 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.Что происходит внутри процессора? Сколько времени уходит на исполнение одной инструкции? Что значит, когда новый процессор имеет 12, или 18, или даже 31-уровневый конвейер?
Программы обычно работают с процессором, как с чёрным ящиком. Инструкции входят и выходят из него по порядку, а внутри совершается некая вычислительная магия.
Программисту полезно знать, что происходит внутри этого ящика, особенно, если он будет заниматься оптимизацией программ. Если вы не знаете какие процессы протекают внутри процессора, как вы сможете оптимизировать под него?
Эта статья рассказывает, как устроен вычислительный конвейер x86 процессора.
Вещи, которые вы уже должны знать
Во-первых, предполагается, что вы немного разбираетесь в программировании или может даже немного знаете ассемблер. Если вы не понимаете, что я имею ввиду, когда использую термин «указатель на инструкцию» (instruction pointer), тогда, возможно, эта статья не для вас. Когда я пишу о регистрах, инструкциях и кэшах, я предполагаю, что вы уже знаете, что это значит, можете понять или нагуглить.
Во-вторых, эта статья – упрощение сложной темы. Если вам кажется, что я пропустил какие-то важные моменты, добро пожаловать в комментарии.
В-третьих, я акцентирую внимание только на процессорах Intel x86 семейства. Я знаю о существовании других семейств процессоров, кроме x86. Я знаю, что AMD внесло много полезных нововведений в x86 семейство, и Intel их приняло. Но архитектура и набор инструкций принадлежит Intel, также Intel представило реализацию самых главных особенностей семейства, так что для простоты и логичности, речь пойдет именно об их процессорах.
В-четвертых, эта статья уже устарела. В разработке более новые процессоры, и некоторые из них уже скоро ожидаются в продаже. Я очень рад, что технологии развиваются такими быстрыми темпами и надеюсь, что когда-нибудь все стадии, описанные ниже, полностью устареют и будут заменены еще более удивительными достижениями в процессоростроении.
Основы вычислительного конвейера
Если посмотреть на x86 семейство в целом, то можно заметить, что оно не сильно изменилось за 35 лет. Было много дополнений, но оригинальный дизайн, как и почти весь набор команд, в основном остались нетронутыми и до сих пор прослеживаются в современных процессорах.
Первоначальный 8086 процессор имеет 14 регистров, которые используются до сих пор. Четыре регистра общего назначения – AX, BX, CX и DX. Четыре сегментных регистра, которые используют для облегчения работы с указателями – CS (Code Segment), DS (Data Segment), ES (Extra Segment) и SS (Stack Segment). Четыре индексных регистра, которые указывают на различные адреса в памяти – SI (Source Index), DI (Destination Index), BP (Base Pointer) и SP (Stack Pointer). Один регистр содержит битовые флаги. И, наконец, самый главный регистр в этой статье – IP (Instruction Pointer).
IP регистр – это указатель с особой функцией, его задача указывать на следующую инструкцию, которая подлежит исполнению.
Все процессоры в x86 семействе следуют одному и тому же принципу. Сначала они следуют указателю на инструкцию и декодируют следующую команду по этому адресу. После декодирования следует этап выполнения этой инструкции. Некоторые инструкции читают из памяти или пишут в нее, другие производят вычисления, сравнения или другую работу. Когда работа окончена, команда проходит через этап отставки (retire stage) и IP начинает указывать на следующую инструкцию.
Этот принцип декодирования, выполнения и отставки одинаково применяется как в первом 8086 процессоре, так и в самом последнем Core i7. С течением времени были добавлены новые этапы конвейера, но принцип работы остался прежним.
Что изменилось за 35 лет
Первые процессоры были просты по сегодняшним меркам. 8086 процессор начинал с проверки команды на текущем указателе на инструкцию, декодировал ее, выполнял, отставлял и продолжал работу со следующей инструкцией на которую указывал IP.
