита создавалась для меня и моих коллег, я вполне допускаю что она может не соответствовать Вашему use-case'у. Так или иначе, спрашивайте.
Соберем crxprof и посмотрим на пример его использования.
Сборка
Что необходимо: Linux (2.6+), autoconf+automake, binutils-dev (включает libbfd), libunwind-dev (у меня он называется libunwind8-dev).
Для сборки выполняем:
autoreconf -fiv ./configure make sudo make install
Если libunwind установлен в нестандартное место, используйте:
./configure --with-libunwind=/path/to/libunwind
Профилирование
Для этого просто запустите
crxprof pid
И все! Теперь используйте ENTER для вывода профайла в консоль, и ^C для завершения. Crxprof также выведет профайл и по выходу программы.
crxprof: ptrace(PTRACE_ATTACH) failed: Operation not permitted
Если вы видите эту ошибку, значит ptrace на вашей системе «залимитирован». (Ubuntu ?)
Подробней можно прочитать здесь
Если кратко, то либо пускайте с sudo, либо (лучше) выполните в консоли:
Подробней можно прочитать здесь
Если кратко, то либо пускайте с sudo, либо (лучше) выполните в консоли:
$ echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
Как все unix-утилиты, crxprof выводит usage при вызове с ключом --help. Подробную информацию см. в
man crxprof.crxprof --help
Usage: crxprof [options] pid Options are: -t|--threshold N: visualize nodes that takes at least N% of time (default: 5.0) -d|--dump FILE: save callgrind dump to given FILE -f|--freq FREQ: set profile frequency to FREQ Hz (default: 100) -m|--max-depth N: show at most N levels while visualizing (default: no limit) -r|--realtime: use realtime profile instead of CPU -h|--help: show this help --full-stack: print full stack while visualizing --print-symbols: just print funcs and addrs (and quit)
Реальный пример
Для того чтобы привести реальный, но не сложный пример я использую этот код на C. Скомпилируем, запустим его и попросим crxprof сохранить граф вызова функций (4054 — pid профилируемой программы):
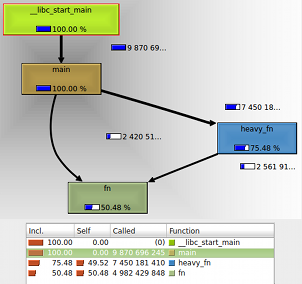
$ crxprof -d /tmp/test.calls 4054 Reading symbols (list of function) reading symbols from /home/dkrot/work/crxprof/test/a.out (exe) reading symbols from /lib/x86_64-linux-gnu/libc-2.15.so (dynlib) reading symbols from /lib/x86_64-linux-gnu/ld-2.15.so (dynlib) Attaching to process: 6704 Starting profile (interval 10ms) Press ENTER to show profile, ^C to quit 1013 snapshot interrputs got (0 dropped) main (100% | 0% self) \_ heavy_fn (75% | 49% self) \_ fn (25% | 25% self) \_ fn (24% | 24% self) Profile saved to /tmp/test.calls (Callgrind format) ^C--- Exit since ^C pressed
По выведенной на консоль статистике видно что:
- main() вызывает heavy_fn() (и это самый «тяжелый» путь)
- heavy_fn() вызывает fn()
- main() также вызывает fn() непосредственно
- heavy_fn() занимает половину времени CPU
- fn() занимает оставшееся время CPU
- main() сама по себе не потребляет ничего
Визуализация делается по схеме «наибольшие поддеревья — первыми». Таким образом, даже для больших реальных программ можно использовать простую визуализацию в консоли, что должно быть удобно на серверах.
Для визуализации сложных графов вызова удобно использовать KCachegrind:
$ kcachegrind /tmp/test.calls
Картинка, которая получилась у меня, представлена справа.
Вместо заключения, напомню что профайлером пока пользуются лишь несколько моих коллег и я сам. Надеюсь, он будет также полезен и Вам.
