На днях я посетил грандиозную тусовку любителей NoSQL — World MongoDB Conference.

Eliot Horowitz, Co-Founder и CTO в MongoDB, рассказал о 3 новшествах, которые будут доступны уже в ближайшем релизе.
Каждое из анонсированных нововведений нацелено на достижение следующих принципов в архитектуре MongoDB:
Видео презентации можно посмотреть здесь.
MongoDB разрабатывается уже, ни много ни мало, 7 лет. И что же пользователи слышали о согласованности все эти годы? В основном они слышали о глобальных локах на уровне всей БД.
Важно помнить о том, что блокировки в MongoDB очень похожи на латчи в реляционных СУБД — они очень простые и обычно занимают не более 10 миллисекунд. В MongoDB 2.2 была решена проблема блокировок на уровне всей БД, а также улучшен агоритм lock yielding. Это позволило существенно уменьшить количество проблем, возникавших у сообщества в связи с локами. Тем не менее, разработчики MongoDB продолжали трудиться в этом направлении.
И вот настал момент истины: MongoDB 2.8 будет иметь блокировки на уровне документов! Это, безусловно, куда большее улучшение, чем долгожданная блокировка на уровне коллекций.
Блокировка на уровне документов уже выложена на github (v.2.7.3), но ещё не готова для использования в продакшене. Для включения режима блокировки на уровне документов необходимо запустить
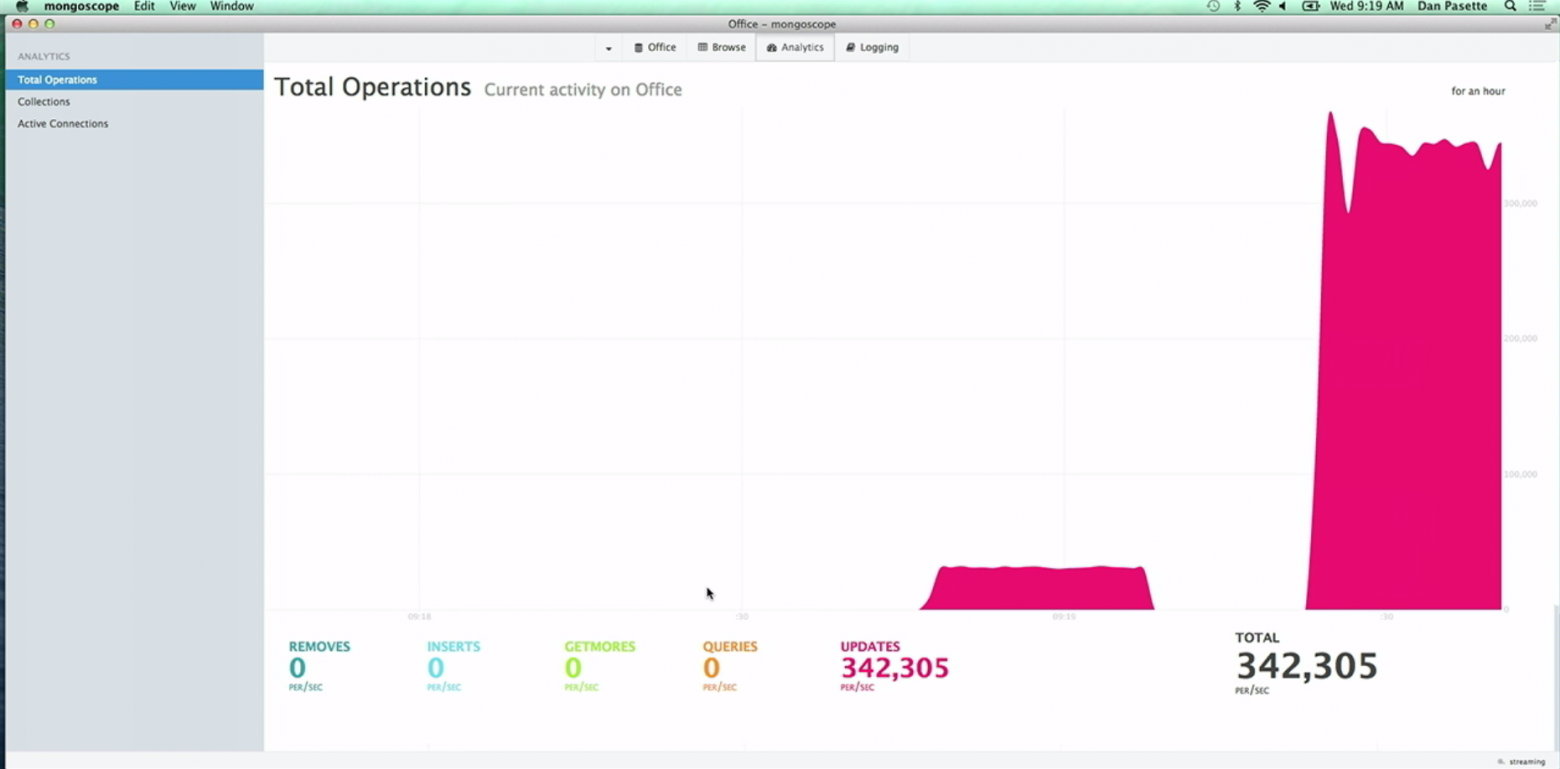
Давайте попробуем ответить на один простой вопрос: какой движок для хранения данных является наилучшим для будущего MongoDB? Ориентированный на скорость чтения? Скорость записи? Безопасность? Ребята из MongoDB предпочли не заморачиваться с ответом. Они решили, что ни один из движков нельзя считать оптимальным сразу для всех нужд. И с этим действительно не поспоришь. В общем, они разработали заменяемое API для произвольного storage engine.
