
Введение
Данная статья является продолжением цикла статей: Использование паттерна синглтон [1], Синглтон и время жизни объекта [2], Обращение зависимостей и порождающие шаблоны проектирования [3], Реализация синглтона в многопоточном приложении [4]. Сейчас я хотел бы поговорить о многопоточности. Эта тема настолько объемна и многогранна, что охватить ее всю не представляется возможным. Здесь я заострю внимание на некоторых практичных вещах, которые позволят вообще не думать о многопоточности, ну или думать о ней в крайне минимальном объеме. Если говорить точнее, то думать о ней только на этапе проектирования, но не реализации. Т.е. будут рассмотрены вопросы о том, как сделать так, чтобы автоматически вызывались правильные конструкции без головной боли. Такой подход, в свою очередь, позволяет значительно уменьшить проблемы, вызванные состояниями гонок (race condition, см. Состояние гонки [5]) и взаимными блокировками (deadlock, см. Взаимная блокировка [6]). Этот факт уже сам по себе представляет немалую ценность. Также будет рассмотрен подход, который позволяет иметь доступ к объекту из нескольких потоков одновременно без использования каких-либо блокировок и атомарных операций!Большинство статей ограничиваются лишь определенным набором примитивов, которыми, хотя и удобно пользоваться, но не решают общих проблем, возникающих в многопоточной среде. Ниже приведен список, который обычно используется в такого рода подходах. При этом я буду считать, что читатель уже знаком с такими подходами, поэтому я не буду заострять внимание на этом.
Сущности для использования:
Описание интерфейса мьютекса:
|
RAII примитив (exception-safe):
|
Класс для издевательств в качестве простого примера:
|
Пример 1. Примитивный подход: C-style
|
Пример 2. Продвинутый подход: RAII-style
|
Пример 3. Практически идеал: инкапсуляция локов
|
Инвариант
Начнем рассмотрение многопоточных вопросов, как это ни странно, с проверки инварианта объекта. Тем не менее, разработанный механизм для инварианта будет использоваться в дальнейшем.Для тех, кто не знаком с понятием “инвариант”, посвящен этот абзац. Остальные могут его смело пропустить и переходить сразу к реализации. Итак, в ООП мы работаем, как это ни странно, с объектами. Каждый объект имеет свое собственное состояние, которое при вызове неконстантных функций его изменяет. Так вот, как правило, для каждого класса существует некий инвариант, который должен выполняться при каждом изменении состояния. Например, если объект представляет собой счетчик элементов, то очевидно, что для любого момента времени выполнения программы величина этого счетчика не должна быть отрицательной, т.е. в данном случае инвариант — это неотрицательное значение счетчика. Таким образом, сохранение инварианта дает некоторую гарантию того, что состояние объекта консистентно.
Представим, что у нашего класса есть метод
isValid, который возвращает true в случае сохранения инварианта, и false — когда инвариант нарушен. Рассмотрим следующий “неотрицательный” счетчик:struct Counter { Counter() : count(0) {} bool isValid() const { return count >= 0; } int get() const { return count; } void set(int newCount) { count = newCount; } void inc() { ++ count; } void dec() { -- count; } private: int count; };
Использование:
Counter c; c.set(5); assert(c.isValid()); // вернет true c.set(-3); assert(c.isValid()); // вернет false и сработает assert
Теперь хочется как-то автоматизировать проверку инварианта, чтобы не звать после каждого изменения значения метод
isValid. Очевидный способ это сделать — включить этот вызов в метод set. Однако в случае присутствия большого количества неконстантных методов класса необходимо внутрь каждого такого метода вставить эту проверку. А хочется добиться автоматизма, чтобы писать меньше, а получать больше. Итак, приступим.Здесь мы будем использовать инструментарий, разработанный в предыдущих циклах статей: Использование паттерна синглтон [1], Синглтон и время жизни объекта [2], Обращение зависимостей и порождающие шаблоны проектирования [3], Реализация синглтона в многопоточном приложении [4]. Ниже приведу для справки реализацию, которая подвергнется припарированию:
An.hpp
#ifndef AN_HPP #define AN_HPP #include <memory> #include <stdexcept> #include <string> // декларативные определения, см. [1] #define PROTO_IFACE(D_iface, D_an) \ template<> void anFill<D_iface>(An<D_iface>& D_an) #define DECLARE_IMPL(D_iface) \ PROTO_IFACE(D_iface, a); #define BIND_TO_IMPL(D_iface, D_impl) \ PROTO_IFACE(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF(D_impl) \ BIND_TO_IMPL(D_impl, D_impl) // Основной класс, реализующий подход DIP - dependency inversion principle template<typename T> struct An { template<typename U> friend struct An; An() {} template<typename U> explicit An(const An<U>& a) : data(a.data) {} template<typename U> explicit An(An<U>&& a) : data(std::move(a.data)) {} T* operator->() { return get0(); } const T* operator->() const { return get0(); } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); return *u; } private: // извлекает объект // при первом доступе происходит его заполнение // с использованием внешней функции anFill, // которая должна быть переопределена для // каждого конкретного типа T T* get0() const { // ленивая инициализации при первом доступе к объекту const_cast<An*>(this)->init(); return data.get(); } std::shared_ptr<T> data; }; // заливка экземпляра, см. [1] // по умолчанию бросается исключение // необходимо переопределять, используя макросы выше // заливать можно как новые экземпляры, // так и синглтоны. см. [3] template<typename T> void anFill(An<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } #endif
Для того, чтобы иметь возможность проверять консистентность, модифицируем доступ к объекту (приватный метод
get0) следующим образом:template<typename T> struct An { // ... T* get0() const { const_cast<An*>(this)->init(); assert(data->isValid()); // добавляем assert return data.get(); } // ... };
Все хорошо, происходит проверка. Но вот беда: она происходит не после изменения, а до. Таким образом, объект может оказаться в неконсистентном состоянии, и только следующий вызов сделает свою работу:
c->set(2); c->set(-2); // здесь assert не сработает c->set(1); // и только здесь он сработает, хотя значение уже валидно!
