 Продолжаем переводить книгу о унифицированной системе IT-мониторинга. После интриги с вопросами, автор начинает на них постепенно отвечать.
Продолжаем переводить книгу о унифицированной системе IT-мониторинга. После интриги с вопросами, автор начинает на них постепенно отвечать. Напоминаю, что эта книга не содержит готовых рецептов, ссылок на определённое ПО и детальные приемы имплементации (для этого есть большое количество книг по конкретным системам мониторинга), излагаемый здесь материал — это скорее набор приемов, которыми можно воспользоваться или, как вариант — продолжать ничего не делать.
Итак, Глава 2. О том, что предпринять, чтобы информация не была разрознена. Для тех, кто уже пользуется системами мониторинга многие вещи покажутся знакомыми.
Содержание
Глава 1. Управление вашим IT окружением: четыре вещи, которые вы делаете неправильно
Глава 2. Устранение практики управления по отдельным участкам в IT-менеджменте
Глава 3. Соединяем всё в единый цикл управления ИТ
Глава 4. Мониторинг: взгляд за пределы ЦОД
Глава 5: Превращаем проблемы в решения
Глава 6: Унифицированное управление на примерах
Глава 2. Устранение практики управления по отдельным участкам в IT-менеджменте
В предыдущей главе, я высказал мнение, что одной из самых больших проблем в современных ИТ является наш способ управления ИТ по технологически изолированным доменам: администраторы БД отвечают за серверы СУБД, админы Windows – за свои машины, администраторы VMware – отвечают за инфраструктуру виртуализации и так далее. На самом деле я не предлагаю взять и отменить существующую практику наличия узких специалистов в команде ИТ – это, на самом деле, серьёзная выгода. Однако, если каждый из этих экспертов использует свой собственный специализированный инструмент, то это создает определённые затруднения. В этой главе мы изучим некоторые из этих проблем, и посмотрим, что мы можем сделать для их решения и каким образом можно создать более эффективное, унифицированное ИТ-окружение.
Слишком много инструментов означает слишком мало решений
«Сравнение тёплого с мягким» — вот та поговорка, которая приходит на ум, когда дело доходит до наших способов измерения производительности, решения вопросов и работы с другими основными процессами в ИТ. Скажите администратору Exchange Server, что у нас тормозит почтовая система, и, с большой долей вероятности, он запустит Windows Performance Monitor, скорее всего, с заранее созданным набором счётчиков, где включены показатели полосы пропускания дисков, утилизации процессора, количество запросов RPC, и так далее, примерно так как это выглядит
Рисунок 2.1: Мониторинг сервера Exchange.
Если администратор Exchange на своём сервере ничего не найдёт, он передаст проблему кому-либо еще. Возможно, это будет администратор Active Directory, потому что служба каталогов компании Microsoft играет весьма важную роль в производительности и работоспособности сервера Exchange. Администратор Active Directory запускает свою любимую утилиту для оценки производительности, скорее всего она будет выглядеть именно так, как на рисунке 2.2. Это очень специализированный инструмент, со специальными экранами и средствами измерений, которые завязаны
Рисунок 2.2: Мониторинг состояния Active Directory.
Если и со службой каталогов всё в порядке, тогда проблема должна быть передана специалисту по сетевой инфраструктуре. Он достанет еще один инструмент, который может выглядеть как ПО управления корпоративными маршрутизаторами, с экранами оценки производительности. См. Рис 2.3.
Рисунок 2.3: Мониторинг рабтоспособности маршрутизатора Cisco.
Если подытожить, то все инструменты привели специалистов к одному и тому же выводу — всё работает отлично. И это несмотря на тот факт, что Exchange, с пользовательской точки зрения, однозначно работает ‘не отлично’, но при этом специалисты не нашли никаких свидетельств, которые бы указывали на проблему. Проще говоря, это как раз тот случай, «когда инструментов много, а ответов — мало». В современных сложных ИТ-системах, производительность – вместе с другими характеристиками, такими как доступность и масштабируемость, является результатом взаимодействия многих компонентов между собой. У вас не получится полноценно управлять ИТ, наблюдая за работой одной подсистемы; вам необходимо рассматривать работу комплексов взаимодействующих и взаимозависящих элементов.