Каждый новый чип в семействе добавлял новую функциональность. Большинство добавляло новые инструкции, некоторые добавляли новые регистры. Чтобы оставаться в рамках этой статьи, я буду уделять внимание изменениям, которые непосредственно касаются прохождения команд через ЦП. Другие изменения, такие как добавление виртуальной памяти или параллельной обработки, конечно же интересны, но выходят за рамки данной статьи.
В 1982 был введён кэш инструкций. Вместо обращения к памяти на каждой команде, процессор читал на несколько байт дальше текущего IP. Кэш инструкций был всего несколько байт в размере, достаточным для хранения лишь нескольких команд, но ощутимо увеличивал производительность, исключая постоянные обращения к памяти каждые несколько тактов.
В 1985 в 386 процессор был добавлен кэш данных и увеличен размер кэша инструкций. Этот шаг позволил увеличить производительность за счет чтения на несколько байт дальше запроса на данные. На тот момент кэши данных и инструкций измерялись в килобайтах, нежели в байтах.
В 1989 i486 процессор перешел на 5-уровневый конвейер. Вместо наличия одной инструкции во всем процессоре, теперь каждый уровень конвейера мог иметь по инструкции. Это нововведение позволило увеличить производительность более чем в два раза по сравнению с 386 процессором на той частоте. Этап загрузки (fetch stage) извлекал команду из кэша инструкций (размер кэша в то время был обычно 8кб). Второй этап декодировал инструкцию. Третий этап транслировал адреса памяти и смещения, необходимые для команды. Четвёртый этап выполнял инструкцию. Пятый этап отправлял команду в отставку и записывал результаты обратно в регистры и память по мере необходимости. Появление возможности держать в процессоре множество инструкций одновременно позволило программам выполняться гораздо быстрее.
1993 год был годом появления процессора Pentium. Название семейства процессоров сменилось с номеров на имена из-за судебного процесса, поэтому оно было названо Pentium вместо 586. Конвейер чипа изменился еще больше по сравнению с i486. Архитектура Pentium добавила второй отдельный суперскалярный конвейер. Основной конвейер работал также, как и на i486, в то время как второй выполнял более простые инструкции, такие как целочисленная арифметика, параллельно и намного быстрее.
В 1995 Intel выпустило процессор Pentium Pro, который имел кардинальные изменения в дизайне. У чипа появилось несколько особенностей, включая ядро с внеочерёдным (Out-of-Order, OOO) и упреждающим (Speculative) исполнением команд. Конвейер был расширен до 12 этапов, и в него вошло нечто, называемое суперконвейером (superpipeline), где большое количество инструкций могло исполняться одновременно. OOO ядро будет более подробно освещено ниже в статье.
Между 1995 годом, когда OOO ядро было представлено, и 2002 было сделано много важных изменений. Были добавлены дополнительные регистры и представлены инструкции, которые могли обрабатывать множество данных за раз (Single Instruction Multiple Data, SIMD). Появились новые кэши, старые увеличились в размере. Этапы конвейера делились и объединялись, адаптируясь к требованиям реального мира. Эти и многие другие изменения были важны для общей производительности, но мало что значили, когда речь шла о потоке данных через процессор.
В 2002 Pentium 4 представил новую технологию — Hyper-Threading. OOO ядро было настолько успешным в обработке команд, что способно было обрабатывать инструкции быстрее, чем они могли быть посланы ядру. Для большинства пользователей OOO ядро процессора практически бездействовало большую часть времени даже под нагрузкой. Для обеспечения постоянного потока инструкций к OOO ядру добавили второй фронт-энд. Операционная система видела два процессора вместо одного. Процессор содержал два набора x86 регистров, два декодера инструкций, которые следили за двумя наборами IP и обрабатывали два набора инструкций. Далее команды обрабатывались одним общим OOO ядром, но это было незаметно для программ. Потом инструкции проходили этап отставки, как и ранее, и посылались назад к виртуальным процессорам, на которые они поступали.