Хочется, чтобы проверка происходила после изменения, а не до. Для этого будем использовать прокси-объект, в деструкторе которого будет происходить нужная проверка:
template<typename T> struct An { // ... struct Access { Access(T& ref_) : ref(ref_) {} ~Access() { assert(ref.isValid()); } T* operator->() { return &ref; } private: T& ref; }; // соответственно, вызов (только неконстантный, т.к. константный не должен менять значение): Access operator->() { return *get0(); } // ... };
Использование:
An<Counter> c; c->set(2); c->set(-2); // теперь assert сработает здесь c->set(1);
Что и требовалось.
Умный мьютекс
Перейдем теперь к нашим многопоточным задачам. Напишем новую реализацию мьютекса и назовем его “умным” по аналогии с умным указателем. Идея умного мьютекста в том, чтобы он брал на себя всю “грязную” работу по работе с объектом, а нам лишь оставалась самая вкусная часть.Для его приготовления нам потребуется “обычный” мьютекс (так же, как и для умного указателя необходим обычный указатель):
// noncopyable struct Mutex { // публичный интерфейс мьютекса void lock(); void unlock(); private: // ... };
Теперь усовершенствуем наработки, применяемые ранее при проверке инварианта. Для этого будем использовать не только деструктор прокси-класса, но и конструктор:
template<typename T> struct AnLock { // ... template<typename U> struct Access { // в конструкторе захватываем мьютекс Access(const An& ref_) : ref(ref_) { ref.mutex->lock(); } // в деструкторе мьютекс автоматически освобождаем ~Access() { ref.mutex->unlock(); } U* operator->() const { return ref.get0(); } private: const An& ref; }; // изменяем реализацию операторов доступа к объекту Access<T> operator->() { return *this; } Access<const T> operator->() const { return *this; } // модифицируем функцию создания template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new Mutex); return *u; } private: // ... std::shared_ptr<T> data; std::shared_ptr<Mutex> mutex; };
Использование:
AnLock<Counter> c; c->set(2); // изменяем значение std::cout << "Extracted value: " << c->get() << std::endl;
Стоит отметить, что при использовании константной ссылки изменение значения будет приводить к ошибке компиляции (в отличие от прямого использования
shared_ptr):const AnLock<Counter>& cc = c; cc->set(3); // эта строчка не скомпилируется
Рассмотрим, что же у нас получилось. Добавив вывод на экран для методов класса
Counter и Mutex, получаем следующий вывод на экран при изменении значения:Mutex::lock Counter::set: 2 Mutex::unlock
Последовательность действий при выводе на экран:
Mutex::lock Counter::get: 2 Extracted value: 2 Mutex::unlock
Удобство налицо: вместо явного вызова мьютекса мы просто работаем с объектом как-будто никакого мьютекса нет, а внутри происходит все, что нужно.
Можно спросить: а что делать, если мне надо, например, 2 раза вызвать
inc, причем сделать это атомарно? Нет проблем! Добавим сначала в наш класс AnLock парочку typedef для удобства:template<typename T> struct AnLock { // ... typedef Access<T> WAccess; // доступ на запись typedef Access<const T> RAccess; // доступ на чтение // ... };
А затем используем следующую конструкцию:
{ AnLock<Counter>::WAccess a = c; a->inc(); a->inc(); }
Что, в свою очередь, дает следующий вывод:
Mutex::lock Counter::inc: 1 Counter::inc: 2 Mutex::unlock
Чем-то напоминает транзакцию, не так ли?