Наша опора на специализированные инструменты не даёт полноценных ответов на существующие в ИТ вопросы. Эта зависимость начинает связывать руки когда приходит время расширять нашу систему, управлять соглашениями о уровне обслуживания (SLA) и решать другие основные задачи. Я в действительности видел ситуации, где подобный специализированный инструмент работал как лошадиные шоры: существенно суживая поле видимости, и не давая эксперту решить проблему, либо максимально быстро её идентифицировать.
Хизер является администратором БД в своей организации, Она отвечает за сервер СУБД целиком, включая ПО СУБД, операционную систему и железо, на котором это всё работает. Однажды, она получает в работу тикет, в котором пользователи жаловались на резкое снижение производительности приложения, использующего её СУБД. Она запустила свои утилиты для мониторинга, но не увидела проблемы. Процессор на сервере по большей части совершенно не нагружен, обмен с диском – в пределах нормы, потребление памяти тоже в порядке. Но она заметила, что рабочая нагрузка, которая обычно есть на сервере ниже, чем обычно. Это заронило в ней подозрение, что проблемы находятся где-то на стороне сети, так что она перевела тикет на команду, занимавшуюся инфраструктурой. Специалисты быстро вернули тикет назад, уверив её, что хотя на сети есть небольшие затыки, они все вызваны трафиком, выходящим с её сервера.
Хизер проверила всё ещё раз и увидела, что сетевой интерфейс на сервере тихо-мирно работает, но с трафиком, чуть большим, чем обычно. Начав тщательную проверку, она наконец-то поняла, что сервер регистрирует слишком большое количество ошибок контрольной суммы (CRC), и из-за этого вынужден передавать повторно слишком большое количество пакетов. А клиенты видят эту проблему как общее замедление работы системы, потому что нормальным пакетам нужно больше времени, чтобы добраться до их компьютеров.
Из-за того, что Хизер проверяла, в первую очередь те вещи, которые хорошо знала сама, это заставило её «растянуть проблему по стене» и передать её сетевым инженерам, теряя время. У неё не было привычки контролировать работу сетевого интерфейса сервера, а процедуры по оценке его работоспособности не входили в рутинную процедуру стандартных проверок при устранении проблем СУБД.
Специализированный инструмент не способствует совместной работе
Если компоненты наших сложных ИТ-систем взаимозависимы и сильно связаны, наши специалисты в ИТ области, часто выглядят как угодно, только не как профессионалы. Другими словами, такой способ управления ИТ провоцирует создание отдельных технологических доменов. Появляется группа администраторов БД, группа администраторов Active Directory, группа сетевой инфраструктуры и так далее. Даже компании, которые практикуют «матричное управление», в которых узкие специалисты распределяются по широким функциональным группам, всё ещё допускают наличие узких технологических секторов. Есть две основные причины из-за которых такие места существуют и практически каждый ИТ профессионал может их вам описать:
- «Я про это ничего не знаю». Каждый узкий специалист является экспертом в своей области технологий. Администратор БД ничего не понимает в мониторинге или управлении маршрутизаторами, да и не особенно хочет с ними работать в принципе. Экстенсивная кросс-специализация в большинстве организаций даёт незначительный эффект, потому что у персонала на это нет достаточного количества времени. Перераспределение времени на обучение дисциплинам второй и третьей специальности неизбежно приводит к уменьшению времени необходимого для выполнения обязанностей по основной работе.
- «Я не хочу, чтобы кто-то вмешивался в то, чем я занимаюсь». ИТ-профессионалы хотят делать свою работу хорошо, и понимают тот факт, что большинство проблем возникают как результат внесения изменений и очень болезненно на это реагируют. Позвольте кому-нибудь куда-нибудь бесконтрольно влезть, и вы гарантированно получите проблемы. Если кто-то что-то меняет в вашей части ИТ-окружения и вы про это ничего не знаете, то ваc уже дожидаются непростые времена в устранении проблем, связанных с посторонним вмешательством.
