В шахматных программах широко используются «битовые доски» (битборды 1, 2) для представления фигур на доске. А так же и для других игр на той же доске 8×8, и даже для карточных игр. С битбордами часто проводят различные операции, например, найти первый установленный бит или посчитать количество установленных битов. Для этих операций придумано много «хитрых» алгоритмов, а на современных процессорах некоторые из этих операций доступны в расширенном наборе инструкций. Например, popcnt, доступный в SSE4.2 ABM. Также есть пара инструкций bsf/bsr, которые доступны уже давно, но из JIT-компилятора к ним нет никакого доступа.
Конечно, всё серьёзные шахматные программы пишут на C++, но для прототипирования каких-нибудь алгоритмов хочется использовать C#, потому что я с ним лучше знаком и у меня меньше шансов выстрелить себе в ногу. Но производительность тоже не хочется терять просто так, в C/C++ интересующие нас инструкции доступны так называемые встроенные функции. Я попробовал сделать подобное решение и для C#.
Для SIMD инструкций есть готовые библиотеки, а для манпуляций с битами — нет.
Что делать? Надо как-то пропатчить имеющийся код.
Остановимся на том, что мы используем 64-битный процессор (на 32х битном не так весело работать с битбордами), и этот процесор — x86_64. Для несовместимых архитектур надо иметь фоллбэки (реализацию на C#). При таких условиях bsf/bsr будут доступны всегда, а popcnt недоступен только на довольно древнем железе, но об этом позже.
Самый простой вариант — написать DLL на С++ и экспортировать оттуда нужные нам функции. Но эти «функции» будут состоять из одной инструкции, а вокруг них будет несколько лишних джампов, которые возникнут при PInvoke.
Второй вариант: использовать GetDelegateForFunctionPointer, он похож на первый, но не требует отдельной нативной DLL.
Третий — подменять уже скомпилированный метод. Про это написано много интересных статей . Но тут возникают проблемы с тем, что это а) сложно б) появляются зависимости от внутренностей рантайма, а следовательно, и его версии. В итоге получаем громоздкое и нестбильное решение, это не наш путь.
Остаётся последний вариант: патчить скомпилированный JIT-ом код.
Для начала нам надо убедиться, что метод скомпилирован: RuntimeHelpers.PrepareMethod(). А чтобы добраться до машинного кода, майкрософт заботливо предоставило нам метод RuntimeMethodHandle.GetFunctionPointer(). Но по этой ссылке в зависимости от рантайма может оказаться как сам метод, так и трамплин на него. Хорошо, что трамплин бывает только одного вида — JMP. Этим мы и воспользуемся:
Итак, адрес мы получили, попробуем записать туда что-нибудь. Надо учесть Call-Convention, благо на x86_64 он один (первые четыре аргумента в RCX, RDX, R8, R9, результат в RAX):
Пробуем… Ура, работает!
Но сейчас наш вариант ничем не отличается по производительности от PInvoke/GetDelegateForFunctionPointer: тут есть лишние call/jmp из вызывающего метода. К тому же, если нашу функцию-фоллбэк компилятор зайинлайнил, то патч данного места ничем не поможет.
От инлайна можно довольно легко отказаться с помощью атрибута [MethodImpl(MethodImplOptions.NoInlining)])].
Ещё, как и в С++-intrinsics, необходимо полностью отказаться от call/jmp. С этим тоже довольно легко справиться, правда, придётся немного испачкать руки ассемблером. Патчить место вызова будем на лету. Для этого надо подменить код нашего фоллбэка не просто на нужную инструкцию, а на вызов «патчера» с нужными параметрами: по какому адресу и на что заменить.
Начнём с определения адреса: у нас есть адрес возврата в стэке (в dword ptr [rax]), обычно вызов нашего метода случается как раз перед ним. Если это инструкция call (а обычно это она), то нам надо проверить предыдущие 5 байт, и если это действительно был вызов нужного метода, то заменить их целиком на опкод нашей инструкции. Метод-патчер будет выглядеть вот так:
А вызывать мы его будем вручную из ассемблера, в итоге наш фоллбэк-метод будет заменён на такую штуку:
Всем этим занимается функция Patcher.PatchMethod, которую мы вызовем для всех методов, которые надо пропатчить.