Умный RW-мьютекс
Итак, теперь мы можем попробовать реализовать несколько более сложную конструкцию под названием read-write mutex (см. Readers–writer lock [7]). Суть использования достаточно простая: допускать возможность чтения данных объекта из нескольких потоков, в то время как одновременное чтение и запись или запись и запись должны быть запрещены.Предположим, у нас есть уже реализация
RWMutex с таким интерфейсом:// noncopyable struct RWMutex { // публичный интерфейс мьютекса // для чтения void rlock(); void runlock(); // для записи void wlock(); void wunlock(); private: // ... };
Казалось бы, все, что надо сделать, это слегка изменить реализацию, чтобы наши прокси-типы
RAccess и WAccess использовали разные функции:template<typename T> struct AnRWLock { // ... // доступ при чтении struct RAccess { RAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->rlock(); } ~RAccess() { ref.mutex->runlock(); } const T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; // доступ при записи struct WAccess { WAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->wlock(); } ~WAccess() { ref.mutex->wunlock(); } T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; WAccess operator->() { return *this; } RAccess operator->() const { return *this; } // ... // модифицируем функцию создания template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new RWMutex); return *u; } private: // ... std::shared_ptr<T> data; std::shared_ptr<RWMutex> mutex; };
Использование:
AnRWLock<Counter> c; c->set(2);
Результат:
RWMutex::wlock Counter::set: 2 RWMutex::wunlock
Пока все отлично! Но последующий код:
std::cout << "Extracted value: " << c->get() << std::endl;
Дает:
RWMutex::wlock Counter::get: 2 Extracted value: 2 RWMutex::wunlock
Для некоторых это не станет неожиданностью, а для остальной части я поясню, почему тут не работает так, как ожидалось. Ведь мы использовали константный метод, поэтому по идее должен был быть использован константный метод
operator->. Однако, компилятор так не считает. И связано это с тем, что операции применяются последовательно: сначала применяется операция -> к неконстантному объекту, а затем вызывается константный метод Counter::get, но поезд ушел, т.к. неконстантный operator-> уже был вызван.В качестве тривиального решения можно предложить вариант с приведением типа к константному перед обращением к объекту:
const AnRWLock<Counter>& cc = c; std::cout << "Extracted value: " << cc->get() << std::endl;
С результатом:
RWMutex::rlock Counter::get: 2 Extracted value: 2 RWMutex::runlock
Но выглядит это решение, мягко говоря, не очень привлекательно. Хочется писать просто и коротко, а не использовать громоздкие конструкции при каждом обращении к константным методам.
Для решения этой проблемы введем новый оператор длинная стрелка
--->, который бы осуществлял запись в объект, т.е. доступ к неконстантным методам, а обычную (короткую) стрелку -> оставим для чтения. Доводы использования короткой стрелки для чтения и длинной — для записи, а не наоборот, следующие:- Визуальный. Сразу видно, где какая операция используется.
- Смысловой. Чтение — это как бы поверхностное использование объекта: потрогал и отпустил. А запись — это более глубинная операция, изменение, так сказать, внутренностей, поэтому и стрелка длиннее.
- Прагматичный. При замене обычного мьютекса на RW-мьютекс необходимо просто поправить ошибки компиляции, заменив короткую стрелку на длинную в этих местах, и все будет работать наиболее оптимальным образом.
Тут, наверно, внимательный читатель задался вопросом: а где взять такую же травку, как и у автора статьи? Ведь

Давайте смотреть на реализацию:
// длинная стрелка, запись: WAccess operator--(int) { return *this; } // короткая стрелка, чтение: RAccess operator->() const { return *this; }
Использование:
AnRWLock<Counter> c; // не будет компилироваться: c->set(2) c--->set(2);
Последовательность действий:
RWMutex::wlock Counter::set: 2 RWMutex::wunlock
Все как и раньше, за исключением использования длинной стрелки. Смотрим дальше:
std::cout << "Extracted value: " << c->get() << std::endl;
RWMutex::rlock Counter::get: 2 Extracted value: 2 RWMutex::runlock
На мой взгляд, использование длинной стрелки для операции записи вполне оправдано: это решают нашу задачу, причем весьма элегантным способом.
Если читатель не совсем разобрался, как это работает
Если читатель не совсем разобрался, как это работает, то я приведу следующий эквивалентный код использования “длинной” стрелки в качестве подсказки:
(c--)->set(2);
Copy-on-write
Далее рассмотрим следующую интересную и полезную идиому: copy-on-write (COW), или Копирование при записи [8]. Как понятно из названия, основная идея заключается в том, что непосредственно перед изменением данных некоторого объекта сначала происходит копирование в новое место памяти, и уже затем изменение данных по новому адресу.Хотя подход COW не связан непосредственно с многопоточностью, тем не менее, использование такого подхода совместно с другими значительно улучшает удобство работы и добавляет ряд незаменимых элементов. Именно поэтому ниже приводится реализация COW. Более того, разработанные трюки легко и непринужденно переносятся на реализацию этой идиомы.