В 2006 Intel выпустило микроархитектуру Core. В маркетинговых целях она была названа Core 2 (потому что каждый знает, что два лучше, чем один). Неожиданным ходом было снижение частоты процессоров и отказ от Hyper-Threading. Снижение частот способствовало расширению всех этапов вычислительного конвейера. OOO ядро было расширено, кэши и буферы были увеличены. Архитектура процессоров была переработана с уклоном на двух- и четырёхъядерные чипы с общими кэшами.
В 2008 Intel ввело схему именования процессоров Core i3, Core i5 и Core i7. В этих процессорах вновь появился Hyper-Threading с общим OOO ядром, и отличались они, в основном, лишь размерами кэшей.
Будущие процессоры: Следующее обновление микроархитектуры, названной Haswell, по слухам, будет выпущено во второй половине 2013. Опубликованные на данный момент документы говорят о том, что это будет 14-уровневый конвейер, и, скорей всего, принцип обработки информации будет все также следовать дизайну Pentium Pro.
Так что же такое этот вычислительный конвейер, что такое OOO ядро и как это все увеличивает скорость обработки?
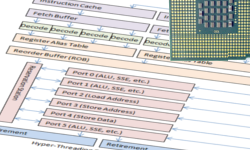
Вычислительный конвейер процессора
В самом простой форме, описанной выше, одиночная инструкция входит в процессор, обрабатывается и выходит с другой стороны. Это довольно интуитивно для большинства программистов.
Процессор i486 имел 5-уровневый конвейер – загрузка (Fetch), основное декодирование (D1), вторичное декодирование или трансляция (D2), выполнение (EX), запись результата в регистры и память (WB). Каждый этап конвейера мог содержать по инструкции.

Конвейер i486 и пять инструкций, проходящие через него одновременно.
Однако такая схема имела серьезный недостаток. Представьте себе код ниже. До прихода конвейера следующие три строки кода были распространенным способом поменять значения двух переменных без использования третьей.
XOR a, b XOR b, a XOR a, b
Чипы, начиная с 8086 и до 386 не имели внутреннего конвейера. Они обрабатывали только одну инструкцию в каждый момент времени, независимо и полностью. Три последовательных XOR инструкции в такой архитектуре вовсе не проблема.
Теперь подумаем, что происходит с i486, так как это был первый x86 чип с конвейером. Наблюдать за многими вещами в движении одновременно может быть затруднительно, поэтому, возможно, вы сочтёте полезным обратиться к диаграмме выше.
Первая инструкция входит в этап загрузки, на этом первый шаг закончен. Следующий шаг – первая инструкция входит в D1 этап, вторая инструкция помещается в этап загрузки. Третий шаг – первая инструкция двигается в D2 этап, вторая в D1 и третья загружается в Fetch. На следующем шагу что-то идет не так – первая инструкция переходит в EX..., но остальные остаются на месте. Декодер останавливается, потому что вторая XOR команда требует результат первой. Переменная «a» должна быть использована во второй инструкции, но в неё не будет произведена запись, пока не выполнилась первая инструкция. Поэтому команды в конвейере ждут, пока первая команда не пройдет EX и WB этапы. Только после этого вторая инструкция может продолжить свой путь по конвейеру. Третья команда аналогично застрянет в ожидании выполнения второй команды.
Такое явление называется ступор конвейера (pipeline stall) или конвейерный пузырь (pipeline bubble).
Другой проблемой конвейеров является возможность одних инструкций выполняться очень быстро, а других очень медленно, что было более заметно с двойным конвейером Pentium.
Pentium Pro представил с собой 12-уровневый конвейер. Когда это число было впервые озвучено, то понимавшие как работал суперскалярный конвейер программисты затаили дыхание. Если бы Intel последовало такому же принципу с 12-уровневым конвейером, то любой ступор конвейера или медленная инструкция серьезно бы сказывались на производительности. Но в то же время Intel анонсировало кардинально отличающийся конвейер, названный ядром с внеочерёдным исполнением (OOO core). Несмотря на то, что это трудно было понять из документации, Intel заверило разработчиков, что они будут потрясены результатами.
