Вступление
    В данной статье я расскажу, как можно немного кастомизировать Zabbix JavaGateway для наиболее удобного низко уровневого обнаружения JMX метрик. Здесь github.com/mfocuz/zabbix_plugins/tree/master/jmx_discovery можно взять патч на версию 2.0.11 и посмотреть примеры external скриптов. Но обо всем по порядку.
    С версии 2.0 в Zabbix появилась нативная поддержка мониторинга Java приложений через JMX. Но возможно не все знают, что кроме сбора метрик мы можем их также дискаверить в Zabbix из коробки. В документации этот момент либо пропустили, либо посчитали фичу несовсем готовой(хотя может я просто не нашел этого в доке?), но эта фича там есть, и, на мой взляд, она действительно не совсем готова. Хотя я не уверен что она вообще работает, до тестирования не дошло.
    В исходниках zabbix_javagw в классе JMXItemChecker.java для версии 2.0.11 строка 157 и далее:
else if (item.getKeyId().equals("jmx.discovery”)) { … for (ObjectName name : mbsc.queryNames(null, null)) { logger.trace("discovered object '{}'", name); for (MBeanAttributeInfo attrInfo : mbsc.getMBeanInfo(name).getAttributes()) { logger.trace("discovered attribute '{}'", attrInfo.getName()); if (!attrInfo.isReadable()) { logger.trace("attribute not readable, skipping"); continue; } try { logger.trace("looking for attributes of primitive types"); String descr = (attrInfo.getName().equals(attrInfo.getDescription()) ? null : attrInfo.getDescription()); findPrimitiveAttributes(counters, name, descr, attrInfo.getName(), mbsc.getAttribute(name, attrInfo.getName())); } catch (Exception e) { Object[] logInfo = {name, attrInfo.getName(), e}; logger.trace("processing '{},{}' failed", logInfo); } } } }
    Как видно из кода, если в конфигурации дискавери правил задать ключ с именем “jmx.discovery”, то отработает обнаружение, которое вернет все атрибуты по всем найденым mbeans.
    Здесь в первую очередь хочется отметить, что в таком запросе нет особой необходимости. Во-первых, подобный запрос работает не совсем быстро, потому что запрос на атрибуты каждого мбина проходит отдельным запросом, а бинов может быть достаточно много. Во вторых, ключ дискавери правила является уникальным значением в Zabbix, а это значит, что используя jmx.discovery мы можем создать одно единственное дискавери правило для JMX метрик в пределах одного хоста, что для большинства задач совершенно не подходит. Ну и в третьих, атрибуты для каждого java mbean как правило не меняются, тоесть их кол-во и назначение в пределах одного бина постоянно. Это значит что сами атрибуты лучше задать в item прототипах и часть кода, которая собственно и является самым тормозом:
for (MBeanAttributeInfo attrInfo : mbsc.getMBeanInfo(name).getAttributes()) { ....... try { (attrInfo.getName().equals(attrInfo.getDescription()) ? null : attrInfo.getDescription()); findPrimitiveAttributes(counters, name, descr, attrInfo.getName(), mbsc.getAttribute(name, attrInfo.getName())); ......
становится не нужна. А вот кол-во mbeans может быть переменным. Например Oracle Coherence создает определенное кол-во бинов под каждую ноду в кластере. В результате мы имеем бины, название которых отличается только по nodeId. И например при рестарте кластера все nodeId меняются. То есть Java метрики имеют динамические имена mbeans. Вот тут мы и используем LLD, но:
1. Нам нужны только сами mbeans, без атрибутов (можно и их обнаружить, но имхо это лишне).
2. Нам важно иметь возможность создавать несколько дискавери правил на один хост.
3. Нам нужна возможность кодировать разнообразную логику для дискавери правил.
    Не так давно появилась одна статья о JMX дискавери www.zabbix.org/wiki/Docs/howto/jmx_discovery. Последний год я использовал похожее решение. В краце: суть этого решени в запуске .jar файла как external скрипта. Огромный его минус в том, что Java не рассчитана на многократный запуск, как это обычно делается для интерпретируемых языков типа python или perl. Этот минус делает решение практически не рабочим. Скажем, на виртуалке с 2мя корами для запуска порядка 20 дискавери правил загрузка CPU уходила полку, в результате external чеки просто отваливались по таймауту. На железках где было по 8кор вроде работало исправно. Но всеравно, запуск пачки JVM раз в N минут решение не красивое и можно рассматривать только как костыль.
Как будет работать новая функциональность
    Для начала рассмотрим, как взаимодействуют Zabbix сервер и JavaGateway. Для сбора JMX метрик Zabbix сервер коннектиться к JavaGateway по TCP, после чего делает запрос на нужные данные по Zabbix протоколу. На оф сайте есть общее описание протокола, опишу его чуть более подроно т.к. он нам понадобиться для LLD.
Сообщение к серверу и ответ от него состоит из 3х частей:
1. Заголовок ZBXD\1
2. Длина сообщения
3. Сообщение в формате JSON.