Итак, как и для RW-мьютекса, нам необходимо отличать операции чтения от операции записи. При чтении ничего особенного не должно происходить, а вот при записи, если у объекта более одного владельца, то предварительно необходимо этот объект скопировать.
template<typename T> struct AnCow { // ... // запись с использованием длинной стрелки T* operator--(int) { return getW0(); } // чтение с использованием короткой стрелки const T* operator->() const { return getR0(); } // функция клонирования (только для неполиморфных объектов!) void clone() { data.reset(new T(*data)); } // ... private: T* getR0() const { const_cast<An*>(this)->init(); return data.get(); } T* getW0() { init(); // клонирование в случае “неуникальности” объекта if (!data.unique()) clone(); return data.get(); }
Стоит обратить внимание, что здесь не рассматривается использование полиморфных объектов (т.е. никогда не создаем наследников шаблонного класса
T), т.к. это выходит за рамки данной статьи. В следующей статье я постараюсь дать детальное решение этого вопроса, при этом реализация будет достаточно необычной.Перейдем к использованию:
| Код | Вывод в консоли |
|---|---|
|
Counter::set: 2 |
|
Counter::get: 2 Extracted value: 2 |
|
Counter::get: 2 Extracted value: 2 |
|
Counter copy ctor: 2 Counter::inc: 3 |
|
Counter::dec: 1 |
2. Далее происходит присвоение значения новой переменной, при этом данные объекта используются одни и те же. При выводе значения d->get() используется тот же самый объект.Далее при вызове
d--->inc() происходит самое интересное: сначала копируется объект, а затем получившееся значение увеличивается до 3-х. При последующем вызове c--->dec() копирования не происходит, т.к. владелец теперь только один и у нас имеется две различные копии объекта. Думаю, этот пример наглядно иллюстрирует работу COW.Key-value хранилище в памяти
Напоследок рассмотрим некоторые вариации реализации key-value хранилища в памяти при работе в многопоточной среде с использованием разработанных методик.Будем использовать следующую реализацию для наших хранилищ:
template<typename T_key, typename T_value> struct KeyValueStorageImpl { // добавление значения в хранилище void set(T_key key, T_value value) { storage.emplace(std::move(key), std::move(value)); } // получение значения T_value get(const T_key& key) const { return storage.at(key); } // удаление значения void del(const T_key& key) { storage.erase(key); } private: std::unordered_map<T_key, T_value> storage; };
Привяжем хранилище к синглтону для упрощения дальнейших манипуляций (см. Использование паттерна синглтон [1]):
template<typename T_key, typename T_value> void anFill(AnRWLock<KeyValueStorageImpl<T_key, T_value>>& D_an) { D_an = anSingleRWLock<KeyValueStorageImpl<T_key, T_value>>(); }
Таким образом, при создании экземпляра
AnRWLock<KeyValueStorageImpl<T,V>> будет “заливаться” объект, извлеченный из синглтона, т.е. AnRWLock<KeyValueStorageImpl<T,V>> всегда будет указывать на единственный экземпляр.Для справки приведу используемую инфраструктуру:
AnRWLock.hpp
#ifndef AN_RWLOCK_HPP #define AN_RWLOCK_HPP #include <memory> #include <stdexcept> #include <string> #include "Mutex.hpp" // fill #define PROTO_IFACE_RWLOCK(D_iface, D_an) \ template<> void anFill<D_iface>(AnRWLock<D_iface>& D_an) #define DECLARE_IMPL_RWLOCK(D_iface) \ PROTO_IFACE_RWLOCK(D_iface, a); #define BIND_TO_IMPL_RWLOCK(D_iface, D_impl) \ PROTO_IFACE_RWLOCK(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF_RWLOCK(D_impl) \ BIND_TO_IMPL_RWLOCK(D_impl, D_impl) #define BIND_TO_IMPL_SINGLE_RWLOCK(D_iface, D_impl) \ PROTO_IFACE_RWLOCK(D_iface, a) { a = anSingleRWLock<D_impl>(); } #define BIND_TO_SELF_SINGLE_RWLOCK(D_impl) \ BIND_TO_IMPL_SINGLE_RWLOCK(D_impl, D_impl) template<typename T> struct AnRWLock { template<typename U> friend struct AnRWLock; struct RAccess { RAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->rlock(); } ~RAccess() { ref.mutex->runlock(); } const T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; struct WAccess { WAccess(const AnRWLock& ref_) : ref(ref_) { ref.mutex->wlock(); } ~WAccess() { ref.mutex->wunlock(); } T* operator->() const { return ref.get0(); } private: const AnRWLock& ref; }; AnRWLock() {} template<typename U> explicit AnRWLock(const AnRWLock<U>& a) : data(a.data) {} template<typename U> explicit AnRWLock(AnRWLock<U>&& a) : data(std::move(a.data)) {} WAccess operator--(int) { return *this; } RAccess operator->() const { return *this; } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); mutex.reset(new RWMutex); return *u; } private: T* get0() const { const_cast<AnRWLock*>(this)->init(); return data.get(); } std::shared_ptr<T> data; std::shared_ptr<RWMutex> mutex; }; template<typename T> void anFill(AnRWLock<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } template<typename T> struct AnRWLockAutoCreate : AnRWLock<T> { AnRWLockAutoCreate() { this->create(); } }; template<typename T> AnRWLock<T> anSingleRWLock() { return single<AnRWLockAutoCreate<T>>(); } #endif