Давайте разберем OOO ядро более детально.
OOO конвейер
В случае с OOO ядром, иллюстрация стоит тысячи слов. Так что давайте посмотрим несколько картинок.
Диаграмы конвейеров процессора
5-уровневый конвейер i486 работал замечательно. Эта идея была довольно распространена среди других семейств процессоров в то время и работала отлично в реальных условиях.
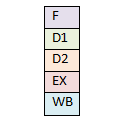
Суперскалярный конвейер i486.
Конвейер Pentium был даже еще лучше i486. Он имел два вычислительных конвейера, которые могли работать параллельно, и каждый из них мог содержать множество инструкций на различных этапах, позволяя вам обрабатывать почти в двое больше инструкций за то же время.
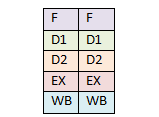
Два параллельных суперскалярных конвейера Pentium.
Однако наличие быстрых команд, ожидающих выполнение медленных, было все также проблемой в параллельных конвейерах, как и наличие последовательных команд (привет ступор). Конвейеры были все так же линейными и могли сталкиваться с непреодолимыми ограничениями производительности.
Дизайн OOO ядра сильно отличался от предыдущих чипов с линейными путями. Сложность конвейера возросла, и были введены нелинейные пути.
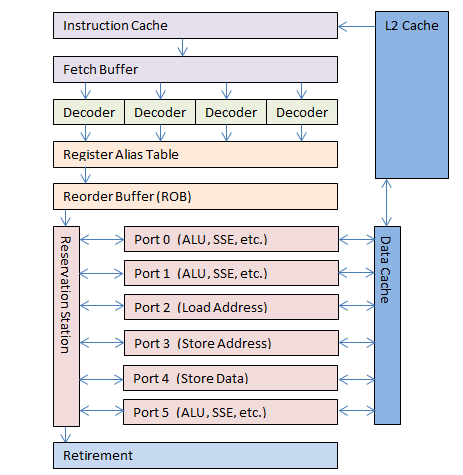
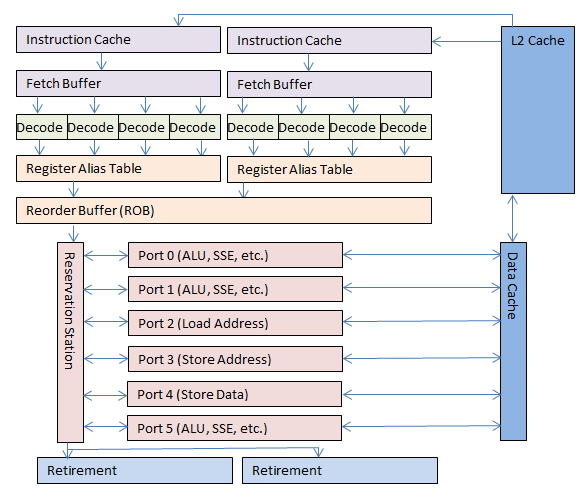
OOO ядро, используемое с 1995 года. Цветовое обозначение соответствует пяти этапам, используемых в предыдущих процессорах. Некоторые этапы и буферы не показаны, так как варьируются от процессора к процессору.
Сначала инструкции загружаются из памяти и помещаются в кэш инструкций процессора. Декодер современного процессора может предсказать появление скорого ветвления (например вызов функции) и начать загрузку инструкций заранее.
Этап декодирования был немного изменен по сравнению с более ранними чипами. Вместо обработки лишь одной инструкции на IP, Pentium Pro мог декодировать до трех инструкций за такт. Сегодняшние процессоры (2008-2013) могут декодировать до четырёх инструкций за такт. Результатом декодирования являются микрооперации (micro-ops / µ-ops).