Оба эти довода достаточно серьёзны, и я совершенно не ратую за то, чтобы каждый специалист в ИТ-команде стал экспертом в каждой из используемых в организации технологий. Однако ряд моментов, которые отражены в этих двух утверждениях, требует небольших уточнений. Одна причина (я опять возвращаюсь к специализированному инструментарию) заключается в том, что инструменты, используемые в технологически независимых областях, провоцируют выстраивание коммуникационных барьеров и ничего не делают даже для поверхностной кооперации между ИТ-специалистами. Сотрудничество, если оно есть, возникает из хороших человеческих взаимоотношений, но даже эти отношения часто вступают в противоречие с тем фактом, что каждый специалист смотрит на свой отдельный набор данных и «играет с другого нотного листа», если так можно сказать. Я бывал в компаниях, где администраторы тратили часы, споря о том, чей же это был «сбой»; где каждый кивал на другого, демонстрируя, в качестве доказательства, данные со своих собственных технологических участков, снятые своими специализированными инструментами.
Дэн работает в своей компании администратором Active Directory и отвечает примерно за пару десятков доменных контроллеров, каждый из которых работает на виртуальной машине. Пэг отвечает за организацию инфраструктуры виртуальных серверов, а также занимается управлением физических хостов, на которых запускаются виртуальные машины.
Как-то раз, после обеда, Пэг получила звонок от Дэна. Дэн пытался разобраться с проблемой низкой производительности на некоторых доменных контроллерах и предположил, что нечто пожирает ресурсы, необходимые его контроллерам, на физическом хосте виртуализации.
Пэг открывает консоль виртуальных серверов и уверяет Дэна, что сервера не исчерпали ресурсов физических CPU или памяти, а обмен с диском вполне нормален и также находится в пределах отведённых значений.
Дэн возражает, ссылаясь на значения из его утилиты для мониторинга Active Directory, которая показывает максимальные значения загрузки CPU и памяти, а также упоминает про удлинение дисковых очередей, что говорит о том, что данные считываются и пишутся на диски с запозданием. Пэг настаивает, что с физическими серверами всё в полном порядке. Дэн спрашивает, не мог ли кто-то поменять настройки виртуальных серверов, так что им стало выделяться меньше ресурсов, но Пэг отвечает – нет.
Два администратора занимаются футболом в течение нескольких часов, оба смотрят в собственные экраны, на которых написаны совершенно разные вещи. Они не в состоянии говорить на общем технологическом языке, и у них не получается совместная работа над решением проблемы.
На самом деле нам не требуется, чтобы каждый ИТ-специалист был экспертом в любой технологии — это слабореально; но нам надо упростить процесс их взаимодействия друг с другом в таких вопросах как работоспособность, производительность, масштабируемость, доступность и так далее. Если при этом использовать непересекающийся инструментарий, индивидуальный для каждого технологического домена, то это будет трудновыполнимой задачей. Сетевому администратору совершенно не нужны средства для мониторинга серверов баз данных, равно как и администратор БД особенно не горит желанием, чтобы у человека, который занимается управлением сетевым железом, был доступ к его рабочим инструментам.
Присутствие специализированного ПО, которое относится к другой технической специализации, приводит в результате именно к тем двум сложностям, про которые я говорил ранее.
В конце концов, проблема может быть решена, если у нас есть унифицированный набор инструментов, в котором вся информация по производительности, с которой работают разные специалисты, собирается на один экран. В этом случае, все будут играть по одним и тем же правилам, и смотреть в одни и те же данные, отражающие общую картину окружения, полного внутренних зависимостей. Каждый сможет увидеть, где находится проблема, и ТОЛЬКО ПОСЛЕ ЭТОГО они могут достать свои любимые специальные инструменты и начать исправлять проблему в своих предметных областях, если есть такая необходимость.
Облачный вопрос. Унификация локального и удаленного мониторинга
Концепция консоли унифицированного мониторинга становится еще важнее, по мере того, как организации начинают перемещать всё бoльшие части своей ИТ-инфраструктуры в «облако».