AnCow.hpp
#ifndef AN_COW_HPP #define AN_COW_HPP #include <memory> #include <stdexcept> #include <string> // fill #define PROTO_IFACE_COW(D_iface, D_an) \ template<> void anFill<D_iface>(AnCow<D_iface>& D_an) #define DECLARE_IMPL_COW(D_iface) \ PROTO_IFACE_COW(D_iface, a); #define BIND_TO_IMPL_COW(D_iface, D_impl) \ PROTO_IFACE_COW(D_iface, a) { a.create<D_impl>(); } #define BIND_TO_SELF_COW(D_impl) \ BIND_TO_IMPL_COW(D_impl, D_impl) #define BIND_TO_IMPL_SINGLE_COW(D_iface, D_impl) \ PROTO_IFACE_COW(D_iface, a) { a = anSingleCow<D_impl>(); } #define BIND_TO_SELF_SINGLE_COW(D_impl) \ BIND_TO_IMPL_SINGLE_COW(D_impl, D_impl) template<typename T> struct AnCow { template<typename U> friend struct AnCow; AnCow() {} template<typename U> explicit AnCow(const AnCow<U>& a) : data(a.data) {} template<typename U> explicit AnCow(AnCow<U>&& a) : data(std::move(a.data)) {} T* operator--(int) { return getW0(); } const T* operator->() const { return getR0(); } bool isEmpty() const { return !data; } void clear() { data.reset(); } void init() { if (!data) reinit(); } void reinit() { anFill(*this); } T& create() { return create<T>(); } template<typename U> U& create() { U* u = new U; data.reset(u); return *u; } // TODO: update clone functionality on creating derived instances void clone() { data.reset(new T(*data)); } private: T* getR0() const { const_cast<AnCow*>(this)->init(); return data.get(); } T* getW0() { init(); if (!data.unique()) clone(); return data.get(); } std::shared_ptr<T> data; }; template<typename T> void anFill(AnCow<T>& a) { throw std::runtime_error(std::string("Cannot find implementation for interface: ") + typeid(T).name()); } template<typename T> struct AnCowAutoCreate : AnCow<T> { AnCowAutoCreate() { this->create(); } }; template<typename T> AnCow<T> anSingleCow() { return single<AnCowAutoCreate<T>>(); } #endif
Далее будут рассмотрены различные способы использования этого хранилища, от простого к сложному.
Пример 1. Простейшее использование.
Будем непосредственно использовать хранилище без дополнительных изысков:// для простоты объявим класс для дальнейшего использования template<typename T_key, typename T_value> struct KeyValueStorage : AnRWLock<KeyValueStorageImpl<T_key, T_value>> { typedef T_value ValueType; };
Пример использования:
| Код | Вывод в консоли |
|---|---|
|
RWMutex::wlock Key-value: inserting key: Peter RWMutex::wunlock |
|
RWMutex::wlock Key-value: inserting key: Nick RWMutex::wunlock |
|
RWMutex::rlock Key-value: extracting key: Peter Peter age: 28 RWMutex::runlock |
kv, в который заливается единственный экземпляр хранилища, используя синглтон (см. функцию anFill). Далее добавляются записи Peter и Nick, а затем выводится возраст Peter.Думаю, из вывода понятно, что при записи автоматически берется write-lock, а при чтении — read-lock.
Пример 2. Вложенные RW-мьютексы.
Рассмотрим чуть более сложный пример. Предположим теперь, что мы хотим завести именованные счетчикиCounter и использовать их из нескольких потоков. Нет проблем:// объявляем новый класс, который может в себе хранить объекты с AnRWLock template<typename T_key, typename T_value> struct KeyValueStorageRW : KeyValueStorage<T_key, AnRWLock<T_value>> { }; // объявим тип для наших счетчиков typedef KeyValueStorageRW<std::string, Counter> KVRWType;
Пример использования:
| Код | Вывод в консоли |
|---|---|
|
RWMutex::wlock Key-value: inserting key: users RWMutex::wunlock |
|
RWMutex::wlock Key-value: inserting key: sessions RWMutex::wunlock |
|
RWMutex::rlock Key-value: extracting key: users RWMutex::wlock Counter::inc: 1 RWMutex::wunlock RWMutex::runlock |
|
RWMutex::rlock Key-value: extracting key: sessions RWMutex::wlock Counter::inc: 1 RWMutex::wunlock RWMutex::runlock |
|
RWMutex::rlock Key-value: extracting key: sessions RWMutex::wlock Counter::dec: 0 RWMutex::wunlock RWMutex::runlock |
Пример 3. Оптимизация доступа.
Хотя о некоторых оптимизациях я хотел бы рассказать в следующей статье, однако здесь опишу, на мой взгляд, достаточно важную оптимизацию.Ниже приведены различные варианты использования для сравнения.