Требований к данному API довольно немало, т.к. оно должно поддерживать все уже существующие фичи MongoDB, поддерживать операционную масштабируемость, добавление одной или нескольких нод в кластер и многое другое.
В итоге, мы получим возможность подключения заменяемого хранилища, которое будет оптимизировано под конкретные нужды: производительность, сжатие данных и т.д.
Предполагаемые типы хранилищ:
— In-Memory
— RocksDB (из Facebook, заточен под сжатие)
— InnoDB (из MySQL)
— TokuKV
— FusionIO (работает в обход файловой системы, заточен под низкие задержки)
In-Memory и RocksDB уже доступны в девелоперской ветке на github. Опять же, не торопитесь использовать это на боевых серверах.
Как известно, MongoDB умеет из коробки реплицироваться и шардироваться. В результате мы получаем не один экземпляр БД, а сразу несколько. В по-настоящему больших проектах таких нод может быть очень много. И проблема заключается не только в развёртывании всех этих нод, но и в их дальнейшем обновлении, бэкапировании, мониторинге и многом другом.
Всю эту рутину теперь за нас будет делать Mongo Management Service (MMS).

MMS представляет собой дружелюбный веб интерфейс, который позволяет решать целый ряд задач буквально в пару кликов мышкой:
И на закуску: MMS научат интегрироваться с Amazon EC2.
Мне очень нравится тот факт, что команда MongoDB уделяет много внимания тому, чтобы их продукт был удобен и полезен разработчикам. И делают это не в сферическом вакууме, а активно интересуясь мнением непосредственно у сообщества. Поэтому я уверен в том, что MongoDB и дальше будет сохранять отличный темп внедрения новых возможностей, совершенствовать безопасность, автоматизировать и делать ещё более незаметной всю рутину.
Eliot Horowitz, Co-Founder и CTO в MongoDB, рассказал о 3 новшествах, которые будут доступны уже в ближайшем релизе.