В облаке нет ничего нового
Я должен признать, что я не большой любитель термина «облако». От него за милю пахнет маркетингом и рекламой, и на самом деле в нем нет ничего сверхъестественно нового. Организации выносили на аутсорсинг некоторые из своих ИТ-элементов в течение многих лет. Возможно, самым часто используемой для этого службой был веб-хостинг; либо это был вынос за пределы компании единичных веб-сайтов, развёрнутых на чьём-то оборудовании, либо колокация своих серверов в стороннем дата-центре.
Договоримся, что в нашем обсуждении, понятие «облако» будет просто ссылаться на какой-то элемент ИТ, который вынесен на аутсорсинг и скрывает свою нижележащую инфраструктуру. Например, если вы содержите на колокации ваши сервера в центре обработки данных компании, оказывающей услуги хостинга, то обычно у вас нет детальной информации о внутреннем устройстве их сети, способах подключения к Интернету, типах маршрутизаторов и так далее, ЦОД, в этом случае, предоставляет вам абстрактное нечто, за что вы платите деньги. В современной модели облачных вычислений, которую предоставляют, например, Windows Azure или Amazon Elastic Cloud, у вас нет ни малейшего понятия о том, на каких физических хостах работают ваши виртуальные машины. За абстракцию физического уровня, а также за сопутствующие элементы, такие как хранилище данных, сетевые коммуникации и т.д., вы платите деньги. При использовании услуги «ПО как сервис (SaaS)», вы даже не будете знать, какие виртуальные машины вовлечены в работу заказанного вами программного обеспечения, потому что вы платите за абстрагирование всей нижележащей инфраструктуры.
Вне зависимости от того сколько подсистем вашей инфраструктуры, больших или малых, перешло в руки провайдера облачного сервиса, эти компоненты всё ещё остаются частью вашего бизнеса. У вас по-прежнему работают критичные бизнес-приложения и процессы, которые зависят от их нормального функционирования. У вас стало меньше контроля над удалённой инфраструктурой, и меньше возможности понимать, что у них там делается внутри в конкретный момент времени.
В этом случае, специализированный инструментарий становится полностью непригоден. Несомненно, часть общей идеи аутсорсинга как раз и заключается в том, чтобы меньше беспокоиться о работе задач, которыми теперь занимаются другие люди, но выведенные за пределы компании ИТ-системы всё еще вовлечены в поддержку бизнеса, за который отвечаете лично вы. Так что вам, как минимум, надо видеть как работа элементов, вынесенных в облако, влияет на оставшуюся часть вашего окружения. А кроме того, вам нужна возможность авторитетно «ткнуть пальцем» в конкретный источник проблемы – даже если им является вынесенный на аутсорсинг элемент, и у вас нет возможности напрямую влиять на устранение сбоев. Именно здесь унифицированный мониторинг занимает своё правильное место в ИТ окружении. Например, на рис.2.4. показан очень простой «набор индикаторов (dashboard) унифицированного мониторинга», который показывает общее состояние некоторых компонентов инфраструктуры, включая некоторые компоненты, переданные на аутсорс — например, Amazon Web Services.
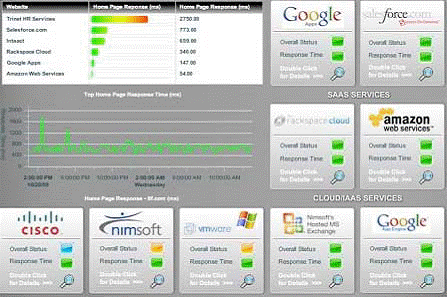
Рисунок 2.4: Набор индикаторов унифицированного мониторинга.
Идея панели индикаторов заключается в том, чтобы можно было быстро, на глаз, определить, где начинаются проблемы с работоспособностью, затем, если потребуется, быстро добраться до деталей, и либо начать исправлять проблему, если она на вашем конце облака, либо эскалировать проблему тому, кто за неё отвечает.