Вариант 1: обычный
| Код | Вывод в консоли |
|---|---|
|
RWMutex::rlock Key-value: extracting key: users RWMutex::wlock Counter::inc: 2 RWMutex::wunlock RWMutex::runlock |
Вариант 2: оптимальный
| Код | Вывод в консоли |
|---|---|
|
RWMutex::rlock Key-value: extracting key: users RWMutex::runlock |
|
RWMutex::wlock Counter::inc: 3 RWMutex::wunlock |
Counter берется только после отпускания первого, который контролирует key-value хранилище. Такая реализация обеспечивает более оптимальное использование мьютексов, хотя и получаем в результате более длинную запись. Эту оптимизацию стоит иметь в виду при использовании вложенных мьютексов.Пример 4. Поддержка атомарности изменений.
Предположим, что нам необходимо атомарно увеличить на 100 один из счетчиков, например “users”. Конечно, для этого можно позвать 100 раз операциюinc(), а можно сделать так:| Код | Вывод в консоли |
|---|---|
|
RWMutex::rlock Key-value: extracting key: users RWMutex::runlock |
|
RWMutex::wlock Counter::get: 4 Counter::set: 104 RWMutex::wunlock |
WAccess далее все операции идут с обычной “короткой” стрелкой, т.к. доступ к объекту на запись уже получен. Также стоит обратить внимание на то, что операции get и set идут под одним и тем же мьютексом, чего мы и хотели достичь. Это очень похоже на то, что мы как будто открыли транзакцию при действии над объектом.Этот же трюк можно использовать совместно с описанной выше оптимизацией для доступа непосредственно к счетчикам.
Вариант 1: обычный
| Код | Вывод в консоли |
|---|---|
|
RWMutex::rlock Key-value: extracting key: users RWMutex::wlock Counter::inc: 4 RWMutex::wunlock RWMutex::runlock |
|
RWMutex::rlock Key-value: extracting key: sessions RWMutex::wlock Counter::dec: -1 RWMutex::wunlock RWMutex::runlock |
Вариант 2: оптимальный
| Код | Вывод в консоли |
|---|---|
|
RWMutex::rlock Key-value: extracting key: users Key-value: extracting key: sessions RWMutex::runlock |
|
RWMutex::wlock Counter::inc: 5 RWMutex::wunlock |
|
RWMutex::wlock Counter::dec: -2 RWMutex::wunlock |
Пример 5. COW.
Предположим, что у нас есть сотрудники со следующей информацией:struct User { std::string name; int age; double salary; // много более другой информации... };
Наша задача: провести различные операции над выбранными пользователями, например рассчитать бухгалтерский баланс. Ситуация осложняется тем, что операция длительная. При этом при расчете изменение информации о сотрудниках недопустимо, т.к. различные показатели должны быть согласованными, и если изменится какие-либо данные, то баланс может не сойтись. При этом хочется, чтобы за время проведения операции информацию о сотрудниках таки можно было изменять, не дожидаясь окончания длительных операций. Чтобы реализовать рассчет, необходимо как бы снимать snapshot данных для какого-то момента времени. Конечно, при этом данные могут стать неактуальны, но для баланса важнее иметь самосогласованность результатов.
Посмотрим, как это можно реализовать с использованием COW. Подготовительный этап:
Использование COW при создании экземпляра User
|
Объявляем новый класс, который может в себе хранить объекты с AnCow
|
Объявление нашего хранилища: int — id пользователя, User — пользователь
|
Добавление информации о пользователе Peter
|
Добавление информации о пользователе George
|
Изменение информации о возрасте сотрудника
|
Получение нужных пользователей
|
Расчет необходимых параметров. Все данные будут самосогласованны и останутся неизменны вплоть до окончания операций.
|
В целом, можно было бы конечно использовать копирование всех элементов перед расчетом. Однако при наличии достаточно большого количества информации это будет достаточно длительная операция. Поэтому она в обозначенном подходе откладывается до тех пор, пока действительно необходимо скопировать данные, т.е. только при их одновременном использовании в расчетах и изменении.