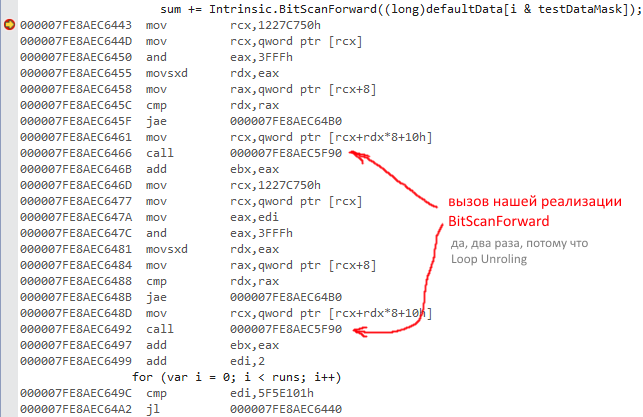
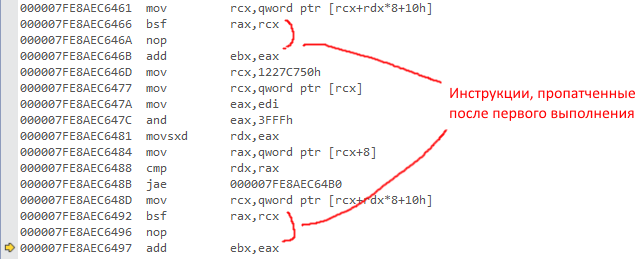
Вот как это выглядит на живом примере (из PerfTest):

(если картинку не видно)
и после первого прохода:
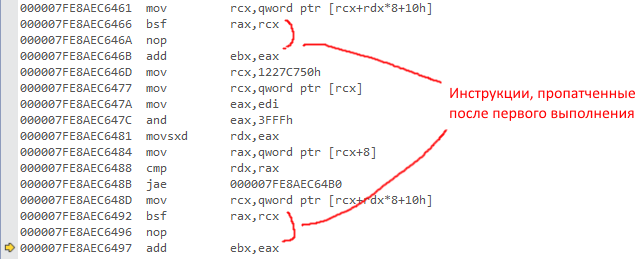
(если картинку не видно)
Теперь остались мелочи: JIT может что-нибудь куда-нибудь очень сильно заинлайнить, или сделать tail-call оптимизацию, тогда адрес возврата не очень-то будет соответствовать вызову нашей функции. К сожалению, я не смог найти примеры таких агрессивных оптимизаций, но на всякий случай это тоже надо проверять. Зная место, откуда был совершён call, мы можем проверить, что он на самом деле вызывал. Тут тоже надо перепрыгнуть через все jmp-ы, и проверить, что они приведут нас в нужное место. А благодаря тому, что заменяющие инструкции мы поместили в самом начале патча в неизменном виде, сделать это очень легко:
А ещё нам желательно ничего не трогать, если мы вдруг оказались на неподдерживаемой архитектуре. Для начала проверим, что она вообще 64-битная: (IntPtr.Size == 8). Дальше надо удостовериться, что это x86_64. Я не нашёл ничего лучше, чем сравнить пролог любой функции с заведомо верными инструкциями (см Patcher.VerifyPrologue в коде).
Некоторые инструкции, например popcnt, доступны не на всех процессорах. Если вам важна скорость, то лучше такие процессоры вообще не использовать, но в библиотеке желательно оставить для них фолл-бэк. В интеловском мануале написано, что проверить наличие инструкции popcnt можно вызвав cpuid с eax=01H и проверить бит ECX.POPCNT[Bit 23]. Тут нам на помощь приходит stackoverflow-driven development, где можно найти готовый кусок кода для вызова cpuid из C#.