Пусть будет совершенно понятной одна мысль: Любая организация, которая выводит на аутсорсинг любую из частей своего ИТ-окружения, влияющую на бизнес, должна готовиться к большим неприятностям, когда рано или поздно в облаке что-то пойдёт не так. Да, конечно, у вас есть соглашения об уровне обслуживания (SLA) с вашими облачными партнёрами, но внимательно почитайте эти SLA — как правило, в них описано, что они вам возвратят вашу оплату, если условия SLA не будут выполняться, и ничего – если дело касается компенсации ущерба для бизнеса, спровоцированному невыполнением SLA. Так что максимальный контроль за вынесенной инфраструктурой находится полностью в ваших интересах.
И если вы уже выстроили такую систему, то, как только обнаруживается, что дела собираются пойти плохо, вы можете немедленно связаться с вашим партнёром по аутсорсингу и заставить кого-нибудь приступить к решению проблемы. Таким образом, отрицательное влияние на ваш бизнес будет хотя бы сведено до минимума.
Пропавшие участки
Есть еще одна проблема, проявляющаяся, когда дело доходит до мониторинга производительности, процедур управления, планирования масштабируемости и так далее, и называется она – «пропавшие участки». Наш подход к ИТ, сконцентрированный исключительно на технологиях, приводит к очень близорукому взгляду на наше окружение. Например, давайте посмотрим на схему на рис.2.5. Это типичная (если не упрощенная) схема, которую каждый администратор ИТ рисует, когда ему требуется видеть структуру компонентов отдельного приложения.
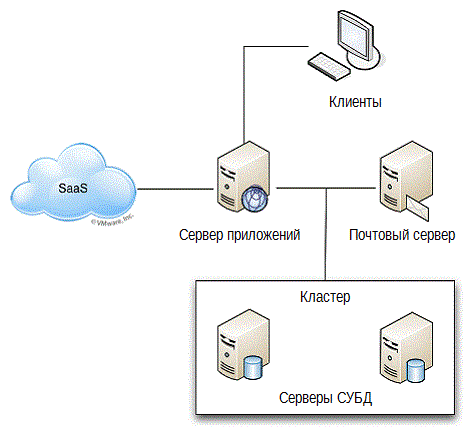
Рисунок 2.5: Структура приложения.
Проблема в том, что в этой картине есть явно пропавшие участки. Где инфраструктура, например? Тот, кто эту картинку рисовал, похоже, не имел дела с инфраструктурой: коммутаторы, маршрутизаторы и прочее — ничего из этого не включено. Подразумевается, что она есть, точно так же как некоторые компоненты, вынесенные в облако. Возможно, рисунок 2.6 будет более точным отображением нашего окружения.
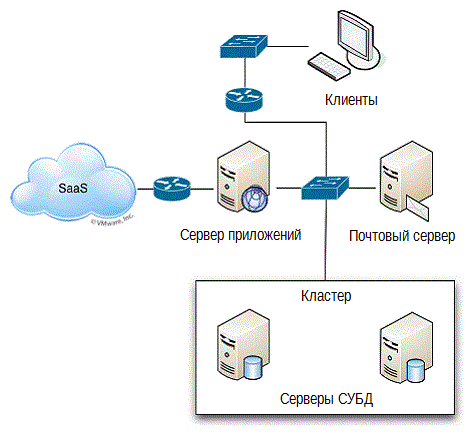
Рисунок 2.6: Детальная схема приложения.
Но даже и на этой схеме, скорее всего, чего-то не хватает (например, системы управления бесперебойным электропитанием — пр.перев.). Такова реальность, и возможно она является одной из самых больших опасностей, существующих в ИТ сегодня: из нашего внимания выпадают определенные части окружения, лежащие за пределами нашего обыденного понимания.
И опять унифицированный мониторинг может дать преимущество. Вместо того, чтобы фокусироваться только на одной технологической части – например, серверах; он может быть технологически независим и собирать информацию отовсюду.