Анализ и обобщение
Ниже будет дан анализ примеров. Наибольший интерес, прежде всего, представляет последний пример с COW, так как там скрываются неожиданные сюрпризы.COW в деталях
Рассмотрим последовательность операций последнего примера. Ниже приведена общая схема при извлечении значения из контейнера: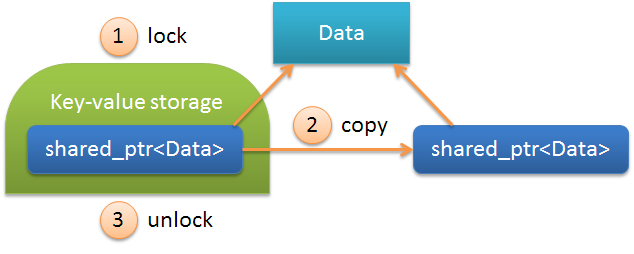
Здесь
Data — это User в описанном выше примере, а shared_ptr<Data> — это содержимое объекта AnCow. Последовательность операций:| N | Описание | |
|---|---|---|
| 1 | lock | Блокировка хранилища, делается автоматически при вызове operator-> |
| 2 | copy | Копирование shared_ptr<Data>, т.е. фактически происходит простое увеличение счетчиков (use_count и weak_count внутри объекта shared_ptr<Data>) |
| 3 | unlock | Снятие блокировки хранилища деструкторе временного объекта |
Что же происходит при записи данных в объект. Смотрим:
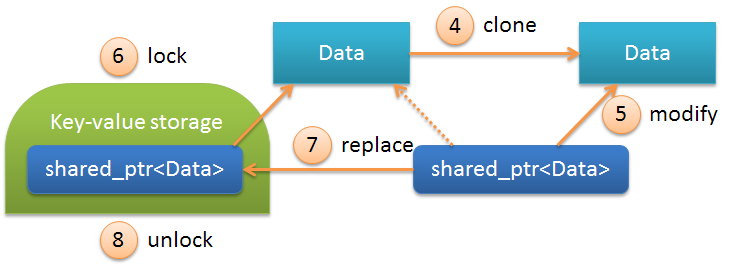
Последовательность операций при этом выглядит следующим образом:
| N | Описание | |
|---|---|---|
| 4 | clone | Клонирование объекта, вызывается конструктор копирования объекта Data, т.е. копирование всех его полей в новую область памяти. После этой операции shared_ptr начинает смотреть на вновь созданный объект. |
| 5 | modify | Непосредственно операция модификации. Может происходить длительное время, т.к. является неблокирующей. |
| 6 | lock | Перед обновлением хранилища прозводится взятие блокировки. |
| 7 | replace | Замена старого значения shared_ptr<Data> на новое, модифицированное на 5-м шаге. |
| 8 | unlock | Снятие блокировки хранилища. |
int. Существенное отличие состоит в том, что при COW данные могут использоваться из одной и той же области памяти в нескольких потоках одновременно.Стоит отметить, что большинство указанных выше операций происходят автоматически, т.е. нет необходимости в выполнении всех операций явным образом.
Оптимизация количества COW
Как показано выше, при изменении объекта COW происходит копирование всех его полей. Это не представляет большой проблемы при малом количестве данных. Но что делать, если у нас в классе имеется большое количество параметров? В этом случае можно использовать многоуровневые COW-объекты. Например, можно было бы ввести следующий классUserInfo:struct UserInfo { AnCow<AccountingInfo> accounting; AnCow<CommonInfo> common; AnCow<WorkInfo> work; }; struct AccountingInfo { AnCow<IncomingInfo> incoming; AnCow<OutcomingInfo> outcoming; AnCow<BalanceInfo> balance; }; struct CommonInfo { // и т.д. }; // и т.п.
Введя на каждом из уровней объекты COW, можно значительно уменьшить количество копирований. При этом, сама операция копирования будет состоять лишь в атомарном увеличении счетчиков. И лишь непосредственно сам объект изменения будет скопирован с использованием конструктора копирования. Можно легко показать, что минимальное количество копирований достигается при количестве объектов на каждом из уровней равным 3-м.
Обобщенная схема
Рассмотрев более детально операции с COW с учетом вложенности, можно теперь смело перейти к обобщению использования рассмотренных идиом. Но для этого сначала рассмотрим схемы, используемые в примерах.В первом примере использовались вложенные
AnRWLock объекты: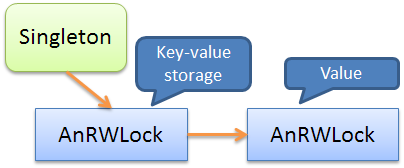
Key-value хранилище в указанном примере был положен в синглтон и сверху обернут “умным” мьютексом. Значения при этом также были обернуты в “умный” мьютекс.