Осталось только красиво всё это завернуть: делаем атрибут [ReplaceWith("F3 48 0F B8 C1", Cpiud1ECX = 1 << 23)], который клеим к фолбэк-функциям. В нём содержится кода, на который надо заменить данный intrinsic, а также условие доступности нужной инструкции.
Бенчмарки довольно примитивные: генерируем массив псевдо-случайных чисел, потом гоняем по нему 100млн раз каждый метод. Чтобы исключить влияние цикла и прочей обвязки, сначала измеряем время пустого цикла. Отдельно протестирован специальный случай «разреженных» досок: довольно часто доска содержит до 8 фигур или помеченных клеток, и на таких досках текущий выбранный фолбэк должен отрабатывать быстрее.
Я померял и проверил на двух процессорах, которые были под рукой: ноутбучный i7 и старый добрый Q6600. Вот детали тестов.
Сводная таблица результатов, тут уже вычтено время «холостого» цикла:
Как мы видим, на инструкциях bsf/bsr наш фоллбэк работает достаточно быстро, так что прирост от интринсика будет небольшим, и даже незаметным на фоне других частей алгоритма. А вот для popcnt уже намного лучше, если у вас есть Core i5/i7, то он ускорится в десятки раз.
Применительно к конечному алгоритму я получил ускорение всего-лишь на 15%, т.к. там ещё много кода, который не только считает биты. Как говорится, YMMV, проверяйте на своём коде.
Код можно взять на гитхабе.
гитхабе.
NuGet: Install-Package NetIntrinsics
Конечно, всё серьёзные шахматные программы пишут на C++, но для прототипирования каких-нибудь алгоритмов хочется использовать C#, потому что я с ним лучше знаком и у меня меньше шансов выстрелить себе в ногу. Но производительность тоже не хочется терять просто так, в C/C++ интересующие нас инструкции доступны так называемые встроенные функции. Я попробовал сделать подобное решение и для C#.
Для SIMD инструкций есть готовые библиотеки, а для манпуляций с битами — нет.
Что делать? Надо как-то пропатчить имеющийся код.
Остановимся на том, что мы используем 64-битный процессор (на 32х битном не так весело работать с битбордами), и этот процесор — x86_64. Для несовместимых архитектур надо иметь фоллбэки (реализацию на C#). При таких условиях bsf/bsr будут доступны всегда, а popcnt недоступен только на довольно древнем железе, но об этом позже.
Самый простой вариант — написать DLL на С++ и экспортировать оттуда нужные нам функции. Но эти «функции» будут состоять из одной инструкции, а вокруг них будет несколько лишних джампов, которые возникнут при PInvoke.
Второй вариант: использовать GetDelegateForFunctionPointer, он похож на первый, но не требует отдельной нативной DLL.
Третий — подменять уже скомпилированный метод. Про это написано много интересных статей . Но тут возникают проблемы с тем, что это а) сложно б) появляются зависимости от внутренностей рантайма, а следовательно, и его версии. В итоге получаем громоздкое и нестбильное решение, это не наш путь.
Остаётся последний вариант: патчить скомпилированный JIT-ом код.
Детали реализации
Для начала нам надо убедиться, что метод скомпилирован: RuntimeHelpers.PrepareMethod(). А чтобы добраться до машинного кода, майкрософт заботливо предоставило нам метод RuntimeMethodHandle.GetFunctionPointer(). Но по этой ссылке в зависимости от рантайма может оказаться как сам метод, так и трамплин на него. Хорошо, что трамплин бывает только одного вида — JMP. Этим мы и воспользуемся:
static byte* GetMethodPtr(MethodInfo method) { RuntimeHelpers.PrepareMethod(method.MethodHandle); var ptr = (byte*)method.MethodHandle.GetFunctionPointer(); // skip all jumps while (*ptr == 0xE9) { var delta = *(int*)(ptr + 1) + 5; ptr += delta; } return ptr; }
Итак, адрес мы получили, попробуем записать туда что-нибудь. Надо учесть Call-Convention, благо на x86_64 он один (первые четыре аргумента в RCX, RDX, R8, R9, результат в RAX):
//bsr rax, rcx; ret *ptr++ = 0x48; *ptr++ = 0x0F; *ptr++ = 0xBD; *ptr++ = 0xC1; *ptr++ = 0xC3;
Пробуем… Ура, работает!