На самом деле, еще лучше, если системы унифицированного мониторинга будут в состоянии самостоятельно искать новые компоненты в вашем окружении. Программному обеспечению не надо руководствоваться теми же предположениями и испытывать те же технологические предрассудки, что и человеку. Унифицированной консоли, в общем-то, без разницы кто вы — специалист по Hyper-V, или вы предпочитаете маршрутизаторы Cisco другим брендам. Она воспринимает действительность такой, какая она есть, ищет различные компоненты и создает точную и полную диаграмму окружения. Затем система может начать мониторинг этих компонентов (возможно запрашивая у вас логины и пароли для доступа в каждый отдельный компонент, в случае необходимости), и позволяет вам создать исчерпывающие, унифицированные панели индикаторов. Я сталкивался с инфраструктурами, где отсутствие функции автопоиска иногда становилось проблемой:
Тэрри отвечает за инфраструктурные компоненты, благодаря которым работают основные бизнес-приложения. Компоненты – это маршрутизаторы, коммутаторы, серверы СУБД, серверы виртуализации, почтовые серверы и даже вынесенный на аутсорсинг в качестве SaaS приложение для управления продажами. Тэрри слышал о системе унифицированного мониторинга, и его компания даже инвестировала в сервис, который обеспечивает унифицированный мониторинг окружения. Тэрри аккуратно сконфигурировал каждый компонент, и всё что было показалось на консоли мониторинга в виде индикаторов.
В один прекрасный день, одно из приложений полностью прекратило работу. Тэрри добрался до консоли мониторинга и увидел несколько индикаторов показывавших 'тревогу'. Он быстро увидел, что недоступен канал до приложения, находящегося в облаке. Просматривая состояние индикаторов инфраструктуры дальше, он увидел, что роутер, через который проходило это соединение, работает прекрасно и состояние брандмауэра также в норме. Тэрри пришел в полное замешательство.
Несколько часов ручной работы и отслеживания кабелей раскрыло о структуре окружения кое-что, о чем Тэрри не догадывался: с другой стороны брандмауэра находился неисправный роутер. Связь с Интернетом была полностью работоспособна, потому что она шла через другой канал, а соединение, через которое шла связь с бизнес-приложением не работало. Этот «экстра»-маршрутизатор был старым, доставшимся по наследству устройством, про которое все давно забыли.
Решение для мониторинга, у которого есть функция автообнаружения, ничего бы «не забыло». Оно бы сумело найти этот лишний роутер и добавило бы его на панель индикаторов, что, вне всякого сомнения, позволило бы Тэрри существенно быстрее изолировать проблему.
Автообнаружение таже может помочь идентифицировать компоненты, которые находятся за пределами наших технологических доменов и, вообще, ни к чему не относятся. Инфраструктурные компоненты типа маршрутизаторов и коммутаторов – наиболее часто используемые примеры «осиротевших» элементов, потому что не в каждой организации есть выделенный специалист, занимающийся поддержкой этих устройств. Однако, есть еще унаследованные приложения и серверы, специализированное оборудование и другие компоненты, которые легко просмотреть, если они не находятся ни в чьей зоне ответственности. Автообнаружение позволяет избежать такие пропуски.
Не всё в ИТ является проблемой: заказы, маршрутизация и обеспечение сервисов.
Большинство организаций склонно иметь привычку воспринимать ИТ-департамент как «пожарную команду», ведь с их точки зрения ИТ существует для решения проблем. Конечно же, это не так и каждая организация возможно куда как больше зависит от ИТ при выполнении своих повседневных задач и требует от ИТ-службы не только аварийного решения проблем. Но рутинная работа не настолько бросается в глаза, в то время как «тушение пожаров» привлекает всеобщее внимание.
В результате такого отношения, ИТ-менеджмент старается, в первую очередь, использовать инструменты, которые позволяют легче устранять последствия серьезных инцидентов. Системы унифицированного мониторинга хорошо сюда вписываются. С другой стороны, если до сих пор ничего такого не происходило, то они нам, вроде бы, и не требуются. Они нужны для того, чтобы быстрее решать проблемы, как раз в области работоспособности и доступности. Правильно?
Не совсем. Действительно унифицированный менеджмент также влечет за собой облегчение выполнения ежедневных задач для всех участников ИТ-процессов.
Пользователям, например, необходимо заказывать и получать рутинные ежедневные сервисы, начиная от простого сброса пароля и разблокировки пользовательского аккаунта, до запросов нового оборудования и ПО.