Следующая схема описывает пример с COW:
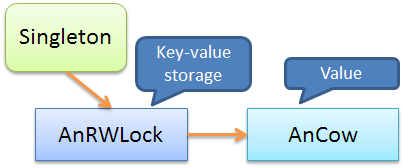
Здесь значение было обернуто в объект
AnCow для реализации семантики COW.Соответственно, обобщенную схему можно представить в виде:
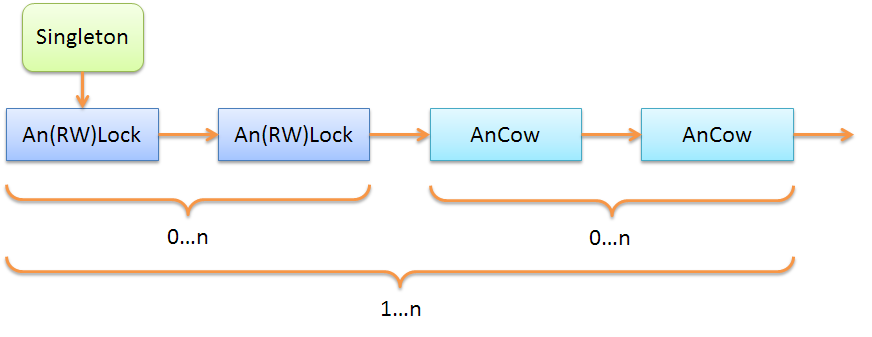
Понятно, что объекты
AnLock и An(RW)Lock взаимозаменяемы: можно использовать как один, так и другой. Также можно цепочку повторять несколько раз, как показно на примере ниже: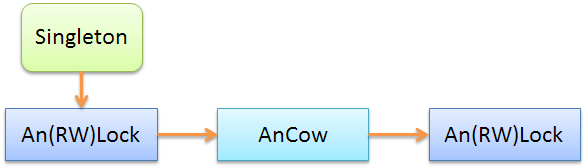
Стоит, однако, помнить, что семантика объектов
An(RW)Lock и AnCow существенно отличается:| Свойство | Умный мьютекс | COW |
|---|---|---|
| Доступ к полям объекта | Блокируется на время чтения/записи | Не блокируется |
| Изменение объекта в контейнере | Изменение “на месте” (in-place) | После изменения необходимо положить новое значение обратно в контейнер |
Выводы
Итак, в статье были рассмотрены некоторые идиомы, повышающие эффективность написания многопоточных приложений. Стоит отметить следующие преимущества:- Простота. Нет необходимости явного использования многопоточных примитивов, все происходит автомагически.
- Гибкость. Решение применимо для широкого класса многопоточных задач с возможностью комбинирования различных идиом. Здесь также стоит упомянуть поддержку транзакционности (в памяти) на некотором начальном уровне.
- Качество. Использование такого подхода позволяет существенно уменьшить количество проблем, связанных с состоянием гонки (race condition) и взаимной блокировки (deadlock). Состояния гонки устраняются наличием автоматических блокировок благодаря умным мьютексам. Вероятность взаимной блокировки существенно уменьшается благодаря гранулярному (fine-grained) доступу к данным на каждом уровне, и фиксированным автоматическим порядком захвата и снятия блокировок.
Такой универсальный подход стал возможен благодаря тому, что в реализации
An-классов происходит полный контроль использования хранимых объектов. Поэтому появляется возможность добавлять нужный функционал, автоматически вызывая на границах доступа необходимые методы. Этот подход будет существенно углублен и расширен в следующей статье.В приведенном материале не рассматривалось использование полиморфных объектов. В частности, реализация
AnCow работает только с тем же шаблонным классом, т.к. всегда вызывается конструктор копирования для объявленного типа T. В следующей статье будет приведена реализация для более общего случая. Также будет проведена унификация объектов и способов их использования, рассказано о различных оптимизациях, о многопоточных ссылках, и многое другое.Литература
[1] Хабрахабр: Использование паттерна синглтон[2] Хабрахабр: Синглтон и время жизни объекта
[3] Хабрахабр: Обращение зависимостей и порождающие шаблоны проектирования
[4] Хабрахабр: Реализация синглтона в многопоточном приложении
[5] Википедия: Состояние гонки
[6] Википедия: Взаимная блокировка
[7] Wikipedia: Readers–writer lock
[8] Википедия: Копирование при записи
[9] Хабрахабр: Многопоточность, общие данные и мьютексы
[10] Хабрахабр: Кросс-платформенные многопоточные приложения
[11] Хабрахабр: Потоки, блокировки и условные переменные в C++11 [Часть 2]
[12] Хабрахабр: Потоки, блокировки и условные переменные в C++11 [Часть 1]
[13] Хабрахабр: Два простых правила для предотвращения взаимных блокировок на мьютексах
[14] DrDobbs: Enforcing Correct Mutex Usage with Synchronized Values
P.S. Решение задачи про количество копирований
Предположим, на каждом из уровней имеется Сокращая Количество копирований
n объектов, количество уровней — k, а общее число элементов — a. Тогда количество элементов a = n^k, или k = ln a/ln n. ln получаем k = a/n.= n*k (необходимо пройти каждый слой и скопировать на каждом слое n раз). Т.е. число копирований = n*ln a/ln n или просто n/ln n, т.к. a — const. Легко найти локальный минимум, он достигается при n = e, что ближе всего соответствует целому числу 3.И напоследок — опрос. На повестке дня 2 вопроса:
Only registered users can participate in poll. Log in, please.
Понравилась ли статья?
85.41%Да, понравилась. Жду продолжения.158
14.59%Ничего интересного, только зря потратил время на прочтение.27
185 users voted. 60 users abstained.
Only registered users can participate in poll. Log in, please.
Понятно ли, откуда взялось число 3 для оптимизации количества операций копирования при рассмотрении вложенных COW-объектов?
16.87%Да, я сам получил такое же число, все понятно.14
83.13%Нет, непонятно. Вывод в студию! (уже в P.S.)69
83 users voted. 92 users abstained.