Но сейчас наш вариант ничем не отличается по производительности от PInvoke/GetDelegateForFunctionPointer: тут есть лишние call/jmp из вызывающего метода. К тому же, если нашу функцию-фоллбэк компилятор зайинлайнил, то патч данного места ничем не поможет.
От инлайна можно довольно легко отказаться с помощью атрибута [MethodImpl(MethodImplOptions.NoInlining)])].
Ещё, как и в С++-intrinsics, необходимо полностью отказаться от call/jmp. С этим тоже довольно легко справиться, правда, придётся немного испачкать руки ассемблером. Патчить место вызова будем на лету. Для этого надо подменить код нашего фоллбэка не просто на нужную инструкцию, а на вызов «патчера» с нужными параметрами: по какому адресу и на что заменить.
Начнём с определения адреса: у нас есть адрес возврата в стэке (в dword ptr [rax]), обычно вызов нашего метода случается как раз перед ним. Если это инструкция call (а обычно это она), то нам надо проверить предыдущие 5 байт, и если это действительно был вызов нужного метода, то заменить их целиком на опкод нашей инструкции. Метод-патчер будет выглядеть вот так:
static void PatchCallSite(byte* rsp, ulong code) { var ptr = rsp - 5; // check call opcode if (*ptr != 0xE8) { // throw ERROR } const ulong Mask5Bytes = (1uL << 40) - 1; *(ulong*)ptr = *(ulong*)ptr & ~Mask5Bytes | (code & Mask5Bytes); }
А вызывать мы его будем вручную из ассемблера, в итоге наш фоллбэк-метод будет заменён на такую штуку:
bsr rax, rcx ; заменяющая инструкция nop ; дополним до 5 байт push rax ; сохраним её ответ sub rsp, 0x20 ; место под register spilling mov rcx, QWORD PTR [rsp+0x28] ; первый аргумент — адрес возврата ; он был на стэке при входе в функию, ; а сейчас «уполз» на 0x20 + 8 байт mov rdx, QWORD PTR [rip-0x16] ; второй аргумент — на что менять ; ссылается на начало этого куска кода movabs rax, <PatchCallSite> call rax add rsp, 0x20 ; поправляем стэк обратно pop rax ; достаём из него ответ ret
Всем этим занимается функция Patcher.PatchMethod, которую мы вызовем для всех методов, которые надо пропатчить.
Вот как это выглядит на живом примере (из PerfTest):
(если картинку не видно)
и после первого прохода:
(если картинку не видно)
Теперь остались мелочи: JIT может что-нибудь куда-нибудь очень сильно заинлайнить, или сделать tail-call оптимизацию, тогда адрес возврата не очень-то будет соответствовать вызову нашей функции. К сожалению, я не смог найти примеры таких агрессивных оптимизаций, но на всякий случай это тоже надо проверять. Зная место, откуда был совершён call, мы можем проверить, что он на самом деле вызывал. Тут тоже надо перепрыгнуть через все jmp-ы, и проверить, что они приведут нас в нужное место. А благодаря тому, что заменяющие инструкции мы поместили в самом начале патча в неизменном виде, сделать это очень легко:
// check call target var calltarget = ptr + *(int*)(ptr + 1) + 5; while (*calltarget == 0xE9) { var delta = *(int*)(calltarget + 1) + 5; calltarget += delta; } code &= Mask5Bytes; if ((*(ulong*)calltarget & Mask5Bytes) != code) { // throw ERROR }
А ещё нам желательно ничего не трогать, если мы вдруг оказались на неподдерживаемой архитектуре. Для начала проверим, что она вообще 64-битная: (IntPtr.Size == 8). Дальше надо удостовериться, что это x86_64. Я не нашёл ничего лучше, чем сравнить пролог любой функции с заведомо верными инструкциями (см Patcher.VerifyPrologue в коде).