Бьюсь об заклад, что кто-нибудь посчитает это смелым заявлением и скажет, что эти рутинные запросы должны обрабатываться точно так же как и проблемы. Посмотрите на любой фреймворк для ИТ, такой например, как ITIL, и вы увидите как через него это проходит красной нитью: Рутинные ИТ процедуры должны быть частью унифицированного процесса управления, который также включает в себя решение проблем.
Рассмотрим некоторые из широких функциональных возможностей, которые унифицированный менеджмент (в отличие от просто «мониторинга») может предложить для работ, связанных с решением проблем и выполнением рутинных ИТ-сервисов:
- Поcледовательность работ (workflow) – когда проблемы возникают, их необходимо направлять в структурированный процесс или последовательность работ. Это поможет сделать решение проблем более эффективным с обязательным прохождением по цепочке обязательных шагов. Последовательности работ будут различными для решения проблем и различных рутинных сервисов, но наличие возможности управлять и отслеживать потоки работ может быть реальной выгодой.
- Согласования. Потоки работ должны включать согласования. Эта возможность наиболее очевидна для рутинных сервисов таких, как запросы на изменение программного и аппаратного обеспечения, запросы на выполнение процедур безопасности и так далее, причем это может быть столь же важно, как и решение проблем. Не каждая задача может быть решена сменой настроек и перезагрузкой устройства; иногда вам потребуется делать более масштабные изменения, и иметь возможность формально проходить маршрут согласования, чтобы удостовериться, что в результате данных изменений будет польза.
- Маршрутизация запросов. Специалист, который занимается устранением проблемы, обычно является последним человеком, который о ней слышит. Те, кто находится на первой линии – ваш хелп-деск и конечные пользователи, являются первыми людьми, кто на неё «реагирует». Им важно иметь возможность выбирать категорию проблем и направлять тикет правильному специалисту, что существенно ускоряет решение проблемы. То же самое является и справедливым для обычных запросов: Процессы начинаются выполняться быстрее, если они направлены в нужное русло. Автоматизированные возможности маршрутизации запросов помогают быстрее привлекать в работу нужных специалистов.
- Самообслуживание. В достижении общей эффективности важным является уменьшение количества телефонных звонков и рукописных е-мейлов. Самообслуживание может помочь как в решении проблем, так и в выполнении обычных запросов. Когда у пользователей возникают вопросы, самообслуживание может помочь им инициировать тикеты и даже решать проблемы самостоятельно, посредством базы знаний. Когда пользователям необходимо выполнение рутинных сервисов, самообслуживание поможет им создать запрос без привлечения на этом этапе дополнительных специалистов или ИТ-сервисов.
- Каталог сервисов. Частью системы самообслуживания является возможность создавать «онлайновое хранилище» для сервисов, которые пользователь может запрашивать.
Конечно, есть и другие функциональные возможности, и мы рассмотрим их далее. Перечислены базовые характеристики, которые нам нужны для того, чтобы большинство рутинных ИТ запросов и решений проблем отрабатывались более эффективно и последовательно.
В следующей серии…
В данной главе мы говорили о том, как стереть границы между технологическими доменами и специалистами, и если это не выполнимо полностью, то хотя бы пробить бреши между ними, что помогает в решении одной из главных проблем в современном мониторинге и управлении ИТ.
Эта глава о том, как стереть границы между технологическими доменами и специалистами, либо о том, как хотя бы наладить проходы между ними. Это помогает в решении одной из главных проблем в современном мониторинге и управлении ИТ.
Следующая глава будет посвящена более сложной теме: как вовлечь всех заинтересованных лиц в единый управленческий цикл. Речь пойдёт об улучшении коммуникаций. К несчастью, коммуникации слишком часто являются необязательным и вторичным занятием – нам приходится делать над собой усилие, чтобы ими заниматься, но когда над нами начинает довлеть обстановка, то мы очень легко начинаем прикладывать эти усилия везде, где можно. Так что нам необходимо адаптировать наши процессы и инструменты, чтобы коммуникации были более «автоматизированными», и помогали нам вовлекать в управленческий процесс каждого сотрудника без прикладывания к этому больших дополнительных усилий.
Перейти к Главе 1
Перейти к Главе 3