Выглядит примерно так:
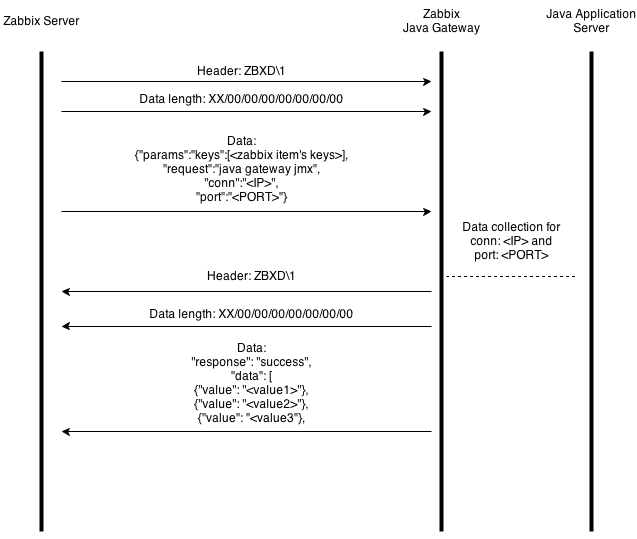
    Мне хотелось сделать минимум изменений в коде Zabbix, поэтому код Zabbix сервера мы не трогаем, в схеме выше мы заменяем Zabbix server на externalscript, который будет делать такое же соединение. А в JavaGateway коде добавим нужную нам фун-ть. И теперь общение с JavaGateway для LLD выглядит вот так:
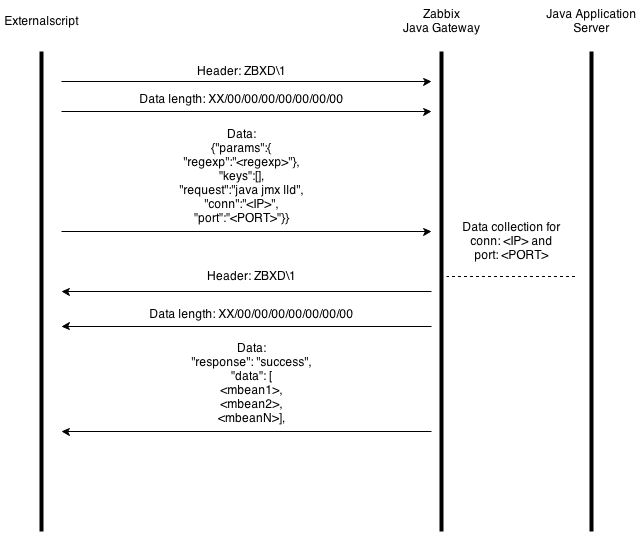
То есть добавилось поле regexp и новый вид request = “java jmx lld”.
Меняем JavaGateway код
    Что же нужно допилить чтобы JMX дискавери стал удобным и быстрым? По задумке разработчиков в JavaGateway есть два возможных request запроса, их можно найти в коде ItemChecker.java, это константы JSON_REQUEST_INTERNAL для сбора пары внутренних JavaGateway метрик, и JSON_REQUEST_JMX — который является основным запросом и служит для сбора JMX метрик. В коде SocketProcessor.java видим:
if (request.getString(ItemChecker.JSON_TAG_REQUEST).equals(ItemChecker.JSON_REQUEST_INTERNAL)) checker = new InternalItemChecker(request); else if (request.getString(ItemChecker.JSON_TAG_REQUEST).equals(ItemChecker.JSON_REQUEST_JMX)) checker = new JMXItemChecker(request); ….. JSONArray values = checker.getValues();
    То есть тут определяется какого типа будет checker. Мы добавим 3й вид запроса — JSON_JMX_LLD. И соот-но еще одно условия для нашего запроса в SocketProcessor.java:
…... else if (request.getString(ItemChecker.JSON_TAG_REQUEST).equals(ItemChecker.JSON_JMX_LLD)) checker = new JMXItemDiscoverer(request); …… JSONArray values = checker.getValues();
    Теперь, когда сервер получит запрос на JSON_JMX_LLD, будет создан экземпляр класса JMXItemDiscoverer и вызван метод getValues. Осталось добавить класс JMXItemDiscoverer, который сделает дискавери правило так, как нам было бы удобно, а именно — сделает запрос на все имеющиеся бины и на выходе будет возвращать список бинов по заданному регэкспу. Код нового класса можно увидить в патче.
Настраиваем новый Java gateway
    Есть два варианта, можно подменить сам JavaGateway, а можно поднять еще один, который будет работать только для LLD. Если меням gateway на PRO, то:
    1.На стороне Zabbix нужно изменить только JavaGateway. По ссылке в начале статьи можно найти патч на zabbix java gateway версии 2.0.11. Я немного полазил diff’ом по коду 2.2 и 2.0.11, так вот java gateway там не сильно отличается, поэтому думаю при базовом знании Java будет не сложно перенести патч и на последнюю версию.
    2.Далее накатываем патч и собираем JavaGateway под установленную версию Java.
    3.Получившийся .jar подкладываем на место старого, все остальные файлы java gateway включая конфиг, либы и прочее оставляем как есть.
    4. Стартуем. Получаем тот же Java gateway, но теперь он умеет обрабаывать еще один вид запросов.
    5. Для самих запросов пишем скрипт который будет цепляться к серверу по TCP и собственно делать сам запрос. Я набросал простой модуль JMXDiscovery.pm для Perl, чтобы было проще написать дискавери скрипт плюс пример дискавери скриптаjmx_discovery.pl и использования модуля.(можно найти там же по ссылке в начале).
    6. Ну и наконец создаем дискавери правила, в типе указываем externalscript. Параметры передаваемы скрипту будут обеспечивать уникальность ключа, что и позволит создать любое кол-во правил.
    Если же хочется поднять отдельный сервер для LLD, то п.3 пропускаем и после сборки вместе с патчем просто ставаим JavaGateway отдельным сервисом.
Заключение
Работает быстро и стабильно.