Некоторые инструкции, например popcnt, доступны не на всех процессорах. Если вам важна скорость, то лучше такие процессоры вообще не использовать, но в библиотеке желательно оставить для них фолл-бэк. В интеловском мануале написано, что проверить наличие инструкции popcnt можно вызвав cpuid с eax=01H и проверить бит ECX.POPCNT[Bit 23]. Тут нам на помощь приходит stackoverflow-driven development, где можно найти готовый кусок кода для вызова cpuid из C#.
Осталось только красиво всё это завернуть: делаем атрибут [ReplaceWith("F3 48 0F B8 C1", Cpiud1ECX = 1 << 23)], который клеим к фолбэк-функциям. В нём содержится кода, на который надо заменить данный intrinsic, а также условие доступности нужной инструкции.
Бенчмарки
Бенчмарки довольно примитивные: генерируем массив псевдо-случайных чисел, потом гоняем по нему 100млн раз каждый метод. Чтобы исключить влияние цикла и прочей обвязки, сначала измеряем время пустого цикла. Отдельно протестирован специальный случай «разреженных» досок: довольно часто доска содержит до 8 фигур или помеченных клеток, и на таких досках текущий выбранный фолбэк должен отрабатывать быстрее.
Я померял и проверил на двух процессорах, которые были под рукой: ноутбучный i7 и старый добрый Q6600. Вот детали тестов.
i7-3667U
Testing Rng... 78ms, sum=369736839 Testing BitScanForward... 123ms, sum=99768073 Testing FallBack.BitScanForward... 239ms, sum=99768073 Testing PopCnt64... 106ms, sum=-1092098543 Testing FallBack.PopCnt64... 3143ms, sum=-1092098543 Testing PopCnt32... 106ms, sum=1598980778 Testing FallBack.PopCnt32... 2139ms, sum=1598980778 Testing PopCnt64 on sparse data... 106ms, sum=758117720 Testing FallBack.PopCnt64 on sparse data... 952ms, sum=758117720
Q6600
Patch status: Ok Feature PopCnt is not supported by this CPU Feature PopCnt is not supported by this CPU Testing Rng... 92ms, sum=369736839 Testing BitScanForward... 154ms, sum=99768073 Testing FallBack.BitScanForward... 323ms, sum=99768073 Testing PopCnt64... 3832ms, sum=-1092098543 Testing FallBack.PopCnt64... 3583ms, sum=-1092098543 Testing PopCnt32... 2414ms, sum=1598980778 Testing FallBack.PopCnt32... 3249ms, sum=1598980778 Testing PopCnt64 on sparse data... 1662ms, sum=758117720 Testing FallBack.PopCnt64 on sparse data... 1076ms, sum=758117720
Сводная таблица результатов, тут уже вычтено время «холостого» цикла:
| bsf | bsf fallback | popcnt64 | popcnt64 fallback | popcnt32 | popcnt32 fallback | sparse popcnt64 | sparse popcnt64 fallback | |
|---|---|---|---|---|---|---|---|---|
| i7-3667U | 45ms | 161ms (~3.6x slower) |
28ms | 3065ms (~100x slower) |
28ms | 2061ms (~70x slower) |
28ms | 874ms (~30x slower) |
| Q6600 | 62ms | 231ms (~3.7x slower) |
N/A | 3491ms | N/A | 3157ms | N/A | 984ms |
Как мы видим, на инструкциях bsf/bsr наш фоллбэк работает достаточно быстро, так что прирост от интринсика будет небольшим, и даже незаметным на фоне других частей алгоритма. А вот для popcnt уже намного лучше, если у вас есть Core i5/i7, то он ускорится в десятки раз.
Применительно к конечному алгоритму я получил ускорение всего-лишь на 15%, т.к. там ещё много кода, который не только считает биты. Как говорится, YMMV, проверяйте на своём коде.
Где взять
Код можно взять на
NuGet: Install-Package NetIntrinsics

{kind=link}
{kind=link}