Каждое из анонсированных нововведений нацелено на достижение следующих принципов в архитектуре MongoDB:
- Продуктивность разработчика
- Горизонтальная масштабируемость
- Операционная масштабируемость
- Администрирование одного вебсервера должно быть простым. То же самое касается кластеров
Видео презентации можно посмотреть здесь.
Согласованность данных
MongoDB разрабатывается уже, ни много ни мало, 7 лет. И что же пользователи слышали о согласованности все эти годы? В основном они слышали о глобальных локах на уровне всей БД.
Важно помнить о том, что блокировки в MongoDB очень похожи на латчи в реляционных СУБД — они очень простые и обычно занимают не более 10 миллисекунд. В MongoDB 2.2 была решена проблема блокировок на уровне всей БД, а также улучшен агоритм lock yielding. Это позволило существенно уменьшить количество проблем, возникавших у сообщества в связи с локами. Тем не менее, разработчики MongoDB продолжали трудиться в этом направлении.
И вот настал момент истины: MongoDB 2.8 будет иметь блокировки на уровне документов! Это, безусловно, куда большее улучшение, чем долгожданная блокировка на уровне коллекций.
Блокировка на уровне документов уже выложена на github (v.2.7.3), но ещё не готова для использования в продакшене. Для включения режима блокировки на уровне документов необходимо запустить
mongod с ключём useExperimantalDocLocking=true. Продемонстрированный на презентации рост скорости апдейтов ошеломляет: он увеличился примерно в 10 раз с 30.000 per/sec по 340.000 per/sec!Произвольные хранилища данных
Давайте попробуем ответить на один простой вопрос: какой движок для хранения данных является наилучшим для будущего MongoDB? Ориентированный на скорость чтения? Скорость записи? Безопасность? Ребята из MongoDB предпочли не заморачиваться с ответом. Они решили, что ни один из движков нельзя считать оптимальным сразу для всех нужд. И с этим действительно не поспоришь. В общем, они разработали заменяемое API для произвольного storage engine.
Требований к данному API довольно немало, т.к. оно должно поддерживать все уже существующие фичи MongoDB, поддерживать операционную масштабируемость, добавление одной или нескольких нод в кластер и многое другое.
В итоге, мы получим возможность подключения заменяемого хранилища, которое будет оптимизировано под конкретные нужды: производительность, сжатие данных и т.д.
Предполагаемые типы хранилищ:
— In-Memory
— RocksDB (из Facebook, заточен под сжатие)
— InnoDB (из MySQL)
— TokuKV
— FusionIO (работает в обход файловой системы, заточен под низкие задержки)
In-Memory и RocksDB уже доступны в девелоперской ветке на github. Опять же, не торопитесь использовать это на боевых серверах.
Автоматизация
Как известно, MongoDB умеет из коробки реплицироваться и шардироваться. В результате мы получаем не один экземпляр БД, а сразу несколько. В по-настоящему больших проектах таких нод может быть очень много. И проблема заключается не только в развёртывании всех этих нод, но и в их дальнейшем обновлении, бэкапировании, мониторинге и многом другом.
Всю эту рутину теперь за нас будет делать Mongo Management Service (MMS).
MMS представляет собой дружелюбный веб интерфейс, который позволяет решать целый ряд задач буквально в пару кликов мышкой:
- Развёртывание в один клик (coming soon)
- Мгновенное обновление нод (coming soon)
- Непрерывное (логирование) и инкрементальное создание резервных копий
- Откат к любому состоянию
- Мониторинг 100+ системных метрик
- Настраиваемые уведомлния
И на закуску: MMS научат интегрироваться с Amazon EC2.
Что дальше?
Мне очень нравится тот факт, что команда MongoDB уделяет много внимания тому, чтобы их продукт был удобен и полезен разработчикам. И делают это не в сферическом вакууме, а активно интересуясь мнением непосредственно у сообщества. Поэтому я уверен в том, что MongoDB и дальше будет сохранять отличный темп внедрения новых возможностей, совершенствовать безопасность, автоматизировать и делать ещё более незаметной всю рутину.