Следующий этап (или группа этапов) состоит из трансляции микроопераций (micro-op transaltion) и последующего присвоения псевдонимов регистрам (register aliasing). Множество операций выполняются одновременно, возможно внеочерёдно, поэтому одна инструкция может читать из регистра, пока другая в него пишет. Запись в регистр может подавить значение, нужное другой инструкции. Оригинальные регистры внутри процессора (AX, BX, CX, DX итд.) транслируются (или создаются псевдонимы) во внутренние, скрытые от программиста регистры. Значение регистров и адресов памяти затем должны быть привязаны к временным значениям для обработки. На данный момент 4 микрооперации могут проходить через этап трансляции за такт.
После трансляции все микрооперации входят в буфер переупорядочивания (reorder buffer, ROB). На данный момент этот буфер может вмещать до 128 микроопераций. На процессорах с HT ROB также может выступать в роли координатора входных команд с виртуальных процессоров, распределяя два потока команд на одно OOO ядро.
Теперь микрооперации готовы для обработки и помещаются в резервацию (reservation station, RS). RS на данный момент может вмещать 36 микроопераций в любой момент времени.
Теперь настало время для магии OOO ядра. Микрооперации обрабатываются одновременно на множестве исполнительных блоков (execution unit), причем каждый блок работает максимально быстро. Микрооперации могут обрабатываться внеочерёдно, если все нужные данные для этого уже доступны. Если данные недоступны, выполнение откладывается до их готовности, пока выполняются другие готовые микрооперации. Таким образом долгие операции не блокируют быстрые и последствия ступора конвейера уже не так печальны.
OOO ядро Pentium Pro имело шесть исполнительных блоков: два для работы с целыми числами, один для чисел с плавающей точкой, загрузочный блок, блок сохранения адресов и блок сохранения данных. Два целочисленных блока были специализированы, один мог работать со сложными операциями, другой мог обрабатывать две простые операции за раз. В идеальных условиях исполнительные блоки Pentium Pro могли обрабатывать семь микроопераций за такт.
Сегодняшнее OOO ядро также содержит шесть исполнительных блоков. Оно до сих пор содержит блоки загрузки адреса, сохранения адреса и сохранения данных. Однако остальные три немного изменились. Каждый из трех блоков теперь может выполнять простые математические операции или более сложную микрооперацию. Каждый из трех блоков специализирован для конкретных микроопераций, позволяя выполнять работу быстрее, по сравнению с блоками общего назначения. В идеальных условиях нынешнее OOO ядро может обрабатывать 11 микроопераций за такт.
Наконец микрооперация начинает выполняться. Она проходит через более мелкие этапы (отличающиеся между процессорами) и проходит этап отставки. В этот момент микрооперация возвращается во внешний мир и IP начинает указывать на следующую инструкцию. С точки зрения программы, инструкция просто входит в процессор и выходит с другой стороны, точно так же, как это было со старым 8086.
Если вы внимательно читали статью, вы возможно могли заметить очень важную проблему в описании выше. Что произойдет в случае смены места исполнения? Например, что произойдет, если код доходит до if или switch конструкции? В более старых процессорах это значило сброс всей работы в суперскалярном конвейере и ожидание начала обработки новой ветки исполнения.
Ступор конвейера, когда в процессоре находится сотня или более инструкций очень серьезно сказывается на производительности. Каждая инструкция вынуждена ждать, пока инструкции с нового адреса будут загружены и конвейер будет перезапущен. В этой ситуации OOO ядро должно отменить всю текущую работу, откатиться до предыдущего состояния, подождать, пока все микрооперации пройдут отставку, отбросить их вместе с результатами и затем продолжить работу по новому адресу. Эта проблема была очень серьёзной и часто случалась при проектировании. Показатели производительности в такой ситуации были неприемлемы для инженеров. Именно здесь приходит на помощь еще одна важная особенность OOO ядра.
Их ответ был – упреждающее выполнение. Упреждающее выполнение означает, что когда OOO ядро встречает в коде условные конструкции (например if блок), оно просто загрузит и выполнит две ветки кода. Как только ядро понимает, какая ветка верная, результаты второй будут сброшены. Это предотвращает ступор конвейера ценой незначительных издержек на запуск кода в неверной ветке. Также был добавлен кэш для предсказания ветвления (branch prediction cache), который намного улучшил результаты в ситуациях, когда ядро было вынуждено прогнозировать среди множества условных переходов. Ступоры конвейера до сих пор встречаются из-за ветвления, однако это решение позволило сделать их редким исключением, нежели обычным явлением.
Ну и наконец, процессор с HT предоставляет два виртуальных процессора для одного общего OOO ядра. Они разделяют общий ROB и OOO ядро и будут видны для операционной системы как два отдельных процессора. Это выглядит примерно так:
OOO ядро с Hyper-Threading, см. примечание.
Процессор с HT получает два виртуальных процессора, которые взамен поставляют больше данных OOO ядру, что дает увеличение производительности при обычном пользовании. Лишь некоторые тяжелые вычислительные нагрузки, оптимизированные под многопроцессорные системы, могут полностью загрузить OOO ядро. В этом случае HT может несколько понизить производительность. Однако такие нагрузки относительно редки. Для потребителя HT обычно позволяет увеличивать скорость работы примерно вдвое при обычном ежедневном пользовании компьютером.
Пример
Всё это может показаться немного запутанным. Надеюсь, пример расставит всё на свои места.
С точки зрения приложения, мы все ещё работаем на вычислительном конвейере старого 8086. Это чёрный ящик. Инструкция, на которую указывает IP, обрабатывается этим ящиком, и, когда инструкция выходит из него, результаты уже отображены в памяти.
Хотя с точки зрения инструкции, этот чёрный ящик то ещё приключение.
Ниже приводится путь, который совершает инструкция в современном процессоре (2008-2013).
Поехали, вы – инструкция в программе, и эта программа запускается.
Вы терпеливо ждете, пока IP начнет указывать на вас для последующей обработки. Когда IP указывает примерно за 4кб до вашего расположения, или за 1500 инструкций, вы перемещаетесь в кэш инструкций. Загрузка в кэш занимает некоторое время, но это не страшно, так как вы ещё нескоро будете запущены. Эта предзагрузка (prefetch) является частью первого этапа конвейера.
Тем временем IP указывает всё ближе и ближе к вам, и, когда он начинает указывать за 24 инструкции до вас, вы и пять соседних команд отправляетесь в очередь инструкций (instruction queue).
Этот процессор имеет четыре декодера, которые могут вмещать одну сложную команду и до трёх простых. Так случилось, что вы сложная инструкция и были декодированы в четыре микрооперации.
Декодирование – это многоуровневый процесс. Часть декодирования включает в себя анализ на предмет требуемых вами данных и вероятность перехода в какое-то новое место. Декодер зафиксировал потребность в дополнительных данных. Без вашего участия, где-то на другом конце компьютера, нужные вам данные начинают загрузку в кэш данных.
Ваши четыре микрооперации подходят к таблице псевдонимов регистров. Вы объявляете с какого адреса памяти вы читаете (это оказывается fs:[eax+18h]), и чип транслирует его во временный адрес для ваших микроопераций. Ваши микрооперации входят в ROB, откуда, при первой же возможности, двигаются в резервацию.
Резервация содержит инструкции, готовые к исполнению. Ваша третья микрооперация немедленно подхватывается пятым портом исполнения. Вам не известно, почему она была выбрана первой, но её уже нет. Через несколько тактов ваша первая микрооперация устремляется во второй порт, блок загрузки адресов. Оставшиеся микрооперации ждут, пока различные порты подхватывают другие микрооперации. Они ждут, пока второй порт загружает данные из кэша данных во временные слоты памяти.
Долго ждут…
Очень долго ждут…
Другие инструкции приходят и уходят, в то время как ваши микрооперации ждут своего друга, пока тот загружает нужные данные. Хорошо, что этот процессор знает как обрабатывать их внеочерёдно.
Внезапно, обе оставшиеся микрооперации подхватываются нулевым и первым портом, должно быть загрузка данных завершена. Все микрооперации запущены и со временем они вновь встречаются в резервации.
По пути обратно через ворота, микрооперации передают свои билеты с временными адресами. Микрооперации собираются и объединяются, и вы вновь, как инструкция, чувствуете себя единым целым. Процессор вручает вам ваш результат и вежливо направляет к выходу.
Через дверь с пометкой “Отставка” стоит короткая очередь. вы встаете в очередь и обнаруживаете, что вы стоите за той же инструкцией, за которой и заходили. Вы даже стоите в том же порядке. Получается, что OOO ядро действительно знает своё дело.
Со стороны выглядит так, что каждая выходящая из процессора команда выходит по одной, точно в таком же порядке, в каком IP указывал на них.
Заключение
Надеюсь, что эта маленькая лекция пролила немного света на то, что происходит внутри процессора. Как видите, здесь нет магии, дыма и зеркал.
Теперь мы можем ответить на вопросы, заданные в начале статьи.
Так что же происходит внутри процессора? Это сложный мир, где инструкции разбиваются на микрооперации, обрабатываются при первой же возможности и в любом порядке, и вновь собираются воедино, сохраняя свой порядок и расположение. Для внешнего мира выглядит так, будто они обрабатываются последовательно и независимо друг от друга. Но мы теперь знаем, что на самом деле, они обрабатываются внеочерёдно, иногда даже предсказывая и запуская вероятные ветки кода.
Сколько времени уходит на исполнение одной инструкции? Тогда как в бесконвейерном мире для этого имелся хороший ответ, в современном же процессоре всё зависит от того какие инструкции находятся рядом, какой размер соседних кэшей и что в них находится. Есть минимальное время прохождения команды через процессор, но эта величина практически постоянна. Хороший программист или оптимизирующий компилятор может заставить множество инструкций исполняться за среднее время близкое к нулю. Среднее время близкое к нулю – это не время исполнения самой медленной инструкции, а время, требуемое для прохождения инструкции через OOO ядро и время, требуемое кэшу для загрузки и выгрузки данных.
Что значит, когда новый процессор имеет 12, или 18, или даже 31-уровневый конвейер? Это значит, что больше инструкций за раз могут быть приглашены на вечеринку. Очень длинный конвейер может значить, что несколько сотен инструкций могут быть помечены как “обрабатываются” за раз. Когда все идет по плану, OOO ядро постоянно загружено и пропускная способность процессора просто впечатляет. К сожалению, это так же значит, что ступор конвейера перерастает из мелкой неприятности, как это было раньше, в кошмар, так как сотни команд будут вынуждены ожидать очистки конвейера.
Как вы можете применить эти знания в своих программах? Хорошие новости – процессор может предугадать большинство распространённых шаблонов кода, и компиляторы оптимизируют код для OOO ядра уже почти два десятилетия. Процессор лучше всего работает с упорядоченными инструкциями и данными. Всегда пишите простой код. Простой и не извилистый код поможет оптимизатору компилятора найти и ускорить результаты. Если возможно, не создавайте переходы по коду. Если вам необходимо совершать переходы, пытайтесь делать это, следуя определенному шаблону. Сложные дизайны, наподобие динамических таблиц переходов, выглядят классно и многое могут, но ни компилятор, ни процессор, не смогут спрогнозировать какой кусок кода будет выполняться в следующий момент времени. Поэтому сложный код с большой вероятностью будет провоцировать ступоры и неверные предсказания ветвления. Напротив, поддерживайте ваши данные простыми. Организуйте данные упорядоченно, связанно и последовательно для предотвращения ступоров. Правильный выбор структуры и разметки данных может заметно сказаться на повышении производительности. До тех пор, пока ваши данные и код остаются простыми, вы обычно можете положиться на работу оптимизирующего компилятора.
Спасибо, что были частью этого путешествия.
Оригинал — www.gamedev.net/page/resources/_/technical/general-programming/a-journey-through-the-cpu-pipeline-r3115
